 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Curbing Task Interference using Representation Similarity-Guided Multi-Task Feature Sharing
Aug 19, 2022
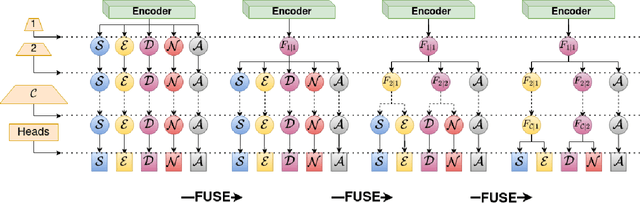

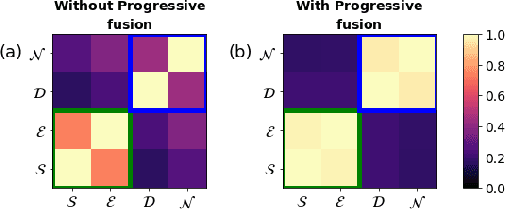
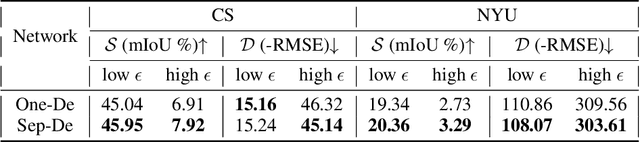
Multi-task learning of dense prediction tasks, by sharing both the encoder and decoder, as opposed to sharing only the encoder, provides an attractive front to increase both accuracy and computational efficiency. When the tasks are similar, sharing the decoder serves as an additional inductive bias providing more room for tasks to share complementary information among themselves. However, increased sharing exposes more parameters to task interference which likely hinders both generalization and robustness. Effective ways to curb this interference while exploiting the inductive bias of sharing the decoder remains an open challenge. To address this challenge, we propose Progressive Decoder Fusion (PDF) to progressively combine task decoders based on inter-task representation similarity. We show that this procedure leads to a multi-task network with better generalization to in-distribution and out-of-distribution data and improved robustness to adversarial attacks. Additionally, we observe that the predictions of different tasks of this multi-task network are more consistent with each other.
Variational Leakage: The Role of Information Complexity in Privacy Leakage
Jun 08, 2021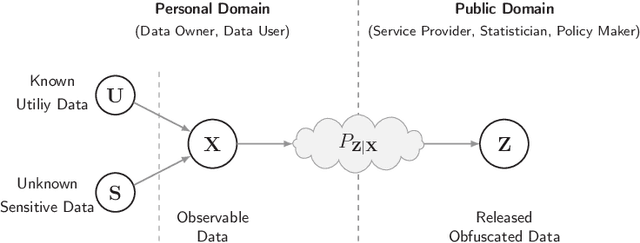
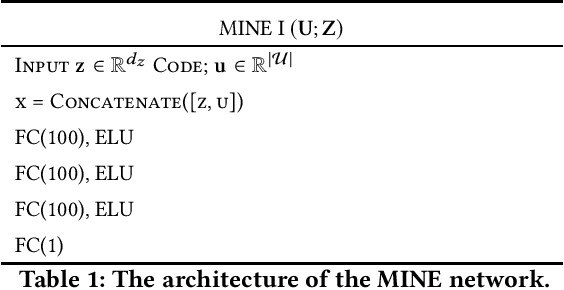
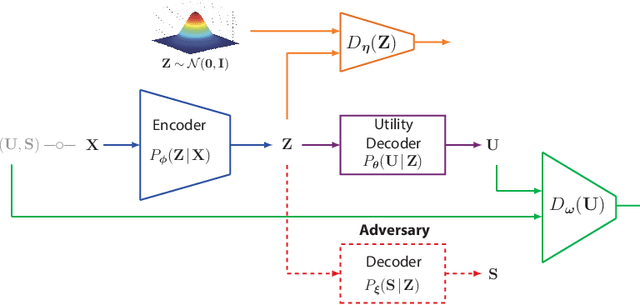

We study the role of information complexity in privacy leakage about an attribute of an adversary's interest, which is not known a priori to the system designer. Considering the supervised representation learning setup and using neural networks to parameterize the variational bounds of information quantities, we study the impact of the following factors on the amount of information leakage: information complexity regularizer weight, latent space dimension, the cardinalities of the known utility and unknown sensitive attribute sets, the correlation between utility and sensitive attributes, and a potential bias in a sensitive attribute of adversary's interest. We conduct extensive experiments on Colored-MNIST and CelebA datasets to evaluate the effect of information complexity on the amount of intrinsic leakage.
