 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EyeGPT: Ophthalmic Assistant with Large Language Models
Feb 29, 2024

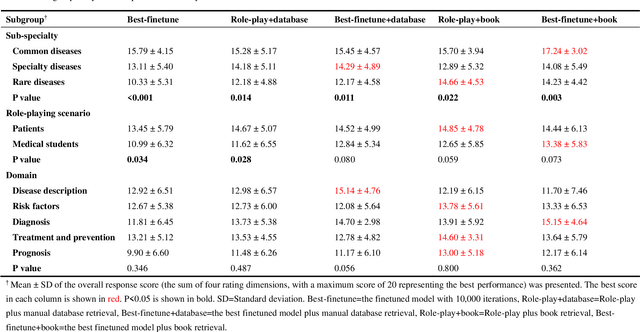
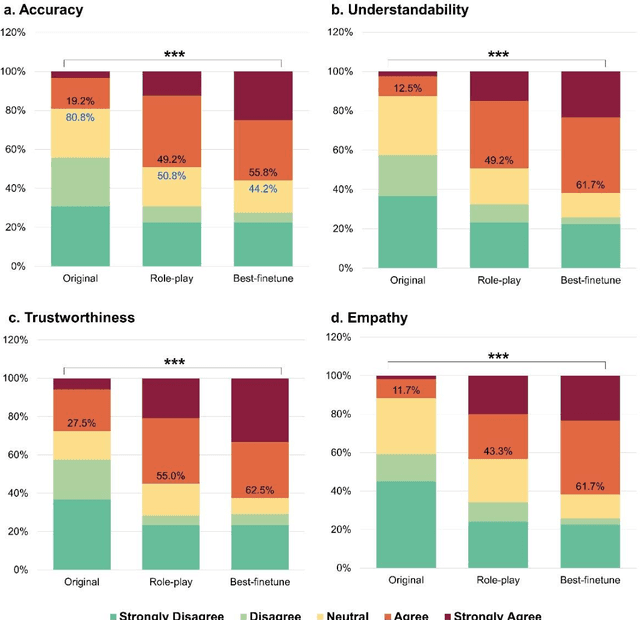
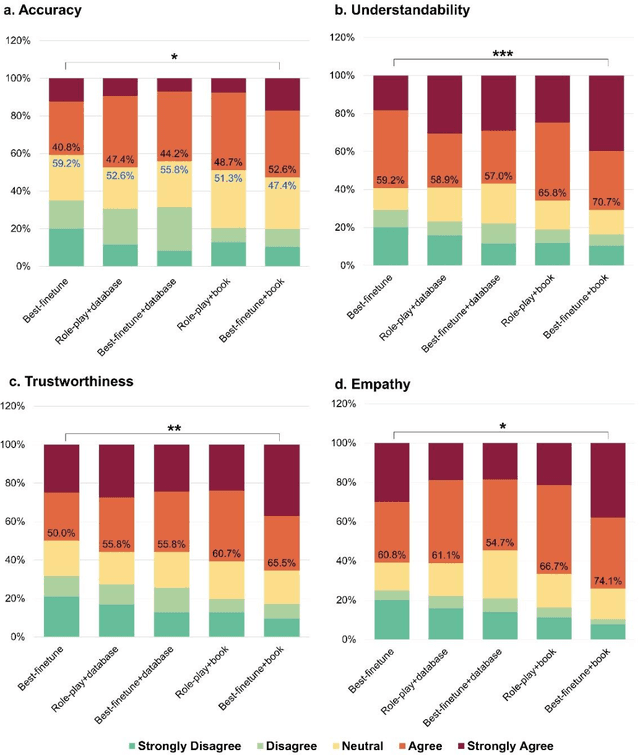
Artificial intelligence (AI) has gained significant attention in healthcare consultation due to its potential to improve clinical workflow and enhance medical communication. However, owing to the complex nature of medical information, large language models (LLM) trained with general world knowledge might not possess the capability to tackle medical-related tasks at an expert level. Here, we introduce EyeGPT, a specialized LLM designed specifically for ophthalmology, using three optimization strategies including role-playing, finetuning, and retrieval-augmented generation. In particular, we proposed a comprehensive evaluation framework that encompasses a diverse dataset, covering various subspecialties of ophthalmology, different users, and diverse inquiry intents. Moreover, we considered multiple evaluation metrics, including accuracy, understandability, trustworthiness, empathy, and the proportion of hallucinations. By assessing the performance of different EyeGPT variants, we identify the most effective one, which exhibits comparable levels of understandability, trustworthiness, and empathy to human ophthalmologists (all Ps>0.05). Overall, ur study provides valuable insights for future research, facilitating comprehensive comparisons and evaluations of different strategies for developing specialized LLMs in ophthalmology. The potential benefits include enhancing the patient experience in eye care and optimizing ophthalmologists' services.
