 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Micro-Vibration Modes Reconstruction Based on Micro-Doppler Coincidence Imaging
Aug 30, 2022




Micro-vibration, a ubiquitous nature phenomenon, can be seen as a characteristic feature on the objects, these vibrations always have tiny amplitudes which are much less than the wavelengths of the sensing systems, thus these motions information can only be reflected in the phase item of echo. Normally the conventional radar system can detect these micro vibrations through the time frequency analyzing, but these vibration characteristics can only be reflected by time-frequency spectrum, the spatial distribution of these micro vibrations can not be reconstructed precisely. Ghost imaging (GI), a novel imaging method also known as Coincidence Imaging that originated in the quantum and optical fields, can reconstruct unknown images using computational methods. To reconstruct the spatial distribution of micro vibrations, this paper proposes a new method based on a coincidence imaging system. A detailed model of target micro-vibration is created first, taking into account two categories: discrete and continuous targets. We use the first-order field correlation feature to obtain objective different micro vibration distribution based on the complex target models and time-frequency analysis in this work.
CD and PMD Effect on Cyclostationarity-Based Timing Recovery for Optical Coherent Receivers
Aug 30, 2022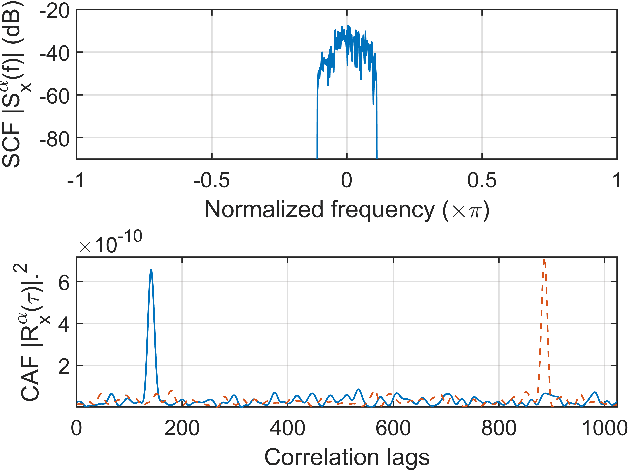

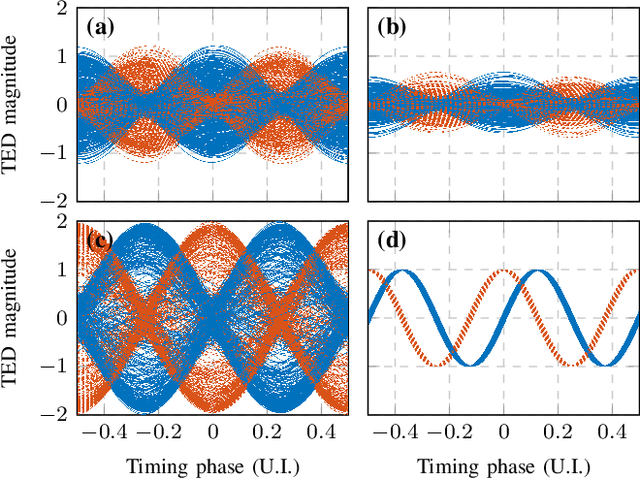
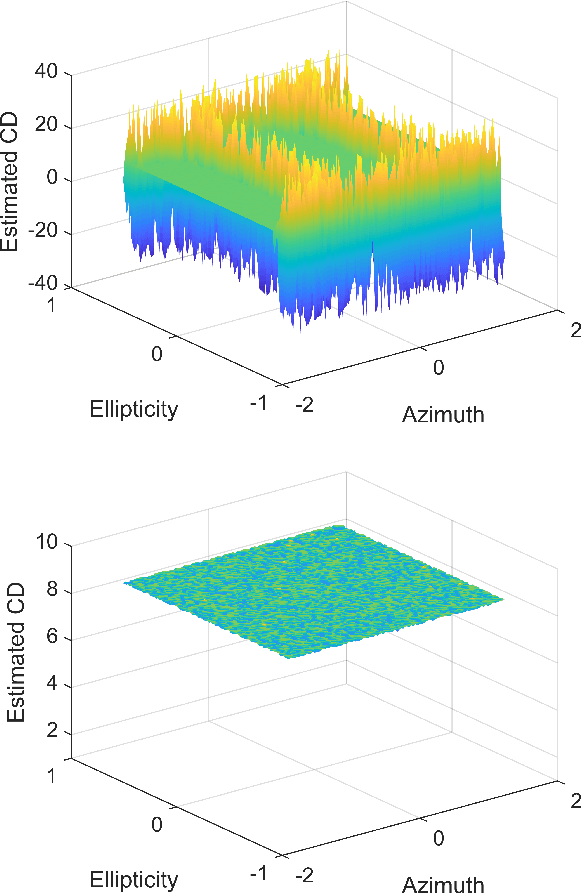
Timing recovery is critical for synchronizing the clocks at the transmitting and receiving ends of a digital coherent communication system. The core of timing recovery is to determine reliably the current sampling error of the local digitizer so that the timing circuit may lock to a stable operation point. Conventional timing phase detectors need to adapt to the optical fiber channel so that the common effects of