 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Low-Light Video Enhancement with Synthetic Event Guidance
Aug 23, 2022
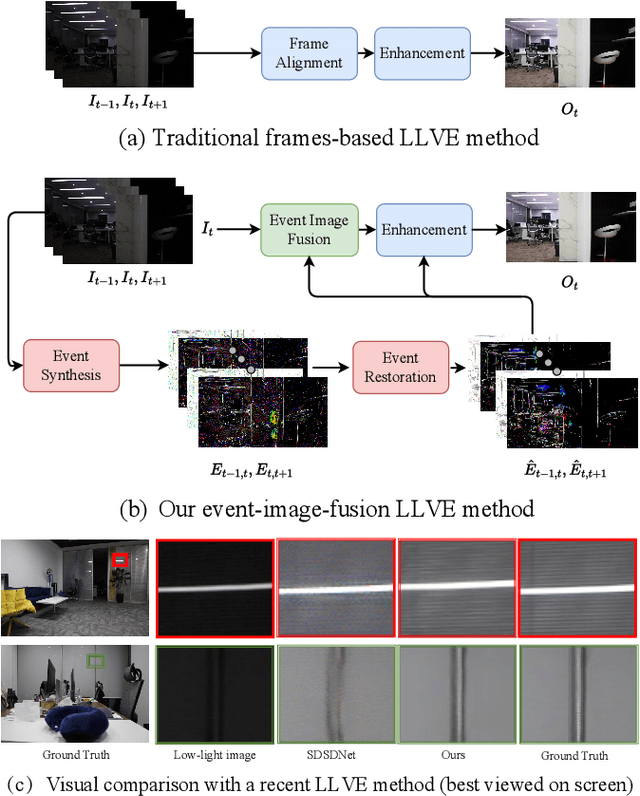
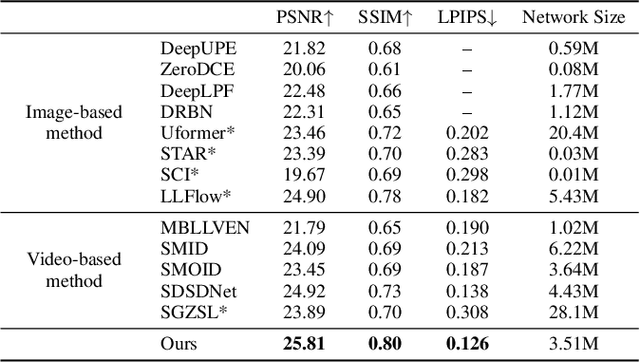

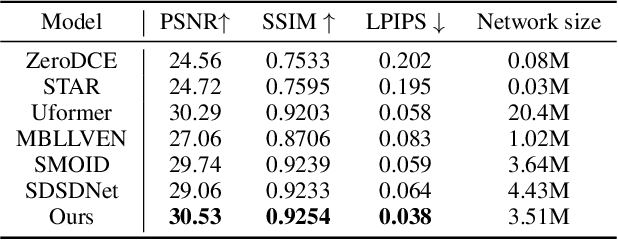
Low-light video enhancement (LLVE) is an important yet challenging task with many applications such as photographing and autonomous driving. Unlike single image low-light enhancement, most LLVE methods utilize temporal information from adjacent frames to restore the color and remove the noise of the target frame. However, these algorithms, based on the framework of multi-frame alignment and enhancement, may produce multi-frame fusion artifacts when encountering extreme low light or fast motion. In this paper, inspired by the low latency and high dynamic range of events, we use synthetic events from multiple frames to guide the enhancement and restoration of low-light videos. Our method contains three stages: 1) event synthesis and enhancement, 2) event and image fusion, and 3) low-light enhancement. In this framework, we design two novel modules (event-image fusion transform and event-guided dual branch) for the second and third stages, respectively. Extensive experiments show that our method outperforms existing low-light video or single image enhancement approaches on both synthetic and real LLVE datasets.
