 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bidirectional Feature Globalization for Few-shot Semantic Segmentation of 3D Point Cloud Scenes
Aug 13, 2022
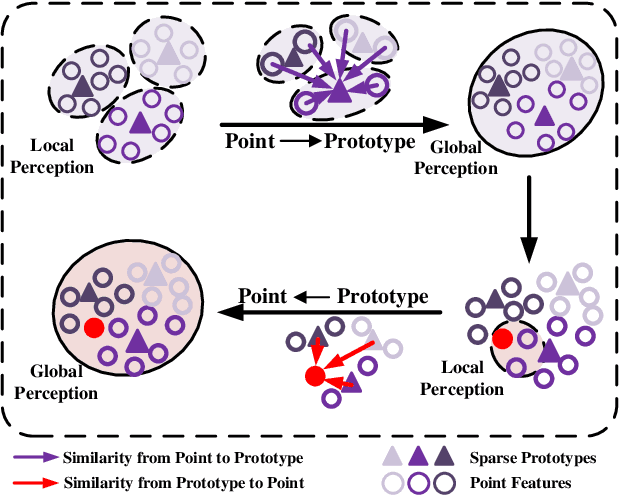
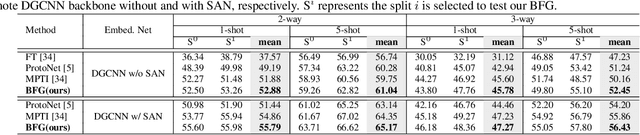
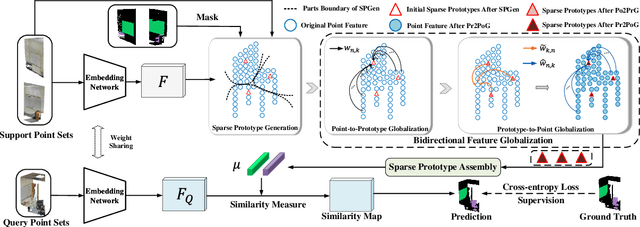
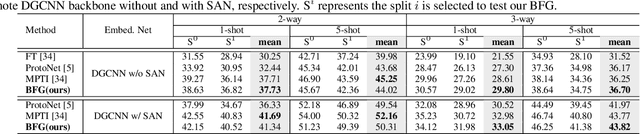
Few-shot segmentation of point cloud remains a challenging task, as there is no effective way to convert local point cloud information to global representation, which hinders the generalization ability of point features. In this study, we propose a bidirectional feature globalization (BFG) approach, which leverages the similarity measurement between point features and prototype vectors to embed global perception to local point features in a bidirectional fashion. With point-to-prototype globalization (Po2PrG), BFG aggregates local point features to prototypes according to similarity weights from dense point features to sparse prototypes. With prototype-to-point globalization (Pr2PoG), the global perception is embedded to local point features based on similarity weights from sparse prototypes to dense point features. The sparse prototypes of each class embedded with global perception are summarized to a single prototype for few-shot 3D segmentation based on the metric learning framework. Extensive experiments on S3DIS and ScanNet demonstrate that BFG significantly outperforms the state-of-the-art methods.
ULDGNN: A Fragmented UI Layer Detector Based on Graph Neural Networks
Aug 13, 2022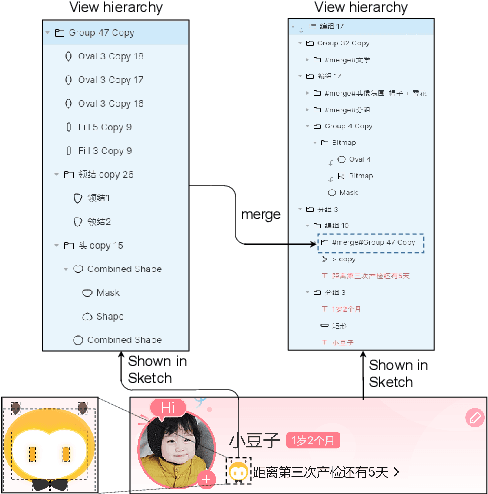
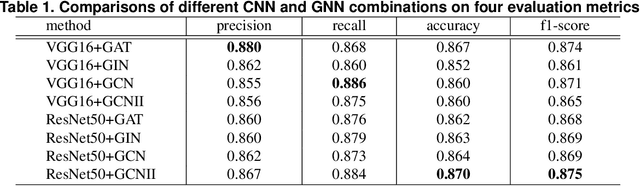
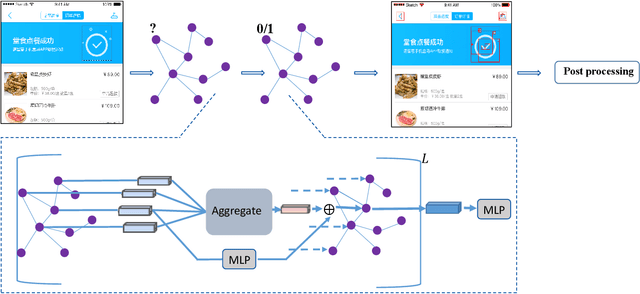

While some work attempt to generate front-end code intelligently from UI screenshots, it may be more convenient to utilize UI design drafts in Sketch which is a popular UI design software, because we can access multimodal UI information directly such as layers type, position, size, and visual images. However, fragmented layers could degrade the code quality without being merged into a whole part if all of them are involved in the code generation. In this paper, we propose a pipeline to merge fragmented layers automatically. We first construct a graph representation for the layer tree of a UI draft and detect all fragmented layers based on the visual features and graph neural networks. Then a rule-based algorithm is designed to merge fragmented layers. Through experiments on a newly constructed dataset, our approach can retrieve most fragmented layers in UI design drafts, and achieve 87% accuracy in the detection task, and the post-processing algorithm is developed to cluster associative layers under simple and general circumstances.
