 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TAG: Boosting Text-VQA via Text-aware Visual Question-answer Generation
Aug 03, 2022
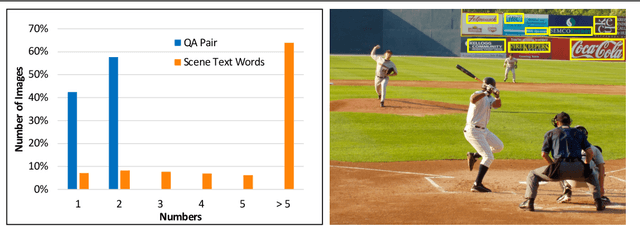
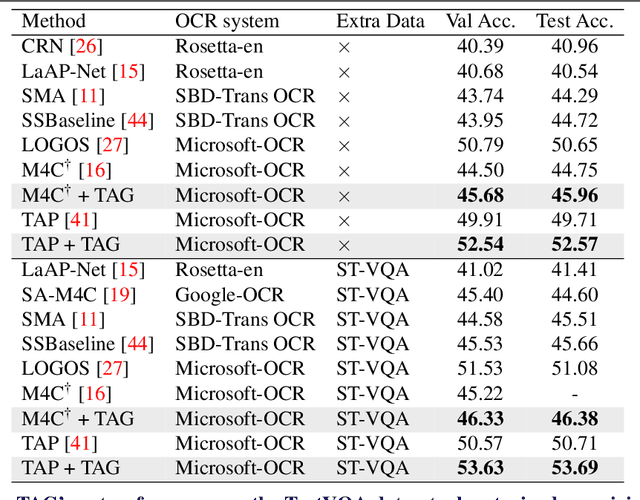

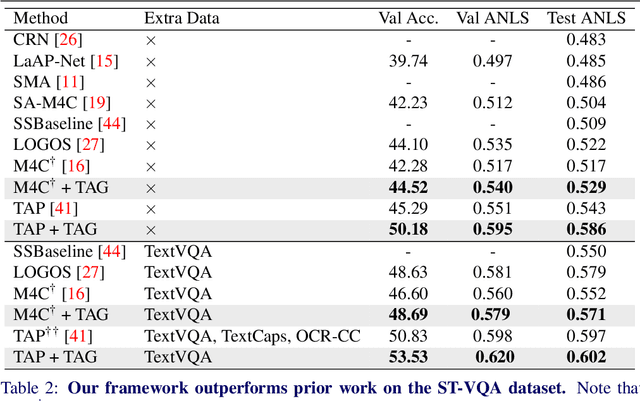
Text-VQA aims at answering questions that require understanding the textual cues in an image. Despite the great progress of existing Text-VQA methods, their performance suffers from insufficient human-labeled question-answer (QA) pairs. However, we observe that, in general, the scene text is not fully exploited in the existing datasets -- only a small portion of text in each image participates in the annotated QA activities. This results in a huge waste of useful information. To address this deficiency, we develop a new method to generate high-quality and diverse QA pairs by explicitly utilizing the existing rich text available in the scene context of each image. Specifically, we propose, TAG, a text-aware visual question-answer generation architecture that learns to produce meaningful, and accurate QA samples using a multimodal transformer. The architecture exploits underexplored scene text information and enhances scene understanding of Text-VQA models by combining the generated QA pairs with the initial training data. Extensive experimental results on two well-known Text-VQA benchmarks (TextVQA and ST-VQA) demonstrate that our proposed TAG effectively enlarges the training data that helps improve the Text-VQA performance without extra labeling effort. Moreover, our model outperforms state-of-the-art approaches that are pre-trained with extra large-scale data. Code will be made publicly available.