Information-Theoretic Generalization Bounds for Iterative Semi-Supervised Learning
Oct 03, 2021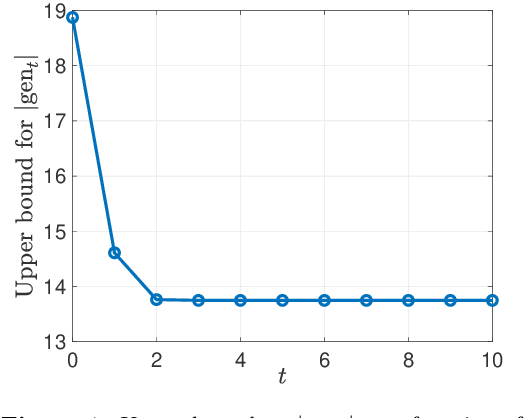


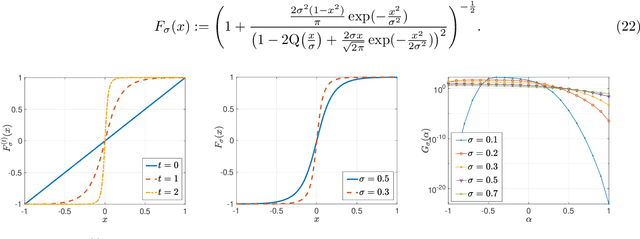
We consider iterative semi-supervised learning (SSL) algorithms that iteratively generate pseudo-labels for a large amount unlabelled data to progressively refine the model parameters. In particular, we seek to understand the behaviour of the {\em generalization error} of iterative SSL algorithms using information-theoretic principles. To obtain bounds that are amenable to numerical evaluation, we first work with a simple model -- namely, the binary Gaussian mixture model. Our theoretical results suggest that when the class conditional variances are not too large, the upper bound on the generalization error decreases monotonically with the number of iterations, but quickly saturates. The theoretical results on the simple model are corroborated by extensive experiments on several benchmark datasets such as the MNIST and CIFAR datasets in which we notice that the generalization error improves after several pseudo-labelling iterations, but saturates afterwards.
CAPD: A Context-Aware, Policy-Driven Framework for Secure and Resilient IoBT Operations
Aug 02, 2022The Internet of Battlefield Things (IoBT) will advance the operational effectiveness of infantry units. However, this requires autonomous assets such as sensors, drones, combat equipment, and uncrewed vehicles to collaborate, securely share information, and be resilient to adversary attacks in contested multi-domain operations. CAPD addresses this problem by providing a context-aware, policy-driven framework supporting data and knowledge exchange among autonomous entities in a battlespace. We propose an IoBT ontology that facilitates controlled information sharing to enable semantic interoperability between systems. Its key contributions include providing a knowledge graph with a shared semantic schema, integration with background knowledge, efficient mechanisms for enforcing data consistency and drawing inferences, and supporting attribute-based access control. The sensors in the IoBT provide data that create populated knowledge graphs based on the ontology. This paper describes using CAPD to detect and mitigate adversary actions. CAPD enables situational awareness using reasoning over the sensed data and SPARQL queries. For example, adversaries can cause sensor failure or hijacking and disrupt the tactical networks to degrade video surveillance. In such instances, CAPD uses an ontology-based reasoner to see how alternative approaches can still support the mission. Depending on bandwidth availability, the reasoner initiates the creation of a reduced frame rate grayscale video by active transcoding or transmits only still images. This ability to reason over the mission sensed environment and attack context permits the autonomous IoBT system to exhibit resilience in contested conditions.
