 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Efficient Self-Supervision using Patch-based Contrastive Learning for Histopathology Image Segmentation
Aug 23, 2022

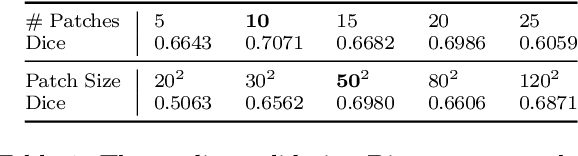
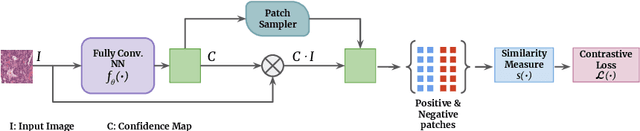
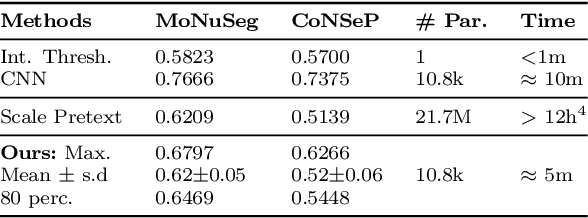
Learning discriminative representations of unlabelled data is a challenging task. Contrastive self-supervised learning provides a framework to learn meaningful representations using learned notions of similarity measures from simple pretext tasks. In this work, we propose a simple and efficient framework for self-supervised image segmentation using contrastive learning on image patches, without using explicit pretext tasks or any further labeled fine-tuning. A fully convolutional neural network (FCNN) is trained in a self-supervised manner to discern features in the input images and obtain confidence maps which capture the network's belief about the objects belonging to the same class. Positive- and negative- patches are sampled based on the average entropy in the confidence maps for contrastive learning. Convergence is assumed when the information separation between the positive patches is small, and the positive-negative pairs is large. We evaluate this method for the task of segmenting nuclei from multiple histopathology datasets, and show comparable performance with relevant self-supervised and supervised methods. The proposed model only consists of a simple FCNN with 10.8k parameters and requires about 5 minutes to converge on the high resolution microscopy datasets, which is orders of magnitude smaller than the relevant self-supervised methods to attain similar performance.
DeepSportradar-v1: Computer Vision Dataset for Sports Understanding with High Quality Annotations
Aug 17, 2022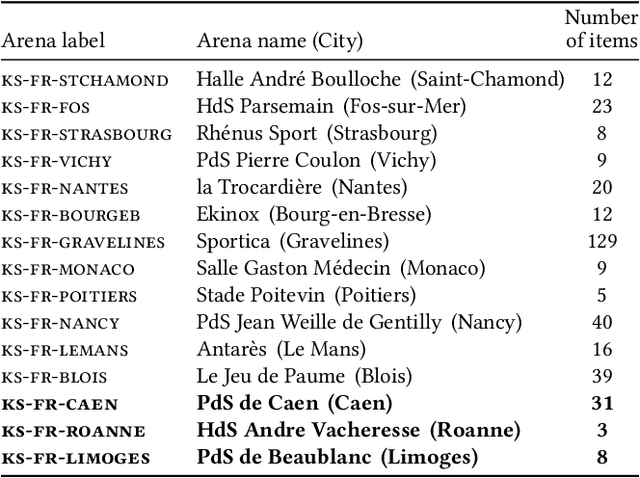
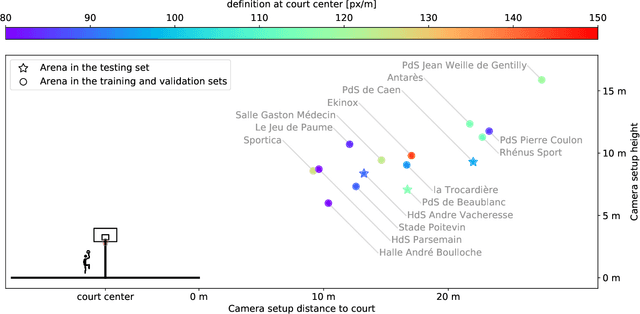


With the recent development of Deep Learning applied to Computer Vision, sport video understanding has gained a lot of attention, providing much richer information for both sport consumers and leagues. This paper introduces DeepSportradar-v1, a suite of computer vision tasks, datasets and benchmarks for automated sport understanding. The main purpose of this framework is to close the gap between academic research and real world settings. To this end, the datasets provide high-resolution raw images, camera parameters and high quality annotations. DeepSportradar currently supports four challenging tasks related to basketball: ball 3D localization, camera calibration, player instance segmentation and player re-identification. For each of the four tasks, a detailed description of the dataset, objective, performance metrics, and the proposed baseline method are provided. To encourage further research on advanced methods for sport understanding, a competition is organized as part of the MMSports workshop from the ACM Multimedia 2022 conference, where participants have to develop state-of-the-art methods to solve the above tasks. The four datasets, development kits and baselines are publicly available.
