 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Single Morphing Attack Detection using Feature Selection and Visualisation based on Mutual Information
Oct 26, 2021
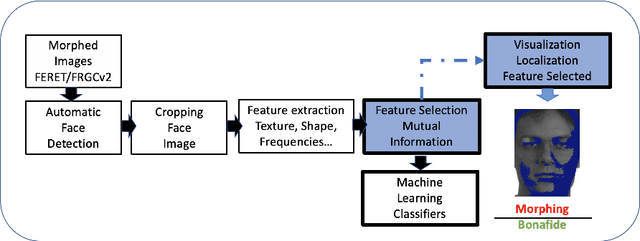
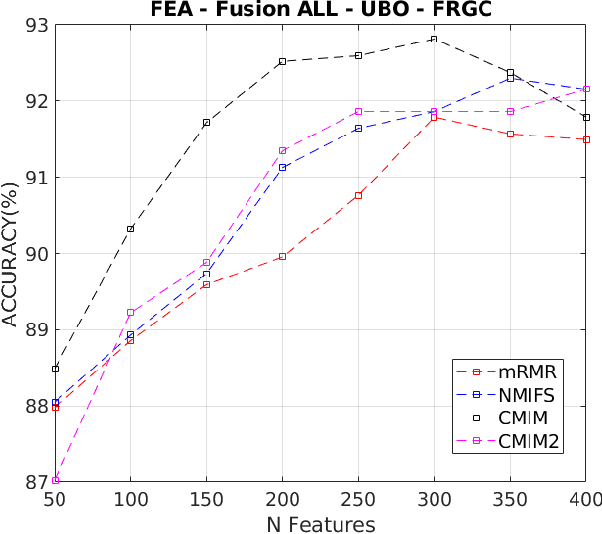
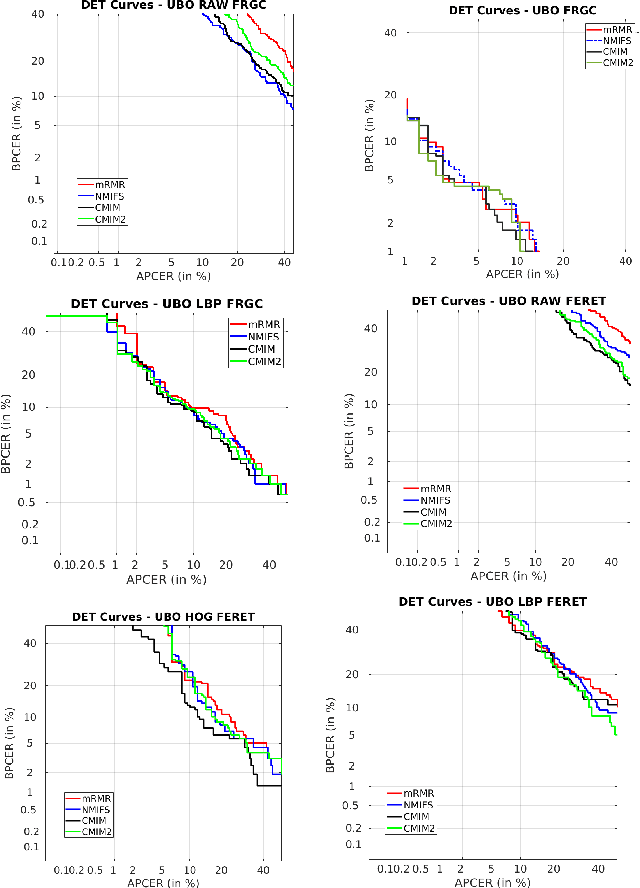
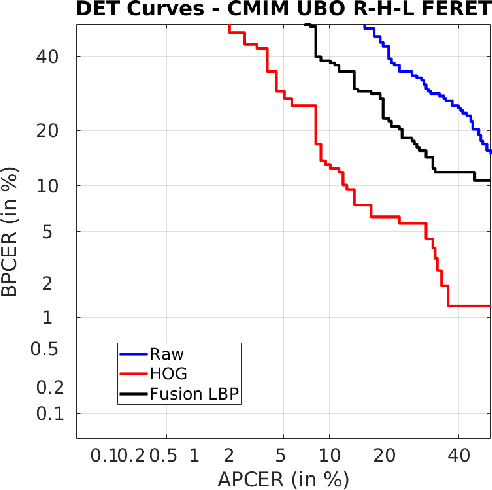
Face morphing attack detection is a challenging task. Automatic classification methods and manual inspection are realised in automatic border control gates to detect morphing attacks. Understanding how a machine learning system can detect morphed faces and the most relevant facial areas is crucial. Those relevant areas contain texture signals that allow us to separate the bona fide and the morph images. Also, it helps in the manual examination to detect a passport generated with morphed images. This paper explores features extracted from intensity, shape, texture, and proposes a feature selection stage based on the Mutual Information filter to select the most relevant and less redundant features. This selection allows us to reduce the workload and know the exact localisation of such areas to understand the morphing impact and create a robust classifier. The best results were obtained for the method based on Conditional Mutual Information and Shape features using only 500 features for FERET images and 800 features for FRGCv2 images from 1,048 features available. The eyes and nose are identified as the most critical areas to be analysed.
Uncertainty Quantification for Deep Unrolling-Based Computational Imaging
