 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LFGCF: Light Folksonomy Graph Collaborative Filtering for Tag-Aware Recommendation
Aug 06, 2022
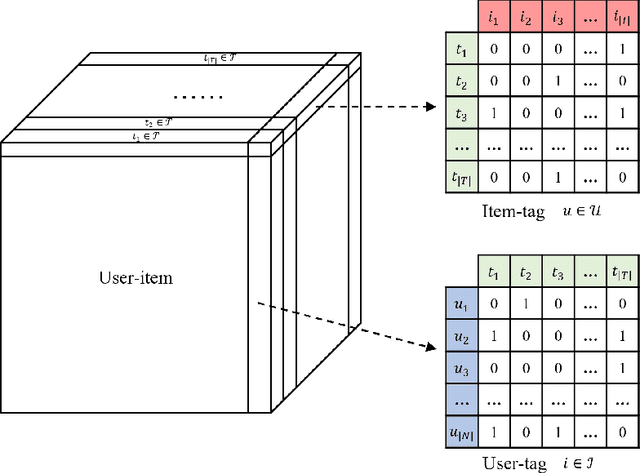
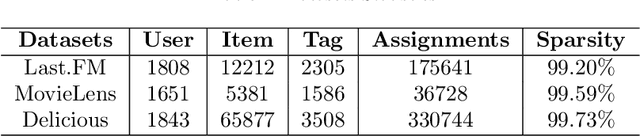
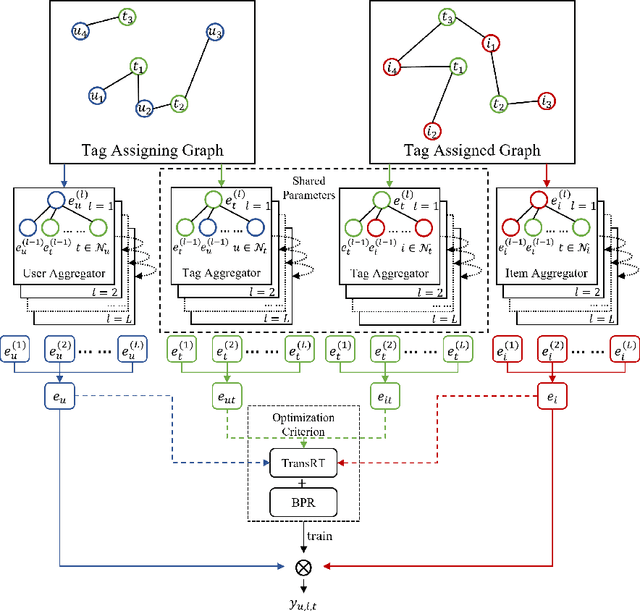
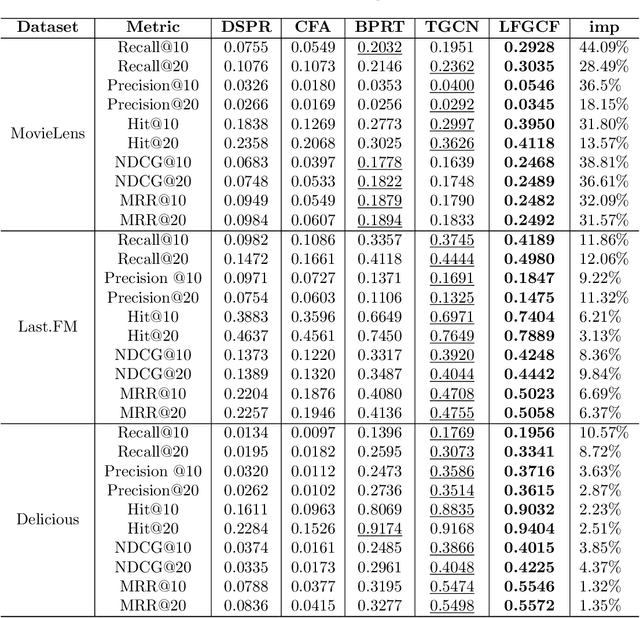
Tag-aware recommendation is a task of predicting a personalized list of items for a user by their tagging behaviors. It is crucial for many applications with tagging capabilities like last.fm or movielens. Recently, many efforts have been devoted to improving Tag-aware recommendation systems (TRS) with Graph Convolutional Networks (GCN), which has become new state-of-the-art for the general recommendation. However, some solutions are directly inherited from GCN without justifications, which is difficult to alleviate the sparsity, ambiguity, and redundancy issues introduced by tags, thus adding to difficulties of training and degrading recommendation performance. In this work, we aim to simplify the design of GCN to make it more concise for TRS. We propose a novel tag-aware recommendation model named Light Folksonomy Graph Collaborative Filtering (LFGCF), which only includes the essential GCN components. Specifically, LFGCF first constructs Folksonomy Graphs from the records of user assigning tags and item getting tagged. Then we leverage the simple design of aggregation to learn the high-order representations on Folksonomy Graphs and use the weighted sum of the embeddings learned at several layers for information updating. We share tags embeddings to bridge the information gap between users and items. Besides, a regularization function named TransRT