this channel, such as chromatic dispersion (CD) and polarization mode dispersion (PMD), on the timing phase extraction must be understood. Here we exploit the cyclostationarity of the optical signal and derive a model for studying the CD and PMD effect. We prove that the CD-adjusted cyclic correlation matrix contains full information about timing and PMD, and the determinant of the matrix is a timing phase detector immune to both CD and PMD. We also obtain other results such as a completely PMD-independent CD estimator, etc. Our analysis is supported by both simulations and experiments over a field implemented optical cable.
Learning a General Clause-to-Clause Relationships for Enhancing Emotion-Cause Pair Extraction
Aug 30, 2022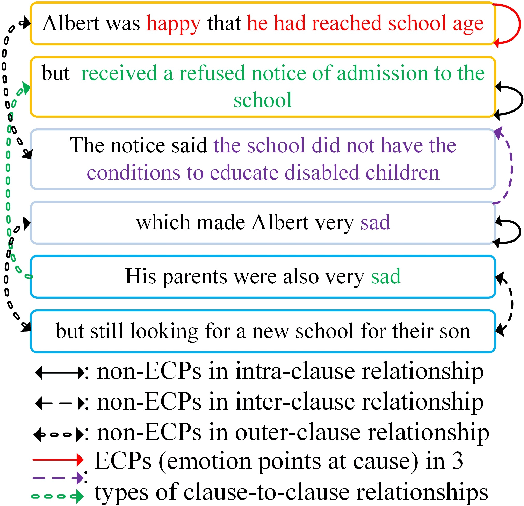
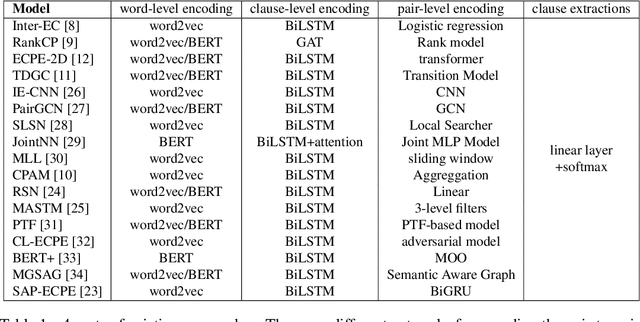
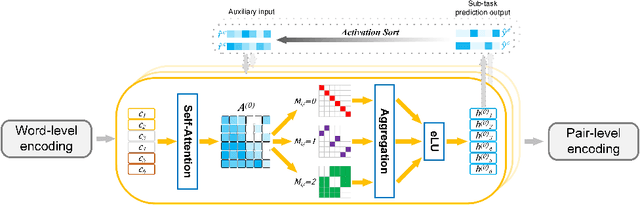
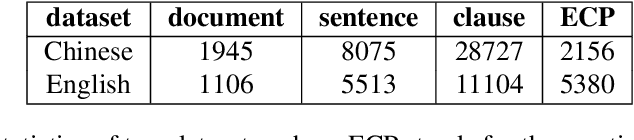
Emotion-cause pair extraction (ECPE) is an emerging task aiming to extract potential pairs of emotions and corresponding causes from documents. Previous approaches have focused on modeling the pair-to-pair relationship and achieved promising results. However, the clause-to-clause relationship, which fundamentally symbolizes the underlying structure of a document, has still been in its research infancy. In this paper, we define a novel clause-to-clause relationship. To learn it applicably, we propose a general clause-level encoding model named EA-GAT comprising E-GAT and Activation Sort. E-GAT is designed to aggregate information from different types of clauses; Activation Sort leverages the individual emotion/cause prediction and the sort-based mapping to propel the clause to a more favorable representation. Since EA-GAT is a clause-level encoding model, it can be broadly integrated with any previous approach. Experimental results show that our approach has a significant advantage over all current approaches on the Chinese and English benchmark corpus, with an average of $2.1\%$ and $1.03\%$.
