 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Extending GCC-PHAT using Shift Equivariant Neural Networks
Aug 09, 2022
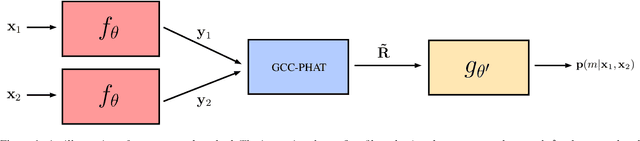
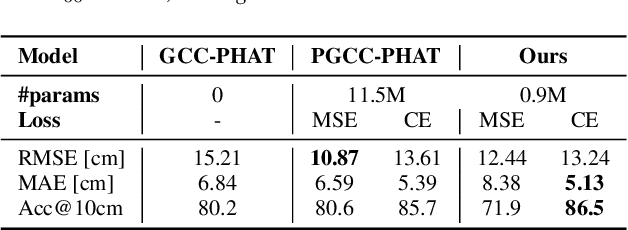
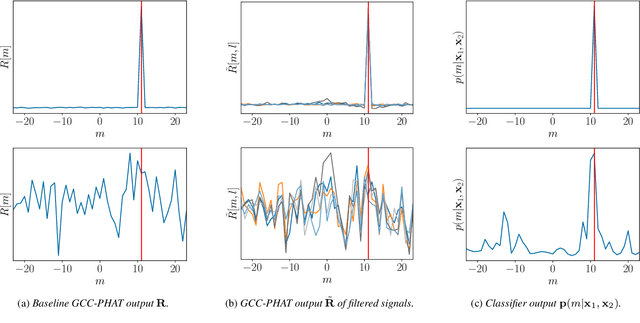

Speaker localization using microphone arrays depends on accurate time delay estimation techniques. For decades, methods based on the generalized cross correlation with phase transform (GCC-PHAT) have been widely adopted for this purpose. Recently, the GCC-PHAT has also been used to provide input features to neural networks in order to remove the effects of noise and reverberation, but at the cost of losing theoretical guarantees in noise-free conditions. We propose a novel approach to extending the GCC-PHAT, where the received signals are filtered using a shift equivariant neural network that preserves the timing information contained in the signals. By extensive experiments we show that our model consistently reduces the error of the GCC-PHAT in adverse environments, with guarantees of exact time delay recovery in ideal conditions.
Quantum compression with classically simulatable circuits
Jul 06, 2022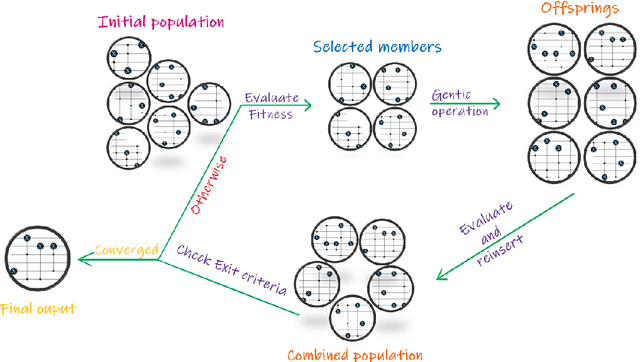
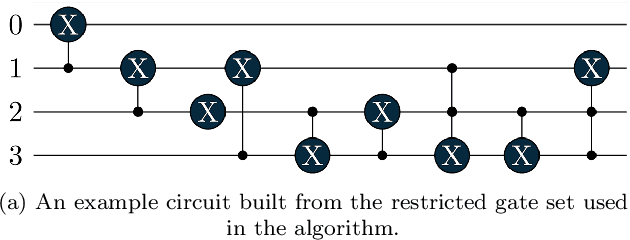
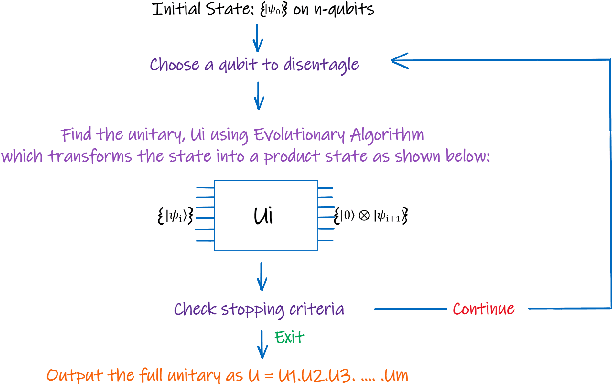
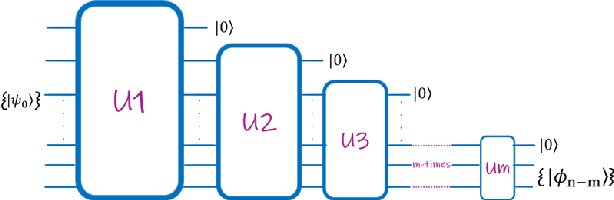
As we continue to find applications where the currently available noisy devices exhibit an advantage over their classical counterparts, the efficient use of quantum resources is highly desirable. The notion of quantum autoencoders was proposed as a way for the compression of quantum information to reduce resource requirements. Here, we present a strategy to design quantum autoencoders using evolutionary algorithms for transforming quantum information into lower-dimensional representations. We successfully demonstrate the initial applications of the algorithm for compressing different families of quantum states. In particular, we point out that using a restricted gate set in the algorithm allows for efficient simulation of the generated circuits. This approach opens the possibility of using classical logic to find low representations of quantum data, using fewer computational resources.
