 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Online Information-Aware Motion Planning with Inertial Parameter Learning for Robotic Free-Flyers
Dec 11, 2021

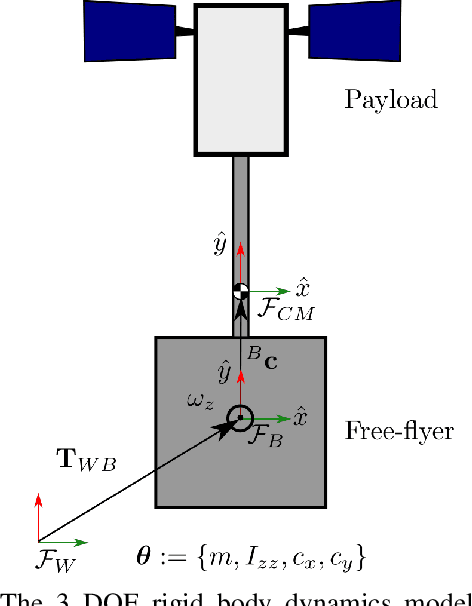
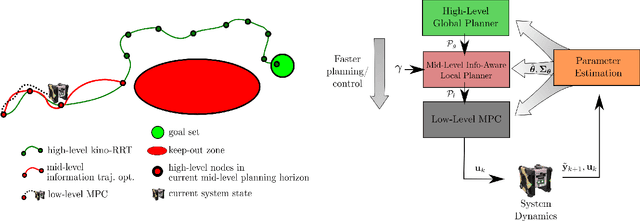

Space free-flyers like the Astrobee robots currently operating aboard the International Space Station must operate with inherent system uncertainties. Parametric uncertainties like mass and moment of inertia are especially important to quantify in these safety-critical space systems and can change in scenarios such as on-orbit cargo movement, where unknown grappled payloads significantly change the system dynamics. Cautiously learning these uncertainties en route can potentially avoid time- and fuel-consuming pure system identification maneuvers. Recognizing this, this work proposes RATTLE, an online information-aware motion planning algorithm that explicitly weights parametric model-learning coupled with real-time replanning capability that can take advantage of improved system models. The method consists of a two-tiered (global and local) planner, a low-level model predictive controller, and an online parameter estimator that produces estimates of the robot's