 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DPTNet: A Dual-Path Transformer Architecture for Scene Text Detection
Aug 21, 2022

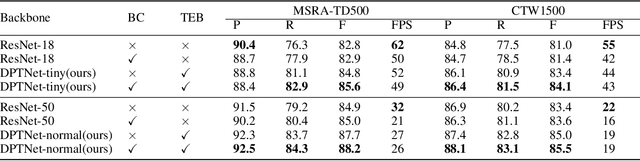
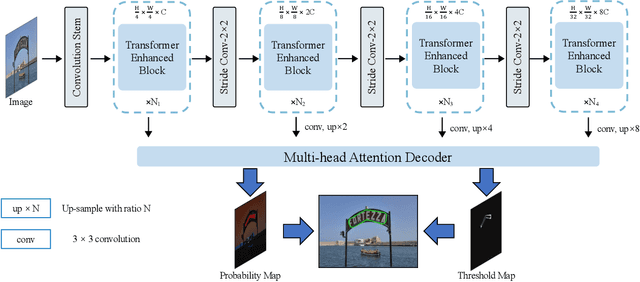
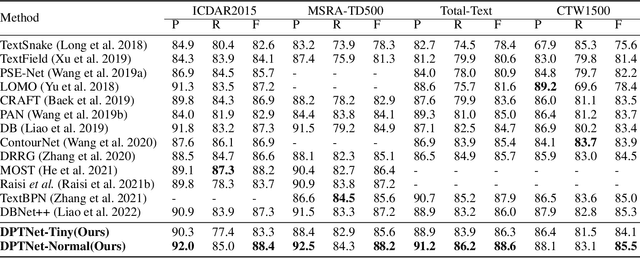
The prosperity of deep learning contributes to the rapid progress in scene text detection. Among all the methods with convolutional networks, segmentation-based ones have drawn extensive attention due to their superiority in detecting text instances of arbitrary shapes and extreme aspect ratios. However, the bottom-up methods are limited to the performance of their segmentation models. In this paper, we propose DPTNet (Dual-Path Transformer Network), a simple yet effective architecture to model the global and local information for the scene text detection task. We further propose a parallel design that integrates the convolutional network with a powerful self-attention mechanism to provide complementary clues between the attention path and convolutional path. Moreover, a bi-directional interaction module across the two paths is developed to provide complementary clues in the channel and spatial dimensions. We also upgrade the concentration operation by adding an extra multi-head attention layer to it. Our DPTNet achieves state-of-the-art results on the MSRA-TD500 dataset, and provides competitive results on other standard benchmarks in terms of both detection accuracy and speed.
WHITE PAPER: Protecting GNSS Against Intentional Interference
Aug 24, 2022
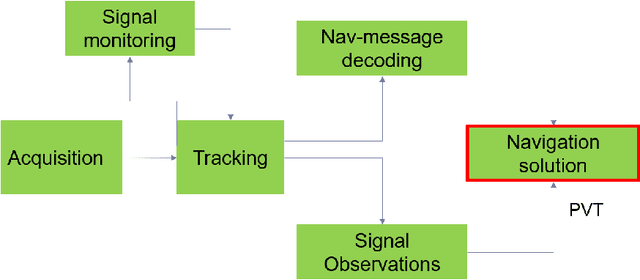
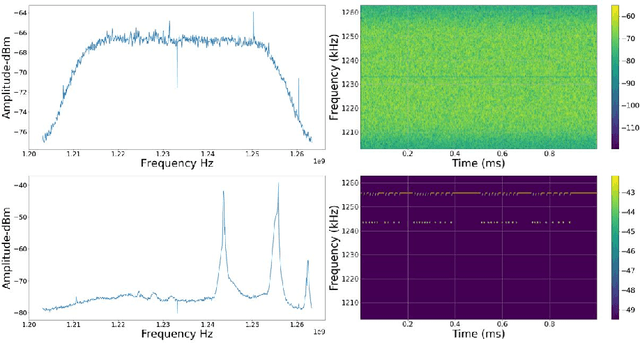

The vulnerabilities associated with modern systems relying on Global Navigation Satellite Systems (GNSS) due to intentional and unintentional interference is an increasing threat. Since radio frequency interference (RFI) significantly degrades the performance of a GNSS receiver. Several traditional critical applications such as aviation, maritime and rail transport systems to more recent applications such as autonomous vehicles, can be severely affected by such undetected nor mitigated RFIs. Moreover, critical infrastructures such as power supply and money transfer, are becoming more and more dependent on the accurate timing information provided by GNSS. Thus, interference detection and management techniques are crucial to be utilised in order to reduce interference effects. This paper offers a state-of-the-art review of several proposed methods for interference detection and mitigation with solutions ranging from traditional to machine learning-based approaches. In addition, to be able to characterise the RFI threats and develop mitigation techniques, it is essential to monitor RFI systematically and share recorded data with interested entities. Therefore, three GNSS threat monitoring systems are briefly described. This White paper is a compilation of the seminar presentations given at a seminar on "Protecting GNSS against intentional interference" in March 2022 in Finland.
