 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Practical & Unified Notation for Information-Theoretic Quantities in ML
Jun 22, 2021
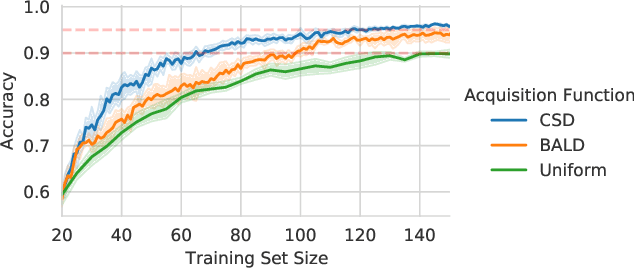

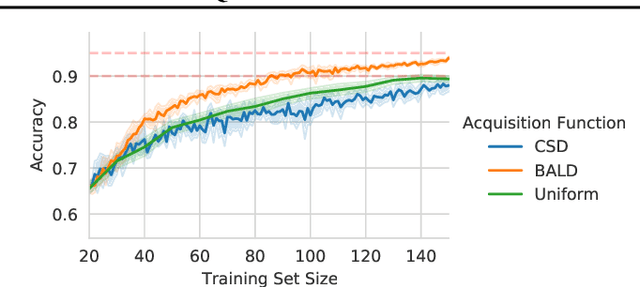
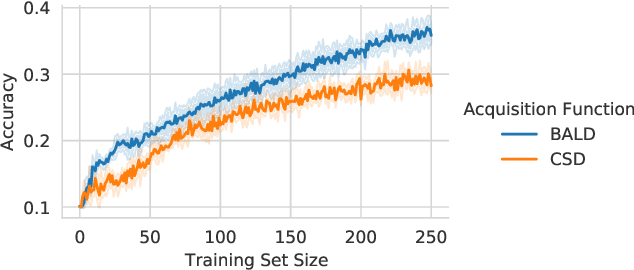
Information theory is of importance to machine learning, but the notation for information-theoretic quantities is sometimes opaque. The right notation can convey valuable intuitions and concisely express new ideas. We propose such a notation for machine learning users and expand it to include information-theoretic quantities between events (outcomes) and random variables. We apply this notation to a popular information-theoretic acquisition function in Bayesian active learning which selects the most informative (unlabelled) samples to be labelled by an expert. We demonstrate the value of our notation when extending the acquisition function to the core-set problem, which consists of selecting the most informative samples \emph{given} the labels.
Bayesian Optimization-based Combinatorial Assignment
Aug 31, 2022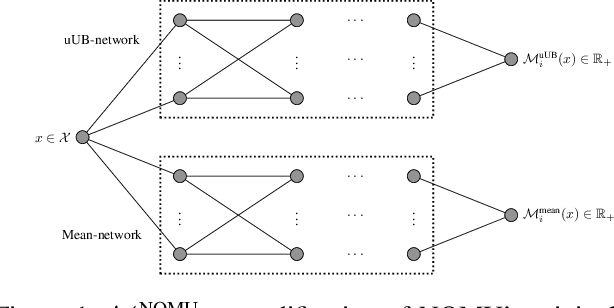

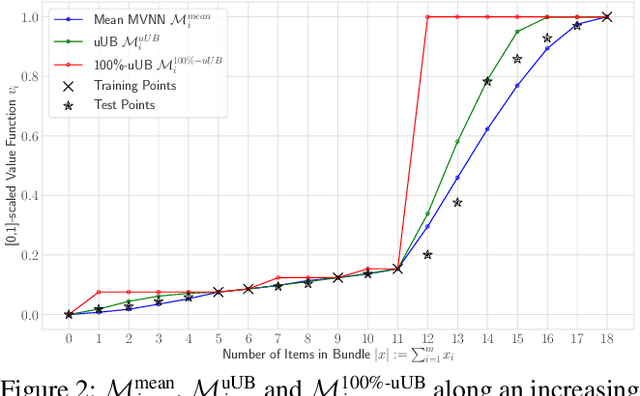
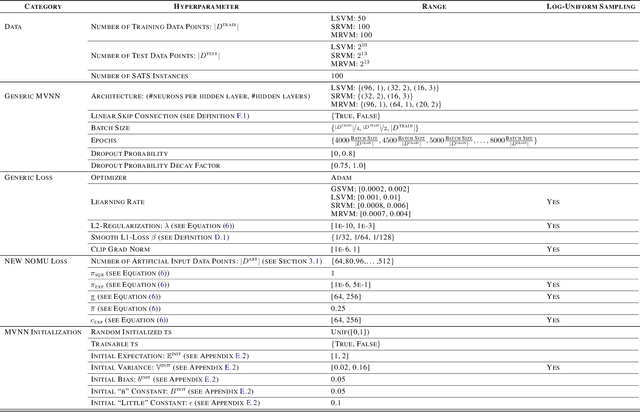
We study the combinatorial assignment domain, which includes combinatorial auctions and course allocation. The main challenge in this domain is that the bundle space grows exponentially in the number of items. To address this, several papers have recently proposed machine learning-based preference elicitation algorithms that aim to elicit only the most important information from agents. However, the main shortcoming of this prior work is that it does not model a mechanism's uncertainty over values for not yet elicited bundles. In this paper, we address this shortcoming by presenting a Bayesian Optimization-based Combinatorial Assignment (BOCA) mechanism. Our key technical contribution is to integrate a method for capturing model uncertainty into an iterative combinatorial auction mechanism. Concretely, we design a new method for estimating an upper