 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Video-based Cross-modal Auxiliary Network for Multimodal Sentiment Analysis
Aug 30, 2022
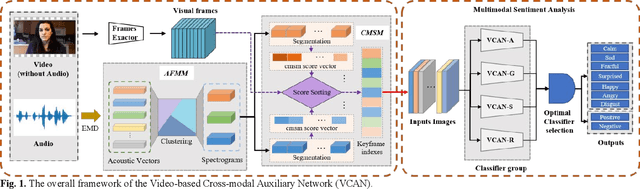
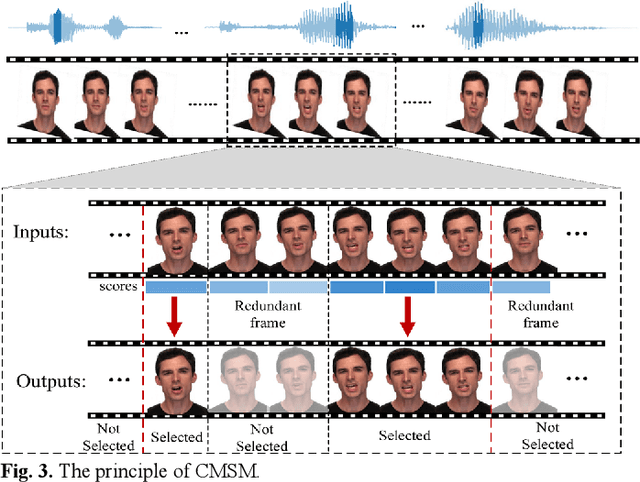
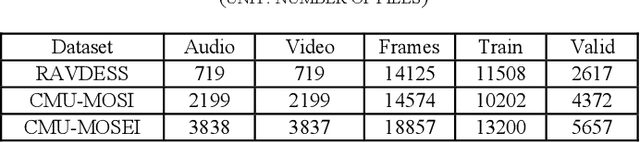
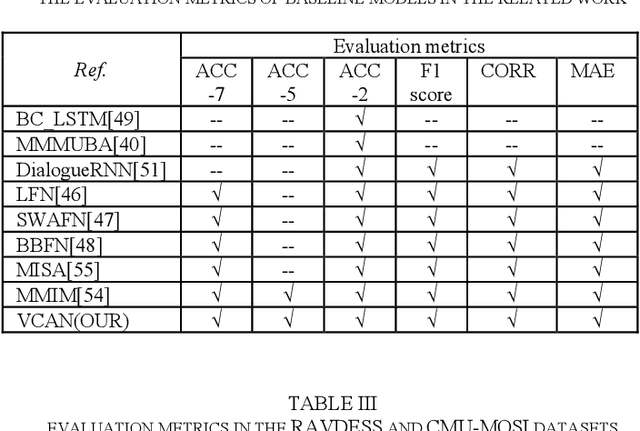
Multimodal sentiment analysis has a wide range of applications due to its information complementarity in multimodal interactions. Previous works focus more on investigating efficient joint representations, but they rarely consider the insufficient unimodal features extraction and data redundancy of multimodal fusion. In this paper, a Video-based Cross-modal Auxiliary Network (VCAN) is proposed, which is comprised of an audio features map module and a cross-modal selection module. The first module is designed to substantially increase feature diversity in audio feature extraction, aiming to improve classification accuracy by providing more comprehensive acoustic representations. To empower the model to handle redundant visual features, the second module is addressed to efficiently filter the redundant visual frames during integrating audiovisual data. Moreover, a classifier group consisting of several image classification networks is introduced to predict sentiment polarities and emotion categories. Extensive experimental results on RAVDESS, CMU-MOSI, and CMU-MOSEI benchmarks indicate that VCAN is significantly superior to the state-of-the-art methods for improving the classification accuracy of multimodal sentiment analysis.