is proposed to better depict user preferences and item features. Extensive hyperparameters experiments and ablation studies on three real-world datasets show that LFGCF uses fewer parameters and significantly outperforms most baselines for the tag-aware top-N recommendations.
Graph-Based Estimation of Time-Varying DOAs
Aug 26, 2022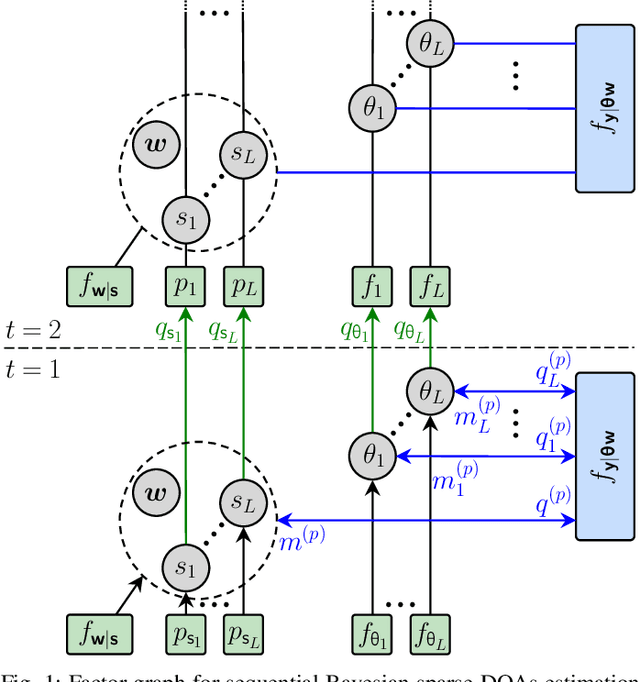
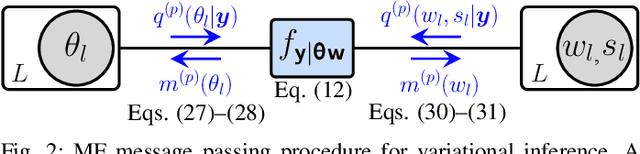
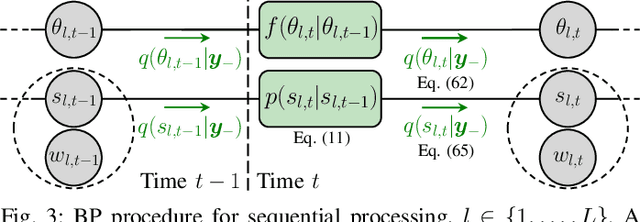

This paper presents a graph-based estimation method for sequential direction finding. The proposed method estimates an unknown number of directions of arrivals (DOAs) by performing message passing on the factor graph that represents the statistical model of the estimation problem. At each time step, belief propagation predicts the number of DOAs and their DOAs based on a new state-transition model and utilizing posterior probability density functions from previous time steps. Mean field message passing updates the DOAs and their number iteratively. The method promotes sparse solutions through a Bernoulli-Gaussian amplitude model, is gridless, and provides marginal posterior probability density functions from which DOA estimates and their uncertainties can be extracted. To propagate source existence and DOA information across time steps, a Bernoulli-von Mises state transition model is introduced. Compared to non-sequential approaches, the method can reduce DOA estimation errors in scenarios involving multiple time steps and time-varying DOAs. Simulation results demonstrate performance improvements compared to state-of-the-art methods. We evaluate the proposed method using ocean acoustic experimental data.