Where the Earth is flat and 9/11 is an inside job: A comparative algorithm audit of conspiratorial information in web search results
Dec 06, 2021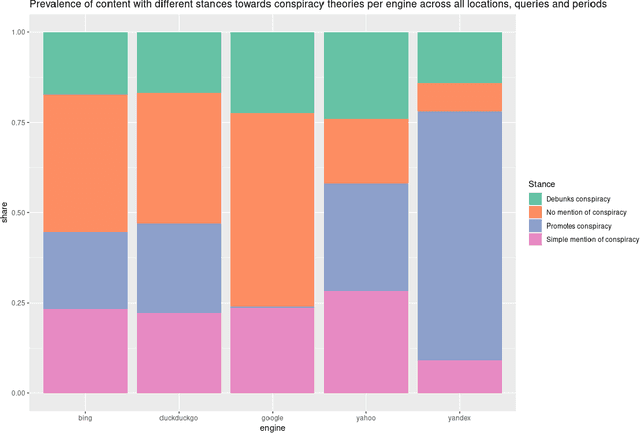
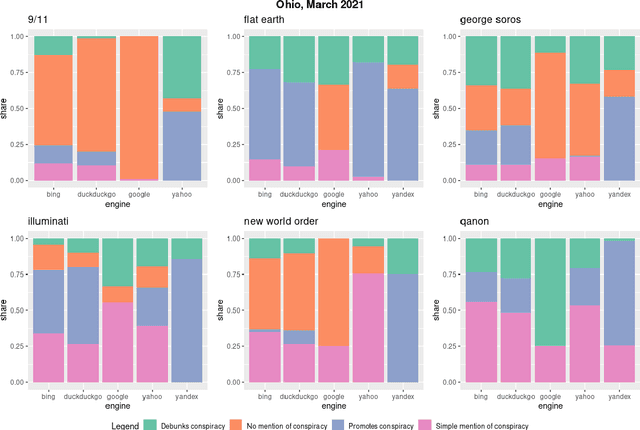
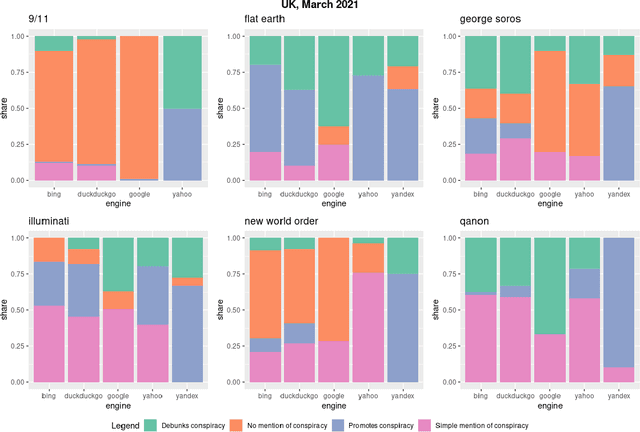
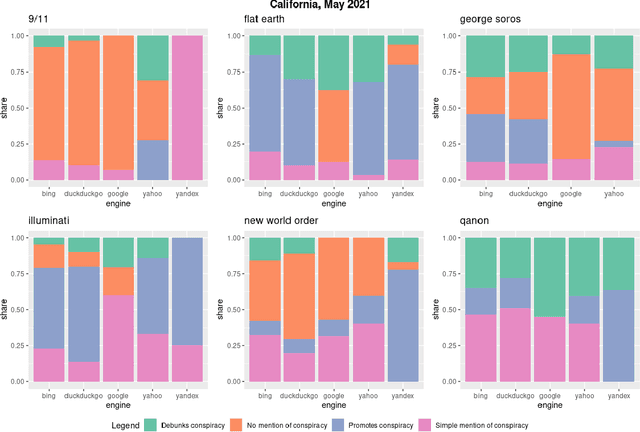
Web search engines are important online information intermediaries that are frequently used and highly trusted by the public despite multiple evidence of their outputs being subjected to inaccuracies and biases. One form of such inaccuracy, which so far received little scholarly attention, is the presence of conspiratorial information, namely pages promoting conspiracy theories. We address this gap by conducting a comparative algorithm audit to examine the distribution of conspiratorial information in search results across five search engines: Google, Bing, DuckDuckGo, Yahoo and Yandex. Using a virtual agent-based infrastructure, we systematically collect search outputs for six conspiracy theory-related queries (flat earth, new world order, qanon, 9/11, illuminati, george soros) across three locations (two in the US and one in the UK) and two observation periods (March and May 2021). We find that all search engines except Google consistently displayed conspiracy-promoting results and returned links to conspiracy-dedicated websites in their top results, although the share of such content varied across queries. Most conspiracy-promoting results came from social media and conspiracy-dedicated websites while conspiracy-debunking information was shared by scientific websites and, to a lesser extent, legacy media. The fact that these observations are consistent across different locations and time periods highlight the possibility of some search engines systematically prioritizing conspiracy-promoting content and, thus, amplifying their distribution in the online environments.