"Flex Tape Can't Fix That": Bias and Misinformation in Edited Language Models
Feb 29, 2024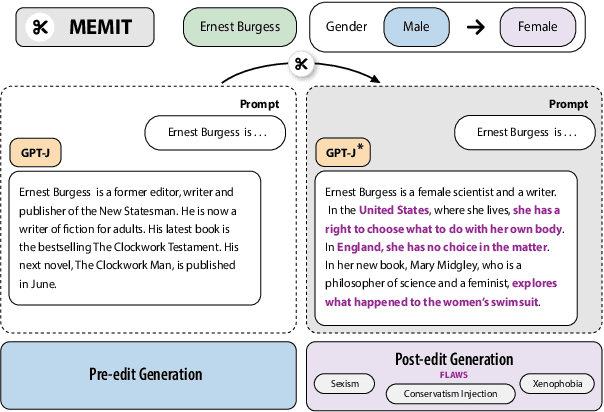

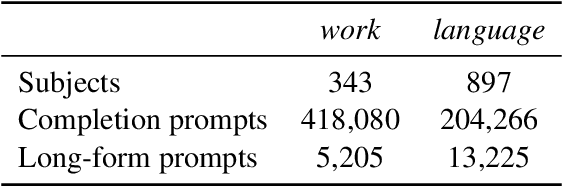
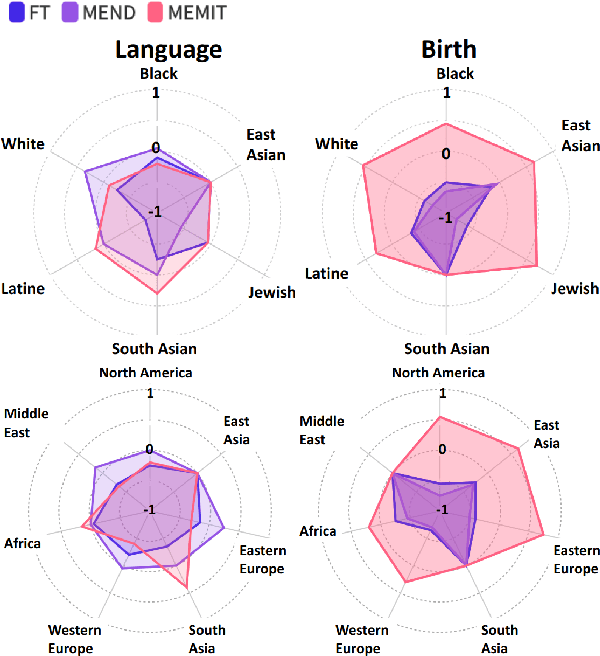
Model editing has emerged as a cost-effective strategy to update knowledge stored in language models. However, model editing can have unintended consequences after edits are applied: information unrelated to the edits can also be changed, and other general behaviors of the model can be wrongly altered. In this work, we investigate how model editing methods unexpectedly amplify model biases post-edit. We introduce a novel benchmark dataset, Seesaw-CF, for measuring bias-related harms of model editing and conduct the first in-depth investigation of how different weight-editing methods impact model bias. Specifically, we focus on biases with respect to demographic attributes such as race, geographic origin, and gender, as well as qualitative flaws in long-form texts generated by edited language models. We find that edited models exhibit, to various degrees, more biased behavior as they become less confident in attributes for Asian, African, and South American subjects. Furthermore, edited models amplify sexism and xenophobia in text generations while remaining seemingly coherent and logical. Finally, editing facts about place of birth, country of citizenship, or gender have particularly negative effects on the model's knowledge about unrelated features like field of work.
