 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Time-distance vision transformers in lung cancer diagnosis from longitudinal computed tomography
Sep 04, 2022
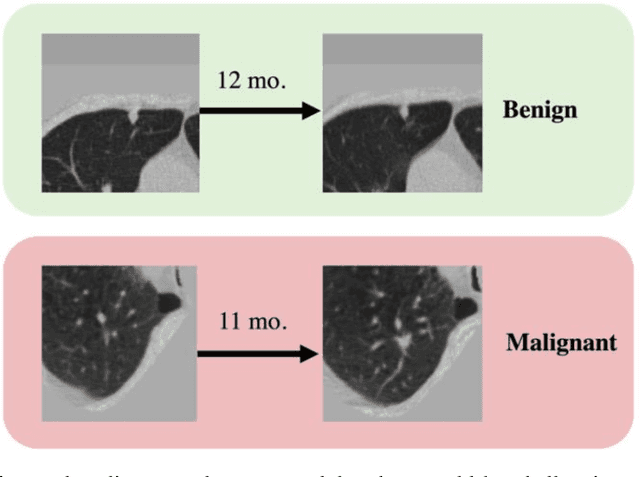

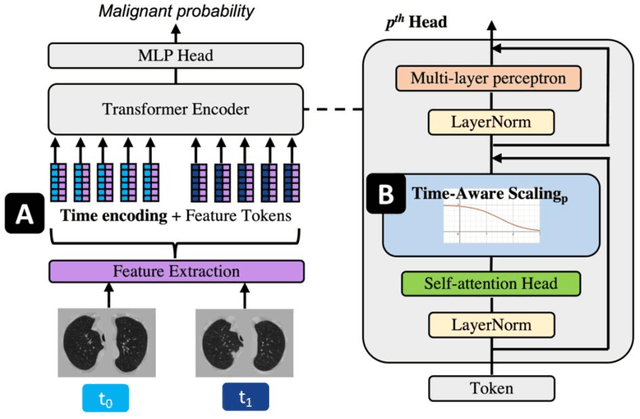

Features learned from single radiologic images are unable to provide information about whether and how much a lesion may be changing over time. Time-dependent features computed from repeated images can capture those changes and help identify malignant lesions by their temporal behavior. However, longitudinal medical imaging presents the unique challenge of sparse, irregular time intervals in data acquisition. While self-attention has been shown to be a versatile and efficient learning mechanism for time series and natural images, its potential for interpreting temporal distance between sparse, irregularly sampled spatial features has not been explored. In this work, we propose two interpretations of a time-distance vision transformer (ViT) by using (1) vector embeddings of continuous time and (2) a temporal emphasis model to scale self-attention weights. The two algorithms are evaluated based on benign versus malignant lung cancer discrimination of synthetic pulmonary nodules and lung screening computed tomography studies from the National Lung Screening Trial (NLST). Experiments evaluating the time-distance ViTs on synthetic nodules show a fundamental improvement in classifying irregularly sampled longitudinal images when compared to standard ViTs. In cross-validation on screening chest CTs from the NLST, our methods (0.785 and 0.786 AUC respectively) significantly outperform a cross-sectional approach (0.734 AUC) and match the discriminative performance of the leading longitudinal medical imaging algorithm (0.779 AUC) on benign versus malignant classification. This work represents the first self-attention-based framework for classifying longitudinal medical images. Our code is available at https://github.com/tom1193/time-distance-transformer.