Jul 02, 2022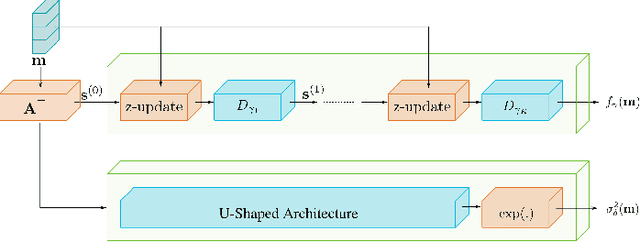
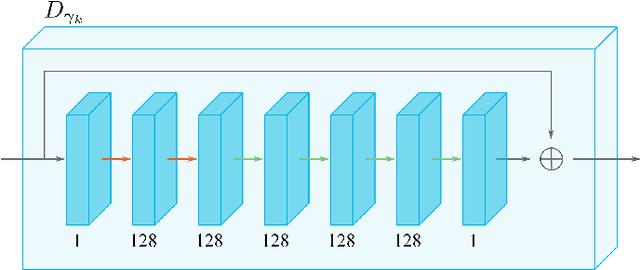

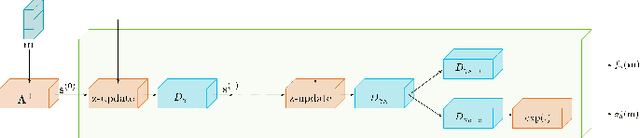
Deep unrolling is an emerging deep learning-based image reconstruction methodology that bridges the gap between model-based and purely deep learning-based image reconstruction methods. Although deep unrolling methods achieve state-of-the-art performance for imaging problems and allow the incorporation of the observation model into the reconstruction process, they do not provide any uncertainty information about the reconstructed image, which severely limits their use in practice, especially for safety-critical imaging applications. In this paper, we propose a learning-based image reconstruction framework that incorporates the observation model into the reconstruction task and that is capable of quantifying epistemic and aleatoric uncertainties, based on deep unrolling and Bayesian neural networks. We demonstrate the uncertainty characterization capability of the proposed framework on magnetic resonance imaging and computed tomography reconstruction problems. We investigate the characteristics of the epistemic and aleatoric uncertainty information provided by the proposed framework to motivate future research on utilizing uncertainty information to develop more accurate, robust, trustworthy, uncertainty-aware, learning-based image reconstruction and analysis methods for imaging problems. We show that the proposed framework can provide uncertainty information while achieving comparable reconstruction performance to state-of-the-art deep unrolling methods.