Where the Earth is flat and 9/11 is an inside job: A comparative algorithm audit of conspiratorial information in web search results
Dec 06, 2021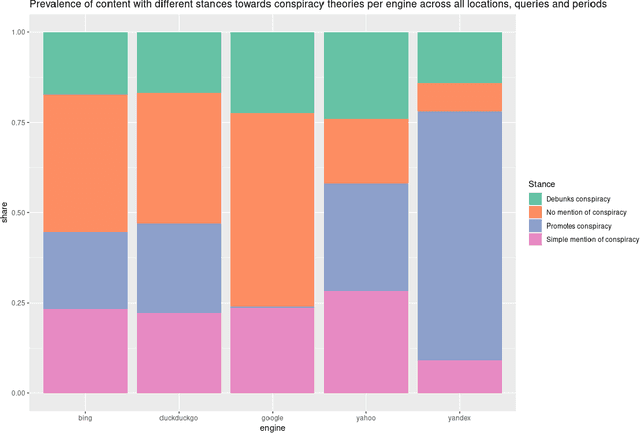
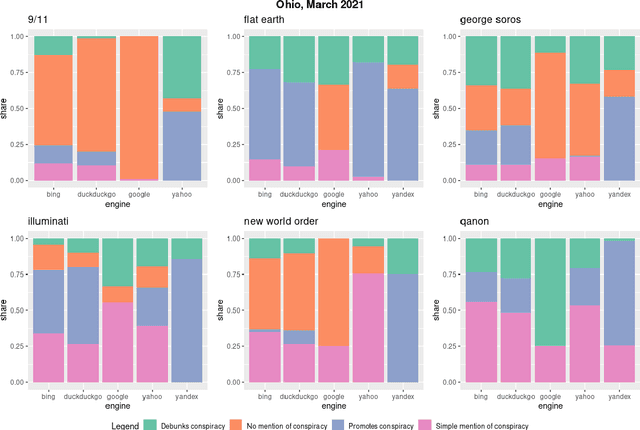
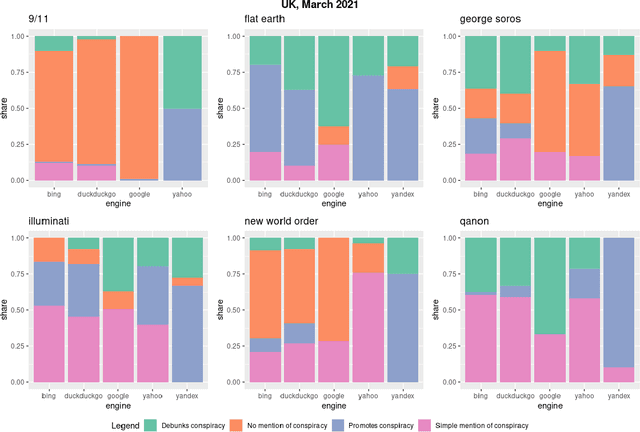
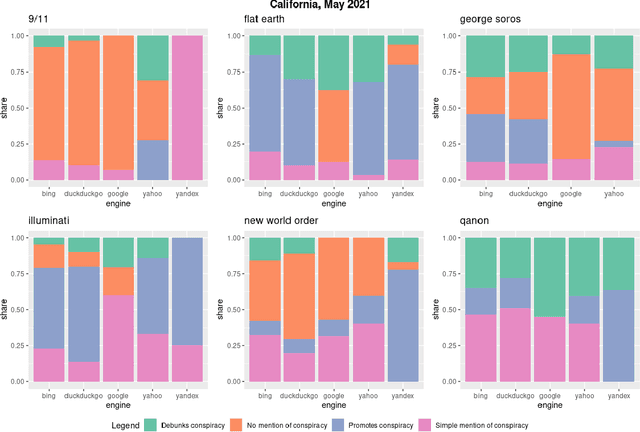
Web search engines are important online information intermediaries that are frequently used and highly trusted by the public despite multiple evidence of their outputs being subjected to inaccuracies and biases. One form of such inaccuracy, which so far received little scholarly attention, is the presence of conspiratorial information, namely pages promoting conspiracy theories. We address this gap by conducting a comparative algorithm audit to examine the distribution of conspiratorial information in search results across five search engines: Google, Bing, DuckDuckGo, Yahoo and Yandex. Using a virtual agent-based infrastructure, we systematically collect search outputs for six conspiracy theory-related queries (flat earth, new world order, qanon, 9/11, illuminati, george soros) across three locations (two in the US and one in the UK) and two observation periods (March and May 2021). We find that all search engines except Google consistently displayed conspiracy-promoting results and returned links to conspiracy-dedicated websites in their top results, although the share of such content varied across queries. Most conspiracy-promoting results came from social media and conspiracy-dedicated websites while conspiracy-debunking information was shared by scientific websites and, to a lesser extent, legacy media. The fact that these observations are consistent across different locations and time periods highlight the possibility of some search engines systematically prioritizing conspiracy-promoting content and, thus, amplifying their distribution in the online environments.