Micro-Vibration Modes Reconstruction Based on Micro-Doppler Coincidence Imaging
Aug 30, 2022



Micro-vibration, a ubiquitous nature phenomenon, can be seen as a characteristic feature on the objects, these vibrations always have tiny amplitudes which are much less than the wavelengths of the sensing systems, thus these motions information can only be reflected in the phase item of echo. Normally the conventional radar system can detect these micro vibrations through the time frequency analyzing, but these vibration characteristics can only be reflected by time-frequency spectrum, the spatial distribution of these micro vibrations can not be reconstructed precisely. Ghost imaging (GI), a novel imaging method also known as Coincidence Imaging that originated in the quantum and optical fields, can reconstruct unknown images using computational methods. To reconstruct the spatial distribution of micro vibrations, this paper proposes a new method based on a coincidence imaging system. A detailed model of target micro-vibration is created first, taking into account two categories: discrete and continuous targets. We use the first-order field correlation feature to obtain objective different micro vibration distribution based on the complex target models and time-frequency analysis in this work.
CD and PMD Effect on Cyclostationarity-Based Timing Recovery for Optical Coherent Receivers
Aug 30, 2022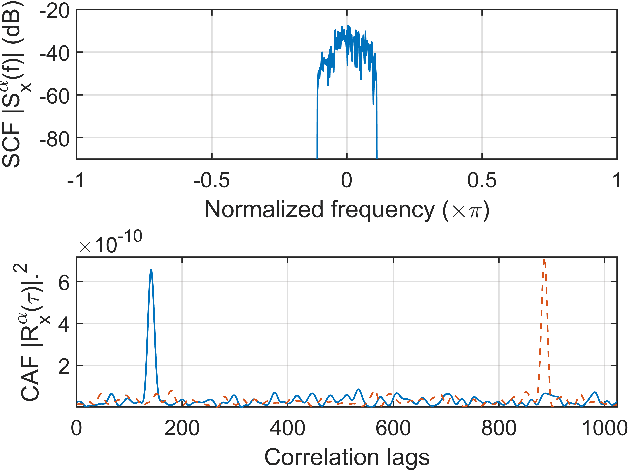

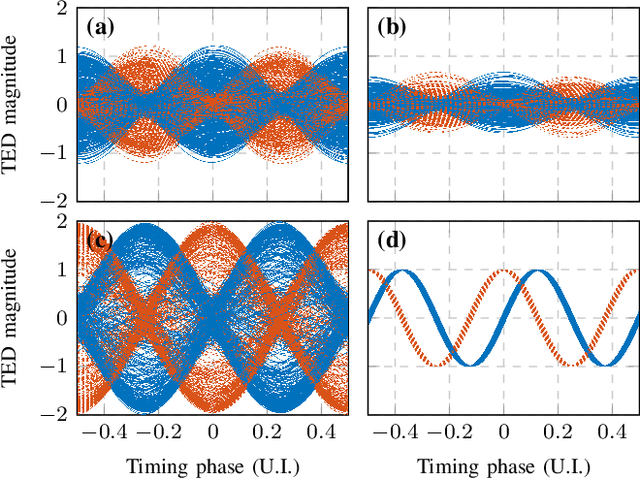
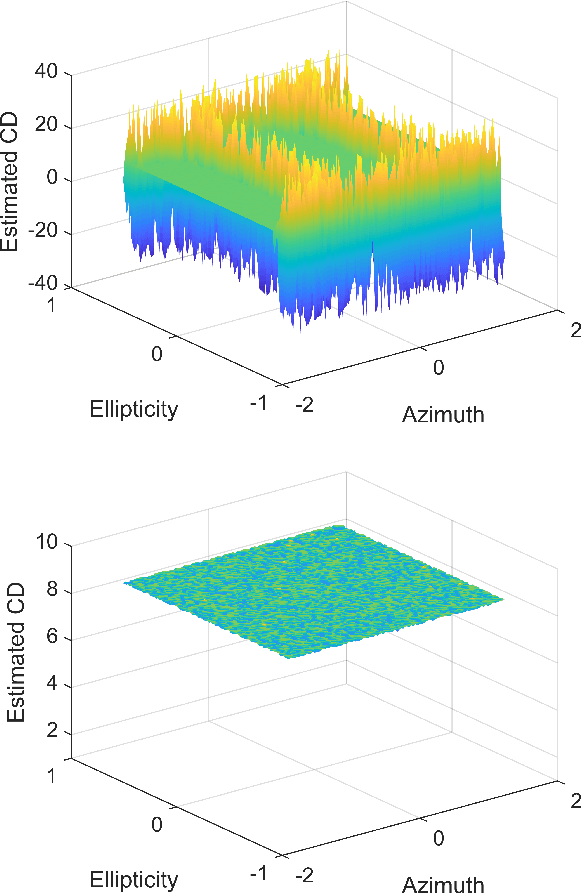
