 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
From Time Series to Networks in R with the ts2net Package
Aug 20, 2022
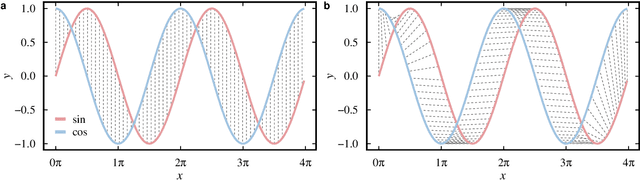
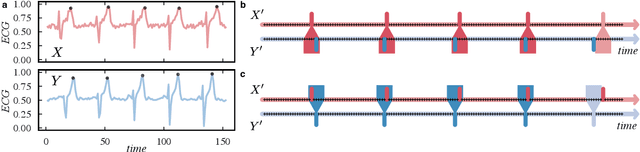
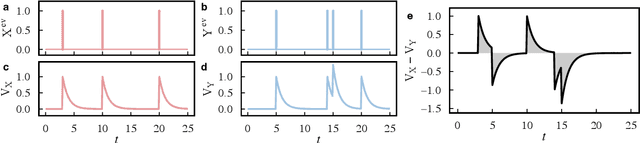
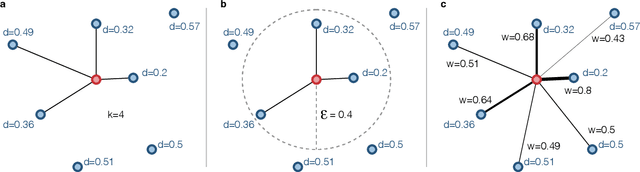
Network science established itself as a prominent tool for modeling time series and complex systems. This modeling process consists of transforming a set or a single time series into a network. Nodes may represent complete time series, segments, or single values, while links define associations or similarities between the represented parts. R is one of the main programming languages used in data science, statistics, and machine learning, with many packages available. However, no single package provides the necessary methods to transform time series into networks. This paper presents ts2net, an R package for modeling one or multiple time series into networks. The package provides the time series distance functions that can be easily computed in parallel and in supercomputers to process larger data sets and methods to transform distance matrices into networks. Ts2net also provides methods to transform a single time series into a network, such as recurrence networks, visibility graphs, and transition networks. Together with other packages, ts2net permits using network science and graph mining tools to extract information from time series.
A Data-driven Latent Semantic Analysis for Automatic Text Summarization using LDA Topic Modelling
Aug 02, 2022

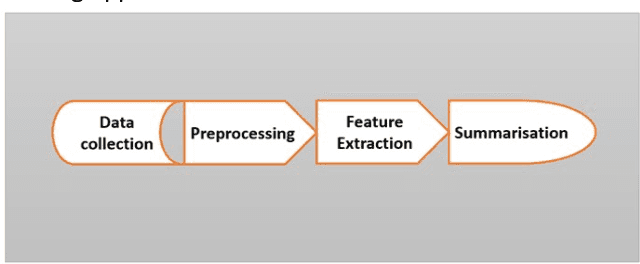

With the advent and popularity of big data mining and huge text analysis in modern times, automated text summarization became prominent for extracting and retrieving important information from documents. This research investigates aspects of automatic text summarization from the perspectives of single and multiple documents. Summarization is a task of condensing huge text articles into short, summarized versions. The text is reduced in size for summarization purpose but preserving key vital information and retaining the meaning of the original document. This study presents the Latent Dirichlet Allocation (LDA) approach used to perform topic modelling from summarised medical science journal articles with topics related to genes and diseases. In this study, PyLDAvis web-based interactive visualization tool was used to visualise the selected topics. The visualisation provides an overarching view of the main topics while allowing and attributing deep meaning to the prevalence individual topic. This study presents a novel approach to summarization of single and multiple documents. The results suggest the terms ranked purely by considering their probability of the topic prevalence within the processed document using extractive summarization technique. PyLDAvis visualization describes the flexibility of exploring the terms of the topics' association to the fitted LDA model. The topic modelling result shows prevalence within topics 1 and 2. This association reveals that there is similarity between the terms in topic 1 and 2 in this study. The efficacy of the LDA and the extractive summarization methods were measured using Latent Semantic Analysis (LSA) and Recall-Oriented Understudy for Gisting Evaluation (ROUGE) metrics to evaluate the reliability and validity of the model.
