 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Instance Attack:An Explanation-based Vulnerability Analysis Framework Against DNNs for Malware Detection
Sep 06, 2022
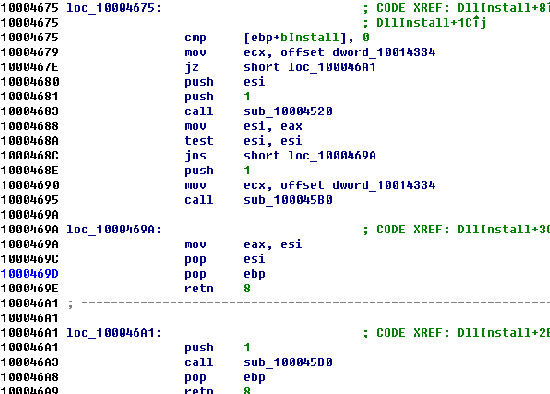

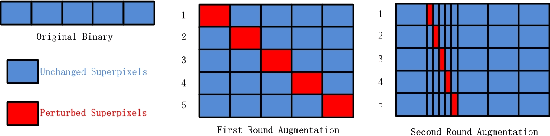
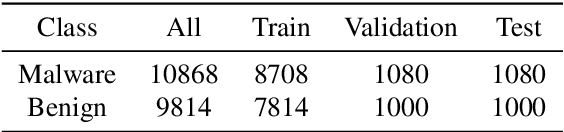
Deep neural networks (DNNs) are increasingly being applied in malware detection and their robustness has been widely debated. Traditionally an adversarial example generation scheme relies on either detailed model information (gradient-based methods) or lots of samples to train a surrogate model, neither of which are available in most scenarios. We propose the notion of the instance-based attack. Our scheme is interpretable and can work in a black-box environment. Given a specific binary example and a malware classifier, we use the data augmentation strategies to produce enough data from which we can train a simple interpretable model. We explain the detection model by displaying the weight of different parts of the specific binary. By analyzing the explanations, we found that the data subsections play an important role in Windows PE malware detection. We proposed a new function preserving transformation algorithm that can be applied to data subsections. By employing the binary-diversification techniques that we proposed, we eliminated the influence of the most weighted part to generate adversarial examples. Our algorithm can fool the DNNs in certain cases with a success rate of nearly 100\%. Our method outperforms the state-of-the-art method . The most important aspect is that our method operates in black-box settings and the results can be validated with domain knowledge. Our analysis model can assist people in improving the robustness of malware detectors.
A New Scheme for Image Compression and Encryption Using ECIES, Henon Map, and AEGAN
Aug 16, 2022


Providing security in the transmission of images and other multimedia data has become one of the most important scientific and practical issues. In this paper, a method for compressing and encryption images is proposed, which can safely transmit images in low-bandwidth data transmission channels. At first, using the autoencoding generative adversarial network (AEGAN) model, the images are mapped to a vector in the latent space with low dimensions. In the next step, the obtained vector is encrypted using public key encryption methods. In the proposed method, Henon chaotic map is used for permutation, which makes information transfer more secure. To evaluate the results of the proposed scheme, three criteria SSIM, PSNR, and execution time have been used.