uncertainty bound that can be used as an acquisition function to determine the next query to the agents. This enables the mechanism to properly explore (and not just exploit) the bundle space during its preference elicitation phase. We run computational experiments in several spectrum auction domains to evaluate BOCA's performance. Our results show that BOCA achieves higher allocative efficiency than state-of-the-art approaches.
GRASP: A Goodness-of-Fit Test for Classification Learning
Sep 05, 2022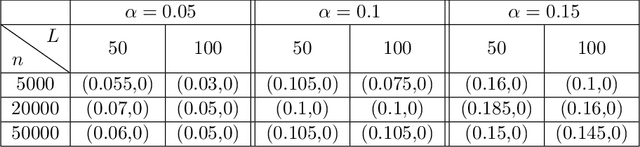
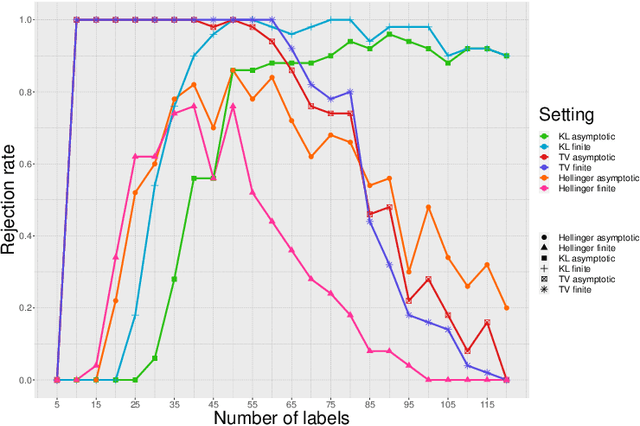
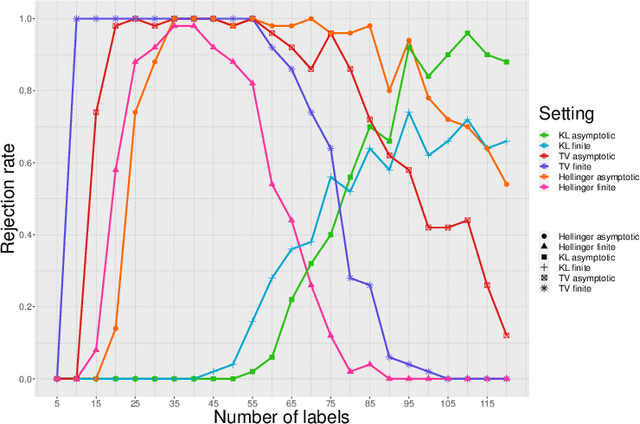
Performance of classifiers is often measured in terms of average accuracy on test data. Despite being a standard measure, average accuracy fails in characterizing the fit of the model to the underlying conditional law of labels given the features vector ($Y|X$), e.g. due to model misspecification, over fitting, and high-dimensionality. In this paper, we consider the fundamental problem of assessing the goodness-of-fit for a general binary classifier. Our framework does not make any parametric assumption on the conditional law $Y|X$, and treats that as a black box oracle model which can be accessed only through queries. We formulate the goodness-of-fit assessment problem as a tolerance hypothesis testing of the form \[ H_0: \mathbb{E}\Big[D_f\Big({\sf Bern}(\eta(X))\|{\sf Bern}(\hat{\eta}(X))\Big)\Big]\leq \tau\,, \] where $D_f$ represents an $f$-divergence function, and $\eta(x)$, $\hat{\eta}(x)$ respectively denote the true and an estimate likelihood for a feature vector $x$ admitting a positive label. We propose a novel test, called \grasp for testing $H_0$, which works in finite sample settings, no matter the features (distribution-free). We also propose model-X \grasp designed for model-X settings where the joint distribution of the features vector is known. Model-X \grasp uses this distributional information to achieve better power. We evaluate the performance of our tests through extensive numerical experiments.
