 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Uncertainty quantification for predictions of atomistic neural networks
Jul 21, 2022
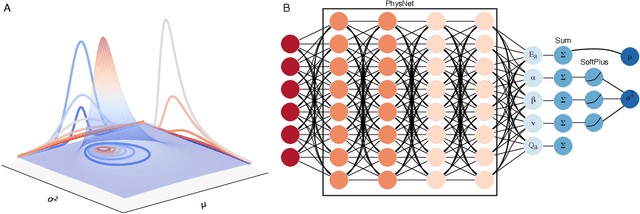
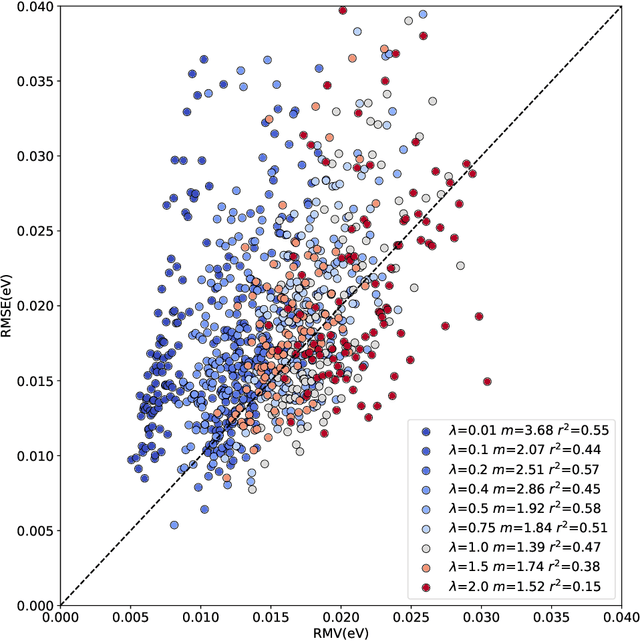
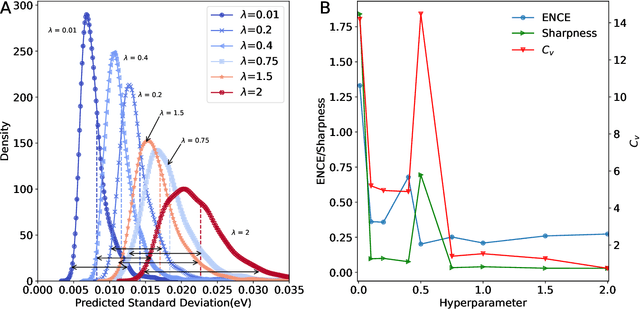
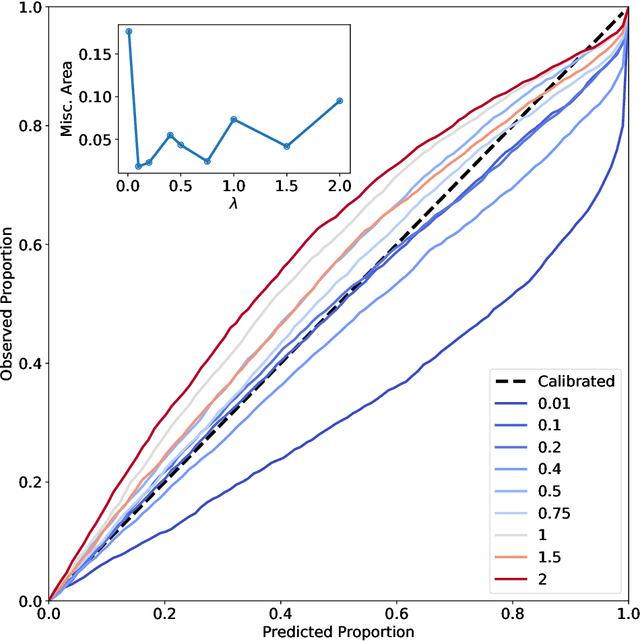
The value of uncertainty quantification on predictions for trained neural networks (NNs) on quantum chemical reference data is quantitatively explored. For this, the architecture of the PhysNet NN was suitably modified and the resulting model was evaluated with different metrics to quantify calibration, quality of predictions, and whether prediction error and the predicted uncertainty can be correlated. The results from training on the QM9 database and evaluating data from the test set within and outside the distribution indicate that error and uncertainty are not linearly related. The results clarify that noise and redundancy complicate property prediction for molecules even in cases for which changes - e.g. double bond migration in two otherwise identical molecules - are small. The model was then applied to a real database of tautomerization reactions. Analysis of the distance between members in feature space combined with other parameters shows that redundant information in the training dataset can lead to large variances and small errors whereas the presence of similar but unspecific information returns large errors but small variances. This was, e.g., observed for nitro-containing aliphatic chains for which predictions were difficult although the training set contained several examples for nitro groups bound to aromatic molecules. This underlines the importance of the composition of the training data and provides chemical insight into how this affects the prediction capabilities of a ML model. Finally, the approach put forward can be used for information-based improvement of chemical databases for target applications through active learning optimization.