Image denoising in acoustic field microscopy
Aug 07, 2022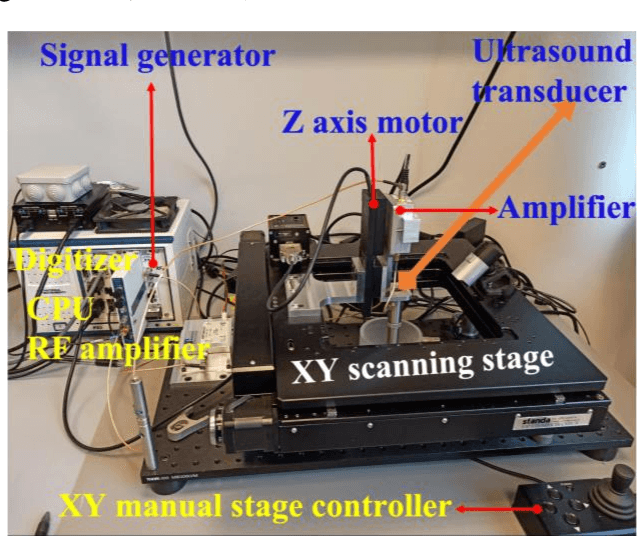
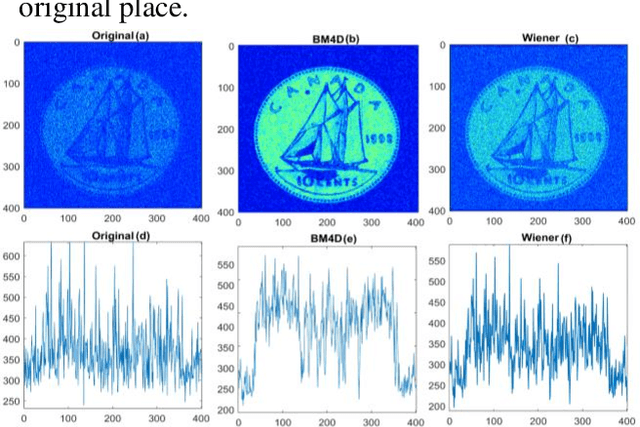
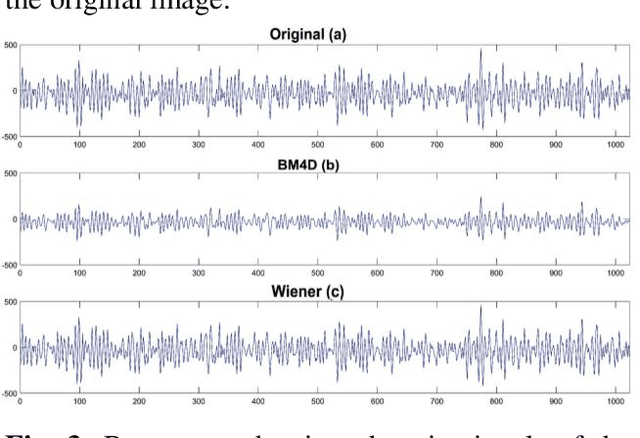
Scanning acoustic microscopy (SAM) has been employed since microscopic images are widely used for biomedical or materials research. Acoustic imaging is an important and well-established method used in nondestructive testing (NDT), bio-medical imaging, and structural health monitoring.The imaging is frequently carried out with signals of low amplitude, which might result in leading that are noisy and lacking in details of image information. In this work, we attempted to analyze SAM images acquired from low amplitude signals and employed a block matching filter over time domain signals to obtain a denoised image. We have compared the images with conventional filters applied over time domain signals, such as the gaussian filter, median filter, wiener filter, and total variation filter. The noted outcomes are shown in this article.