inertial properties for more informed control and replanning on-the-fly; all levels of the planning and control feature online update-able models. Simulation results of RATTLE for the Astrobee free-flyer grappling an uncertain payload are presented alongside results of a hardware demonstration showcasing the ability to explicitly encourage model parametric learning while achieving otherwise useful motion.
Arbitrary unitary rotation of three-dimensional pixellated images
Jul 27, 2022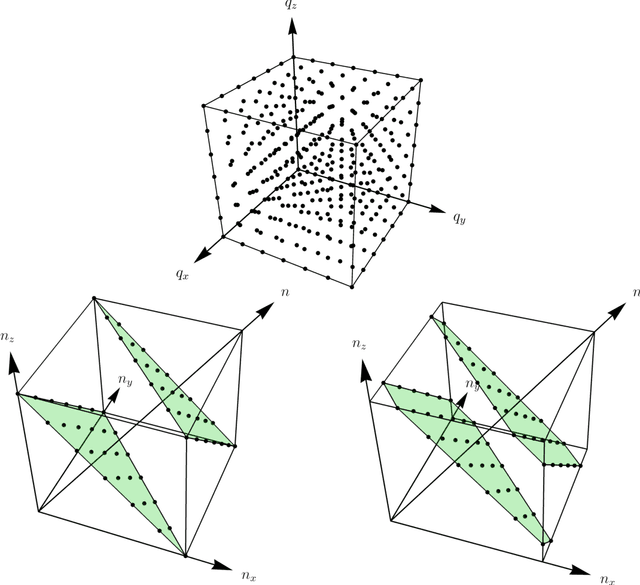
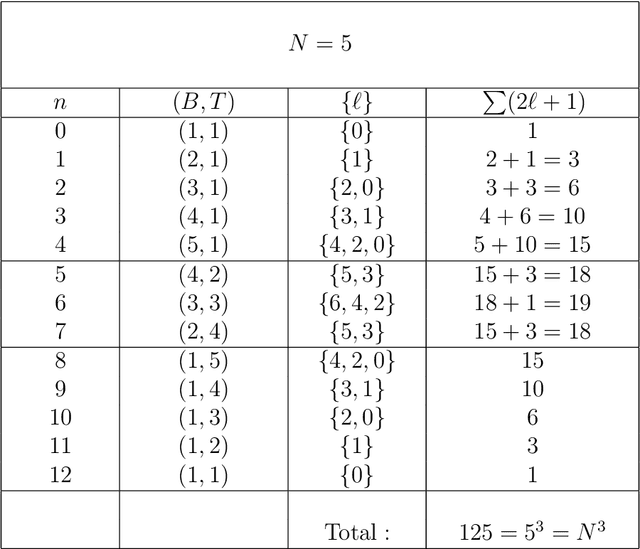
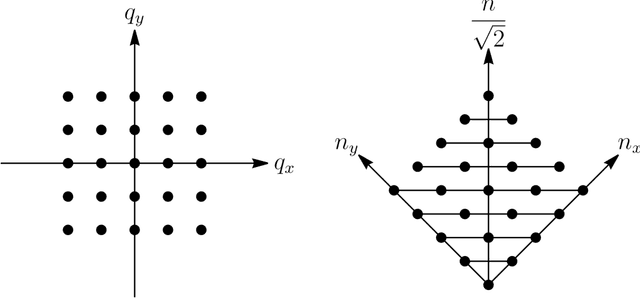
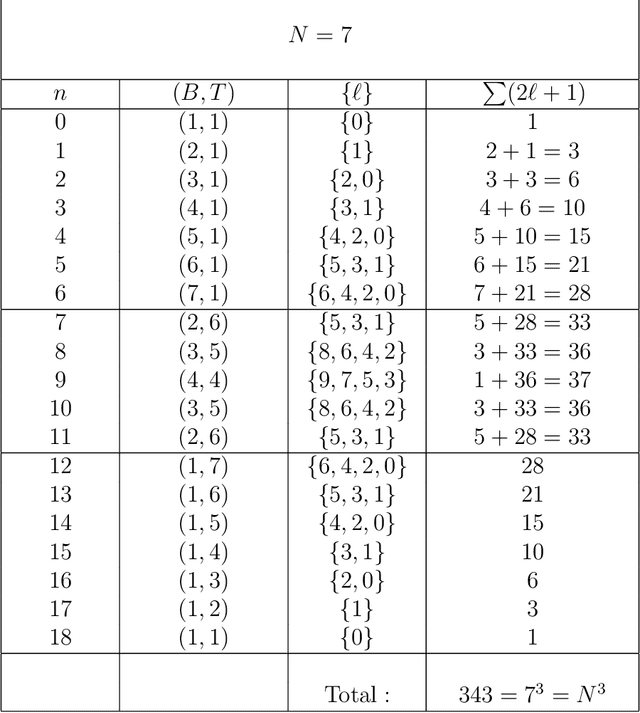
Using the coefficients introduced by Bargmann and Moshinsky for the reduction of the su($3$) algebra of Cartesian three-dimensional oscillator multiplet states into so($3$) angular momentum submultiplets, we implement unitary rotations of three-dimensional Cartesian arrays that form finite pixellated "volume images." Transforming between the Cartesian and spherical bases, the subgroup of rotations in the latter is converted into rotations of the former, allowing for proper concatenation and inversion of these unitary transformations, which entail no loss of information.
