 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A model-based approach to meta-Reinforcement Learning: Transformers and tree search
Aug 24, 2022
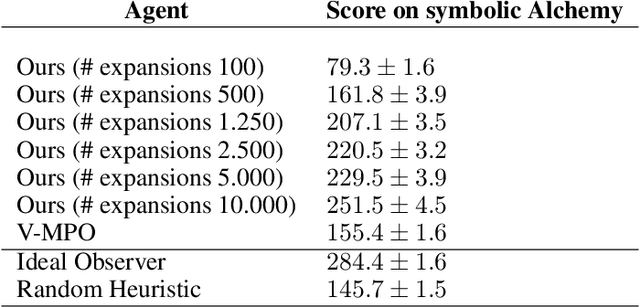
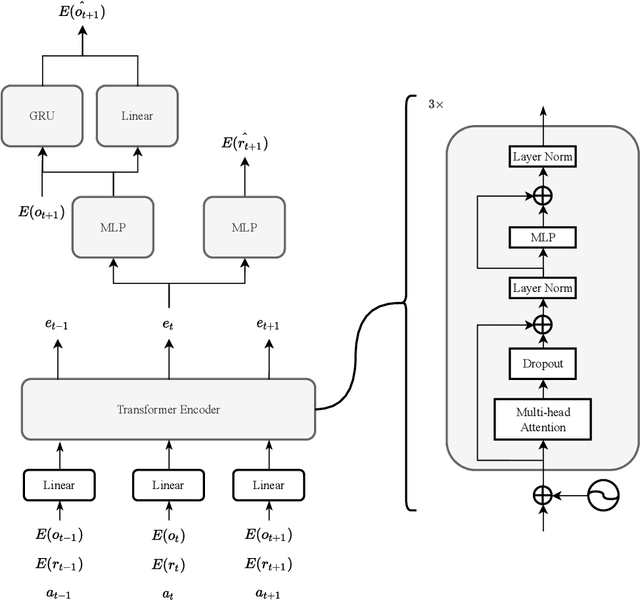
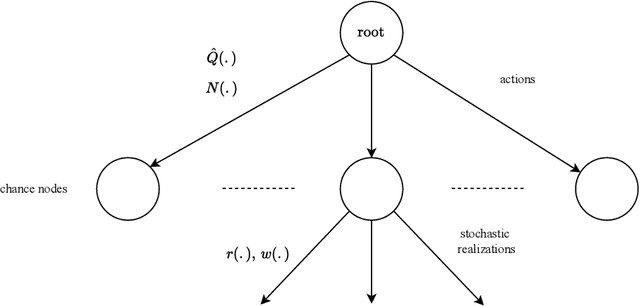
Meta-learning is a line of research that develops the ability to leverage past experiences to efficiently solve new learning problems. Meta-Reinforcement Learning (meta-RL) methods demonstrate a capability to learn behaviors that efficiently acquire and exploit information in several meta-RL problems. In this context, the Alchemy benchmark has been proposed by Wang et al. [2021]. Alchemy features a rich structured latent space that is challenging for state-of-the-art model-free RL methods. These methods fail to learn to properly explore then exploit. We develop a model-based algorithm. We train a model whose principal block is a Transformer Encoder to fit the symbolic Alchemy environment dynamics. Then we define an online planner with the learned model using a tree search method. This algorithm significantly outperforms previously applied model-free RL methods on the symbolic Alchemy problem. Our results reveal the relevance of model-based approaches with online planning to perform exploration and exploitation successfully in meta-RL. Moreover, we show the efficiency of the Transformer architecture to learn complex dynamics that arise from latent spaces present in meta-RL problems.