Improving RGB-D Point Cloud Registration by Learning Multi-scale Local Linear Transformation
Sep 01, 2022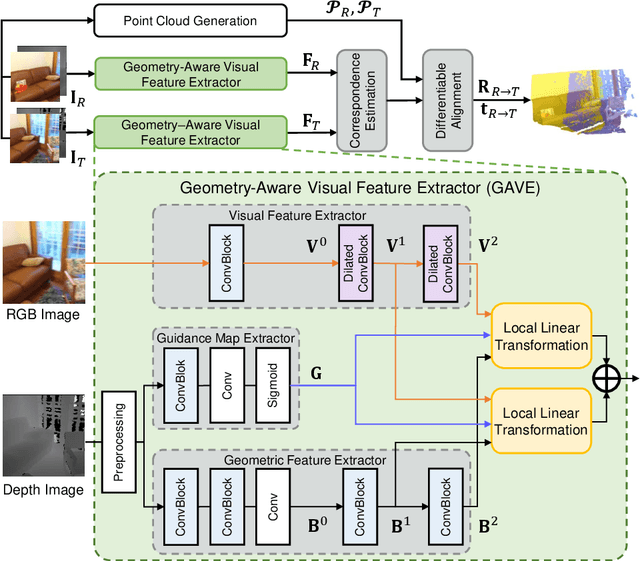
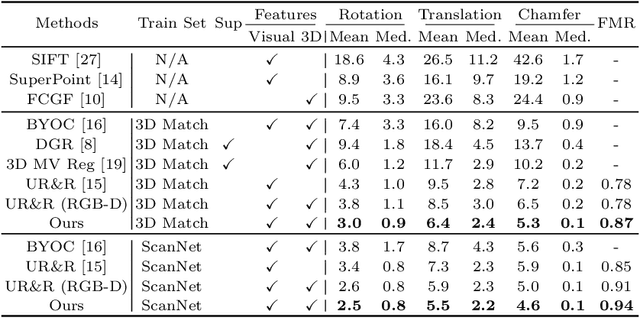
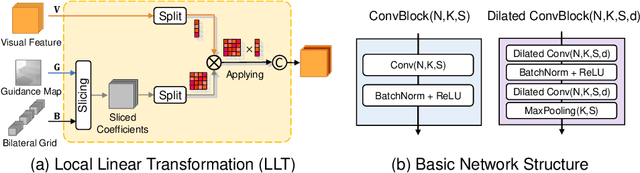
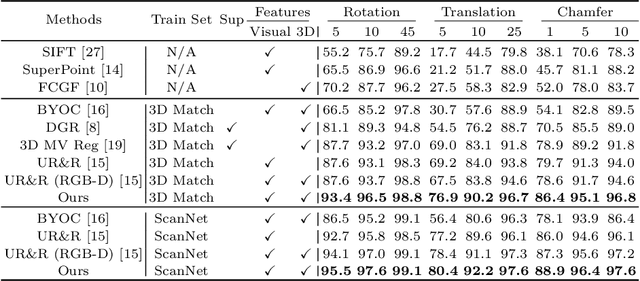
Point cloud registration aims at estimating the geometric transformation between two point cloud scans, in which point-wise correspondence estimation is the key to its success. In addition to previous methods that seek correspondences by hand-crafted or learnt geometric features, recent point cloud registration methods have tried to apply RGB-D data to achieve more accurate correspondence. However, it is not trivial to effectively fuse the geometric and visual information from these two distinctive modalities, especially for the registration problem. In this work, we propose a new Geometry-Aware Visual Feature Extractor (GAVE) that employs multi-scale local linear transformation to progressively fuse these two modalities, where the geometric features from the depth data act as the geometry-dependent convolution kernels to transform the visual features from the RGB data. The resultant visual-geometric features are in canonical feature spaces with alleviated visual dissimilarity caused by geometric changes, by which more reliable correspondence can be achieved. The proposed GAVE module can be readily plugged into recent RGB-D point cloud registration framework. Extensive experiments on 3D Match and ScanNet demonstrate that our method outperforms the state-of-the-art point cloud registration methods even without correspondence or pose supervision. The code is available at: https://github.com/514DNA/LLT.
