 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Automated Classification of General Movements in Infants Using a Two-stream Spatiotemporal Fusion Network
Jul 04, 2022
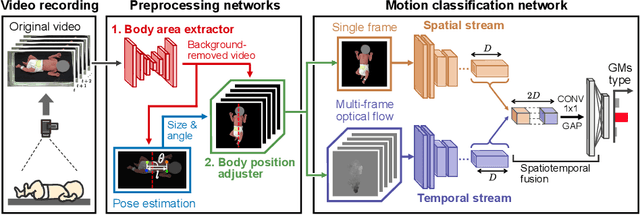
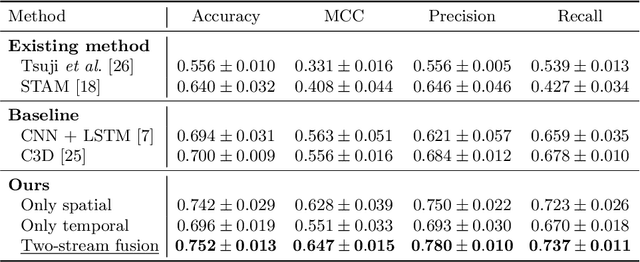
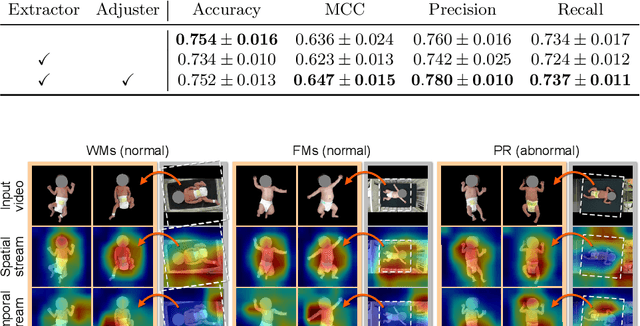
The assessment of general movements (GMs) in infants is a useful tool in the early diagnosis of neurodevelopmental disorders. However, its evaluation in clinical practice relies on visual inspection by experts, and an automated solution is eagerly awaited. Recently, video-based GMs classification has attracted attention, but this approach would be strongly affected by irrelevant information, such as background clutter in the video. Furthermore, for reliability, it is necessary to properly extract the spatiotemporal features of infants during GMs. In this study, we propose an automated GMs classification method, which consists of preprocessing networks that remove unnecessary background information from GMs videos and adjust the infant's body position, and a subsequent motion classification network based on a two-stream structure. The proposed method can efficiently extract the essential spatiotemporal features for GMs classification while preventing overfitting to irrelevant information for different recording environments. We validated the proposed method using videos obtained from 100 infants. The experimental results demonstrate that the proposed method outperforms several baseline models and the existing methods.
RLang: A Declarative Language for Expression Prior Knowledge for Reinforcement Learning
Aug 16, 2022

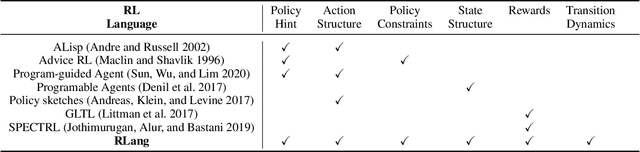
Communicating useful background knowledge to reinforcement learning (RL) agents is an important and effective method for accelerating learning. We introduce RLang, a domain-specific language (DSL) for communicating domain knowledge to an RL agent. Unlike other existing DSLs proposed by the RL community that ground to single elements of a decision-making formalism (e.g., the reward function or policy function), RLang can specify information about every element of a Markov decision process. We define precise syntax and grounding semantics for RLang, and provide a parser implementation that grounds RLang programs to an algorithm-agnostic partial world model and policy that can be exploited by an RL agent. We provide a series of example RLang programs, and demonstrate how different RL methods can exploit the resulting knowledge, including model-free and model-based tabular algorithms, hierarchical approaches, and deep RL algorithms (including both policy gradient and value-based methods).
