 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GRIT: Faster and Better Image captioning Transformer Using Dual Visual Features
Jul 20, 2022


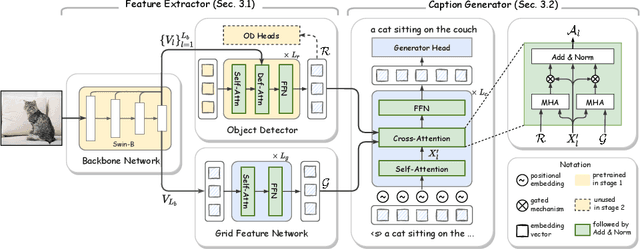

Current state-of-the-art methods for image captioning employ region-based features, as they provide object-level information that is essential to describe the content of images; they are usually extracted by an object detector such as Faster R-CNN. However, they have several issues, such as lack of contextual information, the risk of inaccurate detection, and the high computational cost. The first two could be resolved by additionally using grid-based features. However, how to extract and fuse these two types of features is uncharted. This paper proposes a Transformer-only neural architecture, dubbed GRIT (Grid- and Region-based Image captioning Transformer), that effectively utilizes the two visual features to generate better captions. GRIT replaces the CNN-based detector employed in previous methods with a DETR-based one, making it computationally faster. Moreover, its monolithic design consisting only of Transformers enables end-to-end training of the model. This innovative design and the integration of the dual visual features bring about significant performance improvement. The experimental results on several image captioning benchmarks show that GRIT outperforms previous methods in inference accuracy and speed.
Efficient spike encoding algorithms for neuromorphic speech recognition
Jul 14, 2022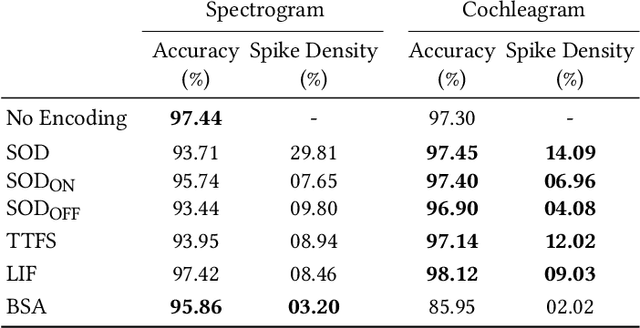
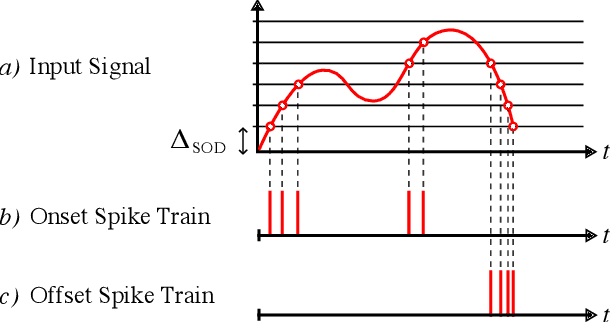

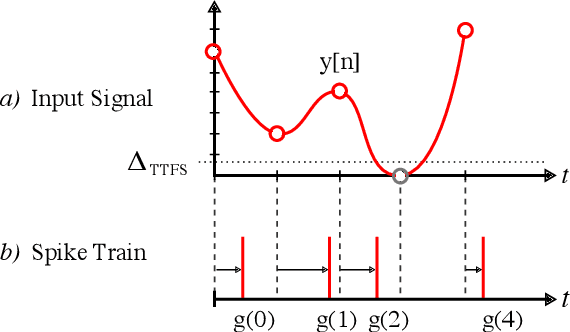
Spiking Neural Networks (SNN) are known to be very effective for neuromorphic processor implementations, achieving orders of magnitude improvements in energy efficiency and computational latency over traditional deep learning approaches. Comparable algorithmic performance was recently made possible as well with the adaptation of supervised training algorithms to the context of SNN. However, information including audio, video, and other sensor-derived data are typically encoded as real-valued signals that are not well-suited to SNN, preventing the network from leveraging spike timing information. Efficient encoding from real-valued signals to spikes is therefore critical and significantly impacts the performance of the overall system. To efficiently encode signals into spikes, both the preservation of information relevant to the task at hand as well as the density of the encoded spikes must be considered. In this paper, we study four spike encoding methods in the context of a speaker independent digit classification system: Send on Delta, Time to First Spike, Leaky Integrate and Fire Neuron and Bens Spiker Algorithm. We first show that all encoding methods yield higher classification accuracy using significantly fewer spikes when encoding a bio-inspired cochleagram as opposed to a traditional short-time Fourier transform. We then show that two Send On Delta variants result in classification results comparable with a state of the art deep convolutional neural network baseline, while simultaneously reducing the encoded bit rate. Finally, we show that several encoding methods result in improved performance over the conventional deep learning baseline in certain cases, further demonstrating the power of spike encoding algorithms in the encoding of real-valued signals and that neuromorphic implementation has the potential to outperform state of the art techniques.