Timing recovery is critical for synchronizing the clocks at the transmitting and receiving ends of a digital coherent communication system. The core of timing recovery is to determine reliably the current sampling error of the local digitizer so that the timing circuit may lock to a stable operation point. Conventional timing phase detectors need to adapt to the optical fiber channel so that the common effects of this channel, such as chromatic dispersion (CD) and polarization mode dispersion (PMD), on the timing phase extraction must be understood. Here we exploit the cyclostationarity of the optical signal and derive a model for studying the CD and PMD effect. We prove that the CD-adjusted cyclic correlation matrix contains full information about timing and PMD, and the determinant of the matrix is a timing phase detector immune to both CD and PMD. We also obtain other results such as a completely PMD-independent CD estimator, etc. Our analysis is supported by both simulations and experiments over a field implemented optical cable.
Dense Teacher: Dense Pseudo-Labels for Semi-supervised Object Detection
Jul 19, 2022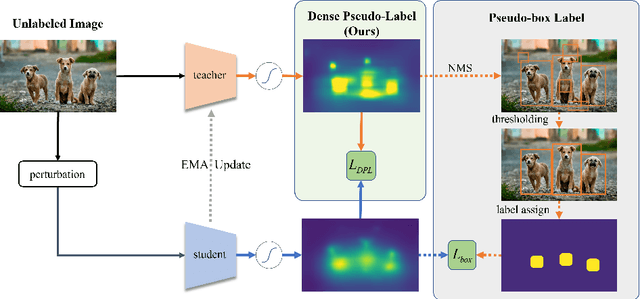
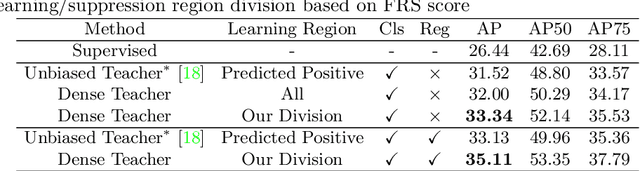
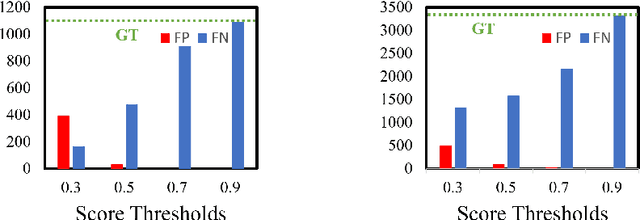
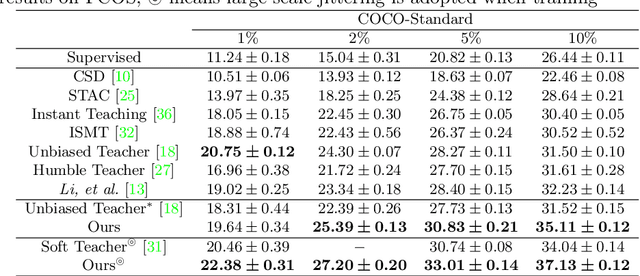
To date, the most powerful semi-supervised object detectors (SS-OD) are based on pseudo-boxes, which need a sequence of post-processing with fine-tuned hyper-parameters. In this work, we propose replacing the sparse pseudo-boxes with the dense prediction as a united and straightforward form of pseudo-label. Compared to the pseudo-boxes, our Dense Pseudo-Label (DPL) does not involve any post-processing method, thus retaining richer information. We also introduce a region selection technique to highlight the key information while suppressing the noise carried by dense labels. We name our proposed SS-OD algorithm that leverages the DPL as Dense Teacher. On COCO and VOC, Dense Teacher shows superior performance under various settings compared with the pseudo-box-based methods.
