 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Neural Pre-training for Enhancing Recommendations using Side Information
Jul 09, 2021
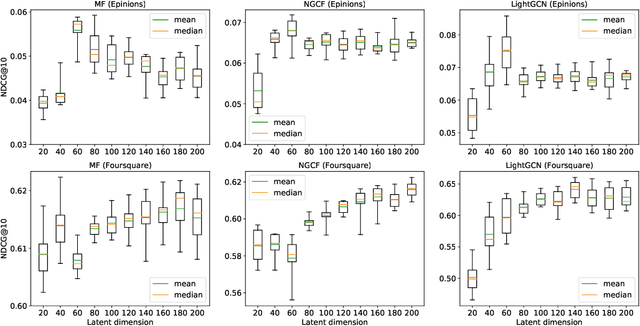

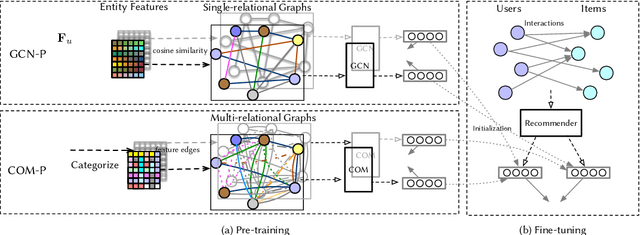
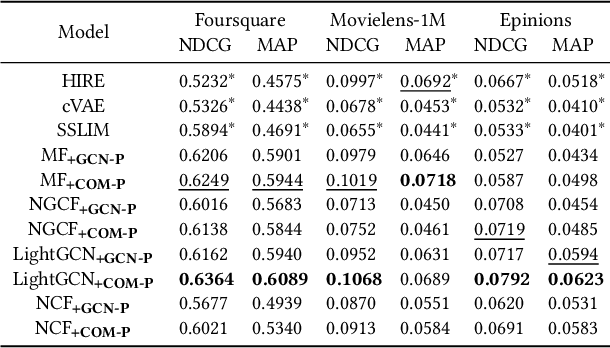
Leveraging the side information associated with entities (i.e. users and items) to enhance the performance of recommendation systems has been widely recognized as an important modelling dimension. While many existing approaches focus on the integration scheme to incorporate entity side information -- by combining the recommendation loss function with an extra side information-aware loss -- in this paper, we propose instead a novel pre-training scheme for leveraging the side information. In particular, we first pre-train a representation model using the side information of the entities, and then fine-tune it using an existing general representation-based recommendation model. Specifically, we propose two pre-training models, named GCN-P and COM-P, by considering the entities and their relations constructed from side information as two different types of graphs respectively, to pre-train entity embeddings. For the GCN-P model, two single-relational graphs are constructed from all the users' and items' side information respectively, to pre-train entity representations by using the Graph Convolutional Networks. For the COM-P model, two multi-relational graphs are constructed to pre-train the entity representations by using the Composition-based Graph Convolutional Networks. An extensive evaluation of our pre-training models fine-tuned under four general representation-based recommender models, i.e. MF, NCF, NGCF and LightGCN, shows that effectively pre-training embeddings with both the user's and item's side information can significantly improve these original models in terms of both effectiveness and stability.
Towards Frame Rate Agnostic Multi-Object Tracking
Sep 23, 2022

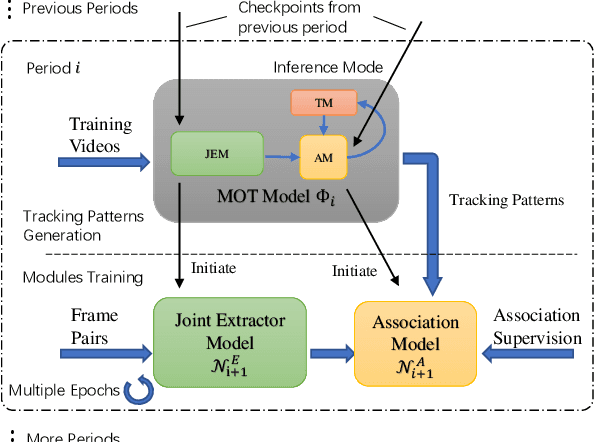
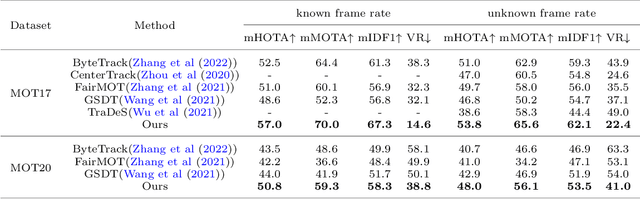
Multi-Object Tracking (MOT) is one of the most fundamental computer vision tasks which contributes to a variety of video analysis applications. Despite the recent promising progress, current MOT research is still limited to a fixed sampling frame rate of the input stream. In fact, we empirically find that the accuracy of all recent state-of-the-art trackers drops dramatically when the input frame rate changes. For a more intelligent tracking solution, we shift the attention of our research work to the problem of Frame Rate Agnostic MOT (FraMOT). In this paper, we propose a Frame Rate Agnostic MOT framework with Periodic training Scheme (FAPS) to tackle the FraMOT problem for the first time. Specifically, we propose a Frame Rate Agnostic Association Module (FAAM) that infers and encodes the frame rate information to aid identity matching across multi-frame-rate inputs, improving the capability of the learned model in handling complex motion-appearance relations in FraMOT. Besides, the association gap between training and inference is enlarged in FraMOT because those post-processing steps not included in training make a larger difference in lower frame rate scenarios. To address it, we propose Periodic Training Scheme (PTS) to reflect all post-processing steps in training via tracking pattern matching and fusion. Along with the proposed approaches, we make the first attempt to establish an evaluation method for this new task of FraMOT in two different modes, i.e., known frame rate and unknown frame rate, aiming to handle a more complex situation. The quantitative experiments on the challenging MOT datasets (FraMOT version) have clearly demonstrated that the proposed approaches can handle different frame rates better and thus improve the robustness against complicated scenarios.