GLASS: Global to Local Attention for Scene-Text Spotting
Aug 05, 2022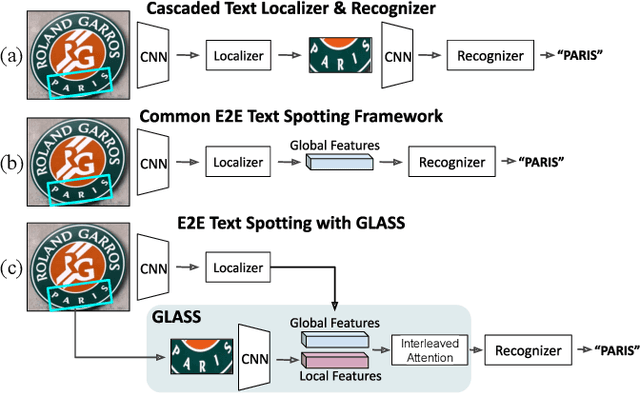
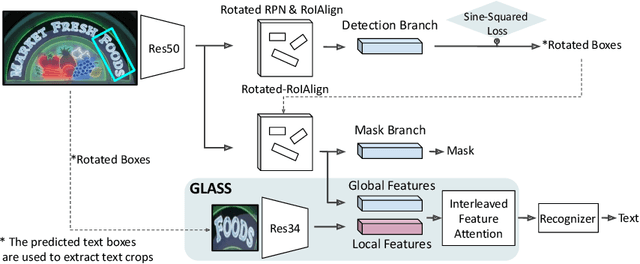
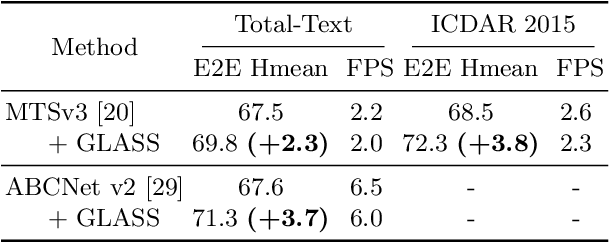
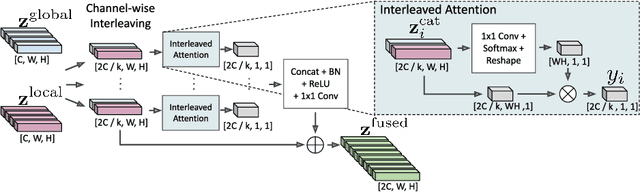
In recent years, the dominant paradigm for text spotting is to combine the tasks of text detection and recognition into a single end-to-end framework. Under this paradigm, both tasks are accomplished by operating over a shared global feature map extracted from the input image. Among the main challenges that end-to-end approaches face is the performance degradation when recognizing text across scale variations (smaller or larger text), and arbitrary word rotation angles. In this work, we address these challenges by proposing a novel global-to-local attention mechanism for text spotting, termed GLASS, that fuses together global and local features. The global features are extracted from the shared backbone, preserving contextual information from the entire image, while the local features are computed individually on resized, high-resolution rotated word crops. The information extracted from the local crops alleviates much of the inherent difficulties with scale and word rotation. We show a performance analysis across scales and angles, highlighting improvement over scale and angle extremities. In addition, we introduce an orientation-aware loss term supervising the detection task, and show its contribution to both detection and recognition performance across all angles. Finally, we show that GLASS is general by incorporating it into other leading text spotting architectures, improving their text spotting performance. Our method achieves state-of-the-art results on multiple benchmarks, including the newly released TextOCR.