The SZ flux-mass ($Y$-$M$) relation at low halo masses: improvements with symbolic regression and strong constraints on baryonic feedback
Sep 05, 2022
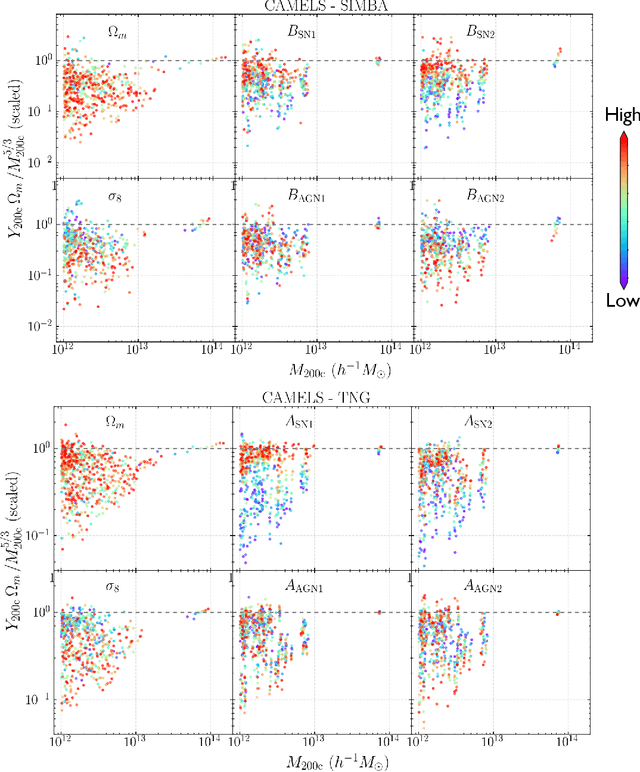
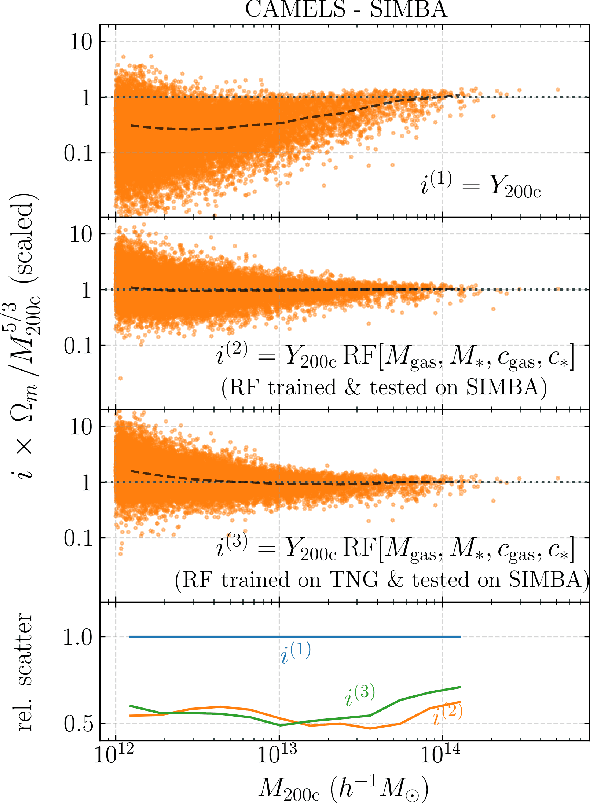

Ionized gas in the halo circumgalactic medium leaves an imprint on the cosmic microwave background via the thermal Sunyaev-Zeldovich (tSZ) effect. Feedback from active galactic nuclei (AGN) and supernovae can affect the measurements of the integrated tSZ flux of halos ($Y_\mathrm{SZ}$) and cause its relation with the halo mass ($Y_\mathrm{SZ}-M$) to deviate from the self-similar power-law prediction of the virial theorem. We perform a comprehensive study of such deviations using CAMELS, a suite of hydrodynamic simulations with extensive variations in feedback prescriptions. We use a combination of two machine learning tools (random forest and symbolic regression) to search for analogues of the $Y-M$ relation which are more robust to feedback processes for low masses ($M\lesssim 10^{14}\, h^{-1} \, M_\odot$); we find that simply replacing $Y\rightarrow Y(1+M_*/M_\mathrm{gas})$ in the relation makes it remarkably self-similar. This could serve as a robust multiwavelength mass proxy for low-mass clusters and galaxy groups. Our methodology can also be generally useful to improve the domain of validity of other astrophysical scaling relations. We also forecast that measurements of the $Y-M$ relation could provide percent-level constraints on certain combinations of feedback parameters and/or rule out a major part of the parameter space of supernova and AGN feedback models used in current state-of-the-art hydrodynamic simulations. Our results can be useful for using upcoming SZ surveys (e.g. SO, CMB-S4) and galaxy surveys (e.g. DESI and Rubin) to constrain the nature of baryonic feedback. Finally, we find that the an alternative relation, $Y-M_*$, provides complementary information on feedback than $Y-M$.
