 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hardware-aware mobile building block evaluation for computer vision
Aug 26, 2022
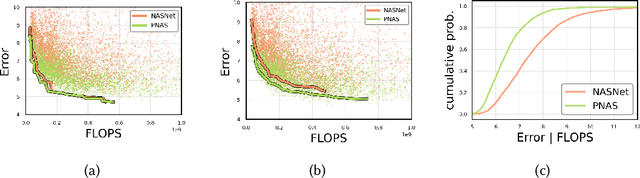
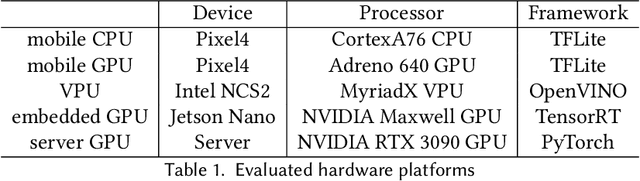
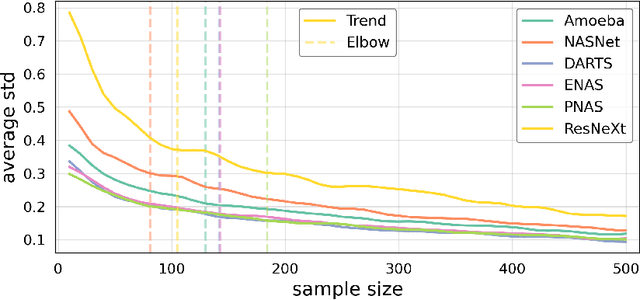
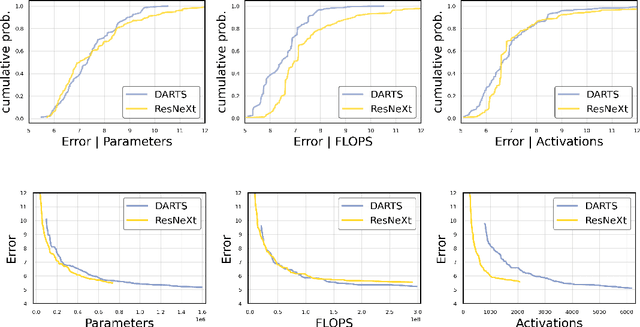
In this work we propose a methodology to accurately evaluate and compare the performance of efficient neural network building blocks for computer vision in a hardware-aware manner. Our comparison uses pareto fronts based on randomly sampled networks from a design space to capture the underlying accuracy/complexity trade-offs. We show that our approach allows to match the information obtained by previous comparison paradigms, but provides more insights in the relationship between hardware cost and accuracy. We use our methodology to analyze different building blocks and evaluate their performance on a range of embedded hardware platforms. This highlights the importance of benchmarking building blocks as a preselection step in the design process of a neural network. We show that choosing the right building block can speed up inference by up to a factor of 2x on specific hardware ML accelerators.
Fusing Sentence Embeddings Into LSTM-based Autoregressive Language Models
Aug 05, 2022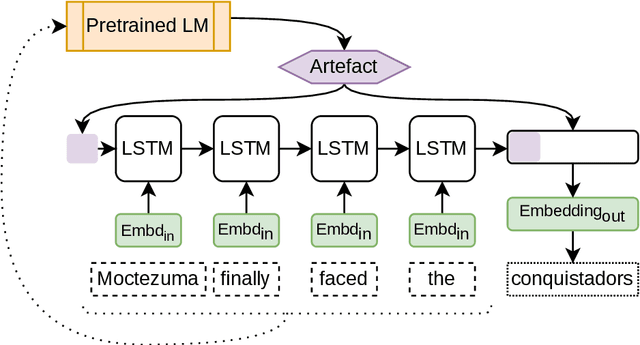
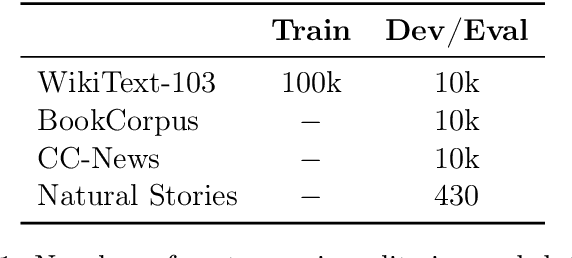
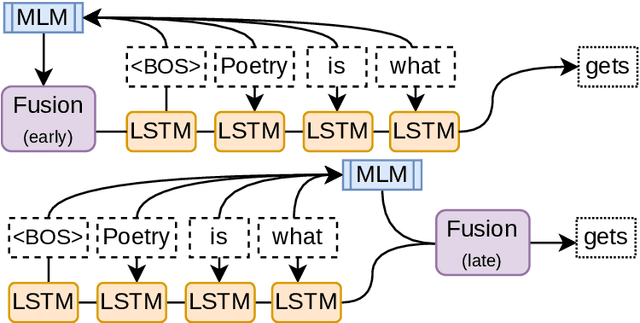

Although masked language models are highly performant and widely adopted by NLP practitioners, they can not be easily used for autoregressive language modelling (next word prediction and sequence probability estimation). We present an LSTM-based autoregressive language model which uses prefix embeddings (from a pretrained masked language model) via fusion (e.g. concatenation) to obtain a richer context representation for language modelling. We