"Mama Always Had a Way of Explaining Things So I Could Understand'': A Dialogue Corpus for Learning to Construct Explanations
Sep 06, 2022
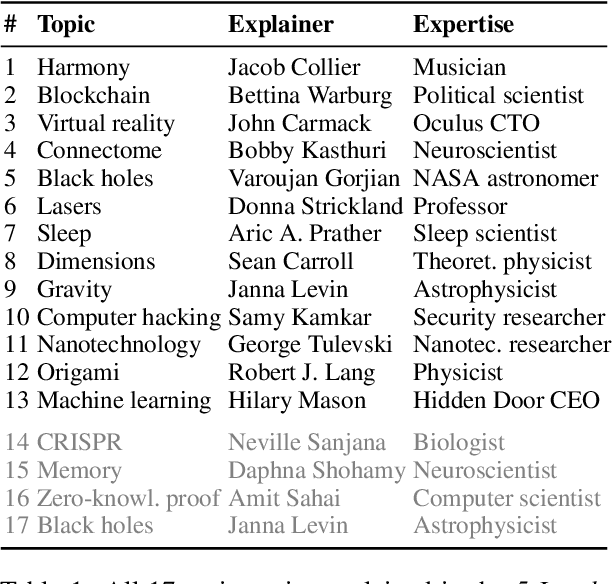
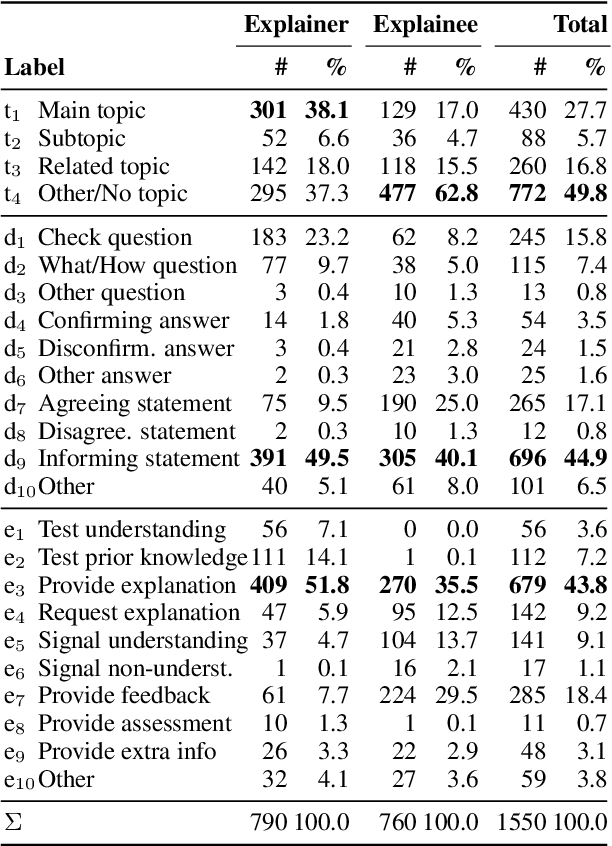
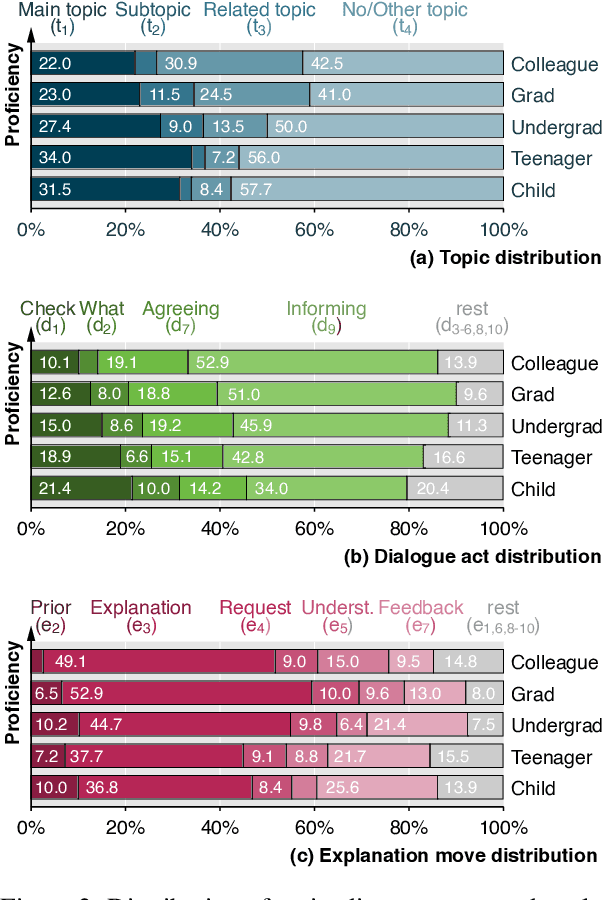
As AI is more and more pervasive in everyday life, humans have an increasing demand to understand its behavior and decisions. Most research on explainable AI builds on the premise that there is one ideal explanation to be found. In fact, however, everyday explanations are co-constructed in a dialogue between the person explaining (the explainer) and the specific person being explained to (the explainee). In this paper, we introduce a first corpus of dialogical explanations to enable NLP research on how humans explain as well as on how AI can learn to imitate this process. The corpus consists of 65 transcribed English dialogues from the Wired video series \emph{5 Levels}, explaining 13 topics to five explainees of different proficiency. All 1550 dialogue turns have been manually labeled by five independent professionals for the topic discussed as well as for the dialogue act and the explanation move performed. We analyze linguistic patterns of explainers and explainees, and we explore differences across proficiency levels. BERT-based baseline results indicate that sequence information helps predicting topics, acts, and moves effectively