Joint Entropy Search For Maximally-Informed Bayesian Optimization
Jun 09, 2022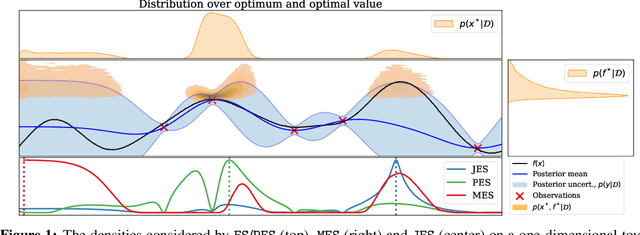
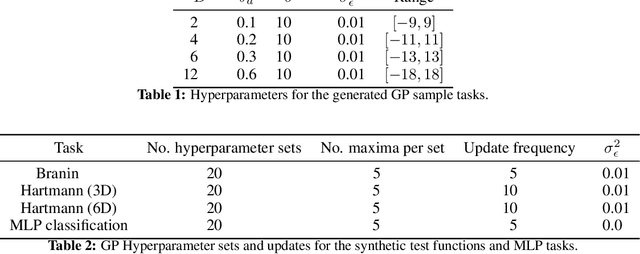
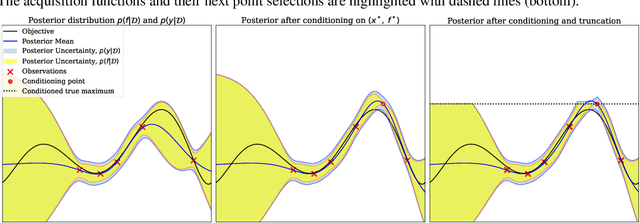
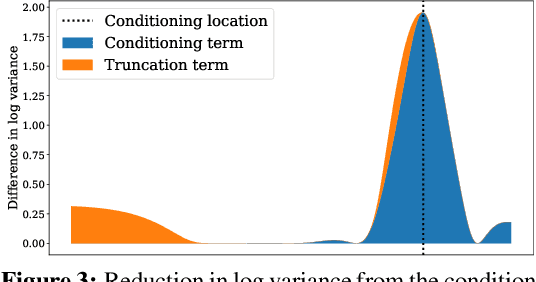
Information-theoretic Bayesian optimization techniques have become popular for optimizing expensive-to-evaluate black-box functions due to their non-myopic qualities. Entropy Search and Predictive Entropy Search both consider the entropy over the optimum in the input space, while the recent Max-value Entropy Search considers the entropy over the optimal value in the output space. We propose Joint Entropy Search (JES), a novel information-theoretic acquisition function that considers an entirely new quantity, namely the entropy over the joint optimal probability density over both input and output space. To incorporate this information, we consider the reduction in entropy from conditioning on fantasized optimal input/output pairs. The resulting approach primarily relies on standard GP machinery and removes complex approximations typically associated with information-theoretic methods. With minimal computational overhead, JES shows superior decision-making, and yields state-of-the-art performance for information-theoretic approaches across a wide suite of tasks. As a light-weight approach with superior results, JES provides a new go-to acquisition function for Bayesian optimization.