Temporally Adjustable Longitudinal Fluid-Attenuated Inversion Recovery MRI Estimation / Synthesis for Multiple Sclerosis
Sep 09, 2022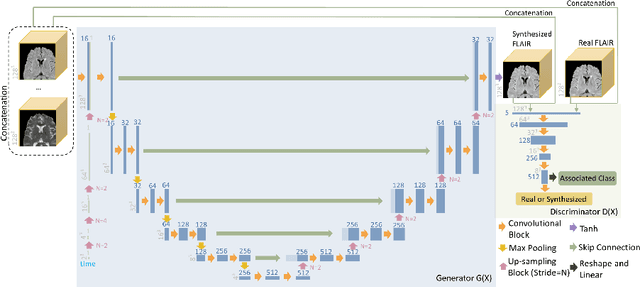
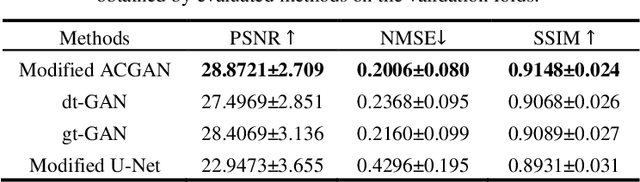
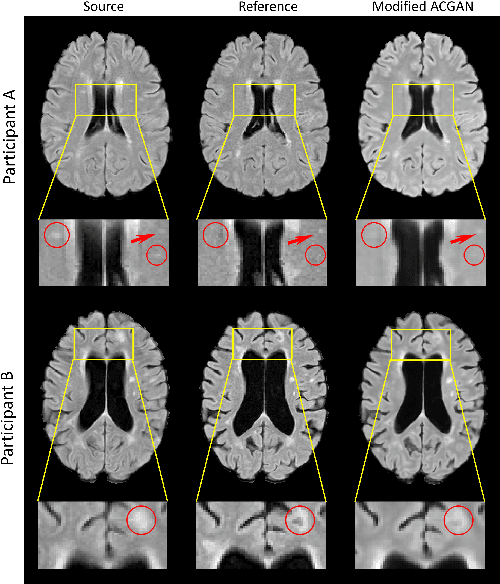
Multiple Sclerosis (MS) is a chronic progressive neurological disease characterized by the development of lesions in the white matter of the brain. T2-fluid-attenuated inversion recovery (FLAIR) brain magnetic resonance imaging (MRI) provides superior visualization and characterization of MS lesions, relative to other MRI modalities. Longitudinal brain FLAIR MRI in MS, involving repetitively imaging a patient over time, provides helpful information for clinicians towards monitoring disease progression. Predicting future whole brain MRI examinations with variable time lag has only been attempted in limited applications, such as healthy aging and structural degeneration in Alzheimer's Disease. In this article, we present novel modifications to deep learning architectures for MS FLAIR image synthesis, in order to support prediction of longitudinal images in a flexible continuous way. This is achieved with learned transposed convolutions, which support modelling time as a spatially distributed array with variable temporal properties at different spatial locations. Thus, this approach can theoretically model spatially-specific time-dependent brain development, supporting the modelling of more rapid growth at appropriate physical locations, such as the site of an MS brain lesion. This approach also supports the clinician user to define how far into the future a predicted examination should target. Accurate prediction of future rounds of imaging can inform clinicians of potentially poor patient outcomes, which may be able to contribute to earlier treatment and better prognoses. Four distinct deep learning architectures have been developed. The ISBI2015 longitudinal MS dataset was used to validate and compare our proposed approaches. Results demonstrate that a modified ACGAN achieves the best performance and reduces variability in model accuracy.