A model-based approach to meta-Reinforcement Learning: Transformers and tree search
Aug 24, 2022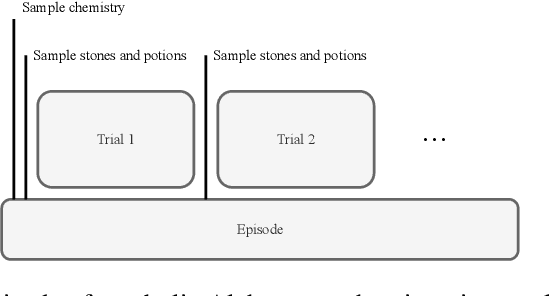
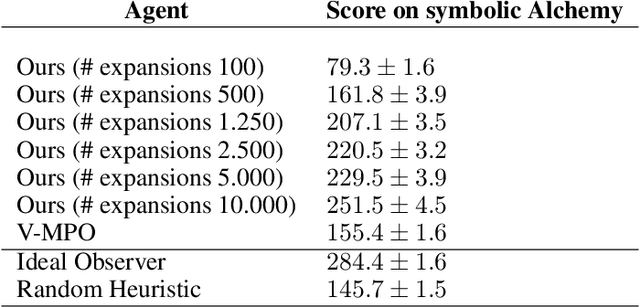
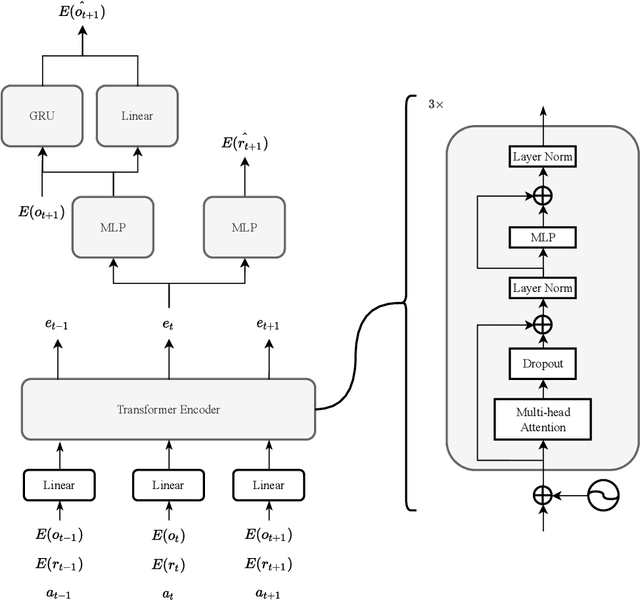
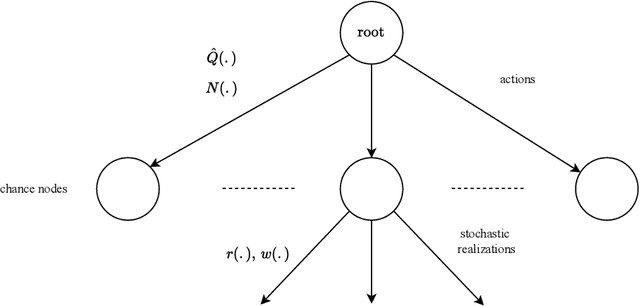
Meta-learning is a line of research that develops the ability to leverage past experiences to efficiently solve new learning problems. Meta-Reinforcement Learning (meta-RL) methods demonstrate a capability to learn behaviors that efficiently acquire and exploit information in several meta-RL problems. In this context, the Alchemy benchmark has been proposed by Wang et al. [2021]. Alchemy features a rich structured latent space that is challenging for state-of-the-art model-free RL methods. These methods fail to learn to properly explore then exploit. We develop a model-based algorithm. We train a model whose principal block is a Transformer Encoder to fit the symbolic Alchemy environment dynamics. Then we define an online planner with the learned model using a tree search method. This algorithm significantly outperforms previously applied model-free RL methods on the symbolic Alchemy problem. Our results reveal the relevance of model-based approaches with online planning to perform exploration and exploitation successfully in meta-RL. Moreover, we show the efficiency of the Transformer architecture to learn complex dynamics that arise from latent spaces present in meta-RL problems.