DPTNet: A Dual-Path Transformer Architecture for Scene Text Detection
Aug 21, 2022
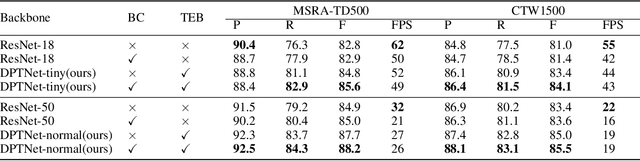
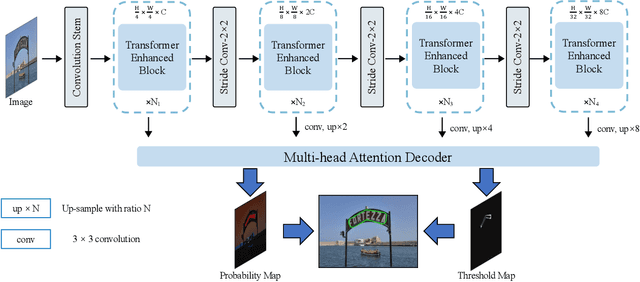
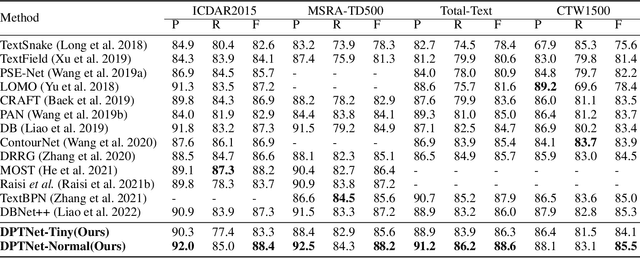
The prosperity of deep learning contributes to the rapid progress in scene text detection. Among all the methods with convolutional networks, segmentation-based ones have drawn extensive attention due to their superiority in detecting text instances of arbitrary shapes and extreme aspect ratios. However, the bottom-up methods are limited to the performance of their segmentation models. In this paper, we propose DPTNet (Dual-Path Transformer Network), a simple yet effective architecture to model the global and local information for the scene text detection task. We further propose a parallel design that integrates the convolutional network with a powerful self-attention mechanism to provide complementary clues between the attention path and convolutional path. Moreover, a bi-directional interaction module across the two paths is developed to provide complementary clues in the channel and spatial dimensions. We also upgrade the concentration operation by adding an extra multi-head attention layer to it. Our DPTNet achieves state-of-the-art results on the MSRA-TD500 dataset, and provides competitive results on other standard benchmarks in terms of both detection accuracy and speed.
Memory-Based Label-Text Tuning for Few-Shot Class-Incremental Learning
Jul 03, 2022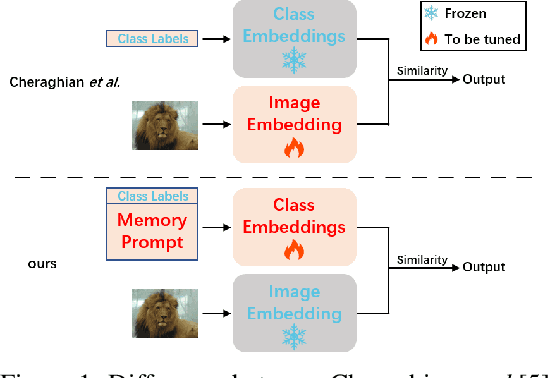
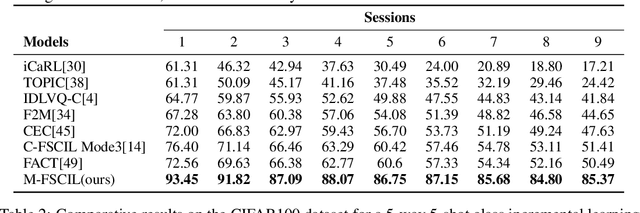
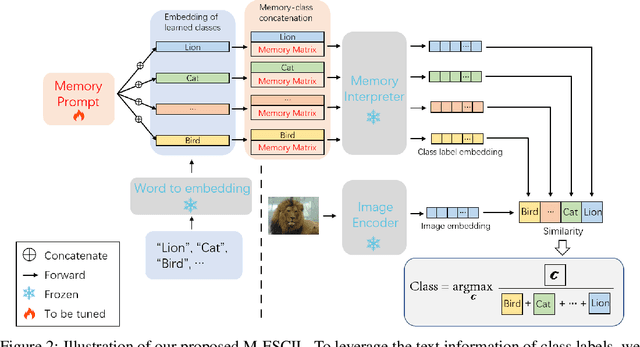
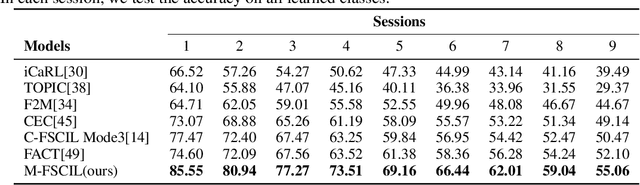
Few-shot class-incremental learning(FSCIL) focuses on designing learning algorithms that can continually learn a sequence of new tasks from a few samples without forgetting old ones. The difficulties are that training on a sequence of limited data from new tasks leads to severe overfitting issues and causes the well-known catastrophic forgetting problem. Existing researches mainly utilize the image information, such as storing the image knowledge of previous tasks or limiting classifiers updating. However, they ignore analyzing the informative and less noisy text information of class labels. In this work, we propose leveraging the label-text information by adopting the memory prompt. The memory prompt can learn new data sequentially, and meanwhile store the previous knowledge. Furthermore, to optimize the memory prompt without undermining the stored knowledge, we propose a stimulation-based training strategy. It optimizes the memory prompt depending on the image embedding stimulation, which is the distribution of the image embedding elements. Experiments show that our proposed method outperforms all prior state-of-the-art approaches, significantly mitigating the catastrophic forgetting and overfitting problems.