Learning Personalized Representations using Graph Convolutional Network
Jul 28, 2022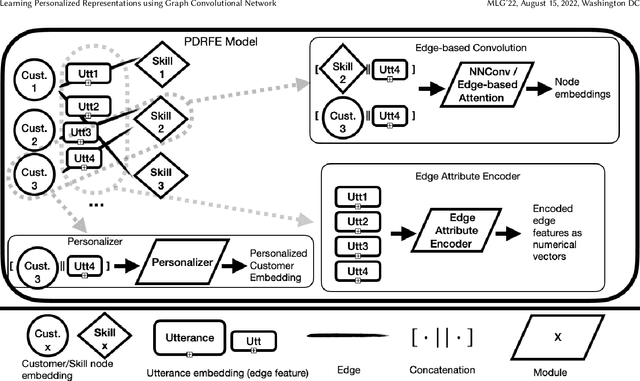

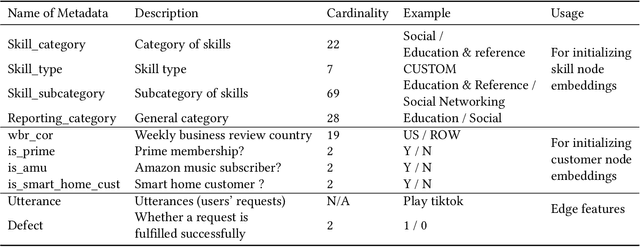
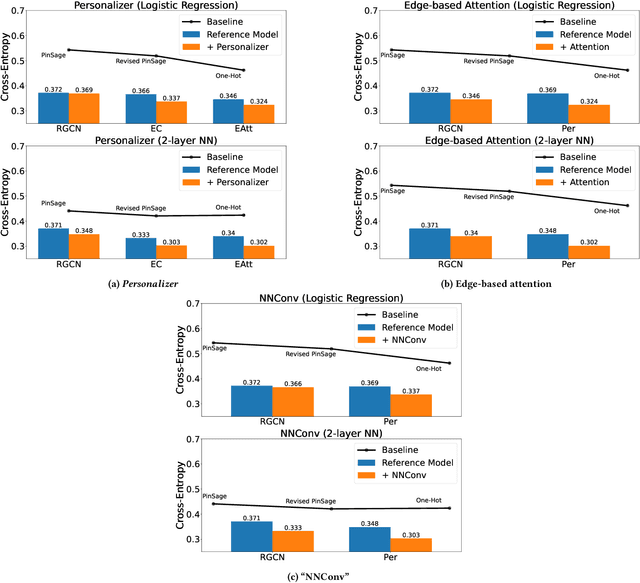
Generating representations that precisely reflect customers' behavior is an important task for providing personalized skill routing experience in Alexa. Currently, Dynamic Routing (DR) team, which is responsible for routing Alexa traffic to providers or skills, relies on two features to be served as personal signals: absolute traffic count and normalized traffic count of every skill usage per customer. Neither of them considers the network based structure for interactions between customers and skills, which contain richer information for customer preferences. In this work, we first build a heterogeneous edge attributed graph based customers' past interactions with the invoked skills, in which the user requests (utterances) are modeled as edges. Then we propose a graph convolutional network(GCN) based model, namely Personalized Dynamic Routing Feature Encoder(PDRFE), that generates personalized customer representations learned from the built graph. Compared with existing models, PDRFE is able to further capture contextual information in the graph convolutional function. The performance of our proposed model is evaluated by a downstream task, defect prediction, that predicts the defect label from the learned embeddings of customers and their triggered skills. We observe up to 41% improvements on the cross entropy metric for our proposed models compared to the baselines.