Domain Generalization with Relaxed Instance Frequency-wise Normalization for Multi-device Acoustic Scene Classification
Jun 24, 2022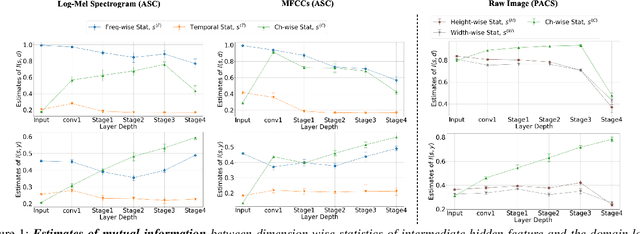
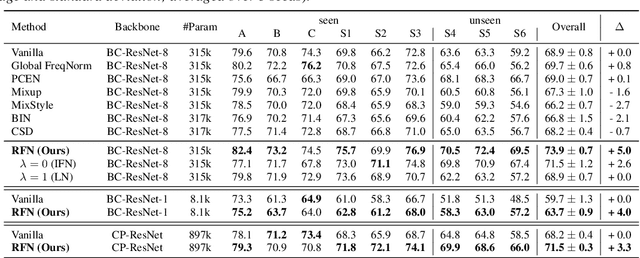
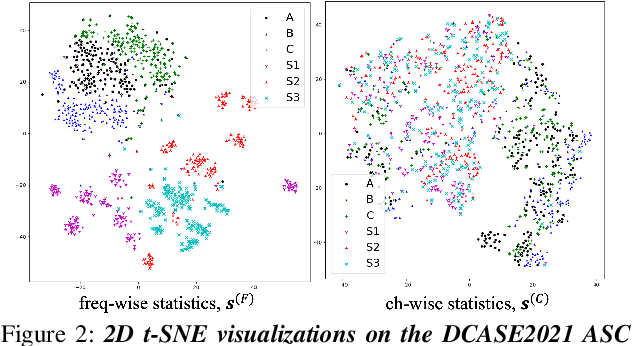
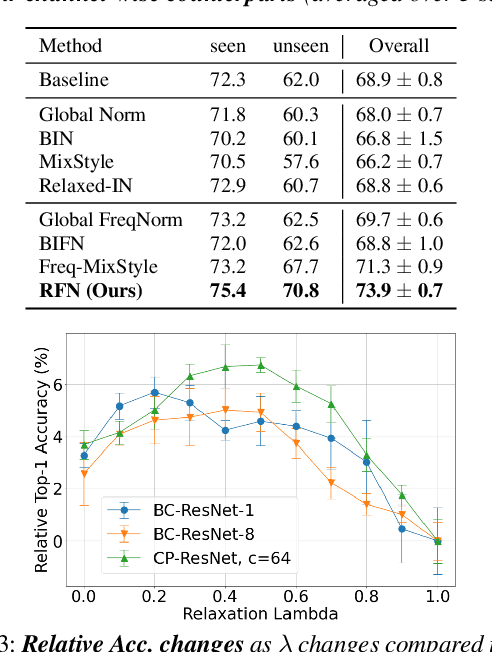
While using two-dimensional convolutional neural networks (2D-CNNs) in image processing, it is possible to manipulate domain information using channel statistics, and instance normalization has been a promising way to get domain-invariant features. However, unlike image processing, we analyze that domain-relevant information in an audio feature is dominant in frequency statistics rather than channel statistics. Motivated by our analysis, we introduce Relaxed Instance Frequency-wise Normalization (RFN): a plug-and-play, explicit normalization module along the frequency axis which can eliminate instance-specific domain discrepancy in an audio feature while relaxing undesirable loss of useful discriminative information. Empirically, simply adding RFN to networks shows clear margins compared to previous domain generalization approaches on acoustic scene classification and yields improved robustness for multiple audio devices. Especially, the proposed RFN won the DCASE2021 challenge TASK1A, low-complexity acoustic scene classification with multiple devices, with a clear margin, and RFN is an extended work of our technical report.