Abstract Interpretation for Generalized Heuristic Search in Model-Based Planning
Aug 05, 2022
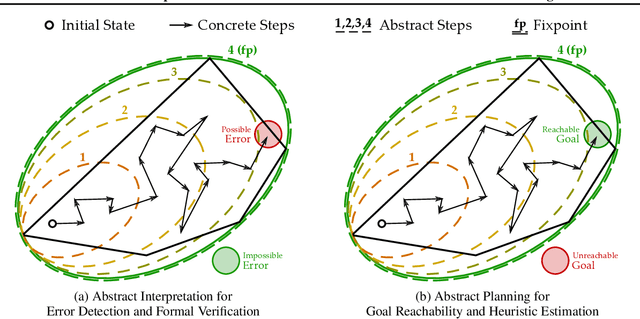
Domain-general model-based planners often derive their generality by constructing search heuristics through the relaxation or abstraction of symbolic world models. We illustrate how abstract interpretation can serve as a unifying framework for these abstraction-based heuristics, extending the reach of heuristic search to richer world models that make use of more complex datatypes and functions (e.g. sets, geometry), and even models with uncertainty and probabilistic effects. These heuristics can also be integrated with learning, allowing agents to jumpstart planning in novel world models via abstraction-derived information that is later refined by experience. This suggests that abstract interpretation can play a key role in building universal reasoning systems.
Data-free Dense Depth Distillation
Aug 26, 2022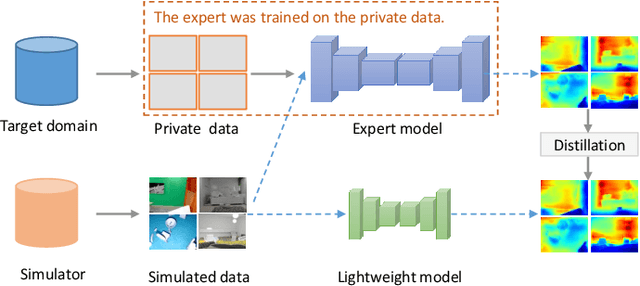
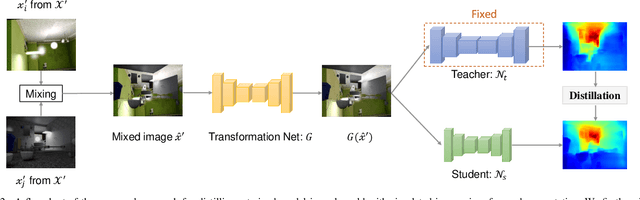

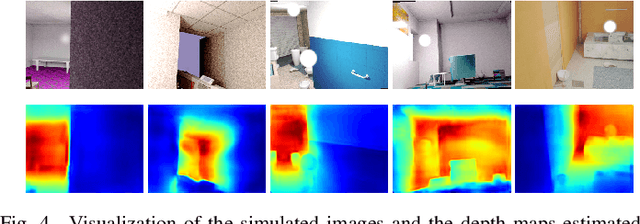
We study data-free knowledge distillation (KD) for monocular depth estimation (MDE), which learns a lightweight network for real-world depth perception by compressing from a trained expert model under the teacher-student framework while lacking training data in the target domain. Owing to the essential difference between dense regression and image recognition, previous methods of data-free KD are not applicable to MDE. To strengthen the applicability in the real world, in this paper, we seek to apply KD with out-of-distribution simulated images. The major challenges are i) lacking prior information about object distribution of the original training data; ii) the domain shift between the real world and the simulation. To cope with the first difficulty, we apply object-wise image mixing to generate new training samples for maximally covering distributed patterns of objects in the target domain. To tackle the second difficulty, we propose to utilize a transformation network that efficiently learns to fit the simulated data to the feature distribution of the teacher model. We evaluate the proposed approach for various depth estimation models and two different datasets. As a result, our method outperforms the baseline KD by a good margin and even achieves slightly better performance with as few as $1/6$ images, demonstrating a clear superiority.