Few-Shot Learning of Accurate Folding Landscape for Protein Structure Prediction
Aug 20, 2022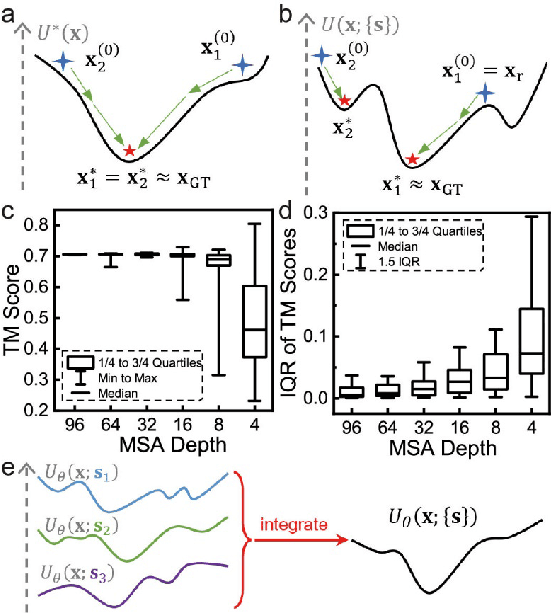
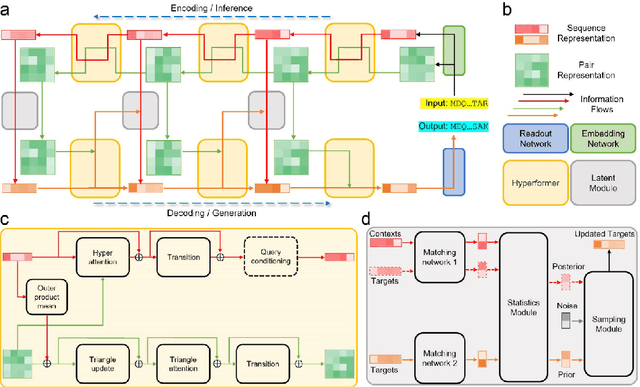
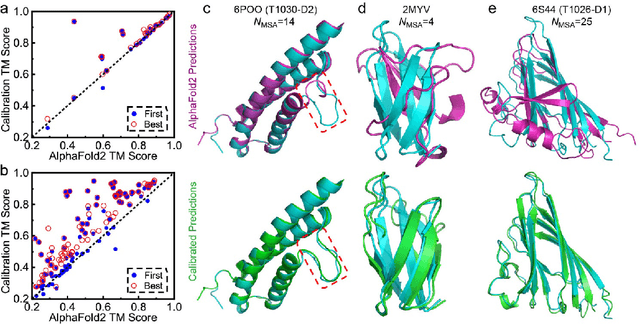
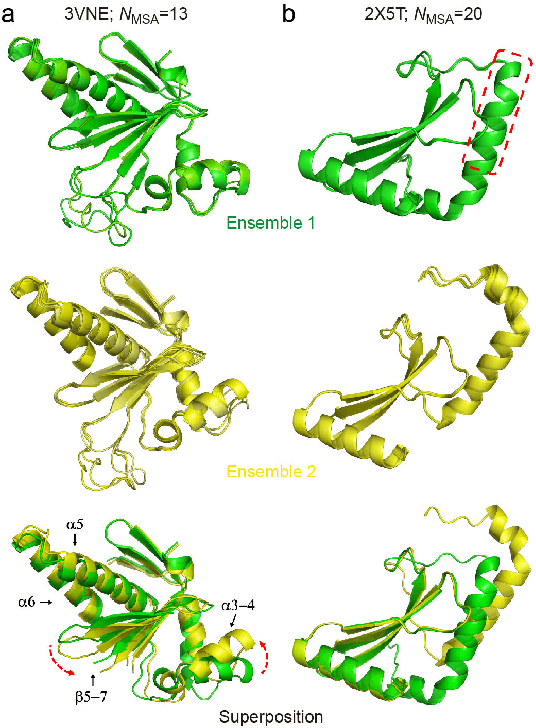
Data-driven predictive methods which can efficiently and accurately transform protein sequences into biologically active structures are highly valuable for scientific research and therapeutical development. Determining accurate folding landscape using co-evolutionary information is fundamental to the success of modern protein structure prediction methods. As the state of the art, AlphaFold2 has dramatically raised the accuracy without performing explicit co-evolutionary analysis. Nevertheless, its performance still shows strong dependence on available sequence homologs. We investigated the cause of such dependence and presented EvoGen, a meta generative model, to remedy the underperformance of AlphaFold2 for poor MSA targets. EvoGen allows us to manipulate the folding landscape either by denoising the searched MSA or by generating virtual MSA, and helps AlphaFold2 fold accurately in low-data regime or even achieve encouraging performance with single-sequence predictions. Being able to make accurate predictions with few-shot MSA not only generalizes AlphaFold2 better for orphan sequences, but also democratizes its use for high-throughput applications. Besides, EvoGen combined with AlphaFold2 yields a probabilistic structure generation method which could explore alternative conformations of protein sequences, and the task-aware differentiable algorithm for sequence generation will benefit other related tasks including protein design.