Coarse-to-Fine Knowledge-Enhanced Multi-Interest Learning Framework for Multi-Behavior Recommendation
Aug 05, 2022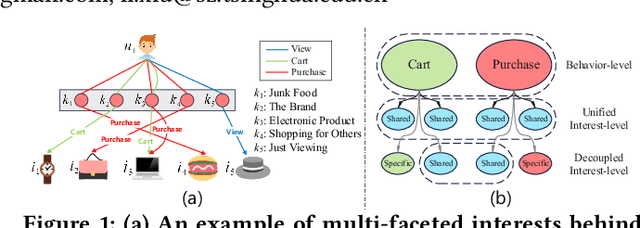
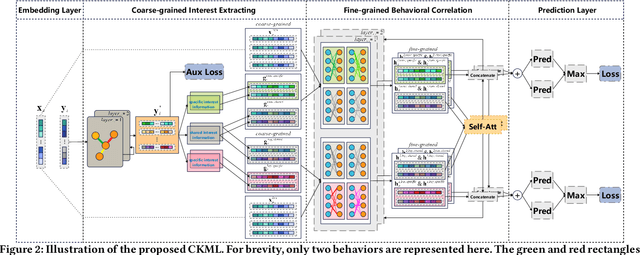
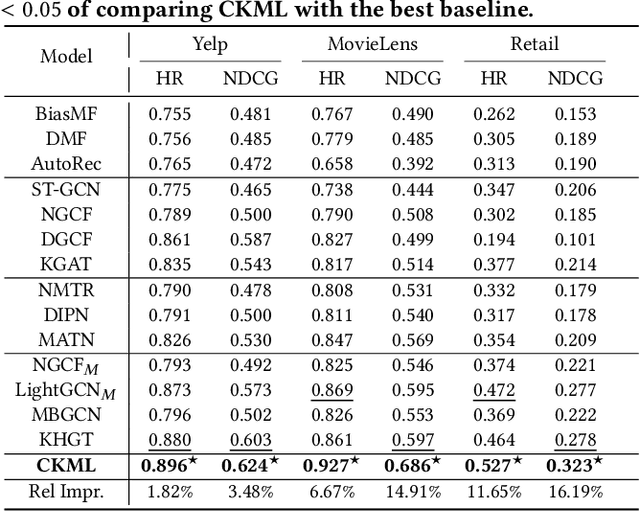
Multi-types of behaviors (e.g., clicking, adding to cart, purchasing, etc.) widely exist in most real-world recommendation scenarios, which are beneficial to learn users' multi-faceted preferences. As dependencies are explicitly exhibited by the multiple types of behaviors, effectively modeling complex behavior dependencies is crucial for multi-behavior prediction. The state-of-the-art multi-behavior models learn behavior dependencies indistinguishably with all historical interactions as input. However, different behaviors may reflect different aspects of user preference, which means that some irrelevant interactions may play as noises to the target behavior to be predicted. To address the aforementioned limitations, we introduce multi-interest learning to the multi-behavior recommendation. More specifically, we propose a novel Coarse-to-fine Knowledge-enhanced Multi-interest Learning (CKML) framework to learn shared and behavior-specific interests for different behaviors. CKML introduces two advanced modules, namely Coarse-grained Interest Extracting (CIE) and Fine-grained Behavioral Correlation (FBC), which work jointly to capture fine-grained behavioral dependencies. CIE uses knowledge-aware information to extract initial representations of each interest. FBC incorporates a dynamic routing scheme to further assign each behavior among interests. Additionally, we use the self-attention mechanism to correlate different behavioral information at the interest level. Empirical results on three real-world datasets verify the effectiveness and efficiency of our model in exploiting multi-behavior data. Further experiments demonstrate the effectiveness of each module and the robustness and superiority of the shared and specific modelling paradigm for multi-behavior data.
