 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bootstrapped Masked Autoencoders for Vision BERT Pretraining
Jul 14, 2022
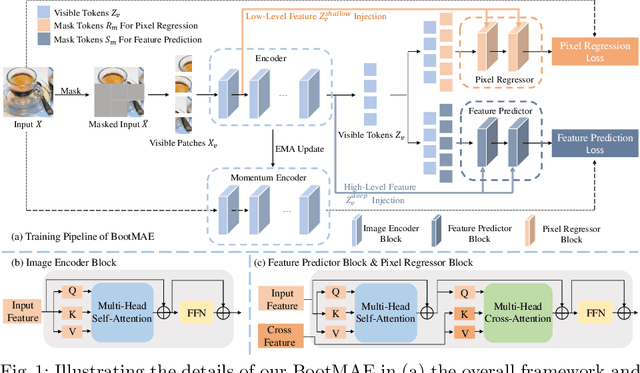



We propose bootstrapped masked autoencoders (BootMAE), a new approach for vision BERT pretraining. BootMAE improves the original masked autoencoders (MAE) with two core designs: 1) momentum encoder that provides online feature as extra BERT prediction targets; 2) target-aware decoder that tries to reduce the pressure on the encoder to memorize target-specific information in BERT pretraining. The first design is motivated by the observation that using a pretrained MAE to extract the features as the BERT prediction target for masked tokens can achieve better pretraining performance. Therefore, we add a momentum encoder in parallel with the original MAE encoder, which bootstraps the pretraining performance by using its own representation as the BERT prediction target. In the second design, we introduce target-specific information (e.g., pixel values of unmasked patches) from the encoder directly to the decoder to reduce the pressure on the encoder of memorizing the target-specific information. Thus, the encoder focuses on semantic modeling, which is the goal of BERT pretraining, and does not need to waste its capacity in memorizing the information of unmasked tokens related to the prediction target. Through extensive experiments, our BootMAE achieves $84.2\%$ Top-1 accuracy on ImageNet-1K with ViT-B backbone, outperforming MAE by $+0.8\%$ under the same pre-training epochs. BootMAE also gets $+1.0$ mIoU improvements on semantic segmentation on ADE20K and $+1.3$ box AP, $+1.4$ mask AP improvement on object detection and segmentation on COCO dataset. Code is released at https://github.com/LightDXY/BootMAE.
Digital Image Processing Applied To Object Segmentation By Intensity And Motion
Aug 26, 2022The current technological development allows us to carry out tasks that some time ago were unthinkable if not impossible, digital image processing has been one of the major constants of development today, taking into account that its implementation dates from a short time ago, OpenCV [1] is a tool focused on machine vision, In this case implemented in an object-oriented programming platform based on Java language offered by the NetBeans development software, based on the above, a physical platform was proposed and implemented as a closed environment which through the development of an algorithm allowed detection and segmentation of objects by means of the RGB color model; In future works this algorithm will provide the information base for the autonomous robotic platform; this advance opens a wide spectrum for the development of applications and tools in the field of artificial vision.
Exploring and Exploiting Multi-Granularity Representations for Machine Reading Comprehension
Aug 18, 2022
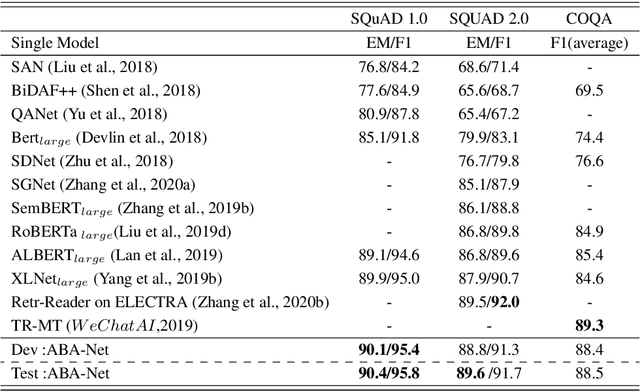
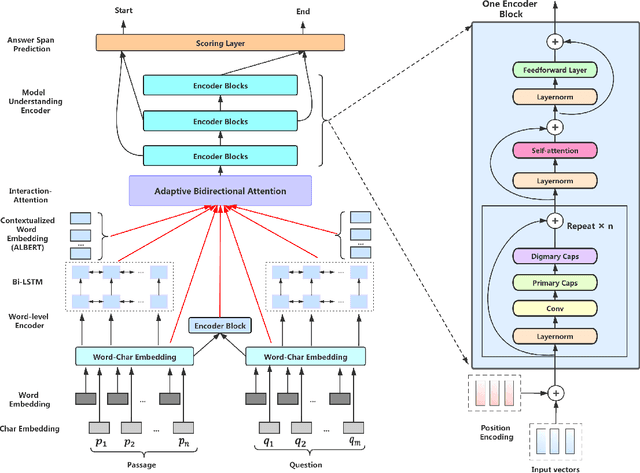