GLASS: Global to Local Attention for Scene-Text Spotting
Aug 05, 2022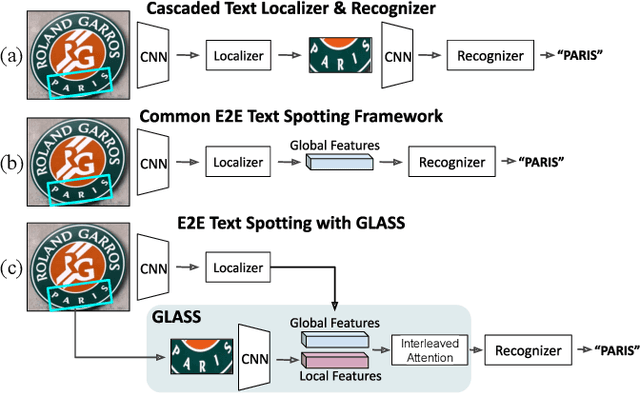
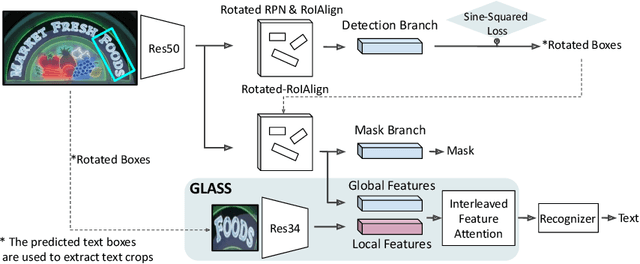
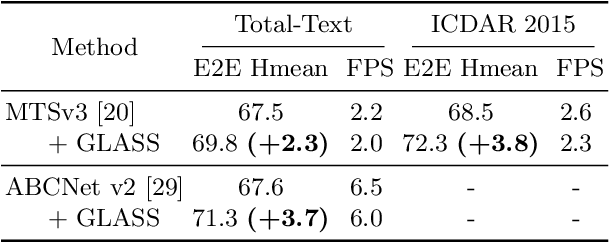
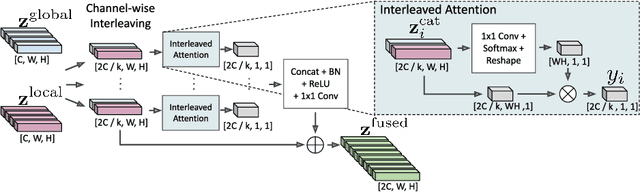
In recent years, the dominant paradigm for text spotting is to combine the tasks of text detection and recognition into a single end-to-end framework. Under this paradigm, both tasks are accomplished by operating over a shared global feature map extracted from the input image. Among the main challenges that end-to-end approaches face is the performance degradation when recognizing text across scale variations (smaller or larger text), and arbitrary word rotation angles. In this work, we address these challenges by proposing a novel global-to-local attention mechanism for text spotting, termed GLASS, that fuses together global and local features. The global features are extracted from the shared backbone, preserving contextual information from the entire image, while the local features are computed individually on resized, high-resolution rotated word crops. The information extracted from the local crops alleviates much of the inherent difficulties with scale and word rotation. We show a performance analysis across scales and angles, highlighting improvement over scale and angle extremities. In addition, we introduce an orientation-aware loss term supervising the detection task, and show its contribution to both detection and recognition performance across all angles. Finally, we show that GLASS is general by incorporating it into other leading text spotting architectures, improving their text spotting performance. Our method achieves state-of-the-art results on multiple benchmarks, including the newly released TextOCR.