Riesz-Quincunx-UNet Variational Auto-Encoder for Satellite Image Denoising
Aug 25, 2022


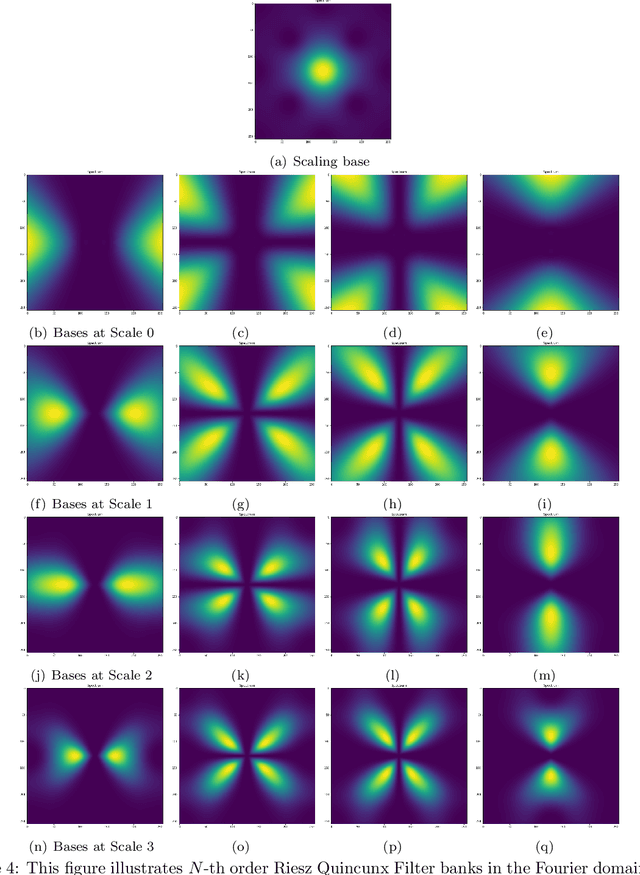
Multiresolution deep learning approaches, such as the U-Net architecture, have achieved high performance in classifying and segmenting images. However, these approaches do not provide a latent image representation and cannot be used to decompose, denoise, and reconstruct image data. The U-Net and other convolutional neural network (CNNs) architectures commonly use pooling to enlarge the receptive field, which usually results in irreversible information loss. This study proposes to include a Riesz-Quincunx (RQ) wavelet transform, which combines 1) higher-order Riesz wavelet transform and 2) orthogonal Quincunx wavelets (which have both been used to reduce blur in medical images) inside the U-net architecture, to reduce noise in satellite images and their time-series. In the transformed feature space, we propose a variational approach to understand how random perturbations of the features affect the image to further reduce noise. Combining both approaches, we introduce a hybrid RQUNet-VAE scheme for image and time series decomposition used to reduce noise in satellite imagery. We present qualitative and quantitative experimental results that demonstrate that our proposed RQUNet-VAE was more effective at reducing noise in satellite imagery compared to other state-of-the-art methods. We also apply our scheme to several applications for multi-band satellite images, including: image denoising, image and time-series decomposition by diffusion and image segmentation.