Keep the Caption Information: Preventing Shortcut Learning in Contrastive Image-Caption Retrieval
Apr 28, 2022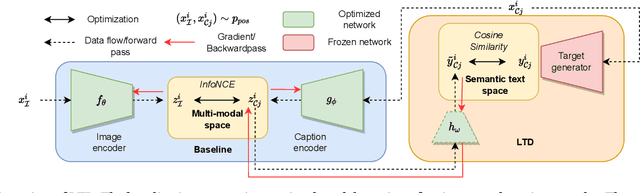
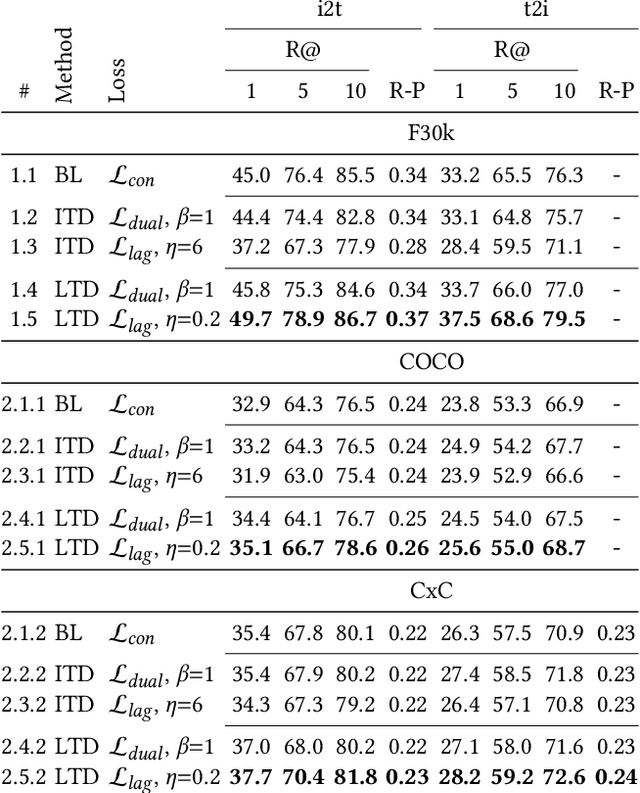
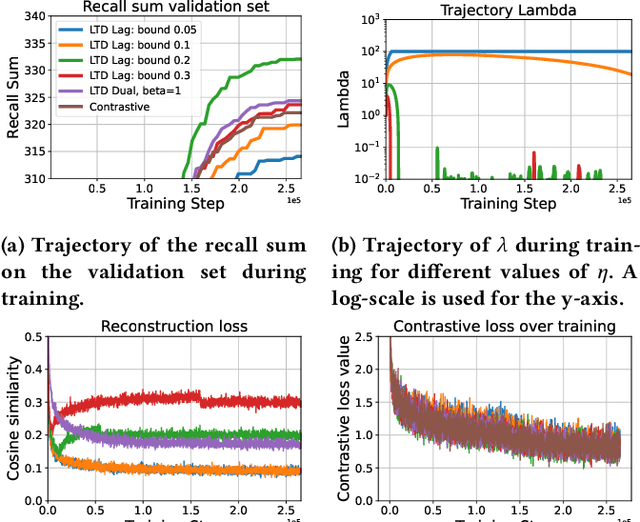
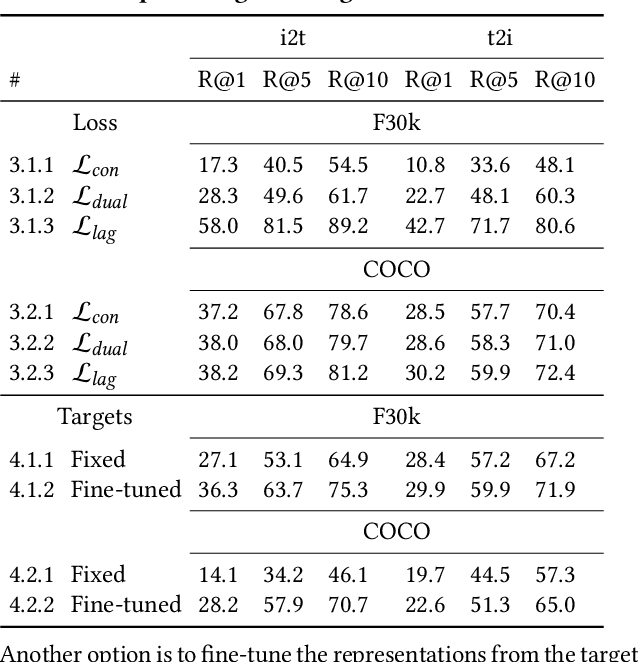
To train image-caption retrieval (ICR) methods, contrastive loss functions are a common choice for optimization functions. Unfortunately, contrastive ICR methods are vulnerable to learning shortcuts: decision rules that perform well on the training data but fail to transfer to other testing conditions. We introduce an approach to reduce shortcut feature representations for the ICR task: latent target decoding (LTD). We add an additional decoder to the learning framework to reconstruct the input caption, which prevents the image and caption encoder from learning shortcut features. Instead of reconstructing input captions in the input space, we decode the semantics of the caption in a latent space. We implement the LTD objective as an optimization constraint, to ensure that the reconstruction loss is below a threshold value while primarily optimizing for the contrastive loss. Importantly, LTD does not depend on additional training data or expensive (hard) negative mining strategies. Our experiments show that, unlike reconstructing the input caption, LTD reduces shortcut learning and improves generalizability by obtaining higher recall@k and r-precision scores. Additionally, we show that the evaluation scores benefit from implementing LTD as an optimization constraint instead of a dual loss.