Defect Transformer: An Efficient Hybrid Transformer Architecture for Surface Defect Detection
Jul 17, 2022
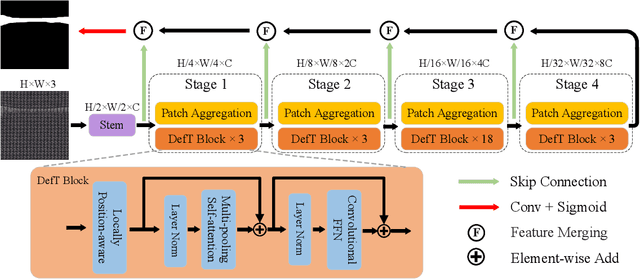
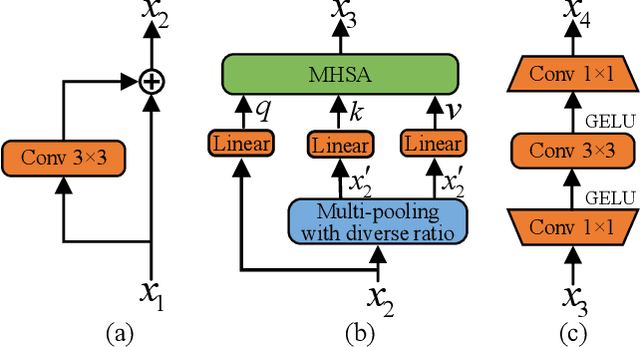
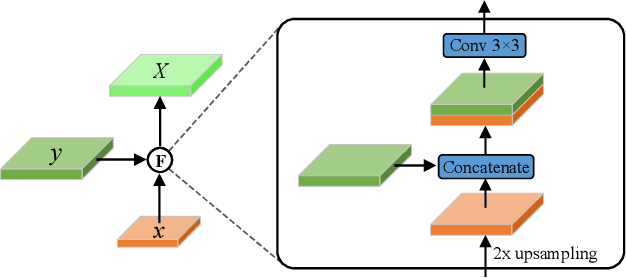
Surface defect detection is an extremely crucial step to ensure the quality of industrial products. Nowadays, convolutional neural networks (CNNs) based on encoder-decoder architecture have achieved tremendous success in various defect detection tasks. However, due to the intrinsic locality of convolution, they commonly exhibit a limitation in explicitly modeling long-range interactions, critical for pixel-wise defect detection in complex cases, e.g., cluttered background and illegible pseudo-defects. Recent transformers are especially skilled at learning global image dependencies but with limited local structural information necessary for detailed defect location. To overcome the above limitations, we propose an efficient hybrid transformer architecture, termed Defect Transformer (DefT), for surface defect detection, which incorporates CNN and transformer into a unified model to capture local and non-local relationships collaboratively. Specifically, in the encoder module, a convolutional stem block is firstly adopted to retain more detailed spatial information. Then, the patch aggregation blocks are used to generate multi-scale representation with four hierarchies, each of them is followed by a series of DefT blocks, which respectively include a locally position-aware block for local position encoding, a lightweight multi-pooling self-attention to model multi-scale global contextual relationships with good computational efficiency, and a convolutional feed-forward network for feature transformation and further location information learning. Finally, a simple but effective decoder module is proposed to gradually recover spatial details from the skip connections in the encoder. Extensive experiments on three datasets demonstrate the superiority and efficiency of our method compared with other CNN- and transformer-based networks.