QA Is the New KR: Question-Answer Pairs as Knowledge Bases
Jul 01, 2022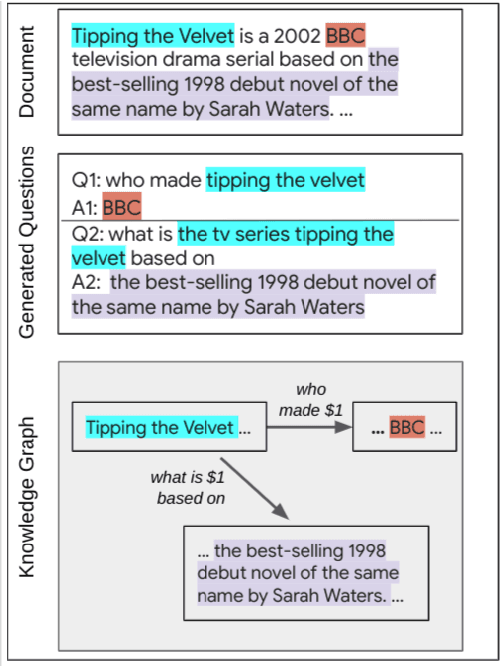
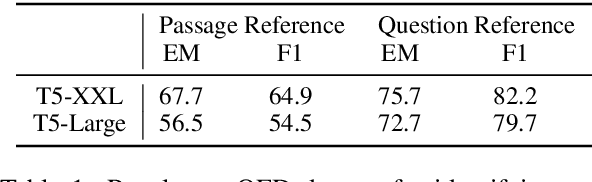
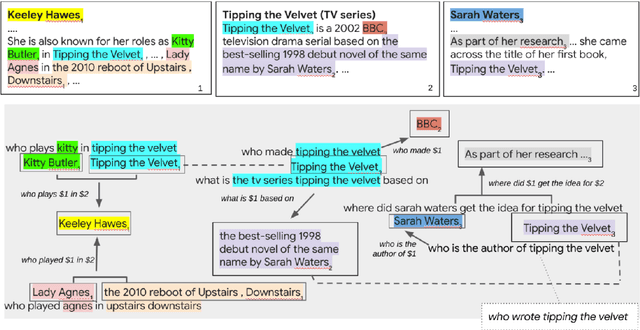
In this position paper, we propose a new approach to generating a type of knowledge base (KB) from text, based on question generation and entity linking. We argue that the proposed type of KB has many of the key advantages of a traditional symbolic KB: in particular, it consists of small modular components, which can be combined compositionally to answer complex queries, including relational queries and queries involving "multi-hop" inferences. However, unlike a traditional KB, this information store is well-aligned with common user information needs.
Uncertainty quantification for predictions of atomistic neural networks
Jul 14, 2022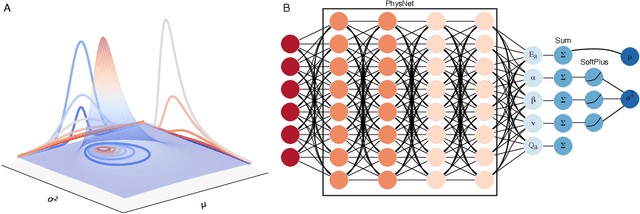
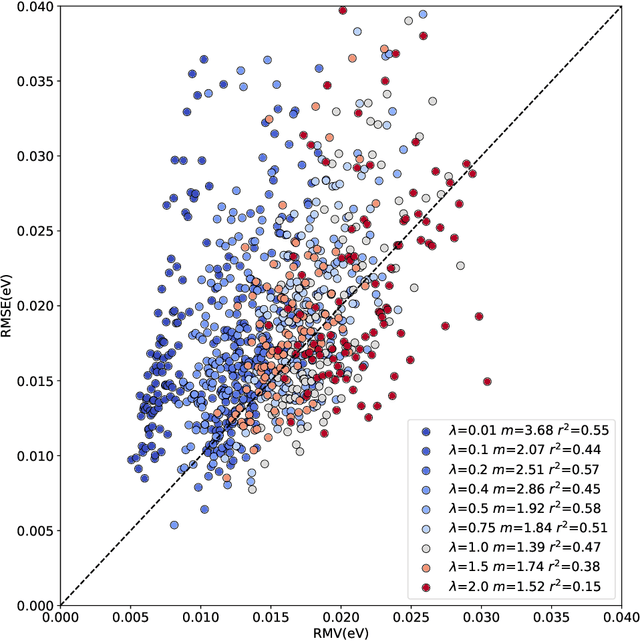
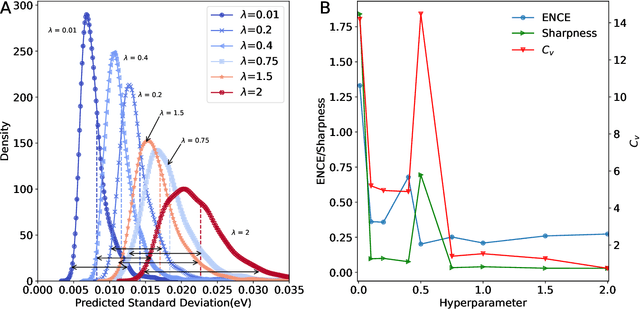
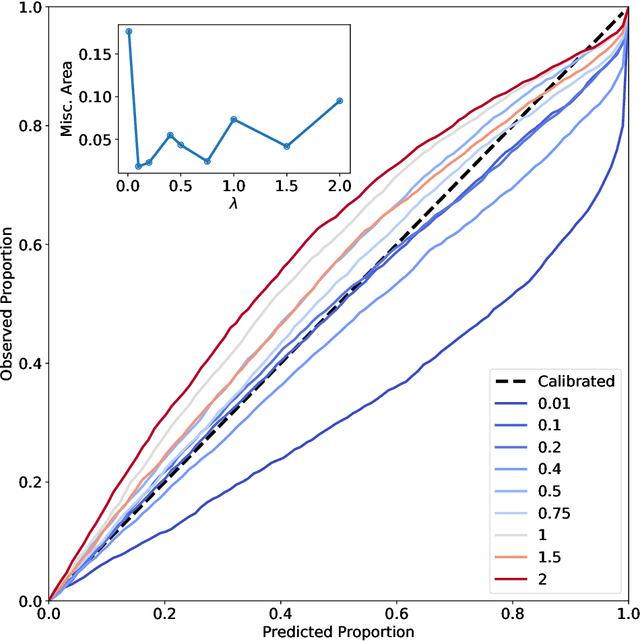
The value of uncertainty quantification on predictions for trained neural networks (NNs) on quantum chemical reference data is quantitatively explored. For this, the architecture of the PhysNet NN was suitably modified and the resulting model was evaluated with different metrics to quantify calibration, quality of predictions, and whether prediction error and the predicted uncertainty can be correlated. The results from training on the QM9 database and evaluating data from the test set within and outside the distribution indicate that error and uncertainty are not linearly related. The results clarify that noise and redundancy complicate property prediction for molecules even in cases for which changes - e.g. double bond migration in two otherwise identical molecules - are small. The model was then applied to a real database of tautomerization reactions. Analysis of the distance between members in feature space combined with other parameters shows that redundant information in the training dataset can lead to large variances and small errors whereas the presence of similar but unspecific information returns large errors but small variances. This was, e.g., observed for nitro-containing aliphatic chains for which predictions were difficult although the training set contained several examples for nitro groups bound to aromatic molecules. This underlines the importance of the composition of the training data and provides chemical insight into how this affects the prediction capabilities of a ML model. Finally, the approach put forward can be used for information-based improvement of chemical databases for target applications through active learning optimization.