SPACE-3: Unified Dialog Model Pre-training for Task-Oriented Dialog Understanding and Generation
Sep 14, 2022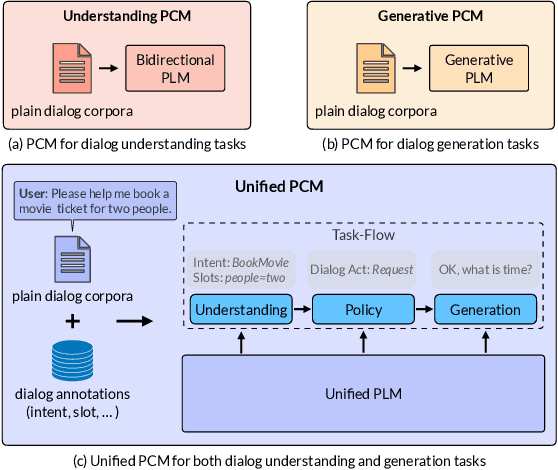
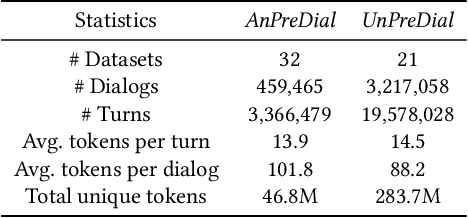
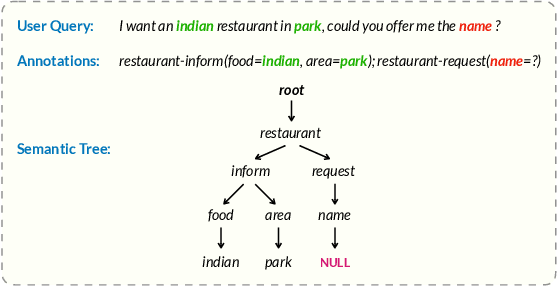

Recently, pre-training methods have shown remarkable success in task-oriented dialog (TOD) systems. However, most existing pre-trained models for TOD focus on either dialog understanding or dialog generation, but not both. In this paper, we propose SPACE-3, a novel unified semi-supervised pre-trained conversation model learning from large-scale dialog corpora with limited annotations, which can be effectively fine-tuned on a wide range of downstream dialog tasks. Specifically, SPACE-3 consists of four successive components in a single transformer to maintain a task-flow in TOD systems: (i) a dialog encoding module to encode dialog history, (ii) a dialog understanding module to extract semantic vectors from either user queries or system responses, (iii) a dialog policy module to generate a policy vector that contains high-level semantics of the response, and (iv) a dialog generation module to produce appropriate responses. We design a dedicated pre-training objective for each component. Concretely, we pre-train the dialog encoding module with span mask language modeling to learn contextualized dialog information. To capture the structured dialog semantics, we pre-train the dialog understanding module via a novel tree-induced semi-supervised contrastive learning objective with the help of extra dialog annotations. In addition, we pre-train the dialog policy module by minimizing the L2 distance between its output policy vector and the semantic vector of the response for policy optimization. Finally, the dialog generation model is pre-trained by language modeling. Results show that SPACE-3 achieves state-of-the-art performance on eight downstream dialog benchmarks, including intent prediction, dialog state tracking, and end-to-end dialog modeling. We also show that SPACE-3 has a stronger few-shot ability than existing models under the low-resource setting.
Time Series Clustering with an EM algorithm for Mixtures of Linear Gaussian State Space Models
Aug 25, 2022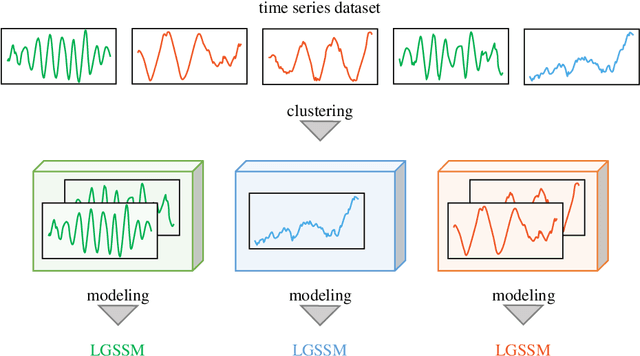
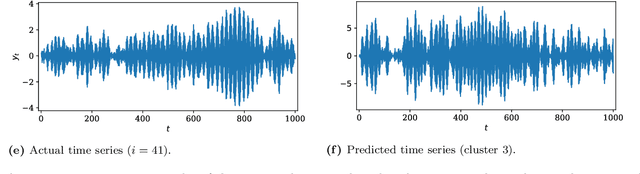
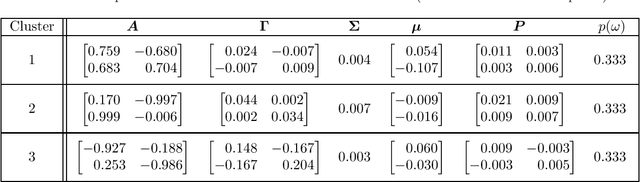
In this paper, we consider the task of clustering a set of individual time series while modeling each cluster, that is, model-based time series clustering. The task requires a parametric model with sufficient flexibility to describe the dynamics in various time series. To address this problem, we propose a novel model-based time series clustering method with mixtures of linear Gaussian state space models, which have high flexibility. The proposed method uses a new expectation-maximization algorithm for the mixture model to estimate the model parameters, and determines the number of clusters using the Bayesian information criterion. Experiments on a simulated dataset demonstrate the effectiveness of the method in clustering, parameter estimation, and model selection. The method is applied to a real dataset for which previously proposed time series clustering methods exhibited low accuracy. Results showed that our method produces more accurate clustering results than those obtained using the previous methods.