Type-enriched Hierarchical Contrastive Strategy for Fine-Grained Entity Typing
Aug 22, 2022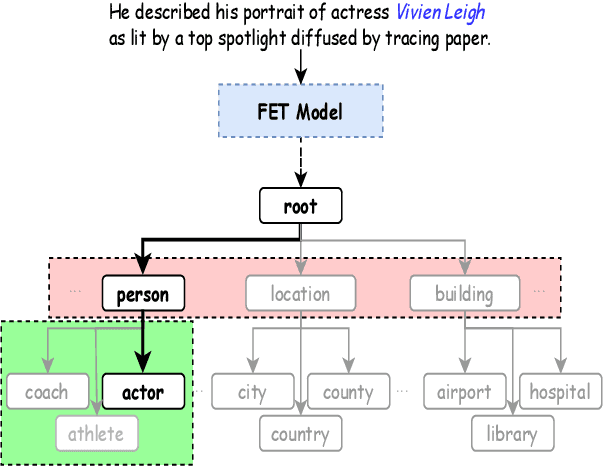
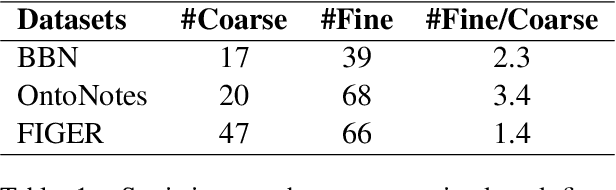
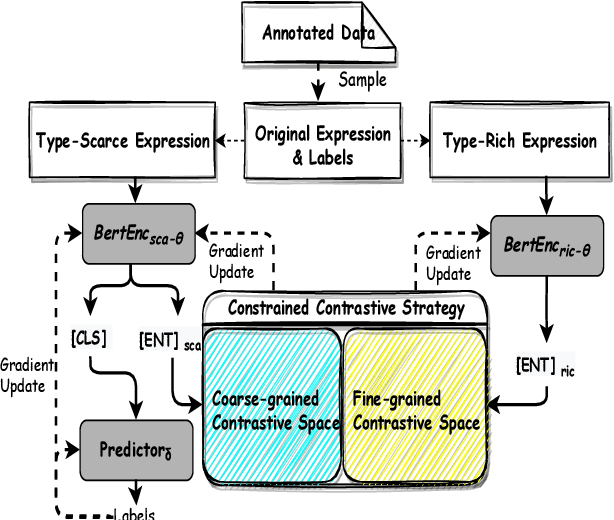
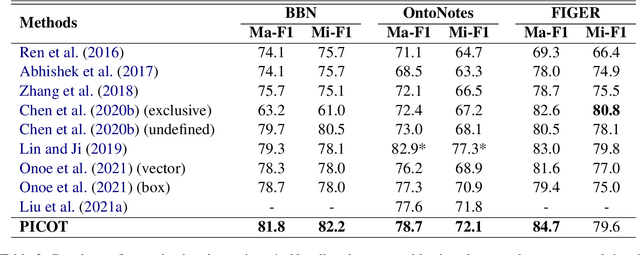
Fine-grained entity typing (FET) aims to deduce specific semantic types of the entity mentions in text. Modern methods for FET mainly focus on learning what a certain type looks like. And few works directly model the type differences, that is, let models know the extent that one type is different from others. To alleviate this problem, we propose a type-enriched hierarchical contrastive strategy for FET. Our method can directly model the differences between hierarchical types and improve the ability to distinguish multi-grained similar types. On the one hand, we embed type into entity contexts to make type information directly perceptible. On the other hand, we design a constrained contrastive strategy on the hierarchical structure to directly model the type differences, which can simultaneously perceive the distinguishability between types at different granularity. Experimental results on three benchmarks, BBN, OntoNotes, and FIGER show that our method achieves significant performance on FET by effectively modeling type differences.
Proceedings End-to-End Compositional Models of Vector-Based Semantics
Aug 10, 2022The workshop End-to-End Compositional Models of Vector-Based Semantics was held at NUI Galway on 15 and 16 August 2022 as part of the 33rd European Summer School in Logic, Language and Information (ESSLLI 2022). The workshop was sponsored by the research project 'A composition calculus for vector-based semantic modelling with a localization for Dutch' (Dutch Research Council 360-89-070, 2017-2022). The workshop program was made up of two parts, the first part reporting on the results of the aforementioned project, the second part consisting of contributed papers on related approaches. The present volume collects the contributed papers and the abstracts of the invited talks.