InstanceFormer: An Online Video Instance Segmentation Framework
Aug 22, 2022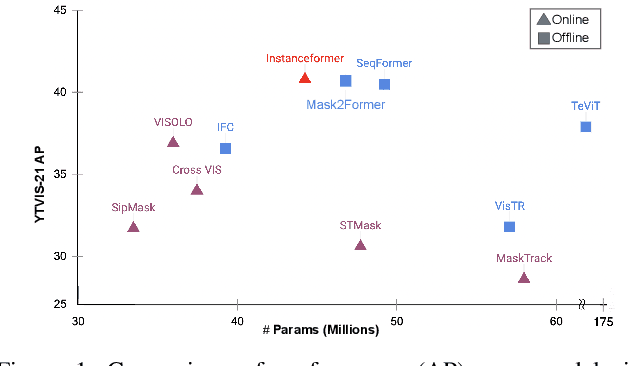
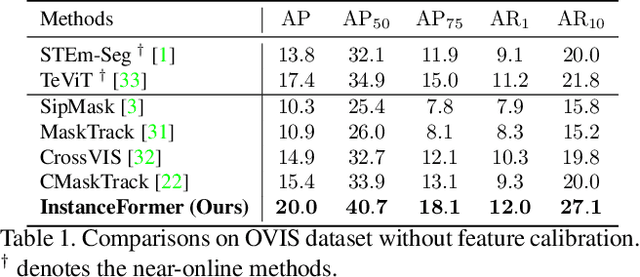
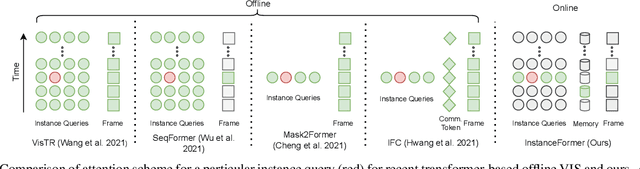
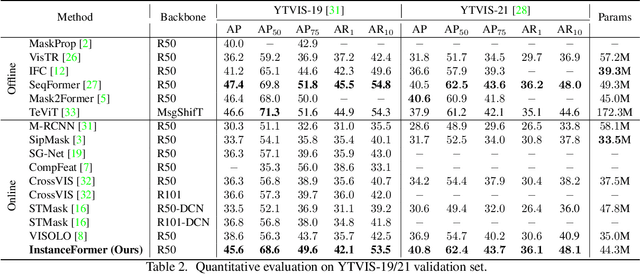
Recent transformer-based offline video instance segmentation (VIS) approaches achieve encouraging results and significantly outperform online approaches. However, their reliance on the whole video and the immense computational complexity caused by full Spatio-temporal attention limit them in real-life applications such as processing lengthy videos. In this paper, we propose a single-stage transformer-based efficient online VIS framework named InstanceFormer, which is especially suitable for long and challenging videos. We propose three novel components to model short-term and long-term dependency and temporal coherence. First, we propagate the representation, location, and semantic information of prior instances to model short-term changes. Second, we propose a novel memory cross-attention in the decoder, which allows the network to look into earlier instances within a certain temporal window. Finally, we employ a temporal contrastive loss to impose coherence in the representation of an instance across all frames. Memory attention and temporal coherence are particularly beneficial to long-range dependency modeling, including challenging scenarios like occlusion. The proposed InstanceFormer outperforms previous online benchmark methods by a large margin across multiple datasets. Most importantly, InstanceFormer surpasses offline approaches for challenging and long datasets such as YouTube-VIS-2021 and OVIS. Code is available at https://github.com/rajatkoner08/InstanceFormer.