GROWN+UP: A Graph Representation Of a Webpage Network Utilizing Pre-training
Aug 03, 2022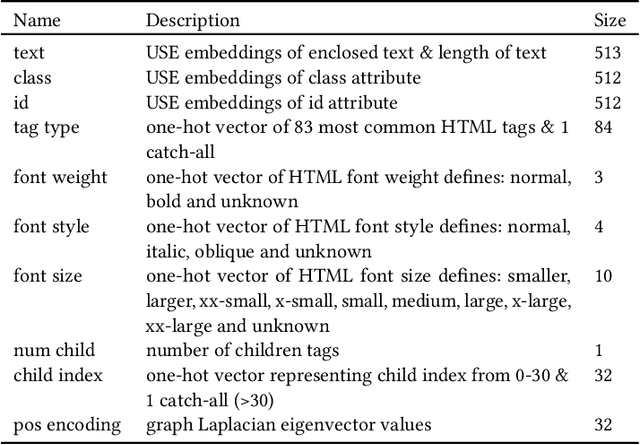
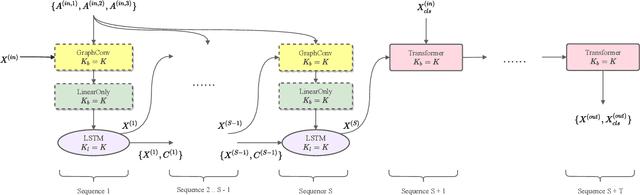
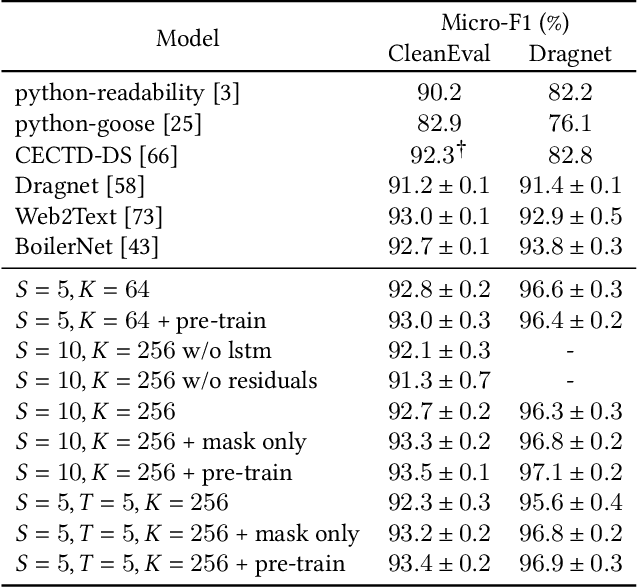
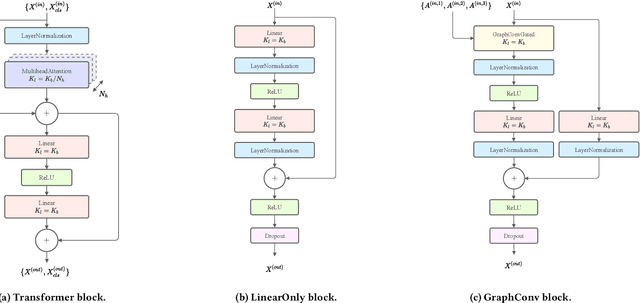
Large pre-trained neural networks are ubiquitous and critical to the success of many downstream tasks in natural language processing and computer vision. However, within the field of web information retrieval, there is a stark contrast in the lack of similarly flexible and powerful pre-trained models that can properly parse webpages. Consequently, we believe that common machine learning tasks like content extraction and information mining from webpages have low-hanging gains that yet remain untapped. We aim to close the gap by introducing an agnostic deep graph neural network feature extractor that can ingest webpage structures, pre-train self-supervised on massive unlabeled data, and fine-tune to arbitrary tasks on webpages effectually. Finally, we show that our pre-trained model achieves state-of-the-art results using multiple datasets on two very different benchmarks: webpage boilerplate removal and genre classification, thus lending support to its potential application in diverse downstream tasks.
Reconstructing Action-Conditioned Human-Object Interactions Using Commonsense Knowledge Priors
