 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GFNet: Geometric Flow Network for 3D Point Cloud Semantic Segmentation
Jul 06, 2022
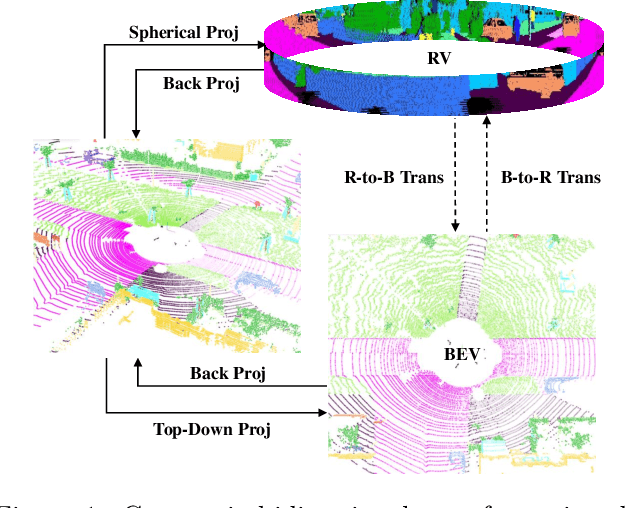

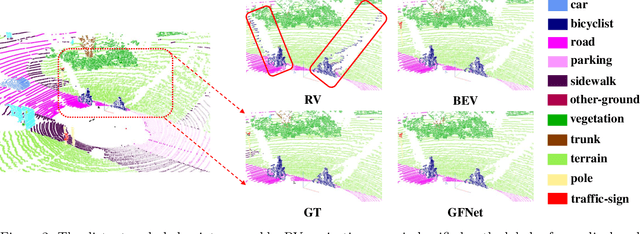
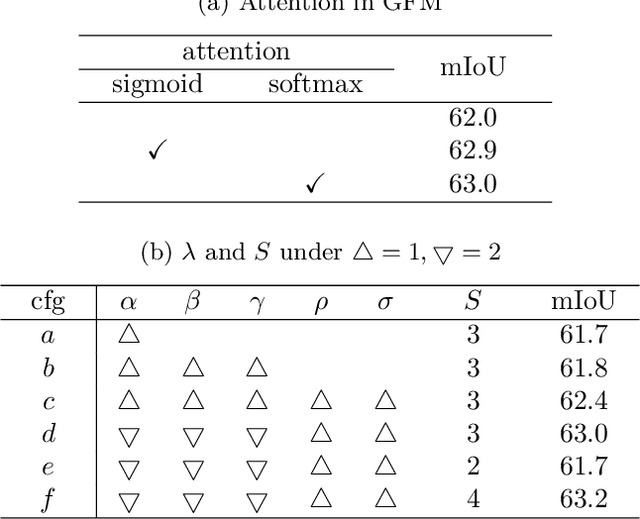
Point cloud semantic segmentation from projected views, such as range-view (RV) and bird's-eye-view (BEV), has been intensively investigated. Different views capture different information of point clouds and thus are complementary to each other. However, recent projection-based methods for point cloud semantic segmentation usually utilize a vanilla late fusion strategy for the predictions of different views, failing to explore the complementary information from a geometric perspective during the representation learning. In this paper, we introduce a geometric flow network (GFNet) to explore the geometric correspondence between different views in an align-before-fuse manner. Specifically, we devise a novel geometric flow module (GFM) to bidirectionally align and propagate the complementary information across different views according to geometric relationships under the end-to-end learning scheme. We perform extensive experiments on two widely used benchmark datasets, SemanticKITTI and nuScenes, to demonstrate the effectiveness of our GFNet for project-based point cloud semantic segmentation. Concretely, GFNet not only significantly boosts the performance of each individual view but also achieves state-of-the-art results over all existing projection-based models. Code is available at \url{https://github.com/haibo-qiu/GFNet}.
DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech
Jul 03, 2022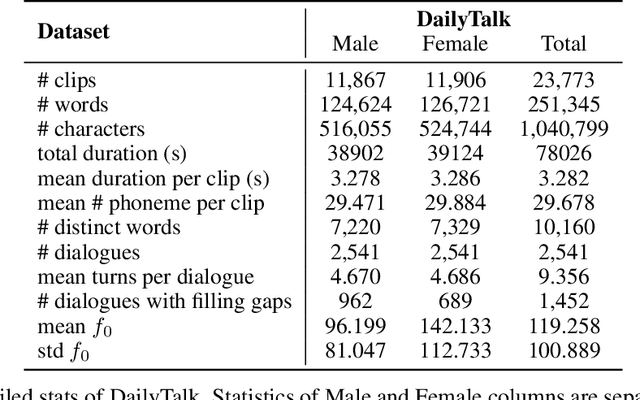
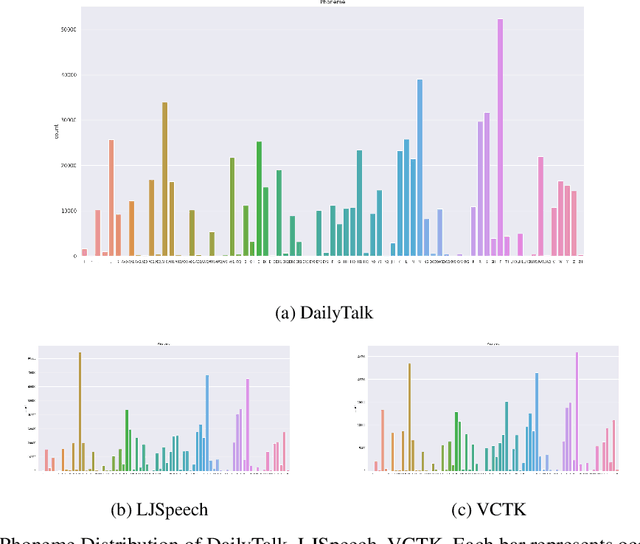

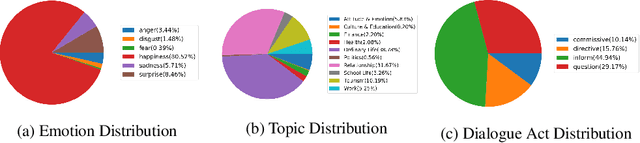
The majority of current TTS datasets, which are collections of individual utterances, contain few conversational aspects in terms of both style and metadata. In this paper, we introduce DailyTalk, a high-quality conversational speech dataset designed for Text-to-Speech. We sampled, modified, and recorded 2,541 dialogues from the open-domain dialogue dataset DailyDialog which are adequately long to represent context of each dialogue. During the data construction step, we maintained attributes distribution originally annotated in DailyDialog to support diverse dialogue in DailyTalk. On top of our dataset, we extend prior work as our baseline, where a non-autoregressive TTS is conditioned on historical information in a dialog. We gather metadata so that a TTS model can learn historical dialog information, the key to generating context-aware speech. From the baseline experiment results, we show that DailyTalk can be used to train neural text-to-speech models, and our baseline can represent contextual information. The DailyTalk dataset and baseline code are freely available for academic use with CC-BY-SA 4.0 license.
Estimating Appearance Models for Image Segmentation via Tensor Factorization
Aug 16, 2022
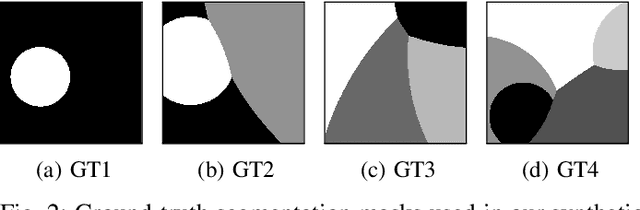

Image Segmentation is one of the core tasks in Computer Vision and solving it often depends on modeling the image appearance data via the color distributions of each it its constituent regions. Whereas many segmentation algorithms handle the appearance models dependence using alternation or implicit methods, we propose here a new approach to directly estimate them from the image without prior information on the underlying segmentation. Our method uses local high order color statistics from the image as an input to tensor factorization-based estimator for latent variable models. This approach is able to estimate models in multiregion images and automatically output the regions proportions without prior user interaction, overcoming the drawbacks from a prior attempt to this problem. We also demonstrate the performance of our proposed method in many challenging synthetic and real imaging scenarios and show that it leads to an efficient segmentation algorithm.