Manifold Free Riemannian Optimization
Sep 07, 2022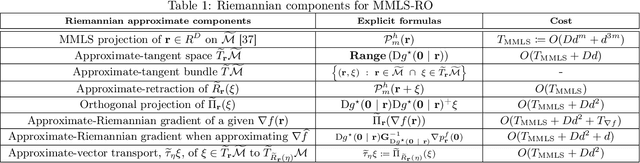
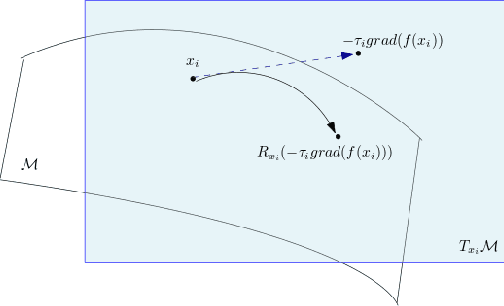
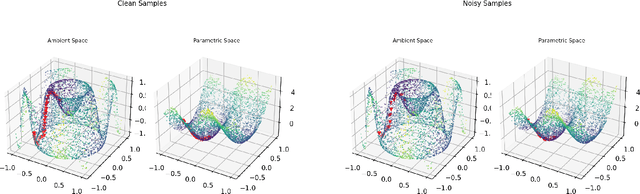
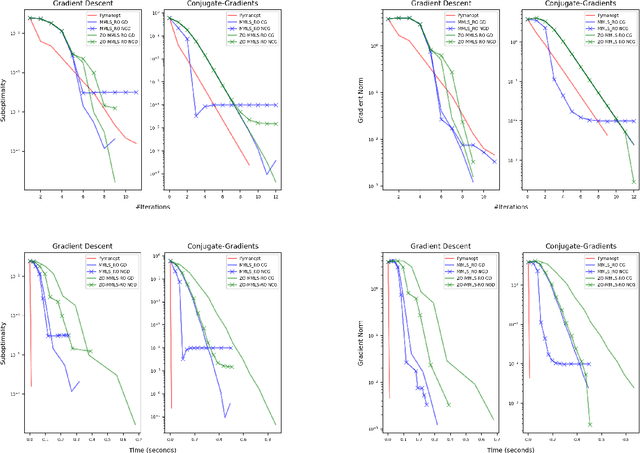
Riemannian optimization is a principled framework for solving optimization problems where the desired optimum is constrained to a smooth manifold $\mathcal{M}$. Algorithms designed in this framework usually require some geometrical description of the manifold, which typically includes tangent spaces, retractions, and gradients of the cost function. However, in many cases, only a subset (or none at all) of these elements can be accessed due to lack of information or intractability. In this paper, we propose a novel approach that can perform approximate Riemannian optimization in such cases, where the constraining manifold is a submanifold of $\R^{D}$. At the bare minimum, our method requires only a noiseless sample set of the cost function $(\x_{i}, y_{i})\in {\mathcal{M}} \times \mathbb{R}$ and the intrinsic dimension of the manifold $\mathcal{M}$. Using the samples, and utilizing the Manifold-MLS framework (Sober and Levin 2020), we construct approximations of the missing components entertaining provable guarantees and analyze their computational costs. In case some of the components are given analytically (e.g., if the cost function and its gradient are given explicitly, or if the tangent spaces can be computed), the algorithm can be easily adapted to use the accurate expressions instead of the approximations. We analyze the global convergence of Riemannian gradient-based methods using our approach, and we demonstrate empirically the strength of this method, together with a conjugate-gradients type method based upon similar principles.
Back from the future: bidirectional CTC decoding using future information in speech recognition
Oct 07, 2021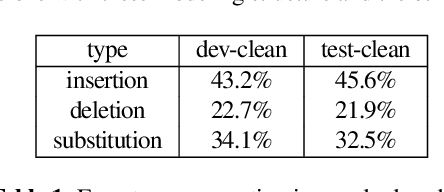

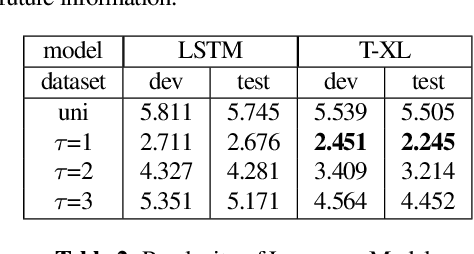
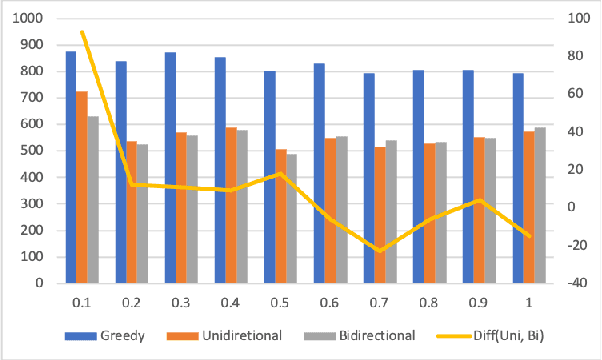
In this paper, we propose a simple but effective method to decode the output of Connectionist Temporal Classifier (CTC) model using a bi-directional neural language model. The bidirectional language model uses the future as well as the past information in order to predict the next output in the sequence. The proposed method based on bi-directional beam search takes advantage of the CTC greedy decoding output to represent the noisy future information. Experiments on the Librispeechdataset demonstrate the superiority of our proposed method compared to baselines using unidirectional decoding. In particular, the boost inaccuracy is most apparent at the start of a sequence which is the most erroneous part for existing systems based on unidirectional decoding.