Recently, the attention-enhanced multi-layer encoder, such as Transformer, has been extensively studied in Machine Reading Comprehension (MRC). To predict the answer, it is common practice to employ a predictor to draw information only from the final encoder layer which generates the coarse-grained representations of the source sequences, i.e., passage and question. The analysis shows that the representation of source sequence becomes more coarse-grained from finegrained as the encoding layer increases. It is generally believed that with the growing number of layers in deep neural networks, the encoding process will gather relevant information for each location increasingly, resulting in more coarse-grained representations, which adds the likelihood of similarity to other locations (referring to homogeneity). Such phenomenon will mislead the model to make wrong judgement and degrade the performance. In this paper, we argue that it would be better if the predictor could exploit representations of different granularity from the encoder, providing different views of the source sequences, such that the expressive power of the model could be fully utilized. To this end, we propose a novel approach called Adaptive Bidirectional Attention-Capsule Network (ABA-Net), which adaptively exploits the source representations of different levels to the predictor. Furthermore, due to the better representations are at the core for boosting MRC performance, the capsule network and self-attention module are carefully designed as the building blocks of our encoders, which provides the capability to explore the local and global representations, respectively. Experimental results on three benchmark datasets, i.e., SQuAD 1.0, SQuAD 2.0 and COQA, demonstrate the effectiveness of our approach. In particular, we set the new state-of-the-art performance on the SQuAD 1.0 dataset
Investigation into Target Speaking Rate Adaptation for Voice Conversion
Sep 05, 2022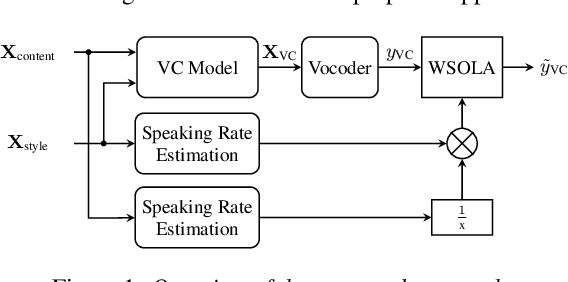

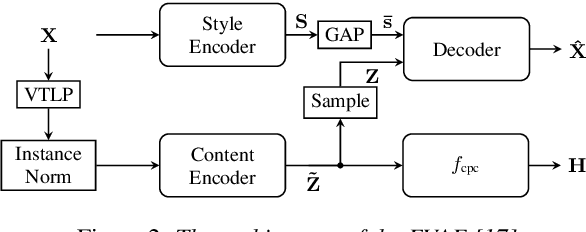
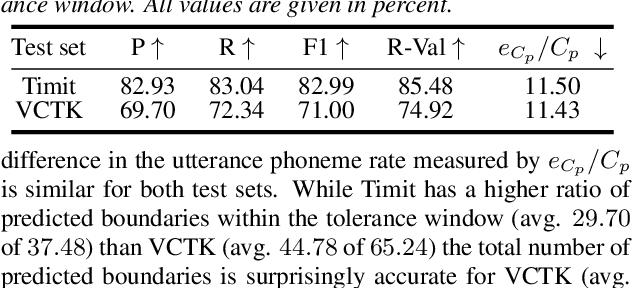
Disentangling speaker and content attributes of a speech signal into separate latent representations followed by decoding the content with an exchanged speaker representation is a popular approach for voice conversion, which can be trained with non-parallel and unlabeled speech data. However, previous approaches perform disentanglement only implicitly via some sort of information bottleneck or normalization, where it is usually hard to find a good trade-off between voice conversion and content reconstruction. Further, previous works usually do not consider an adaptation of the speaking rate to the target speaker or they put some major restrictions to the data or use case. Therefore, the contribution of this work is two-fold. First, we employ an explicit and fully unsupervised disentanglement approach, which has previously only been used for representation learning, and show that it allows to obtain both superior voice conversion and content reconstruction. Second, we investigate simple and generic approaches to linearly adapt the length of a speech signal, and hence the speaking rate, to a target speaker and show that the proposed adaptation allows to increase the speaking rate similarity with respect to the target speaker.