PIC 4th Challenge: Semantic-Assisted Multi-Feature Encoding and Multi-Head Decoding for Dense Video Captioning
Jul 06, 2022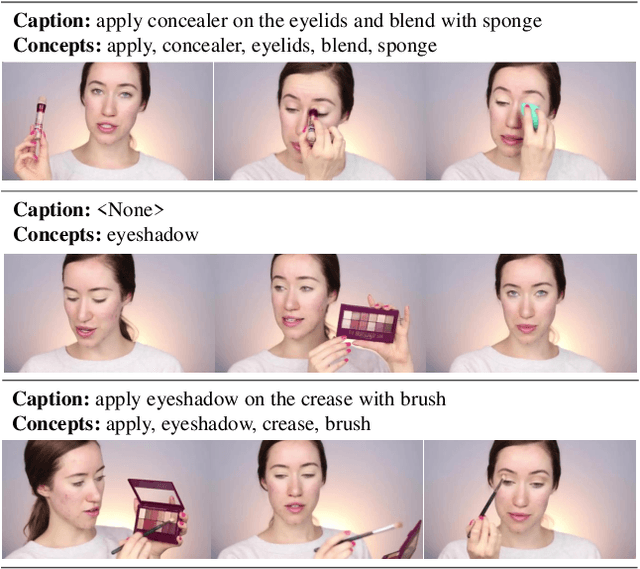
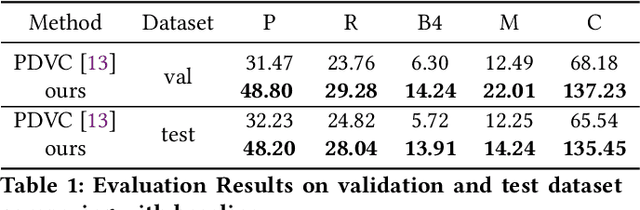
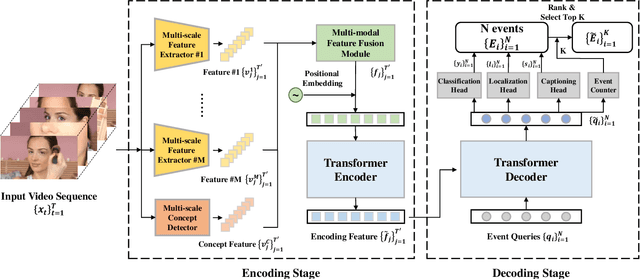
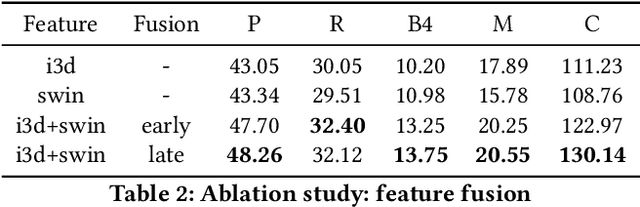
The task of Dense Video Captioning (DVC) aims to generate captions with timestamps for multiple events in one video. Semantic information plays an important role for both localization and description of DVC. We present a semantic-assisted dense video captioning model based on the encoding-decoding framework. In the encoding stage, we design a concept detector to extract semantic information, which is then fused with multi-modal visual features to sufficiently represent the input video. In the decoding stage, we design a classification head, paralleled with the localization and captioning heads, to provide semantic supervision. Our method achieves significant improvements on the YouMakeup dataset under DVC evaluation metrics and achieves high performance in the Makeup Dense Video Captioning (MDVC) task of PIC 4th Challenge.