Scaling Gaussian Processes with Derivative Information Using Variational Inference
Jul 08, 2021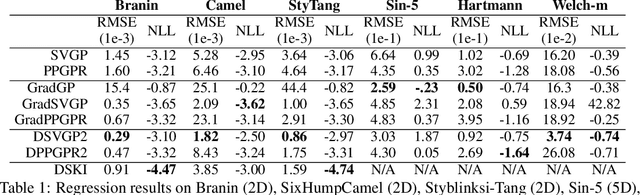
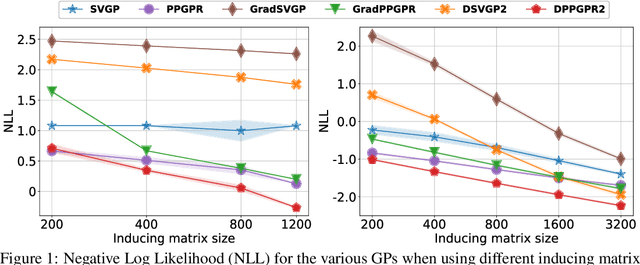

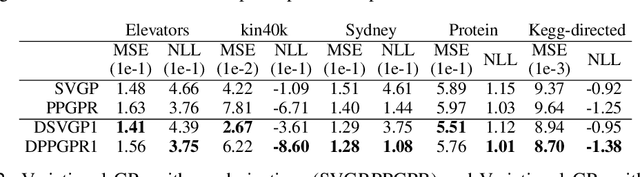
Gaussian processes with derivative information are useful in many settings where derivative information is available, including numerous Bayesian optimization and regression tasks that arise in the natural sciences. Incorporating derivative observations, however, comes with a dominating $O(N^3D^3)$ computational cost when training on $N$ points in $D$ input dimensions. This is intractable for even moderately sized problems. While recent work has addressed this intractability in the low-$D$ setting, the high-$N$, high-$D$ setting is still unexplored and of great value, particularly as machine learning problems increasingly become high dimensional. In this paper, we introduce methods to achieve fully scalable Gaussian process regression with derivatives using variational inference. Analogous to the use of inducing values to sparsify the labels of a training set, we introduce the concept of inducing directional derivatives to sparsify the partial derivative information of a training set. This enables us to construct a variational posterior that incorporates derivative information but whose size depends neither on the full dataset size $N$ nor the full dimensionality $D$. We demonstrate the full scalability of our approach on a variety of tasks, ranging from a high dimensional stellarator fusion regression task to training graph convolutional neural networks on Pubmed using Bayesian optimization. Surprisingly, we find that our approach can improve regression performance even in settings where only label data is available.