Figure Descriptive Text Extraction using Ontological Representation
Aug 11, 2022
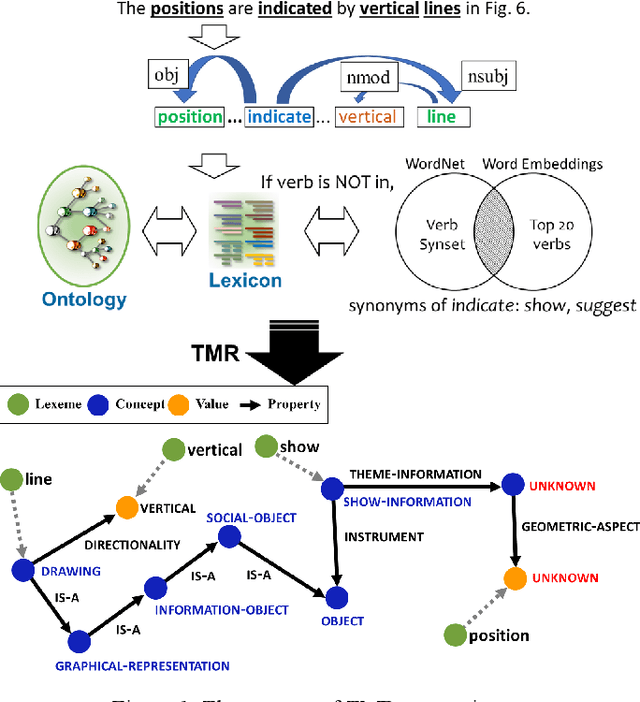
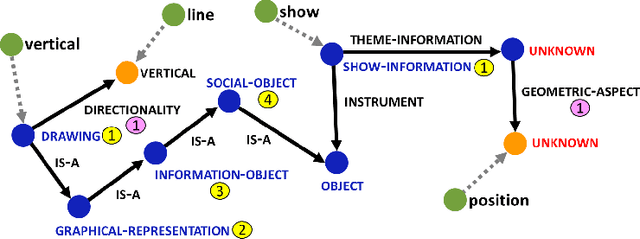
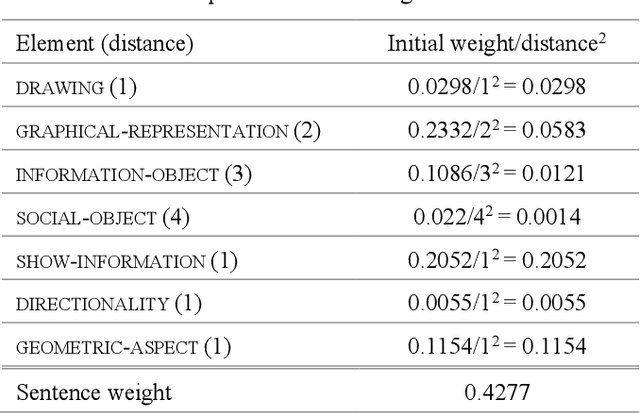
Experimental research publications provide figure form resources including graphs, charts, and any type of images to effectively support and convey methods and results. To describe figures, authors add captions, which are often incomplete, and more descriptions reside in body text. This work presents a method to extract figure descriptive text from the body of scientific articles. We adopted ontological semantics to aid concept recognition of figure-related information, which generates human- and machine-readable knowledge representations from sentences. Our results show that conceptual models bring an improvement in figure descriptive sentence classification over word-based approaches.
Back from the future: bidirectional CTC decoding using future information in speech recognition
Oct 07, 2021

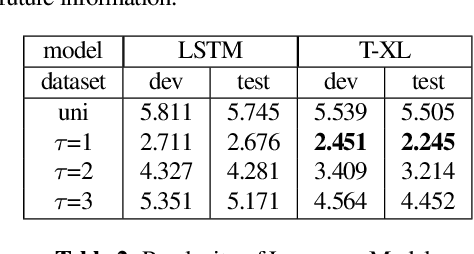
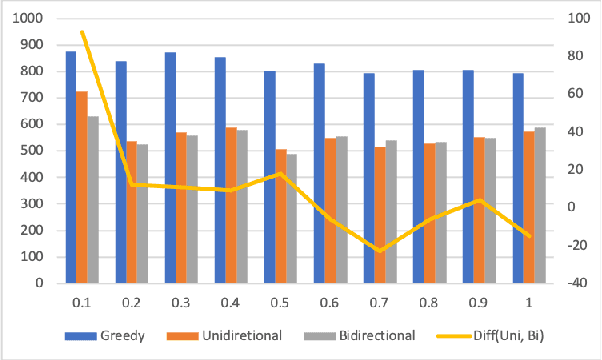
In this paper, we propose a simple but effective method to decode the output of Connectionist Temporal Classifier (CTC) model using a bi-directional neural language model. The bidirectional language model uses the future as well as the past information in order to predict the next output in the sequence. The proposed method based on bi-directional beam search takes advantage of the CTC greedy decoding output to represent the noisy future information. Experiments on the Librispeechdataset demonstrate the superiority of our proposed method compared to baselines using unidirectional decoding. In particular, the boost inaccuracy is most apparent at the start of a sequence which is the most erroneous part for existing systems based on unidirectional decoding.
