 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross-receptive Focused Inference Network for Lightweight Image Super-Resolution
Jul 06, 2022
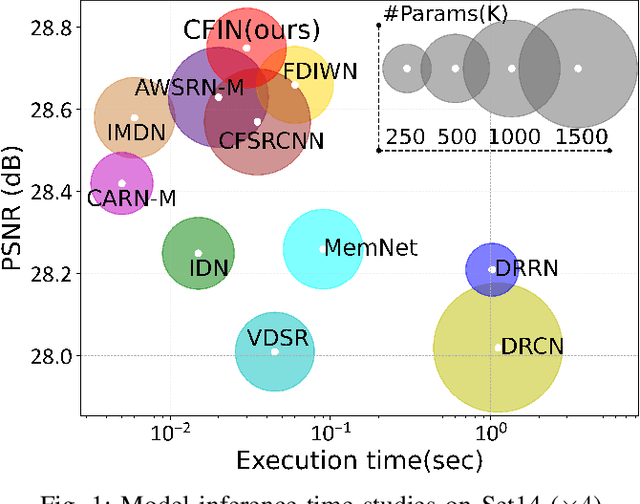
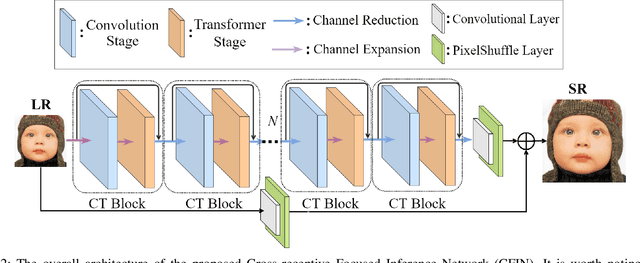
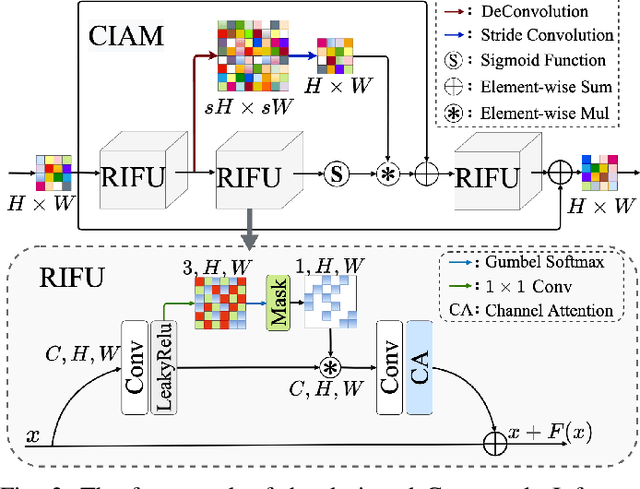
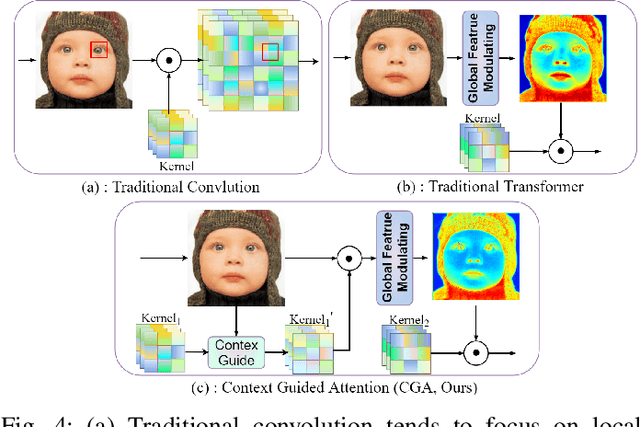
With the development of deep learning, single image super-resolution (SISR) has achieved significant breakthroughs. Recently, methods to enhance the performance of SISR networks based on global feature interactions have been proposed. However, the capabilities of neurons that need to adjust their function in response to the context dynamically are neglected. To address this issue, we propose a lightweight Cross-receptive Focused Inference Network (CFIN), a hybrid network composed of a Convolutional Neural Network (CNN) and a Transformer. Specifically, a novel Cross-receptive Field Guide Transformer (CFGT) is designed to adaptively modify the network weights by using modulated convolution kernels combined with local representative semantic information. In addition, a CNN-based Cross-scale Information Aggregation Module (CIAM) is proposed to make the model better focused on potentially practical information and improve the efficiency of the Transformer stage. Extensive experiments show that our proposed CFIN is a lightweight and efficient SISR model, which can achieve a good balance between computational cost and model performance.