Privacy-Preserving Representation Learning on Graphs: A Mutual Information Perspective
Jul 03, 2021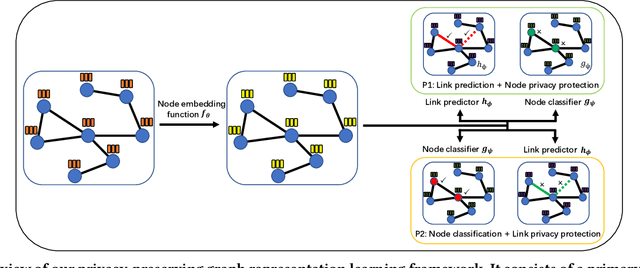
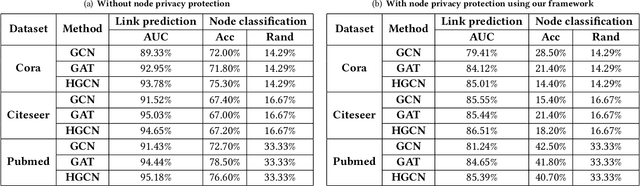
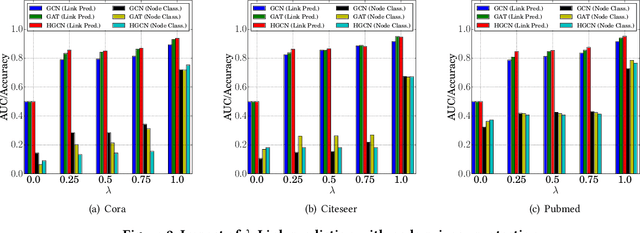
Learning with graphs has attracted significant attention recently. Existing representation learning methods on graphs have achieved state-of-the-art performance on various graph-related tasks such as node classification, link prediction, etc. However, we observe that these methods could leak serious private information. For instance, one can accurately infer the links (or node identity) in a graph from a node classifier (or link predictor) trained on the learnt node representations by existing methods. To address the issue, we propose a privacy-preserving representation learning framework on graphs from the \emph{mutual information} perspective. Specifically, our framework includes a primary learning task and a privacy protection task, and we consider node classification and link prediction as the two tasks of interest. Our goal is to learn node representations such that they can be used to achieve high performance for the primary learning task, while obtaining performance for the privacy protection task close to random guessing. We formally formulate our goal via mutual information objectives. However, it is intractable to compute mutual information in practice. Then, we derive tractable variational bounds for the mutual information terms, where each bound can be parameterized via a neural network. Next, we train these parameterized neural networks to approximate the true mutual information and learn privacy-preserving node representations. We finally evaluate our framework on various graph datasets.