Sep 06, 2022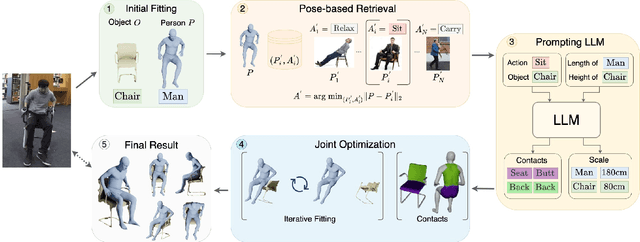
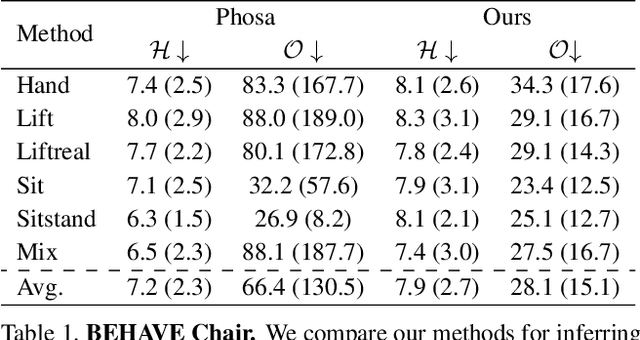
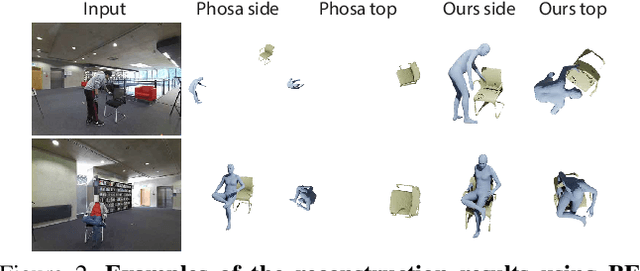
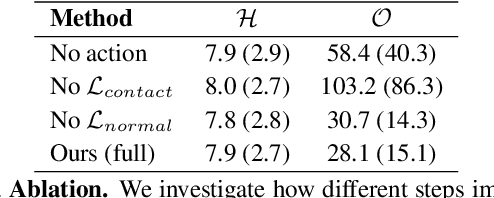
We present a method for inferring diverse 3D models of human-object interactions from images. Reasoning about how humans interact with objects in complex scenes from a single 2D image is a challenging task given ambiguities arising from the loss of information through projection. In addition, modeling 3D interactions requires the generalization ability towards diverse object categories and interaction types. We propose an action-conditioned modeling of interactions that allows us to infer diverse 3D arrangements of humans and objects without supervision on contact regions or 3D scene geometry. Our method extracts high-level commonsense knowledge from large language models (such as GPT-3), and applies them to perform 3D reasoning of human-object interactions. Our key insight is priors extracted from large language models can help in reasoning about human-object contacts from textural prompts only. We quantitatively evaluate the inferred 3D models on a large human-object interaction dataset and show how our method leads to better 3D reconstructions. We further qualitatively evaluate the effectiveness of our method on real images and demonstrate its generalizability towards interaction types and object categories.