An Object Deformation-Agnostic Framework for Human-Robot Collaborative Transportation
Jul 27, 2022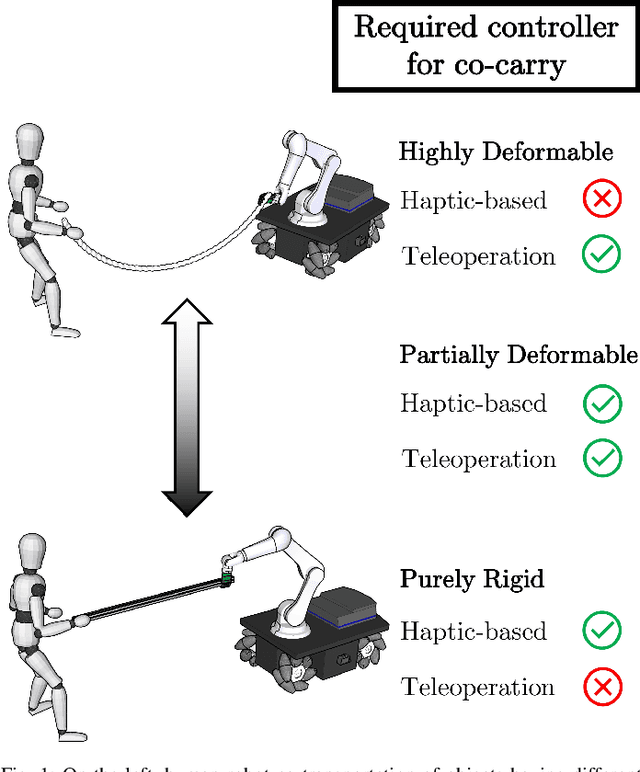
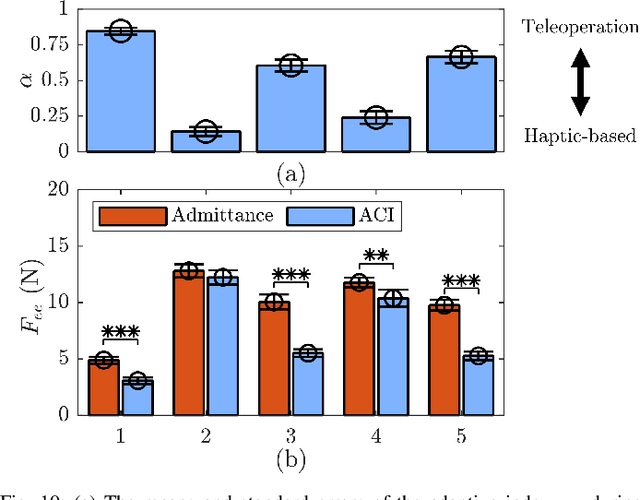
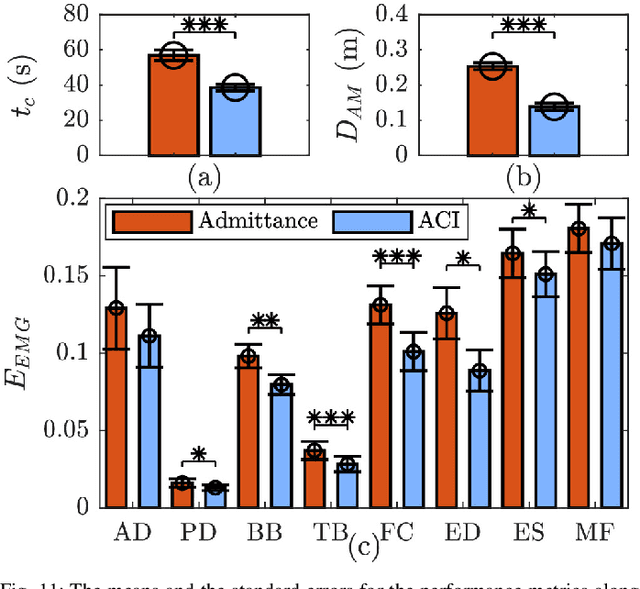
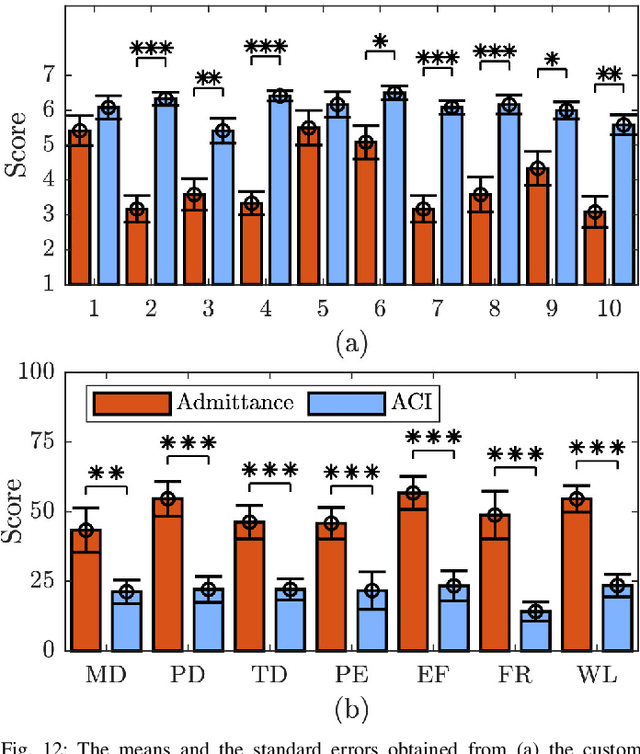
In this study, an adaptive object deformability-agnostic human-robot collaborative transportation framework is presented. The proposed framework enables to combine the haptic information transferred through the object with the human kinematic information obtained from a motion capture system to generate reactive whole-body motions on a mobile collaborative robot. Furthermore, it allows rotating the objects in an intuitive and accurate way during co-transportation based on an algorithm that detects the human rotation intention using the torso and hand movements. First, we validate the framework with the two extremities of the object deformability range (i.e, purely rigid aluminum rod and highly deformable rope) by utilizing a mobile manipulator which consists of an Omni-directional mobile base and a collaborative robotic arm. Next, its performance is compared with an admittance controller during a co-carry task of a partially deformable object in a 12-subjects user study. Quantitative and qualitative results of this experiment show that the proposed framework can effectively handle the transportation of objects regardless of their deformability and provides intuitive assistance to human partners. Finally, we have demonstrated the potential of our framework in a different scenario, where the human and the robot co-transport a manikin using a deformable sheet.
Meta-learning using privileged information for dynamics
Apr 29, 2021
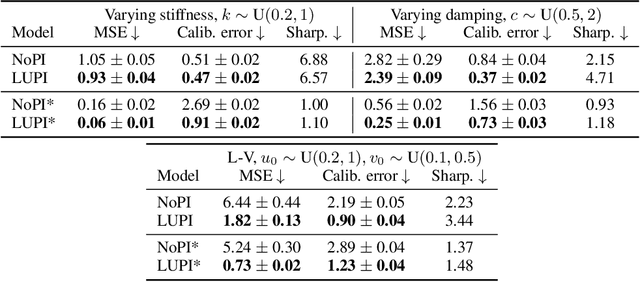
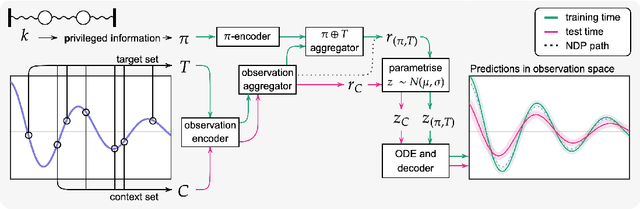

Neural ODE Processes approach the problem of meta-learning for dynamics using a latent variable model, which permits a flexible aggregation of contextual information. This flexibility is inherited from the Neural Process framework and allows the model to aggregate sets of context observations of arbitrary size into a fixed-length representation. In the physical sciences, we often have access to structured knowledge in addition to raw observations of a system, such as