MSMDFusion: Fusing LiDAR and Camera at Multiple Scales with Multi-Depth Seeds for 3D Object Detection
Sep 07, 2022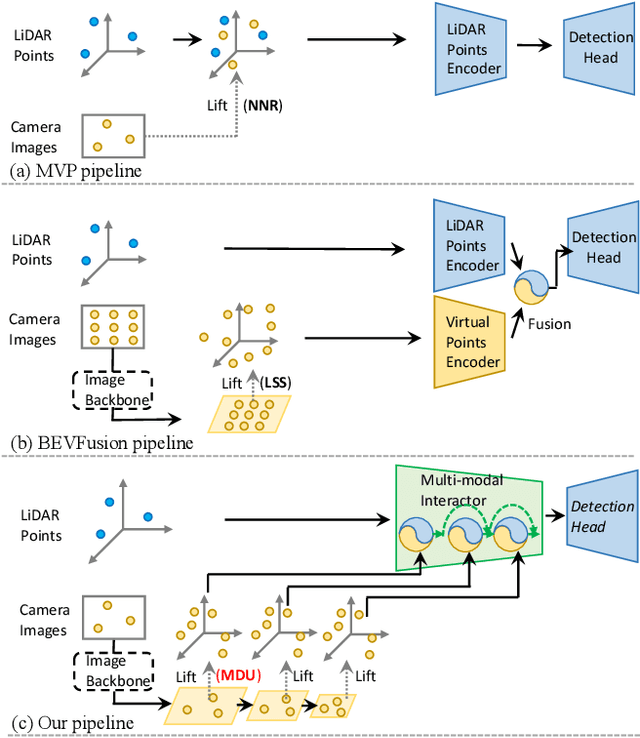
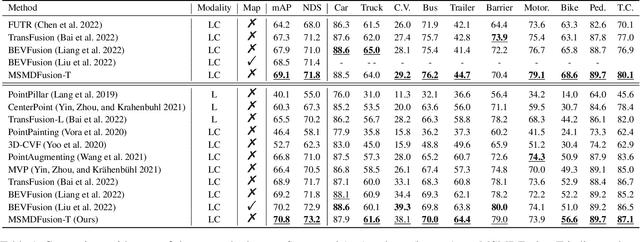
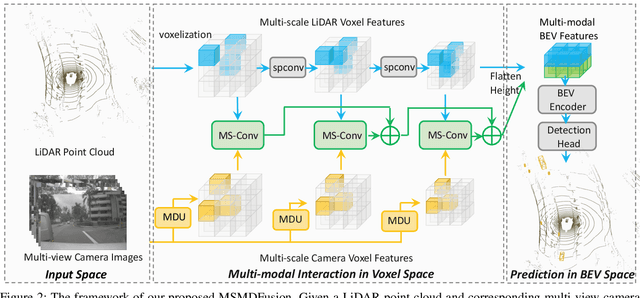
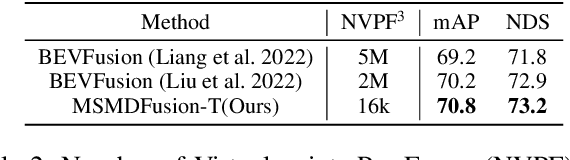
Fusing LiDAR and camera information is essential for achieving accurate and reliable 3D object detection in autonomous driving systems. However, this is challenging due to the difficulty of combining multi-granularity geometric and semantic features from two drastically different modalities. Recent approaches aim at exploring the semantic densities of camera features through lifting points in 2D camera images (referred to as seeds) into 3D space for fusion, and they can be roughly divided into 1) early fusion of raw points that aims at augmenting the 3D point cloud at the early input stage, and 2) late fusion of BEV (bird-eye view) maps that merges LiDAR and camera BEV features before the detection head. While both have their merits in enhancing the representation power of the combined features, this single-level fusion strategy is a suboptimal solution to the aforementioned challenge. Their major drawbacks are the inability to interact the multi-granularity semantic features from two distinct modalities sufficiently. To this end, we propose a novel framework that focuses on the multi-scale progressive interaction of the multi-granularity LiDAR and camera features. Our proposed method, abbreviated as MDMSFusion, achieves state-of-the-art results in 3D object detection, with 69.1 mAP and 71.8 NDS on nuScenes validation set, and 70.8 mAP and 73.2 NDS on nuScenes test set, which rank 1st and 2nd respectively among single-model non-ensemble approaches by the time of submission.
MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction
Aug 30, 2022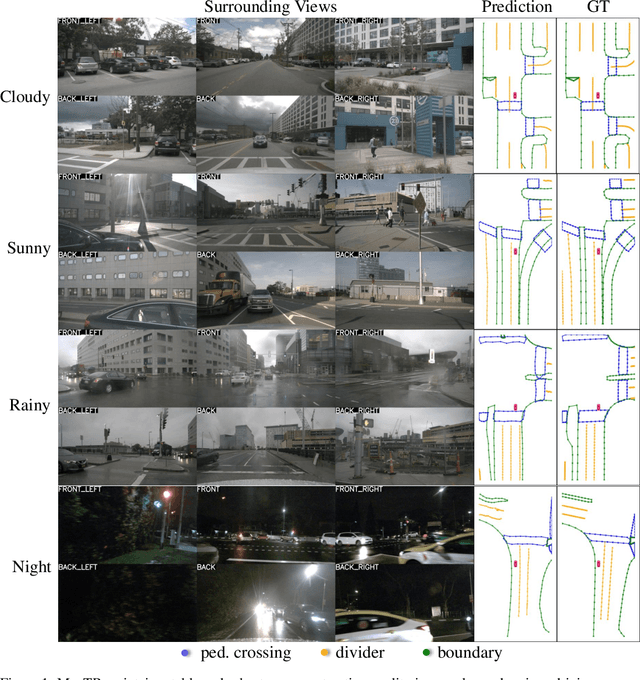
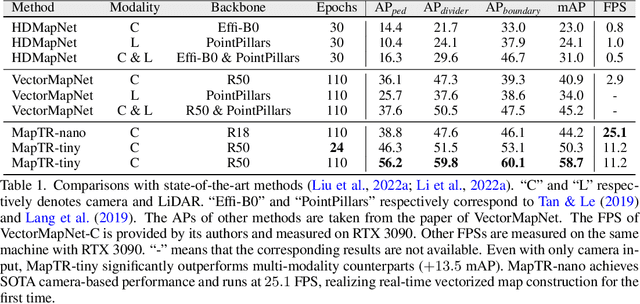
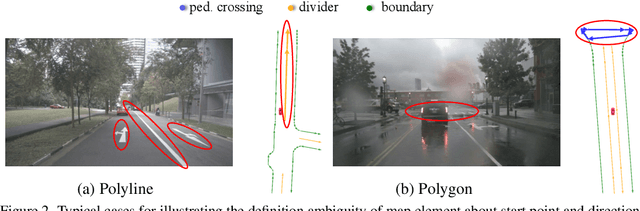

We present MapTR, a structured end-to-end framework for efficient online vectorized HD map construction. We propose a unified permutation-based modeling approach, i.e., modeling map element as a point set with a group of equivalent permutations, which avoids the definition ambiguity of map element and eases learning. We adopt a hierarchical query embedding scheme to flexibly encode structured map information and perform hierarchical bipartite matching for map element learning. MapTR achieves the best performance and efficiency among existing vectorized map construction approaches on nuScenes dataset. In particular, MapTR-nano runs at real-time inference speed ($25.1$ FPS) on RTX 3090, $8\times$ faster than the existing state-of-the-art camera-based method while achieving $3.3$ higher mAP. MapTR-tiny significantly outperforms the existing state-of-the-art multi-modality method by $13.5$ mAP while being faster. Qualitative results show that MapTR maintains stable and robust map construction quality in complex and various driving scenes. Abundant demos are available at \url{https://github.com/hustvl/MapTR} to prove the effectiveness in real-world scenarios. MapTR is of great application value in autonomous driving. Code will be released for facilitating further research and application.