Dataset Condensation with Latent Space Knowledge Factorization and Sharing
Aug 21, 2022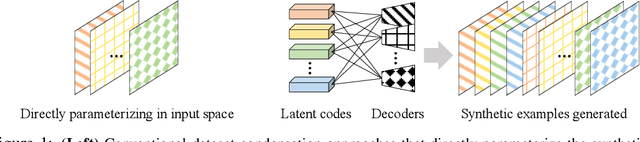
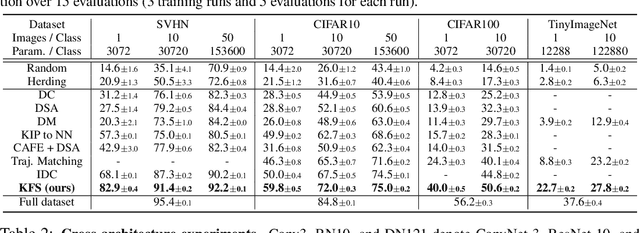
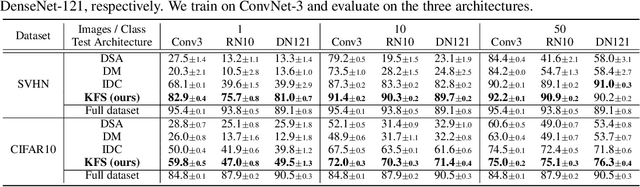
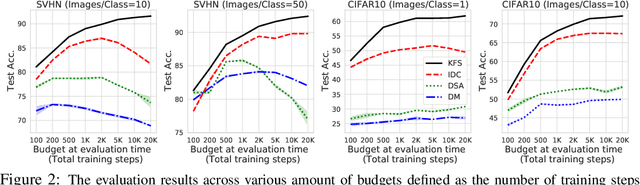
In this paper, we introduce a novel approach for systematically solving dataset condensation problem in an efficient manner by exploiting the regularity in a given dataset. Instead of condensing the dataset directly in the original input space, we assume a generative process of the dataset with a set of learnable codes defined in a compact latent space followed by a set of tiny decoders which maps them differently to the original input space. By combining different codes and decoders interchangeably, we can dramatically increase the number of synthetic examples with essentially the same parameter count, because the latent space is much lower dimensional and since we can assume as many decoders as necessary to capture different styles represented in the dataset with negligible cost. Such knowledge factorization allows efficient sharing of information between synthetic examples in a systematic way, providing far better trade-off between compression ratio and quality of the generated examples. We experimentally show that our method achieves new state-of-the-art records by significant margins on various benchmark datasets such as SVHN, CIFAR10, CIFAR100, and TinyImageNet.
Parallel Hierarchical Transformer with Attention Alignment for Abstractive Multi-Document Summarization
Aug 16, 2022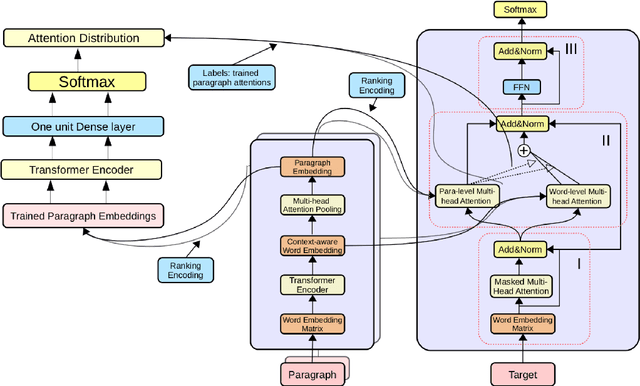
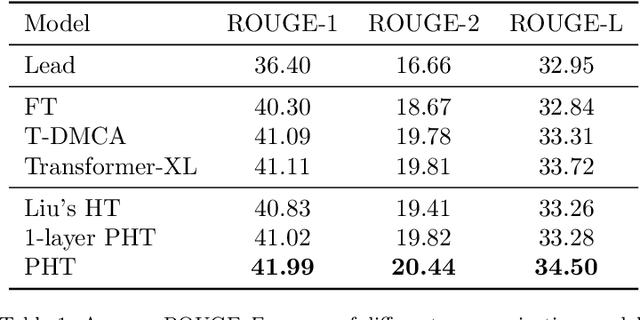
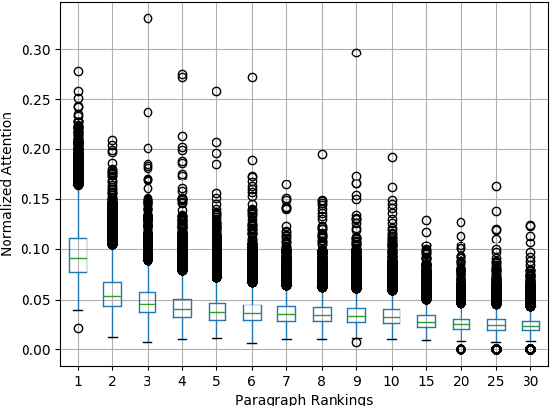
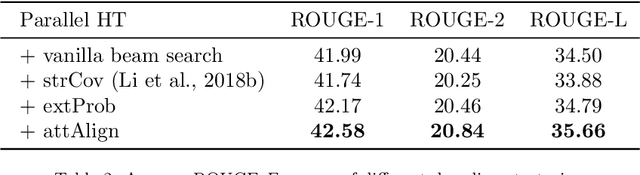
In comparison to single-document summarization, abstractive Multi-Document Summarization (MDS) brings challenges on the representation and coverage of its lengthy and linked sources. This study develops a Parallel Hierarchical Transformer (PHT) with attention alignment for MDS. By incorporating word- and