MatSciBERT: A Materials Domain Language Model for Text Mining and Information Extraction
Sep 30, 2021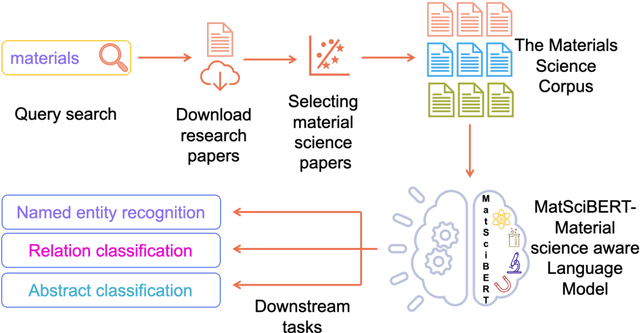
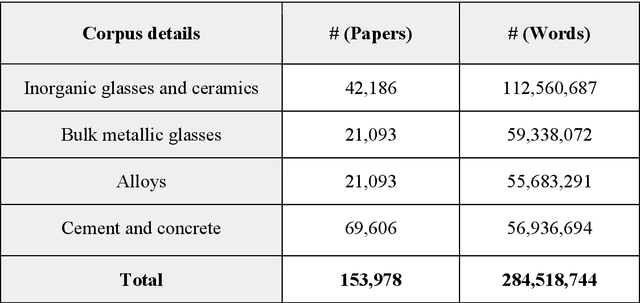
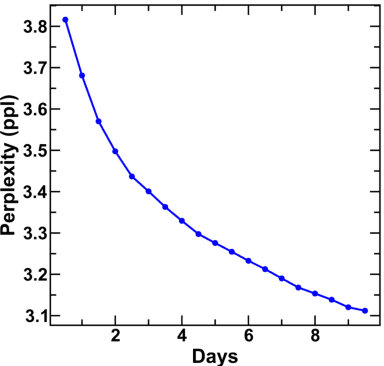
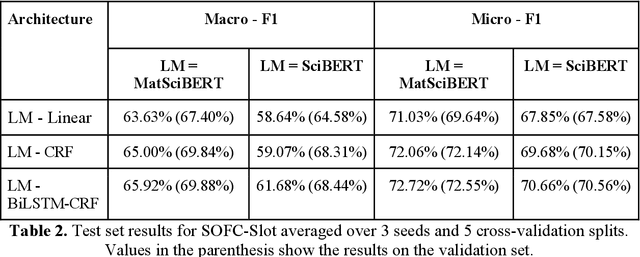
An overwhelmingly large amount of knowledge in the materials domain is generated and stored as text published in peer-reviewed scientific literature. Recent developments in natural language processing, such as bidirectional encoder representations from transformers (BERT) models, provide promising tools to extract information from these texts. However, direct application of these models in the materials domain may yield suboptimal results as the models themselves may not be trained on notations and jargon that are specific to the domain. Here, we present a materials-aware language model, namely, MatSciBERT, which is trained on a large corpus of scientific literature published in the materials domain. We further evaluate the performance of MatSciBERT on three downstream tasks, namely, abstract classification, named entity recognition, and relation extraction, on different materials datasets. We show that MatSciBERT outperforms SciBERT, a language model trained on science corpus, on all the tasks. Further, we discuss some of the applications of MatSciBERT in the materials domain for extracting information, which can, in turn, contribute to materials discovery or optimization. Finally, to make the work accessible to the larger materials community, we make the pretrained and finetuned weights and the models of MatSciBERT freely accessible.