A Portable Multiscopic Camera for Novel View and Time Synthesis in Dynamic Scenes
Aug 30, 2022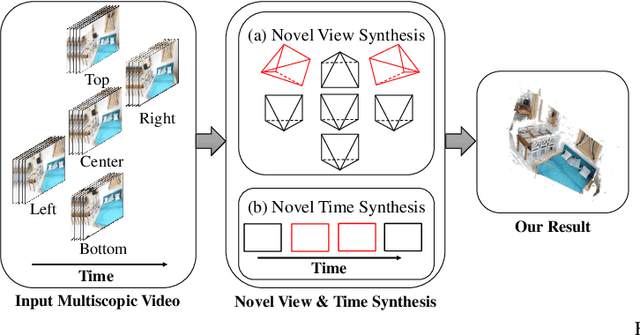
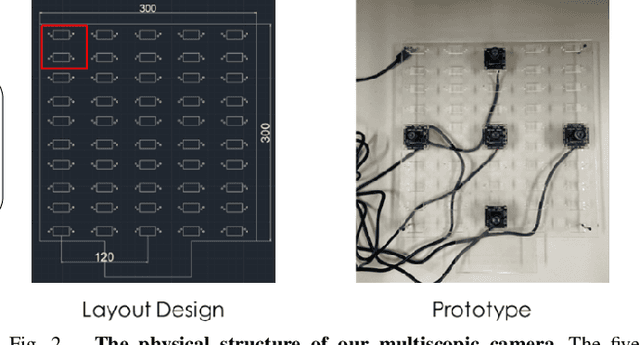
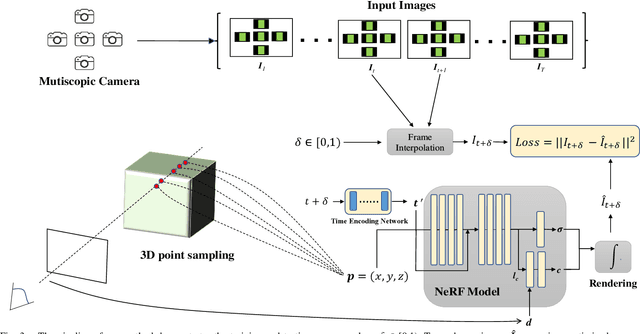

We present a portable multiscopic camera system with a dedicated model for novel view and time synthesis in dynamic scenes. Our goal is to render high-quality images for a dynamic scene from any viewpoint at any time using our portable multiscopic camera. To achieve such novel view and time synthesis, we develop a physical multiscopic camera equipped with five cameras to train a neural radiance field (NeRF) in both time and spatial domains for dynamic scenes. Our model maps a 6D coordinate (3D spatial position, 1D temporal coordinate, and 2D viewing direction) to view-dependent and time-varying emitted radiance and volume density. Volume rendering is applied to render a photo-realistic image at a specified camera pose and time. To improve the robustness of our physical camera, we propose a camera parameter optimization module and a temporal frame interpolation module to promote information propagation across time. We conduct experiments on both real-world and synthetic datasets to evaluate our system, and the results show that our approach outperforms alternative solutions qualitatively and quantitatively. Our code and dataset are available at https://yuenfuilau.github.io.
Design of Negative Sampling Strategies for Distantly Supervised Skill Extraction
Sep 13, 2022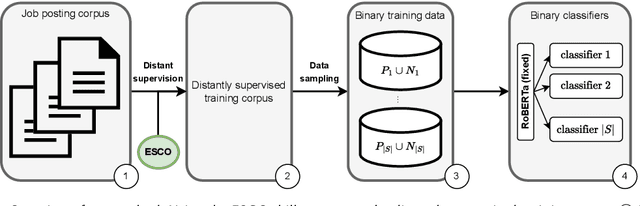
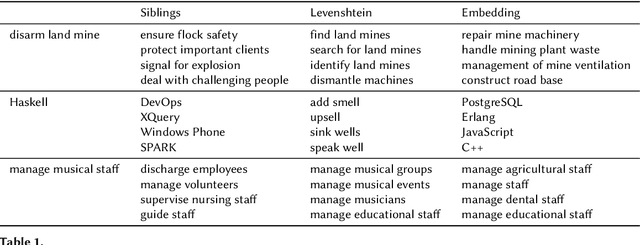
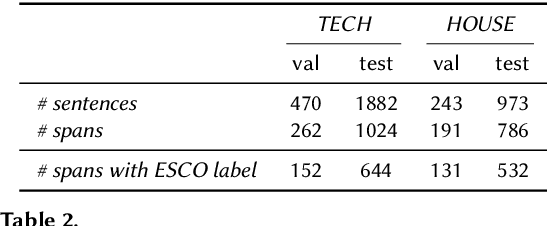
Skills play a central role in the job market and many human resources (HR) processes. In the wake of other digital experiences, today's online job market has candidates expecting to see the right opportunities based on their skill set. Similarly, enterprises increasingly need to use data to guarantee that the skills within their workforce remain future-proof. However, structured information about skills is often missing, and processes building on self- or manager-assessment have shown to struggle with issues around adoption, completeness, and freshness of the resulting data. Extracting skills is a highly challenging task, given the many thousands of possible skill labels mentioned either explicitly or merely described implicitly and the lack of finely annotated training corpora. Previous work on skill extraction overly simplifies the task to an explicit entity detection task or builds on manually annotated training data that would be infeasible if applied to a complete vocabulary of skills. We propose an end-to-end system for skill extraction, based on distant supervision through literal matching. We propose and evaluate several negative sampling strategies, tuned on a small validation dataset, to improve the generalization of skill extraction towards implicitly mentioned skills, despite the lack of such implicit skills in the distantly supervised data. We observe that using the ESCO taxonomy to select negative examples from related skills yields the biggest improvements, and combining three different strategies in one model further increases the performance, up to 8 percentage points in RP@5. We introduce a manually annotated evaluation benchmark for skill extraction based on the ESCO taxonomy, on which we validate our models. We release the benchmark dataset for research purposes to stimulate further research on the task.