Do You Know My Emotion? Emotion-Aware Strategy Recognition towards a Persuasive Dialogue System
Jun 24, 2022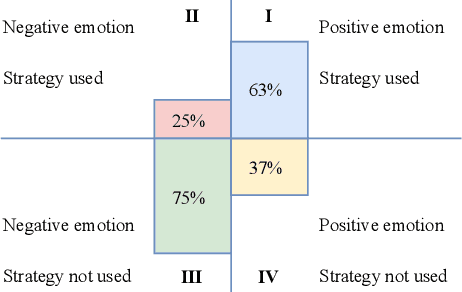
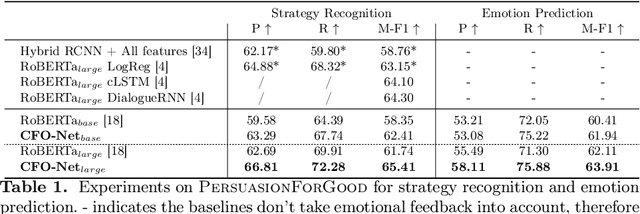
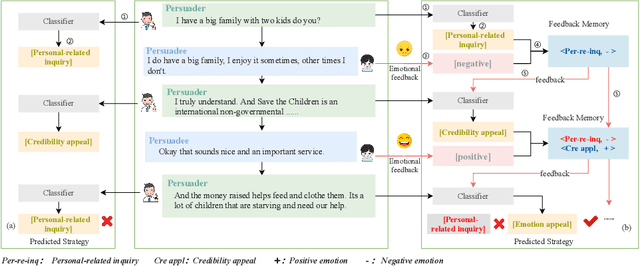

Persuasive strategy recognition task requires the system to recognize the adopted strategy of the persuader according to the conversation. However, previous methods mainly focus on the contextual information, little is known about incorporating the psychological feedback, i.e. emotion of the persuadee, to predict the strategy. In this paper, we propose a Cross-channel Feedback memOry Network (CFO-Net) to leverage the emotional feedback to iteratively measure the potential benefits of strategies and incorporate them into the contextual-aware dialogue information. Specifically, CFO-Net designs a feedback memory module, including strategy pool and feedback pool, to obtain emotion-aware strategy representation. The strategy pool aims to store historical strategies and the feedback pool is to obtain updated strategy weight based on feedback emotional information. Furthermore, a cross-channel fusion predictor is developed to make a mutual interaction between the emotion-aware strategy representation and the contextual-aware dialogue information for strategy recognition. Experimental results on \textsc{PersuasionForGood} confirm that the proposed model CFO-Net is effective to improve the performance on M-F1 from 61.74 to 65.41.
Intention-Conditioned Long-Term Human Egocentric Action Forecasting @ EGO4D Challenge 2022
Jul 25, 2022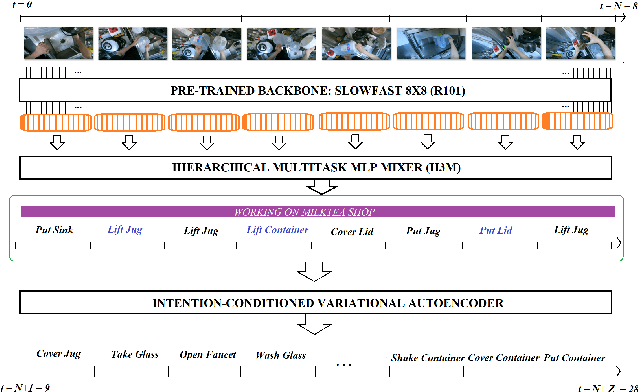
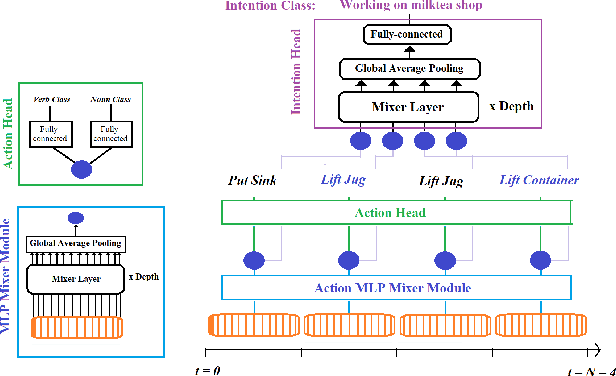
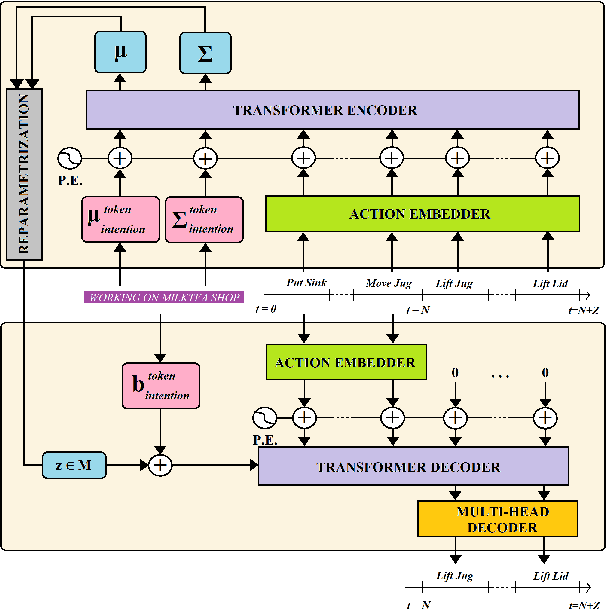
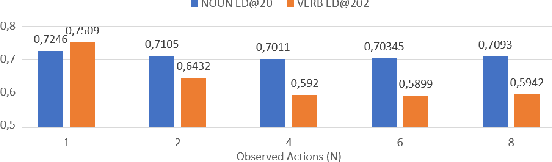