Collective Obfuscation and Crowdsourcing
Aug 12, 2022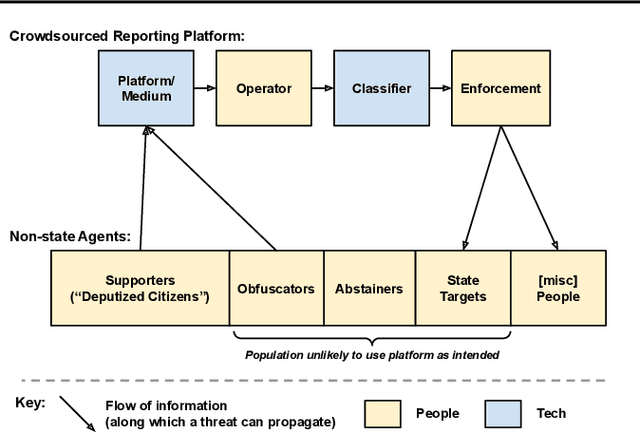
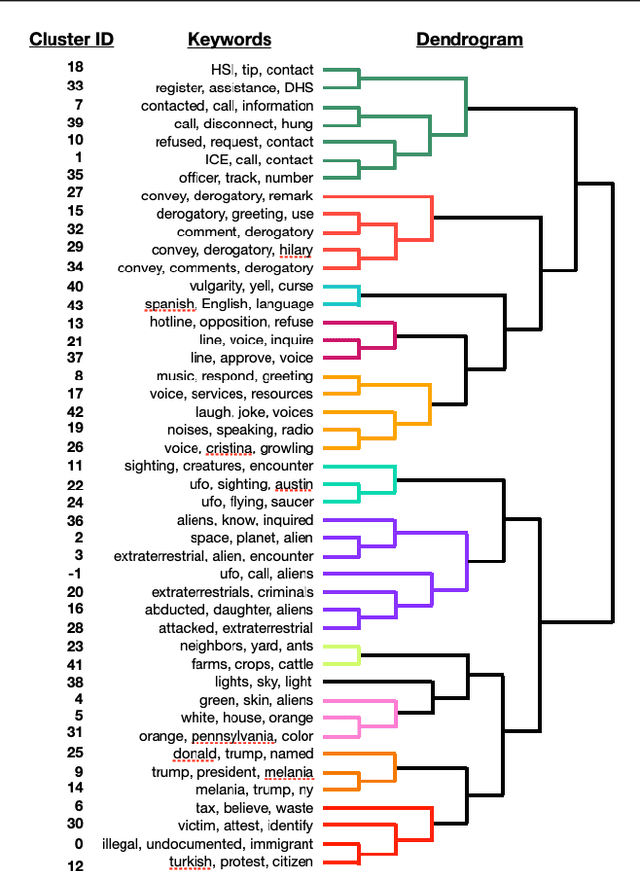
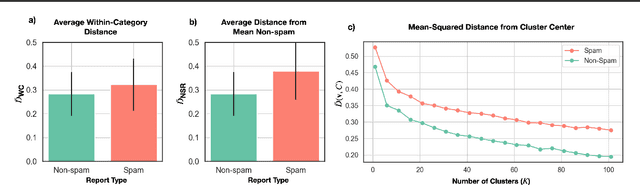
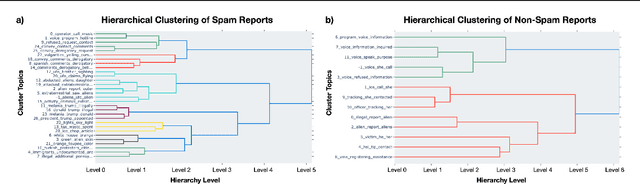
Crowdsourcing technologies rely on groups of people to input information that may be critical for decision-making. This work examines obfuscation in the context of reporting technologies. We show that widespread use of reporting platforms comes with unique security and privacy implications, and introduce a threat model and corresponding taxonomy to outline some of the many attack vectors in this space. We then perform an empirical analysis of a dataset of call logs from a controversial, real-world reporting hotline and identify coordinated obfuscation strategies that are intended to hinder the platform's legitimacy. We propose a variety of statistical measures to quantify the strength of this obfuscation strategy with respect to the structural and semantic characteristics of the reporting attacks in our dataset.