Learning a General Clause-to-Clause Relationships for Enhancing Emotion-Cause Pair Extraction
Aug 30, 2022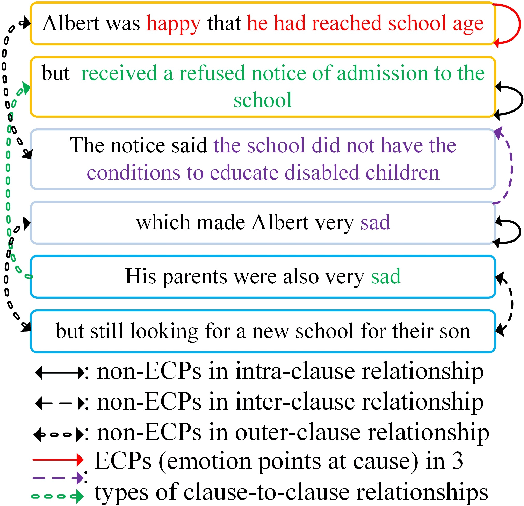
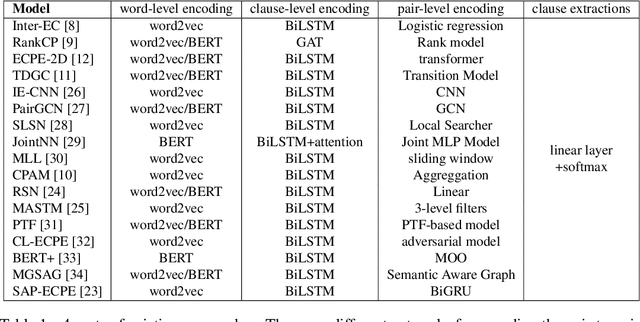
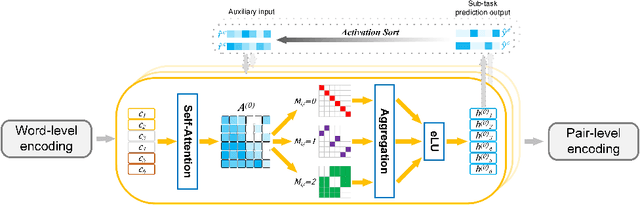
Emotion-cause pair extraction (ECPE) is an emerging task aiming to extract potential pairs of emotions and corresponding causes from documents. Previous approaches have focused on modeling the pair-to-pair relationship and achieved promising results. However, the clause-to-clause relationship, which fundamentally symbolizes the underlying structure of a document, has still been in its research infancy. In this paper, we define a novel clause-to-clause relationship. To learn it applicably, we propose a general clause-level encoding model named EA-GAT comprising E-GAT and Activation Sort. E-GAT is designed to aggregate information from different types of clauses; Activation Sort leverages the individual emotion/cause prediction and the sort-based mapping to propel the clause to a more favorable representation. Since EA-GAT is a clause-level encoding model, it can be broadly integrated with any previous approach. Experimental results show that our approach has a significant advantage over all current approaches on the Chinese and English benchmark corpus, with an average of $2.1\%$ and $1.03\%$.