Exploring Wasserstein Distance across Concept Embeddings for Ontology Matching
Jul 22, 2022



Measuring the distance between ontological elements is a fundamental component for any matching solutions. String-based distance metrics relying on discrete symbol operations are notorious for shallow syntactic matching. In this study, we explore Wasserstein distance metric across ontology concept embeddings. Wasserstein distance metric targets continuous space that can incorporate linguistic, structural, and logical information. In our exploratory study, we use a pre-trained word embeddings system, fasttext, to embed ontology element labels. We examine the effectiveness of Wasserstein distance for measuring similarity between (blocks of) ontolgoies, discovering matchings between individual elements, and refining matchings incorporating contextual information. Our experiments with the OAEI conference track and MSE benchmarks achieve competitive results compared to the leading systems such as AML and LogMap. Results indicate a promising trajectory for the application of optimal transport and Wasserstein distance to improve embedding-based unsupervised ontology matchings.
Back from the future: bidirectional CTC decoding using future information in speech recognition
Oct 07, 2021

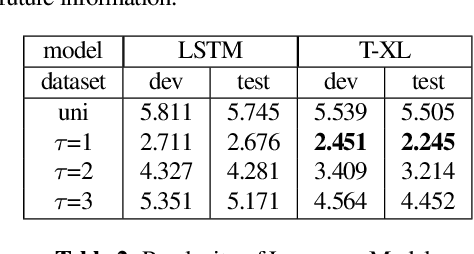
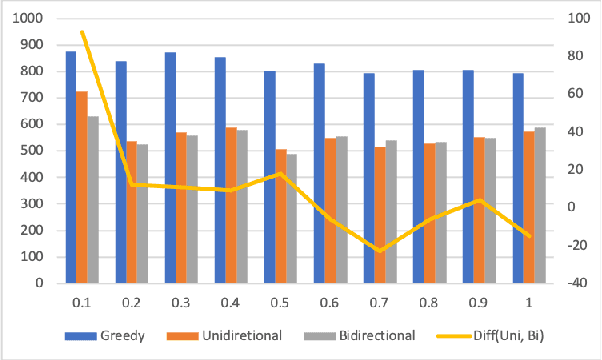
In this paper, we propose a simple but effective method to decode the output of Connectionist Temporal Classifier (CTC) model using a bi-directional neural language model. The bidirectional language model uses the future as well as the past information in order to predict the next output in the sequence. The proposed method based on bi-directional beam search takes advantage of the CTC greedy decoding output to represent the noisy future information. Experiments on the Librispeechdataset demonstrate the superiority of our proposed method compared to baselines using unidirectional decoding. In particular, the boost inaccuracy is most apparent at the start of a sequence which is the most erroneous part for existing systems based on unidirectional decoding.