Efficient Learning of Pinball TWSVM using Privileged Information and its applications
Jul 14, 2021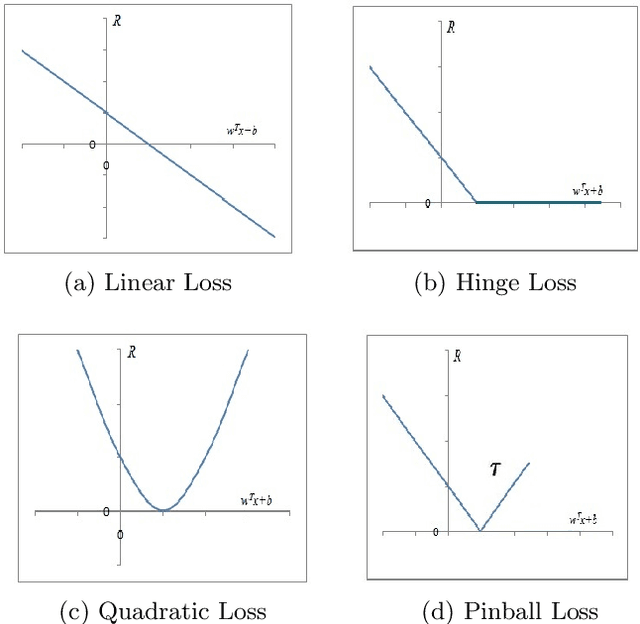

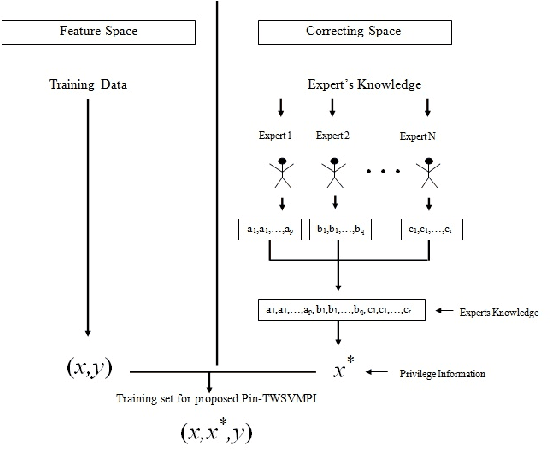

In any learning framework, an expert knowledge always plays a crucial role. But, in the field of machine learning, the knowledge offered by an expert is rarely used. Moreover, machine learning algorithms (SVM based) generally use hinge loss function which is sensitive towards the noise. Thus, in order to get the advantage from an expert knowledge and to reduce the sensitivity towards the noise, in this paper, we propose privileged information based Twin Pinball Support Vector Machine classifier (Pin-TWSVMPI) where expert's knowledge is in the form of privileged information. The proposed Pin-TWSVMPI incorporates privileged information by using correcting function so as to obtain two nonparallel decision hyperplanes. Further, in order to make computations more efficient and fast, we use Sequential Minimal Optimization (SMO) technique for obtaining the classifier and have also shown its application for Pedestrian detection and Handwritten digit recognition. Further, for UCI datasets, we first implement a procedure which extracts privileged information from the features of the dataset which are then further utilized by Pin-TWSVMPI that leads to enhancement in classification accuracy with comparatively lesser computational time.
Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis
Sep 01, 2021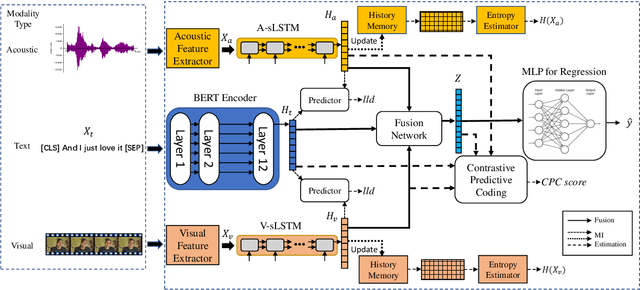
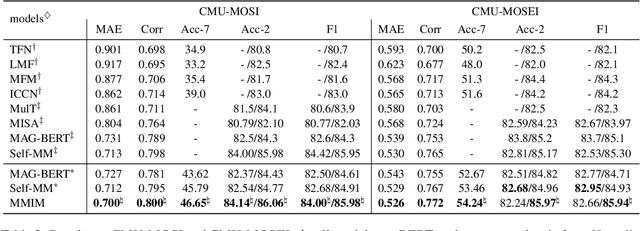
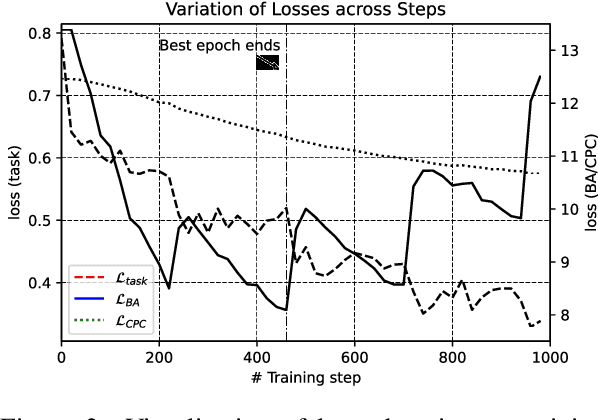
In multimodal sentiment analysis (MSA), the performance of a model highly depends on the quality of synthesized embeddings. These embeddings are generated from the upstream process called multimodal fusion, which aims to extract and combine the input unimodal raw data to produce a richer multimodal representation. Previous work either back-propagates the task loss or manipulates the geometric property of feature spaces to produce favorable fusion results, which neglects the preservation of critical task-related information that flows from input to the fusion results. In this work, we propose a framework named MultiModal InfoMax (MMIM), which hierarchically maximizes the Mutual Information (MI) in unimodal input pairs (inter-modality) and between multimodal fusion result and unimodal input in order to maintain task-related information through multimodal fusion. The framework is jointly trained with the main task (MSA) to improve the performance of the downstream MSA task. To address the intractable issue of MI bounds, we further formulate a set of computationally simple parametric and non-parametric methods to approximate their truth value. Experimental results on the two widely used datasets demonstrate the efficacy of our approach. The implementation of this work is publicly available at https://github.com/declare-lab/Multimodal-Infomax.
Few-Shot Semantic Relation Prediction across Heterogeneous Graphs
Jul 11, 2022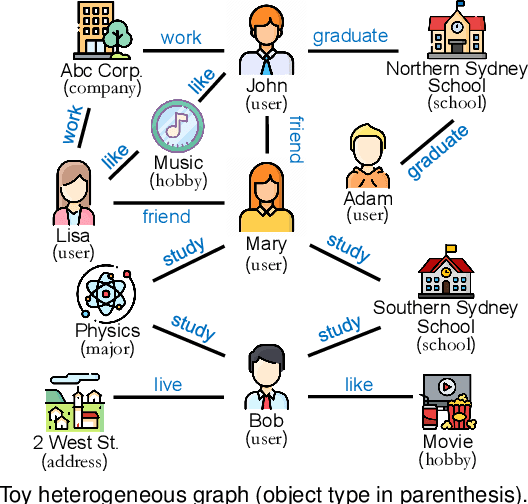

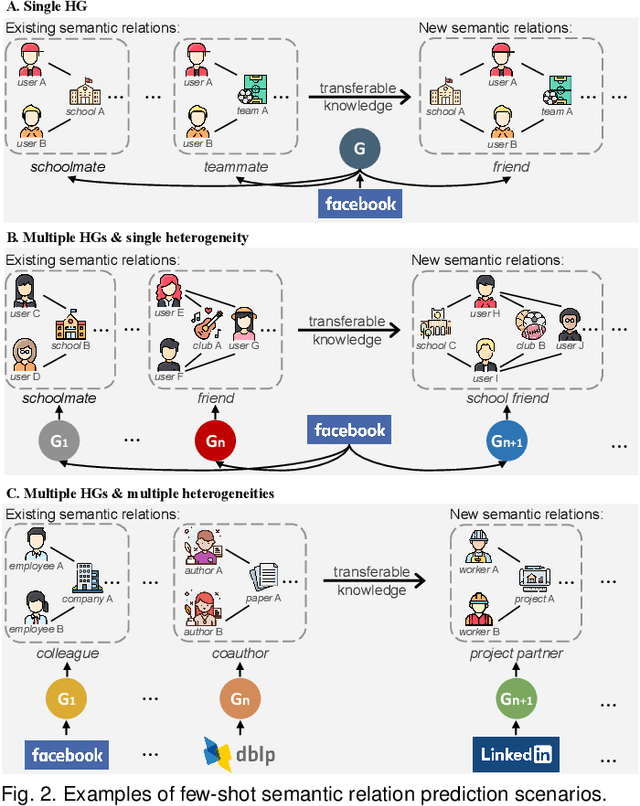
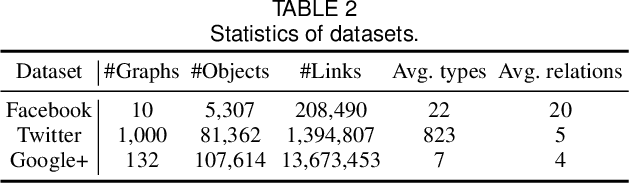
Semantic relation prediction aims to mine the implicit relationships between objects in heterogeneous graphs, which consist of different types of objects and different types of links. In real-world scenarios, new semantic relations constantly emerge and they typically appear with only a few labeled data. Since a variety of semantic relations exist in multiple heterogeneous graphs, the transferable knowledge can be mined from some existing semantic relations to help predict the new semantic relations with few