Unsupervised Speaker Diarization that is Agnostic to Language, Overlap-Aware, and Tuning Free
Jul 25, 2022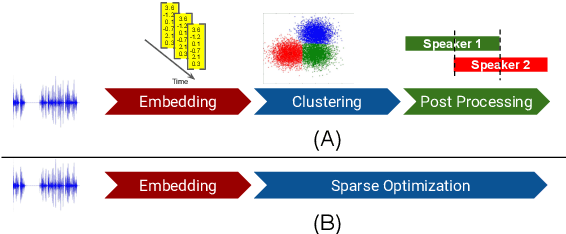
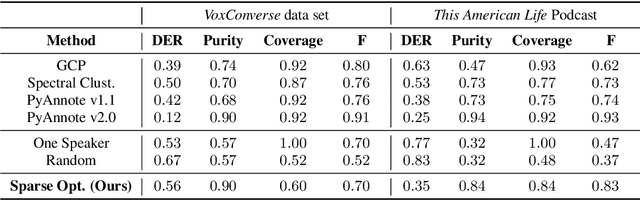
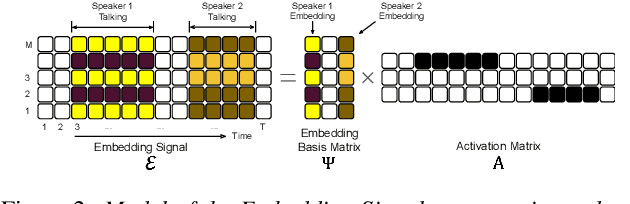
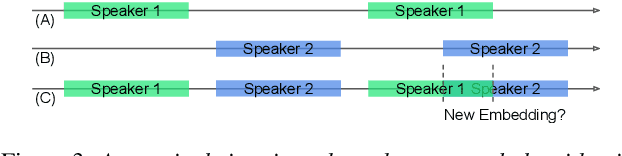
Podcasts are conversational in nature and speaker changes are frequent -- requiring speaker diarization for content understanding. We propose an unsupervised technique for speaker diarization without relying on language-specific components. The algorithm is overlap-aware and does not require information about the number of speakers. Our approach shows 79% improvement on purity scores (34% on F-score) against the Google Cloud Platform solution on podcast data.
Event-related data conditioning for acoustic event classification
Jun 16, 2022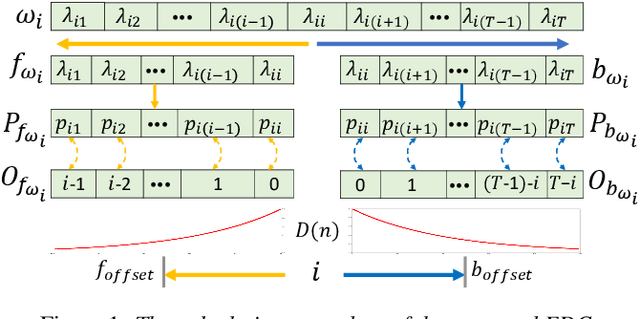
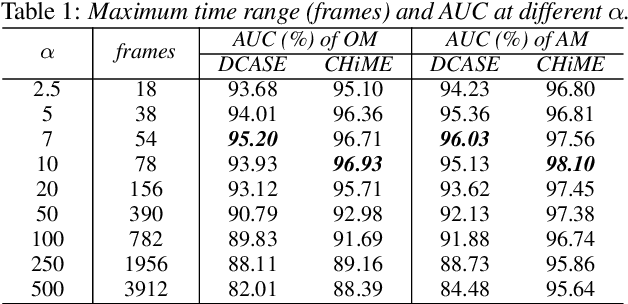
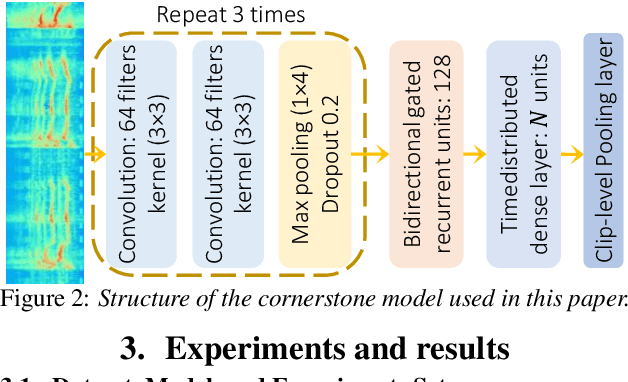
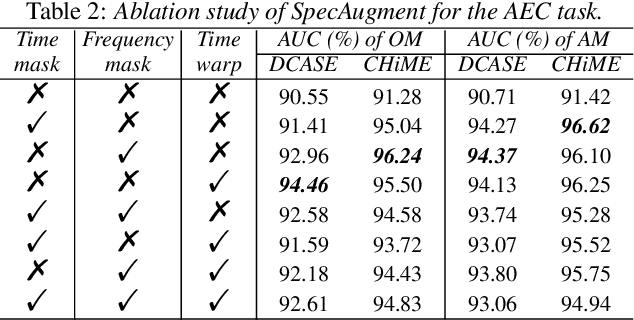
Models based on diverse attention mechanisms have recently shined in tasks related to acoustic event classification (AEC). Among them, self-attention is often used in audio-only tasks to help the model recognize different acoustic events. Self-attention relies on the similarity between time frames, and uses global information from the whole segment to highlight specific features within a frame. In real life, information related to acoustic events will attenuate over time, which means the information within some frames around the event deserves more attention than distant time global information that may be unrelated to the event. This paper shows that self-attention may over-enhance certain segments of audio representations, and smooth out the boundaries between events representations and background noises. Hence, this paper proposes an event-related data conditioning (EDC) for AEC. EDC directly works on spectrograms. The idea of EDC is to adaptively select the frame-related attention range based on acoustic features, and gather the event-related local information to represent the frame. Experiments show that: 1) compared with spectrogram-based data augmentation methods and trainable feature weighting and self-attention, EDC outperforms them in both the original-size mode and the augmented mode; 2) EDC effectively gathers event-related local information and enhances boundaries between events and backgrounds, improving the performance of AEC.