EViT: Privacy-Preserving Image Retrieval via Encrypted Vision Transformer in Cloud Computing
Aug 31, 2022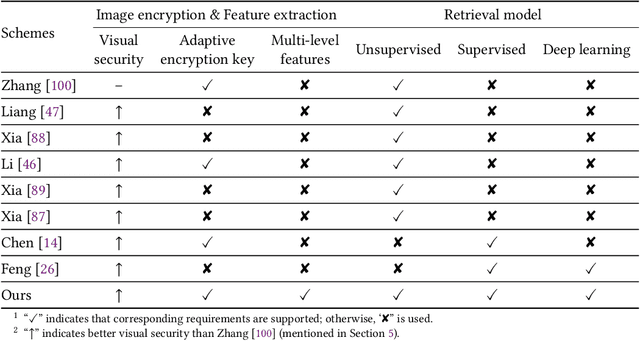
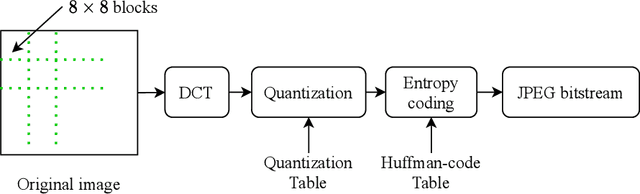
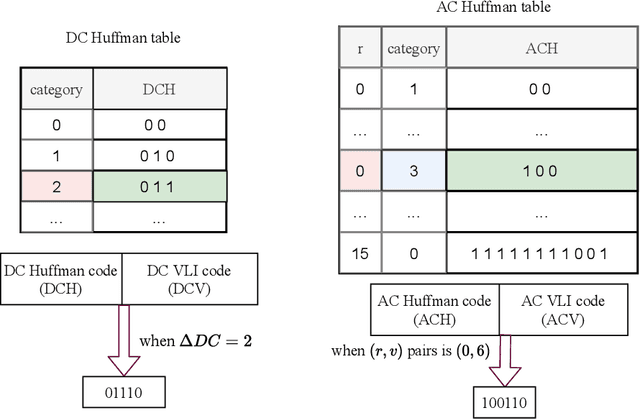
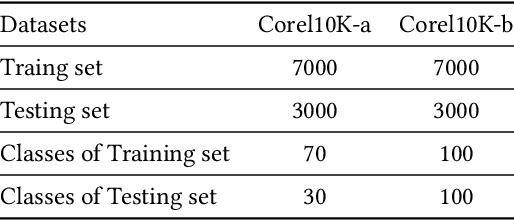
Image retrieval systems help users to browse and search among extensive images in real-time. With the rise of cloud computing, retrieval tasks are usually outsourced to cloud servers. However, the cloud scenario brings a daunting challenge of privacy protection as cloud servers cannot be fully trusted. To this end, image-encryption-based privacy-preserving image retrieval schemes have been developed, which first extract features from cipher-images, and then build retrieval models based on these features. Yet, most existing approaches extract shallow features and design trivial retrieval models, resulting in insufficient expressiveness for the cipher-images. In this paper, we propose a novel paradigm named Encrypted Vision Transformer (EViT), which advances the discriminative representations capability of cipher-images. First, in order to capture comprehensive ruled information, we extract multi-level local length sequence and global Huffman-code frequency features from the cipher-images which are encrypted by stream cipher during JPEG compression process. Second, we design the Vision Transformer-based retrieval model to couple with the multi-level features, and propose two adaptive data augmentation methods to improve representation power of the retrieval model. Our proposal can be easily adapted to unsupervised and supervised settings via self-supervised contrastive learning manner. Extensive experiments reveal that EViT achieves both excellent encryption and retrieval performance, outperforming current schemes in terms of retrieval accuracy by large margins while protecting image privacy effectively. Code is publicly available at \url{https://github.com/onlinehuazai/EViT}.