DPIT: Dual-Pipeline Integrated Transformer for Human Pose Estimation
Sep 02, 2022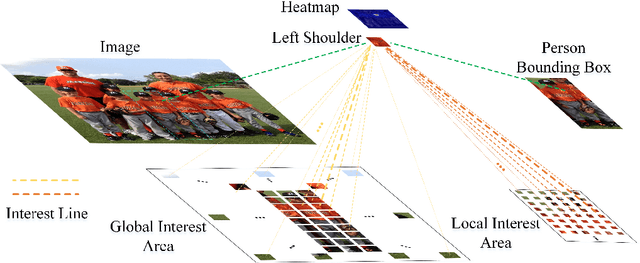
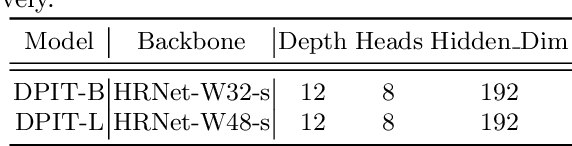
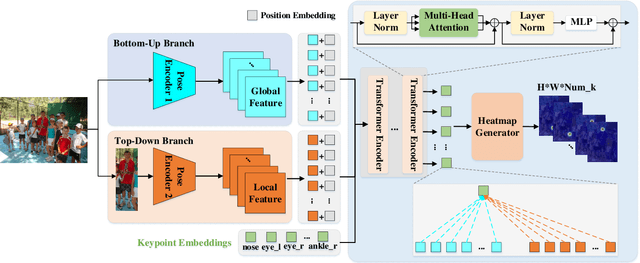
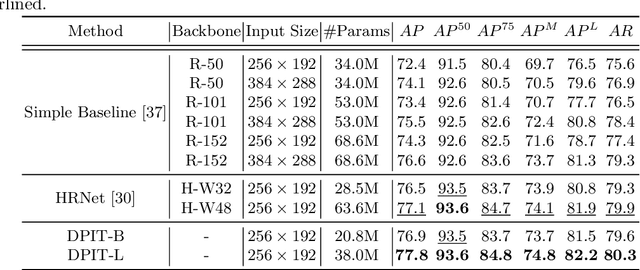
Human pose estimation aims to figure out the keypoints of all people in different scenes. Current approaches still face some challenges despite promising results. Existing top-down methods deal with a single person individually, without the interaction between different people and the scene they are situated in. Consequently, the performance of human detection degrades when serious occlusion happens. On the other hand, existing bottom-up methods consider all people at the same time and capture the global knowledge of the entire image. However, they are less accurate than the top-down methods due to the scale variation. To address these problems, we propose a novel Dual-Pipeline Integrated Transformer (DPIT) by integrating top-down and bottom-up pipelines to explore the visual clues of different receptive fields and achieve their complementarity. Specifically, DPIT consists of two branches, the bottom-up branch deals with the whole image to capture the global visual information, while the top-down branch extracts the feature representation of local vision from the single-human bounding box. Then, the extracted feature representations from bottom-up and top-down branches are fed into the transformer encoder to fuse the global and local knowledge interactively. Moreover, we define the keypoint queries to explore both full-scene and single-human posture visual clues to realize the mutual complementarity of the two pipelines. To the best of our knowledge, this is one of the first works to integrate the bottom-up and top-down pipelines with transformers for human pose estimation. Extensive experiments on COCO and MPII datasets demonstrate that our DPIT achieves comparable performance to the state-of-the-art methods.