labeled data. This inspires a novel problem of few-shot semantic relation prediction across heterogeneous graphs. However, the existing methods cannot solve this problem because they not only require a large number of labeled samples as input, but also focus on a single graph with a fixed heterogeneity. Targeting this novel and challenging problem, in this paper, we propose a Meta-learning based Graph neural network for Semantic relation prediction, named MetaGS. Firstly, MetaGS decomposes the graph structure between objects into multiple normalized subgraphs, then adopts a two-view graph neural network to capture local heterogeneous information and global structure information of these subgraphs. Secondly, MetaGS aggregates the information of these subgraphs with a hyper-prototypical network, which can learn from existing semantic relations and adapt to new semantic relations. Thirdly, using the well-initialized two-view graph neural network and hyper-prototypical network, MetaGS can effectively learn new semantic relations from different graphs while overcoming the limitation of few labeled data. Extensive experiments on three real-world datasets have demonstrated the superior performance of MetaGS over the state-of-the-art methods.
SAL-CNN: Estimate the Remaining Useful Life of Bearings Using Time-frequency Information
Apr 11, 2022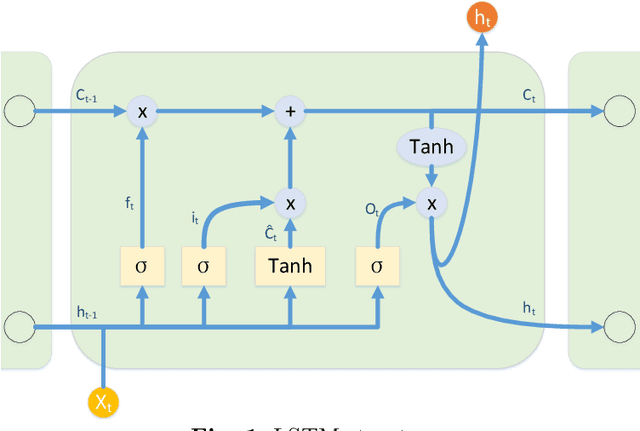
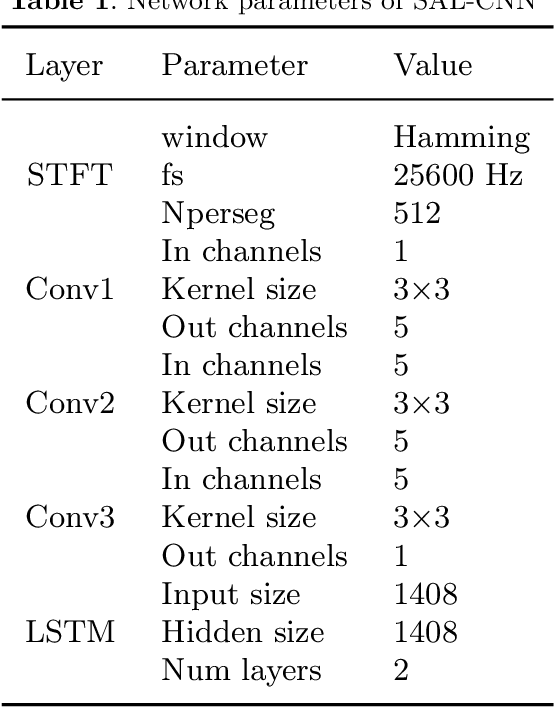
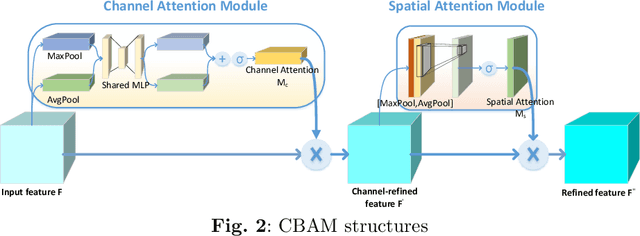

In modern industrial production, the prediction ability of the remaining useful life (RUL) of bearings directly affects the safety and stability of the system. Traditional methods require rigorous physical modeling and perform poorly for complex systems. In this paper, an end-to-end RUL prediction method is proposed, which uses short-time Fourier transform (STFT) as preprocessing. Considering the time correlation of signal sequences, a long and short-term memory network is designed in CNN, incorporating the convolutional block attention module, and understanding the decision-making process of the network from the interpretability level. Experiments were carried out on the 2012PHM dataset and compared with other methods, and the results proved the effectiveness of the method.