Predict-and-Update Network: Audio-Visual Speech Recognition Inspired by Human Speech Perception
Sep 05, 2022
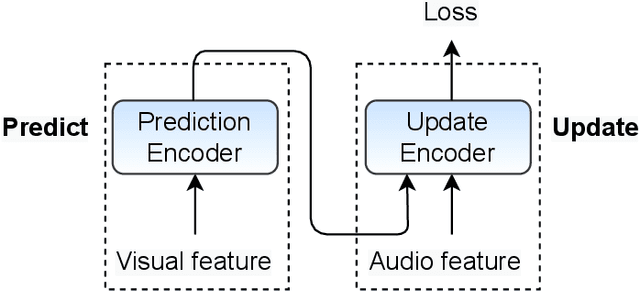
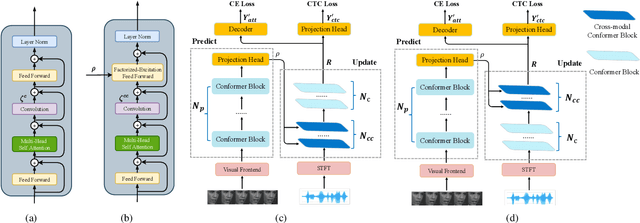
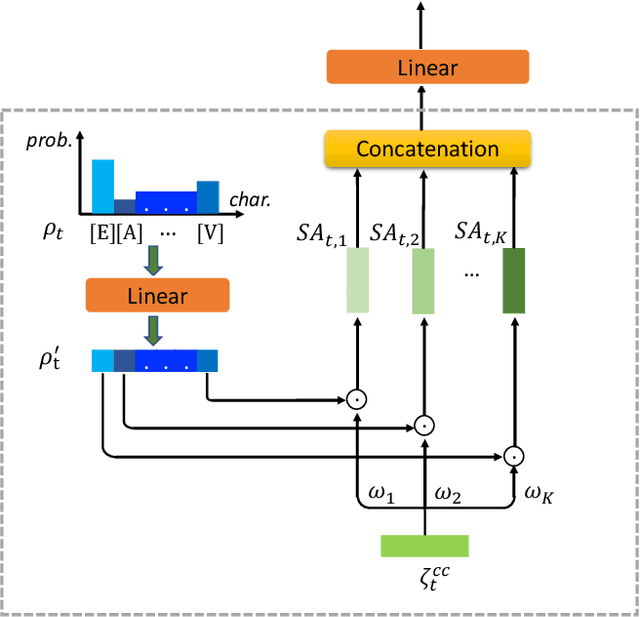
Audio and visual signals complement each other in human speech perception, so do they in speech recognition. The visual hint is less evident than the acoustic hint, but more robust in a complex acoustic environment, as far as speech perception is concerned. It remains a challenge how we effectively exploit the interaction between audio and visual signals for automatic speech recognition. There have been studies to exploit visual signals as redundant or complementary information to audio input in a synchronous manner. Human studies suggest that visual signal primes the listener in advance as to when and on which frequency to attend to. We propose a Predict-and-Update Network (P&U net), to simulate such a visual cueing mechanism for Audio-Visual Speech Recognition (AVSR). In particular, we first predict the character posteriors of the spoken words, i.e. the visual embedding, based on the visual signals. The audio signal is then conditioned on the visual embedding via a novel cross-modal Conformer, that updates the character posteriors. We validate the effectiveness of the visual cueing mechanism through extensive experiments. The proposed P&U net outperforms the state-of-the-art AVSR methods on both LRS2-BBC and LRS3-BBC datasets, with the relative reduced Word Error Rate (WER)s exceeding 10% and 40% under clean and noisy conditions, respectively.