Multi-Pair D2D Communications Aided by An Active RIS over Spatially Correlated Channels with Phase Noise
Aug 16, 2022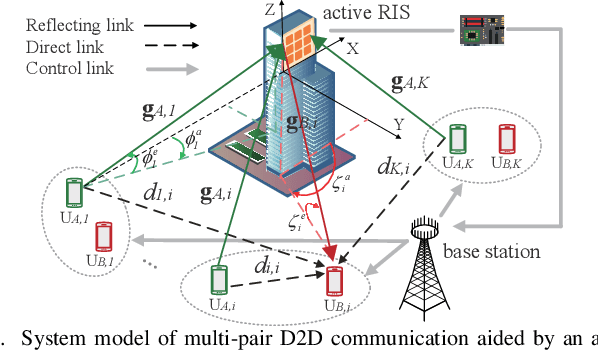
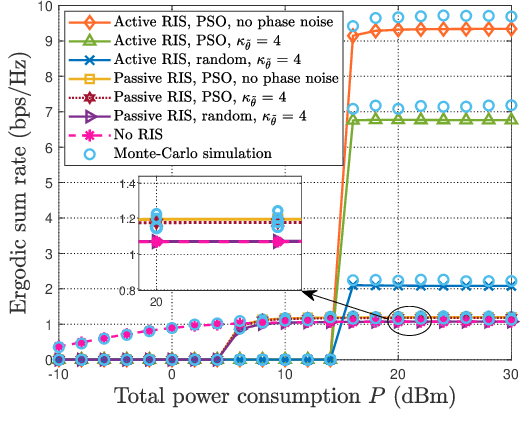
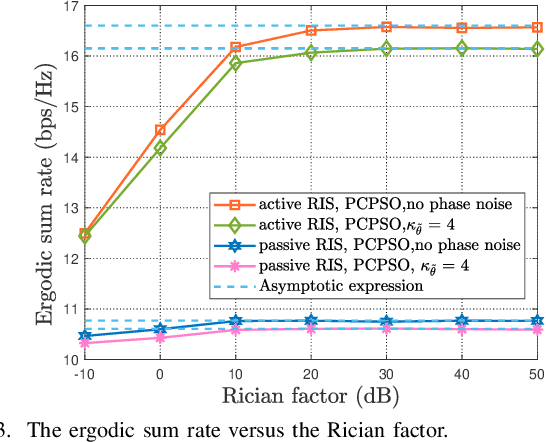
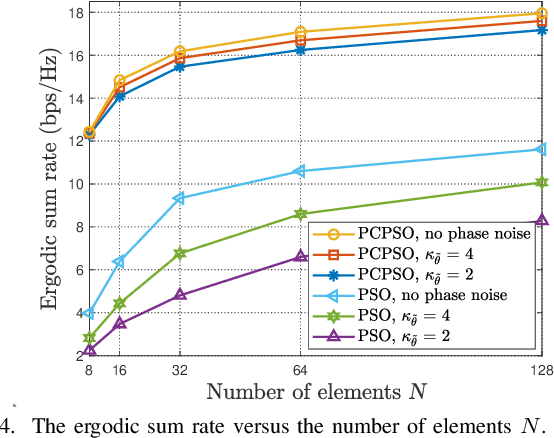
This paper investigates a multi-pair device-to-device (D2D) communication system aided by an active reconfigurable intelligent surface (RIS) with phase noise and direct link. The approximate closed-form expression of the ergodic sum rate is derived over spatially correlated Rician fading channels with statistical channel state information (CSI). When the Rician factors go to infinity, the asymptotic expressions of the ergodic sum rates are presented to give insights in poor scattering environment. The power scaling law for the special case of a single D2D pair is presented without phase noise under uncorrelated Rician fading condition. Then, to solve the ergodic sum rate maximization problem, a method based on genetic algorithm (GA) is proposed for joint power control and discrete phase shifts optimization. Simulation results verify the accuracy of our derivations, and also show that the active RIS outperforms the passive RIS.