Differential evolution variants for Searching D- and A-optimal designs
Aug 24, 2022
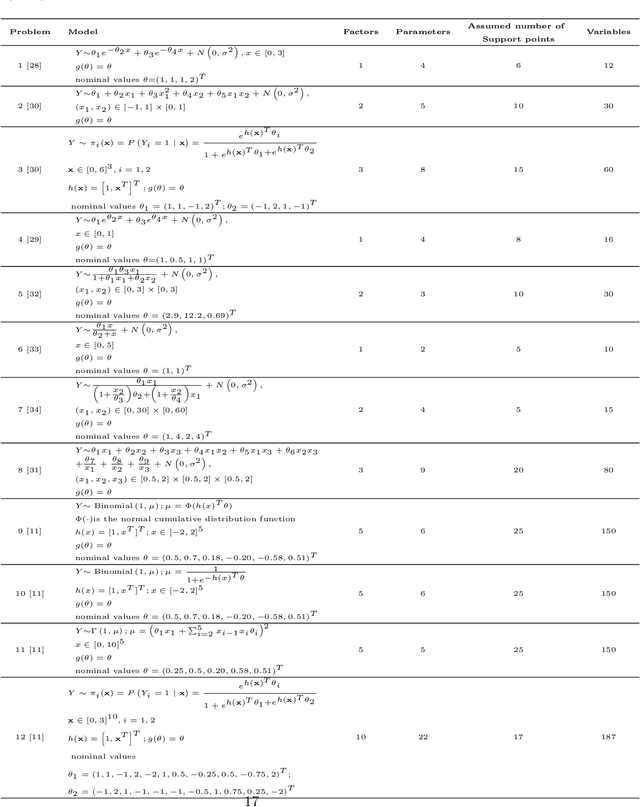
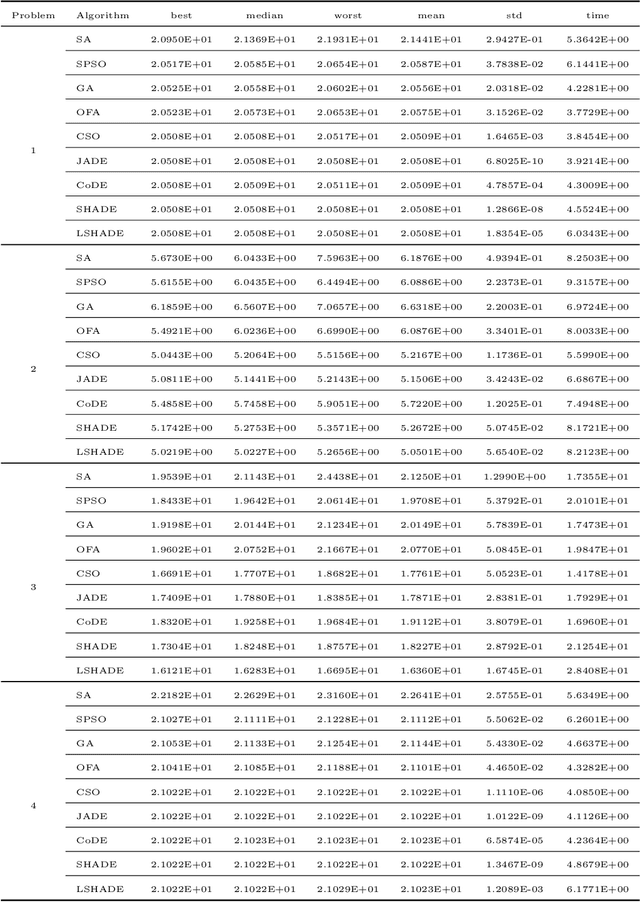
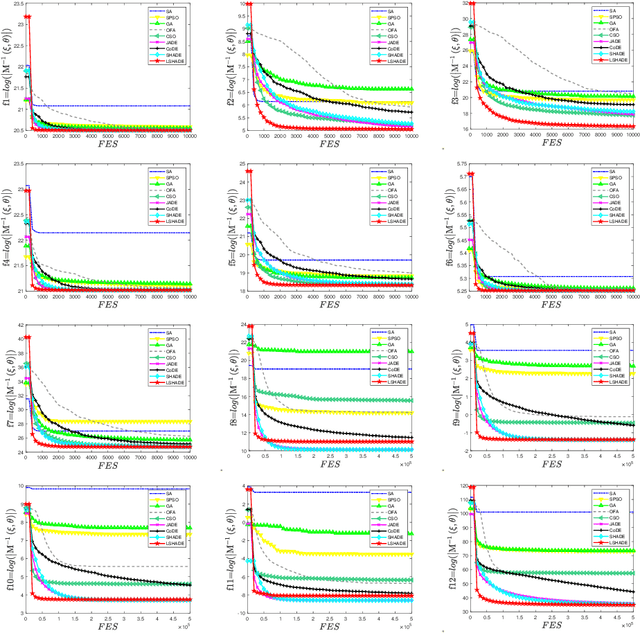
Optimal experimental design is an essential subfield of statistics that maximizes the chances of experimental success. The D- and A-optimal design is a very challenging problem in the field of optimal design, namely minimizing the determinant and trace of the inverse Fisher information matrix. Due to the flexibility and ease of implementation, traditional evolutionary algorithms (EAs) are applied to deal with a small part of experimental optimization design problems without mathematical derivation and assumption. However, the current EAs remain the issues of determining the support point number, handling the infeasible weight solution, and the insufficient experiment. To address the above issues, this paper investigates differential evolution (DE) variants for finding D- and A-optimal designs on several different statistical models. The repair operation is proposed to automatically determine the support point by combining similar support points with their corresponding weights based on Euclidean distance and deleting the support point with less weight. Furthermore, the repair operation fixes the infeasible weight solution into the feasible weight solution. To enrich our optimal design experiments, we utilize the proposed DE variants to test the D- and A-optimal design problems on 12 statistical models. Compared with other competitor algorithms, simulation experiments show that LSHADE can achieve better performance on the D- and A-optimal design problems.