Graph Signal Processing for Heterogeneous Change Detection Part I: Vertex Domain Filtering
Aug 08, 2022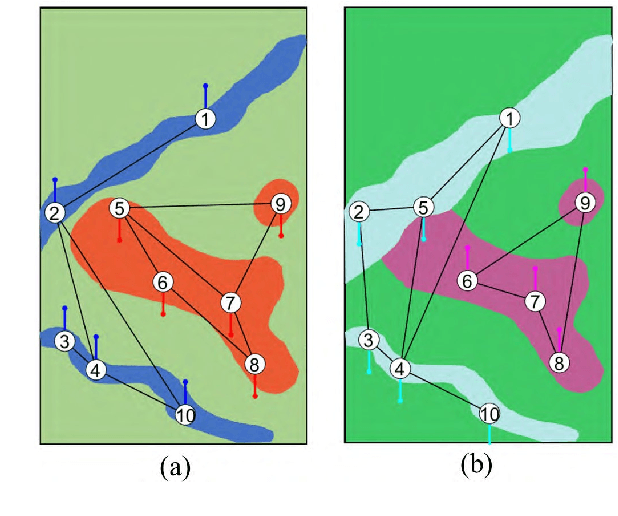
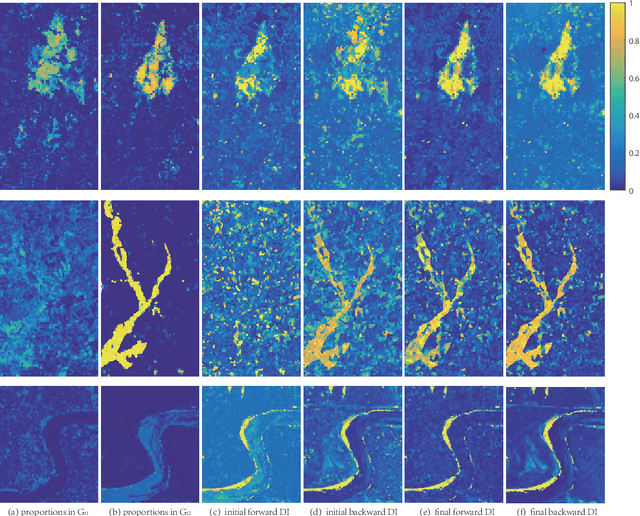
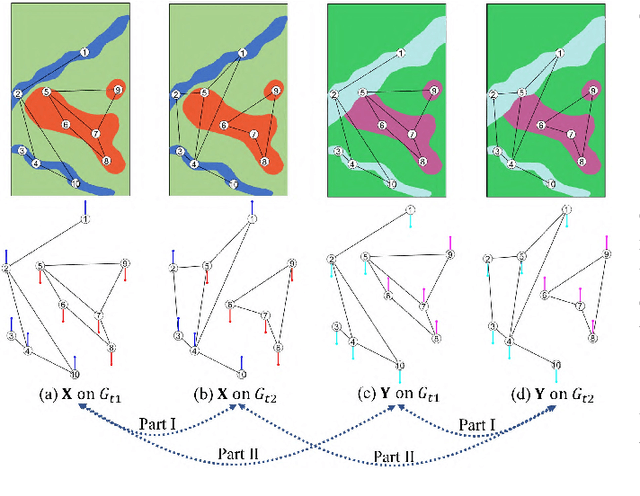
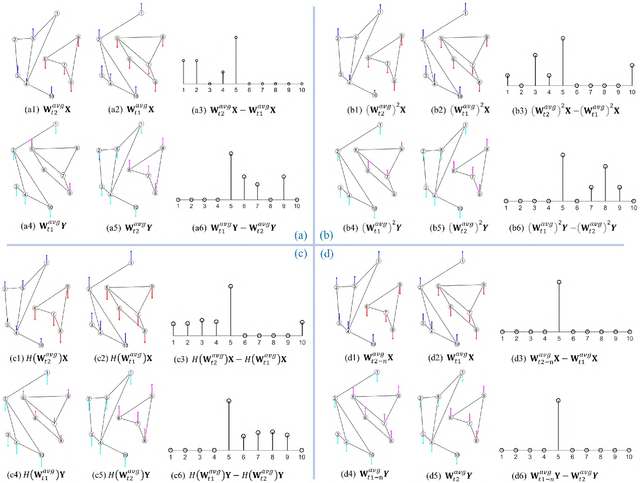
This paper provides a new strategy for the Heterogeneous Change Detection (HCD) problem: solving HCD from the perspective of Graph Signal Processing (GSP). We construct a graph for each image to capture the structure information, and treat each image as the graph signal. In this way, we convert the HCD into a GSP problem: a comparison of the responses of the two signals on different systems defined on the two graphs, which attempts to find structural differences (Part I) and signal differences (Part II) due to the changes between heterogeneous images. In this first part, we analyze the HCD with GSP from the vertex domain. We first show that for the unchanged images, their structures are consistent, and then the outputs of the same signal on systems defined on the two graphs are similar. However, once a region has changed, the local structure of the image changes, i.e., the connectivity of the vertex containing this region changes. Then, we can compare the output signals of the same input graph signal passing through filters defined on the two graphs to detect changes. We design different filters from the vertex domain, which can flexibly explore the high-order neighborhood information hidden in original graphs. We also analyze the detrimental effects of changing regions on the change detection results from the viewpoint of signal propagation. Experiments conducted on seven real data sets show the effectiveness of the vertex domain filtering based HCD method.