Probabilistic Safe Online Learning with Control Barrier Functions
Aug 23, 2022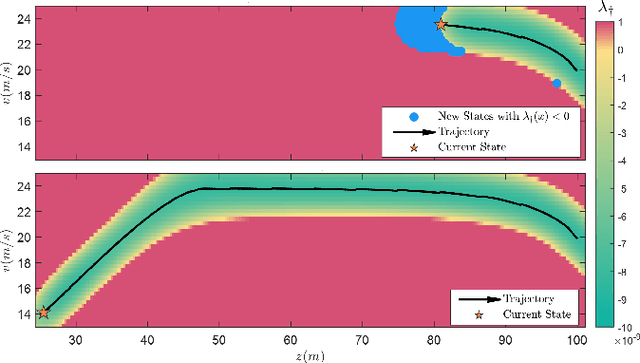
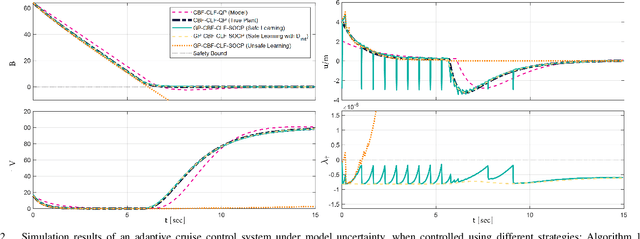
Learning-based control schemes have recently shown great efficacy performing complex tasks. However, in order to deploy them in real systems, it is of vital importance to guarantee that the system will remain safe during online training and execution. We therefore need safe online learning frameworks able to autonomously reason about whether the current information at their disposal is enough to ensure safety or, in contrast, new measurements are required. In this paper, we present a framework consisting of two parts: first, an out-of-distribution detection mechanism actively collecting measurements when needed to guarantee that at least one safety backup direction is always available for use; and second, a Gaussian Process-based probabilistic safety-critical controller that ensures the system stays safe at all times with high probability. Our method exploits model knowledge through the use of Control Barrier Functions, and collects measurements from the stream of online data in an event-triggered fashion to guarantee recursive feasibility of the learned safety-critical controller. This, in turn, allows us to provide formal results of forward invariance of a safe set with high probability, even in a priori unexplored regions. Finally, we validate the proposed framework in numerical simulations of an adaptive cruise control system.
Video Mobile-Former: Video Recognition with Efficient Global Spatial-temporal Modeling
Aug 25, 2022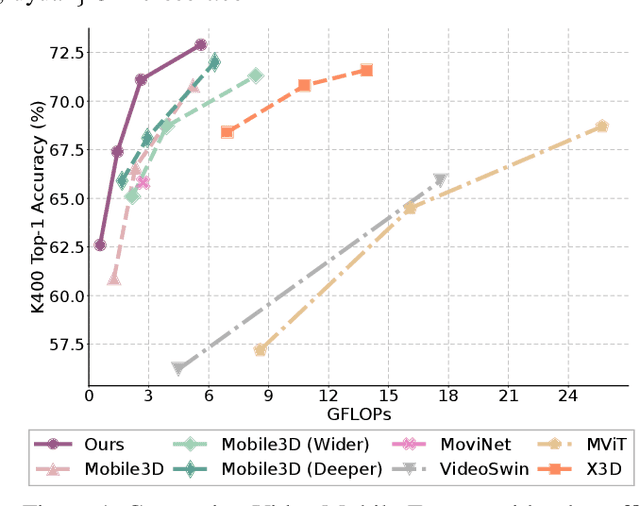
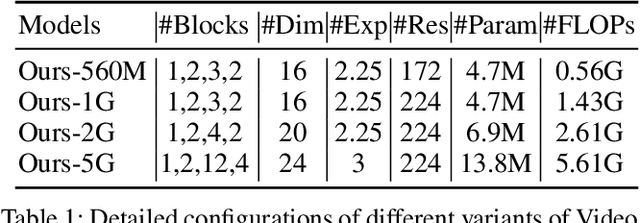
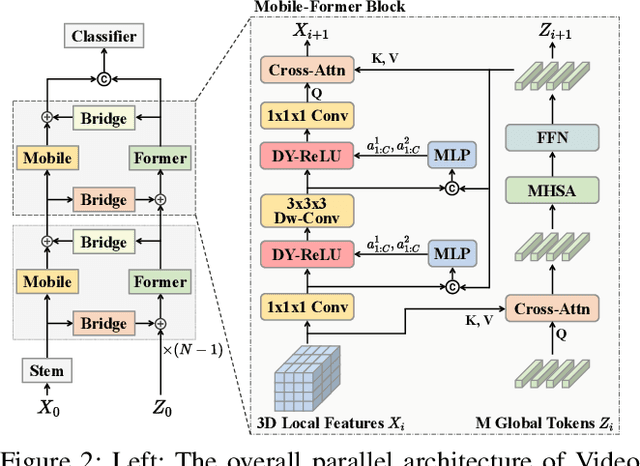
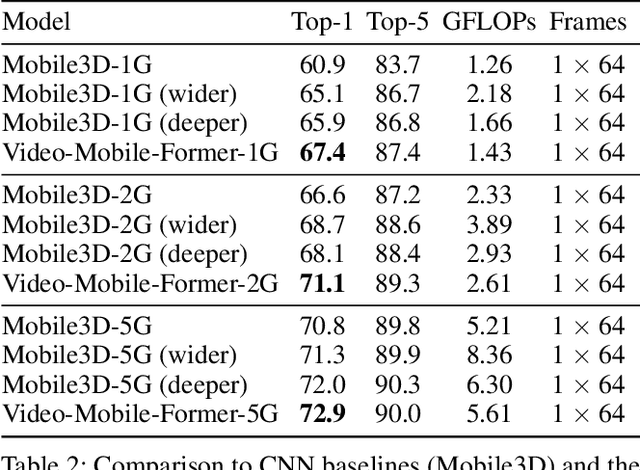
Transformer-based models have achieved top performance on major video recognition benchmarks. Benefiting from the self-attention mechanism, these models show stronger ability of modeling long-range dependencies compared to CNN-based models. However, significant computation overheads, resulted from the quadratic complexity of self-attention on top of a tremendous number of tokens, limit the use of existing video transformers in applications with limited resources like mobile devices. In this paper, we extend Mobile-Former to Video Mobile-Former, which decouples the video architecture into a lightweight 3D-CNNs for local context modeling and a Transformer modules for global interaction modeling in a parallel fashion. To