Fast Re-Optimization of LeadingOnes with Frequent Changes
Sep 09, 2022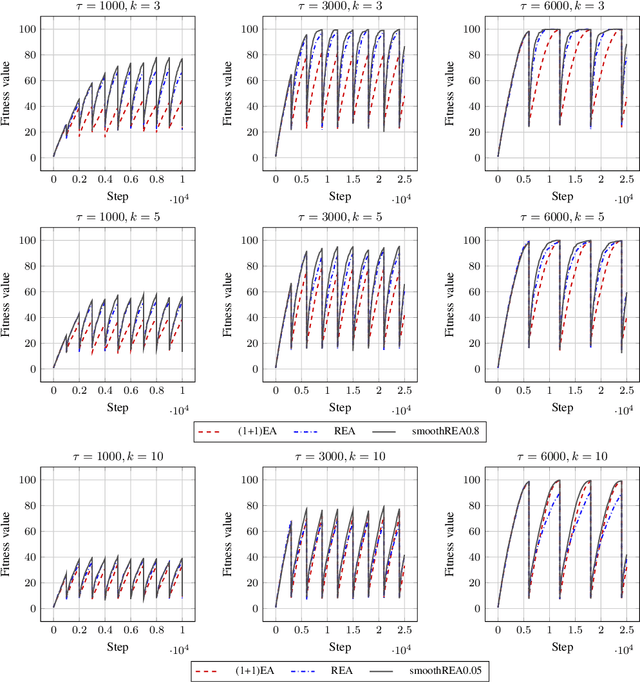
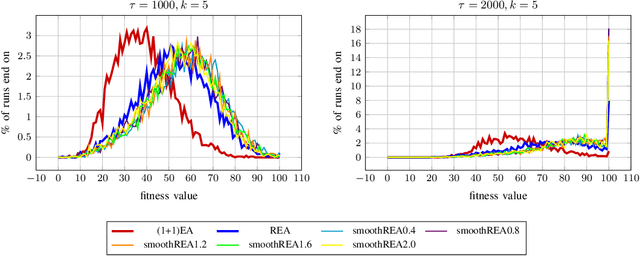
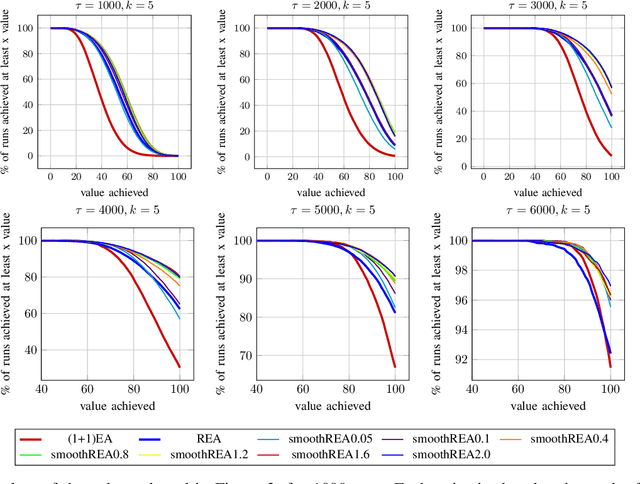
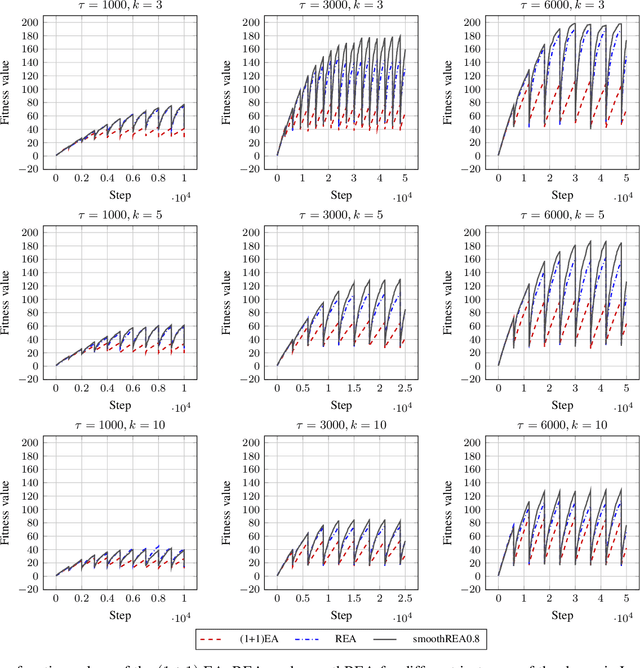
In real-world optimization scenarios, the problem instance that we are asked to solve may change during the optimization process, e.g., when new information becomes available or when the environmental conditions change. In such situations, one could hope to achieve reasonable performance by continuing the search from the best solution found for the original problem. Likewise, one may hope that when solving several problem instances that are similar to each other, it can be beneficial to ``warm-start'' the optimization process of the second instance by the best solution found for the first. However, it was shown in [Doerr et al., GECCO 2019] that even when initialized with structurally good solutions, evolutionary algorithms can have a tendency to replace these good solutions by structurally worse ones, resulting in optimization times that have no advantage over the same algorithms started from scratch. Doerr et al. also proposed a diversity mechanism to overcome this problem. Their approach balances greedy search around a best-so-far solution for the current problem with search in the neighborhood around the best-found solution for the previous instance. In this work, we first show that the re-optimization approach suggested by Doerr et al. reaches a limit when the problem instances are prone to more frequent changes. More precisely, we show that they get stuck on the dynamic LeadingOnes problem in which the target string changes periodically. We then propose a modification of their algorithm which interpolates between greedy search around the previous-best and the current-best solution. We empirically evaluate our smoothed re-optimization algorithm on LeadingOnes instances with various frequencies of change and with different perturbation factors and show that it outperforms both a fully restarted (1+1) Evolutionary Algorithm and the re-optimization approach by Doerr et al.