Neural Network Verification using Residual Reasoning
Aug 05, 2022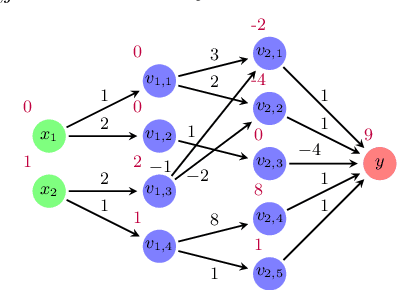
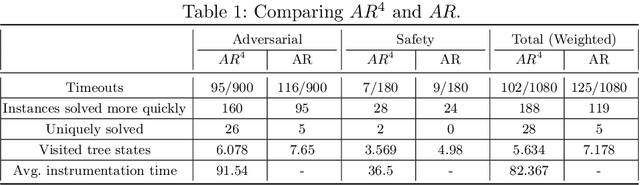
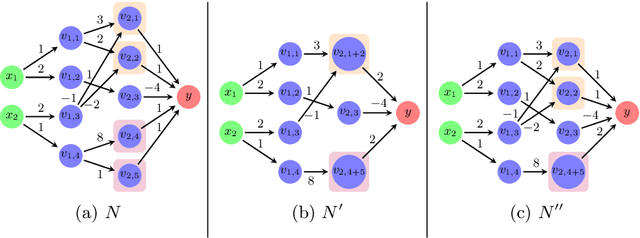
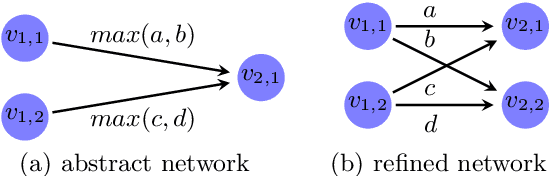
With the increasing integration of neural networks as components in mission-critical systems, there is an increasing need to ensure that they satisfy various safety and liveness requirements. In recent years, numerous sound and complete verification methods have been proposed towards that end, but these typically suffer from severe scalability limitations. Recent work has proposed enhancing such verification techniques with abstraction-refinement capabilities, which have been shown to boost scalability: instead of verifying a large and complex network, the verifier constructs and then verifies a much smaller network, whose correctness implies the correctness of the original network. A shortcoming of such a scheme is that if verifying the smaller network fails, the verifier needs to perform a refinement step that increases the size of the network being verified, and then start verifying the new network from scratch -- effectively ``wasting'' its earlier work on verifying the smaller network. In this paper, we present an enhancement to abstraction-based verification of neural networks, by using \emph{residual reasoning}: the process of utilizing information acquired when verifying an abstract network, in order to expedite the verification of a refined network. In essence, the method allows the verifier to store information about parts of the search space in which the refined network is guaranteed to behave correctly, and allows it to focus on areas where bugs might be discovered. We implemented our approach as an extension to the Marabou verifier, and obtained promising results.
Learning to Navigate using Visual Sensor Networks
Aug 05, 2022
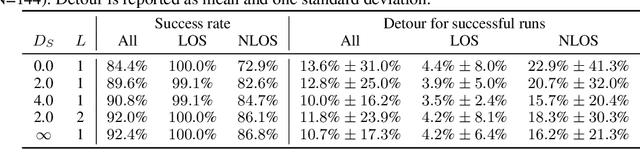
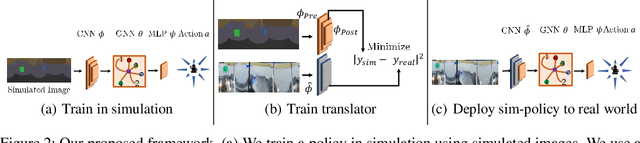
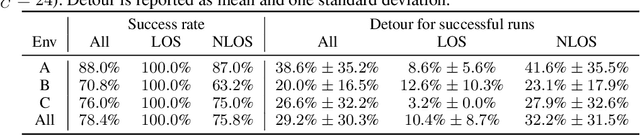
We consider the problem of navigating a mobile robot towards a target in an unknown environment that is endowed with visual sensors, where neither the robot nor the sensors have access to global positioning information and only use first-person-view images. While prior work in sensor network-based navigation uses explicit mapping and planning techniques, and is often aided by external positioning systems, we propose a vision-only based learning approach that leverages a Graph Neural Network (GNN) to encode and communicate relevant viewpoint information to the mobile robot. During navigation, the robot is guided by a model that we train through imitation learning to approximate optimal motion primitives, thereby predicting the effective cost-to-go (to the target). In our experiments, we first demonstrate generalizability to previously unseen environments with various sensor layouts. The results show that communication among the sensors and robot facilitates a significant improvement in success rate while decreasing path detour mean and variability. This is done without requiring a global map, positioning data, nor pre-calibration of the sensor network. Second, we perform a zero-shot transfer of our model from simulation to the real world. To this end, we train a`translator' model that translates between {latent encodings of} real and simulated images so that the navigation policy (which is trained entirely in simulation) can be used directly on the real robot, without additional fine-tuning. Physical experiments demonstrate the feasibility of our approach in various cluttered environments.