Assessing Attendance by Peer Information
Jun 06, 2021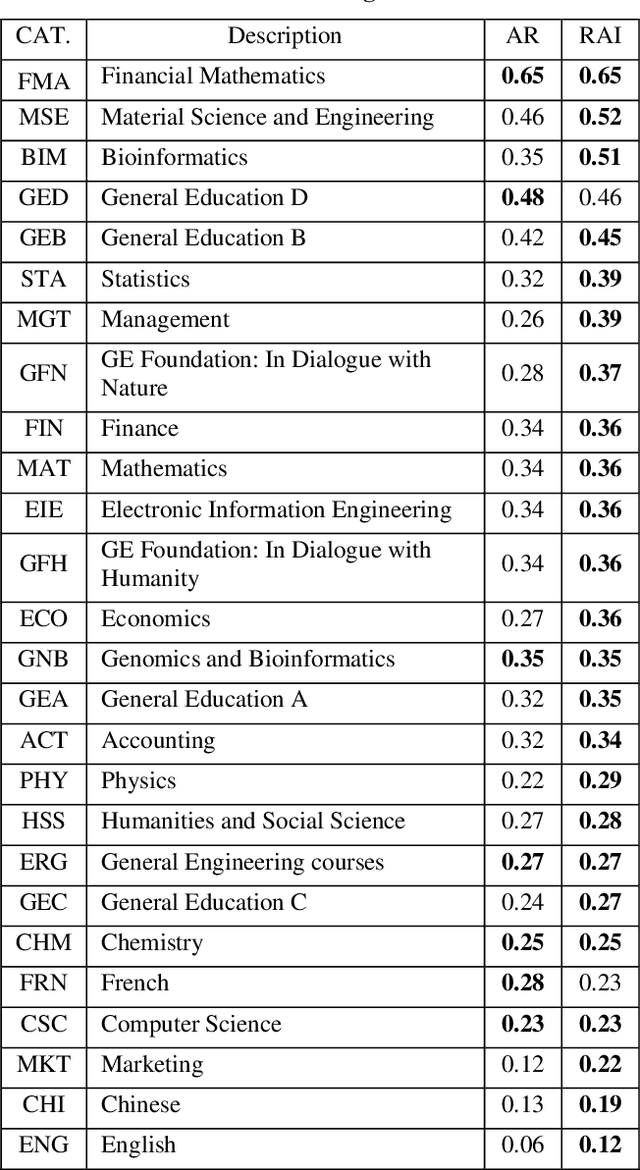
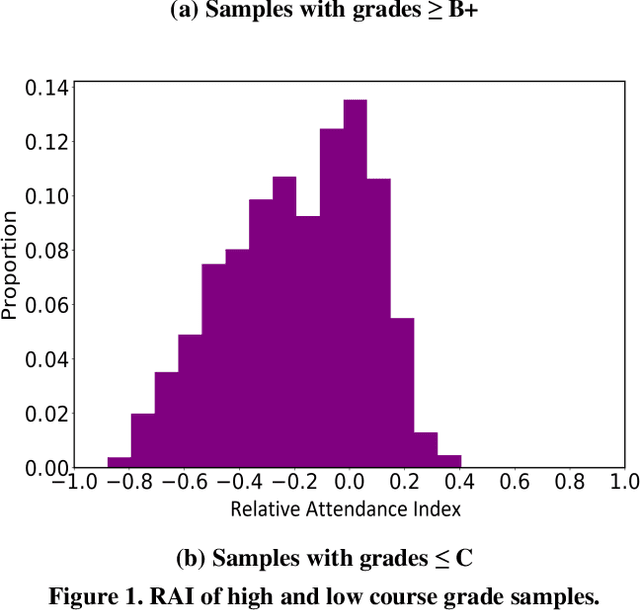
Attendance rate is an important indicator of students' study motivation, behavior and Psychological status; However, the heterogeneous nature of student attendance rates due to the course registration difference or the online/offline difference in a blended learning environment makes it challenging to compare attendance rates. In this paper, we propose a novel method called Relative Attendance Index (RAI) to measure attendance rates, which reflects students' efforts on attending courses. While traditional attendance focuses on the record of a single person or course, relative attendance emphasizes peer attendance information of relevant individuals or courses, making the comparisons of attendance more justified. Experimental results on real-life data show that RAI can indeed better reflect student engagement.