Sustaining Fairness via Incremental Learning
Aug 25, 2022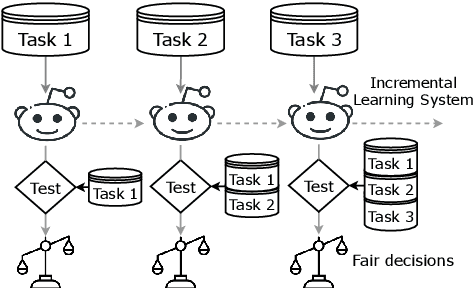
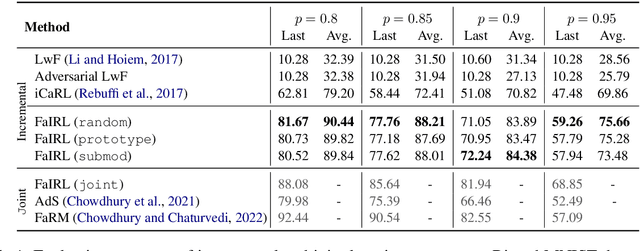
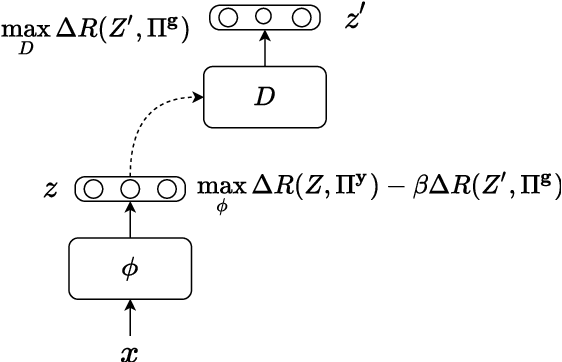
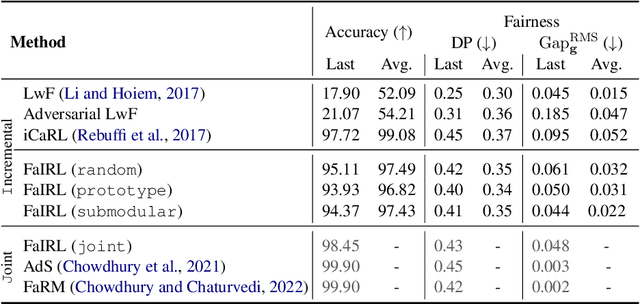
Machine learning systems are often deployed for making critical decisions like credit lending, hiring, etc. While making decisions, such systems often encode the user's demographic information (like gender, age) in their intermediate representations. This can lead to decisions that are biased towards specific demographics. Prior work has focused on debiasing intermediate representations to ensure fair decisions. However, these approaches fail to remain fair with changes in the task or demographic distribution. To ensure fairness in the wild, it is important for a system to adapt to such changes as it accesses new data in an incremental fashion. In this work, we propose to address this issue by introducing the problem of learning fair representations in an incremental learning setting. To this end, we present Fairness-aware Incremental Representation Learning (FaIRL), a representation learning system that can sustain fairness while incrementally learning new tasks. FaIRL is able to achieve fairness and learn new tasks by controlling the rate-distortion function of the learned representations. Our empirical evaluations show that FaIRL is able to make fair decisions while achieving high performance on the target task, outperforming several baselines.