avoid significant computational cost incurred by computing self-attention between the large number of local patches in videos, we propose to use very few global tokens (e.g., 6) for a whole video in Transformers to exchange information with 3D-CNNs with a cross-attention mechanism. Through efficient global spatial-temporal modeling, Video Mobile-Former significantly improves the video recognition performance of alternative lightweight baselines, and outperforms other efficient CNN-based models at the low FLOP regime from 500M to 6G total FLOPs on various video recognition tasks. It is worth noting that Video Mobile-Former is the first Transformer-based video model which constrains the computational budget within 1G FLOPs.
A Gis Aided Approach for Geolocalizing an Unmanned Aerial System Using Deep Learning
Aug 25, 2022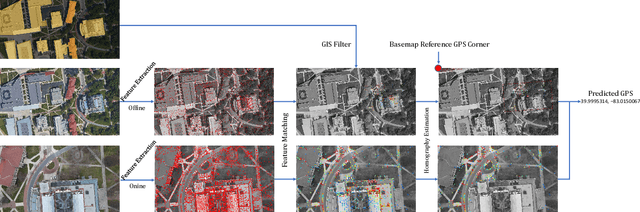
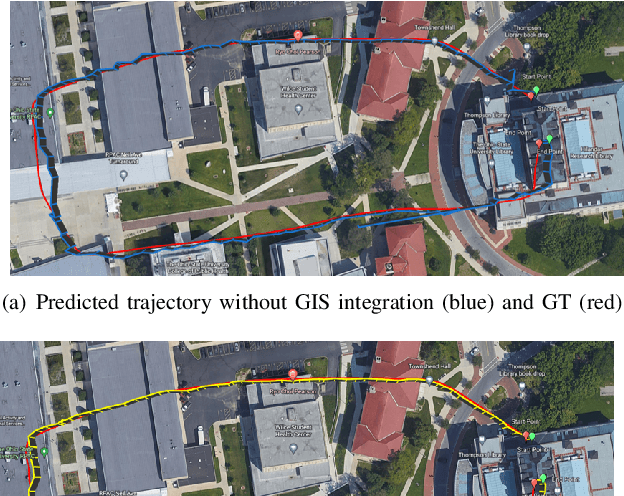
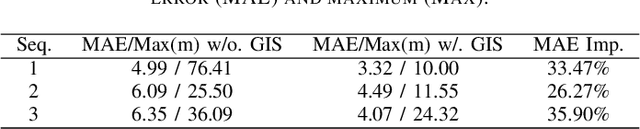
The Global Positioning System (GPS) has become a part of our daily life with the primary goal of providing geopositioning service. For an unmanned aerial system (UAS), geolocalization ability is an extremely important necessity which is achieved using Inertial Navigation System (INS) with the GPS at its heart. Without geopositioning service, UAS is unable to fly to its destination or come back home. Unfortunately, GPS signals can be jammed and suffer from a multipath problem in urban canyons. Our goal is to propose an alternative approach to geolocalize a UAS when GPS signal is degraded or denied. Considering UAS has a downward-looking camera on its platform that can acquire real-time images as the platform flies, we apply modern deep learning techniques to achieve geolocalization. In particular, we perform image matching to establish latent feature conjugates between UAS acquired imagery and satellite orthophotos. A typical application of feature matching suffers from high-rise buildings and new constructions in the field that introduce uncertainties into homography estimation, hence results in poor geolocalization performance. Instead, we extract GIS information from OpenStreetMap (OSM) to semantically segment matched features into building and terrain classes. The GIS mask works as a filter in selecting semantically matched features that enhance coplanarity conditions and the UAS geolocalization accuracy. Once the paper is published our code will be publicly available at https://github.com/OSUPCVLab/UbihereDrone2021.