A cross-corpus study on speech emotion recognition
Jul 05, 2022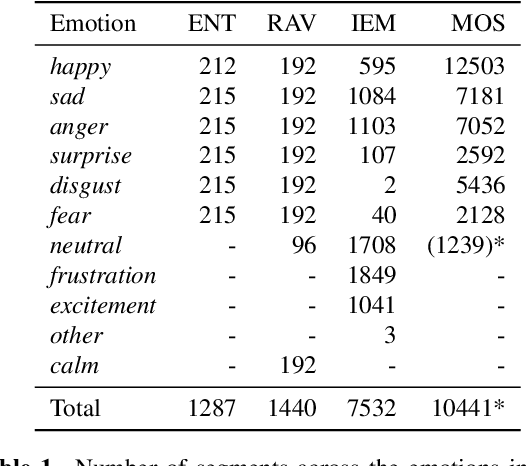
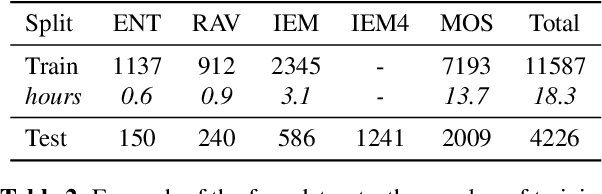
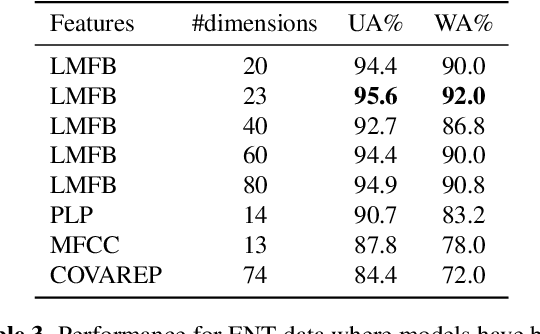
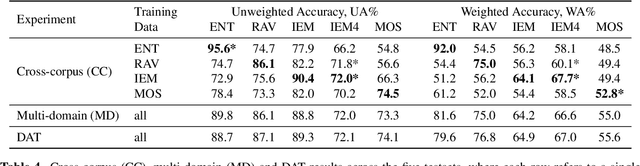
For speech emotion datasets, it has been difficult to acquire large quantities of reliable data and acted emotions may be over the top compared to less expressive emotions displayed in everyday life. Lately, larger datasets with natural emotions have been created. Instead of ignoring smaller, acted datasets, this study investigates whether information learnt from acted emotions is useful for detecting natural emotions. Cross-corpus research has mostly considered cross-lingual and even cross-age datasets, and difficulties arise from different methods of annotating emotions causing a drop in performance. To be consistent, four adult English datasets covering acted, elicited and natural emotions are considered. A state-of-the-art model is proposed to accurately investigate the degradation of performance. The system involves a bi-directional LSTM with an attention mechanism to classify emotions across datasets. Experiments study the effects of training models in a cross-corpus and multi-domain fashion and results show the transfer of information is not successful. Out-of-domain models, followed by adapting to the missing dataset, and domain adversarial training (DAT) are shown to be more suitable to generalising to emotions across datasets. This shows positive information transfer from acted datasets to those with more natural emotions and the benefits from training on different corpora.
* ASRU 2019
Derivative-Informed Neural Operator: An Efficient Framework for High-Dimensional Parametric Derivative Learning
Jun 23, 2022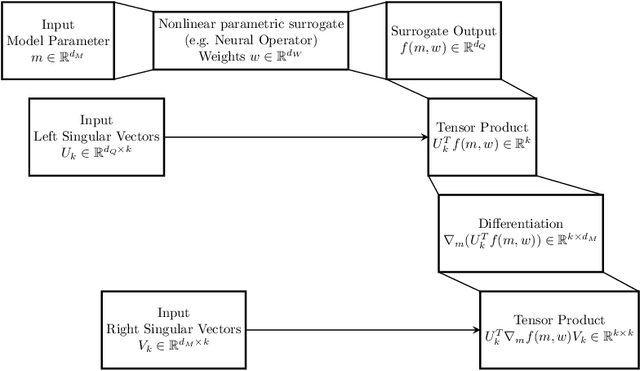
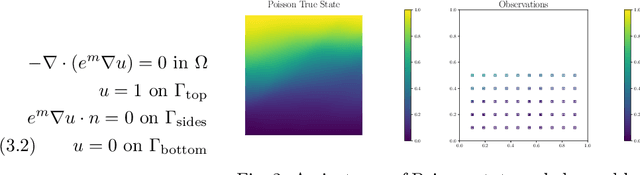
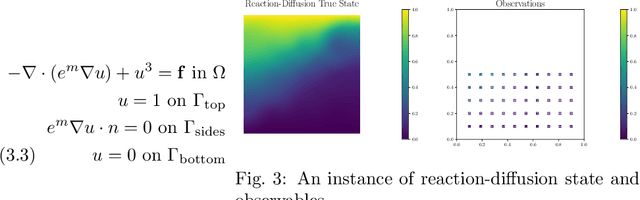
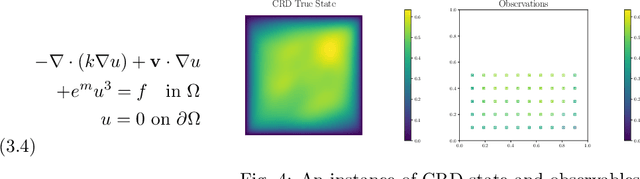