Cross-Lingual and Cross-Domain Crisis Classification for Low-Resource Scenarios
Sep 05, 2022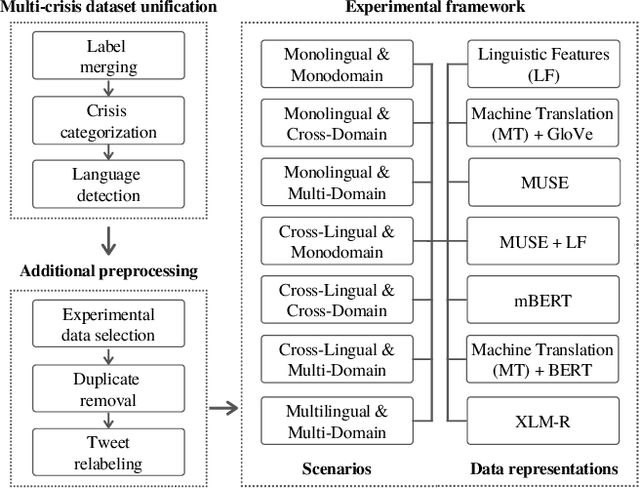
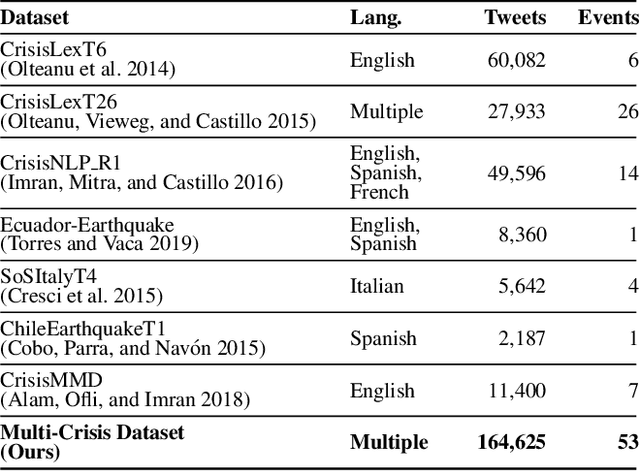
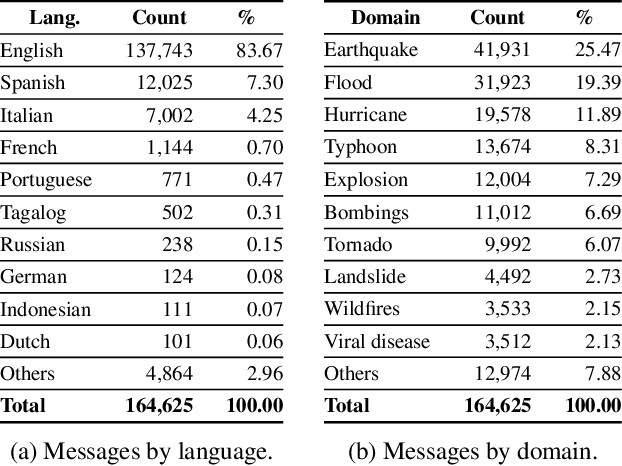
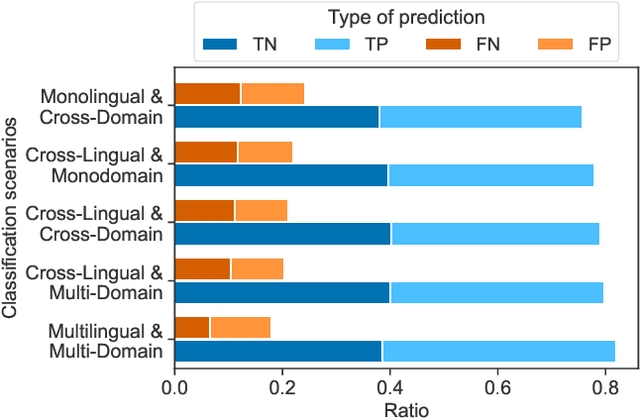
Social media data has emerged as a useful source of timely information about real-world crisis events. One of the main tasks related to the use of social media for disaster management is the automatic identification of crisis-related messages. Most of the studies on this topic have focused on the analysis of data for a particular type of event in a specific language. This limits the possibility of generalizing existing approaches because models cannot be directly applied to new types of events or other languages. In this work, we study the task of automatically classifying messages that are related to crisis events by leveraging cross-language and cross-domain labeled data. Our goal is to make use of labeled data from high-resource languages to classify messages from other (low-resource) languages and/or of new (previously unseen) types of crisis situations. For our study we consolidated from the literature a large unified dataset containing multiple crisis events and languages. Our empirical findings show that it is indeed possible to leverage data from crisis events in English to classify the same type of event in other languages, such as Spanish and Italian (80.0% F1-score). Furthermore, we achieve good performance for the cross-domain task (80.0% F1-score) in a cross-lingual setting. Overall, our work contributes to improving the data scarcity problem that is so important for multilingual crisis classification. In particular, mitigating cold-start situations in emergency events, when time is of essence.