Autoencoder Based Iterative Modeling and Multivariate Time-Series Subsequence Clustering Algorithm
Sep 09, 2022


This paper introduces an algorithm for the detection of change-points and the identification of the corresponding subsequences in transient multivariate time-series data (MTSD). The analysis of such data has become more and more important due to the increase of availability in many industrial fields. Labeling, sorting or filtering highly transient measurement data for training condition based maintenance (CbM) models is cumbersome and error-prone. For some applications it can be sufficient to filter measurements by simple thresholds or finding change-points based on changes in mean value and variation. But a robust diagnosis of a component within a component group for example, which has a complex non-linear correlation between multiple sensor values, a simple approach would not be feasible. No meaningful and coherent measurement data which could be used for training a CbM model would emerge. Therefore, we introduce an algorithm which uses a recurrent neural network (RNN) based Autoencoder (AE) which is iteratively trained on incoming data. The scoring function uses the reconstruction error and latent space information. A model of the identified subsequence is saved and used for recognition of repeating subsequences as well as fast offline clustering. For evaluation, we propose a new similarity measure based on the curvature for a more intuitive time-series subsequence clustering metric. A comparison with seven other state-of-the-art algorithms and eight datasets shows the capability and the increased performance of our algorithm to cluster MTSD online and offline in conjunction with mechatronic systems.
Lost in Context? On the Sense-wise Variance of Contextualized Word Embeddings
Aug 20, 2022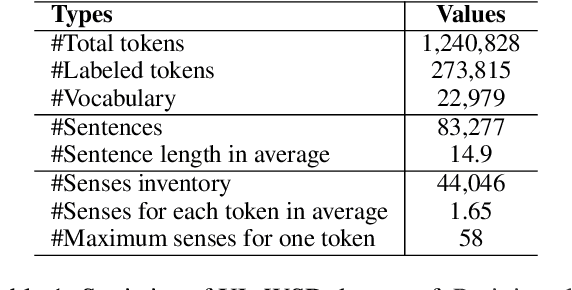
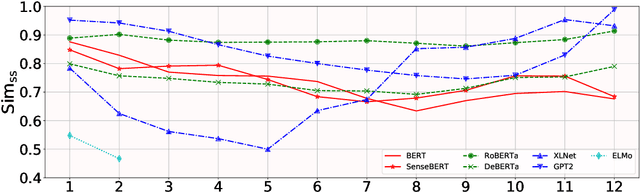
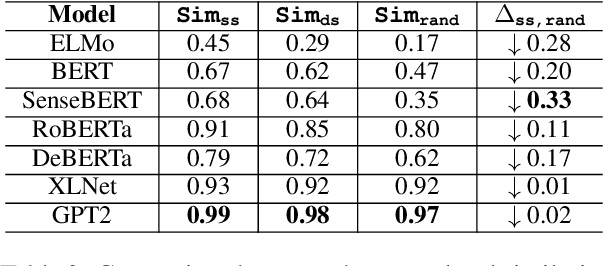
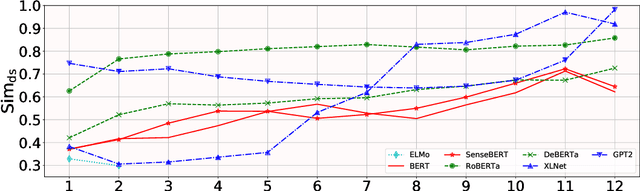
Contextualized word embeddings in language models have given much advance to NLP. Intuitively, sentential information is integrated into the representation of words, which can help model polysemy. However, context sensitivity also leads to the variance of representations, which may break the semantic consistency for synonyms. We quantify how much the contextualized embeddings of each word sense vary across contexts in typical pre-trained models. Results show that contextualized embeddings can be highly consistent across contexts. In addition, part-of-speech, number of word senses, and sentence length have an influence on the variance of sense representations. Interestingly, we find that word representations are position-biased, where the first words in different contexts tend to be more similar. We analyze such a phenomenon and also propose a simple way to alleviate such bias in distance-based word sense disambiguation settings.