SAL-CNN: Estimate the Remaining Useful Life of Bearings Using Time-frequency Information
Apr 11, 2022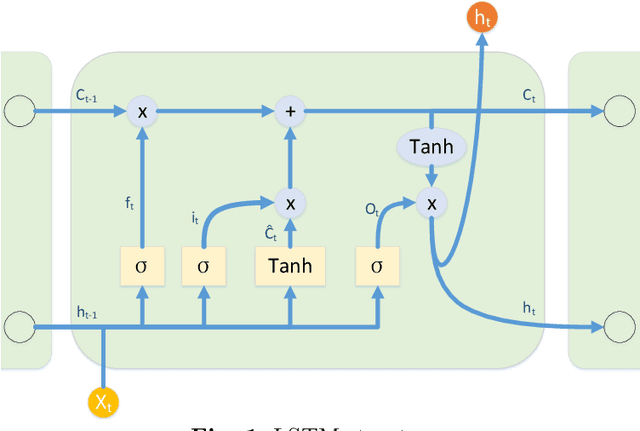
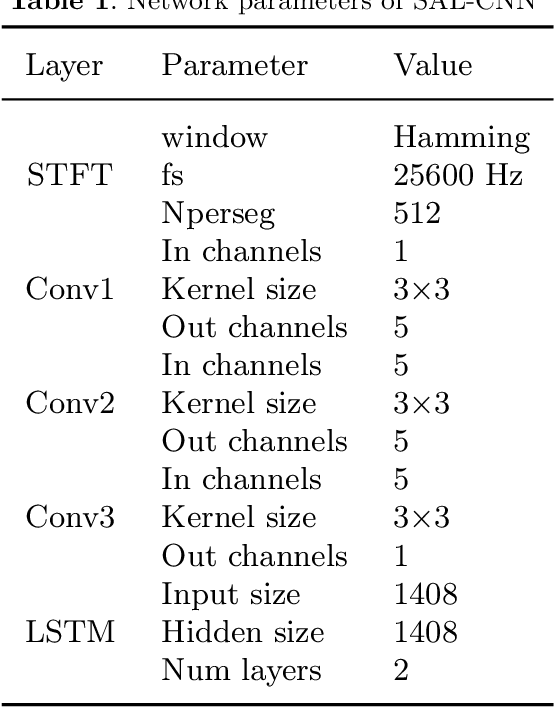
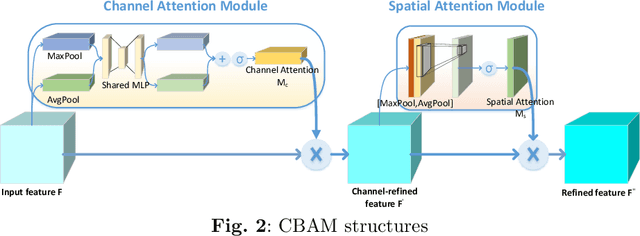

In modern industrial production, the prediction ability of the remaining useful life (RUL) of bearings directly affects the safety and stability of the system. Traditional methods require rigorous physical modeling and perform poorly for complex systems. In this paper, an end-to-end RUL prediction method is proposed, which uses short-time Fourier transform (STFT) as preprocessing. Considering the time correlation of signal sequences, a long and short-term memory network is designed in CNN, incorporating the convolutional block attention module, and understanding the decision-making process of the network from the interpretability level. Experiments were carried out on the 2012PHM dataset and compared with other methods, and the results proved the effectiveness of the method.