Bayesian tensor factorization for predicting clinical outcomes using integrated human genetics evidence
Jul 25, 2022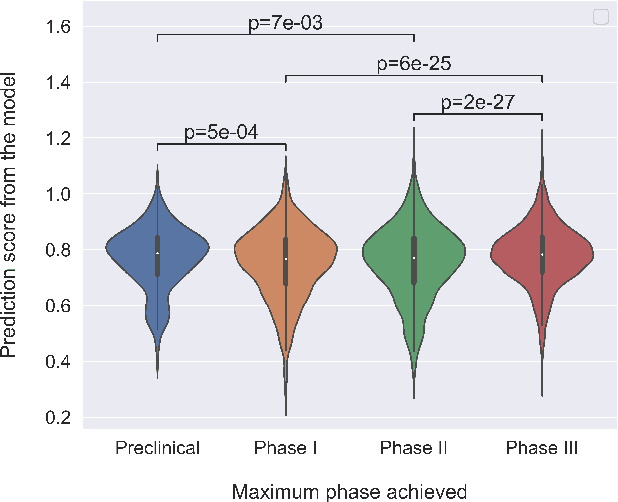

The approval success rate of drug candidates is very low with the majority of failure due to safety and efficacy. Increasingly available high dimensional information on targets, drug molecules and indications provides an opportunity for ML methods to integrate multiple data modalities and better predict clinically promising drug targets. Notably, drug targets with human genetics evidence are shown to have better odds to succeed. However, a recent tensor factorization-based approach found that additional information on targets and indications might not necessarily improve the predictive accuracy. Here we revisit this approach by integrating different types of human genetics evidence collated from publicly available sources to support each target-indication pair. We use Bayesian tensor factorization to show that models incorporating all available human genetics evidence (rare disease, gene burden, common disease) modestly improves the clinical outcome prediction over models using single line of genetics evidence. We provide additional insight into the relative predictive power of different types of human genetics evidence for predicting the success of clinical outcomes.
Game State Learning via Game Scene Augmentation
Jul 08, 2022

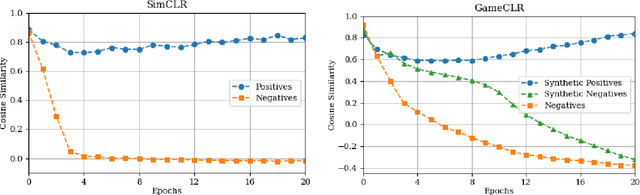
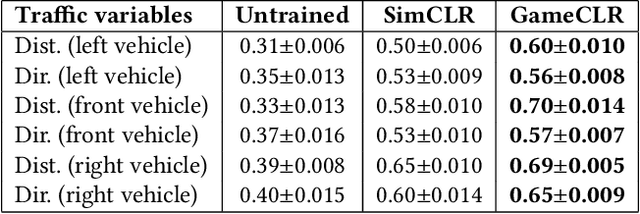
Having access to accurate game state information is of utmost importance for any artificial intelligence task including game-playing, testing, player modeling, and procedural content generation. Self-Supervised Learning (SSL) techniques have shown to be capable of inferring accurate game state information from the high-dimensional pixel input of game footage into compressed latent representations. Contrastive Learning is a popular SSL paradigm where the visual understanding of the game's images comes from contrasting dissimilar and similar game states defined by simple image augmentation methods. In this study, we introduce a new game scene augmentation technique -- named GameCLR -- that takes advantage of the game-engine to define and synthesize specific, highly-controlled renderings of different game states, thereby, boosting contrastive learning performance. We test our GameCLR technique on images of the CARLA driving simulator environment and compare it against the popular SimCLR baseline SSL method. Our results suggest that GameCLR can infer the game's state information from game footage more accurately compared to the baseline. Our proposed approach allows us to conduct game artificial intelligence research by directly utilizing screen pixels as input.