CAEN: A Hierarchically Attentive Evolution Network for Item-Attribute-Change-Aware Recommendation in the Growing E-commerce Environment
Aug 29, 2022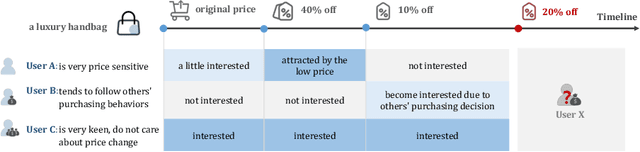

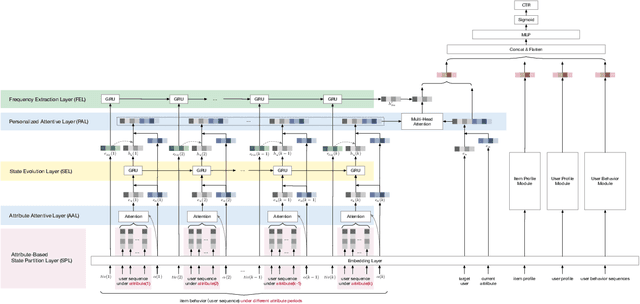
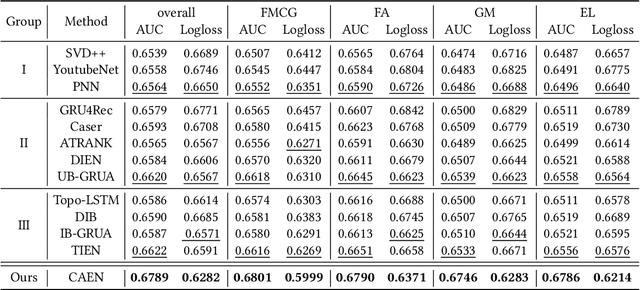
Traditional recommendation systems mainly focus on modeling user interests. However, the dynamics of recommended items caused by attribute modifications (e.g. changes in prices) are also of great importance in real systems, especially in the fast-growing e-commerce environment, which may cause the users' demands to emerge, shift and disappear. Recent studies that make efforts on dynamic item representations treat the item attributes as side information but ignore its temporal dependency, or model the item evolution with a sequence of related users but do not consider item attributes. In this paper, we propose Core Attribute Evolution Network (CAEN), which partitions the user sequence according to the attribute value and thus models the item evolution over attribute dynamics with these users. Under this framework, we further devise a hierarchical attention mechanism that applies attribute-aware attention for user aggregation under each attribute, as well as personalized attention for activating similar users in assessing the matching degree between target user and item. Results from the extensive experiments over actual e-commerce datasets show that our approach outperforms the state-of-art methods and achieves significant improvements on the items with rapid changes over attributes, therefore helping the item recommendation to adapt to the growth of the e-commerce platform.
Trust Calibration as a Function of the Evolution of Uncertainty in Knowledge Generation: A Survey
Sep 09, 2022User trust is a crucial consideration in designing robust visual analytics systems that can guide users to reasonably sound conclusions despite inevitable biases and other uncertainties introduced by the human, the machine, and the data sources which paint the canvas upon which knowledge emerges. A multitude of factors emerge upon studied consideration which introduce considerable complexity and exacerbate our understanding of how trust relationships evolve in visual analytics systems, much as they do in intelligent sociotechnical systems. A visual analytics system, however, does not by its nature provoke exactly the same phenomena as its simpler cousins, nor are the phenomena necessarily of the same exact kind. Regardless, both application domains present the same root causes from which the need for trustworthiness arises: Uncertainty and the assumption of risk. In addition, visual analytics systems, even more than the intelligent systems which (traditionally) tend to be closed to direct human input and direction during processing, are influenced by a multitude of cognitive biases that further exacerbate an accounting of the uncertainties that may afflict the user's confidence, and ultimately trust in the system. In this article we argue that accounting for the propagation of uncertainty from data sources all the way through extraction of information and hypothesis testing is necessary to understand how user trust in a visual analytics system evolves over its lifecycle, and that the analyst's selection of visualization parameters affords us a simple means to capture the interactions between uncertainty and cognitive bias as a function of the attributes of the search tasks the analyst executes while evaluating explanations. We sample a broad cross-section of the literature from visual analytics, human cognitive theory, and uncertainty, and attempt to synthesize a useful perspective.