A taxonomy of surprise definitions
Sep 02, 2022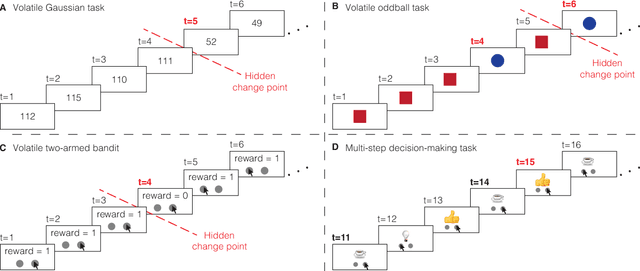

Surprising events trigger measurable brain activity and influence human behavior by affecting learning, memory, and decision-making. Currently there is, however, no consensus on the definition of surprise. Here we identify 18 mathematical definitions of surprise in a unifying framework. We first propose a technical classification of these definitions into three groups based on their dependence on an agent's belief, show how they relate to each other, and prove under what conditions they are indistinguishable. Going beyond this technical analysis, we propose a taxonomy of surprise definitions and classify them into four conceptual categories based on the quantity they measure: (i) 'prediction surprise' measures a mismatch between a prediction and an observation; (ii) 'change-point detection surprise' measures the probability of a change in the environment; (iii) 'confidence-corrected surprise' explicitly accounts for the effect of confidence; and (iv) 'information gain surprise' measures the belief-update upon a new observation. The taxonomy poses the foundation for principled studies of the functional roles and physiological signatures of surprise in the brain.
Mapping the ocular surface from monocular videos with an application to dry eye disease grading
Sep 05, 2022With a prevalence of 5 to 50%, Dry Eye Disease (DED) is one of the leading reasons for ophthalmologist consultations. The diagnosis and quantification of DED usually rely on ocular surface analysis through slit-lamp examinations. However, evaluations are subjective and non-reproducible. To improve the diagnosis, we propose to 1) track the ocular surface in 3-D using video recordings acquired during examinations, and 2) grade the severity using registered frames. Our registration method uses unsupervised image-to-depth learning. These methods learn depth from lights and shadows and estimate pose based on depth maps. However, DED