Contact-Free Multi-Target Tracking Using Distributed Massive MIMO-OFDM Communication System: Prototype and Analysis
Aug 26, 2022



Wireless-based human activity recognition has become an essential technology that enables contact-free human-machine and human-environment interactions. In this paper, we consider contact-free multi-target tracking (MTT) based on available communication systems. A radar-like prototype is built upon a sub-6 GHz distributed massive multiple-input and multiple-output (MIMO) orthogonal frequency-division multiplexing communication system. Specifically, the raw channel state information (CSI) is calibrated in the frequency and antenna domain before being used for tracking. Then the targeted CSIs reflected or scattered from the moving pedestrians are extracted. To evade the complex association problem of distributed massive MIMO-based MTT, we propose to use a complex Bayesian compressive sensing (CBCS) algorithm to estimate the targets' locations based on the extracted target-of-interest CSI signal directly. The estimated locations from CBCS are fed to a Gaussian mixture probability hypothesis density filter for tracking. A multi-pedestrian tracking experiment is conducted in a room with size of 6.5 m$\times$10 m to evaluate the performance of the proposed algorithm. According to experimental results, we achieve 75th and 95th percentile accuracy of 12.7 cm and 18.2 cm for single-person tracking and 28.9 cm and 45.7 cm for multi-person tracking, respectively. Furthermore, the proposed algorithm achieves the tracking purposes in real-time, which is promising for practical MTT use cases.
Using Chatbots to Teach Languages
Jul 31, 2022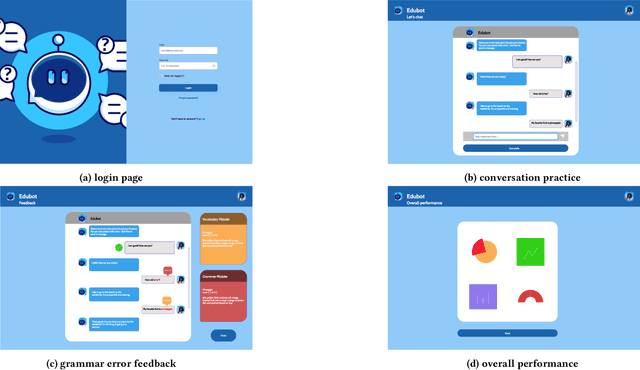

This paper reports on progress towards building an online language learning tool to provide learners with conversational experience by using dialog systems as conversation practice partners. Our system can adapt to users' language proficiency on the fly. We also provide automatic grammar error feedback to help users learn from their mistakes. According to our first adopters, our system is entertaining and useful. Furthermore, we will provide the learning technology community a large-scale conversation dataset on language learning and grammar correction. Our next step is to make our system more adaptive to user profile information by using reinforcement learning algorithms.
Dense Teacher: Dense Pseudo-Labels for Semi-supervised Object Detection
Jul 06, 2022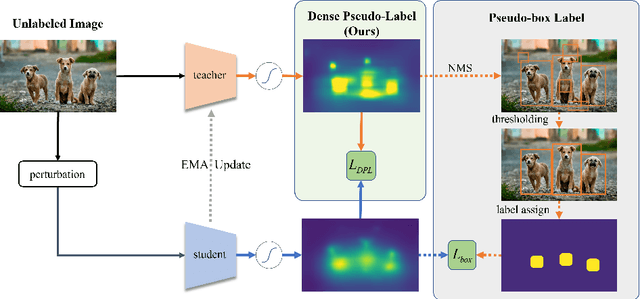
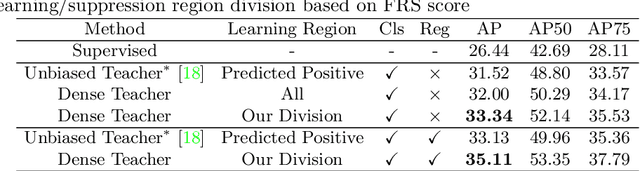
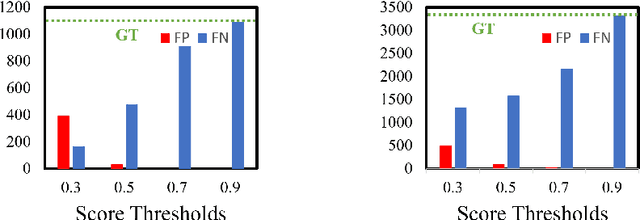
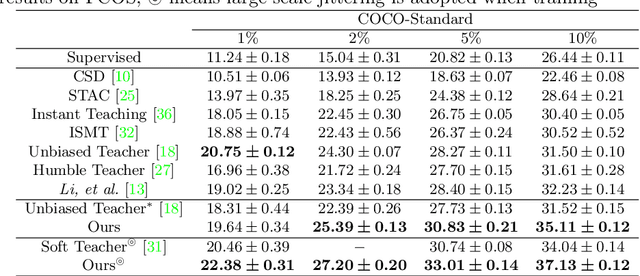
To date, the most powerful semi-supervised object detectors (SS-OD) are based on pseudo-boxes, which need a sequence of post-processing with fine-tuned hyper-parameters. In this work, we propose replacing the sparse pseudo-boxes with the dense prediction as a united and straightforward form of pseudo-label. Compared to the pseudo-boxes, our Dense Pseudo-Label (DPL) does not involve any post-processing method, thus retaining richer information. We also introduce a region selection technique to highlight the key information while suppressing the noise carried by dense labels. We name our proposed SS-OD algorithm that leverages the DPL as Dense Teacher. On COCO and VOC, Dense Teacher shows superior performance under various settings compared with the pseudo-box-based methods.