Neural operators have gained significant attention recently due to their ability to approximate high-dimensional parametric maps between function spaces. At present, only parametric function approximation has been addressed in the neural operator literature. In this work we investigate incorporating parametric derivative information in neural operator training; this information can improve function approximations, additionally it can be used to improve the approximation of the derivative with respect to the parameter, which is often the key to scalable solution of high-dimensional outer-loop problems (e.g. Bayesian inverse problems). Parametric Jacobian information is formally intractable to incorporate due to its high-dimensionality, to address this concern we propose strategies based on reduced SVD, randomized sketching and the use of reduced basis surrogates. All of these strategies only require only $O(r)$ Jacobian actions to construct sample Jacobian data, and allow us to reduce the linear algebra and memory costs associated with the Jacobian training from the product of the input and output dimensions down to $O(r^2)$, where $r$ is the dimensionality associated with the dimension reduction technique. Numerical results for parametric PDE problems demonstrate that the addition of derivative information to the training problem can significantly improve the parametric map approximation, particularly given few data. When Jacobian actions are inexpensive compared to the parametric map, this information can be economically substituted for parametric map data. Additionally we show that Jacobian error approximations improve significantly with the introduction of Jacobian training data. This result opens the door to the use of derivative-informed neural operators (DINOs) in outer-loop algorithms where they can amortize the additional training data cost via repeated evaluations.
A Simple Baseline for Multi-Camera 3D Object Detection
Aug 22, 2022
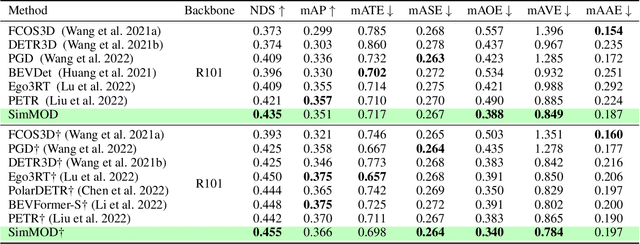
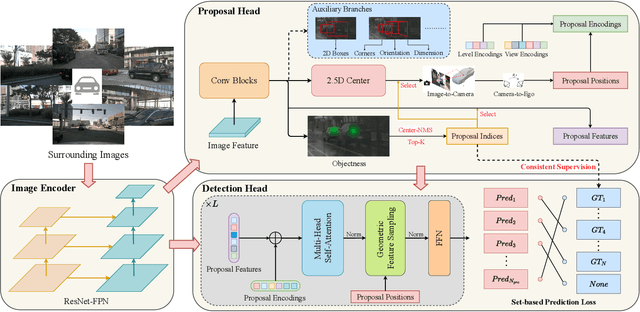
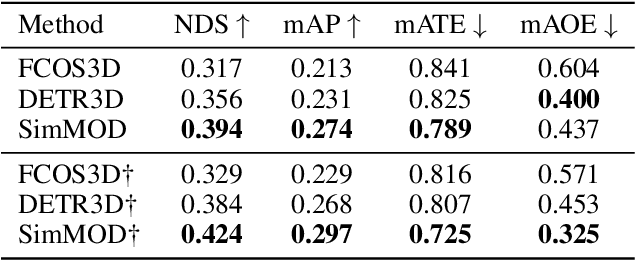
3D object detection with surrounding cameras has been a promising direction for autonomous driving. In this paper, we present SimMOD, a Simple baseline for Multi-camera Object Detection, to solve the problem. To incorporate multi-view information as well as build upon previous efforts on monocular 3D object detection, the framework is built on sample-wise object proposals and designed to work in a two-stage manner. First, we