Hybrid Fusion Based Interpretable Multimodal Emotion Recognition with Insufficient Labelled Data
Aug 24, 2022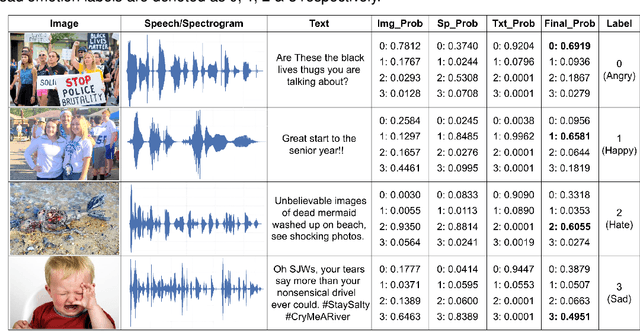
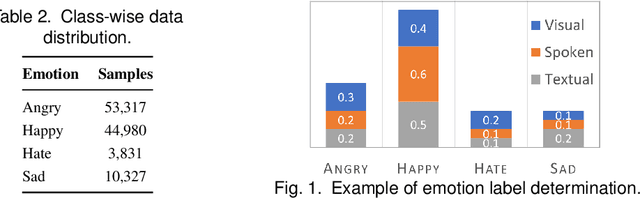
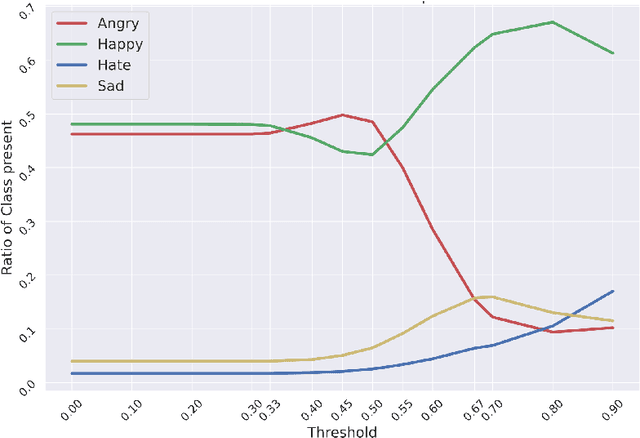
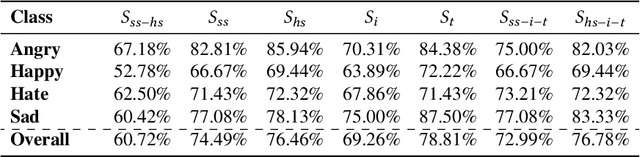
This paper proposes a multimodal emotion recognition system, VIsual Spoken Textual Additive Net (VISTA Net), to classify the emotions reflected by a multimodal input containing image, speech, and text into discrete classes. A new interpretability technique, K-Average Additive exPlanation (KAAP), has also been developed to identify the important visual, spoken, and textual features leading to predicting a particular emotion class. The VISTA Net fuses the information from image, speech & text modalities using a hybrid of early and late fusion. It automatically adjusts the weights of their intermediate outputs while computing the weighted average without human intervention. The KAAP technique computes the contribution of each modality and corresponding features toward predicting a particular emotion class. To mitigate the insufficiency of multimodal emotion datasets labeled with discrete emotion classes, we have constructed a large-scale IIT-R MMEmoRec dataset consisting of real-life images, corresponding speech & text, and emotion labels ('angry,' 'happy,' 'hate,' and 'sad.'). The VISTA Net has resulted in 95.99% emotion recognition accuracy on considering image, speech, and text modalities, which is better than the performance on considering the inputs of any one or two modalities.
DAHiTrA: Damage Assessment Using a Novel Hierarchical Transformer Architecture
Aug 03, 2022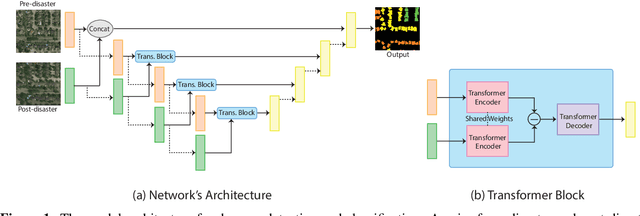
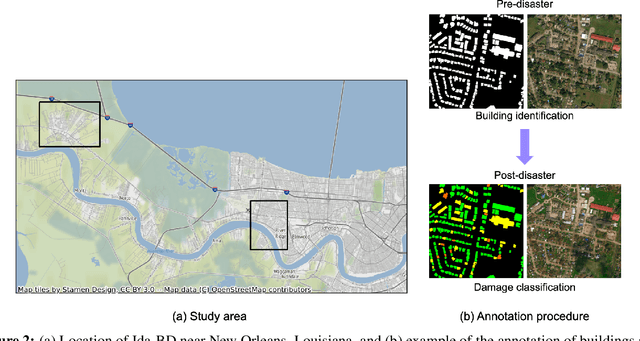


This paper presents DAHiTrA, a novel deep-learning model with hierarchical transformers to classify building damages based on satellite images in the aftermath of hurricanes. An automated building damage assessment provides critical information for decision making and resource allocation for rapid emergency response. Satellite imagery provides real-time, high-coverage information and offers opportunities to inform large-scale post-disaster building damage assessment. In addition, deep-learning methods have shown to be promising in classifying building damage. In this work, a novel transformer-based network is proposed for assessing building damage. This network leverages hierarchical spatial features of multiple resolutions and captures temporal difference in the feature domain after applying a transformer encoder on the spatial features. The proposed network achieves state-of-the-art-performance when tested on a large-scale disaster damage dataset (xBD) for building localization and damage classification, as well as on LEVIR-CD dataset for change detection tasks. In addition, we introduce a new high-resolution satellite imagery dataset, Ida-BD (related to the 2021 Hurricane Ida in Louisiana in 2021, for domain adaptation to further evaluate the capability of the model to be applied to newly damaged areas with scarce data. The domain adaptation results indicate that the proposed model can be adapted to a new event with only limited fine-tuning. Hence, the proposed model advances the current state of the art through better performance and domain adaptation. Also, Ida-BD provides a higher-resolution annotated dataset for future studies in this field.