On the Role of Spatial, Spectral, and Temporal Processing for DNN-based Non-linear Multi-channel Speech Enhancement
Jun 22, 2022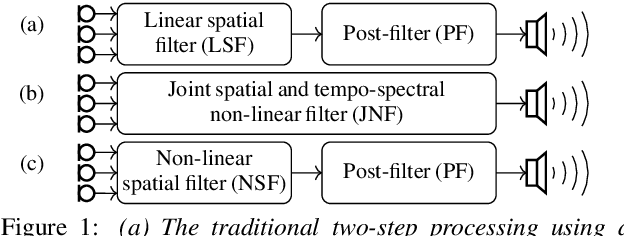
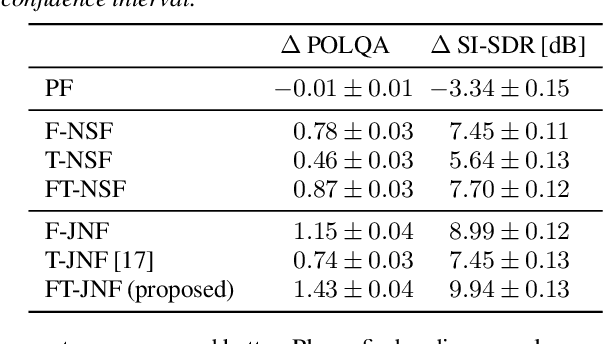
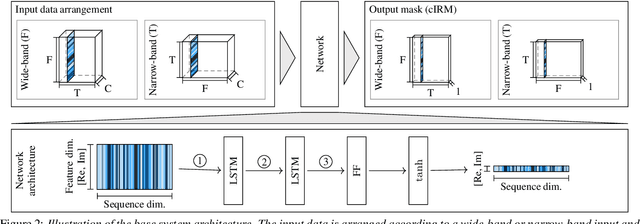
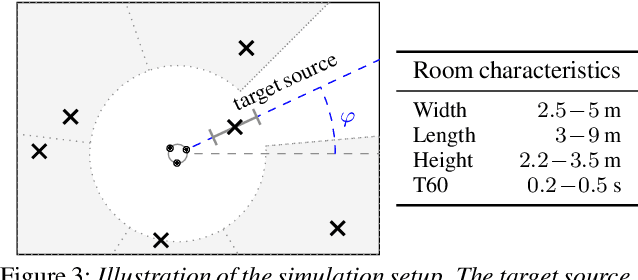
Employing deep neural networks (DNNs) to directly learn filters for multi-channel speech enhancement has potentially two key advantages over a traditional approach combining a linear spatial filter with an independent tempo-spectral post-filter: 1) non-linear spatial filtering allows to overcome potential restrictions originating from a linear processing model and 2) joint processing of spatial and tempo-spectral information allows to exploit interdependencies between different sources of information. A variety of DNN-based non-linear filters have been proposed recently, for which good enhancement performance is reported. However, little is known about the internal mechanisms which turns network architecture design into a game of chance. Therefore, in this paper, we perform experiments to better understand the internal processing of spatial, spectral and temporal information by DNN-based non-linear filters. On the one hand, our experiments in a difficult speech extraction scenario confirm the importance of non-linear spatial filtering, which outperforms an oracle linear spatial filter by 0.24 POLQA score. On the other hand, we demonstrate that joint processing results in a large performance gap of 0.4 POLQA score between network architectures exploiting spectral versus temporal information besides spatial information.