Information Bottleneck: Exact Analysis of (Quantized) Neural Networks
Jun 24, 2021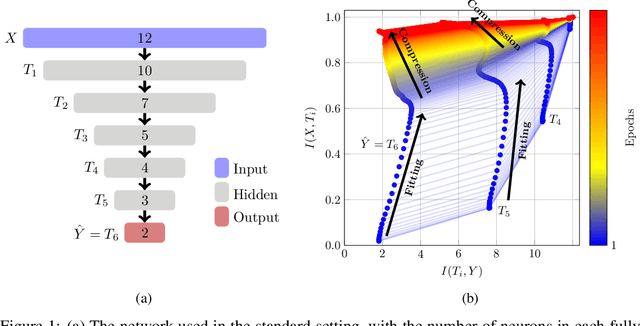
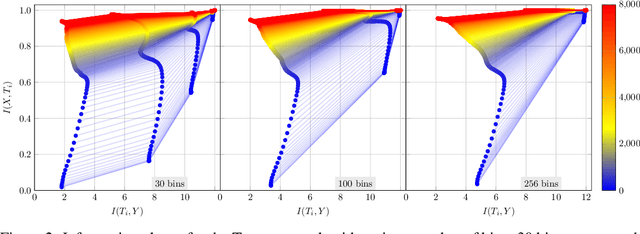
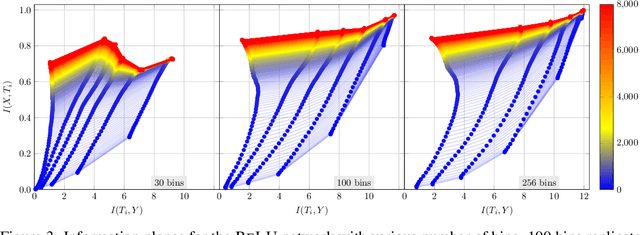
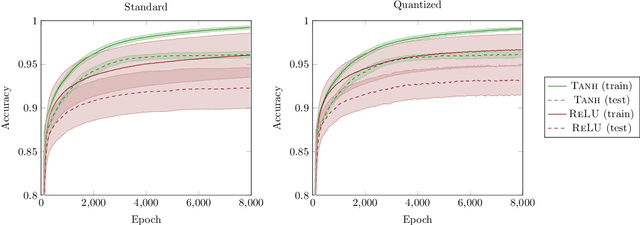
The information bottleneck (IB) principle has been suggested as a way to analyze deep neural networks. The learning dynamics are studied by inspecting the mutual information (MI) between the hidden layers and the input and output. Notably, separate fitting and compression phases during training have been reported. This led to some controversy including claims that the observations are not reproducible and strongly dependent on the type of activation function used as well as on the way the MI is estimated. Our study confirms that different ways of binning when computing the MI lead to qualitatively different results, either supporting or refusing IB conjectures. To resolve the controversy, we study the IB principle in settings where MI is non-trivial and can be computed exactly. We monitor the dynamics of quantized neural networks, that is, we discretize the whole deep learning system so that no approximation is required when computing the MI. This allows us to quantify the information flow without measurement errors. In this setting, we observed a fitting phase for all layers and a compression phase for the output layer in all experiments; the compression in the hidden layers was dependent on the type of activation function. Our study shows that the initial IB results were not artifacts of binning when computing the MI. However, the critical claim that the compression phase may not be observed for some networks also holds true.