Anomaly Detection based on Compressed Data: an Information Theoretic Characterization
Oct 06, 2021
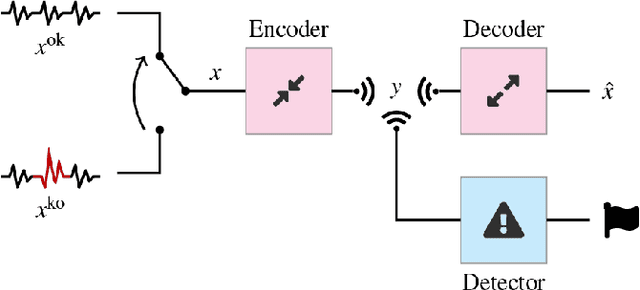
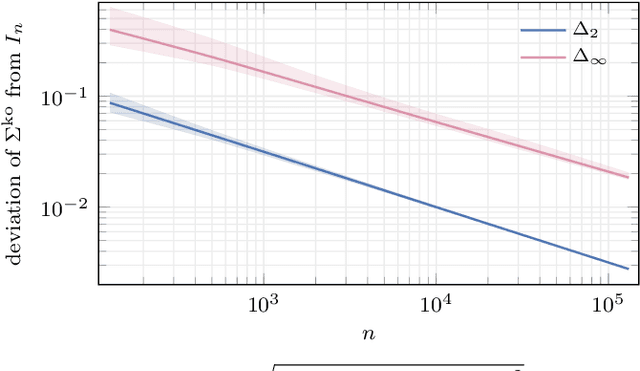
We analyze the effect of lossy compression in the processing of sensor signals that must be used to detect anomalous events in the system under observation. The intuitive relationship between the quality loss at higher compression and the possibility of telling anomalous behaviours from normal ones is formalized in terms of information-theoretic quantities. Some analytic derivations are made within the Gaussian framework and possibly in the asymptotic regime for what concerns the stretch of signals considered. Analytical conclusions are matched with the performance of practical detectors in a toy case allowing the assessment of different compression/detector configurations.