Location Information Assisted Beamforming Design for Reconfigurable Intelligent Surface Aided Communication Systems
Oct 18, 2021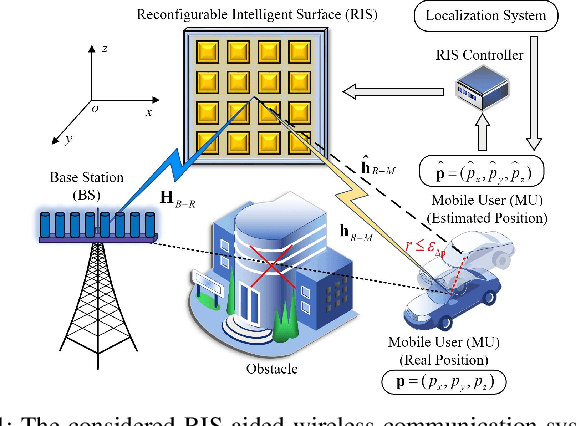
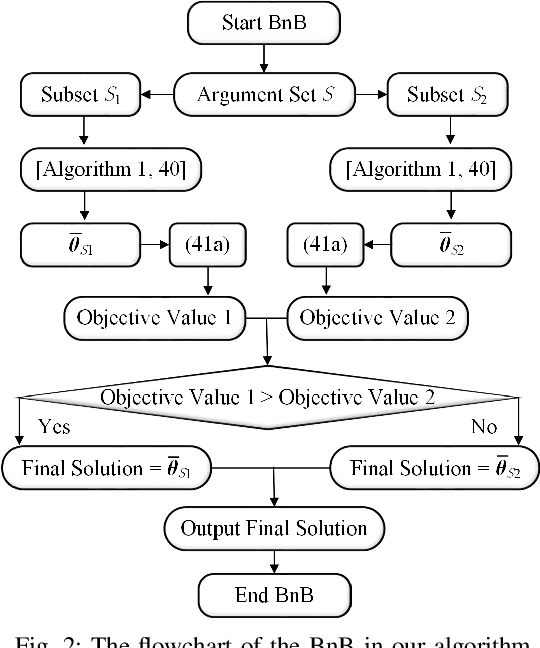
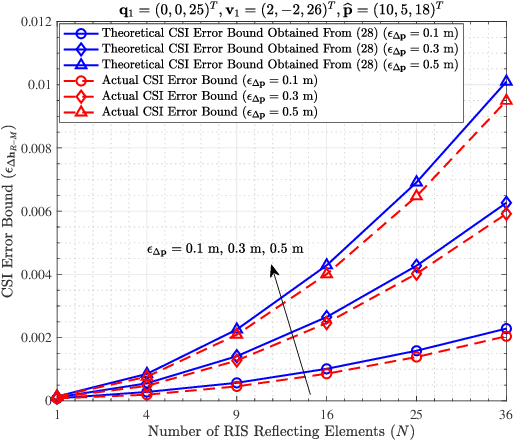
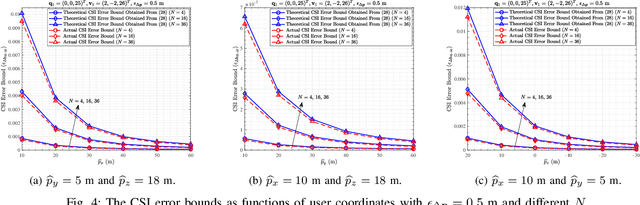
In reconfigurable intelligent surface (RIS) aided millimeter-wave (mmWave) communication systems, in order to overcome the limitation of the conventional channel state information (CSI) acquisition techniques, this paper proposes a location information assisted beamforming design without the requirement of the conventional channel training process. First, we establish the geometrical relation between the channel model and the user location, based on which we derive an approximate CSI error bound based on the user location error by means of Taylor approximation, triangle and power mean inequalities, and semidefinite relaxation (SDR). Second, for combating the uncertainty of the location error, we formulate a worst-case robust beamforming optimization problem. To solve the problem efficiently, we develop a novel iterative algorithm by utilizing various optimization tools such as Lagrange multiplier, matrix inversion lemma, SDR, as well as branch-and-bound (BnB). Particularly, the BnB algorithm is modified to acquire the phase shift solution under an arbitrary constraint of possible phase shift values. Finally, we analyse the algorithm complexity, and carry out simulations to validate the theoretical derivation of the CSI error bound and the robustness of the proposed algorithm. Compared with the existing non-robust approach and the robust beamforming techniques based on S-procedure and penalty convex-concave procedure (CCP), our method converges faster and achieves better performance in terms of the worst-case signal-to-noise ratio (SNR) at the receiver.