Adaptive Asymmetric Label-guided Hashing for Multimedia Search
Jul 26, 2022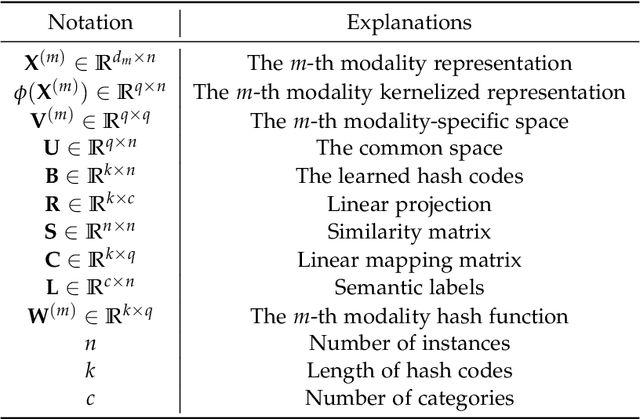
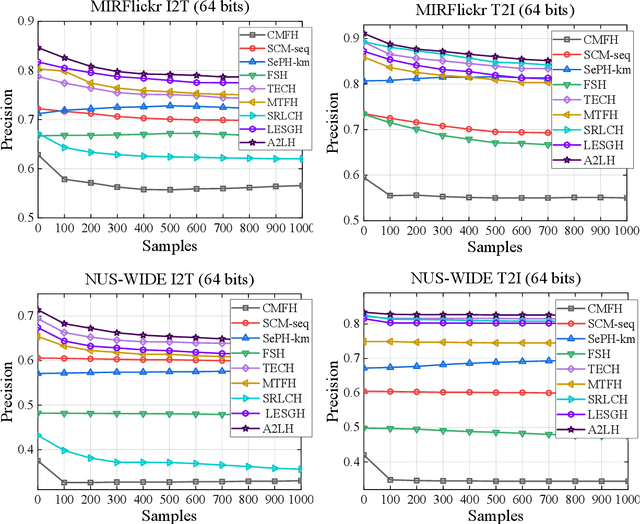
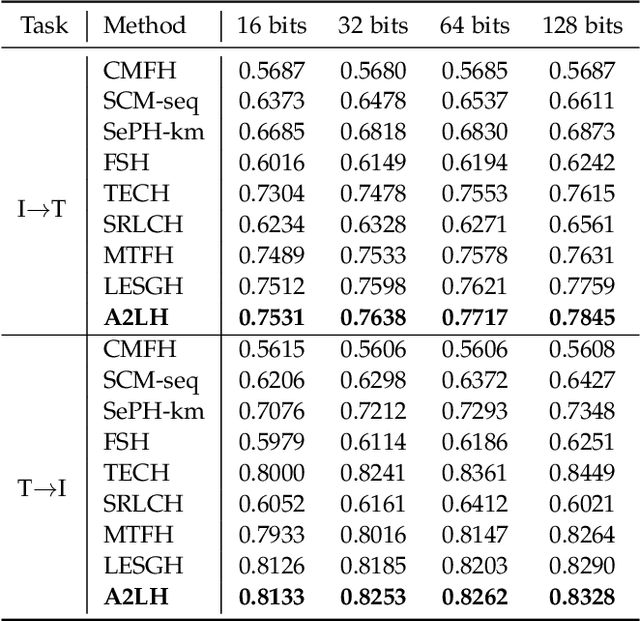
With the rapid growth of multimodal media data on the Web in recent years, hash learning methods as a way to achieve efficient and flexible cross-modal retrieval of massive multimedia data have received a lot of attention from the current Web resource retrieval research community. Existing supervised hashing methods simply transform label information into pairwise similarity information to guide hash learning, leading to a potential risk of semantic error in the face of multi-label data. In addition, most existing hash optimization methods solve NP-hard optimization problems by employing approximate approximation strategies based on relaxation strategies, leading to a large quantization error. In order to address above obstacles, we present a simple yet efficient Adaptive Asymmetric Label-guided Hashing, named A2LH, for Multimedia Search. Specifically, A2LH is a two-step hashing method. In the first step, we design an association representation model between the different modality representations and semantic label representation separately, and use the semantic label representation as an intermediate bridge to solve the semantic gap existing between different modalities. In addition, we present an efficient discrete optimization algorithm for solving the quantization error problem caused by relaxation-based optimization algorithms. In the second step, we leverage the generated hash codes to learn the hash mapping functions. The experimental results show that our proposed method achieves optimal performance on all compared baseline methods.