Jointly Learning Agent and Lane Information for Multimodal Trajectory Prediction
Nov 26, 2021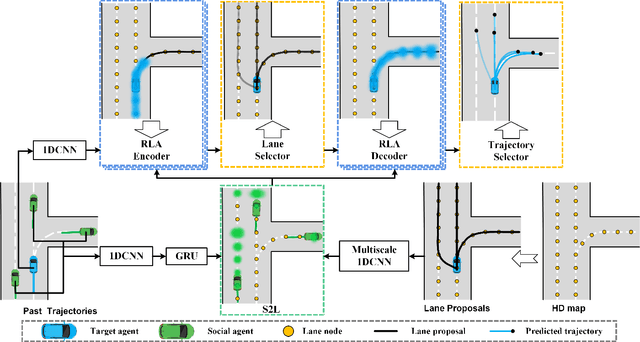
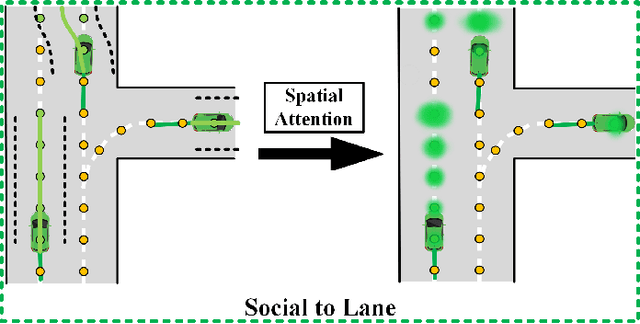
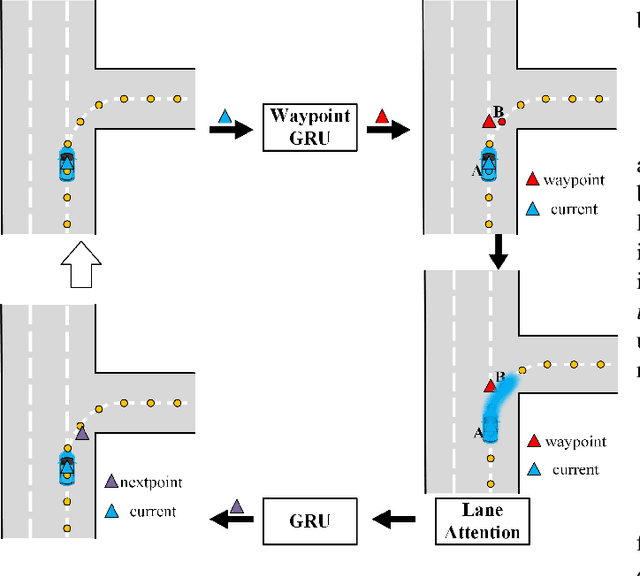
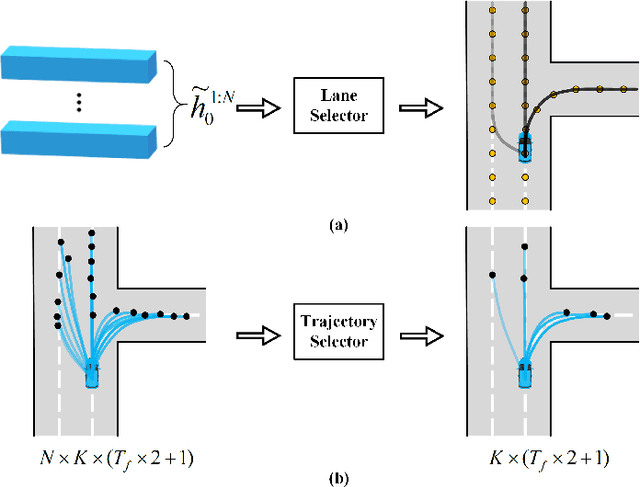
Predicting the plausible future trajectories of nearby agents is a core challenge for the safety of Autonomous Vehicles and it mainly depends on two external cues: the dynamic neighbor agents and static scene context. Recent approaches have made great progress in characterizing the two cues separately. However, they ignore the correlation between the two cues and most of them are difficult to achieve map-adaptive prediction. In this paper, we use lane as scene data and propose a staged network that Jointly learning Agent and Lane information for Multimodal Trajectory Prediction (JAL-MTP). JAL-MTP use a Social to Lane (S2L) module to jointly represent the static lane and the dynamic motion of the neighboring agents as instance-level lane, a Recurrent Lane Attention (RLA) mechanism for utilizing the instance-level lanes to predict the map-adaptive future trajectories and two selectors to identify the typical and reasonable trajectories. The experiments conducted on the public Argoverse dataset demonstrate that JAL-MTP significantly outperforms the existing models in both quantitative and qualitative.