extract multi-scale features and generate the perspective object proposals on each monocular image. Second, the multi-view proposals are aggregated and then iteratively refined with multi-view and multi-scale visual features in the DETR3D-style. The refined proposals are end-to-end decoded into the detection results. To further boost the performance, we incorporate the auxiliary branches alongside the proposal generation to enhance the feature learning. Also, we design the methods of target filtering and teacher forcing to promote the consistency of two-stage training. We conduct extensive experiments on the 3D object detection benchmark of nuScenes to demonstrate the effectiveness of SimMOD and achieve new state-of-the-art performance. Code will be available at https://github.com/zhangyp15/SimMOD.
Disentangling private classes through regularization
Jul 05, 2022
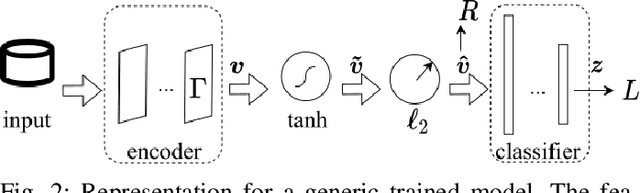
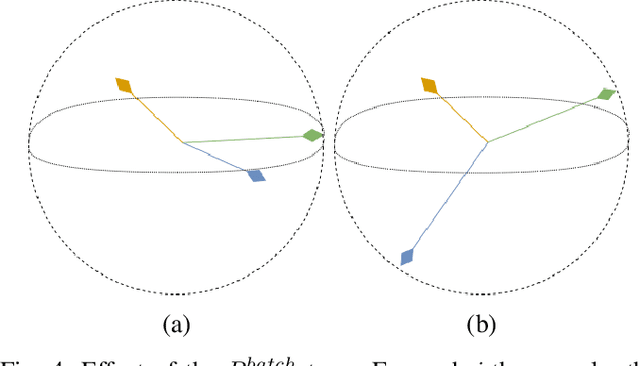
Deep learning models are nowadays broadly deployed to solve an incredibly large variety of tasks. However, little attention has been devoted to connected legal aspects. In 2016, the European Union approved the General Data Protection Regulation which entered into force in 2018. Its main rationale was to protect the privacy and data protection of its citizens by the way of operating of the so-called "Data Economy". As data is the fuel of modern Artificial Intelligence, it is argued that the GDPR can be partly applicable to a series of algorithmic decision making tasks before a more structured AI Regulation enters into force. In the meantime, AI should not allow undesired information leakage deviating from the purpose for which is created. In this work we propose DisP, an approach for deep learning models disentangling the information related to some classes we desire to keep private, from the data processed by AI. In particular, DisP is a regularization strategy de-correlating the features belonging to the same private class at training time, hiding the information of private classes membership. Our experiments on state-of-the-art deep learning models show the effectiveness of DisP, minimizing the risk of extraction for the classes we desire to keep private.