Semi-Supervised Manifold Learning with Complexity Decoupled Chart Autoencoders
Aug 22, 2022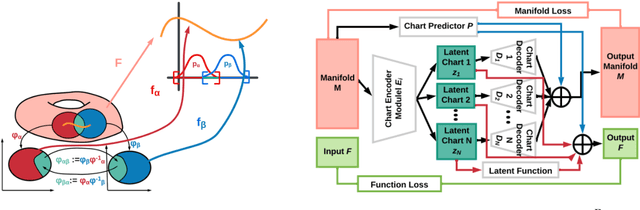
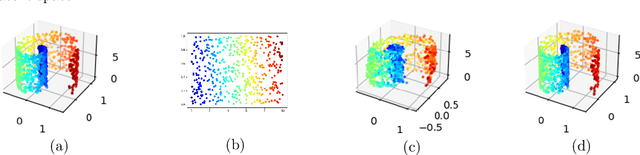
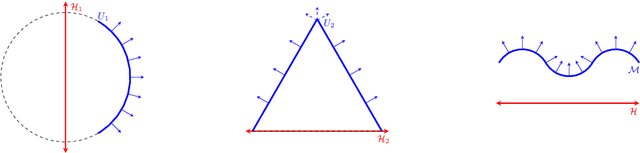
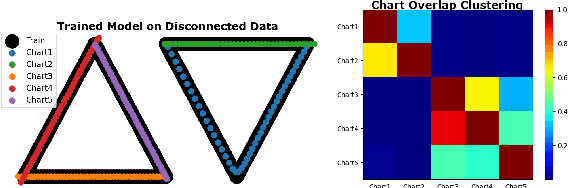
Autoencoding is a popular method in representation learning. Conventional autoencoders employ symmetric encoding-decoding procedures and a simple Euclidean latent space to detect hidden low-dimensional structures in an unsupervised way. This work introduces a chart autoencoder with an asymmetric encoding-decoding process that can incorporate additional semi-supervised information such as class labels. Besides enhancing the capability for handling data with complicated topological and geometric structures, these models can successfully differentiate nearby but disjoint manifolds and intersecting manifolds with only a small amount of supervision. Moreover, this model only requires a low complexity encoder, such as local linear projection. We discuss the theoretical approximation power of such networks that essentially depends on the intrinsic dimension of the data manifold and not the dimension of the observations. Our numerical experiments on synthetic and real-world data verify that the proposed model can effectively manage data with multi-class nearby but disjoint manifolds of different classes, overlapping manifolds, and manifolds with non-trivial topology.
Unsupervised Learning of 3D Scene Flow with 3D Odometry Assistance
Sep 11, 2022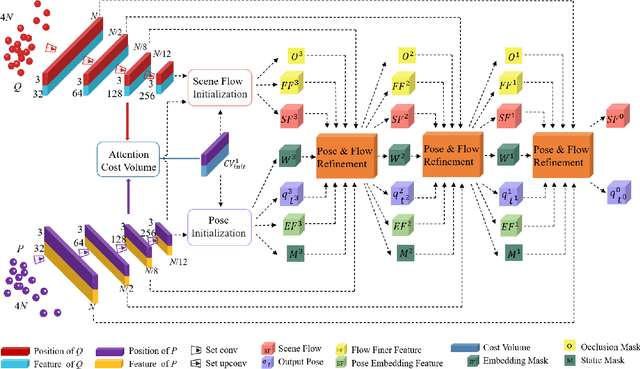
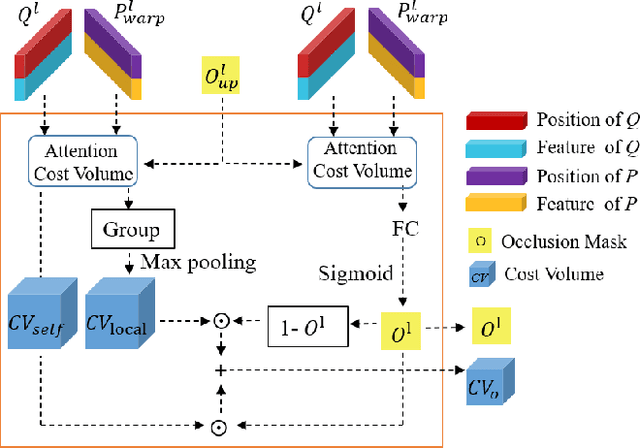
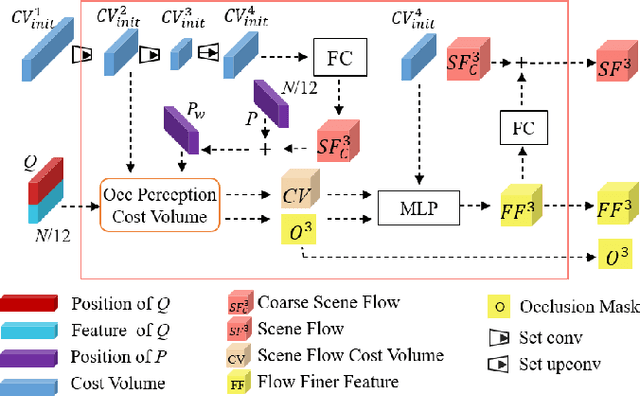
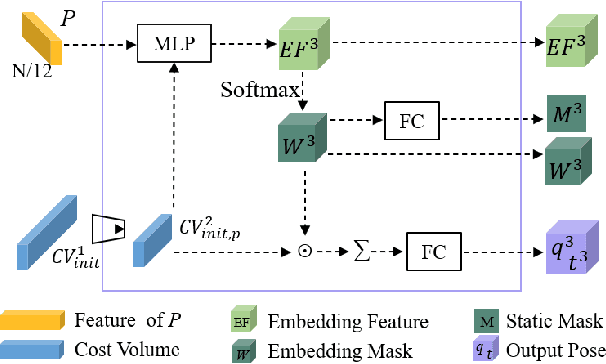
Scene flow represents the 3D motion of each point in the scene, which explicitly describes the distance and the direction of each point's movement. Scene flow estimation is used in various applications such as autonomous driving fields, activity recognition, and virtual reality fields. As it is challenging to