PSAQ-ViT V2: Towards Accurate and General Data-Free Quantization for Vision Transformers
Sep 13, 2022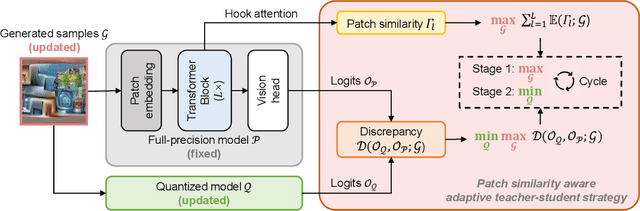
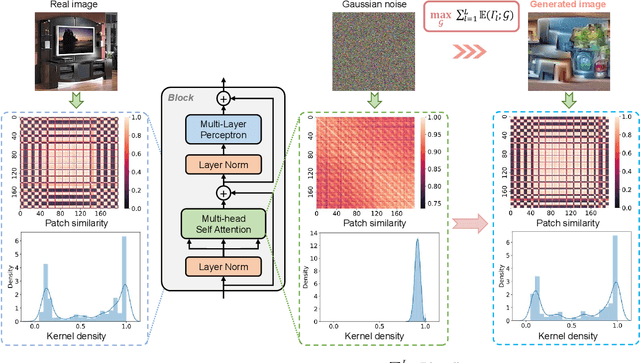

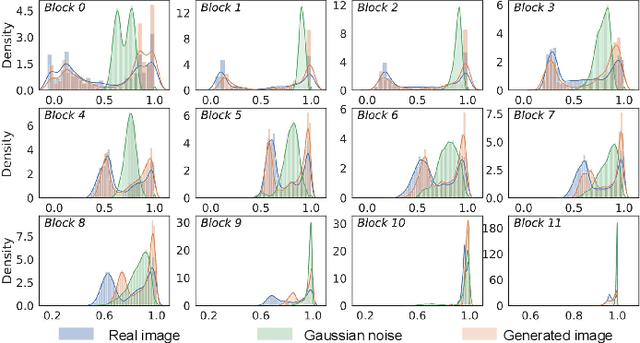
Data-free quantization can potentially address data privacy and security concerns in model compression, and thus has been widely investigated. Recently, PSAQ-ViT designs a relative value metric, patch similarity, to generate data from pre-trained vision transformers (ViTs), achieving the first attempt at data-free quantization for ViTs. In this paper, we propose PSAQ-ViT V2, a more accurate and general data-free quantization framework for ViTs, built on top of PSAQ-ViT. More specifically, following the patch similarity metric in PSAQ-ViT, we introduce an adaptive teacher-student strategy, which facilitates the constant cyclic evolution of the generated samples and the quantized model (student) in a competitive and interactive fashion under the supervision of the full-precision model (teacher), thus significantly improving the accuracy of the quantized model. Moreover, without the auxiliary category guidance, we employ the task- and model-independent prior information, making the general-purpose scheme compatible with a broad range of vision tasks and models. Extensive experiments are conducted on various models on image classification, object detection, and semantic segmentation tasks, and PSAQ-ViT V2, with the naive quantization strategy and without access to real-world data, consistently achieves competitive results, showing potential as a powerful baseline on data-free quantization for ViTs. For instance, with Swin-S as the (backbone) model, 8-bit quantization reaches 82.13 top-1 accuracy on ImageNet, 50.9 box AP and 44.1 mask AP on COCO, and 47.2 mIoU on ADE20K. We hope that accurate and general PSAQ-ViT V2 can serve as a potential and practice solution in real-world applications involving sensitive data. Code will be released and merged at: https://github.com/zkkli/PSAQ-ViT.