Semidefinite Programming for Community Detection with Side Information
May 06, 2021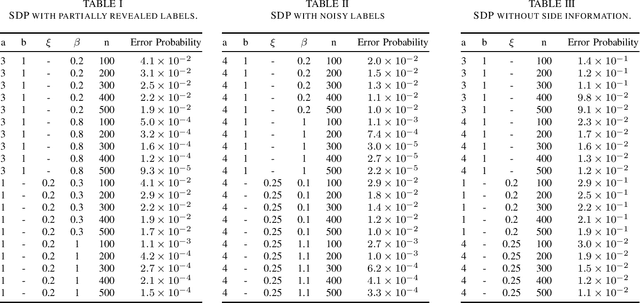
This paper produces an efficient Semidefinite Programming (SDP) solution for community detection that incorporates non-graph data, which in this context is known as side information. SDP is an efficient solution for standard community detection on graphs. We formulate a semi-definite relaxation for the maximum likelihood estimation of node labels, subject to observing both graph and non-graph data. This formulation is distinct from the SDP solution of standard community detection, but maintains its desirable properties. We calculate the exact recovery threshold for three types of non-graph information, which in this paper are called side information: partially revealed labels, noisy labels, as well as multiple observations (features) per node with arbitrary but finite cardinality. We find that SDP has the same exact recovery threshold in the presence of side information as maximum likelihood with side information. Thus, the methods developed herein are computationally efficient as well as asymptotically accurate for the solution of community detection in the presence of side information. Simulations show that the asymptotic results of this paper can also shed light on the performance of SDP for graphs of modest size.
Learning Robust Variational Information Bottleneck with Reference
Apr 29, 2021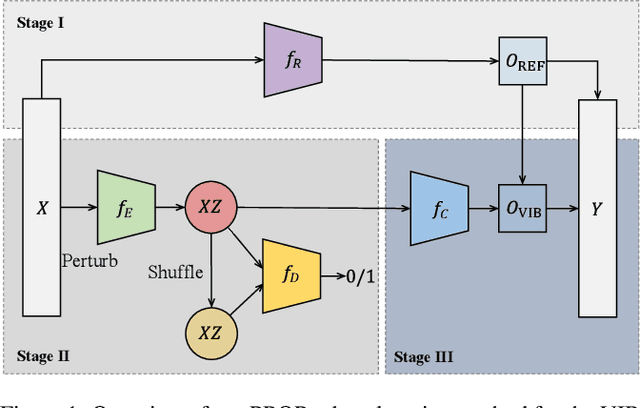
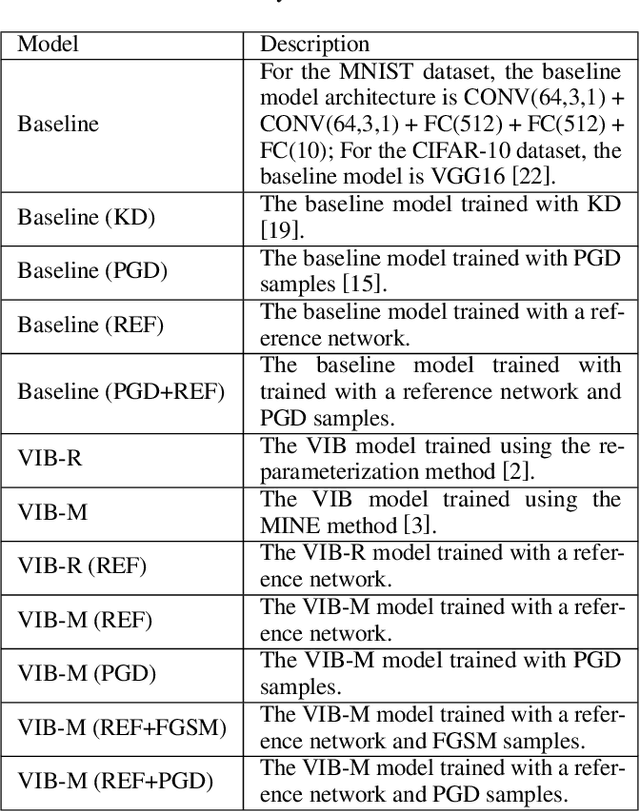