Uformer-ICS: A Specialized U-Shaped Transformer for Image Compressive Sensing
Sep 05, 2022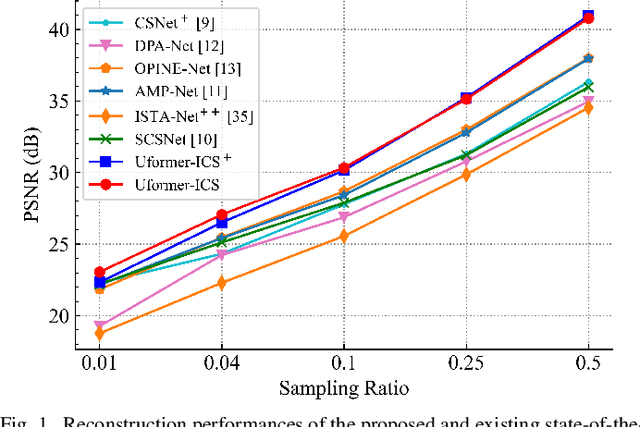
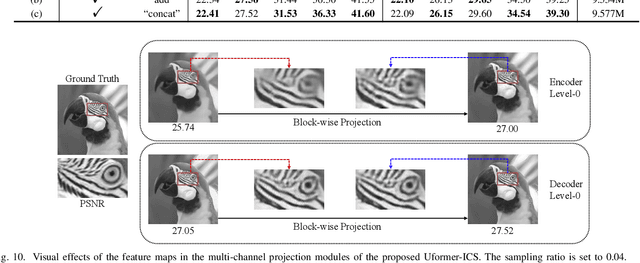
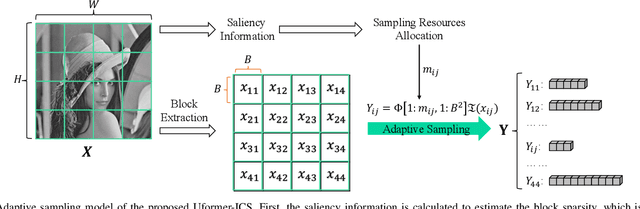

Recently, several studies have applied deep convolutional neural networks (CNNs) in image compressive sensing (CS) tasks to improve reconstruction quality. However, convolutional layers generally have a small receptive field; therefore, capturing long-range pixel correlations using CNNs is challenging, which limits their reconstruction performance in image CS tasks. Considering this limitation, we propose a U-shaped transformer for image CS tasks, called the Uformer-ICS. We develop a projection-based transformer block by integrating the prior projection knowledge of CS into the original transformer blocks, and then build a symmetrical reconstruction model using the projection-based transformer blocks and residual convolutional blocks. Compared with previous CNN-based CS methods that can only exploit local image features, the proposed reconstruction model can simultaneously utilize the local features and long-range dependencies of an image, and the prior projection knowledge of the CS theory. Additionally, we design an adaptive sampling model that can adaptively sample image blocks based on block sparsity, which can ensure that the compressed results retain the maximum possible information of the original image under a fixed sampling ratio. The proposed Uformer-ICS is an end-to-end framework that simultaneously learns the sampling and reconstruction processes. Experimental results demonstrate that it achieves significantly better reconstruction performance than existing state-of-the-art deep learning-based CS methods.