find that fusion helps reliably in lowering the perplexity (16.74 $\rightarrow$ 15.80), which is even preserved after a transfer to a dataset from a different domain than the training data. We also evaluate the best-performing fusion model by correlating its next word surprisal estimates with human reading times. Contradicting our expectation, and despite the improvement in perplexity overall, the correlation remains the same as for the baseline model. Lastly, while we focus on language models pre-trained on text as the sources for the fusion, our approach can be possibly extended to fuse any information represented as a fixed-size vector into an auto-regressive language model. These include e.g. sentence external information retrieved for a knowledge base or representations of multi-modal encoders.
gBuilder: A Scalable Knowledge Graph Construction System for Unstructured Corpus
Aug 20, 2022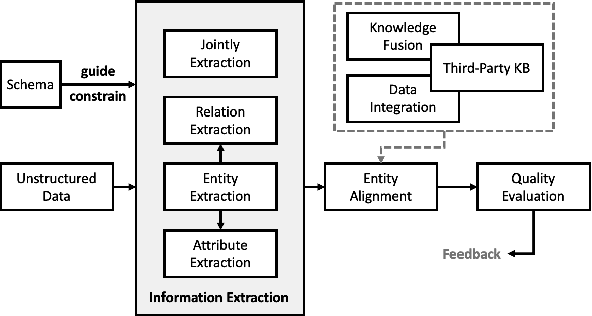

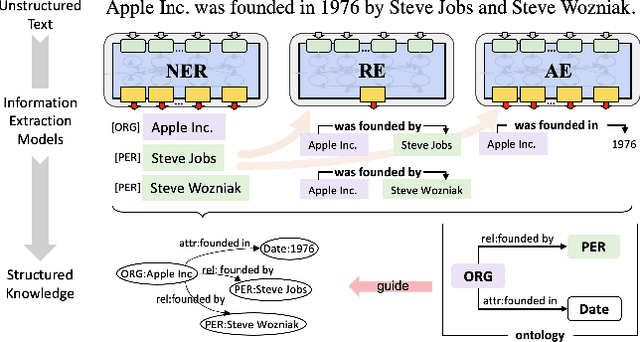
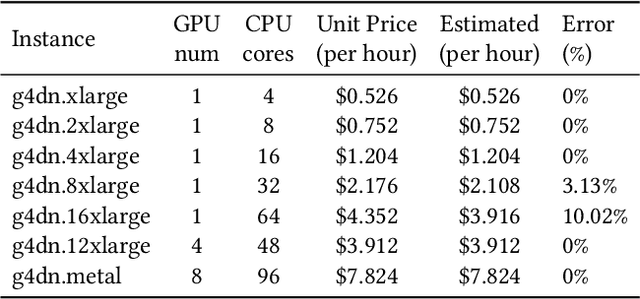
We design a user-friendly and scalable knowledge graph construction (KGC) system for extracting structured knowledge from the unstructured corpus. Different from existing KGC systems, gBuilder provides a flexible and user-defined pipeline to embracing the rapid development of IE models. More built-in template-based or heuristic operators and programmable operators are available for adapting to data from different domains. Furthermore, we also design a cloud-based self-adaptive task scheduling for gBuilder to ensure its scalability on large-scale knowledge graph construction. Experimental evaluation not only demonstrates the ability of gBuilder to organize multiple information extraction models for knowledge graph construction in a uniform platform, and also confirms its high scalability on large-scale KGC task.