Event-related data conditioning for acoustic event classification
Jun 16, 2022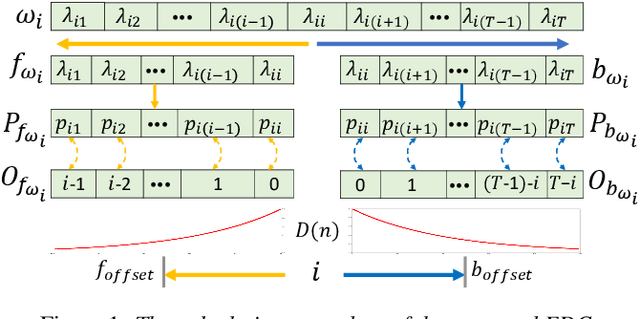
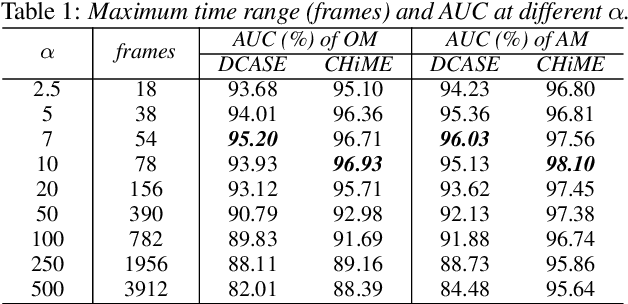
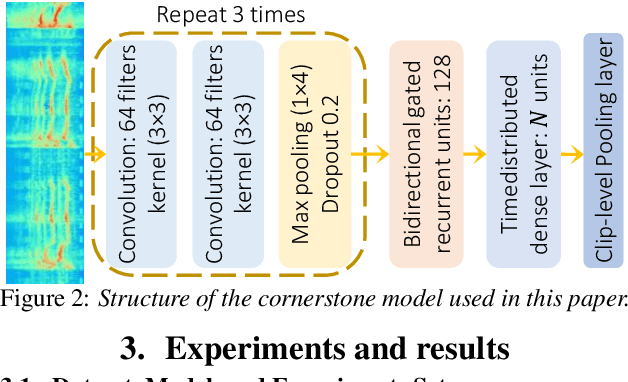
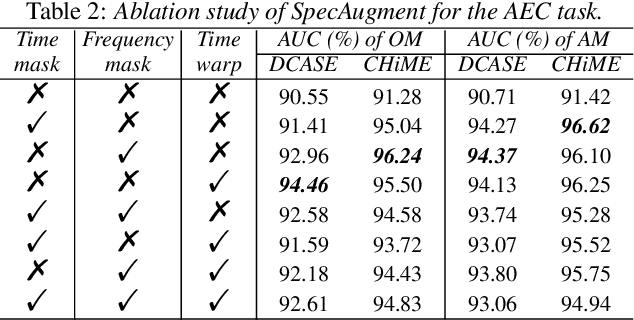
Models based on diverse attention mechanisms have recently shined in tasks related to acoustic event classification (AEC). Among them, self-attention is often used in audio-only tasks to help the model recognize different acoustic events. Self-attention relies on the similarity between time frames, and uses global information from the whole segment to highlight specific features within a frame. In real life, information related to acoustic events will attenuate over time, which means the information within some frames around the event deserves more attention than distant time global information that may be unrelated to the event. This paper shows that self-attention may over-enhance certain segments of audio representations, and smooth out the boundaries between events representations and background noises. Hence, this paper proposes an event-related data conditioning (EDC) for AEC. EDC directly works on spectrograms. The idea of EDC is to adaptively select the frame-related attention range based on acoustic features, and gather the event-related local information to represent the frame. Experiments show that: 1) compared with spectrogram-based data augmentation methods and trainable feature weighting and self-attention, EDC outperforms them in both the original-size mode and the augmented mode; 2) EDC effectively gathers event-related local information and enhances boundaries between events and backgrounds, improving the performance of AEC.