Graph Signal Processing for Heterogeneous Change Detection Part I: Vertex Domain Filtering
Aug 08, 2022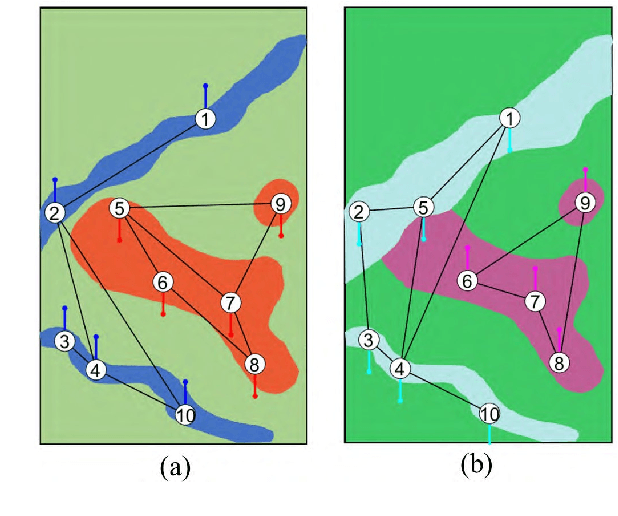
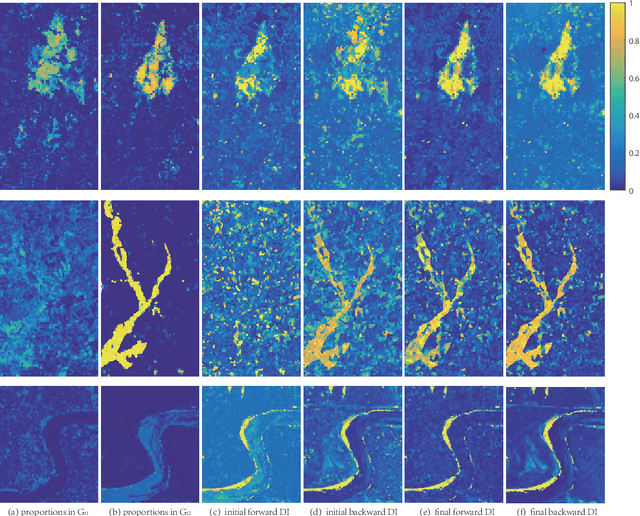
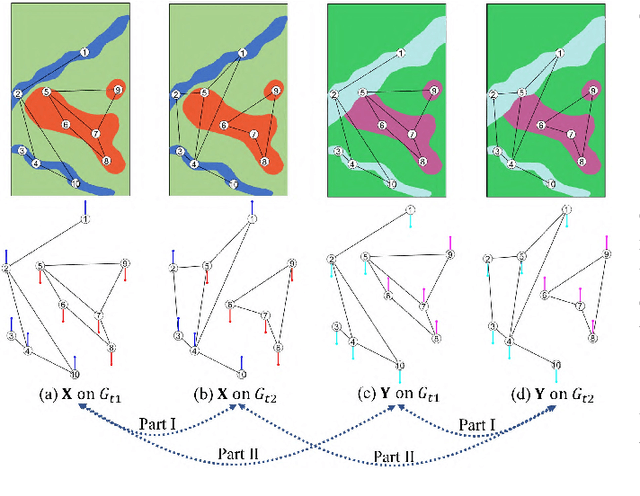
This paper provides a new strategy for the Heterogeneous Change Detection (HCD) problem: solving HCD from the perspective of Graph Signal Processing (GSP). We construct a graph for each image to capture the structure information, and treat each image as the graph signal. In this way, we convert the HCD into a GSP problem: a comparison of the responses of the two signals on different systems defined on the two graphs, which attempts to find structural differences (Part I) and signal differences (Part II) due to the changes between heterogeneous images. In this first part, we analyze the HCD with GSP from the vertex domain. We first show that for the unchanged images, their structures are consistent, and then the outputs of the same signal on systems defined on the two graphs are similar. However, once a region has changed, the local structure of the image changes, i.e., the connectivity of the vertex containing this region changes. Then, we can compare the output signals of the same input graph signal passing through filters defined on the two graphs to detect changes. We design different filters from the vertex domain, which can flexibly explore the high-order neighborhood information hidden in original graphs. We also analyze the detrimental effects of changing regions on the change detection results from the viewpoint of signal propagation. Experiments conducted on seven real data sets show the effectiveness of the vertex domain filtering based HCD method.