Dynamic collaborative filtering Thompson Sampling for cross-domain advertisements recommendation
Aug 25, 2022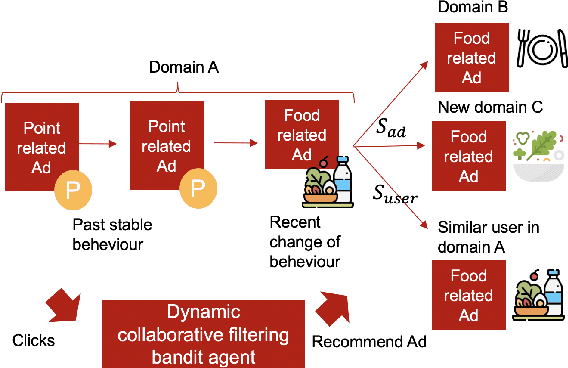
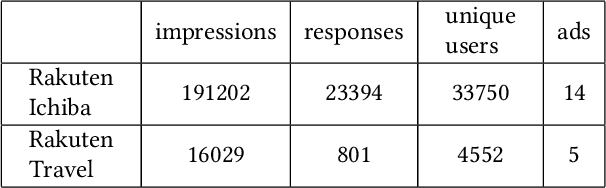
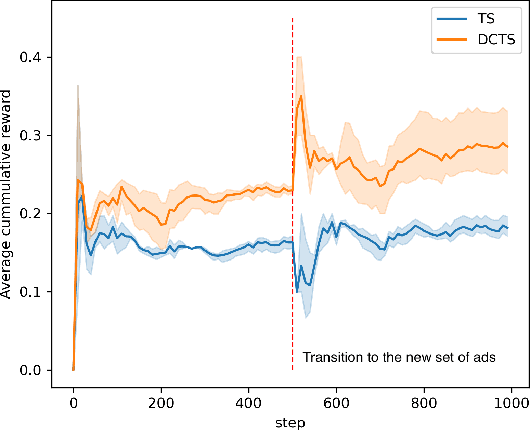
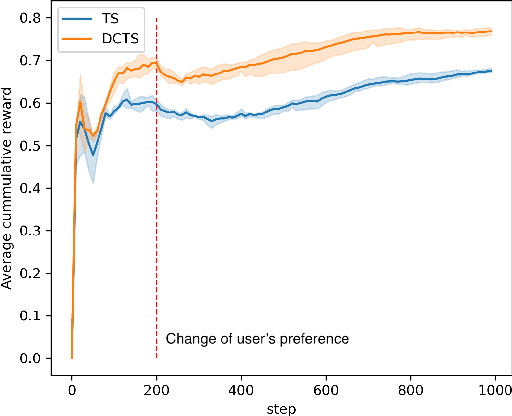
Recently online advertisers utilize Recommender systems (RSs) for display advertising to improve users' engagement. The contextual bandit model is a widely used RS to exploit and explore users' engagement and maximize the long-term rewards such as clicks or conversions. However, the current models aim to optimize a set of ads only in a specific domain and do not share information with other models in multiple domains. In this paper, we propose dynamic collaborative filtering Thompson Sampling (DCTS), the novel yet simple model to transfer knowledge among multiple bandit models. DCTS exploits similarities between users and between ads to estimate a prior distribution of Thompson sampling. Such similarities are obtained based on contextual features of users and ads. Similarities enable models in a domain that didn't have much data to converge more quickly by transferring knowledge. Moreover, DCTS incorporates temporal dynamics of users to track the user's recent change of preference. We first show transferring knowledge and incorporating temporal dynamics improve the performance of the baseline models on a synthetic dataset. Then we conduct an empirical analysis on a real-world dataset and the result showed that DCTS improves click-through rate by 9.7% than the state-of-the-art models. We also analyze hyper-parameters that adjust temporal dynamics and similarities and show the best parameter which maximizes CTR.