Multi-view hierarchical Variational AutoEncoders with Factor Analysis latent space
Jul 19, 2022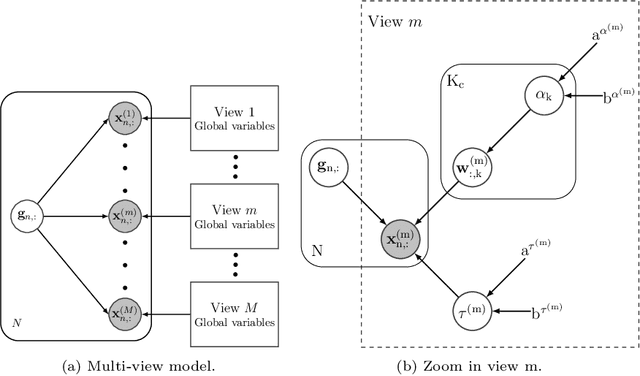


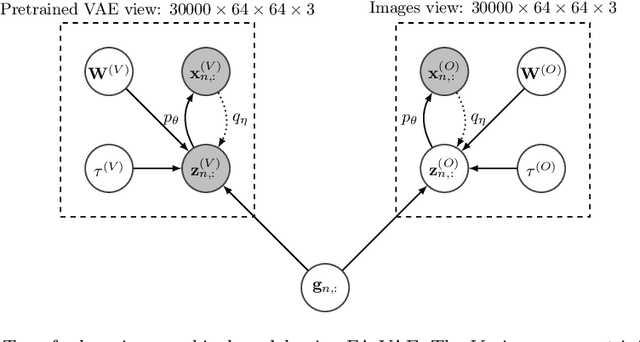
Real-world databases are complex, they usually present redundancy and shared correlations between heterogeneous and multiple representations of the same data. Thus, exploiting and disentangling shared information between views is critical. For this purpose, recent studies often fuse all views into a shared nonlinear complex latent space but they lose the interpretability. To overcome this limitation, here we propose a novel method to combine multiple Variational AutoEncoders (VAE) architectures with a Factor Analysis latent space (FA-VAE). Concretely, we use a VAE to learn a private representation of each heterogeneous view in a continuous latent space. Then, we model the shared latent space by projecting every private variable to a low-dimensional latent space using a linear projection matrix. Thus, we create an interpretable hierarchical dependency between private and shared information. This way, the novel model is able to simultaneously: (i) learn from multiple heterogeneous views, (ii) obtain an interpretable hierarchical shared space, and, (iii) perform transfer learning between generative models.
Towards Explaining Demographic Bias through the Eyes of Face Recognition Models
Aug 29, 2022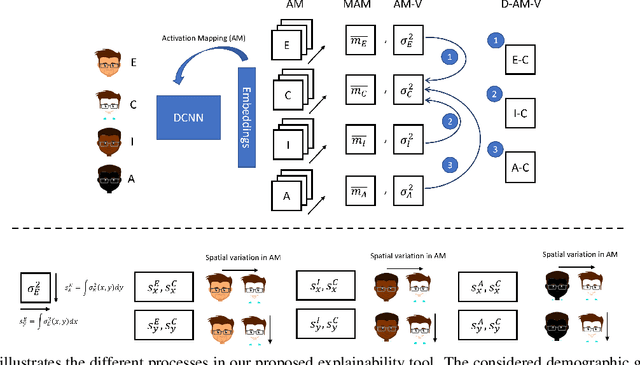
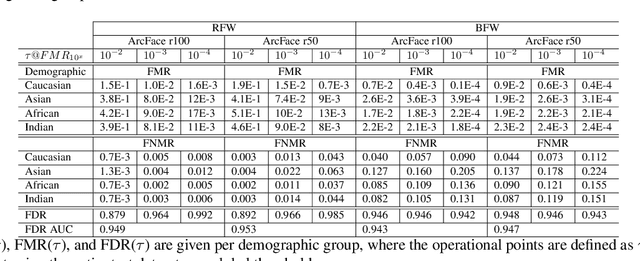
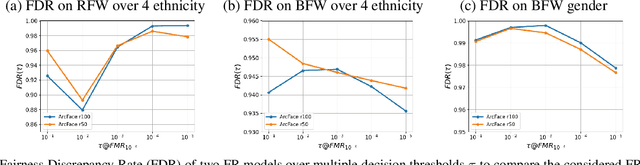
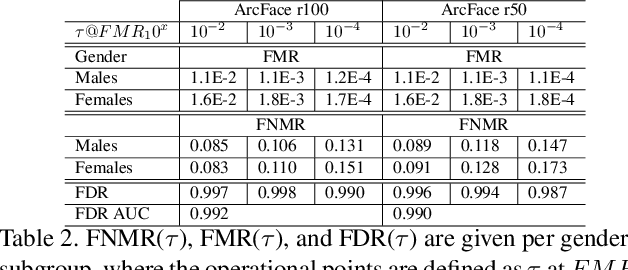
Biases inherent in both data and algorithms make the fairness of widespread machine learning (ML)-based decision-making systems less than optimal. To improve the trustfulness of such ML decision systems, it is crucial to be aware of the inherent biases in these solutions and to make them more transparent to the public and developers. In this work, we aim at providing a set of explainability tool that analyse the difference in the face recognition models' behaviors when processing different demographic groups. We do that by leveraging higher-order statistical information based on activation maps to build explainability tools that link the FR models' behavior differences to certain facial regions. The experimental results on two datasets and two face recognition models pointed out certain areas of the face where the FR models react differently for certain demographic groups compared to reference groups. The outcome of these analyses interestingly aligns well with the results of studies that analyzed the anthropometric differences and the human judgment differences on the faces of different demographic groups. This is thus the first study that specifically tries to explain the biased behavior of FR models on different demographic groups and link it directly to the spatial facial features. The code is publicly available here.