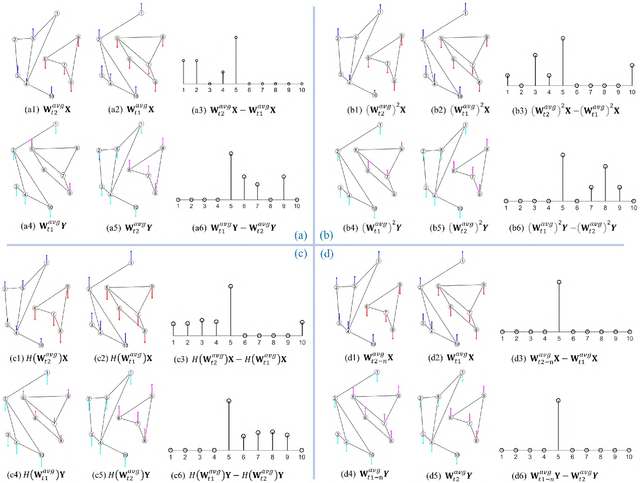
MSMDFusion: Fusing LiDAR and Camera at Multiple Scales with Multi-Depth Seeds for 3D Object Detection
Sep 07, 2022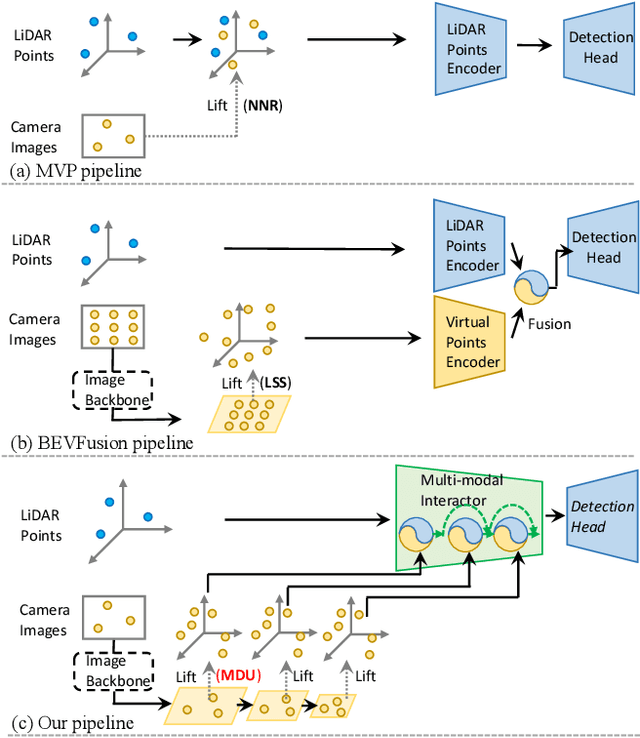
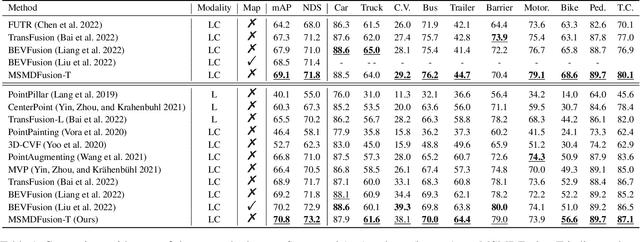
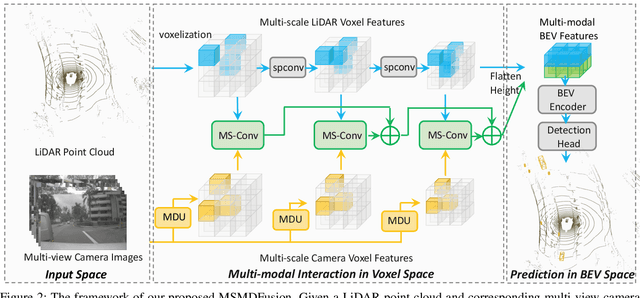
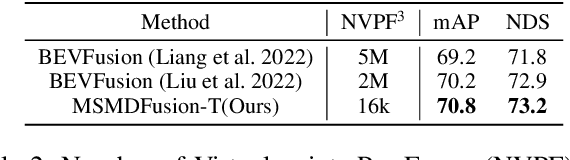
Fusing LiDAR and camera information is essential for achieving accurate and reliable 3D object detection in autonomous driving systems. However, this is challenging due to the difficulty of combining multi-granularity geometric and semantic features from two drastically different modalities. Recent approaches aim at exploring the semantic densities of camera features through lifting points in 2D camera images (referred to as seeds) into 3D space for fusion, and they can be roughly divided into 1) early fusion of raw points that aims at augmenting the 3D point cloud at the early input stage, and 2) late fusion of BEV (bird-eye view) maps that merges LiDAR and camera BEV features before the detection head. While both have their merits in enhancing the representation power of the combined features, this single-level fusion strategy is a suboptimal solution to the aforementioned challenge. Their major drawbacks are the inability to interact the multi-granularity semantic features from two distinct modalities sufficiently. To this end, we propose a novel framework that focuses on the multi-scale progressive interaction of the multi-granularity LiDAR and camera features. Our proposed method, abbreviated as MDMSFusion, achieves state-of-the-art results in 3D object detection, with 69.1 mAP and 71.8 NDS on nuScenes validation set, and 70.8 mAP and 73.2 NDS on nuScenes test set, which rank 1st and 2nd respectively among single-model non-ensemble approaches by the time of submission.