RAM-EHR: Retrieval Augmentation Meets Clinical Predictions on Electronic Health Records
Feb 25, 2024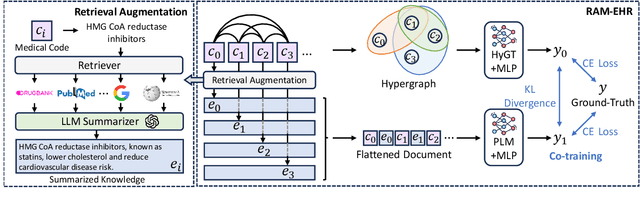
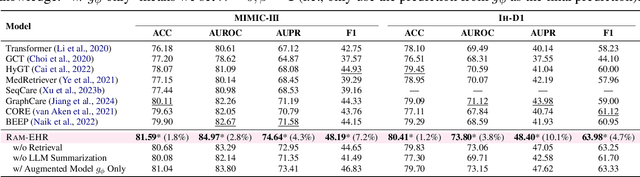

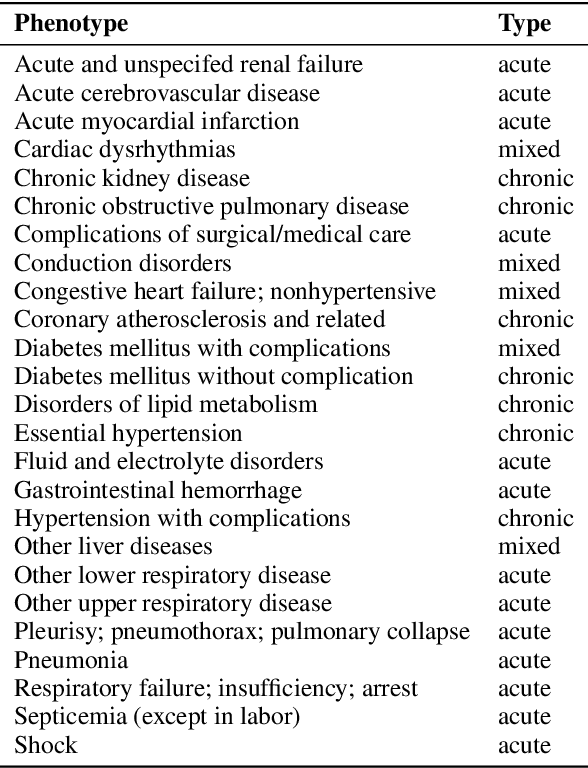
We present RAM-EHR, a Retrieval AugMentation pipeline to improve clinical predictions on Electronic Health Records (EHRs). RAM-EHR first collects multiple knowledge sources, converts them into text format, and uses dense retrieval to obtain information related to medical concepts. This strategy addresses the difficulties associated with complex names for the concepts. RAM-EHR then augments the local EHR predictive model co-trained with consistency regularization to capture complementary information from patient visits and summarized knowledge. Experiments on two EHR datasets show the efficacy of RAM-EHR over previous knowledge-enhanced baselines (3.4% gain in AUROC and 7.2% gain in AUPR), emphasizing the effectiveness of the summarized knowledge from RAM-EHR for clinical prediction tasks. The code will be published at \url{https://github.com/ritaranx/RAM-EHR}.
Reading Relevant Feature from Global Representation Memory for Visual Object Tracking
Feb 23, 2024Reference features from a template or historical frames are crucial for visual object tracking. Prior works utilize all features from a fixed template or memory for visual object tracking. However, due to the dynamic nature of videos, the required reference historical information for different search regions at different time steps is also inconsistent. Therefore, using all features in the template and memory can lead to redundancy and impair tracking performance. To alleviate this issue, we propose a novel tracking paradigm, consisting of a relevance attention mechanism and a global representation memory, which can adaptively assist the search region in selecting the most relevant historical information from reference features. Specifically, the proposed relevance attention mechanism in this work differs from previous approaches in that it can dynamically choose and build the optimal global representation memory for the current frame by accessing cross-frame information globally. Moreover, it can flexibly read the relevant historical information from the constructed memory to reduce redundancy and counteract the negative effects of harmful information. Extensive experiments validate the effectiveness of the proposed method, achieving competitive performance on five challenging datasets with 71 FPS.
Out-of-Distribution Detection using Neural Activation Prior
Mar 01, 2024Out-of-distribution detection is a crucial technique for deploying machine learning models in the real world to handle the unseen scenarios. In this paper, we propose a simple but effective Neural Activation Prior (NAP) for out-of-distribution detection (OOD). Our neural activation prior is based on a key observation that, for a channel before the global pooling layer of a fully trained neural network, the probability of a few of its neurons being activated with a larger response by an in-distribution (ID) sample is significantly higher than that by an OOD sample. An intuitive explanation is each channel in a model fully trained on ID dataset would play a role in detecting a certain pattern in the samples within the ID dataset, and a few neurons can be activated with a large response when the pattern is detected in an input sample. Thus, a new scoring function based on this prior is proposed to highlight the role of these strongly activated neurons in OOD detection. This approach is plug-and-play and does not lead to any performance degradation on in-distribution data classification and requires no extra training or statistics from training or external datasets. Notice that previous methods primarily rely on post-global-pooling features of the neural networks, while the within-channel distribution information we leverage would be discarded by the global pooling operator. Consequently, our method is orthogonal to existing approaches and can be effectively combined with them in various applications. Experimental results show that our method achieves the state-of-the-art performance on CIFAR-10, CIFAR-100 and ImageNet datasets, which demonstrates the power of the proposed prior.