Dual Vision Transformer
Jul 12, 2022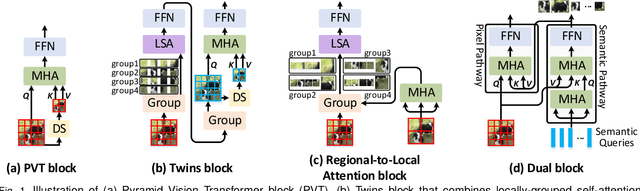
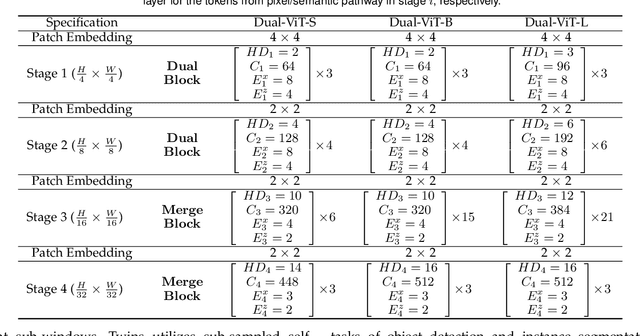
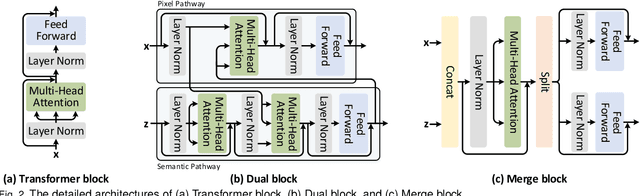
Prior works have proposed several strategies to reduce the computational cost of self-attention mechanism. Many of these works consider decomposing the self-attention procedure into regional and local feature extraction procedures that each incurs a much smaller computational complexity. However, regional information is typically only achieved at the expense of undesirable information lost owing to down-sampling. In this paper, we propose a novel Transformer architecture that aims to mitigate the cost issue, named Dual Vision Transformer (Dual-ViT). The new architecture incorporates a critical semantic pathway that can more efficiently compress token vectors into global semantics with reduced order of complexity. Such compressed global semantics then serve as useful prior information in learning finer pixel level details, through another constructed pixel pathway. The semantic pathway and pixel pathway are then integrated together and are jointly trained, spreading the enhanced self-attention information in parallel through both of the pathways. Dual-ViT is henceforth able to reduce the computational complexity without compromising much accuracy. We empirically demonstrate that Dual-ViT provides superior accuracy than SOTA Transformer architectures with reduced training complexity. Source code is available at \url{https://github.com/YehLi/ImageNetModel}.
EchoCoTr: Estimation of the Left Ventricular Ejection Fraction from Spatiotemporal Echocardiography
Sep 09, 2022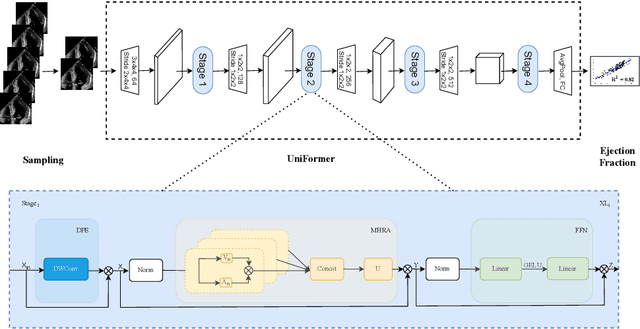
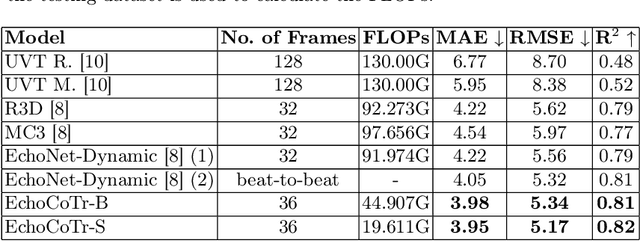
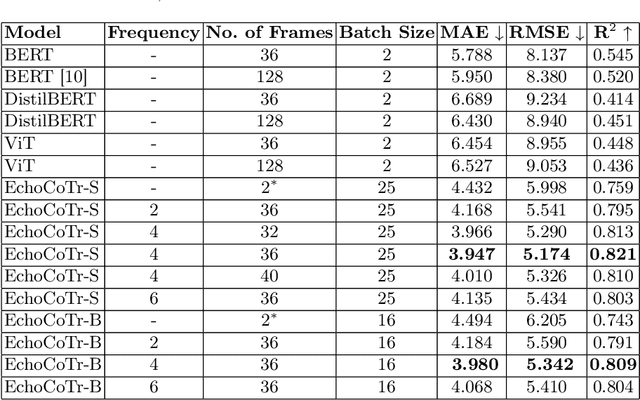
Learning spatiotemporal features is an important task for efficient video understanding especially in medical images such as echocardiograms. Convolutional neural networks (CNNs) and more recent vision transformers (ViTs) are the most commonly used methods with limitations per each. CNNs are good at capturing local context but fail to learn global information across video frames. On the other hand, vision transformers can incorporate global details and long sequences but are computationally expensive and typically require more data to train. In this paper, we propose a method that addresses the limitations we typically face when training on medical video data such as echocardiographic scans. The algorithm we propose (EchoCoTr) utilizes the strength of vision transformers and CNNs to tackle the problem of estimating the left ventricular ejection fraction (LVEF) on ultrasound videos. We demonstrate how the proposed method outperforms state-of-the-art work to-date on the EchoNet-Dynamic dataset with MAE of 3.95 and $R^2$ of 0.82. These results show noticeable improvement compared to all published research. In addition, we show extensive ablations and comparisons with several algorithms, including ViT and BERT. The code is available at https://github.com/BioMedIA-MBZUAI/EchoCoTr.