SB-SSL: Slice-Based Self-Supervised Transformers for Knee Abnormality Classification from MRI
Aug 29, 2022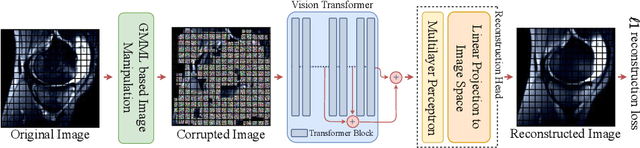
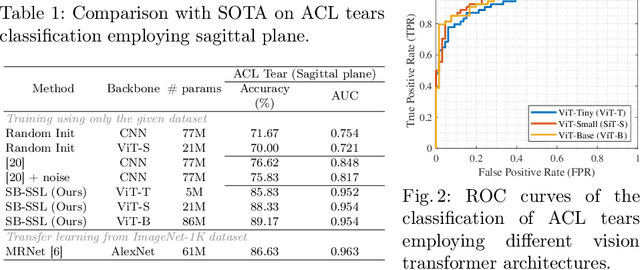
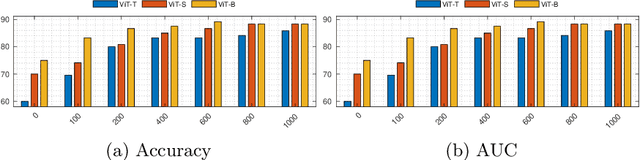
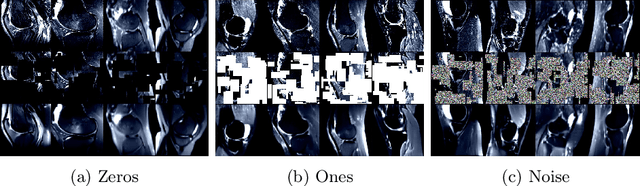
The availability of large scale data with high quality ground truth labels is a challenge when developing supervised machine learning solutions for healthcare domain. Although, the amount of digital data in clinical workflows is increasing, most of this data is distributed on clinical sites and protected to ensure patient privacy. Radiological readings and dealing with large-scale clinical data puts a significant burden on the available resources, and this is where machine learning and artificial intelligence play a pivotal role. Magnetic Resonance Imaging (MRI) for musculoskeletal (MSK) diagnosis is one example where the scans have a wealth of information, but require a significant amount of time for reading and labeling. Self-supervised learning (SSL) can be a solution for handling the lack of availability of ground truth labels, but generally requires a large amount of training data during the pretraining stage. Herein, we propose a slice-based self-supervised deep learning framework (SB-SSL), a novel slice-based paradigm for classifying abnormality using knee MRI scans. We show that for a limited number of cases (<1000), our proposed framework is capable to identify anterior cruciate ligament tear with an accuracy of 89.17% and an AUC of 0.954, outperforming state-of-the-art without usage of external data during pretraining. This demonstrates that our proposed framework is suited for SSL in the limited data regime.