Exploiting Domain Transferability for Collaborative Inter-level Domain Adaptive Object Detection
Jul 20, 2022
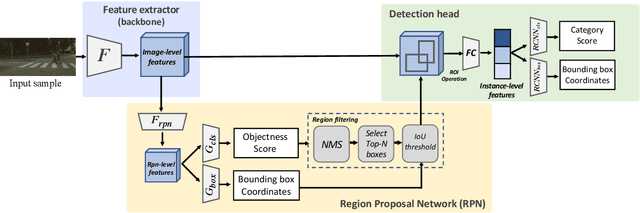
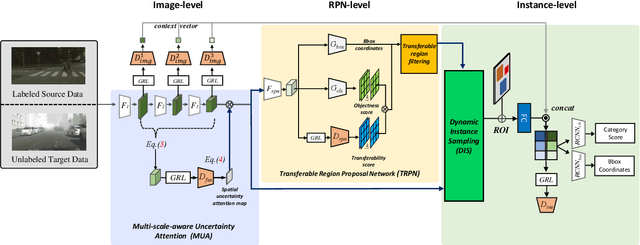
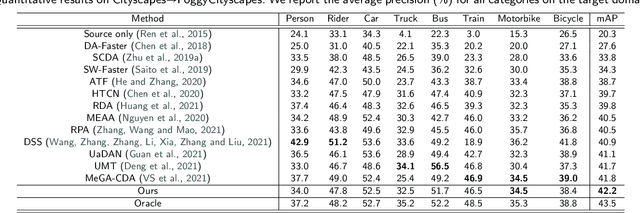
Domain adaptation for object detection (DAOD) has recently drawn much attention owing to its capability of detecting target objects without any annotations. To tackle the problem, previous works focus on aligning features extracted from partial levels (e.g., image-level, instance-level, RPN-level) in a two-stage detector via adversarial training. However, individual levels in the object detection pipeline are closely related to each other and this inter-level relation is unconsidered yet. To this end, we introduce a novel framework for DAOD with three proposed components: Multi-scale-aware Uncertainty Attention (MUA), Transferable Region Proposal Network (TRPN), and Dynamic Instance Sampling (DIS). With these modules, we seek to reduce the negative transfer effect during training while maximizing transferability as well as discriminability in both domains. Finally, our framework implicitly learns domain invariant regions for object detection via exploiting the transferable information and enhances the complementarity between different detection levels by collaboratively utilizing their domain information. Through ablation studies and experiments, we show that the proposed modules contribute to the performance improvement in a synergic way, demonstrating the effectiveness of our method. Moreover, our model achieves a new state-of-the-art performance on various benchmarks.