To anticipate how a human would act in the future, it is essential to understand the human intention since it guides the human towards a certain goal. In this paper, we propose a hierarchical architecture which assumes a sequence of human action (low-level) can be driven from the human intention (high-level). Based on this, we deal with Long-Term Action Anticipation task in egocentric videos. Our framework first extracts two level of human information over the N observed videos human actions through a Hierarchical Multi-task MLP Mixer (H3M). Then, we condition the uncertainty of the future through an Intention-Conditioned Variational Auto-Encoder (I-CVAE) that generates K stable predictions of the next Z=20 actions that the observed human might perform. By leveraging human intention as high-level information, we claim that our model is able to anticipate more time-consistent actions in the long-term, thus improving the results over baseline methods in EGO4D Challenge. This work ranked first in the EGO4D LTA Challenge by providing more plausible anticipated sequences, improving the anticipation of nouns and overall actions. The code is available at https://github.com/Evm7/ego4dlta-icvae.
Sustaining Fairness via Incremental Learning
Aug 25, 2022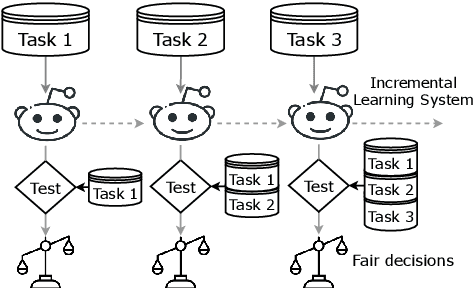
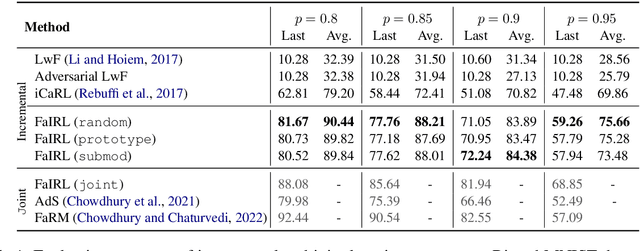
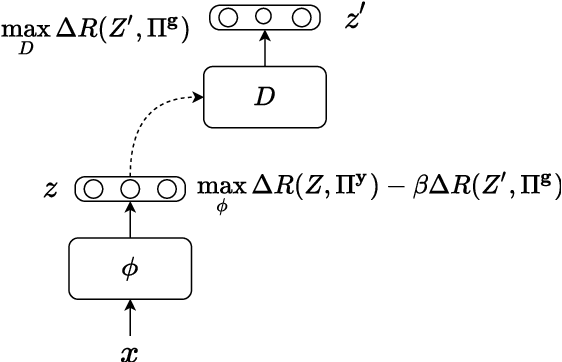
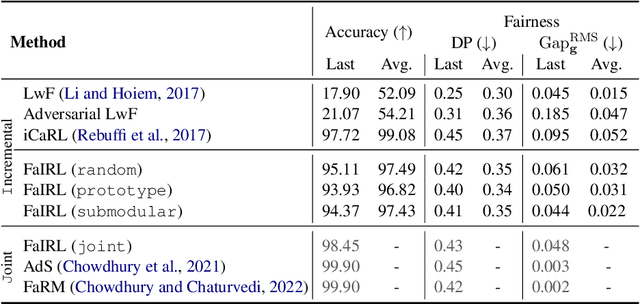
Machine learning systems are often deployed for making critical decisions like credit lending, hiring, etc. While making decisions, such systems often encode the user's demographic information (like gender, age) in their intermediate representations. This can lead to decisions that are biased towards specific demographics. Prior work has focused on debiasing intermediate representations to ensure fair decisions. However, these approaches fail to remain fair with changes in the task or demographic distribution. To ensure fairness in the wild, it is important for a system to adapt to such changes as it accesses new data in an incremental fashion. In this work, we propose