examinations undergo unresolved challenges including a moving light source, transparent ocular tissues, etc. To overcome these and estimate the ego-motion, we implement joint CNN architectures with multiple losses incorporating prior known information, namely the shape of the eye, through semantic segmentation as well as sphere fitting. The achieved tracking errors outperform the state-of-the-art, with a mean Euclidean distance as low as 0.48% of the image width on our test set. This registration improves the DED severity classification by a 0.20 AUC difference. The proposed approach is the first to address DED diagnosis with supervision from monocular videos
Graph Distance Neural Networks for Predicting Multiple Drug Interactions
Aug 30, 2022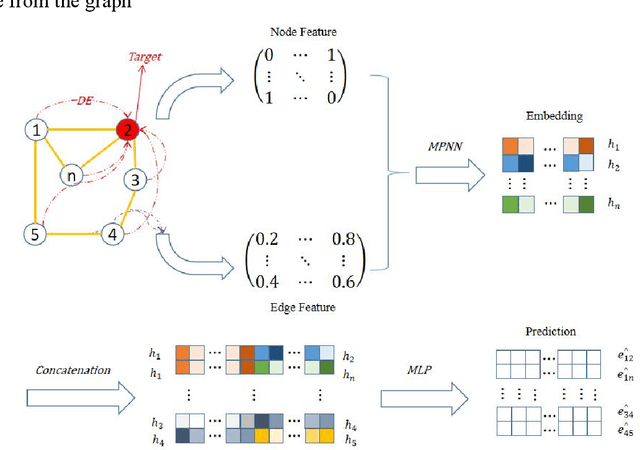
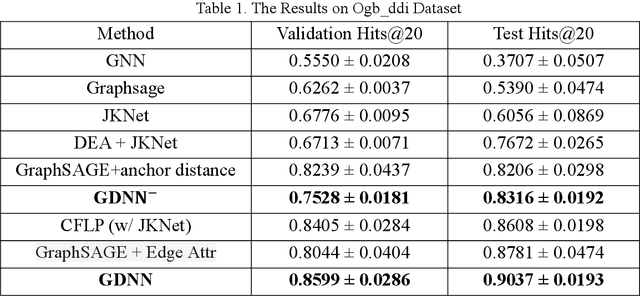
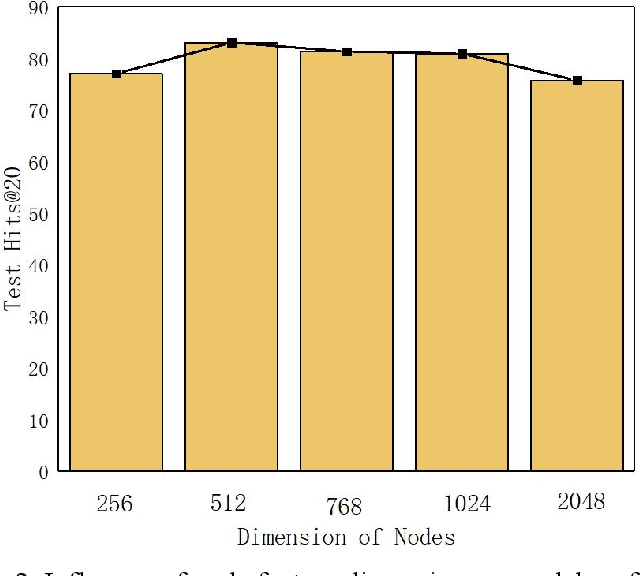
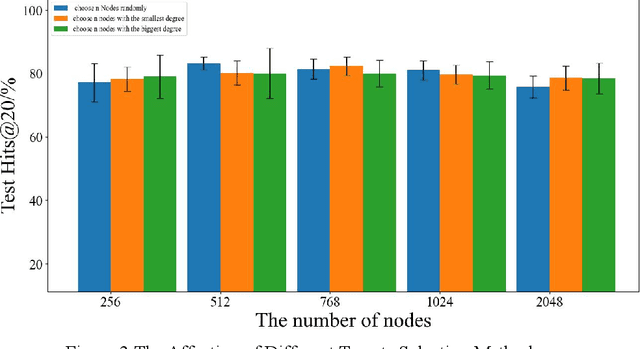
Since multidrug combination is widely applied, the accurate prediction of drug-drug interaction (DDI) is becoming more and more critical. In our method, we use graph to represent drug-drug interaction: nodes represent drug; edges represent drug-drug interactions. Based on our assumption, we convert the prediction of DDI to link prediction problem, utilizing known drug node characteristics and DDI types to predict unknown DDI types. This work proposes a Graph Distance Neural Network (GDNN) to predict drug-drug interactions. Firstly, GDNN generates initial features for nodes via target point method, fully including the distance information in the graph. Secondly, GDNN adopts an improved message passing framework to better generate each drug node embedded expression, comprehensively considering the nodes and edges characteristics synchronously. Thirdly, GDNN aggregates the embedded expressions, undergoing MLP processing to generate the final predicted drug interaction type. GDNN achieved Test Hits@20=0.9037 on the ogb-ddi dataset, proving GDNN can predict DDI efficiently.