Interactive Visualization for Exploring Information Fragments in Software Repositories
Apr 28, 2021Software developers explore and inspect software repository data to obtain detailed information archived in the development history. However, developers who are not acquainted with the development context suffer from delving into the repositories with a handful of information; they have difficulty discovering and expanding information fragments considering the topological and sequential multi-dimensional structure of repositories. We introduce ExIF, an interactive visualization for exploring information fragments in software repositories. ExIF helps users discover new information fragments within clusters or topological neighbors and identify revisions incorporating user-collected fragments.
Intelligence and Unambitiousness Using Algorithmic Information Theory
May 13, 2021
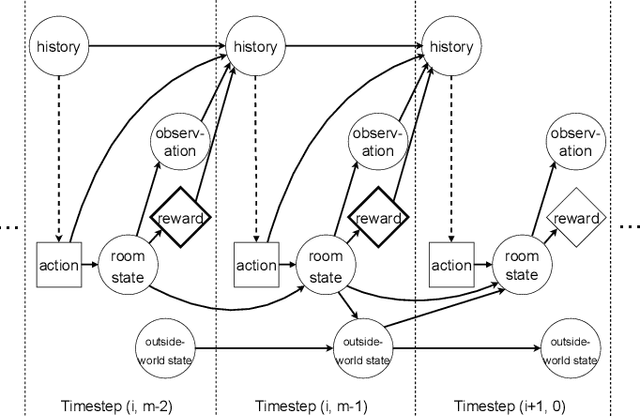
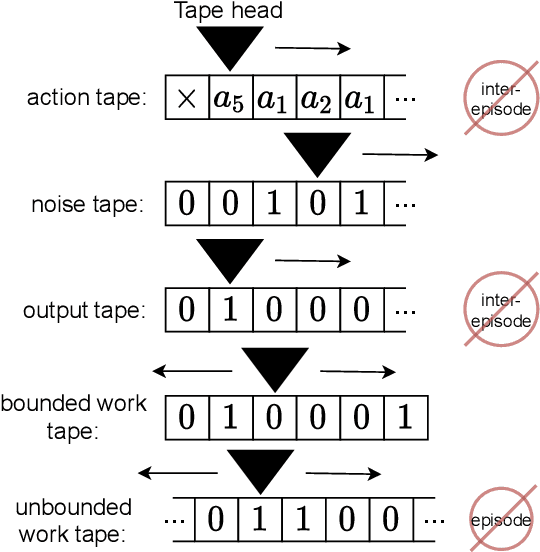
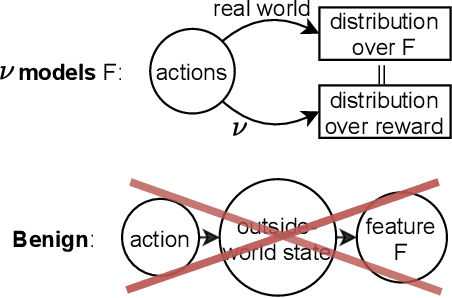
Algorithmic Information Theory has inspired intractable constructions of general intelligence (AGI), and undiscovered tractable approximations are likely feasible. Reinforcement Learning (RL), the dominant paradigm by which an agent might learn to solve arbitrary solvable problems, gives an agent a dangerous incentive: to gain arbitrary "power" in order to intervene in the provision of their own reward. We review the arguments that generally intelligent algorithmic-information-theoretic reinforcement learners such as Hutter's (2005) AIXI would seek arbitrary power, including over us. Then, using an information-theoretic exploration schedule, and a setup inspired by causal influence theory, we present a variant of AIXI which learns to not seek arbitrary power; we call it "unambitious". We show that our agent learns to accrue reward at least as well as a human mentor, while relying on that mentor with diminishing probability. And given a formal assumption that we probe empirically, we show that eventually, the agent's world-model incorporates the following true fact: intervening in the "outside world" will have no effect on reward acquisition; hence, it has no incentive to shape the outside world.