* Accepted to Expert Systems with Applications. The first three authors contributed equally
Semantic Interleaving Global Channel Attention for Multilabel Remote Sensing Image Classification
Aug 04, 2022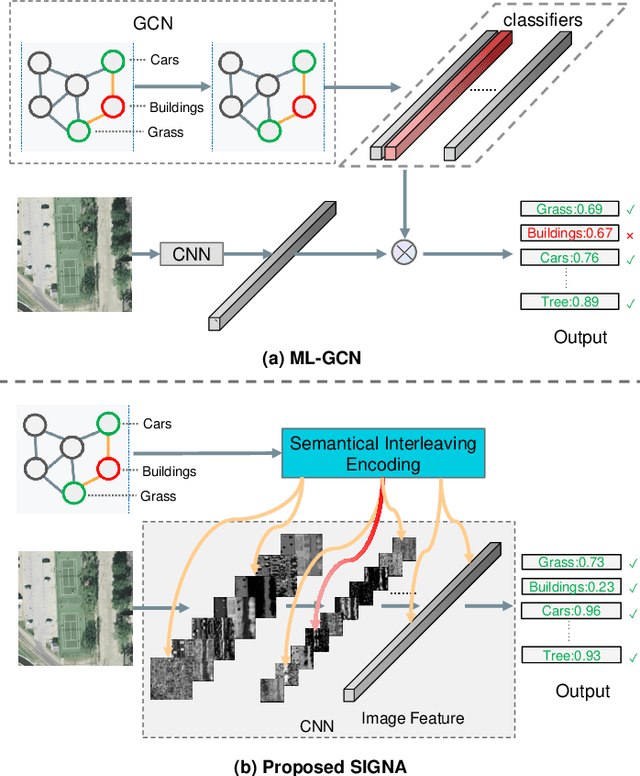
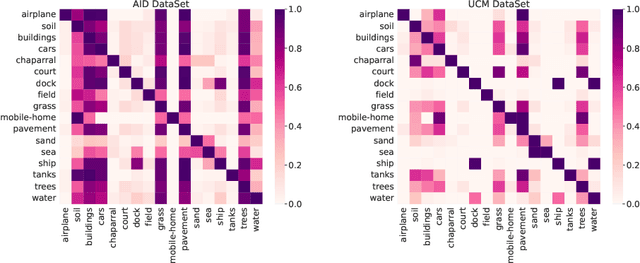
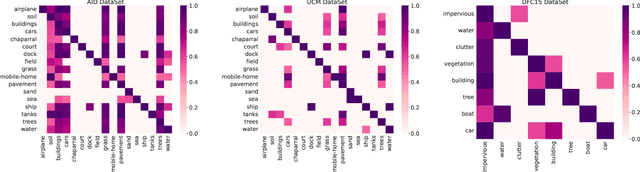
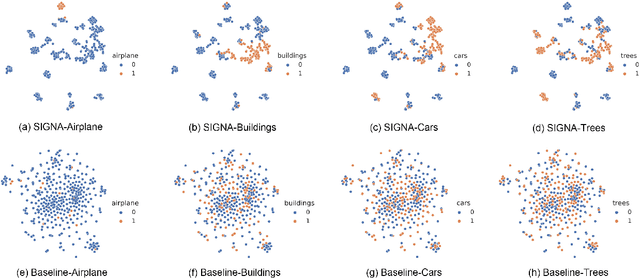
Multi-Label Remote Sensing Image Classification (MLRSIC) has received increasing research interest. Taking the cooccurrence relationship of multiple labels as additional information helps to improve the performance of this task. Current methods focus on using it to constrain the final feature output of a Convolutional Neural Network (CNN). On the one hand, these methods do not make full use of label correlation to form feature representation. On the other hand, they increase the label noise sensitivity of the system, resulting in poor robustness. In this paper, a novel method called Semantic Interleaving Global Channel Attention (SIGNA) is proposed for MLRSIC. First, the label co-occurrence graph is obtained according to the statistical information of the data set. The label co-occurrence graph is used as the input of the Graph Neural Network (GNN) to generate optimal feature representations. Then, the semantic features and visual features are interleaved, to guide the feature expression of the image from the original feature space to the semantic feature space with embedded label relations. SIGNA triggers global attention of feature maps channels in a new semantic feature space to extract more important visual features. Multihead SIGNA based feature adaptive weighting networks are proposed to act on any layer of CNN in a plug-and-play manner. For remote sensing images, better classification performance can be achieved by inserting CNN into the shallow layer. We conduct extensive experimental comparisons on three data sets: UCM data set, AID data set, and DFC15 data set. Experimental results demonstrate that the proposed SIGNA achieves superior classification performance compared to state-of-the-art (SOTA) methods. It is worth mentioning that the codes of this paper will be open to the community for reproducibility research. Our codes are available at https://github.com/kyle-one/SIGNA.