Disentangle and Remerge: Interventional Knowledge Distillation for Few-Shot Object Detection from A Conditional Causal Perspective
Aug 26, 2022
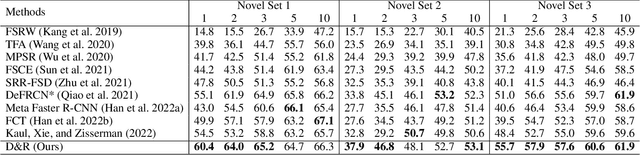
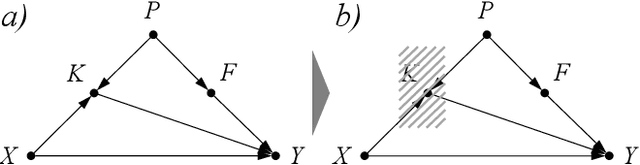
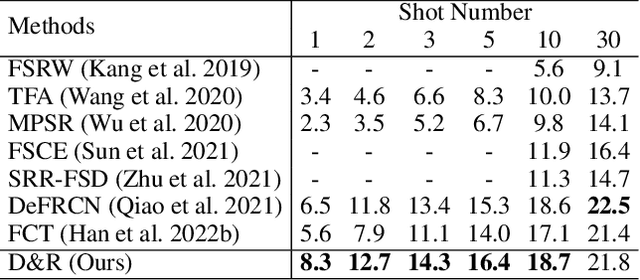
Few-shot learning models learn representations with limited human annotations, and such a learning paradigm demonstrates practicability in various tasks, e.g., image classification, object detection, etc. However, few-shot object detection methods suffer from an intrinsic defect that the limited training data makes the model cannot sufficiently explore semantic information. To tackle this, we introduce knowledge distillation to the few-shot object detection learning paradigm. We further run a motivating experiment, which demonstrates that in the process of knowledge distillation the empirical error of the teacher model degenerates the prediction performance of the few-shot object detection model, as the student. To understand the reasons behind this phenomenon, we revisit the learning paradigm of knowledge distillation on the few-shot object detection task from the causal theoretic standpoint, and accordingly, develop a Structural Causal Model. Following the theoretical guidance, we propose a backdoor adjustment-based knowledge distillation method for the few-shot object detection task, namely Disentangle and Remerge (D&R), to perform conditional causal intervention toward the corresponding Structural Causal Model. Theoretically, we provide an extended definition, i.e., general backdoor path, for the backdoor criterion, which can expand the theoretical application boundary of the backdoor criterion in specific cases. Empirically, the experiments on multiple benchmark datasets demonstrate that D&R can yield significant performance boosts in few-shot object detection.
Reinforcement Learning based Multi-connectivity Resource Allocation in Factory Automation Systems
Aug 26, 2022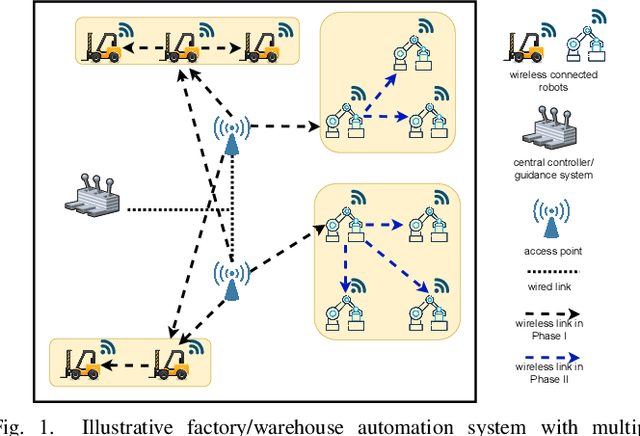
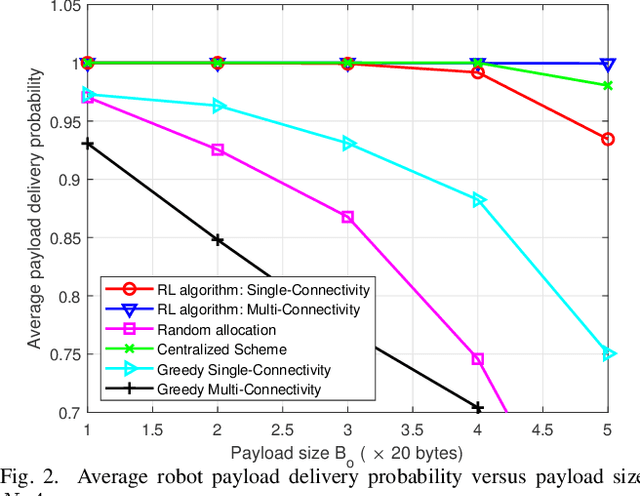
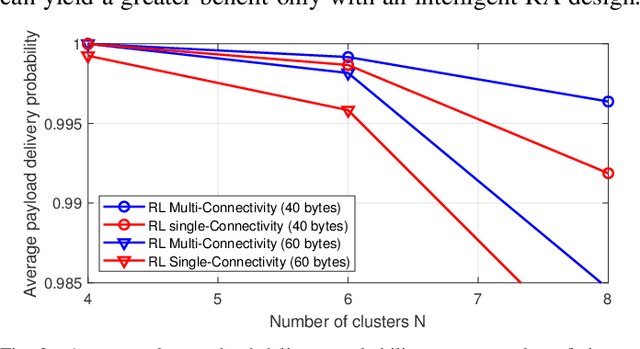
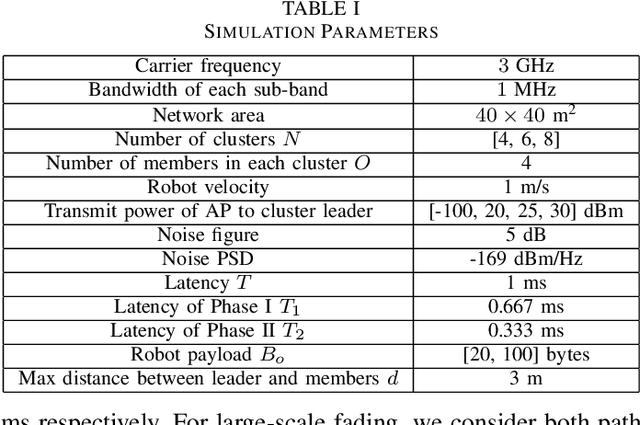