Lossy compression of multidimensional medical images using sinusoidal activation networks: an evaluation study
Aug 03, 2022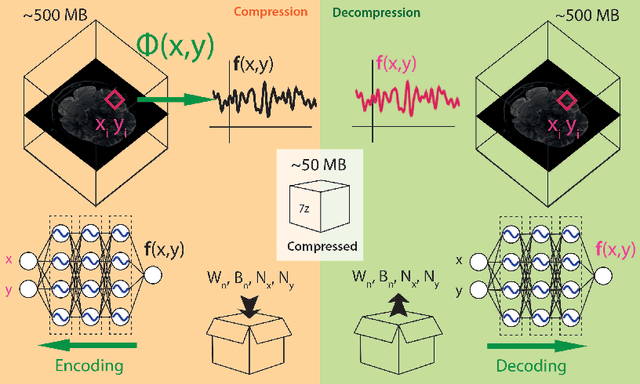
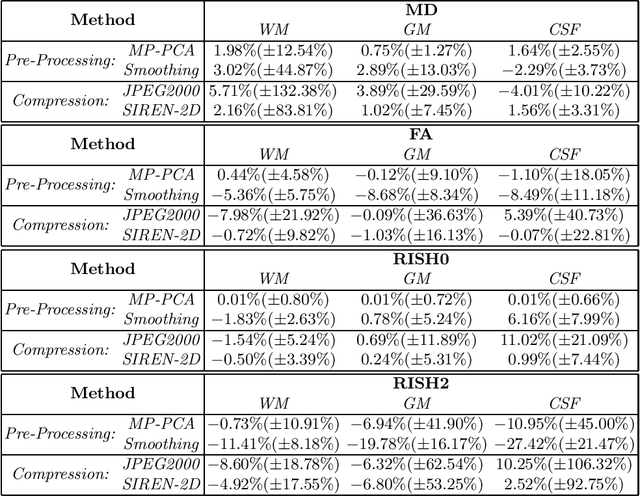
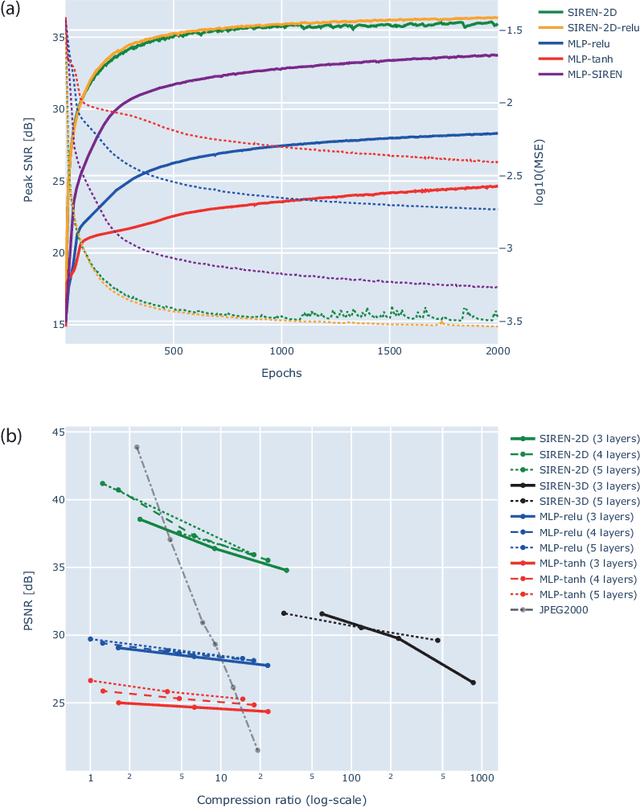
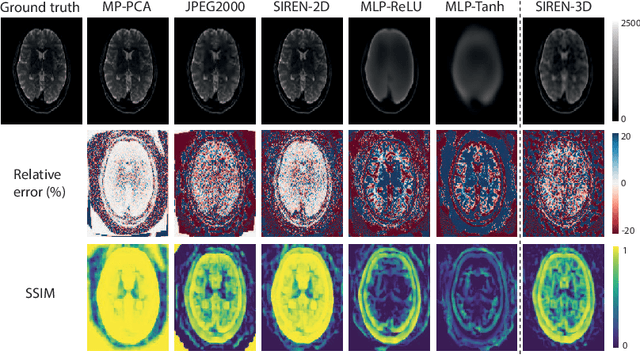
In this work, we evaluate how neural networks with periodic activation functions can be leveraged to reliably compress large multidimensional medical image datasets, with proof-of-concept application to 4D diffusion-weighted MRI (dMRI). In the medical imaging landscape, multidimensional MRI is a key area of research for developing biomarkers that are both sensitive and specific to the underlying tissue microstructure. However, the high-dimensional nature of these data poses a challenge in terms of both storage and sharing capabilities and associated costs, requiring appropriate algorithms able to represent the information in a low-dimensional space. Recent theoretical developments in deep learning have shown how periodic activation functions are a powerful tool for implicit neural representation of images and can be used for compression of 2D images. Here we extend this approach to 4D images and show how any given 4D dMRI dataset can be accurately represented through the parameters of a sinusoidal activation network, achieving a data compression rate about 10 times higher than the standard DEFLATE algorithm. Our results show that the proposed approach outperforms benchmark ReLU and Tanh activation perceptron architectures in terms of mean squared error, peak signal-to-noise ratio and structural similarity index. Subsequent analyses using the tensor and spherical harmonics representations demonstrate that the proposed lossy compression reproduces accurately the characteristics of the original data, leading to relative errors about 5 to 10 times lower than the benchmark JPEG2000 lossy compression and similar to standard pre-processing steps such as MP-PCA denosing, suggesting a loss of information within the currently accepted levels for clinical application.