* 13 pages, 6 figures, 5-page appendix. arXiv admin note: text overlap with arXiv:1905.12186
AutoPruner: Transformer-Based Call Graph Pruning
Sep 07, 2022
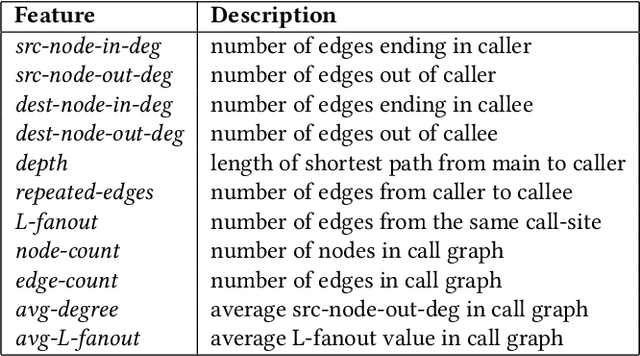
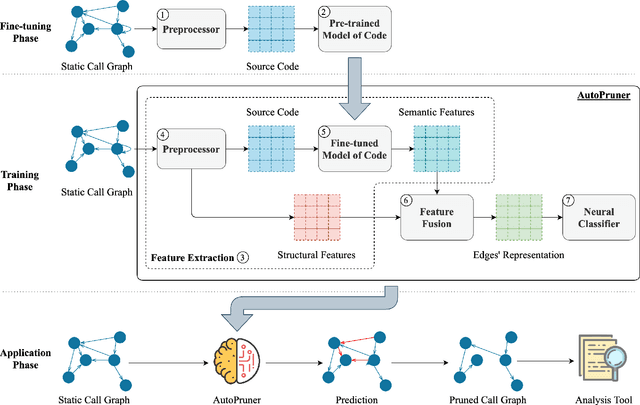

Constructing a static call graph requires trade-offs between soundness and precision. Program analysis techniques for constructing call graphs are unfortunately usually imprecise. To address this problem, researchers have recently proposed call graph pruning empowered by machine learning to post-process call graphs constructed by static analysis. A machine learning model is built to capture information from the call graph by extracting structural features for use in a random forest classifier. It then removes edges that are predicted to be false positives. Despite the improvements shown by machine learning models, they are still limited as they do not consider the source code semantics and thus often are not able to effectively distinguish true and false positives. In this paper, we present a novel call graph pruning technique, AutoPruner, for eliminating false positives in call graphs via both statistical semantic and structural analysis. Given a call graph constructed by traditional static analysis tools, AutoPruner takes a Transformer-based approach to capture the semantic relationships between the caller and callee functions associated with each edge in the call graph. To do so, AutoPruner fine-tunes a model of code that was pre-trained on a large corpus to represent source code based on descriptions of its semantics. Next, the model is used to extract semantic features from the functions related to each edge in the call graph. AutoPruner uses these semantic features together with the structural features extracted from the call graph to classify each edge via a feed-forward neural network. Our empirical evaluation on a benchmark dataset of real-world programs shows that AutoPruner outperforms the state-of-the-art baselines, improving on F-measure by up to 13% in identifying false-positive edges in a static call graph.
Prediction Errors for Penalized Regressions based on Generalized Approximate Message Passing
Jun 29, 2022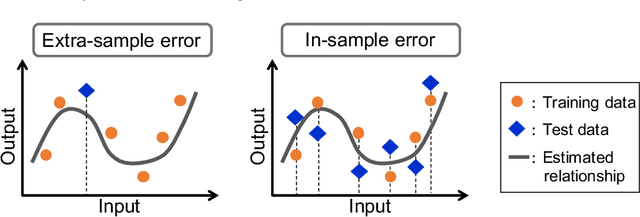

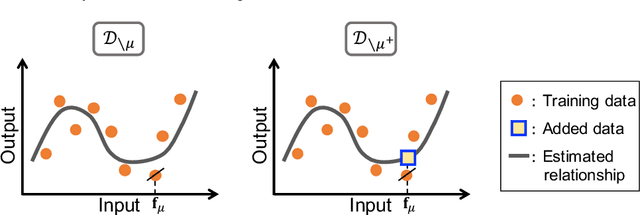
We discuss the prediction accuracy of assumed statistical models in terms of prediction errors for the generalized linear model and penalized maximum likelihood methods. We derive the forms of estimators for the prediction errors: $C_p$ criterion, information criteria, and leave-one-out cross validation (LOOCV) error, using the generalized approximate message passing (GAMP) algorithm and replica method. These estimators coincide with each other when the number of model parameters is sufficiently small; however, there is a discrepancy between them in particular in the overparametrized region where the number of model parameters is larger than the data dimension. In this paper, we review the prediction errors and corresponding estimators, and discuss their differences. In the framework of GAMP, we show that the information criteria can be expressed by using the variance of the estimates. Further, we demonstrate how to approach LOOCV error from the information criteria by utilizing the expression provided by GAMP.