We propose joint user association, channel assignment and power allocation for mobile robot Ultra-Reliable and Low Latency Communications (URLLC) based on multi-connectivity and reinforcement learning. The mobile robots require control messages from the central guidance system at regular intervals. We use a two-phase communication scheme where robots can form multiple clusters. The robots in a cluster are close to each other and can have reliable Device-to-Device (D2D) communications. In Phase I, the APs transmit the combined payload of a cluster to the cluster leader within a latency constraint. The cluster leader broadcasts this message to its members in Phase II. We develop a distributed Multi-Agent Reinforcement Learning (MARL) algorithm for joint user association and resource allocation (RA) for Phase I. The cluster leaders use their local Channel State Information (CSI) to decide the APs for connection along with the sub-band and power level. The cluster leaders utilize multi-connectivity to connect to multiple APs to increase their reliability. The objective is to maximize the successful payload delivery probability for all robots. Illustrative simulation results indicate that the proposed scheme can approach the performance of the centralized algorithm and offer a substantial gain in reliability as compared to single-connectivity (when cluster leaders are able to connect to 1 AP).
Massive MIMO Channel Prediction Using Machine Learning: Power of Domain Transformation
Aug 09, 2022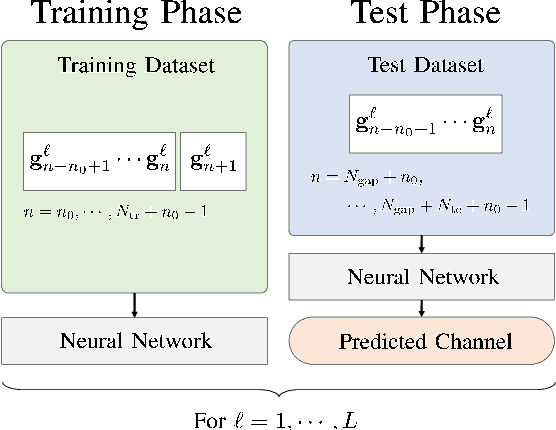
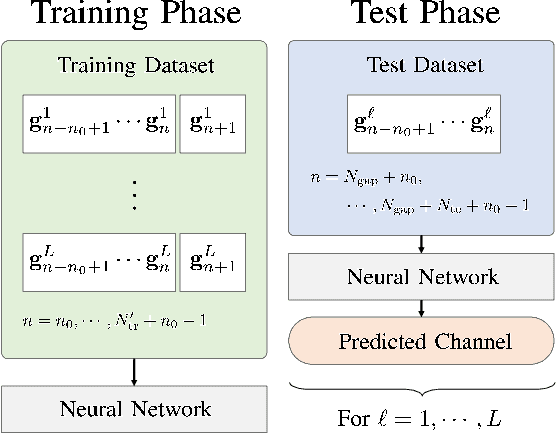
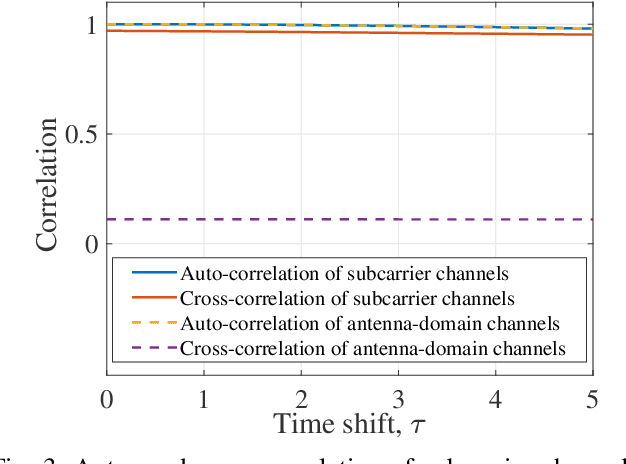
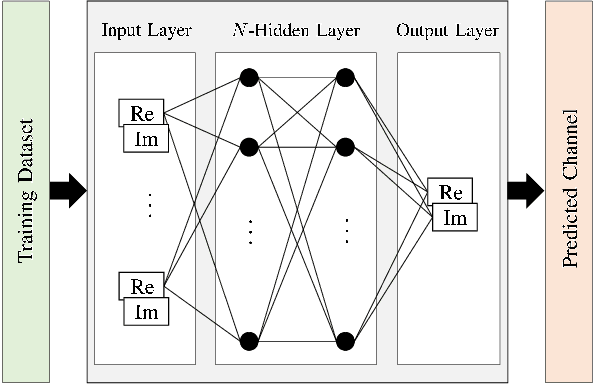
To compensate the loss from outdated channel state information in wideband massive multiple-input multipleoutput (MIMO) systems, channel prediction can be performed by leveraging the temporal correlation of wireless channels. Machine learning (ML)-based channel predictors for massive MIMO systems were designed recently; however, the time overhead to collect a large amount of training data directly affects the latency of the system. In this paper, we propose a novel ML-based channel prediction technique, which can reduce the time overhead to collect the training data by transforming the domain of channels from subcarrier to antenna in wideband massive MIMO systems. Numerical results show that the proposed technique can not only reduce the time overhead but also give additional performance gain compared to the ML-based channel prediction techniques without the domain transformation.