Unsupervised Domain Adaptation via Style-Aware Self-intermediate Domain
Sep 05, 2022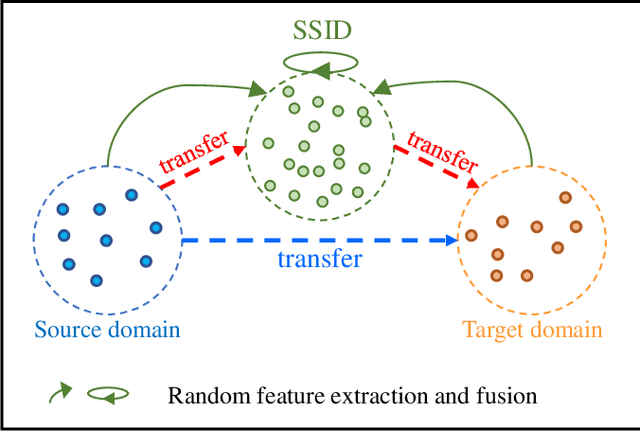
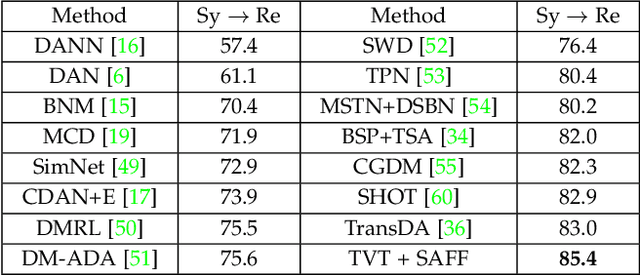
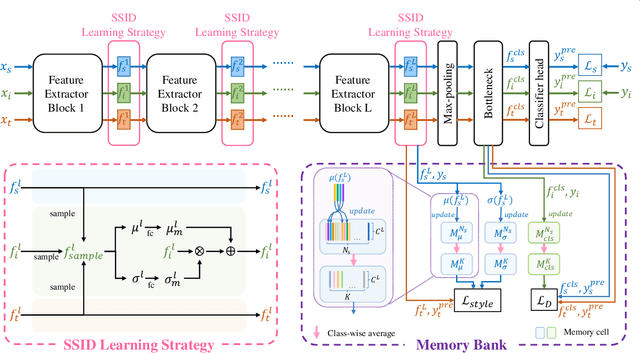
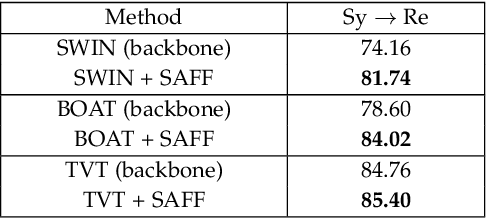
Unsupervised domain adaptation (UDA) has attracted considerable attention, which transfers knowledge from a label-rich source domain to a related but unlabeled target domain. Reducing inter-domain differences has always been a crucial factor to improve performance in UDA, especially for tasks where there is a large gap between source and target domains. To this end, we propose a novel style-aware feature fusion method (SAFF) to bridge the large domain gap and transfer knowledge while alleviating the loss of class-discriminative information. Inspired by the human transitive inference and learning ability, a novel style-aware self-intermediate domain (SSID) is investigated to link two seemingly unrelated concepts through a series of intermediate auxiliary synthesized concepts. Specifically, we propose a novel learning strategy of SSID, which selects samples from both source and target domains as anchors, and then randomly fuses the object and style features of these anchors to generate labeled and style-rich intermediate auxiliary features for knowledge transfer. Moreover, we design an external memory bank to store and update specified labeled features to obtain stable class features and class-wise style features. Based on the proposed memory bank, the intra- and inter-domain loss functions are designed to improve the class recognition ability and feature compatibility, respectively. Meanwhile, we simulate the rich latent feature space of SSID by infinite sampling and the convergence of the loss function by mathematical theory. Finally, we conduct comprehensive experiments on commonly used domain adaptive benchmarks to evaluate the proposed SAFF, and the experimental results show that the proposed SAFF can be easily combined with different backbone networks and obtain better performance as a plug-in-plug-out module.