Disentangled Information Bottleneck
Dec 19, 2020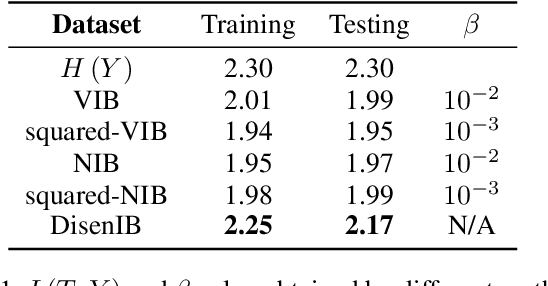
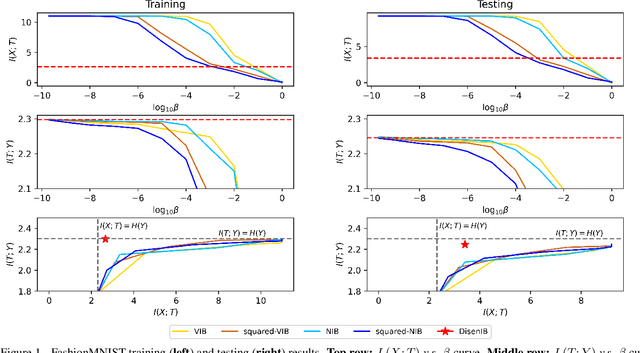
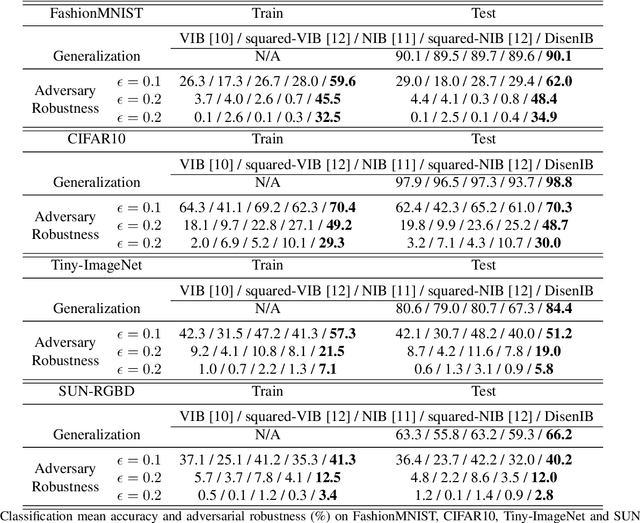
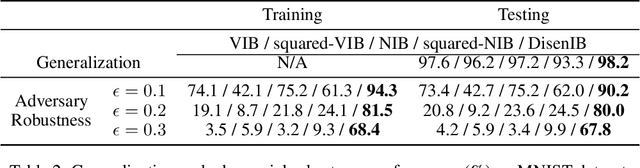
The information bottleneck (IB) method is a technique for extracting information that is relevant for predicting the target random variable from the source random variable, which is typically implemented by optimizing the IB Lagrangian that balances the compression and prediction terms. However, the IB Lagrangian is hard to optimize, and multiple trials for tuning values of Lagrangian multiplier are required. Moreover, we show that the prediction performance strictly decreases as the compression gets stronger during optimizing the IB Lagrangian. In this paper, we implement the IB method from the perspective of supervised disentangling. Specifically, we introduce Disentangled Information Bottleneck (DisenIB) that is consistent on compressing source maximally without target prediction performance loss (maximum compression). Theoretical and experimental results demonstrate that our method is consistent on maximum compression, and performs well in terms of generalization, robustness to adversarial attack, out-of-distribution detection, and supervised disentangling.
Reconstructing Sparse Illicit Supply Networks: A Case Study of Multiplex Drug Trafficking Networks
Jul 29, 2022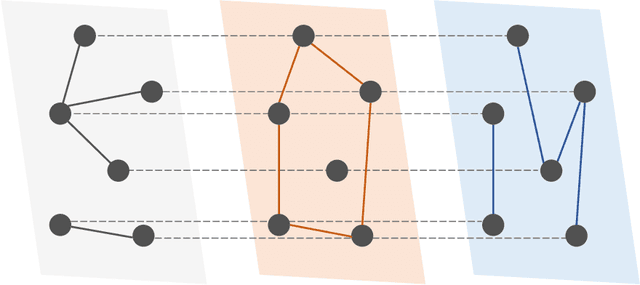

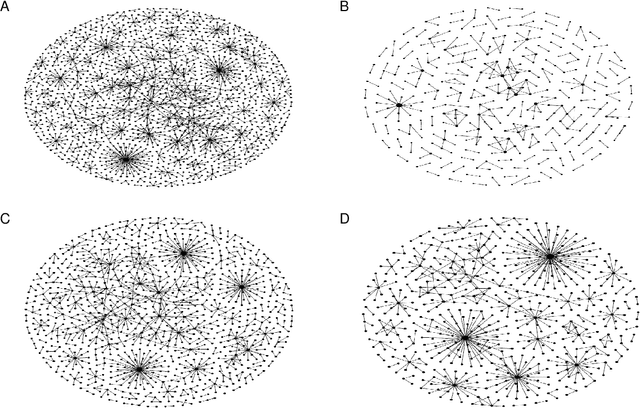

The network structure provides critical information for law enforcement agencies to develop effective strategies to interdict illicit supply networks. However, the complete structure of covert networks is often unavailable, thus it is crucially important to develop approaches to infer a more complete structure of covert networks. In this paper, we work on real-world multiplex drug trafficking networks extracted from an investigation report. A statistical approach built on the EM algorithm (DegEM) as well as other methods based on structural similarity are applied to reconstruct the multiplex drug trafficking network given different fractions of observed nodes and links. It is found that