Towards Two-view 6D Object Pose Estimation: A Comparative Study on Fusion Strategy
Jul 01, 2022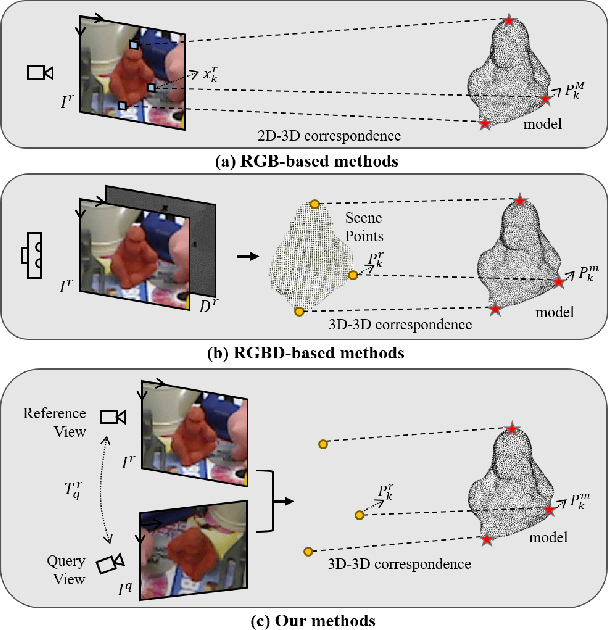
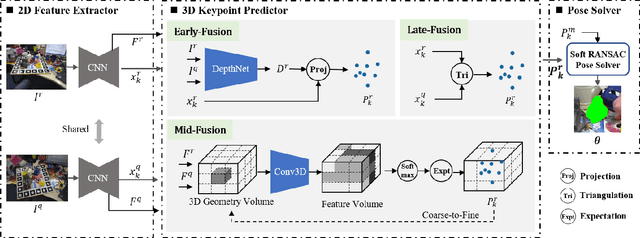

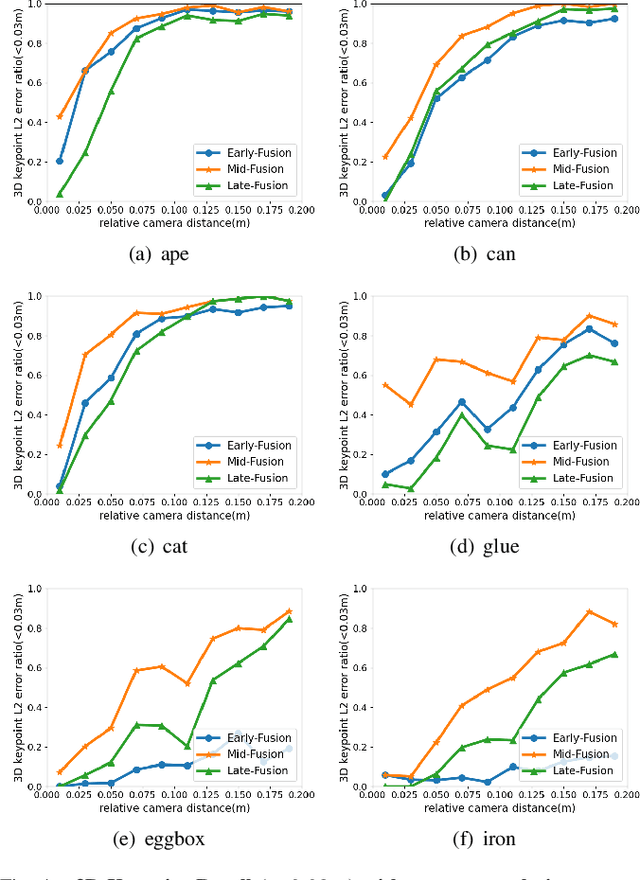
Current RGB-based 6D object pose estimation methods have achieved noticeable performance on datasets and real world applications. However, predicting 6D pose from single 2D image features is susceptible to disturbance from changing of environment and textureless or resemblant object surfaces. Hence, RGB-based methods generally achieve less competitive results than RGBD-based methods, which deploy both image features and 3D structure features. To narrow down this performance gap, this paper proposes a framework for 6D object pose estimation that learns implicit 3D information from 2 RGB images. Combining the learned 3D information and 2D image features, we establish more stable correspondence between the scene and the object models. To seek for the methods best utilizing 3D information from RGB inputs, we conduct an investigation on three different approaches, including Early- Fusion, Mid-Fusion, and Late-Fusion. We ascertain the Mid- Fusion approach is the best approach to restore the most precise 3D keypoints useful for object pose estimation. The experiments show that our method outperforms state-of-the-art RGB-based methods, and achieves comparable results with RGBD-based methods.