Isoform Function Prediction Using Deep Neural Network
Aug 05, 2022



Isoforms are mRNAs produced from the same gene site in the phenomenon called Alternative Splicing. Studies have shown that more than 95% of human multi-exon genes have undergone alternative splicing. Although there are few changes in mRNA sequence, They may have a systematic effect on cell function and regulation. It is widely reported that isoforms of a gene have distinct or even contrasting functions. Most studies have shown that alternative splicing plays a significant role in human health and disease. Despite the wide range of gene function studies, there is little information about isoforms' functionalities. Recently, some computational methods based on Multiple Instance Learning have been proposed to predict isoform function using gene function and gene expression profile. However, their performance is not desirable due to the lack of labeled training data. In addition, probabilistic models such as Conditional Random Field (CRF) have been used to model the relation between isoforms. This project uses all the data and valuable information such as isoform sequences, expression profiles, and gene ontology graphs and proposes a comprehensive model based on Deep Neural Networks. The UniProt Gene Ontology (GO) database is used as a standard reference for gene functions. The NCBI RefSeq database is used for extracting gene and isoform sequences, and the NCBI SRA database is used for expression profile data. Metrics such as Receiver Operating Characteristic Area Under the Curve (ROC AUC) and Precision-Recall Under the Curve (PR AUC) are used to measure the prediction accuracy.
Learning an Ensemble of Deep Fingerprint Representations
Sep 02, 2022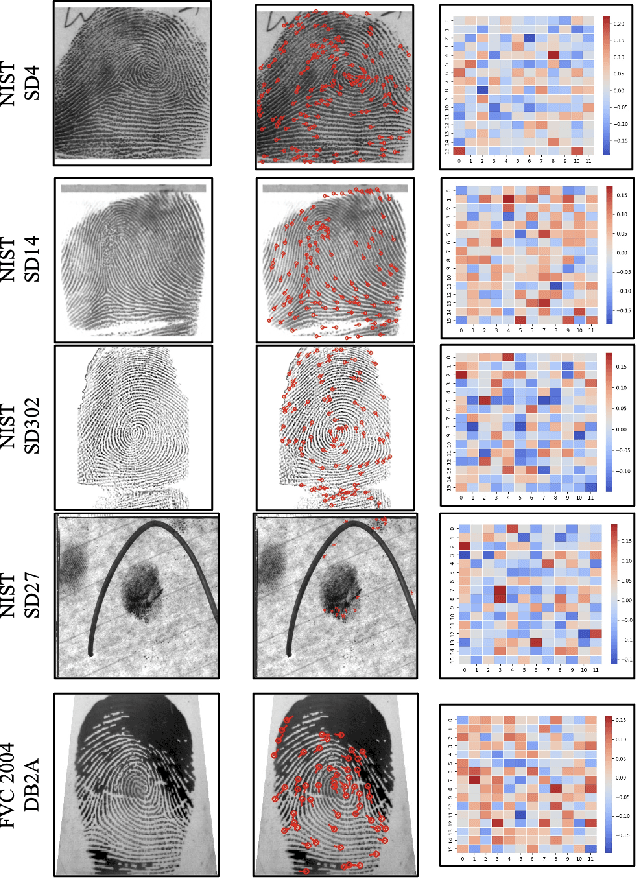

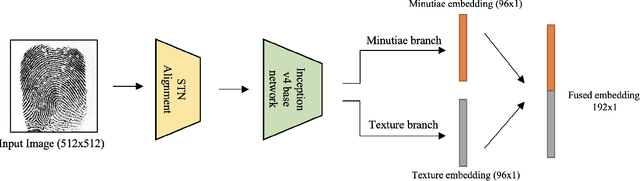
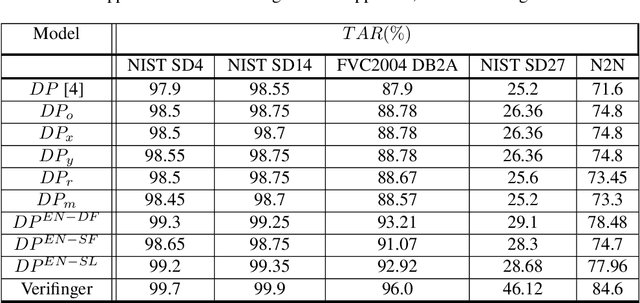
Deep neural networks (DNNs) have shown incredible promise in learning fixed-length representations from fingerprints. Since the representation learning is often focused on capturing specific prior knowledge (e.g., minutiae), there is no universal representation that comprehensively encapsulates all the discriminatory information available in a fingerprint. While learning an ensemble of representations can mitigate this problem, two critical challenges need to be addressed: (i) How to extract multiple diverse representations from the same fingerprint image? and (ii) How to optimally exploit these representations during the matching process? In this work, we train multiple instances of DeepPrint (a state-of-the-art DNN-based fingerprint encoder) on different transformations of the input image to generate an ensemble of fingerprint embeddings. We also propose a feature fusion technique that distills these multiple representations into a single embedding, which faithfully captures the diversity present in the ensemble without increasing the computational complexity. The proposed approach has been comprehensively evaluated on five databases containing rolled, plain, and latent fingerprints (NIST SD4, NIST SD14, NIST SD27, NIST SD302, and FVC2004 DB2A) and statistically significant improvements in accuracy have been consistently demonstrated across a range of verification as well as closed- and open-set identification settings. The proposed approach serves as a wrapper capable of improving the accuracy of any DNN-based recognition system.