3D Siamese Transformer Network for Single Object Tracking on Point Clouds
Jul 26, 2022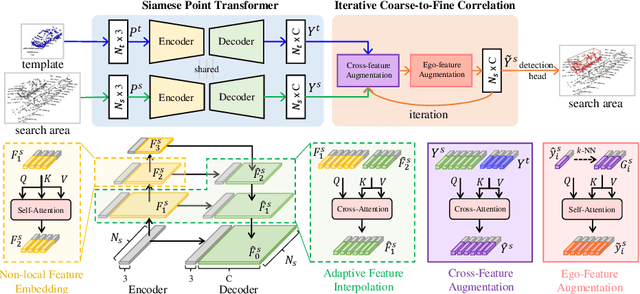
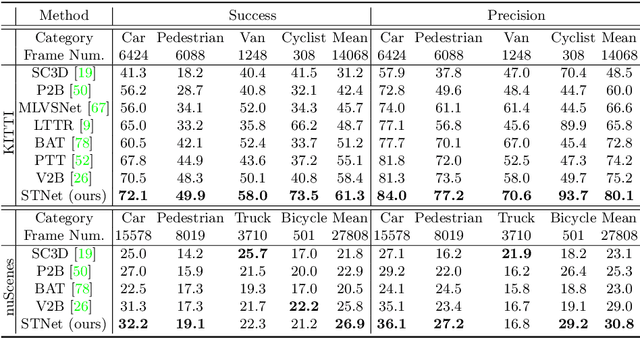
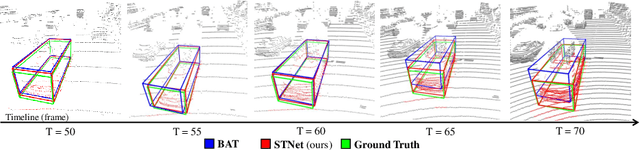
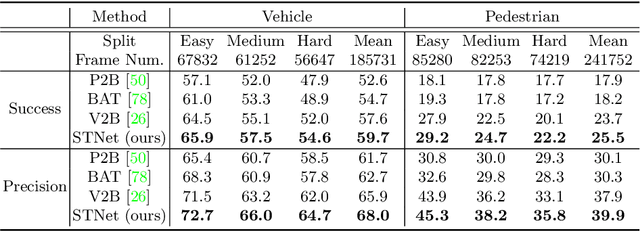
Siamese network based trackers formulate 3D single object tracking as cross-correlation learning between point features of a template and a search area. Due to the large appearance variation between the template and search area during tracking, how to learn the robust cross correlation between them for identifying the potential target in the search area is still a challenging problem. In this paper, we explicitly use Transformer to form a 3D Siamese Transformer network for learning robust cross correlation between the template and the search area of point clouds. Specifically, we develop a Siamese point Transformer network to learn shape context information of the target. Its encoder uses self-attention to capture non-local information of point clouds to characterize the shape information of the object, and the decoder utilizes cross-attention to upsample discriminative point features. After that, we develop an iterative coarse-to-fine correlation network to learn the robust cross correlation between the template and the search area. It formulates the cross-feature augmentation to associate the template with the potential target in the search area via cross attention. To further enhance the potential target, it employs the ego-feature augmentation that applies self-attention to the local k-NN graph of the feature space to aggregate target features. Experiments on the KITTI, nuScenes, and Waymo datasets show that our method achieves state-of-the-art performance on the 3D single object tracking task.
SoftGroup++: Scalable 3D Instance Segmentation with Octree Pyramid Grouping
Sep 17, 2022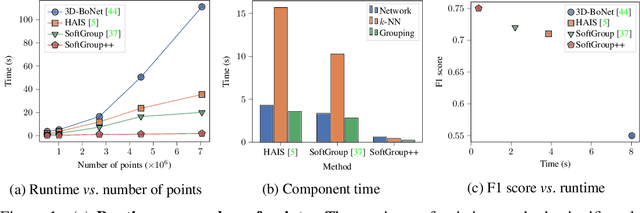
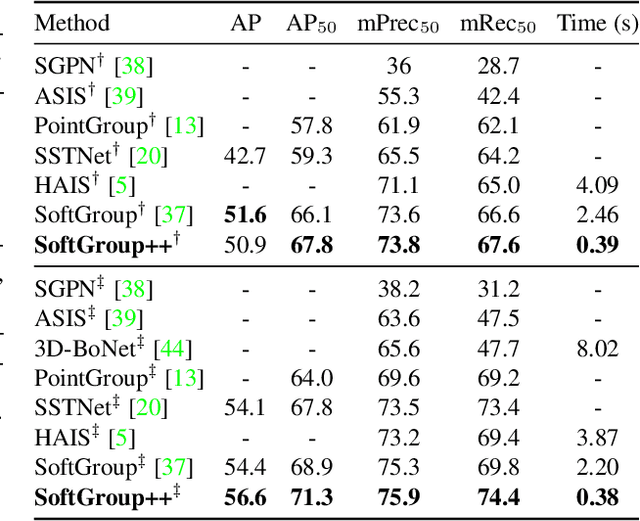
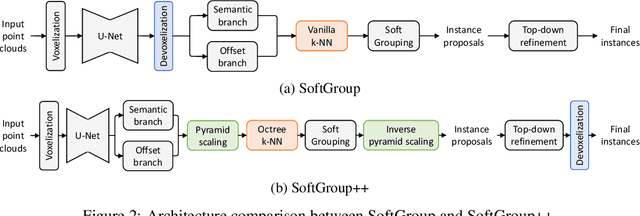
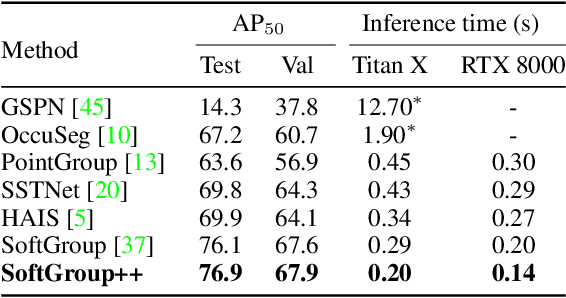
Existing state-of-the-art 3D point cloud instance segmentation methods rely on a grouping-based approach that groups points to obtain object instances. Despite improvement in producing accurate segmentation results, these methods lack scalability and commonly require dividing large input into multiple parts. To process a scene with millions of points, the existing fastest method SoftGroup \cite{vu2022softgroup} requires tens of seconds, which is under satisfaction. Our finding is that $k$-Nearest Neighbor ($k$-NN), which serves as the prerequisite of grouping, is