Contrastive Audio-Language Learning for Music
Aug 25, 2022

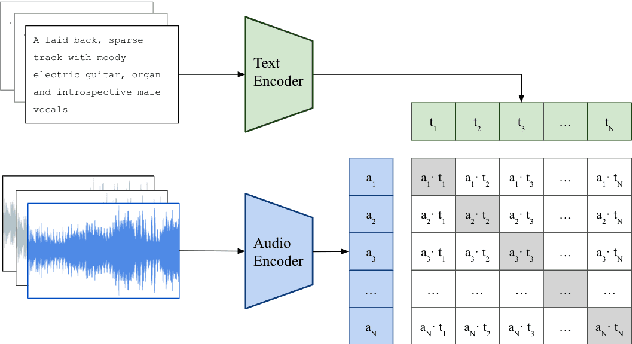
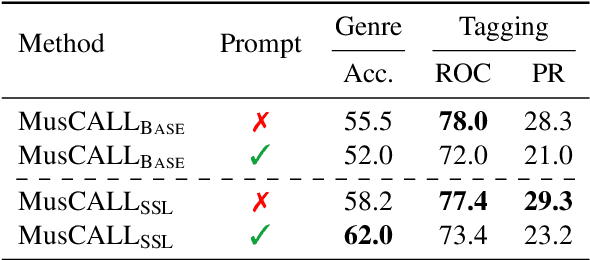
As one of the most intuitive interfaces known to humans, natural language has the potential to mediate many tasks that involve human-computer interaction, especially in application-focused fields like Music Information Retrieval. In this work, we explore cross-modal learning in an attempt to bridge audio and language in the music domain. To this end, we propose MusCALL, a framework for Music Contrastive Audio-Language Learning. Our approach consists of a dual-encoder architecture that learns the alignment between pairs of music audio and descriptive sentences, producing multimodal embeddings that can be used for text-to-audio and audio-to-text retrieval out-of-the-box. Thanks to this property, MusCALL can be transferred to virtually any task that can be cast as text-based retrieval. Our experiments show that our method performs significantly better than the baselines at retrieving audio that matches a textual description and, conversely, text that matches an audio query. We also demonstrate that the multimodal alignment capability of our model can be successfully extended to the zero-shot transfer scenario for genre classification and auto-tagging on two public datasets.
Mutual-Information Based Few-Shot Classification
Jun 23, 2021
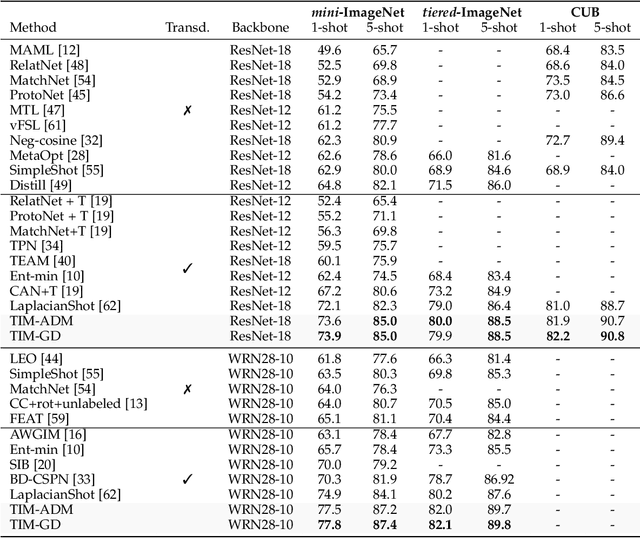
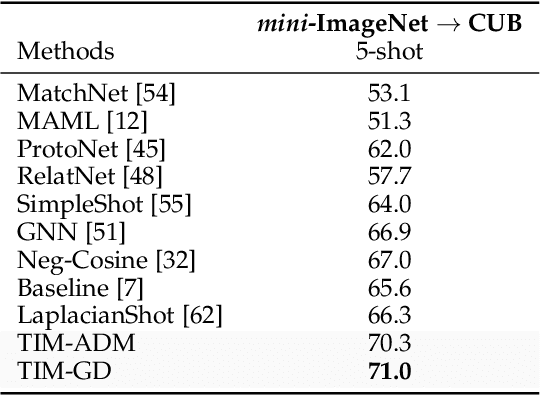
We introduce Transductive Infomation Maximization (TIM) for few-shot learning. Our method maximizes the mutual information between the query features and their label predictions for a given few-shot task, in conjunction with a supervision loss based on the support set. We motivate our transductive loss by deriving a formal relation between the classification accuracy and mutual-information maximization. Furthermore, we propose a new alternating-direction solver, which substantially speeds up transductive inference over gradient-based optimization, while yielding competitive accuracy. We also provide a convergence analysis of our solver based on Zangwill's theory and bound-optimization arguments. TIM inference