Network Binarization via Contrastive Learning
Jul 16, 2022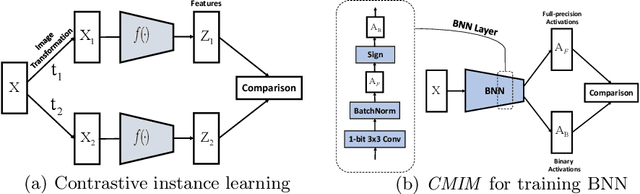
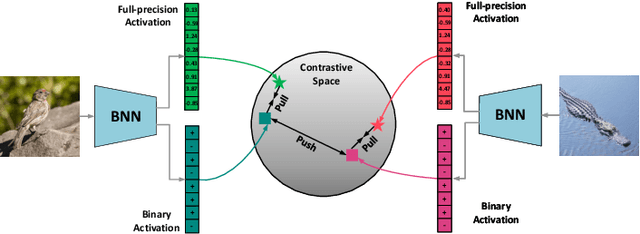
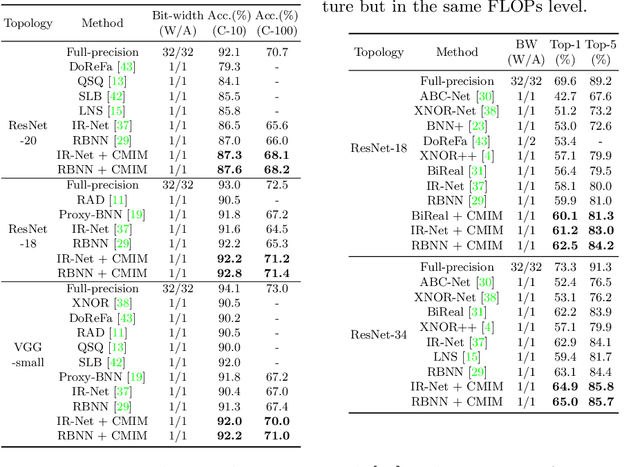

Neural network binarization accelerates deep models by quantizing their weights and activations into 1-bit. However, there is still a huge performance gap between Binary Neural Networks (BNNs) and their full-precision (FP) counterparts. As the quantization error caused by weights binarization has been reduced in earlier works, the activations binarization becomes the major obstacle for further improvement of the accuracy. BNN characterises a unique and interesting structure, where the binary and latent FP activations exist in the same forward pass (i.e., $\text{Binarize}(\mathbf{a}_F) = \mathbf{a}_B$). To mitigate the information degradation caused by the binarization operation from FP to binary activations, we establish a novel contrastive learning framework while training BNNs through the lens of Mutual Information (MI) maximization. MI is introduced as the metric to measure the information shared between binary and FP activations, which assists binarization with contrastive learning. Specifically, the representation ability of the BNNs is greatly strengthened via pulling the positive pairs with binary and FP activations from the same input samples, as well as pushing negative pairs from different samples (the number of negative pairs can be exponentially large). This benefits the downstream tasks, not only classification but also segmentation and depth estimation, etc. The experimental results show that our method can be implemented as a pile-up module on existing state-of-the-art binarization methods and can remarkably improve the performance over them on CIFAR-10/100 and ImageNet, in addition to the great generalization ability on NYUD-v2.