DegEM approach achieves the best predictive performance in terms of several accuracy metrics. Meanwhile, structural similarity-based methods perform poorly in reconstructing the drug trafficking networks due to the sparsity of links between nodes in the network. The inferred multiplex networks can be leveraged to (i) inform the decision-making on monitoring covert networks as well as allocating limited resources for collecting additional information to improve the reconstruction accuracy and (ii) develop more effective interdiction strategies.
BiFuse++: Self-supervised and Efficient Bi-projection Fusion for 360 Depth Estimation
Sep 07, 2022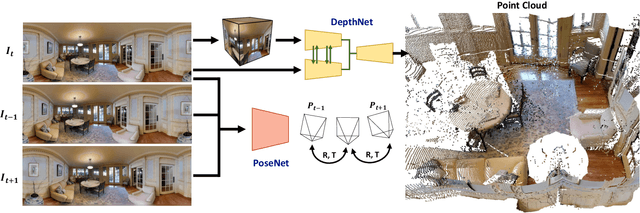
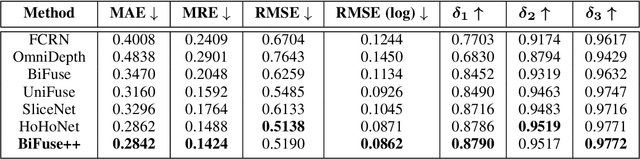

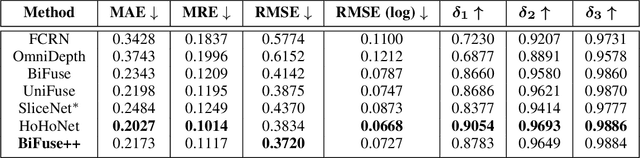
Due to the rise of spherical cameras, monocular 360 depth estimation becomes an important technique for many applications (e.g., autonomous systems). Thus, state-of-the-art frameworks for monocular 360 depth estimation such as bi-projection fusion in BiFuse are proposed. To train such a framework, a large number of panoramas along with the corresponding depth ground truths captured by laser sensors are required, which highly increases the cost of data collection. Moreover, since such a data collection procedure is time-consuming, the scalability of extending these methods to different scenes becomes a challenge. To this end, self-training a network for monocular depth estimation from 360 videos is one way to alleviate this issue. However, there are no existing frameworks that incorporate bi-projection fusion into the self-training scheme, which highly limits the self-supervised performance since bi-projection fusion can leverage information from different projection types. In this paper, we propose BiFuse++ to explore the combination of bi-projection fusion and the self-training scenario. To be specific, we propose a new fusion module and Contrast-Aware Photometric Loss to improve the performance of BiFuse and increase the stability of self-training on real-world videos. We conduct both supervised and self-supervised experiments on benchmark datasets and achieve state-of-the-art performance.