a computational bottleneck. This bottleneck severely worsens the inference time in the scene with a large number of points. This paper proposes SoftGroup++ to address this computational bottleneck and further optimize the inference speed of the whole network. SoftGroup++ is built upon SoftGroup, which differs in three important aspects: (1) performs octree $k$-NN instead of vanilla $k$-NN to reduce time complexity from $\mathcal{O}(n^2)$ to $\mathcal{O}(n \log n)$, (2) performs pyramid scaling that adaptively downsamples backbone outputs to reduce search space for $k$-NN and grouping, and (3) performs late devoxelization that delays the conversion from voxels to points towards the end of the model such that intermediate components operate at a low computational cost. Extensive experiments on various indoor and outdoor datasets demonstrate the efficacy of the proposed SoftGroup++. Notably, SoftGroup++ processes large scenes of millions of points by a single forward without dividing the input into multiple parts, thus enriching contextual information. Especially, SoftGroup++ achieves 2.4 points AP$_{50}$ improvement while nearly $6\times$ faster than the existing fastest method on S3DIS dataset. The code and trained models will be made publicly available.
Invariant Information Bottleneck for Domain Generalization
Jun 11, 2021
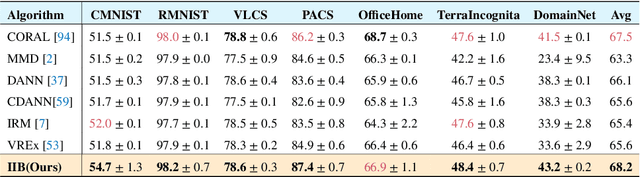
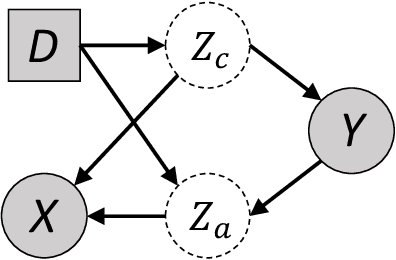
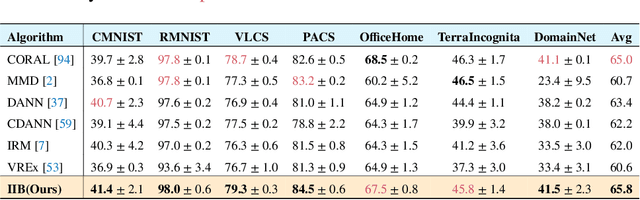
The main challenge for domain generalization (DG) is to overcome the potential distributional shift between multiple training domains and unseen test domains. One popular class of DG algorithms aims to learn representations that have an invariant causal relation across the training domains. However, certain features, called \emph{pseudo-invariant features}, may be invariant in the training domain but not the test domain and can substantially decreases the performance of existing algorithms. To address this issue, we propose a novel algorithm, called Invariant Information Bottleneck (IIB), that learns a minimally sufficient representation that is invariant across training and testing domains. By minimizing the mutual information between the representation and inputs, IIB alleviates its reliance on pseudo-invariant features, which is desirable for DG. To verify the effectiveness of the IIB principle, we conduct extensive experiments on large-scale DG benchmarks. The results show that IIB outperforms invariant learning baseline (e.g. IRM) by an average of 2.8\% and 3.8\% accuracy over two evaluation metrics.