annotate scene flow with ground truth for real-world data, this leaves no real-world dataset available to provide a large amount of data with ground truth for scene flow estimation. Therefore, many works use synthesized data to pre-train their network and real-world LiDAR data to finetune. Unlike the previous unsupervised learning of scene flow in point clouds, we propose to use odometry information to assist the unsupervised learning of scene flow and use real-world LiDAR data to train our network. Supervised odometry provides more accurate shared cost volume for scene flow. In addition, the proposed network has mask-weighted warp layers to get a more accurate predicted point cloud. The warp operation means applying an estimated pose transformation or scene flow to a source point cloud to obtain a predicted point cloud and is the key to refining scene flow from coarse to fine. When performing warp operations, the points in different states use different weights for the pose transformation and scene flow transformation. We classify the states of points as static, dynamic, and occluded, where the static masks are used to divide static and dynamic points, and the occlusion masks are used to divide occluded points. The mask-weighted warp layer indicates that static masks and occlusion masks are used as weights when performing warp operations. Our designs are proved to be effective in ablation experiments. The experiment results show the promising prospect of an odometry-assisted unsupervised learning method for 3D scene flow in real-world data.
Consistency of the Maximal Information Coefficient Estimator
Jul 08, 2021The Maximal Information Coefficient (MIC) of Reshef et al. (Science, 2011) is a statistic for measuring dependence between variable pairs in large datasets. In this note, we prove that MIC is a consistent estimator of the corresponding population statistic MIC$_*$. This corrects an error in an argument of Reshef et al. (JMLR, 2016), which we describe.