Knowing Where and What: Unified Word Block Pretraining for Document Understanding
Jul 29, 2022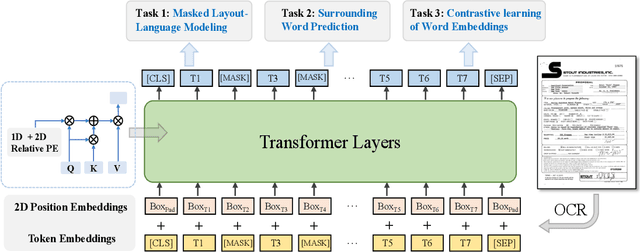
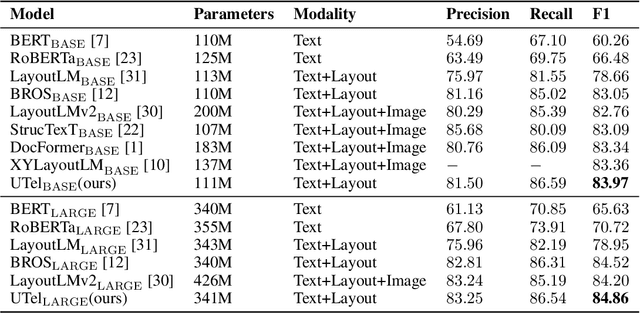
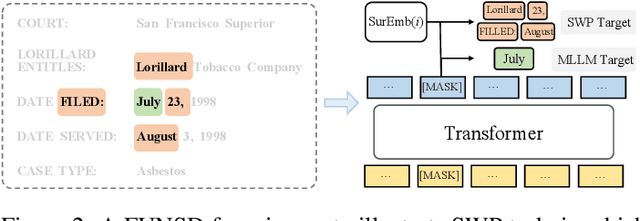

Due to the complex layouts of documents, it is challenging to extract information for documents. Most previous studies develop multimodal pre-trained models in a self-supervised way. In this paper, we focus on the embedding learning of word blocks containing text and layout information, and propose UTel, a language model with Unified TExt and Layout pre-training. Specifically, we propose two pre-training tasks: Surrounding Word Prediction (SWP) for the layout learning, and Contrastive learning of Word Embeddings (CWE) for identifying different word blocks. Moreover, we replace the commonly used 1D position embedding with a 1D clipped relative position embedding. In this way, the joint training of Masked Layout-Language Modeling (MLLM) and two newly proposed tasks enables the interaction between semantic and spatial features in a unified way. Additionally, the proposed UTel can process arbitrary-length sequences by removing the 1D position embedding, while maintaining competitive performance. Extensive experimental results show UTel learns better joint representations and achieves superior performance than previous methods on various downstream tasks, though requiring no image modality. Code is available at \url{https://github.com/taosong2019/UTel}.
Label-Efficient Domain Generalization via Collaborative Exploration and Generalization
Aug 07, 2022
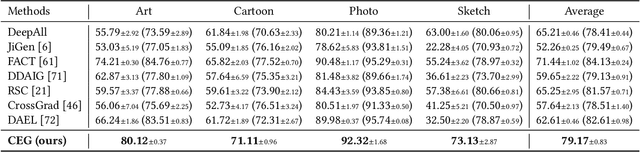
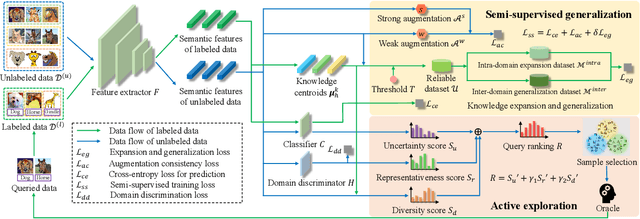

Considerable progress has been made in domain generalization (DG) which aims to learn a generalizable model from multiple well-annotated source domains to unknown target domains. However, it can be prohibitively expensive to obtain sufficient annotation for source datasets in many real scenarios. To escape from the dilemma between domain generalization and annotation costs, in this paper, we introduce a novel task named label-efficient domain generalization (LEDG) to enable model generalization with label-limited source domains. To address this challenging task, we propose a novel framework called Collaborative Exploration and Generalization (CEG) which jointly optimizes active exploration and semi-supervised generalization. Specifically, in active exploration, to explore class and domain discriminability while avoiding information divergence and redundancy, we query the labels of the samples with the highest overall ranking of class uncertainty, domain representativeness, and information diversity. In semi-supervised generalization, we design MixUp-based intra- and inter-domain knowledge augmentation to expand domain knowledge and generalize domain invariance. We unify active exploration and semi-supervised generalization in a collaborative way and promote mutual enhancement between them, boosting model generalization with limited annotation. Extensive experiments show that CEG yields superior generalization performance. In particular, CEG can even use only 5% data annotation budget to achieve competitive results compared to the previous DG methods with fully labeled data on PACS dataset.