SIND: A Drone Dataset at Signalized Intersection in China
Sep 06, 2022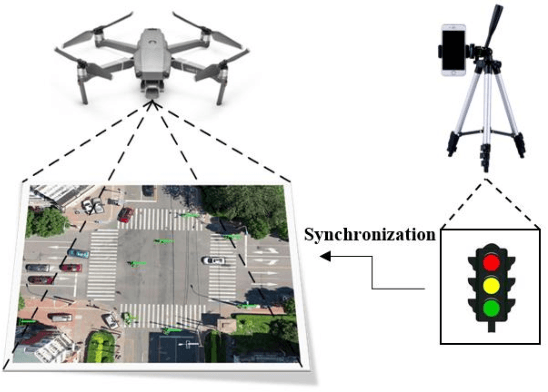

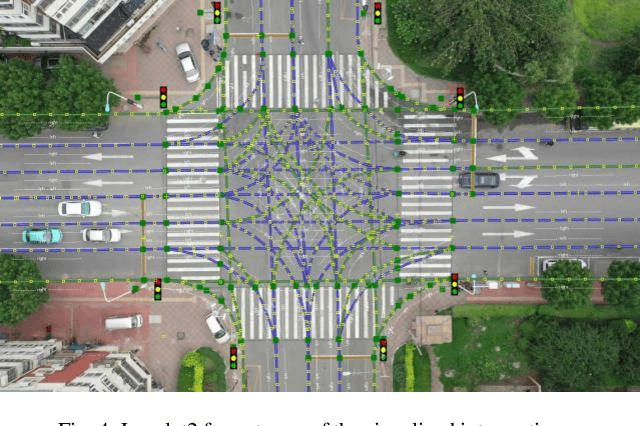
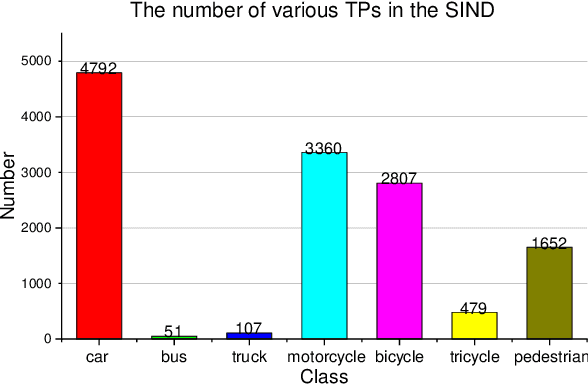
Intersection is one of the most challenging scenarios for autonomous driving tasks. Due to the complexity and stochasticity, essential applications (e.g., behavior modeling, motion prediction, safety validation, etc.) at intersections rely heavily on data-driven techniques. Thus, there is an intense demand for trajectory datasets of traffic participants (TPs) in intersections. Currently, most intersections in urban areas are equipped with traffic lights. However, there is not yet a large-scale, high-quality, publicly available trajectory dataset for signalized intersections. Therefore, in this paper, a typical two-phase signalized intersection is selected in Tianjin, China. Besides, a pipeline is designed to construct a Signalized INtersection Dataset (SIND), which contains 7 hours of recording including over 13,000 TPs with 7 types. Then, the behaviors of traffic light violations in SIND are recorded. Furthermore, the SIND is also compared with other similar works. The features of the SIND can be summarized as follows: 1) SIND provides more comprehensive information, including traffic light states, motion parameters, High Definition (HD) map, etc. 2) The category of TPs is diverse and characteristic, where the proportion of vulnerable road users (VRUs) is up to 62.6% 3) Multiple traffic light violations of non-motor vehicles are shown. We believe that SIND would be an effective supplement to existing datasets and can promote related research on autonomous driving.The dataset is available online via: https://github.com/SOTIF-AVLab/SinD
Multi-Agent Reinforcement Learning with Graph Convolutional Neural Networks for optimal Bidding Strategies of Generation Units in Electricity Markets
Aug 11, 2022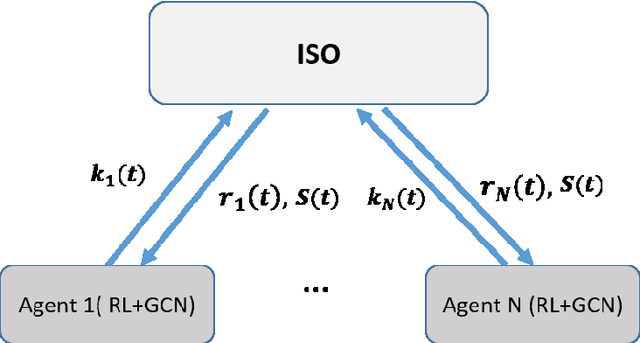
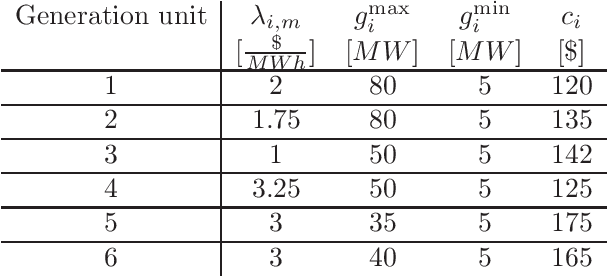
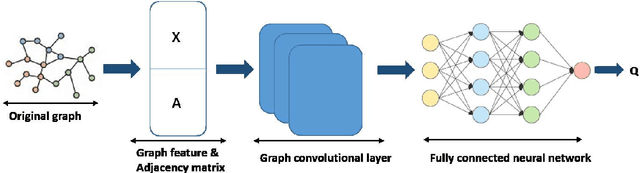
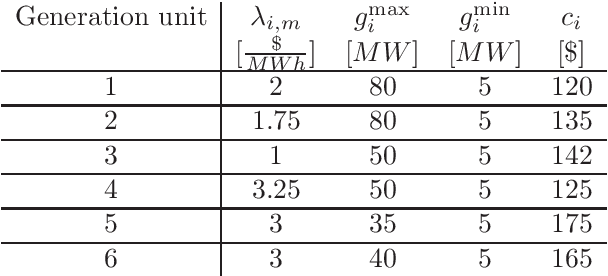
Finding optimal bidding strategies for generation units in electricity markets would result in higher profit. However, it is a challenging problem due to the system uncertainty which is due to the unknown other generation units' strategies. Distributed optimization, where each entity or agent decides on its bid individually, has become state of the art. However, it cannot overcome the challenges of system uncertainties. Deep reinforcement learning is a promising approach to learn the optimal strategy in uncertain environments. Nevertheless, it is not able to integrate the information on the spatial system topology in the learning process. This paper proposes a distributed learning algorithm based on deep reinforcement learning (DRL) combined with a graph convolutional