is modular: it can be used on top of any base-training feature extractor. Following standard transductive few-shot settings, our comprehensive experiments demonstrate that TIM outperforms state-of-the-art methods significantly across various datasets and networks, while used on top of a fixed feature extractor trained with simple cross-entropy on the base classes, without resorting to complex meta-learning schemes. It consistently brings between 2 % and 5 % improvement in accuracy over the best performing method, not only on all the well-established few-shot benchmarks but also on more challenging scenarios, with random tasks, domain shift and larger numbers of classes, as in the recently introduced META-DATASET. Our code is publicly available at https://github.com/mboudiaf/TIM. We also publicly release a standalone PyTorch implementation of META-DATASET, along with additional benchmarking results, at https://github.com/mboudiaf/pytorch-meta-dataset.
Spatial-Temporal Identity: A Simple yet Effective Baseline for Multivariate Time Series Forecasting
Aug 19, 2022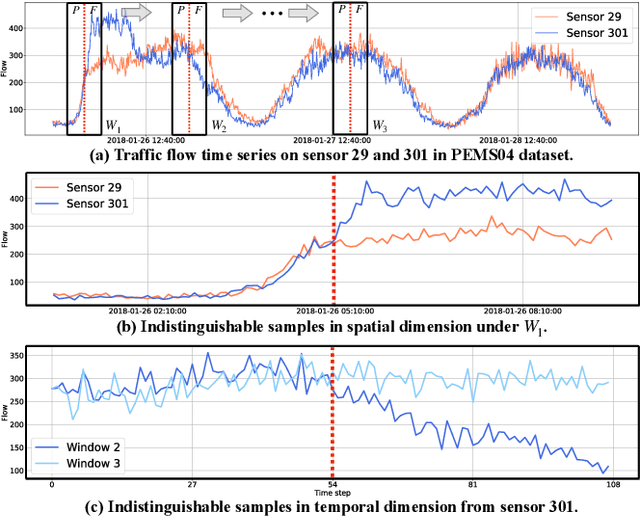

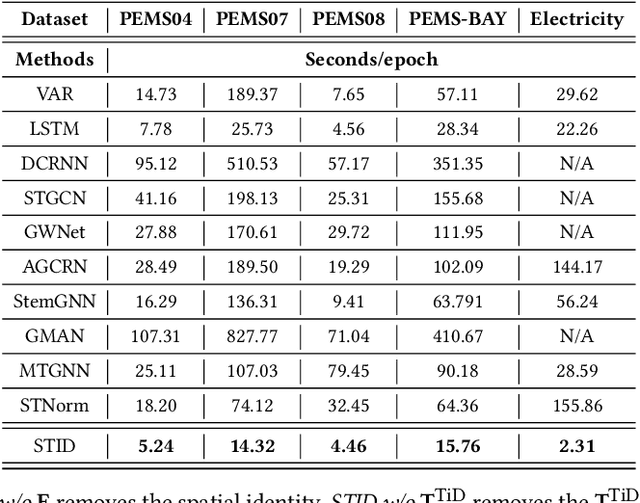
Multivariate Time Series (MTS) forecasting plays a vital role in a wide range of applications. Recently, Spatial-Temporal Graph Neural Networks (STGNNs) have become increasingly popular MTS forecasting methods due to their state-of-the-art performance. However, recent works are becoming more sophisticated with limited performance improvements. This phenomenon motivates us to explore the critical factors of MTS forecasting and design a model that is as powerful as STGNNs, but more concise and efficient. In this paper, we identify the indistinguishability of samples in both spatial and temporal dimensions as a key bottleneck, and propose a simple yet effective baseline for MTS forecasting by attaching Spatial and Temporal IDentity information (STID), which achieves the best performance and efficiency simultaneously based on simple Multi-Layer Perceptrons (MLPs). These results suggest that we can design efficient and effective models as long as they solve the indistinguishability of samples, without being limited to STGNNs.