paragraph-level multi-head attentions, the hierarchical architecture of PHT allows better processing of dependencies at both token and document levels. To guide the decoding towards a better coverage of the source documents, the attention-alignment mechanism is then introduced to calibrate beam search with predicted optimal attention distributions. Based on the WikiSum data, a comprehensive evaluation is conducted to test improvements on MDS by the proposed architecture. By better handling the inner- and cross-document information, results in both ROUGE and human evaluation suggest that our hierarchical model generates summaries of higher quality relative to other Transformer-based baselines at relatively low computational cost.
HTNet: Anchor-free Temporal Action Localization with Hierarchical Transformers
Jul 21, 2022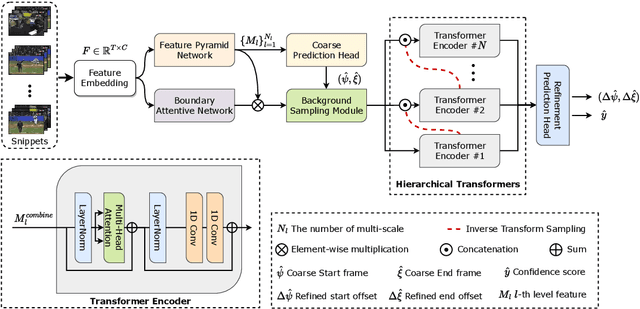
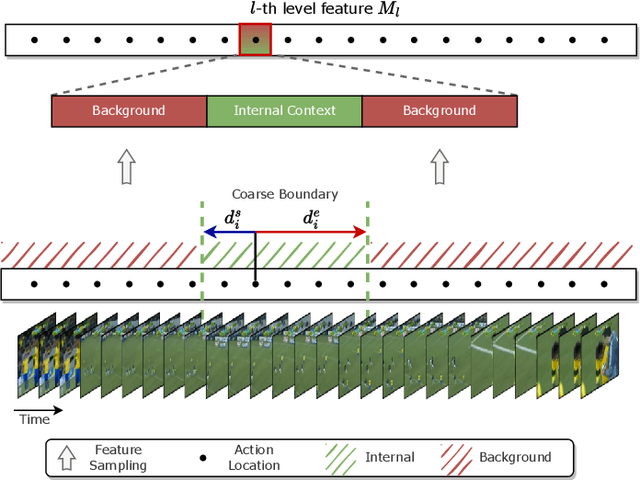


Temporal action localization (TAL) is a task of identifying a set of actions in a video, which involves localizing the start and end frames and classifying each action instance. Existing methods have addressed this task by using predefined anchor windows or heuristic bottom-up boundary-matching strategies, which are major bottlenecks in inference time. Additionally, the main challenge is the inability to capture long-range actions due to a lack of global contextual information. In this paper, we present a novel anchor-free framework, referred to as HTNet, which predicts a set of <start time, end time, class> triplets from a video based on a Transformer architecture. After the prediction of coarse boundaries, we refine it through a background feature sampling (BFS) module and hierarchical Transformers, which enables our model to aggregate global contextual information and effectively exploit the inherent semantic relationships in a video. We demonstrate how our method localizes accurate action instances and achieves state-of-the-art performance on two TAL benchmark datasets: THUMOS14 and ActivityNet 1.3.