Mesh-based 3D Motion Tracking in Cardiac MRI using Deep Learning
Sep 05, 2022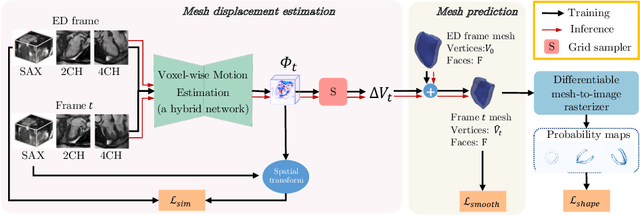
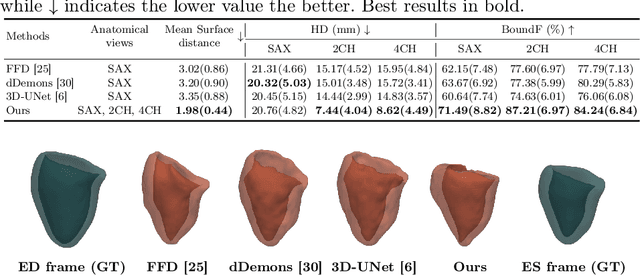
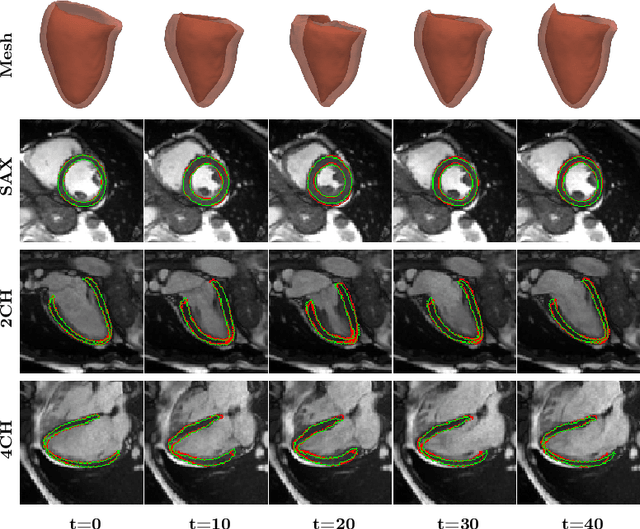

3D motion estimation from cine cardiac magnetic resonance (CMR) images is important for the assessment of cardiac function and diagnosis of cardiovascular diseases. Most of the previous methods focus on estimating pixel-/voxel-wise motion fields in the full image space, which ignore the fact that motion estimation is mainly relevant and useful within the object of interest, e.g., the heart. In this work, we model the heart as a 3D geometric mesh and propose a novel deep learning-based method that can estimate 3D motion of the heart mesh from 2D short- and long-axis CMR images. By developing a differentiable mesh-to-image rasterizer, the method is able to leverage the anatomical shape information from 2D multi-view CMR images for 3D motion estimation. The differentiability of the rasterizer enables us to train the method end-to-end. One advantage of the proposed method is that by tracking the motion of each vertex, it is able to keep the vertex correspondence of 3D meshes between time frames, which is important for quantitative assessment of the cardiac function on the mesh. We evaluate the proposed method on CMR images acquired from the UK Biobank study. Experimental results show that the proposed method quantitatively and qualitatively outperforms both conventional and learning-based cardiac motion tracking methods.
Probabilistically Resilient Multi-Robot Informative Path Planning
Jun 23, 2022
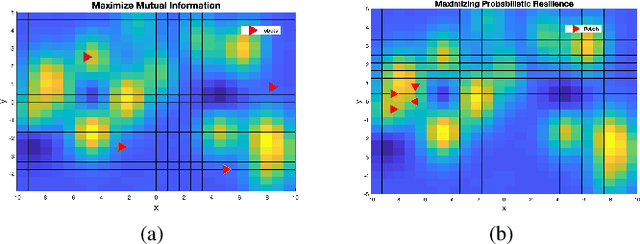
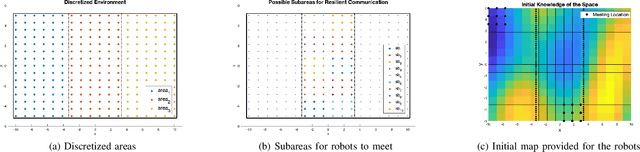
In this paper, we solve a multi-robot informative path planning (MIPP) task under the influence of uncertain communication and adversarial attackers. The goal is to create a multi-robot system that can learn and unify its knowledge of an unknown environment despite the presence of corrupted robots sharing malicious information. We use a Gaussian Process (GP) to model our unknown environment and define informativeness using the metric of mutual information. The objectives of our MIPP task is to maximize the amount of information collected by the team while maximizing the probability of resilience to attack. Unfortunately, these objectives are at odds especially when exploring large environments which necessitates disconnections between robots. As a result, we impose a probabilistic communication constraint that allows robots to meet intermittently and resiliently share information, and then act to maximize collected information during all other times. To solve our problem, we select meeting locations with the highest probability of resilience and use a sequential greedy algorithm to optimize paths for robots to explore. Finally, we show the validity of our results by comparing the learning ability of well-behaving robots applying resilient vs. non-resilient MIPP algorithms.