Identification of feasible pathway information for c-di-GMP binding proteins in cellulose production
Apr 26, 2022
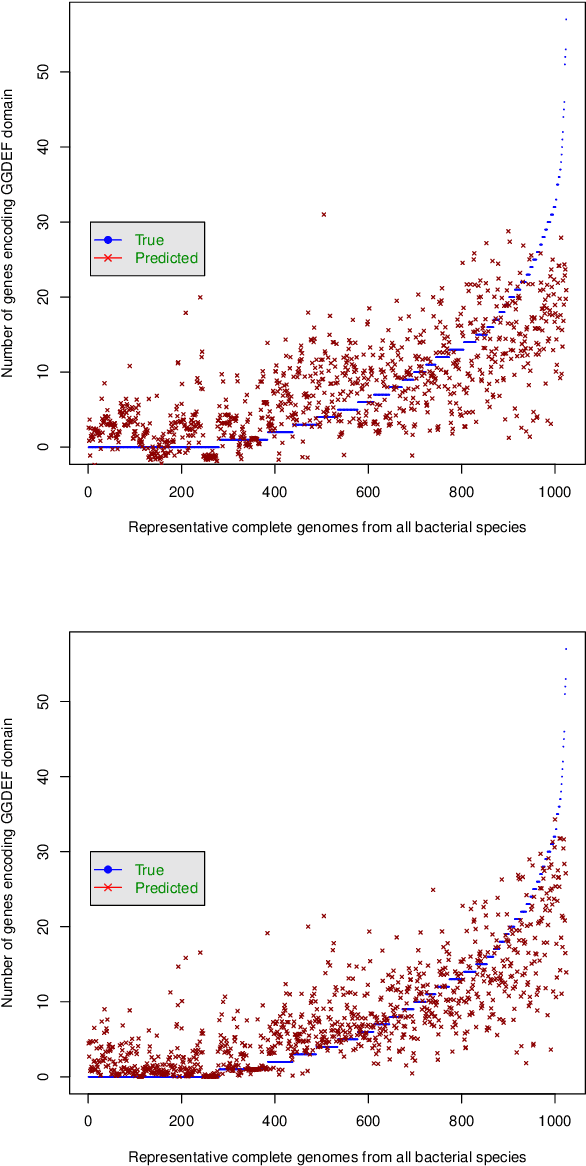
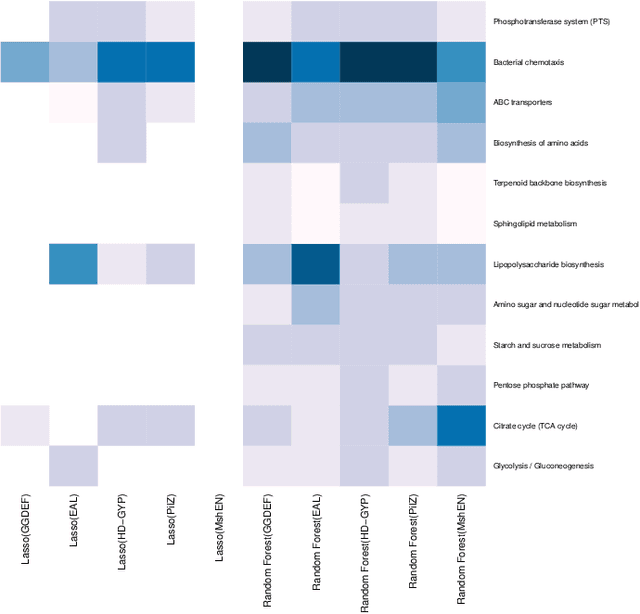
In this paper, we utilize a machine learning approach to identify the significant pathways for c-di-GMP signaling proteins. The dataset involves gene counts from 12 pathways and 5 essential c-di-GMP binding domains for 1024 bacterial genomes. Two novel approaches, Least absolute shrinkage and selection operator (Lasso) and Random forests, have been applied for analyzing and modeling the dataset. Both approaches show that bacterial chemotaxis is the most essential pathway for c-di-GMP encoding domains. Though popular for feature selection, the strong regularization of Lasso method fails to associate any pathway to MshE domain. Results from the analysis may help to understand and emphasize the supporting pathways involved in bacterial cellulose production. These findings demonstrate the need for a chassis to restrict the behavior or functionality by deactivating the selective pathways in cellulose production.