Team Precoding Towards Scalable Cell-free Massive MIMO Networks
Aug 24, 2022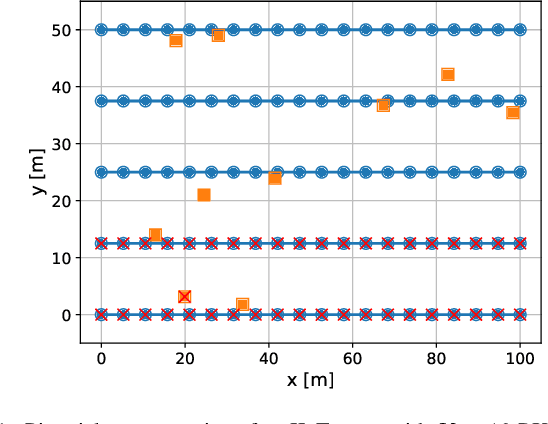
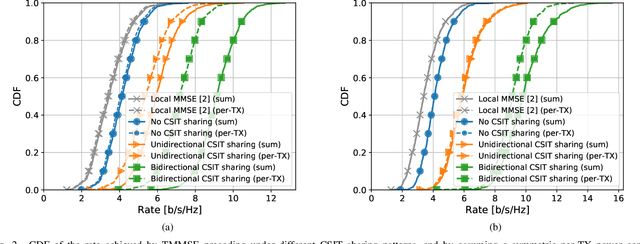
In a recent work, we studied a novel precoding design for cell-free networks called team minimum mean-square error (TMMSE) precoding, which rigorously generalizes centralized MMSE precoding to distributed operations based on transmitter-specific channel state information (CSI). Despite its flexibility in handling different cooperation regimes at the CSI sharing level, TMMSE precoding assumes network-wide sharing of the data bearing signals, and hence it is inherently not scalable. In this work, inspired by recent advances on scalable cell-free architectures based on user-centric network clustering techniques, we address this issue by proposing a novel version of the TMMSE precoding design covering partial message sharing. The obtained framework is then successfully applied to derive a variety of novel, optimal, and efficient precoding schemes for a user-centric cell-free network deployed using multiple radio stripes. Numerical simulations of a typical industrial internet-of-things scenario corroborate the gains of TMMSE precoding over competing schemes in terms of spectral efficiency under different power constraints. Although presented in the context of downlink precoding, the results of this paper may be applied also on the uplink.
Variational Leakage: The Role of Information Complexity in Privacy Leakage
Jun 05, 2021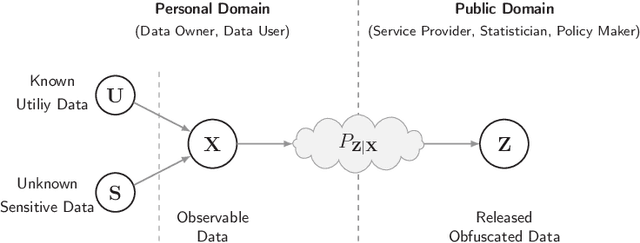
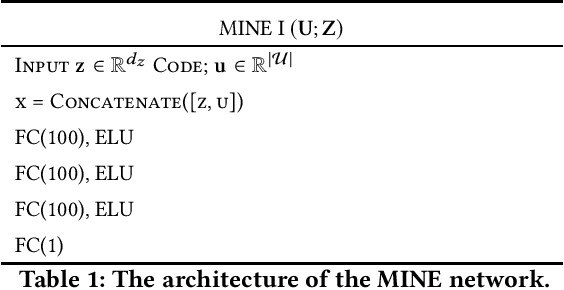
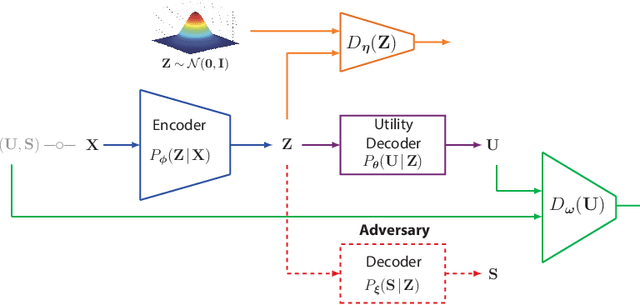

We study the role of information complexity in privacy leakage about an attribute of an adversary's interest, which is not known a priori to the system designer. Considering the supervised representation learning setup and using neural networks to parameterize the variational bounds of information quantities, we study the impact of the following factors on the amount of information leakage: information complexity regularizer weight, latent space dimension, the cardinalities of the known utility and unknown sensitive attribute sets, the correlation between utility and sensitive attributes, and a potential bias in a sensitive attribute of adversary's interest. We conduct extensive experiments on Colored-MNIST and CelebA datasets to evaluate the effect of information complexity on the amount of intrinsic leakage.