MatSciBERT: A Materials Domain Language Model for Text Mining and Information Extraction
Sep 30, 2021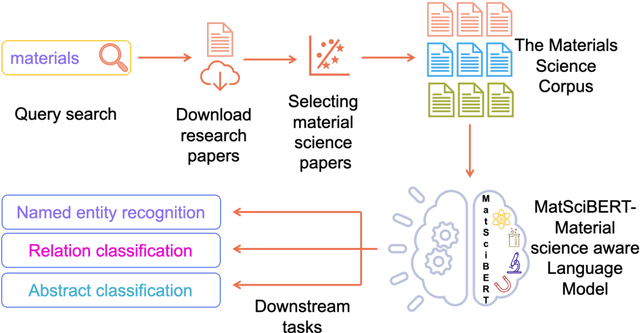
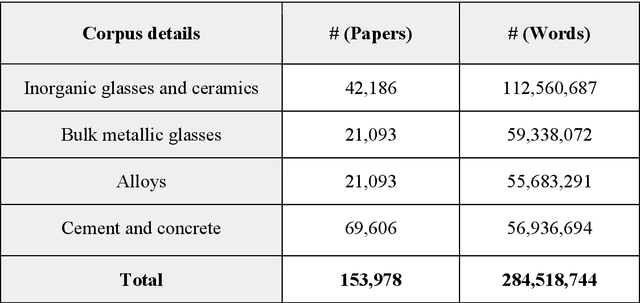
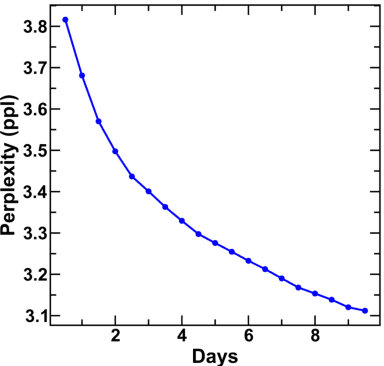
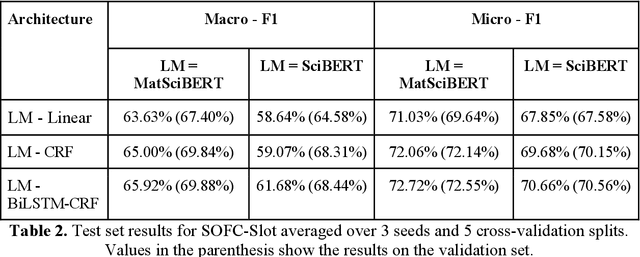
An overwhelmingly large amount of knowledge in the materials domain is generated and stored as text published in peer-reviewed scientific literature. Recent developments in natural language processing, such as bidirectional encoder representations from transformers (BERT) models, provide promising tools to extract information from these texts. However, direct application of these models in the materials domain may yield suboptimal results as the models themselves may not be trained on notations and jargon that are specific to the domain. Here, we present a materials-aware language model, namely, MatSciBERT, which is trained on a large corpus of scientific literature published in the materials domain. We further evaluate the performance of MatSciBERT on three downstream tasks, namely, abstract classification, named entity recognition, and relation extraction, on different materials datasets. We show that MatSciBERT outperforms SciBERT, a language model trained on science corpus, on all the tasks. Further, we discuss some of the applications of MatSciBERT in the materials domain for extracting information, which can, in turn, contribute to materials discovery or optimization. Finally, to make the work accessible to the larger materials community, we make the pretrained and finetuned weights and the models of MatSciBERT freely accessible.