Contrastive Learning for Context-aware Neural Machine TranslationUsing Coreference Information
Sep 13, 2021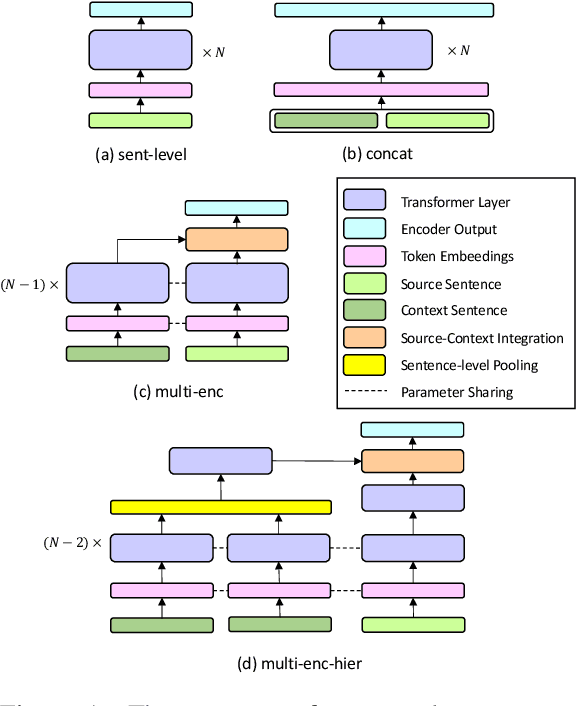
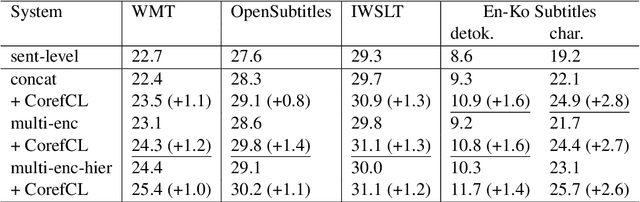

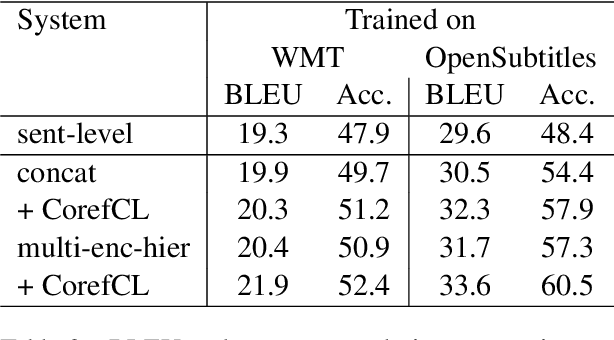
Context-aware neural machine translation (NMT) incorporates contextual information of surrounding texts, that can improve the translation quality of document-level machine translation. Many existing works on context-aware NMT have focused on developing new model architectures for incorporating additional contexts and have shown some promising results. However, most existing works rely on cross-entropy loss, resulting in limited use of contextual information. In this paper, we propose CorefCL, a novel data augmentation and contrastive learning scheme based on coreference between the source and contextual sentences. By corrupting automatically detected coreference mentions in the contextual sentence, CorefCL can train the model to be sensitive to coreference inconsistency. We experimented with our method on common context-aware NMT models and two document-level translation tasks. In the experiments, our method consistently improved BLEU of compared models on English-German and English-Korean tasks. We also show that our method significantly improves coreference resolution in the English-German contrastive test suite.