Exploring Wasserstein Distance across Concept Embeddings for Ontology Matching
Jul 22, 2022



Measuring the distance between ontological elements is a fundamental component for any matching solutions. String-based distance metrics relying on discrete symbol operations are notorious for shallow syntactic matching. In this study, we explore Wasserstein distance metric across ontology concept embeddings. Wasserstein distance metric targets continuous space that can incorporate linguistic, structural, and logical information. In our exploratory study, we use a pre-trained word embeddings system, fasttext, to embed ontology element labels. We examine the effectiveness of Wasserstein distance for measuring similarity between (blocks of) ontolgoies, discovering matchings between individual elements, and refining matchings incorporating contextual information. Our experiments with the OAEI conference track and MSE benchmarks achieve competitive results compared to the leading systems such as AML and LogMap. Results indicate a promising trajectory for the application of optimal transport and Wasserstein distance to improve embedding-based unsupervised ontology matchings.
The Cross-Lingual Arabic Information REtrieval (CLAIRE) System
Jul 29, 2021
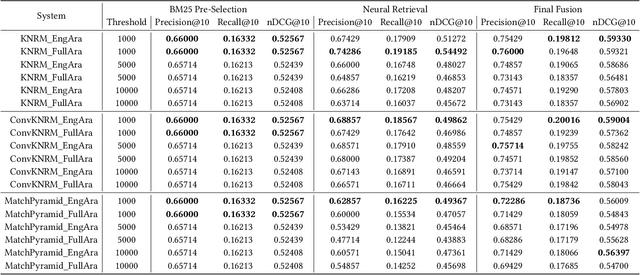
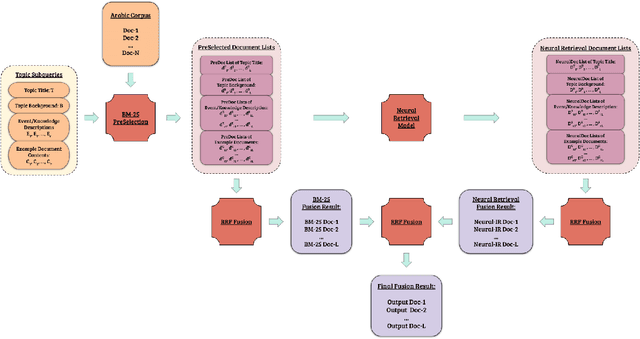
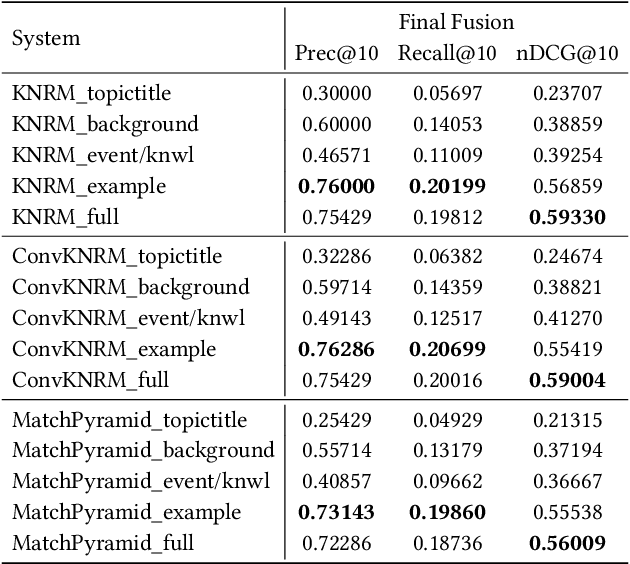
Despite advances in neural machine translation, cross-lingual retrieval tasks in which queries and documents live in different natural language spaces remain challenging. Although neural translation models may provide an intuitive approach to tackle the cross-lingual problem, their resource-consuming training and advanced model structures may complicate the overall retrieval pipeline and reduce users engagement. In this paper, we build our end-to-end Cross-Lingual Arabic Information REtrieval (CLAIRE) system based on the cross-lingual word embedding where searchers are assumed to have a passable passive understanding of Arabic and various supporting information in English is provided to aid retrieval experience. The proposed system has three major advantages: (1) The usage of English-Arabic word embedding simplifies the overall pipeline and avoids the potential mistakes caused by machine translation. (2) Our CLAIRE system can incorporate arbitrary word embedding-based neural retrieval models without structural modification. (3) Early empirical results on an Arabic news collection show promising performance.