Defect Transformer: An Efficient Hybrid Transformer Architecture for Surface Defect Detection
Jul 17, 2022
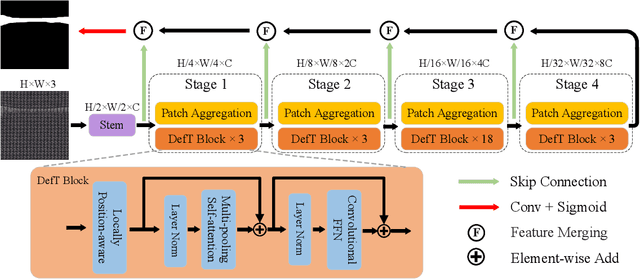
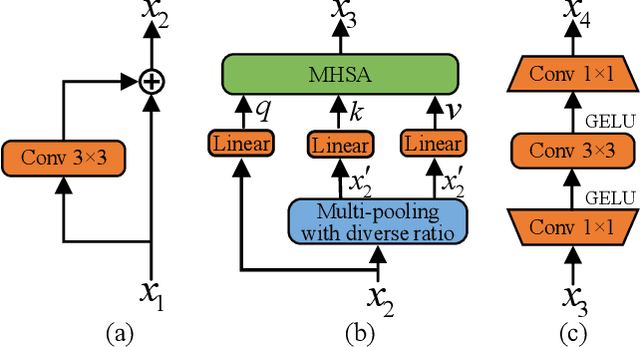
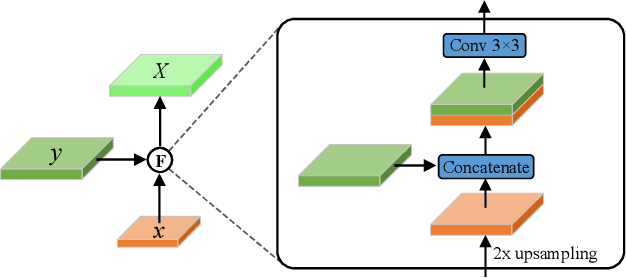
Surface defect detection is an extremely crucial step to ensure the quality of industrial products. Nowadays, convolutional neural networks (CNNs) based on encoder-decoder architecture have achieved tremendous success in various defect detection tasks. However, due to the intrinsic locality of convolution, they commonly exhibit a limitation in explicitly modeling long-range interactions, critical for pixel-wise defect detection in complex cases, e.g., cluttered background and illegible pseudo-defects. Recent transformers are especially skilled at learning global image dependencies but with limited local structural information necessary for detailed defect location. To overcome the above limitations, we propose an efficient hybrid transformer architecture, termed Defect Transformer (DefT), for surface defect detection, which incorporates CNN and transformer into a unified model to capture local and non-local relationships collaboratively. Specifically, in the encoder module, a convolutional stem block is firstly adopted to retain more detailed spatial information. Then, the patch aggregation blocks are used to generate multi-scale representation with four hierarchies, each of them is followed by a series of DefT blocks, which respectively include a locally position-aware block for local position encoding, a lightweight multi-pooling self-attention to model multi-scale global contextual relationships with good computational efficiency, and a convolutional feed-forward network for feature transformation and further location information learning. Finally, a simple but effective decoder module is proposed to gradually recover spatial details from the skip connections in the encoder. Extensive experiments on three datasets demonstrate the superiority and efficiency of our method compared with other CNN- and transformer-based networks.