Effective Multi-User Delay-Constrained Scheduling with Deep Recurrent Reinforcement Learning
Aug 30, 2022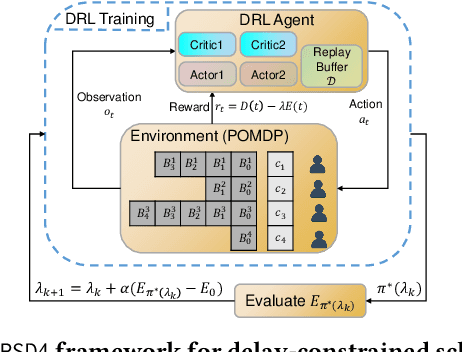

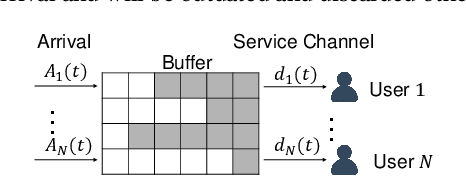
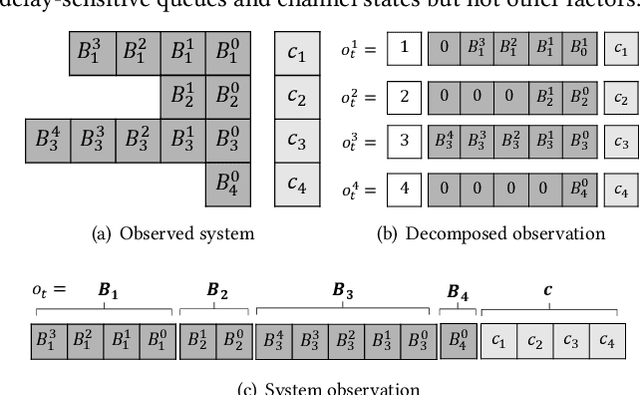
Multi-user delay constrained scheduling is important in many real-world applications including wireless communication, live streaming, and cloud computing. Yet, it poses a critical challenge since the scheduler needs to make real-time decisions to guarantee the delay and resource constraints simultaneously without prior information of system dynamics, which can be time-varying and hard to estimate. Moreover, many practical scenarios suffer from partial observability issues, e.g., due to sensing noise or hidden correlation. To tackle these challenges, we propose a deep reinforcement learning (DRL) algorithm, named Recurrent Softmax Delayed Deep Double Deterministic Policy Gradient ($\mathtt{RSD4}$), which is a data-driven method based on a Partially Observed Markov Decision Process (POMDP) formulation. $\mathtt{RSD4}$ guarantees resource and delay constraints by Lagrangian dual and delay-sensitive queues, respectively. It also efficiently tackles partial observability with a memory mechanism enabled by the recurrent neural network (RNN) and introduces user-level decomposition and node-level merging to ensure scalability. Extensive experiments on simulated/real-world datasets demonstrate that $\mathtt{RSD4}$ is robust to system dynamics and partially observable environments, and achieves superior performances over existing DRL and non-DRL-based methods.
Entropy, Information, and the Updating of Probabilities
Jul 09, 2021This paper is a review of a particular approach to the method of maximum entropy as a general framework for inference. The discussion emphasizes the pragmatic elements in the derivation. An epistemic notion of information is defined in terms of its relation to the Bayesian beliefs of ideally rational agents. The method of updating from a prior to a posterior probability distribution is designed through an eliminative induction process. The logarithmic relative entropy is singled out as the unique tool for updating that (a) is of universal applicability; (b) that recognizes the value of prior information; and (c) that recognizes the privileged role played by the notion of independence in science. The resulting framework -- the ME method -- can handle arbitrary priors and arbitrary constraints. It includes MaxEnt and Bayes' rule as special cases and, therefore, it unifies entropic and Bayesian methods into a single general inference scheme. The ME method goes beyond the mere selection of a single posterior, but also addresses the question of how much less probable other distributions might be, which provides a direct bridge to the theories of fluctuations and large deviations.