A Weighted Random Forest Based PositioningAlgorithm for 6G Indoor Communications
Aug 22, 2022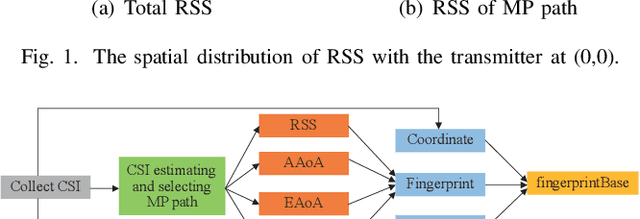
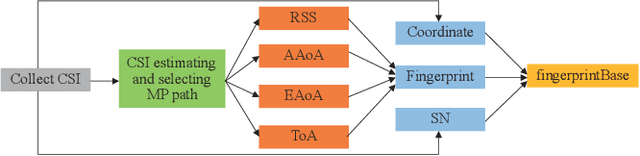
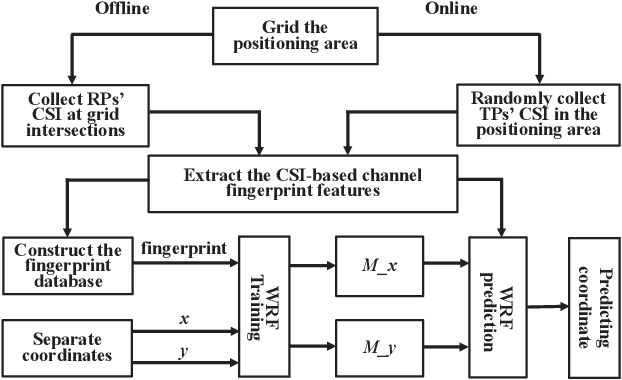
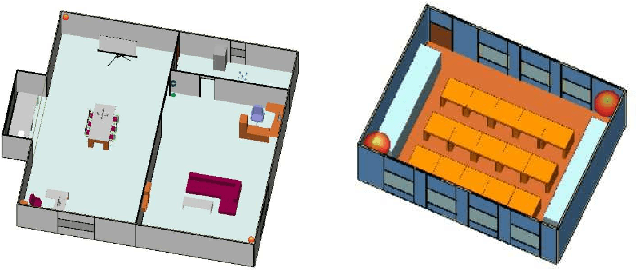
Due to the indoor none-line-of-sight (NLoS) propagation and multi-access interference (MAI), it is a great challenge to achieve centimeter-level positioning accuracy in indoor scenarios. However, the sixth generation (6G) wireless communications provide a good opportunity for the centimeter-level positioning. In 6G, the millimeter wave (mmWave) and terahertz (THz) communications have ultra-broad bandwidth so that the channel state information (CSI) will have a high resolution. In this paper, a weighted random forest (WRF) based indoor positioning algorithm using CSI based channel fingerprint feature is proposed to achieve high-precision positioning for 6G indoor communications. In addition, ray-tracing (RT) is used to improve the efficiency of establishing channel fingerprint database. The simulation results demonstrate the accuracy and robustness of the proposed algorithm. It is shown that the positioning accuracy of the algorithm is stable within 6 cm in different indoor scenarios with the channel fingerprint database established at 0.2 m intervals.