On the evolution of research in hypersonics: application of natural language processing and machine learning
Aug 17, 2022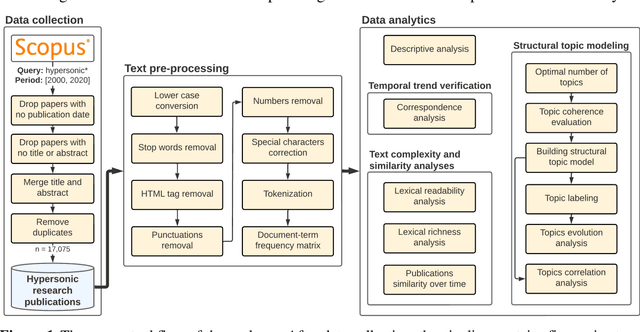
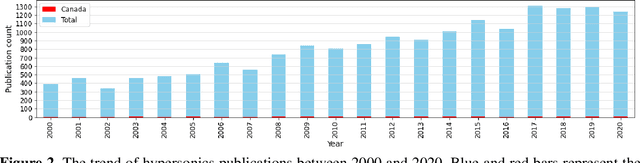
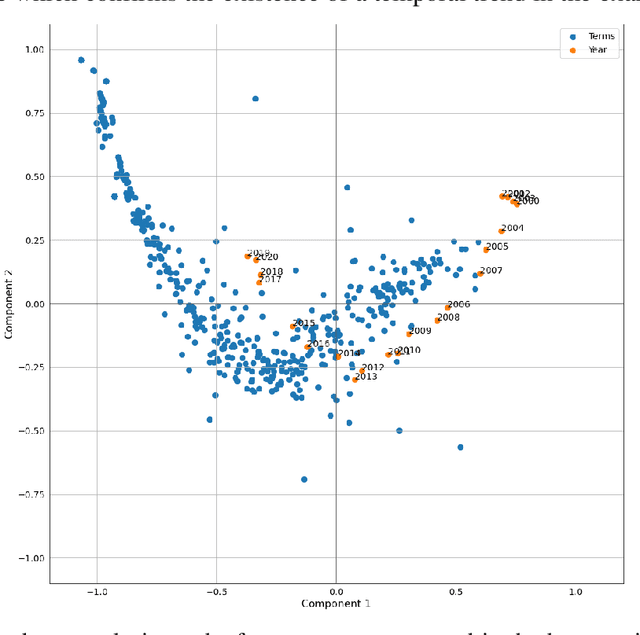
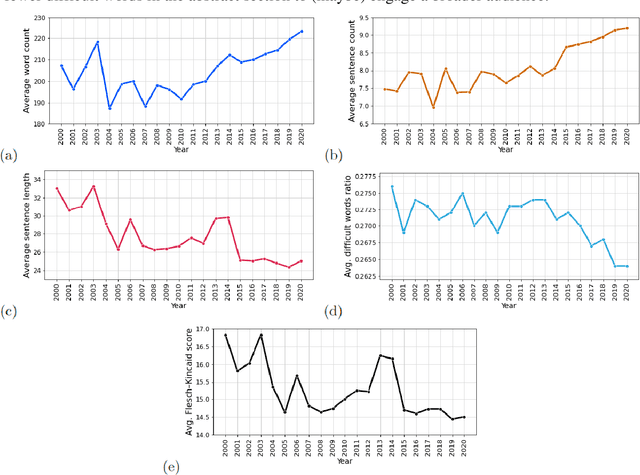
Research and development in hypersonics have progressed significantly in recent years, with various military and commercial applications being demonstrated increasingly. Public and private organizations in several countries have been investing in hypersonics, with the aim to overtake their competitors and secure/improve strategic advantage and deterrence. For these organizations, being able to identify emerging technologies in a timely and reliable manner is paramount. Recent advances in information technology have made it possible to analyze large amounts of data, extract hidden patterns, and provide decision-makers with new insights. In this study, we focus on scientific publications about hypersonics within the period of 2000-2020, and employ natural language processing and machine learning to characterize the research landscape by identifying 12 key latent research themes and analyzing their temporal evolution. Our publication similarity analysis revealed patterns that are indicative of cycles during two decades of research. The study offers a comprehensive analysis of the research field and the fact that the research themes are algorithmically extracted removes subjectivity from the exercise and enables consistent comparisons between topics and between time intervals.