neural network (GCN). In fact, the proposed framework helps the agents to update their decisions by getting feedback from the environment so that it can overcome the challenges of the uncertainties. In this proposed algorithm, the state and connection between nodes are the inputs of the GCN, which can make agents aware of the structure of the system. This information on the system topology helps the agents to improve their bidding strategies and increase the profit. We evaluate the proposed algorithm on the IEEE 30-bus system under different scenarios. Also, to investigate the generalization ability of the proposed approach, we test the trained model on IEEE 39-bus system. The results show that the proposed algorithm has more generalization abilities compare to the DRL and can result in higher profit when changing the topology of the system.
Active Learning for Optimal Intervention Design in Causal Models
Sep 10, 2022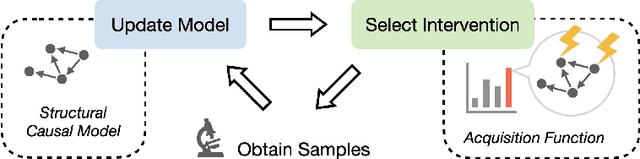
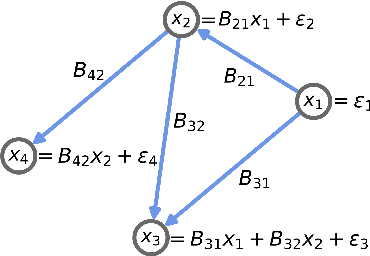
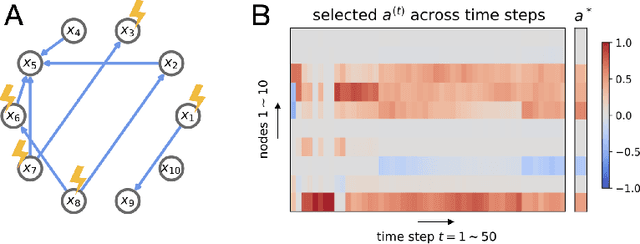
An important problem across disciplines is the discovery of interventions that produce a desired outcome. When the space of possible interventions is large, making an exhaustive search infeasible, experimental design strategies are needed. In this context, encoding the causal relationships between the variables, and thus the effect of interventions on the system, is critical in order to identify desirable interventions efficiently. We develop an iterative causal method to identify optimal interventions, as measured by the discrepancy between the post-interventional mean of the distribution and a desired target mean. We formulate an active learning strategy that uses the samples obtained so far from different interventions to update the belief about the underlying causal model, as well as to identify samples that are most informative about optimal interventions and thus should be acquired in the next batch. The approach employs a Bayesian update for the causal model and prioritizes interventions using a carefully designed, causally informed acquisition function. This acquisition function is evaluated in closed form, allowing for efficient optimization. The resulting algorithms are theoretically grounded with information-theoretic bounds and provable consistency results. We illustrate the method on both synthetic data and real-world biological data, namely gene expression data from Perturb-CITE-seq experiments, to identify optimal perturbations that induce a specific cell state transition; the proposed causal approach is observed to achieve better sample efficiency compared to several baselines. In both cases we observe that the causally informed acquisition function notably outperforms existing criteria allowing for optimal intervention design with significantly less experiments.