BiFuse++: Self-supervised and Efficient Bi-projection Fusion for 360 Depth Estimation
Sep 07, 2022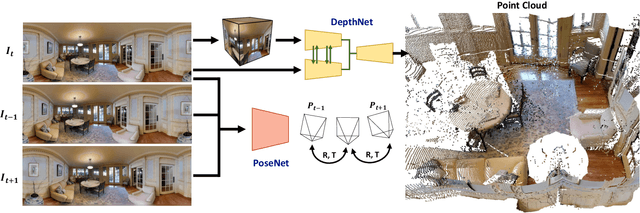
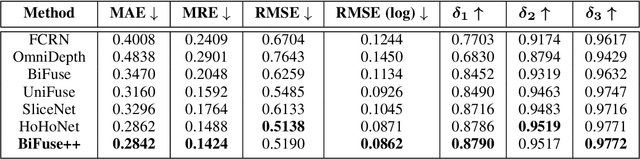

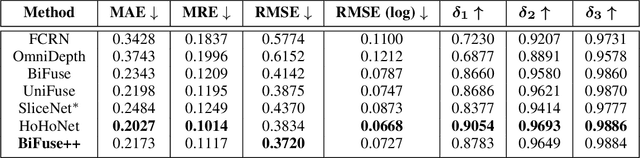
Due to the rise of spherical cameras, monocular 360 depth estimation becomes an important technique for many applications (e.g., autonomous systems). Thus, state-of-the-art frameworks for monocular 360 depth estimation such as bi-projection fusion in BiFuse are proposed. To train such a framework, a large number of panoramas along with the corresponding depth ground truths captured by laser sensors are required, which highly increases the cost of data collection. Moreover, since such a data collection procedure is time-consuming, the scalability of extending these methods to different scenes becomes a challenge. To this end, self-training a network for monocular depth estimation from 360 videos is one way to alleviate this issue. However, there are no existing frameworks that incorporate bi-projection fusion into the self-training scheme, which highly limits the self-supervised performance since bi-projection fusion can leverage information from different projection types. In this paper, we propose BiFuse++ to explore the combination of bi-projection fusion and the self-training scenario. To be specific, we propose a new fusion module and Contrast-Aware Photometric Loss to improve the performance of BiFuse and increase the stability of self-training on real-world videos. We conduct both supervised and self-supervised experiments on benchmark datasets and achieve state-of-the-art performance.
Layer-refined Graph Convolutional Networks for Recommendation
Jul 22, 2022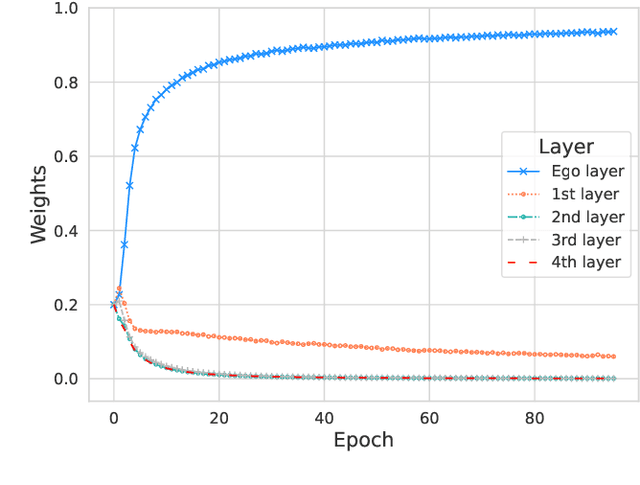
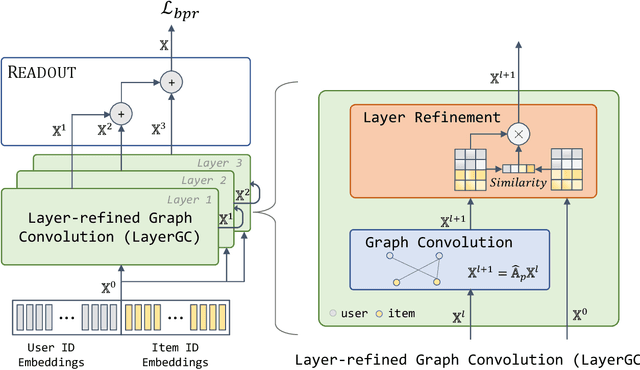
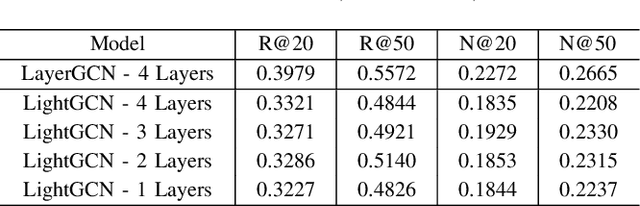
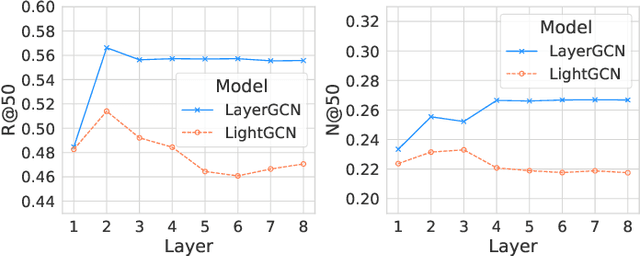
Recommendation models utilizing Graph Convolutional Networks (GCNs) have achieved state-of-the-art performance, as they can integrate both the node information and the topological structure of the user-item interaction graph. However, these GCN-based recommendation models not only suffer from over-smoothing when stacking too many layers but also bear performance degeneration resulting from the existence of noise in user-item interactions. In this paper, we first identify a recommendation dilemma of over-smoothing and solution collapsing in current GCN-based models. Specifically, these models usually aggregate all layer embeddings for node updating and achieve their best recommendation performance within a few layers because of over-smoothing. Conversely, if we place learnable weights on layer