Multi-Prior Learning via Neural Architecture Search for Blind Face Restoration
Jun 28, 2022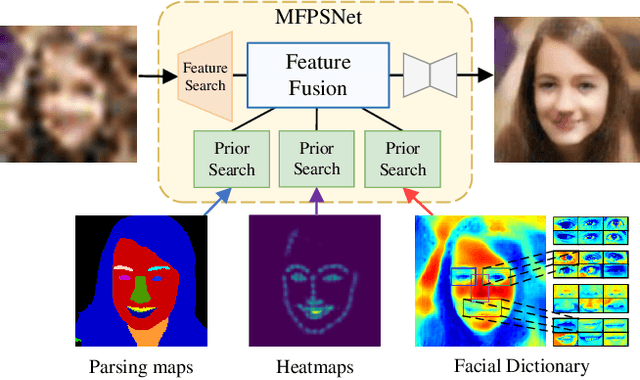
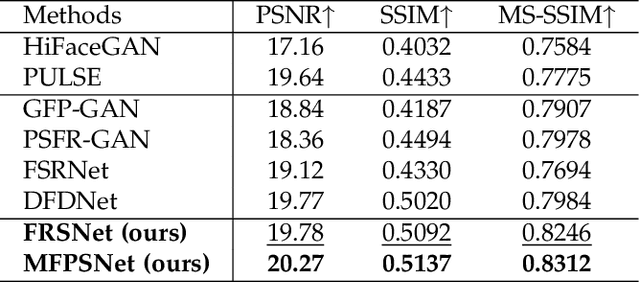
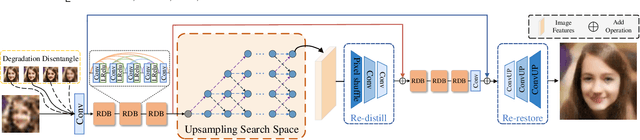
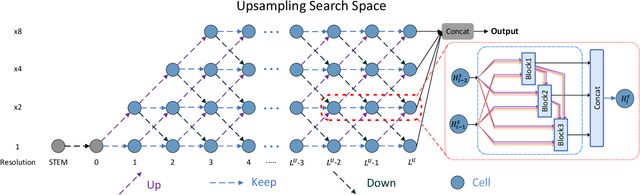
Blind Face Restoration (BFR) aims to recover high-quality face images from low-quality ones and usually resorts to facial priors for improving restoration performance. However, current methods still suffer from two major difficulties: 1) how to derive a powerful network architecture without extensive hand tuning; 2) how to capture complementary information from multiple facial priors in one network to improve restoration performance. To this end, we propose a Face Restoration Searching Network (FRSNet) to adaptively search the suitable feature extraction architecture within our specified search space, which can directly contribute to the restoration quality. On the basis of FRSNet, we further design our Multiple Facial Prior Searching Network (MFPSNet) with a multi-prior learning scheme. MFPSNet optimally extracts information from diverse facial priors and fuses the information into image features, ensuring that both external guidance and internal features are reserved. In this way, MFPSNet takes full advantage of semantic-level (parsing maps), geometric-level (facial heatmaps), reference-level (facial dictionaries) and pixel-level (degraded images) information and thus generates faithful and realistic images. Quantitative and qualitative experiments show that MFPSNet performs favorably on both synthetic and real-world datasets against the state-of-the-art BFR methods. The codes are publicly available at: https://github.com/YYJ1anG/MFPSNet.