the value of a conserved quantity or a description of an understood component. Taking advantage of the aggregation flexibility, we extend the Neural ODE Process model to use additional information within the Learning Using Privileged Information setting, and we validate our extension with experiments showing improved accuracy and calibration on simulated dynamics tasks.
H2-Stereo: High-Speed, High-Resolution Stereoscopic Video System
Aug 04, 2022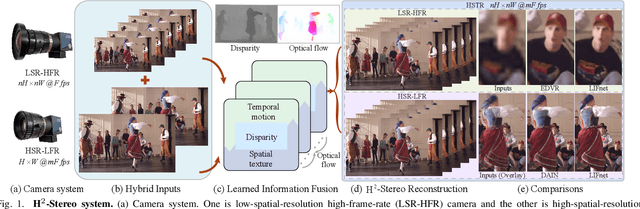



High-speed, high-resolution stereoscopic (H2-Stereo) video allows us to perceive dynamic 3D content at fine granularity. The acquisition of H2-Stereo video, however, remains challenging with commodity cameras. Existing spatial super-resolution or temporal frame interpolation methods provide compromised solutions that lack temporal or spatial details, respectively. To alleviate this problem, we propose a dual camera system, in which one camera captures high-spatial-resolution low-frame-rate (HSR-LFR) videos with rich spatial details, and the other captures low-spatial-resolution high-frame-rate (LSR-HFR) videos with smooth temporal details. We then devise a Learned Information Fusion network (LIFnet) that exploits the cross-camera redundancies to enhance both camera views to high spatiotemporal resolution (HSTR) for reconstructing the H2-Stereo video effectively. We utilize a disparity network to transfer spatiotemporal information across views even in large disparity scenes, based on which, we propose disparity-guided flow-based warping for LSR-HFR view and complementary warping for HSR-LFR view. A multi-scale fusion method in feature domain is proposed to minimize occlusion-induced warping ghosts and holes in HSR-LFR view. The LIFnet is trained in an end-to-end manner using our collected high-quality Stereo Video dataset from YouTube. Extensive experiments demonstrate that our model outperforms existing state-of-the-art methods for both views on synthetic data and camera-captured real data with large disparity. Ablation studies explore various aspects, including spatiotemporal resolution, camera baseline, camera desynchronization, long/short exposures and applications, of our system to fully understand its capability for potential applications.