Joint optimal beamforming and power control in cell-free massive MIMO
Aug 11, 2022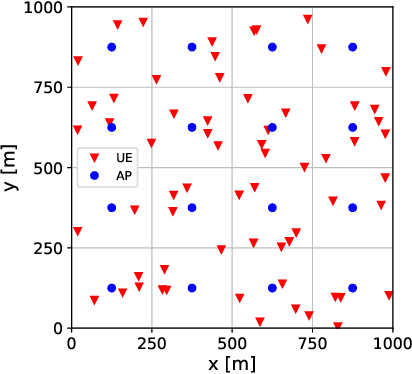
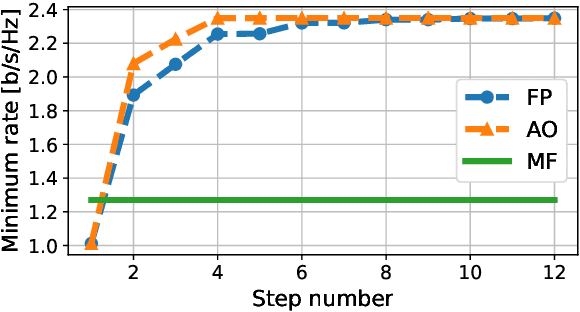
We derive a fast and optimal algorithm for solving practical weighted max-min SINR problems in cell-free massive MIMO networks. For the first time, the optimization problem jointly covers long-term power control and distributed beamforming design under imperfect cooperation. In particular, we consider user-centric clusters of access points cooperating on the basis of possibly limited channel state information sharing. Our optimal algorithm merges powerful power control tools based on interference calculus with the recently developed team theoretic framework for distributed beamforming design. In addition, we propose a variation that shows faster convergence in practice.
Algorithmic Differentiation for Automatized Modelling of Machine Learned Force Fields
Aug 25, 2022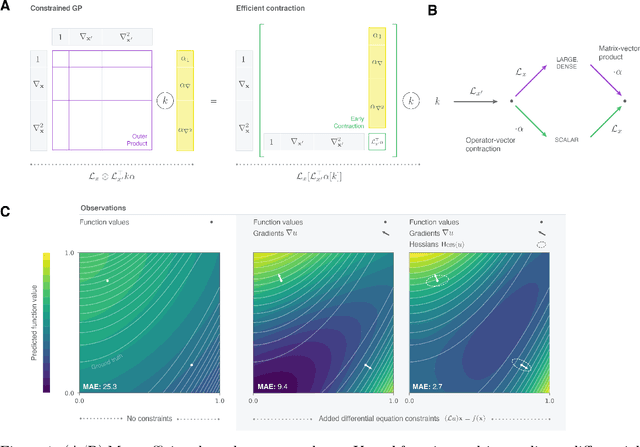


Reconstructing force fields (FF) from atomistic simulation data is a challenge since accurate data can be highly expensive. Here, machine learning (ML) models can help to be data economic as they can be successfully constrained using the underlying symmetry and conservation laws of physics. However, so far, every descriptor newly proposed for an ML model has required a cumbersome and mathematically tedious remodeling. We therefore propose to use modern techniques from algorithmic differentiation within the ML modeling process -- effectively enabling the usage of novel descriptors or models fully automatically at an order of magnitude higher computational efficiency. This paradigmatic approach enables not only a versatile usage of novel representations, the efficient computation of larger systems -- all of high value to the FF community -- but also the simple inclusion of further physical knowledge such as higher-order information (e.g.~Hessians, more complex partial differential equations constraints etc.), even beyond the presented FF domain.