DeepInteraction: 3D Object Detection via Modality Interaction
Aug 24, 2022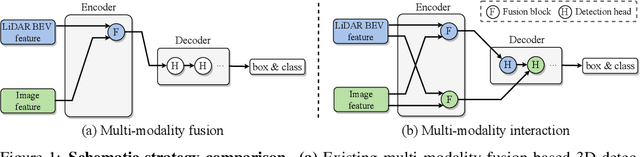
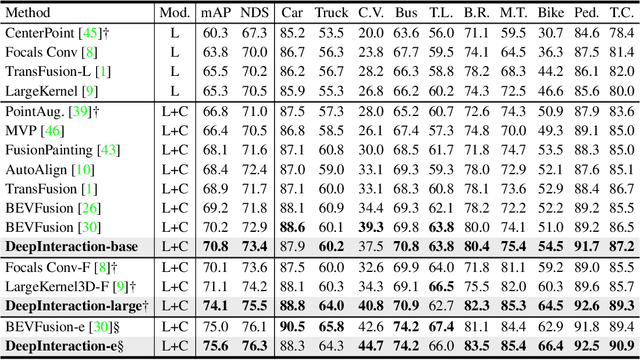
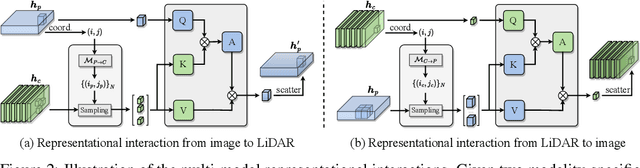
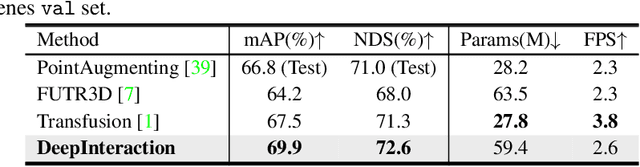
Existing top-performance 3D object detectors typically rely on the multi-modal fusion strategy. This design is however fundamentally restricted due to overlooking the modality-specific useful information and finally hampering the model performance. To address this limitation, in this work we introduce a novel modality interaction strategy where individual per-modality representations are learned and maintained throughout for enabling their unique characteristics to be exploited during object detection. To realize this proposed strategy, we design a DeepInteraction architecture characterized by a multi-modal representational interaction encoder and a multi-modal predictive interaction decoder. Experiments on the large-scale nuScenes dataset show that our proposed method surpasses all prior arts often by a large margin. Crucially, our method is ranked at the first position at the highly competitive nuScenes object detection leaderboard.
Improving the Performance of Automated Audio Captioning via Integrating the Acoustic and Semantic Information
Oct 12, 2021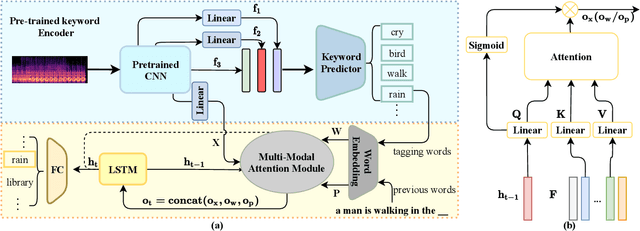
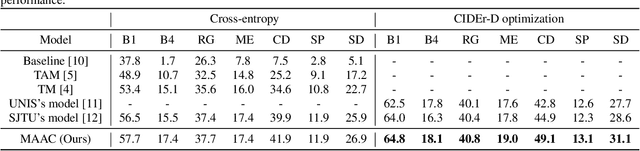
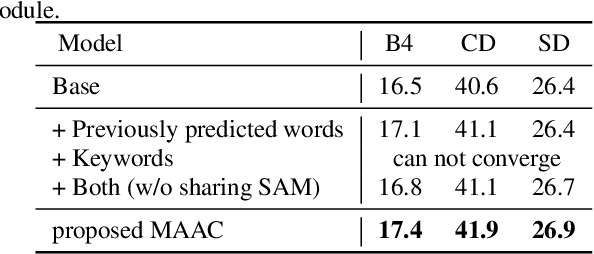
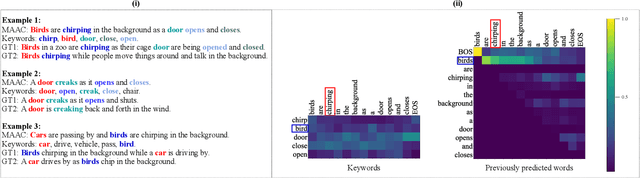
Automated audio captioning (AAC) has developed rapidly in recent years, involving acoustic signal processing and natural language processing to generate human-readable sentences for audio clips. The current models are generally based on the neural encoder-decoder architecture, and their decoder mainly uses acoustic information that is extracted from the CNN-based encoder. However, they have ignored semantic information that could help the AAC model to generate meaningful descriptions. This paper proposes a novel approach for automated audio captioning based on incorporating semantic and acoustic information. Specifically, our audio captioning model consists of two sub-modules. (1) The pre-trained keyword encoder utilizes pre-trained ResNet38 to initialize its parameters, and then it is trained by extracted keywords as labels. (2) The multi-modal attention decoder adopts an LSTM-based decoder that contains semantic and acoustic attention modules. Experiments demonstrate that our proposed model achieves state-of-the-art performance on the Clotho dataset. Our code can be found at https://github.com/WangHelin1997/DCASE2021_Task6_PKU