Efficient Video Deblurring Guided by Motion Magnitude
Jul 27, 2022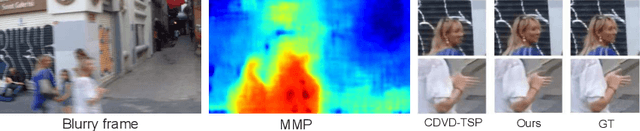

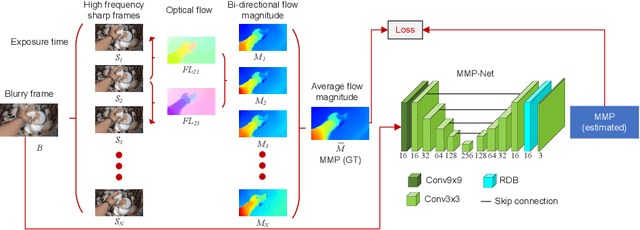
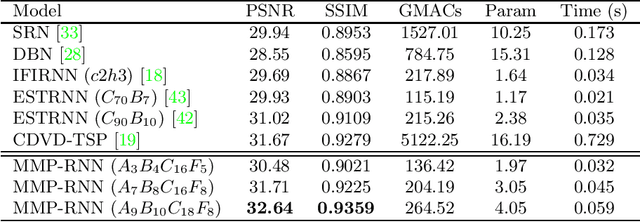
Video deblurring is a highly under-constrained problem due to the spatially and temporally varying blur. An intuitive approach for video deblurring includes two steps: a) detecting the blurry region in the current frame; b) utilizing the information from clear regions in adjacent frames for current frame deblurring. To realize this process, our idea is to detect the pixel-wise blur level of each frame and combine it with video deblurring. To this end, we propose a novel framework that utilizes the motion magnitude prior (MMP) as guidance for efficient deep video deblurring. Specifically, as the pixel movement along its trajectory during the exposure time is positively correlated to the level of motion blur, we first use the average magnitude of optical flow from the high-frequency sharp frames to generate the synthetic blurry frames and their corresponding pixel-wise motion magnitude maps. We then build a dataset including the blurry frame and MMP pairs. The MMP is then learned by a compact CNN by regression. The MMP consists of both spatial and temporal blur level information, which can be further integrated into an efficient recurrent neural network (RNN) for video deblurring. We conduct intensive experiments to validate the effectiveness of the proposed methods on the public datasets.