Differentiable WORLD Synthesizer-based Neural Vocoder With Application To End-To-End Audio Style Transfer
Aug 15, 2022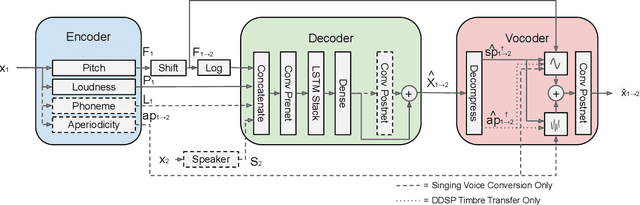

In this paper, we propose a differentiable WORLD synthesizer and demonstrate its use in end-to-end audio style transfer tasks such as (singing) voice conversion and the DDSP timbre transfer task. Accordingly, our baseline differentiable synthesizer has no model parameters, yet it yields adequate synthesis quality. We can extend the baseline synthesizer by appending lightweight black-box postnets which apply further processing to the baseline output in order to improve fidelity. An alternative differentiable approach considers extraction of the source excitation spectrum directly, which can improve naturalness albeit for a narrower class of style transfer applications. The acoustic feature parameterization used by our approaches has the added benefit that it naturally disentangles pitch and timbral information so that they can be modeled separately. Moreover, as there exists a robust means of estimating these acoustic features from monophonic audio sources, it allows for parameter loss terms to be added to an end-to-end objective function, which can help convergence and/or further stabilize (adversarial) training.
Efficient Learning of Pinball TWSVM using Privileged Information and its applications
Jul 14, 2021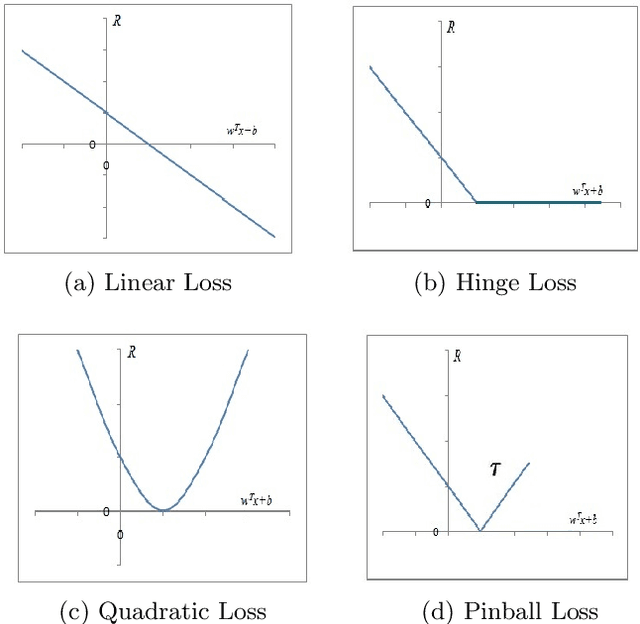

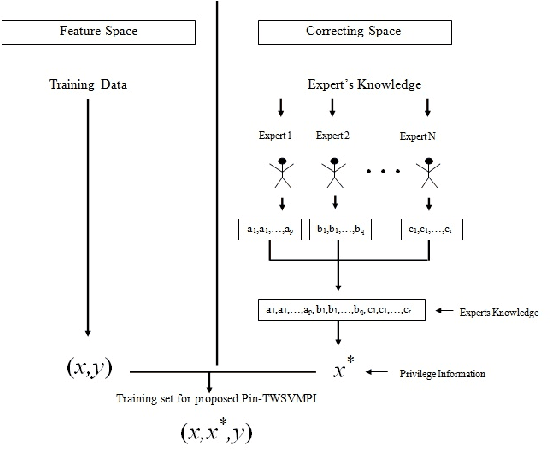

In any learning framework, an expert knowledge always plays a crucial role. But, in the field of machine learning, the knowledge offered by an expert is rarely used. Moreover, machine learning algorithms (SVM based) generally use hinge loss function which is sensitive towards the noise. Thus, in order to get the advantage from an expert knowledge and to reduce the sensitivity towards the noise, in this paper, we propose privileged information based Twin Pinball Support Vector Machine classifier (Pin-TWSVMPI) where expert's knowledge is in the form of privileged information. The proposed Pin-TWSVMPI incorporates privileged information by using correcting function so as to obtain two nonparallel decision hyperplanes. Further, in order to make computations more efficient and fast, we use Sequential Minimal Optimization (SMO) technique for obtaining the classifier and have also shown its application for Pedestrian detection and Handwritten digit recognition. Further, for UCI datasets, we first implement a procedure which extracts privileged information from the features of the dataset which are then further utilized by Pin-TWSVMPI that leads to enhancement in classification accuracy with comparatively lesser computational time.