to address this issue by introducing the problem of learning fair representations in an incremental learning setting. To this end, we present Fairness-aware Incremental Representation Learning (FaIRL), a representation learning system that can sustain fairness while incrementally learning new tasks. FaIRL is able to achieve fairness and learn new tasks by controlling the rate-distortion function of the learned representations. Our empirical evaluations show that FaIRL is able to make fair decisions while achieving high performance on the target task, outperforming several baselines.
Contrastive Audio-Language Learning for Music
Aug 25, 2022

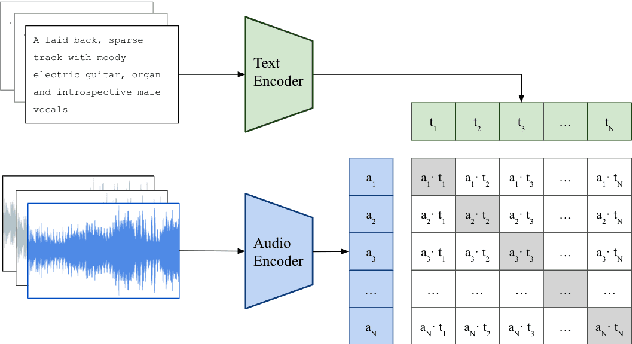
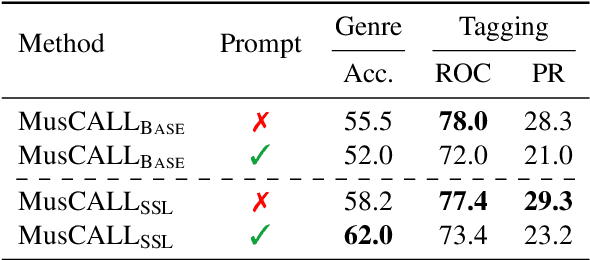
As one of the most intuitive interfaces known to humans, natural language has the potential to mediate many tasks that involve human-computer interaction, especially in application-focused fields like Music Information Retrieval. In this work, we explore cross-modal learning in an attempt to bridge audio and language in the music domain. To this end, we propose MusCALL, a framework for Music Contrastive Audio-Language Learning. Our approach consists of a dual-encoder architecture that learns the alignment between pairs of music audio and descriptive sentences, producing multimodal embeddings that can be used for text-to-audio and audio-to-text retrieval out-of-the-box. Thanks to this property, MusCALL can be transferred to virtually any task that can be cast as text-based retrieval. Our experiments show that our method performs significantly better than the baselines at retrieving audio that matches a textual description and, conversely, text that matches an audio query. We also demonstrate that the multimodal alignment capability of our model can be successfully extended to the zero-shot transfer scenario for genre classification and auto-tagging on two public datasets.