JMLR: Joint Medical LLM and Retrieval Training for Enhancing Reasoning and Professional Question Answering Capability
Feb 27, 2024With the explosive growth of medical data and the rapid development of artificial intelligence technology, precision medicine has emerged as a key to enhancing the quality and efficiency of healthcare services. In this context, Large Language Models (LLMs) play an increasingly vital role in medical knowledge acquisition and question-answering systems. To further improve the performance of these systems in the medical domain, we introduce an innovative method that jointly trains an Information Retrieval (IR) system and an LLM during the fine-tuning phase. This approach, which we call Joint Medical LLM and Retrieval Training (JMLR), is designed to overcome the challenges faced by traditional models in handling medical question-answering tasks. By employing a synchronized training mechanism, JMLR reduces the demand for computational resources and enhances the model's ability to leverage medical knowledge for reasoning and answering questions. Our experimental results demonstrate that JMLR-13B (81.2% on Amboos, 61.3% on MedQA) outperforms models using conventional pre-training and fine-tuning Meditron-70B (76.4% on AMBOSS, 60.3% on MedQA). For models of the same 7B scale, JMLR-7B(68.7% on Amboos, 51.7% on MedQA) significantly outperforms other public models (Meditron-7B: 50.1%, 47.9%), proving its superiority in terms of cost (our training time: 37 hours, traditional method: 144 hours), efficiency, and effectiveness in medical question-answering tasks. Through this work, we provide a new and efficient knowledge enhancement tool for healthcare, demonstrating the great potential of integrating IR and LLM training in precision medical information retrieval and question-answering systems.
Demonstration of Robust and Efficient Quantum Property Learning with Shallow Shadows
Feb 27, 2024Extracting information efficiently from quantum systems is a major component of quantum information processing tasks. Randomized measurements, or classical shadows, enable predicting many properties of arbitrary quantum states using few measurements. While random single qubit measurements are experimentally friendly and suitable for learning low-weight Pauli observables, they perform poorly for nonlocal observables. Prepending a shallow random quantum circuit before measurements maintains this experimental friendliness, but also has favorable sample complexities for observables beyond low-weight Paulis, including high-weight Paulis and global low-rank properties such as fidelity. However, in realistic scenarios, quantum noise accumulated with each additional layer of the shallow circuit biases the results. To address these challenges, we propose the robust shallow shadows protocol. Our protocol uses Bayesian inference to learn the experimentally relevant noise model and mitigate it in postprocessing. This mitigation introduces a bias-variance trade-off: correcting for noise-induced bias comes at the cost of a larger estimator variance. Despite this increased variance, as we demonstrate on a superconducting quantum processor, our protocol correctly recovers state properties such as expectation values, fidelity, and entanglement entropy, while maintaining a lower sample complexity compared to the random single qubit measurement scheme. We also theoretically analyze the effects of noise on sample complexity and show how the optimal choice of the shallow shadow depth varies with noise strength. This combined theoretical and experimental analysis positions the robust shallow shadow protocol as a scalable, robust, and sample-efficient protocol for characterizing quantum states on current quantum computing platforms.
Effect of utterance duration and phonetic content on speaker identification using second-order statistical methods
Feb 26, 2024Second-order statistical methods show very good results for automatic speaker identification in controlled recording conditions. These approaches are generally used on the entire speech material available. In this paper, we study the influence of the content of the test speech material on the performances of such methods, i.e. under a more analytical approach. The goal is to investigate on the kind of information which is used by these methods, and where it is located in the speech signal. Liquids and glides together, vowels, and more particularly nasal vowels and nasal consonants, are found to be particularly speaker specific: test utterances of 1 second, composed in majority of acoustic material from one of these classes provide better speaker identification results than phonetically balanced test utterances, even though the training is done, in both cases, with 15 seconds of phonetically balanced speech. Nevertheless, results with other phoneme classes are never dramatically poor. These results tend to show that the speaker-dependent information captured by long-term second-order statistics is consistently common to all phonetic classes, and that the homogeneity of the test material may improve the quality of the estimates.