Joint optimal beamforming and power control in cell-free massive MIMO
Aug 02, 2022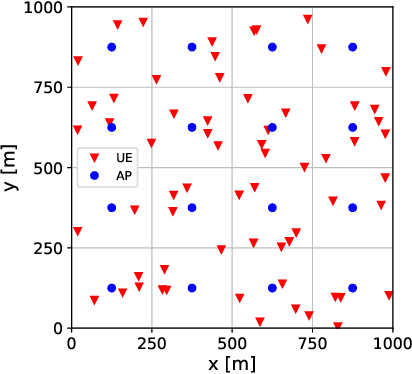
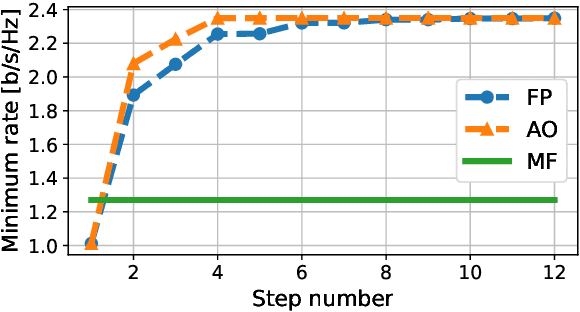
We derive a fast and optimal algorithm for solving practical weighted max-min SINR problems in cell-free massive MIMO networks. For the first time, the optimization problem jointly covers long-term power control and distributed beamforming design under imperfect cooperation. In particular, we consider user-centric clusters of access points cooperating on the basis of possibly limited channel state information sharing. Our optimal algorithm merges powerful power control tools based on interference calculus with the recently developed team theoretic framework for distributed beamforming design. In addition, we propose a variation that shows faster convergence in practice.
Computational valency lexica and Homeric formularity
Aug 23, 2022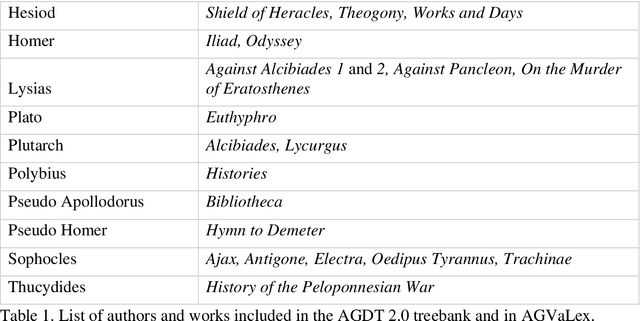

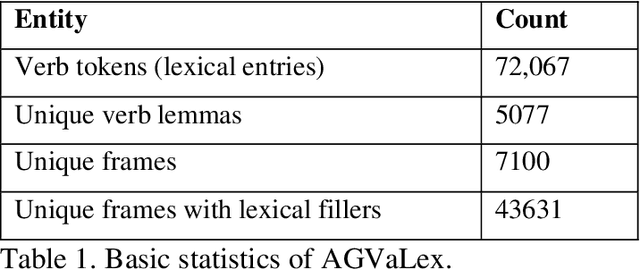
Distributional semantics, the quantitative study of meaning variation and change through corpus collocations, is currently one of the most productive research areas in computational linguistics. The wider availability of big data and of reproducible algorithms for analysis has boosted its application to living languages in recent years. But can we use distributional semantics to study a language with such a limited corpus as ancient Greek? And can this approach tell us something about such vexed questions in classical studies as the language and composition of the Homeric poems? Our paper will compare the semantic flexibility of formulae involving transitive verbs in archaic Greek epic to similar verb phrases in a non-formulaic corpus, in order to detect unique patterns of variation in formulae. To address this, we present AGVaLex, a computational valency lexicon for ancient Greek automatically extracted from the Ancient Greek Dependency Treebank. The lexicon contains quantitative corpus-driven morphological, syntactic and lexical information about verbs and their arguments, such as objects, subjects, and prepositional phrases, and has a wide range of applications for the study of the language of ancient Greek authors.