SpOT: Spatiotemporal Modeling for 3D Object Tracking
Jul 12, 2022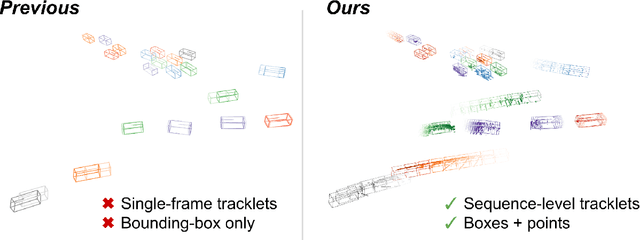
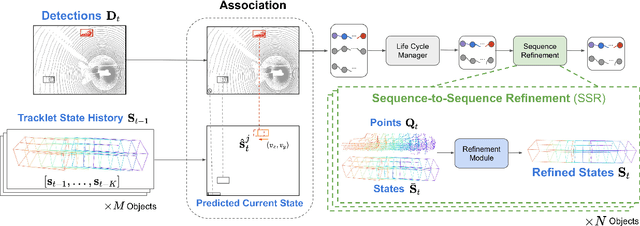
3D multi-object tracking aims to uniquely and consistently identify all mobile entities through time. Despite the rich spatiotemporal information available in this setting, current 3D tracking methods primarily rely on abstracted information and limited history, e.g. single-frame object bounding boxes. In this work, we develop a holistic representation of traffic scenes that leverages both spatial and temporal information of the actors in the scene. Specifically, we reformulate tracking as a spatiotemporal problem by representing tracked objects as sequences of time-stamped points and bounding boxes over a long temporal history. At each timestamp, we improve the location and motion estimates of our tracked objects through learned refinement over the full sequence of object history. By considering time and space jointly, our representation naturally encodes fundamental physical priors such as object permanence and consistency across time. Our spatiotemporal tracking framework achieves state-of-the-art performance on the Waymo and nuScenes benchmarks.
SHDM-NET: Heat Map Detail Guidance with Image Matting for Industrial Weld Semantic Segmentation Network
Jul 09, 2022
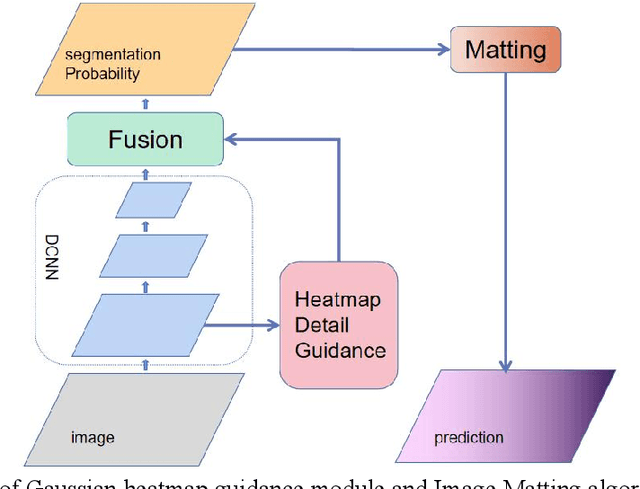
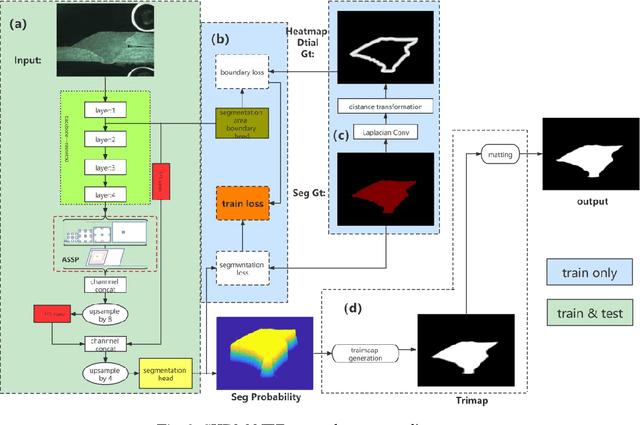
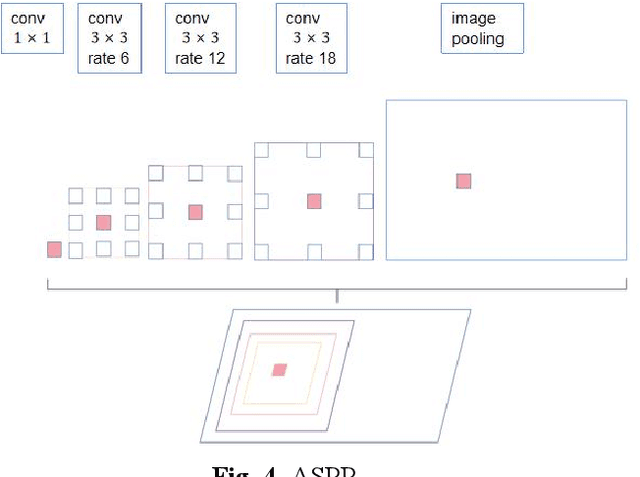
In actual industrial production, the assessment of the steel plate welding effect is an important task, and the segmentation of the weld section is the basis of the assessment. This paper proposes an industrial weld segmentation network based on a deep learning semantic segmentation algorithm fused with heatmap detail guidance and Image Matting to solve the automatic segmentation problem of weld regions. In the existing semantic segmentation networks, the boundary information can be preserved by fusing the features of both high-level and low-level layers. However, this method can lead to insufficient expression of the