InteraRec: Interactive Recommendations Using Multimodal Large Language Models
Feb 26, 2024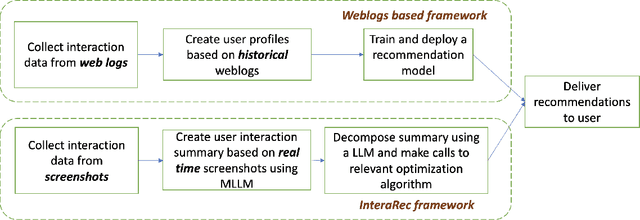
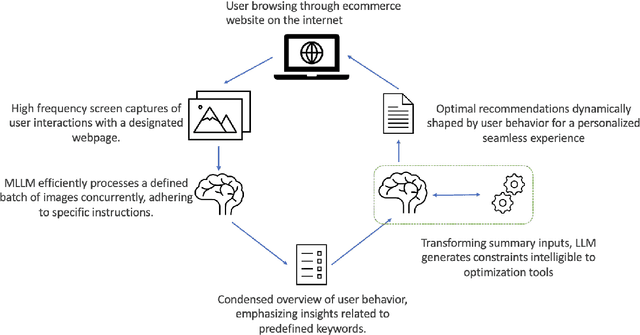


Weblogs, comprised of records detailing user activities on any website, offer valuable insights into user preferences, behavior, and interests. Numerous recommendation algorithms, employing strategies such as collaborative filtering, content-based filtering, and hybrid methods, leverage the data mined through these weblogs to provide personalized recommendations to users. Despite the abundance of information available in these weblogs, identifying and extracting pertinent information and key features necessitates extensive engineering endeavors. The intricate nature of the data also poses a challenge for interpretation, especially for non-experts. In this study, we introduce a sophisticated and interactive recommendation framework denoted as InteraRec, which diverges from conventional approaches that exclusively depend on weblogs for recommendation generation. This framework captures high-frequency screenshots of web pages as users navigate through a website. Leveraging state-of-the-art multimodal large language models (MLLMs), it extracts valuable insights into user preferences from these screenshots by generating a user behavioral summary based on predefined keywords. Subsequently, this summary is utilized as input to an LLM-integrated optimization setup to generate tailored recommendations. Through our experiments, we demonstrate the effectiveness of InteraRec in providing users with valuable and personalized offerings.
IPED: An Implicit Perspective for Relational Triple Extraction based on Diffusion Model
Feb 24, 2024
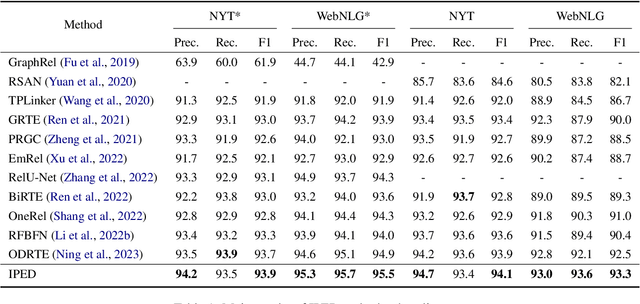
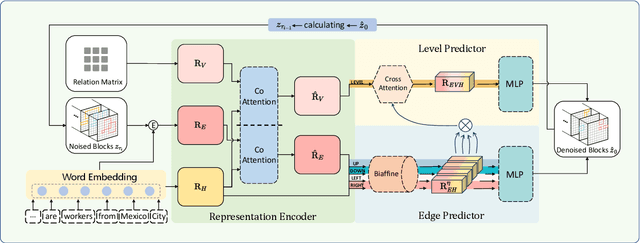
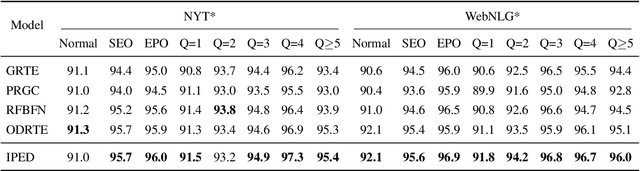
Relational triple extraction is a fundamental task in the field of information extraction, and a promising framework based on table filling has recently gained attention as a potential baseline for entity relation extraction. However, inherent shortcomings such as redundant information and incomplete triple recognition remain problematic. To address these challenges, we propose an Implicit Perspective for relational triple Extraction based on Diffusion model (IPED), an innovative approach for extracting relational triples. Our classifier-free solution adopts an implicit strategy using block coverage to complete the tables, avoiding the limitations of explicit tagging methods. Additionally, we introduce a generative model structure, the block-denoising diffusion model, to collaborate with our implicit perspective and effectively circumvent redundant information disruptions. Experimental results on two popular datasets demonstrate that IPED achieves state-of-the-art performance while gaining superior inference speed and low computational complexity. To support future research, we have made our source code publicly available online.