Hybrid Fusion Based Interpretable Multimodal Emotion Recognition with Insufficient Labelled Data
Aug 24, 2022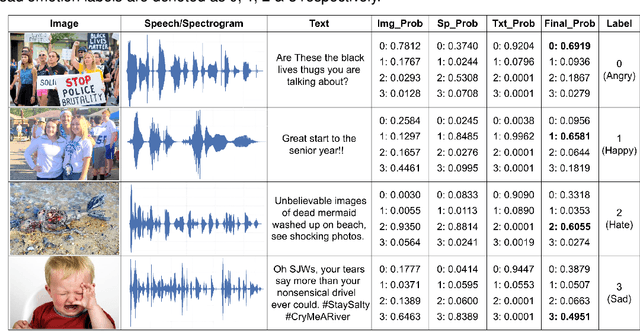
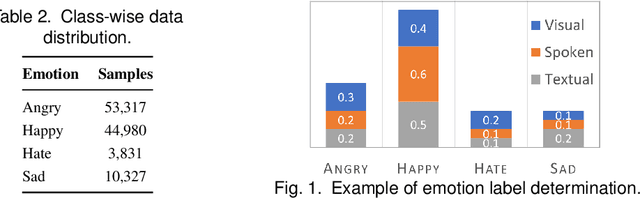
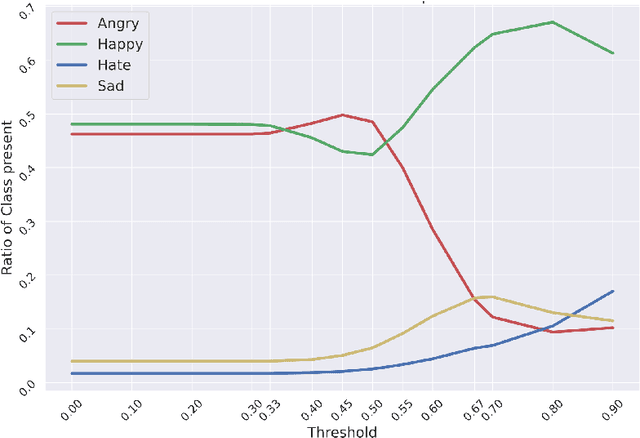
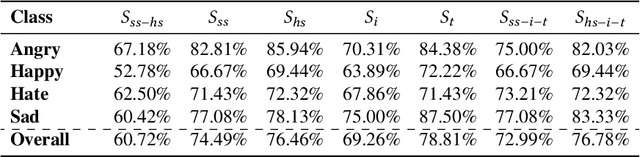
This paper proposes a multimodal emotion recognition system, VIsual Spoken Textual Additive Net (VISTA Net), to classify the emotions reflected by a multimodal input containing image, speech, and text into discrete classes. A new interpretability technique, K-Average Additive exPlanation (KAAP), has also been developed to identify the important visual, spoken, and textual features leading to predicting a particular emotion class. The VISTA Net fuses the information from image, speech & text modalities using a hybrid of early and late fusion. It automatically adjusts the weights of their intermediate outputs while computing the weighted average without human intervention. The KAAP technique computes the contribution of each modality and corresponding features toward predicting a particular emotion class. To mitigate the insufficiency of multimodal emotion datasets labeled with discrete emotion classes, we have constructed a large-scale IIT-R MMEmoRec dataset consisting of real-life images, corresponding speech & text, and emotion labels ('angry,' 'happy,' 'hate,' and 'sad.'). The VISTA Net has resulted in 95.99% emotion recognition accuracy on considering image, speech, and text modalities, which is better than the performance on considering the inputs of any one or two modalities.