Memory-Based Label-Text Tuning for Few-Shot Class-Incremental Learning
Jul 03, 2022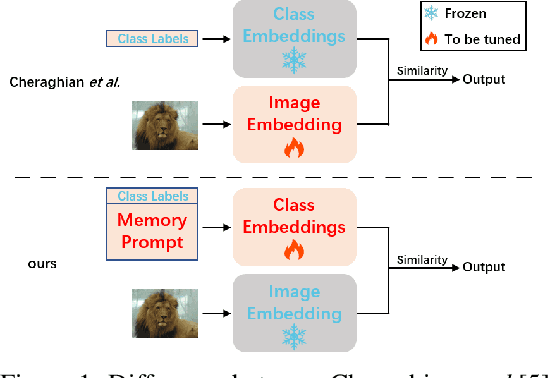
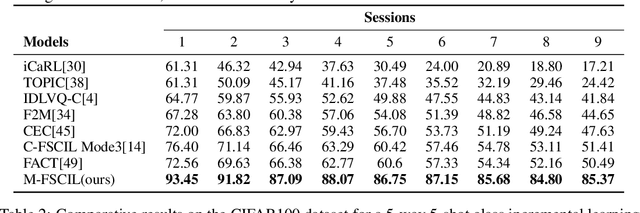
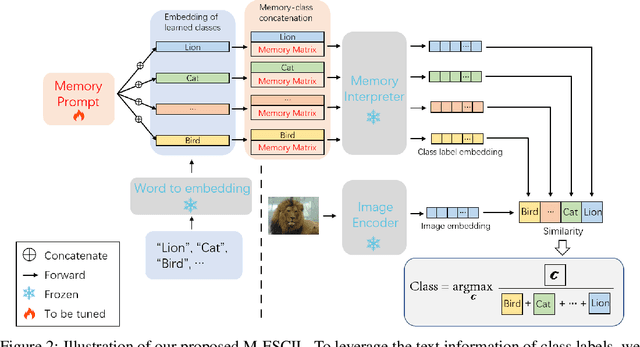
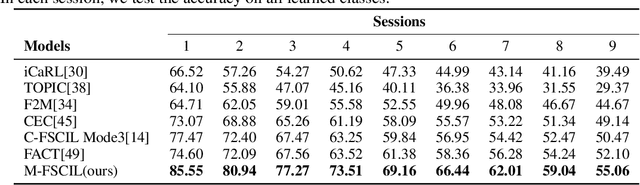
Few-shot class-incremental learning(FSCIL) focuses on designing learning algorithms that can continually learn a sequence of new tasks from a few samples without forgetting old ones. The difficulties are that training on a sequence of limited data from new tasks leads to severe overfitting issues and causes the well-known catastrophic forgetting problem. Existing researches mainly utilize the image information, such as storing the image knowledge of previous tasks or limiting classifiers updating. However, they ignore analyzing the informative and less noisy text information of class labels. In this work, we propose leveraging the label-text information by adopting the memory prompt. The memory prompt can learn new data sequentially, and meanwhile store the previous knowledge. Furthermore, to optimize the memory prompt without undermining the stored knowledge, we propose a stimulation-based training strategy. It optimizes the memory prompt depending on the image embedding stimulation, which is the distribution of the image embedding elements. Experiments show that our proposed method outperforms all prior state-of-the-art approaches, significantly mitigating the catastrophic forgetting and overfitting problems.