Motion Robust High-Speed Light-weighted Object Detection with Event Camera
Aug 24, 2022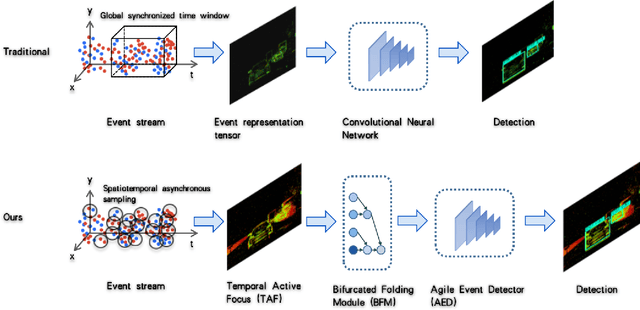
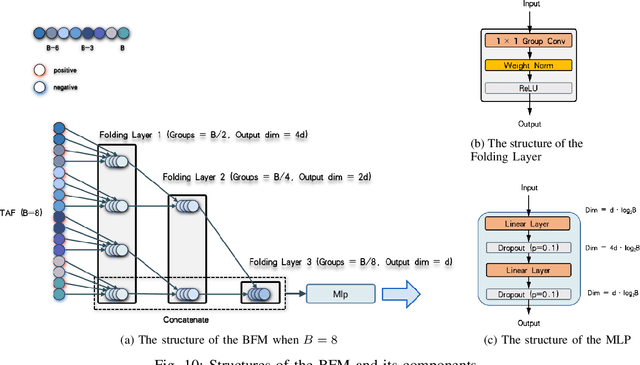
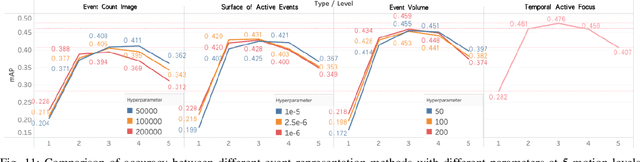
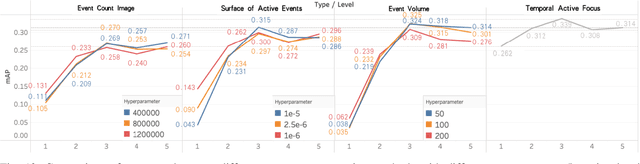
The event camera produces a large dynamic range event stream with a very high temporal resolution discarding redundant visual information, thus bringing new possibilities for object detection tasks. However, the existing methods of applying the event camera to object detection tasks using deep learning methods still have many problems. First, existing methods cannot take into account objects with different velocities relative to the motion of the event camera due to the global synchronized time window and temporal resolution. Second, most of the existing methods rely on large parameter neural networks, which implies a large computational burden and low inference speed, thus contrary to the high temporal resolution of the event stream. In our work, we design a high-speed lightweight detector called Agile Event Detector (AED) with a simple but effective data augmentation method. Also, we propose an event stream representation tensor called Temporal Active Focus (TAF), which takes full advantage of the asynchronous generation of event stream data and is robust to the motion of moving objects. It can also be constructed without much time-consuming. We further propose a module called the Bifurcated Folding Module (BFM) to extract the rich temporal information in the TAF tensor at the input layer of the AED detector. We conduct our experiments on two typical real-scene event camera object detection datasets: the complete Prophesee GEN1 Automotive Detection Dataset and the Prophesee 1 MEGAPIXEL Automotive Detection Dataset with partial annotation. Experiments show that our method is competitive in terms of accuracy, speed, and the number of parameters simultaneously. Also by classifying the objects into multiple motion levels based on the optical flow density metric, we illustrated the robustness of our method for objects with different velocities relative to the camera.