Antecedent Predictions Are Dominant for Tree-Based Code Generation
Aug 22, 2022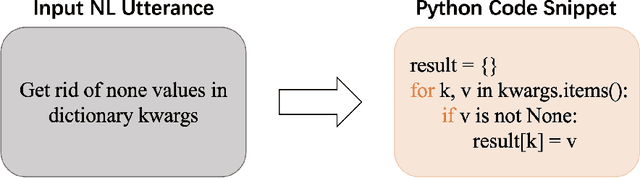
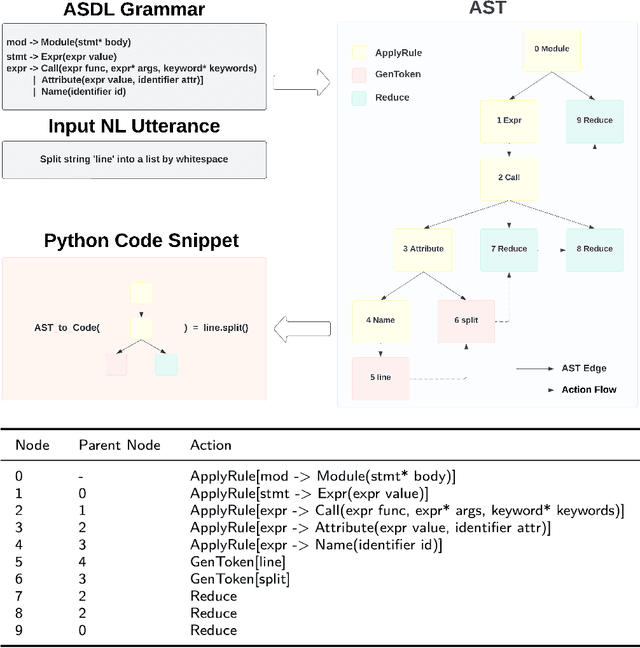
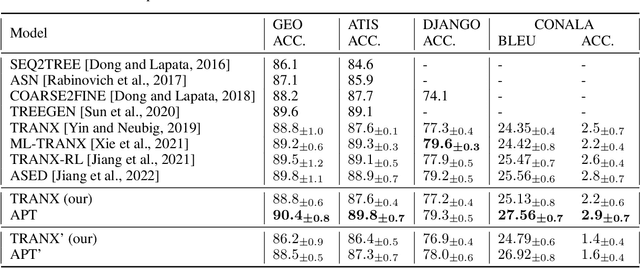
Code generation focuses on the automatic conversion of natural language (NL) utterances into code snippets. The sequence-to-tree (Seq2Tree) methods, e.g., TRANX, are proposed for code generation, with the guarantee of the compilability of the generated code, which generate the subsequent Abstract Syntax Tree (AST) node relying on antecedent predictions of AST nodes. Existing Seq2Tree methods tend to treat both antecedent predictions and subsequent predictions equally. However, under the AST constraints, it is difficult for Seq2Tree models to produce the correct subsequent prediction based on incorrect antecedent predictions. Thus, antecedent predictions ought to receive more attention than subsequent predictions. To this end, in this paper, we propose an effective method, named APTRANX (Antecedent Prioritized TRANX), on the basis of TRANX. APTRANX contains an Antecedent Prioritized (AP) Loss, which helps the model attach importance to antecedent predictions by exploiting the position information of the generated AST nodes. With better antecedent predictions and accompanying subsequent predictions, APTRANX significantly improves the performance. We conduct extensive experiments on several benchmark datasets, and the experimental results demonstrate the superiority and generality of our proposed method compared with the state-of-the-art methods.