We propose a new approach to train a variational information bottleneck (VIB) that improves its robustness to adversarial perturbations. Unlike the traditional methods where the hard labels are usually used for the classification task, we refine the categorical class information in the training phase with soft labels which are obtained from a pre-trained reference neural network and can reflect the likelihood of the original class labels. We also relax the Gaussian posterior assumption in the VIB implementation by using the mutual information neural estimation. Extensive experiments have been performed with the MNIST and CIFAR-10 datasets, and the results show that our proposed approach significantly outperforms the benchmarked models.
A Practical & Unified Notation for Information-Theoretic Quantities in ML
Jun 22, 2021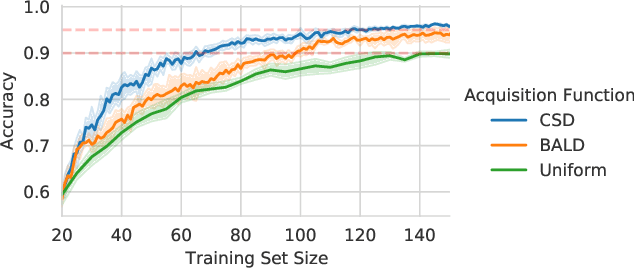

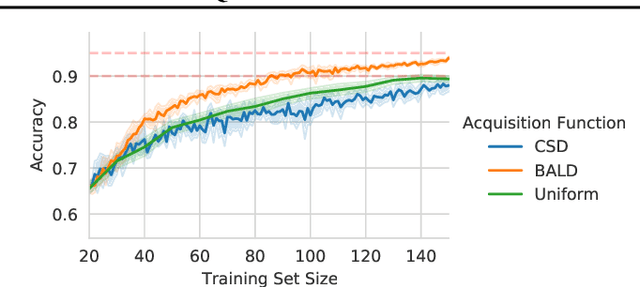
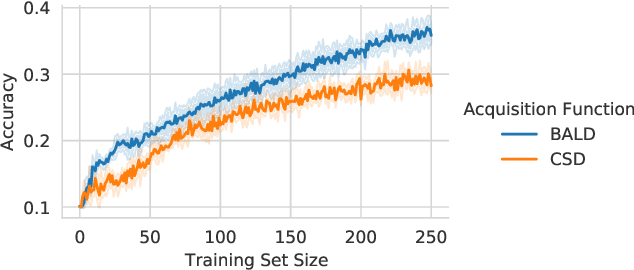
Information theory is of importance to machine learning, but the notation for information-theoretic quantities is sometimes opaque. The right notation can convey valuable intuitions and concisely express new ideas. We propose such a notation for machine learning users and expand it to include information-theoretic quantities between events (outcomes) and random variables. We apply this notation to a popular information-theoretic acquisition function in Bayesian active learning which selects the most informative (unlabelled) samples to be labelled by an expert. We demonstrate the value of our notation when extending the acquisition function to the core-set problem, which consists of selecting the most informative samples \emph{given} the labels.