Variational Leakage: The Role of Information Complexity in Privacy Leakage
Jun 05, 2021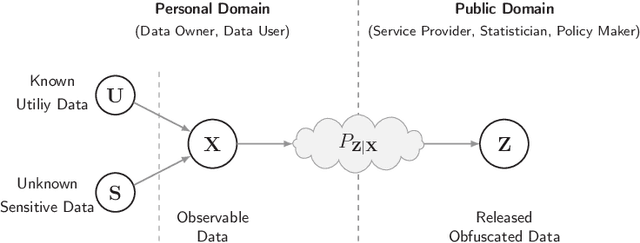
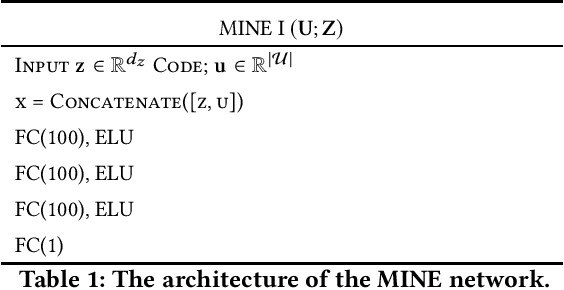
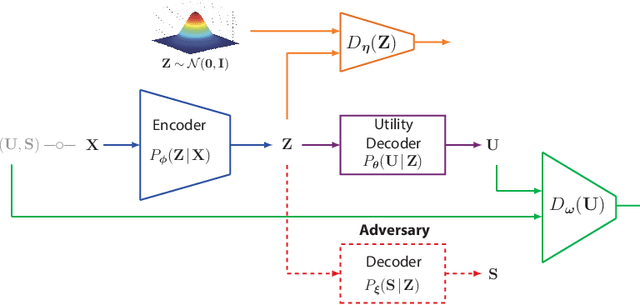

We study the role of information complexity in privacy leakage about an attribute of an adversary's interest, which is not known a priori to the system designer. Considering the supervised representation learning setup and using neural networks to parameterize the variational bounds of information quantities, we study the impact of the following factors on the amount of information leakage: information complexity regularizer weight, latent space dimension, the cardinalities of the known utility and unknown sensitive attribute sets, the correlation between utility and sensitive attributes, and a potential bias in a sensitive attribute of adversary's interest. We conduct extensive experiments on Colored-MNIST and CelebA datasets to evaluate the effect of information complexity on the amount of intrinsic leakage.
A multimedia recommendation model based on collaborative graph
May 30, 2022
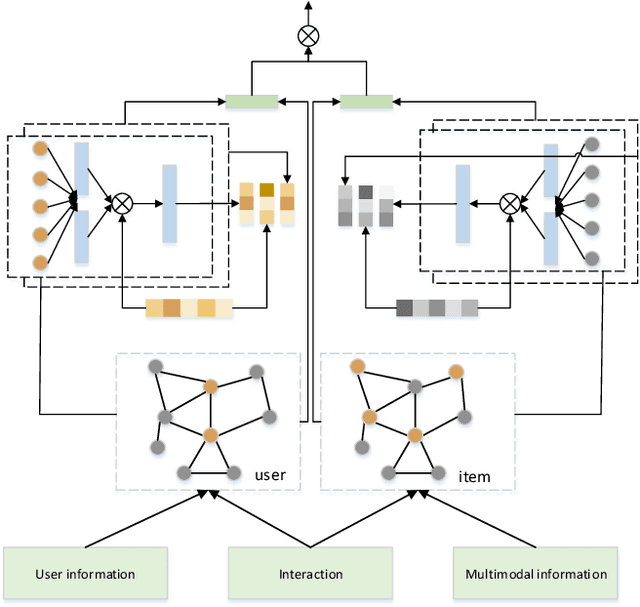
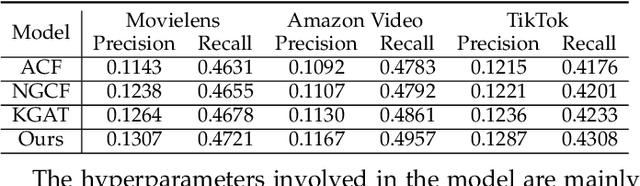
As one of the main solutions to the information overload problem, recommender systems are widely used in daily life. In the recent emerging micro-video recommendation scenario, micro-videos contain rich multimedia information, involving text, image, video and other multimodal data, and these rich multimodal information conceals users' deep interest in the items. Most of the current recommendation algorithms based on multimodal data use multimodal information to expand the information on the item side, but ignore the different preferences of users for different modal information, and lack the fine-grained mining of the internal connection of multimodal information. To investigate the problems in the micro-video recommendr system mentioned above, we design a hybrid recommendation model based on multimodal information, introduces multimodal information and user-side auxiliary information in the network structure, fully explores the deep interest of users, measures the importance of each dimension of user and item feature representation in the scoring prediction task, makes the application of graph neural network in the recommendation system is improved by using an attention mechanism to fuse the multi-layer state output information, allowing the shallow structural features provided by the intermediate layer to better participate in the prediction task. The recommendation accuracy is improved compared with the traditional recommendation algorithm on different data sets, and the feasibility and effectiveness of our model is verified.