AV-Gaze: A Study on the Effectiveness of Audio Guided Visual Attention Estimation for Non-Profilic Faces
Jul 07, 2022
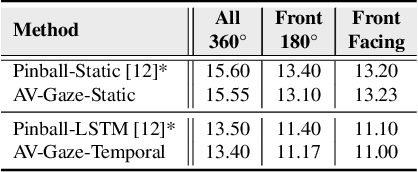
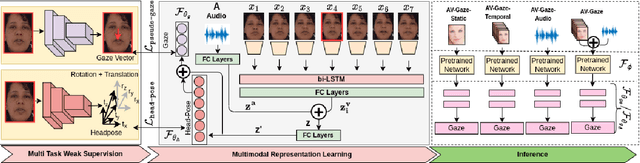
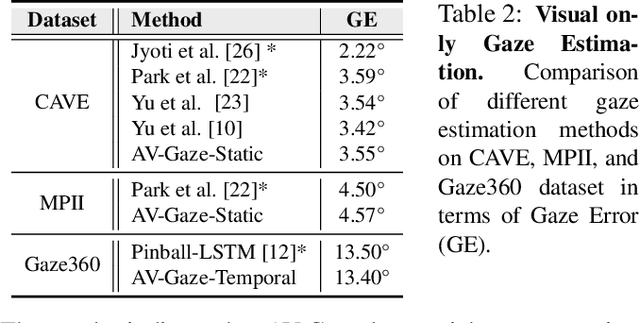
In challenging real-life conditions such as extreme head-pose, occlusions, and low-resolution images where the visual information fails to estimate visual attention/gaze direction, audio signals could provide important and complementary information. In this paper, we explore if audio-guided coarse head-pose can further enhance visual attention estimation performance for non-prolific faces. Since it is difficult to annotate audio signals for estimating the head-pose of the speaker, we use off-the-shelf state-of-the-art models to facilitate cross-modal weak-supervision. During the training phase, the framework learns complementary information from synchronized audio-visual modality. Our model can utilize any of the available modalities i.e. audio, visual or audio-visual for task-specific inference. It is interesting to note that, when AV-Gaze is tested on benchmark datasets with these specific modalities, it achieves competitive results on multiple datasets, while being highly adaptive towards challenging scenarios.
Task-agnostic Continual Hippocampus Segmentation for Smooth Population Shifts
Aug 05, 2022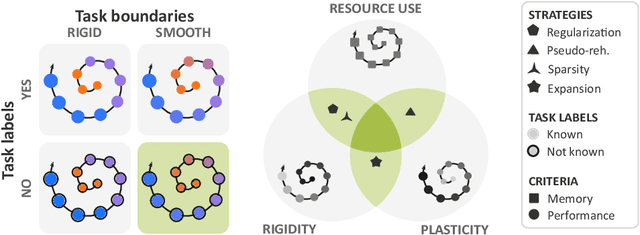
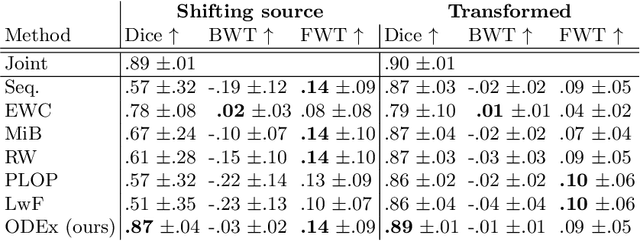


Most continual learning methods are validated in settings where task boundaries are clearly defined and task identity information is available during training and testing. We explore how such methods perform in a task-agnostic setting that more closely resembles dynamic clinical environments with gradual population shifts. We propose ODEx, a holistic solution that combines out-of-distribution detection with continual learning techniques. Validation on two scenarios of hippocampus segmentation shows that our proposed method reliably maintains performance on earlier tasks without losing plasticity.