INV-Flow2PoseNet: Light-Resistant Rigid Object Pose from Optical Flow of RGB-D Images using Images, Normals and Vertices
Sep 14, 2022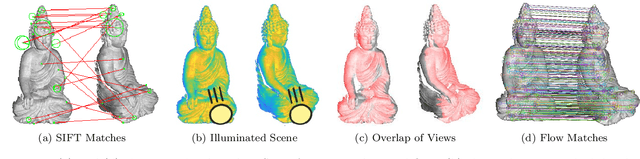
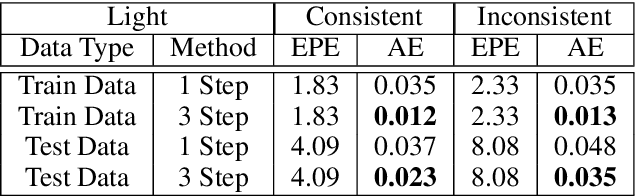

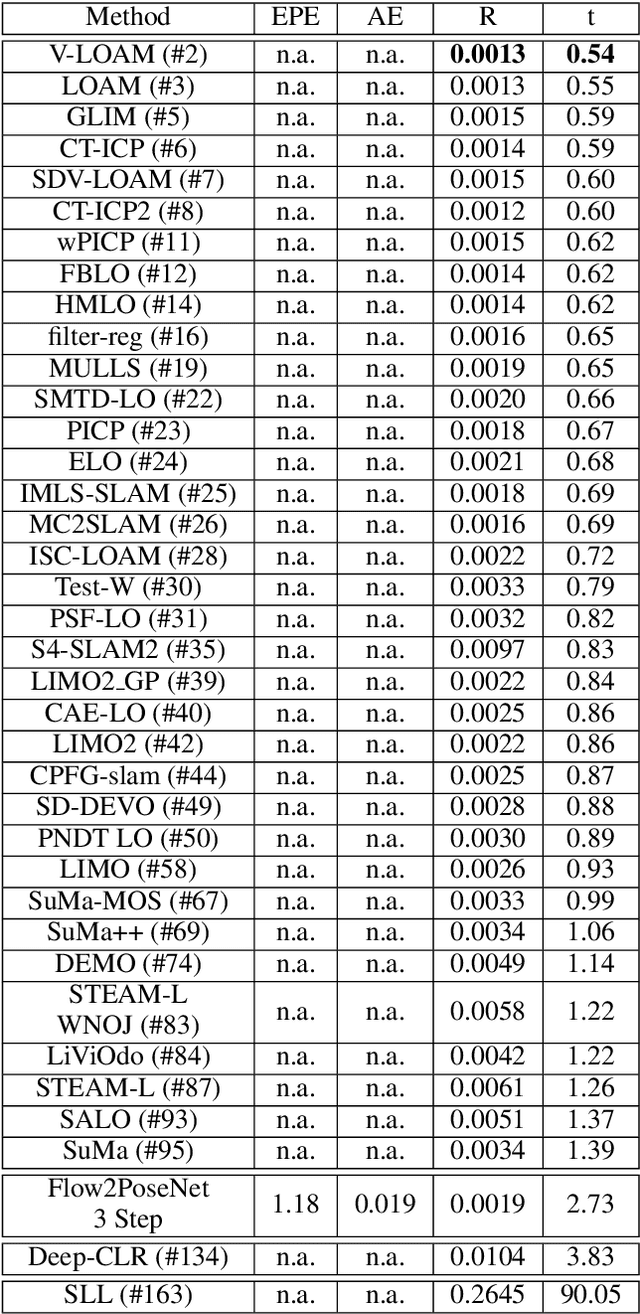
This paper presents a novel architecture for simultaneous estimation of highly accurate optical flows and rigid scene transformations for difficult scenarios where the brightness assumption is violated by strong shading changes. In the case of rotating objects or moving light sources, such as those encountered for driving cars in the dark, the scene appearance often changes significantly from one view to the next. Unfortunately, standard methods for calculating optical flows or poses are based on the expectation that the appearance of features in the scene remain constant between views. These methods may fail frequently in the investigated cases. The presented method fuses texture and geometry information by combining image, vertex and normal data to compute an illumination-invariant optical flow. By using a coarse-to-fine strategy, globally anchored optical flows are learned, reducing the impact of erroneous shading-based pseudo-correspondences. Based on the learned optical flows, a second architecture is proposed that predicts robust rigid transformations from the warped vertex and normal maps. Particular attention is payed to situations with strong rotations, which often cause such shading changes. Therefore a 3-step procedure is proposed that profitably exploits correlations between the normals and vertices. The method has been evaluated on a newly created dataset containing both synthetic and real data with strong rotations and shading effects. This data represents the typical use case in 3D reconstruction, where the object often rotates in large steps between the partial reconstructions. Additionally, we apply the method to the well-known Kitti Odometry dataset. Even if, due to fulfillment of the brighness assumption, this is not the typical use case of the method, the applicability to standard situations and the relation to other methods is therefore established.