The SZ flux-mass ($Y$-$M$) relation at low halo masses: improvements with symbolic regression and strong constraints on baryonic feedback
Sep 05, 2022
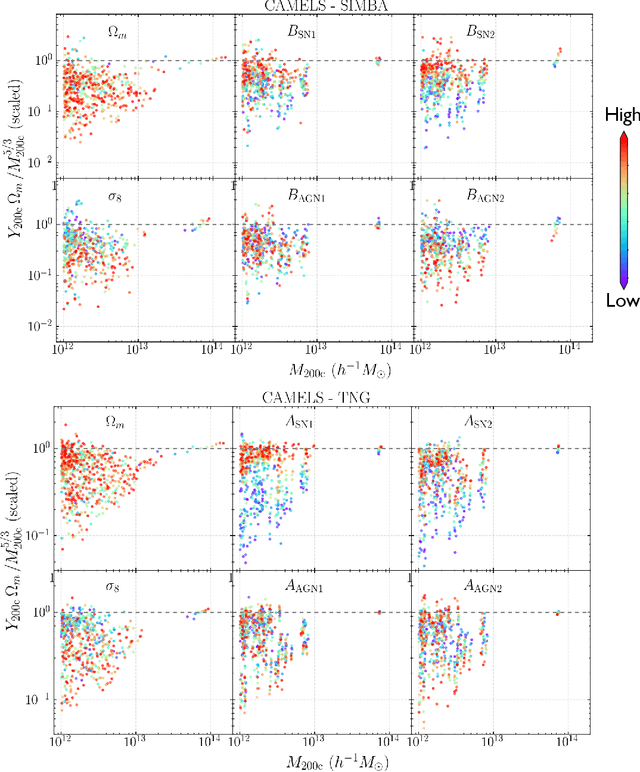
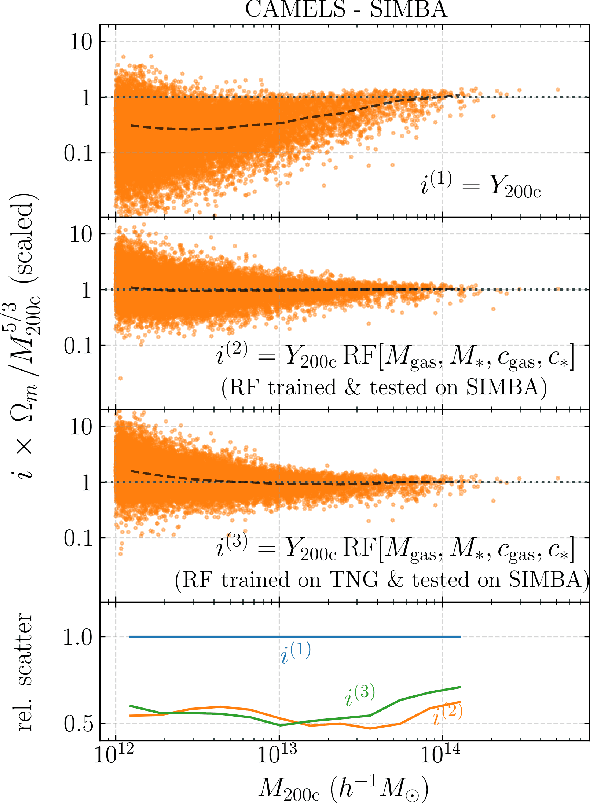

Ionized gas in the halo circumgalactic medium leaves an imprint on the cosmic microwave background via the thermal Sunyaev-Zeldovich (tSZ) effect. Feedback from active galactic nuclei (AGN) and supernovae can affect the measurements of the integrated tSZ flux of halos ($Y_\mathrm{SZ}$) and cause its relation with the halo mass ($Y_\mathrm{SZ}-M$) to deviate from the self-similar power-law prediction of the virial theorem. We perform a comprehensive study of such deviations using CAMELS, a suite of hydrodynamic simulations with extensive variations in feedback prescriptions. We use a combination of two machine learning tools (random forest and symbolic regression) to search for analogues of the $Y-M$ relation which are more robust to feedback processes for low masses ($M\lesssim 10^{14}\, h^{-1} \, M_\odot$); we find that simply replacing $Y\rightarrow Y(1+M_*/M_\mathrm{gas})$ in the relation makes it remarkably self-similar. This could serve as a robust multiwavelength mass proxy for low-mass clusters and galaxy groups. Our methodology can also be generally useful to improve the domain of validity of other astrophysical scaling relations. We also forecast that measurements of the $Y-M$ relation could provide percent-level constraints on certain combinations of feedback parameters and/or rule out a major part of the parameter space of supernova and AGN feedback models used in current state-of-the-art hydrodynamic simulations. Our results can be useful for using upcoming SZ surveys (e.g. SO, CMB-S4) and galaxy surveys (e.g. DESI and Rubin) to constrain the nature of baryonic feedback. Finally, we find that the an alternative relation, $Y-M_*$, provides complementary information on feedback than $Y-M$.