IRL with Partial Observations using the Principle of Uncertain Maximum Entropy
Aug 15, 2022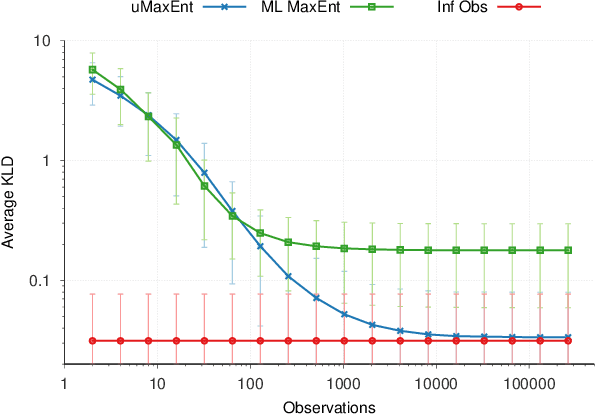
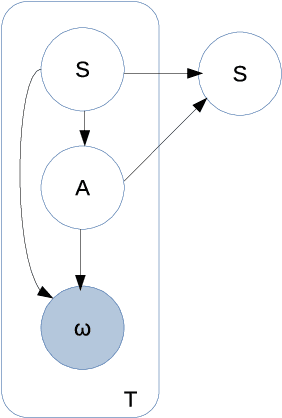
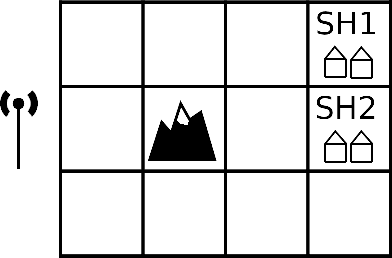
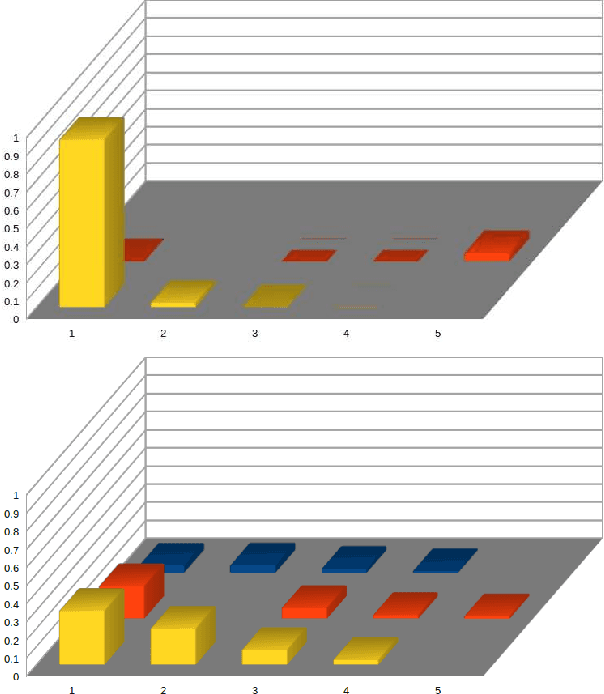
The principle of maximum entropy is a broadly applicable technique for computing a distribution with the least amount of information possible while constrained to match empirically estimated feature expectations. However, in many real-world applications that use noisy sensors computing the feature expectations may be challenging due to partial observation of the relevant model variables. For example, a robot performing apprenticeship learning may lose sight of the agent it is learning from due to environmental occlusion. We show that in generalizing the principle of maximum entropy to these types of scenarios we unavoidably introduce a dependency on the learned model to the empirical feature expectations. We introduce the principle of uncertain maximum entropy and present an expectation-maximization based solution generalized from the principle of latent maximum entropy. Finally, we experimentally demonstrate the improved robustness to noisy data offered by our technique in a maximum causal entropy inverse reinforcement learning domain.
Delay Estimation for Ranging and Localization Using Multiband Channel State Information
Nov 20, 2021



In wireless networks, an essential step for precise range-based localization is the high-resolution estimation of multipath channel delays. The resolution of traditional delay estimation algorithms is inversely proportional to the bandwidth of the training signals used for channel probing. Considering that typical training signals have limited bandwidth, delay estimation using these algorithms often leads to poor localization performance. To mitigate these constraints, we exploit the multiband and carrier frequency switching capabilities of wireless transceivers and propose to acquire channel state information (CSI) in multiple bands spread over a large frequency aperture. The data model of the acquired measurements has a multiple shift-invariance structure, and we use this property to develop a high-resolution delay estimation algorithm. We derive the Cram\'er-Rao Bound (CRB) for the data model and perform numerical simulations of the algorithm using system parameters of the emerging IEEE 802.11be standard. Simulations show that the algorithm is asymptotically efficient and converges to the CRB. To validate modeling assumptions, we test the algorithm using channel measurements acquired in real indoor scenarios. From these results, it is seen that delays (ranges) estimated from multiband CSI with a total bandwidth of 320 MHz show an average RMSE of less than 0.3 ns (10 cm) in 90% of the cases.
* 16 pages, 17 figures, 2 tables, journal