spatial information in the low-level layer, resulting in inaccurate segmentation boundary positioning. We propose a detailed guidance module based on heatmaps to fully express the segmented region boundary information in the low-level network to address this problem. Specifically, the expression of boundary information can be enhanced by adding a detailed branch to predict segmented boundary and then matching it with the boundary heat map generated by mask labels to calculate the mean square error loss. In addition, although deep learning has achieved great success in the field of semantic segmentation, the precision of the segmentation boundary region is not high due to the loss of detailed information caused by the classical segmentation network in the process of encoding and decoding process. This paper introduces a matting algorithm to calibrate the boundary of the segmentation region of the semantic segmentation network to solve this problem. Through many experiments on industrial weld data sets, the effectiveness of our method is demonstrated, and the MIOU reaches 97.93%. It is worth noting that this performance is comparable to human manual segmentation ( MIOU 97.96%).
RadSegNet: A Reliable Approach to Radar Camera Fusion
Aug 08, 2022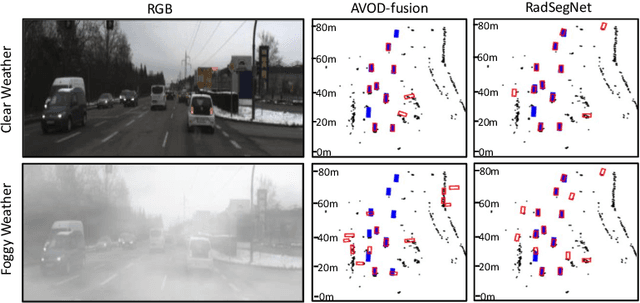
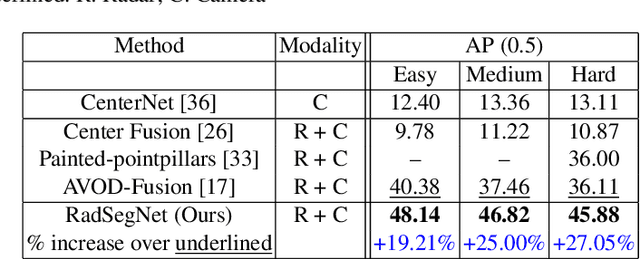
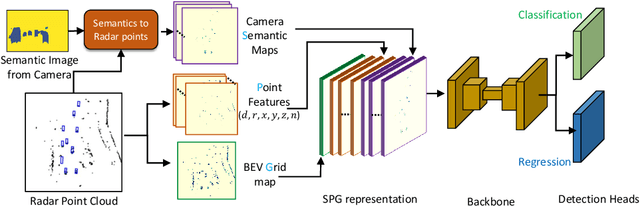
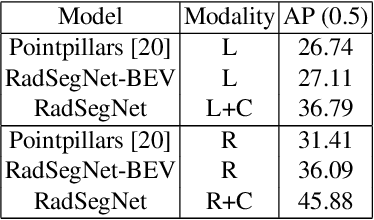
Perception systems for autonomous driving have seen significant advancements in their performance over last few years. However, these systems struggle to show robustness in extreme weather conditions because sensors like lidars and cameras, which are the primary sensors in a sensor suite, see a decline in performance under these conditions. In order to solve this problem, camera-radar fusion systems provide a unique opportunity for all weather reliable high quality perception. Cameras provides rich semantic information while radars can work through occlusions and in all weather conditions. In this work, we show that the state-of-the-art fusion methods perform poorly when camera input is degraded, which essentially results in losing the all-weather reliability they set out to achieve. Contrary to these approaches, we propose a new method, RadSegNet, that uses a new design philosophy of independent information extraction