Scaling Gaussian Processes with Derivative Information Using Variational Inference
Jul 08, 2021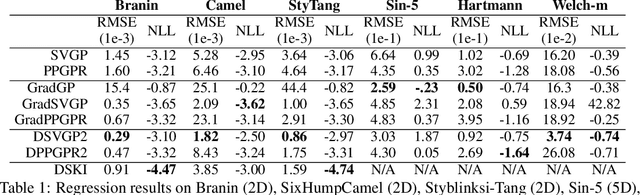
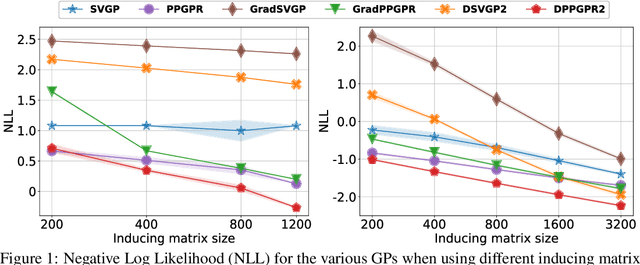

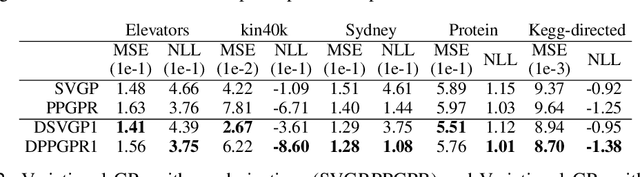
Gaussian processes with derivative information are useful in many settings where derivative information is available, including numerous Bayesian optimization and regression tasks that arise in the natural sciences. Incorporating derivative observations, however, comes with a dominating $O(N^3D^3)$ computational cost when training on $N$ points in $D$ input dimensions. This is intractable for even moderately sized problems. While recent work has addressed this intractability in the low-$D$ setting, the high-$N$, high-$D$ setting is still unexplored and of great value, particularly as machine learning problems increasingly become high dimensional. In this paper, we introduce methods to achieve fully scalable Gaussian process regression with derivatives using variational inference. Analogous to the use of inducing values to sparsify the labels of a training set, we introduce the concept of inducing directional derivatives to sparsify the partial derivative information of a training set. This enables us to construct a variational posterior that incorporates derivative information but whose size depends neither on the full dataset size $N$ nor the full dimensionality $D$. We demonstrate the full scalability of our approach on a variety of tasks, ranging from a high dimensional stellarator fusion regression task to training graph convolutional neural networks on Pubmed using Bayesian optimization. Surprisingly, we find that our approach can improve regression performance even in settings where only label data is available.