A Review of Knowledge Graph Completion
Aug 24, 2022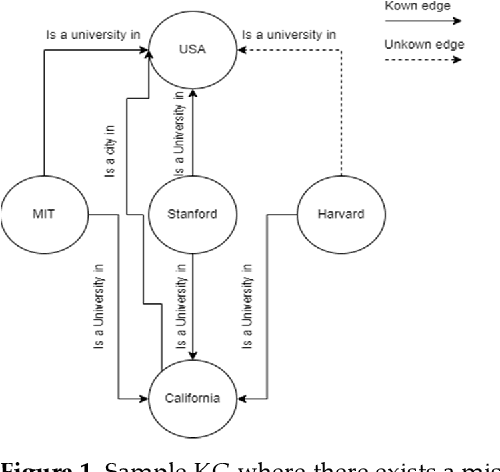



Information extraction methods proved to be effective at triple extraction from structured or unstructured data. The organization of such triples in the form of (head entity, relation, tail entity) is called the construction of Knowledge Graphs (KGs). Most of the current knowledge graphs are incomplete. In order to use KGs in downstream tasks, it is desirable to predict missing links in KGs. Different approaches have been recently proposed for representation learning of KGs by embedding both entities and relations into a low-dimensional vector space aiming to predict unknown triples based on previously visited triples. According to how the triples will be treated independently or dependently, we divided the task of knowledge graph completion into conventional and graph neural network representation learning and we discuss them in more detail. In conventional approaches, each triple will be processed independently and in GNN-based approaches, triples also consider their local neighborhood. View Full-Text
Lesion-Specific Prediction with Discriminator-Based Supervised Guided Attention Module Enabled GANs in Multiple Sclerosis
Aug 30, 2022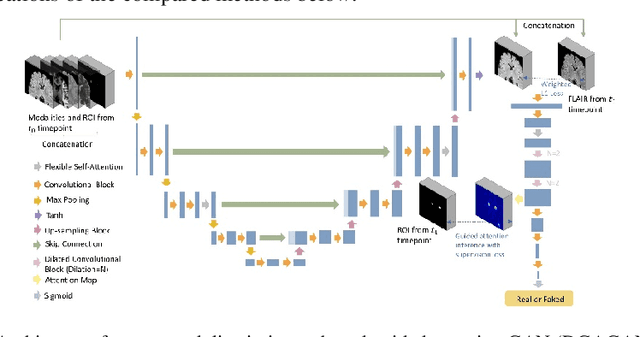
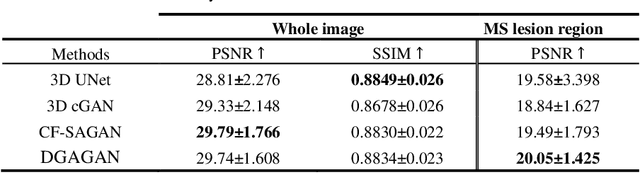
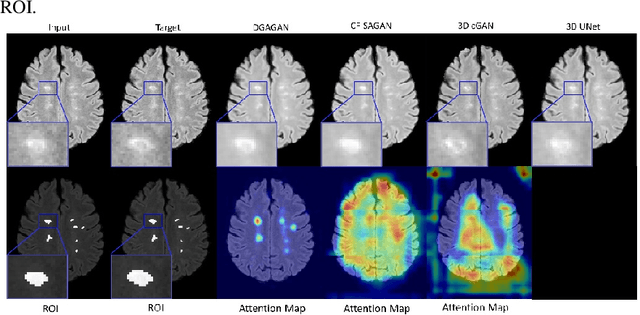
Multiple Sclerosis (MS) is a chronic neurological condition characterized by the development of lesions in the white matter of the brain. T2-fluid attenuated inversion recovery (FLAIR) brain magnetic resonance imaging (MRI) provides superior visualization and characterization of MS lesions, relative to other MRI modalities. Follow-up brain FLAIR MRI in MS provides helpful information for clinicians towards monitoring disease progression. In this study, we propose a novel modification to generative adversarial networks (GANs) to predict future lesion-specific FLAIR MRI for MS at fixed time intervals. We use supervised guided attention and dilated convolutions in the discriminator, which supports making an informed prediction of whether the generated images are real or not based on attention to the lesion area, which in turn has potential to help improve the generator to predict the lesion area of future examinations more accurately. We compared our method to several baselines and one state-of-art CF-SAGAN model [1]. In conclusion, our results indicate that the proposed method achieves higher accuracy and reduces the standard deviation of the prediction errors in the lesion area compared with other models with similar overall performance.