Robust and Efficient Imbalanced Positive-Unlabeled Learning with Self-supervision
Sep 06, 2022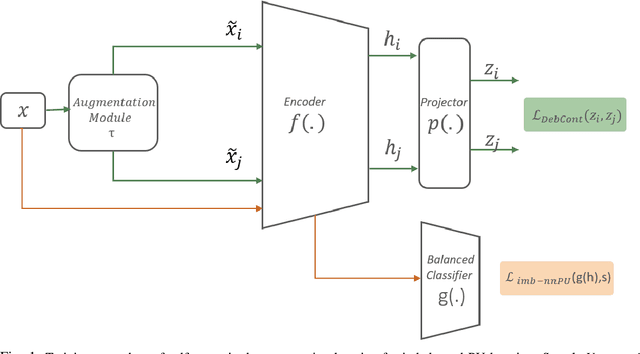
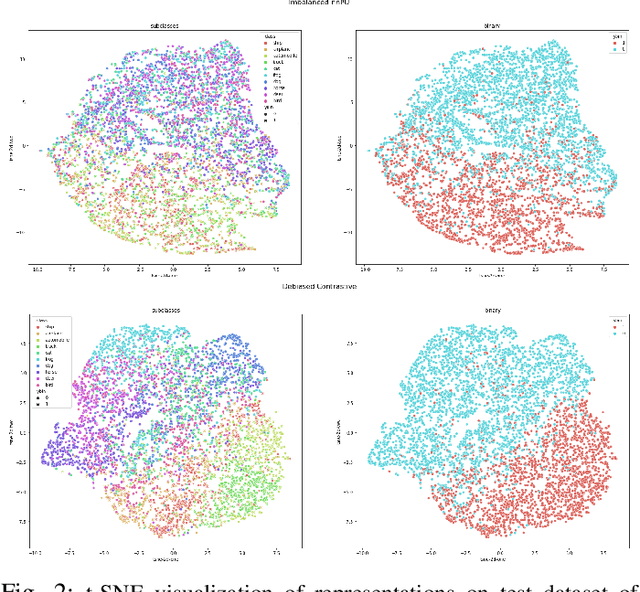
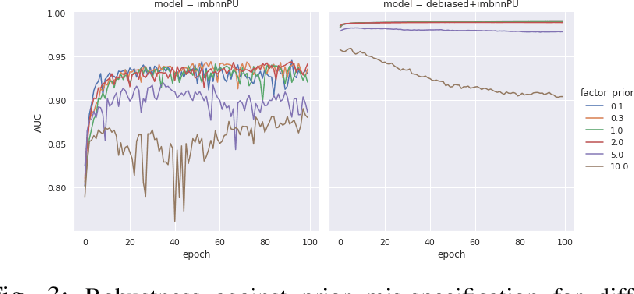
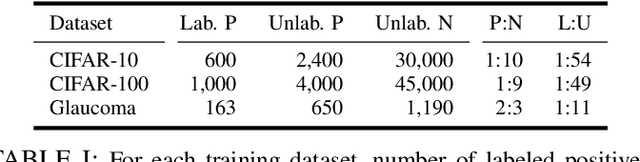
Learning from positive and unlabeled (PU) data is a setting where the learner only has access to positive and unlabeled samples while having no information on negative examples. Such PU setting is of great importance in various tasks such as medical diagnosis, social network analysis, financial markets analysis, and knowledge base completion, which also tend to be intrinsically imbalanced, i.e., where most examples are actually negatives. Most existing approaches for PU learning, however, only consider artificially balanced datasets and it is unclear how well they perform in the realistic scenario of imbalanced and long-tail data distribution. This paper proposes to tackle this challenge via robust and efficient self-supervised pretraining. However, training conventional self-supervised learning methods when applied with highly imbalanced PU distribution needs better reformulation. In this paper, we present \textit{ImPULSeS}, a unified representation learning framework for \underline{Im}balanced \underline{P}ositive \underline{U}nlabeled \underline{L}earning leveraging \underline{Se}lf-\underline{S}upervised debiase pre-training. ImPULSeS uses a generic combination of large-scale unsupervised learning with debiased contrastive loss and additional reweighted PU loss. We performed different experiments across multiple datasets to show that ImPULSeS is able to halve the error rate of the previous state-of-the-art, even compared with previous methods that are given the true prior. Moreover, our method showed increased robustness to prior misspecification and superior performance even when pretraining was performed on an unrelated dataset. We anticipate such robustness and efficiency will make it much easier for practitioners to obtain excellent results on other PU datasets of interest. The source code is available at \url{https://github.com/JSchweisthal/ImPULSeS}