and truly achieves reliability in all conditions, including occlusions and adverse weather. We develop and validate our proposed system on the benchmark Astyx dataset and further verify these results on the RADIATE dataset. When compared to state-of-the-art methods, RadSegNet achieves a 27% improvement on Astyx and 41.46% increase on RADIATE, in average precision score and maintains a significantly better performance in adverse weather conditions
M^4I: Multi-modal Models Membership Inference
Sep 15, 2022
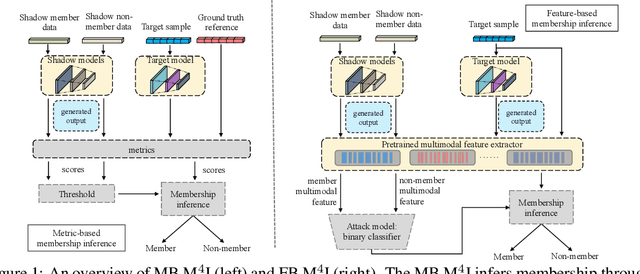
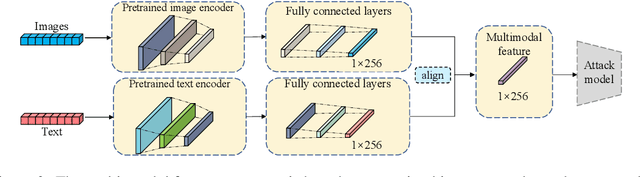
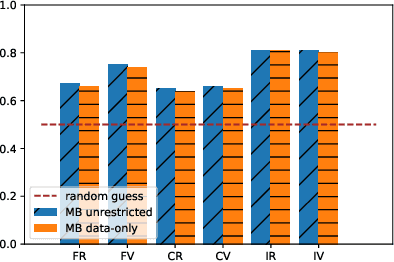
With the development of machine learning techniques, the attention of research has been moved from single-modal learning to multi-modal learning, as real-world data exist in the form of different modalities. However, multi-modal models often carry more information than single-modal models and they are usually applied in sensitive scenarios, such as medical report generation or disease identification. Compared with the existing membership inference against machine learning classifiers, we focus on the problem that the input and output of the multi-modal models are in different modalities, such as image captioning. This work studies the privacy leakage of multi-modal models through the lens of membership inference attack, a process of determining whether a data record involves in the model training process or not. To achieve this, we propose Multi-modal Models Membership Inference (M^4I) with two attack methods to infer the membership status, named metric-based (MB) M^4I and feature-based (FB) M^4I, respectively. More specifically, MB M^4I adopts similarity metrics while attacking to infer target data membership. FB M^4I uses a pre-trained shadow multi-modal feature extractor to achieve the purpose of data inference attack by comparing the similarities from extracted input and output features. Extensive experimental results show that both attack methods can achieve strong performances. Respectively, 72.5% and 94.83% of attack success rates on average can be obtained under unrestricted scenarios. Moreover, we evaluate multiple defense mechanisms against our attacks. The source code of M^4I attacks is publicly available at https://github.com/MultimodalMI/Multimodal-membership-inference.git.