embeddings for node updating, the weight space will always collapse to a fixed point, at which the weighting of the ego layer almost holds all. We propose a layer-refined GCN model, dubbed LayerGCN, that refines layer representations during information propagation and node updating of GCN. Moreover, previous GCN-based recommendation models aggregate all incoming information from neighbors without distinguishing the noise nodes, which deteriorates the recommendation performance. Our model further prunes the edges of the user-item interaction graph following a degree-sensitive probability instead of the uniform distribution. Experimental results show that the proposed model outperforms the state-of-the-art models significantly on four public datasets with fast training convergence. The implementation code of the proposed method is available at https://github.com/enoche/ImRec.
MHNF: Multi-hop Heterogeneous Neighborhood information Fusion graph representation learning
Jun 17, 2021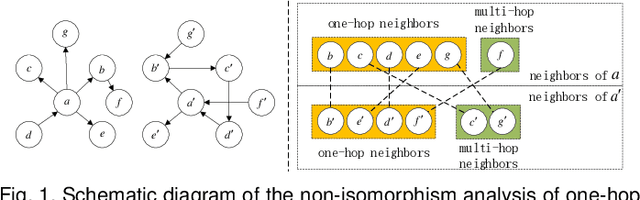

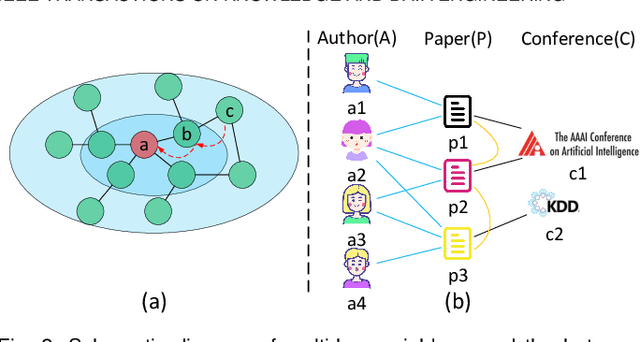
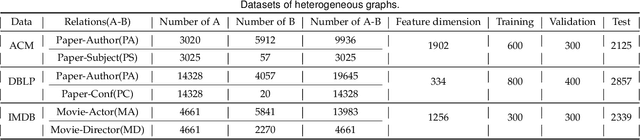
Attention mechanism enables the Graph Neural Networks(GNNs) to learn the attention weights between the target node and its one-hop neighbors, the performance is further improved. However, the most existing GNNs are oriented to homogeneous graphs and each layer can only aggregate the information of one-hop neighbors. Stacking multi-layer networks will introduce a lot of noise and easily lead to over smoothing. We propose a Multi-hop Heterogeneous Neighborhood information Fusion graph representation learning method (MHNF). Specifically, we first propose a hybrid metapath autonomous extraction model to efficiently extract multi-hop hybrid neighbors. Then, we propose a hop-level heterogeneous Information aggregation model, which selectively aggregates different-hop neighborhood information within the same hybrid metapath. Finally, a hierarchical semantic attention fusion model (HSAF) is proposed, which can efficiently integrate different-hop and different-path neighborhood information respectively. This paper can solve the problem of aggregating the multi-hop neighborhood information and can learn hybrid metapaths for target task, reducing the limitation of manually specifying metapaths. In addition, HSAF can extract the internal node information of the metapaths and better integrate the semantic information of different levels. Experimental results on real datasets show that MHNF is superior to state-of-the-art methods in node classification and clustering tasks (10.94% - 69.09% and 11.58% - 394.93% relative improvement on average, respectively).