 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning-based and unrolled motion-compensated reconstruction for cardiac MR CINE imaging
Sep 08, 2022




Motion-compensated MR reconstruction (MCMR) is a powerful concept with considerable potential, consisting of two coupled sub-problems: Motion estimation, assuming a known image, and image reconstruction, assuming known motion. In this work, we propose a learning-based self-supervised framework for MCMR, to efficiently deal with non-rigid motion corruption in cardiac MR imaging. Contrary to conventional MCMR methods in which the motion is estimated prior to reconstruction and remains unchanged during the iterative optimization process, we introduce a dynamic motion estimation process and embed it into the unrolled optimization. We establish a cardiac motion estimation network that leverages temporal information via a group-wise registration approach, and carry out a joint optimization between the motion estimation and reconstruction. Experiments on 40 acquired 2D cardiac MR CINE datasets demonstrate that the proposed unrolled MCMR framework can reconstruct high quality MR images at high acceleration rates where other state-of-the-art methods fail. We also show that the joint optimization mechanism is mutually beneficial for both sub-tasks, i.e., motion estimation and image reconstruction, especially when the MR image is highly undersampled.
Computing with Hypervectors for Efficient Speaker Identification
Aug 28, 2022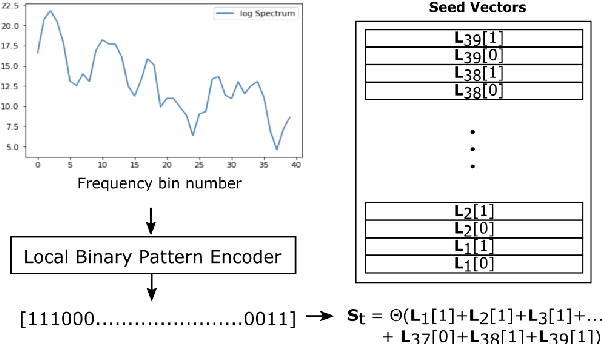

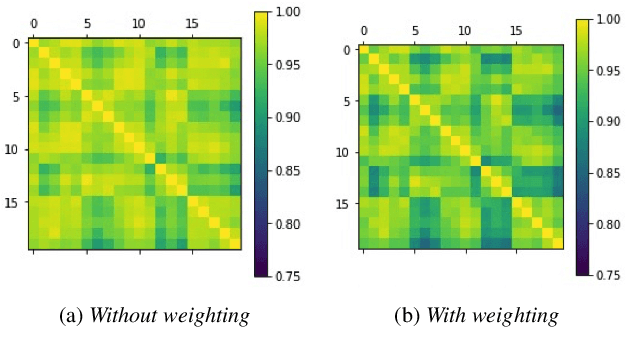
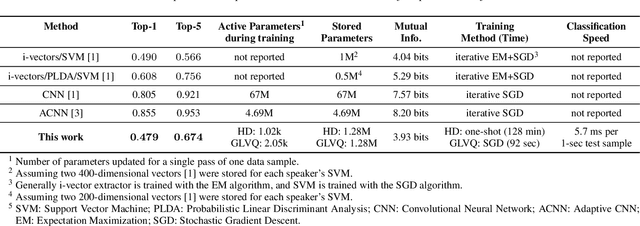
We introduce a method to identify speakers by computing with high-dimensional random vectors. Its strengths are simplicity and speed. With only 1.02k active parameters and a 128-minute pass through the training data we achieve Top-1 and Top-5 scores of 31% and 52% on the VoxCeleb1 dataset of 1,251 speakers. This is in contrast to CNN models requiring several million parameters and orders of magnitude higher computational complexity for only a 2$\times$ gain in discriminative power as measured in mutual information. An additional 92 seconds of training with Generalized Learning Vector Quantization (GLVQ) raises the scores to 48% and 67%. A trained classifier classifies 1 second of speech in 5.7 ms. All processing was done on standard CPU-based machines.
Asymptotic Average Mutual Information Over Finite Input Mixture Gamma Distributed Channels
Nov 24, 2021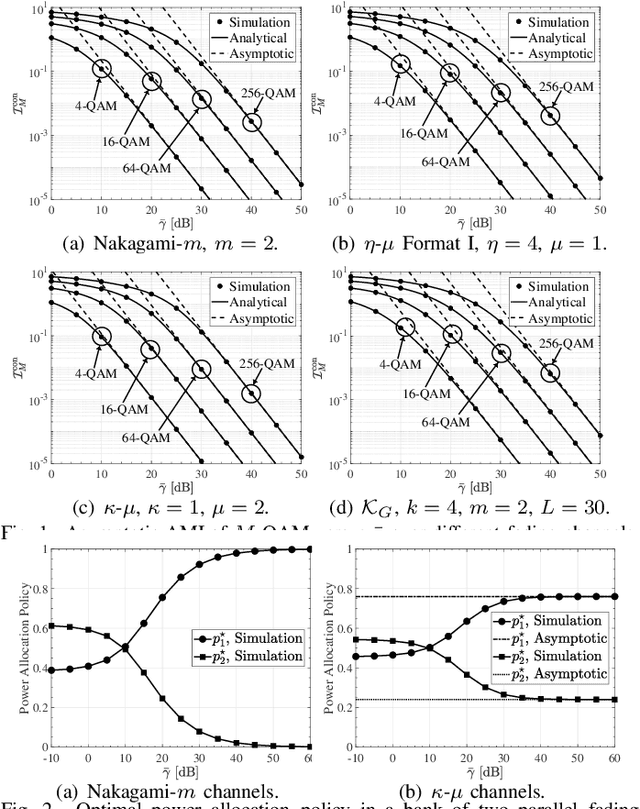
This letter establishes a unified analytical framework to study the asymptotic average mutual information (AMI) of mixture gamma (MG) distributed fading channels driven by finite input signals in the high signal-to-noise ratio (SNR) regime. It is found that the AMI converges to some constant as the average SNR increases and its rate of convergence (ROC) is determined by the coding gain and diversity order. Moreover, the derived results are used to investigate the asymptotic optimal power allocation policy of a bank of parallel fading channels having finite inputs. It is suggested that in the high SNR region, the sub-channel with a lower coding gain or diversity order should be allocated with more power. Finally, numerical results are provided to collaborate the theoretical analyses.
ELIT: Emory Language and Information Toolkit
Sep 08, 2021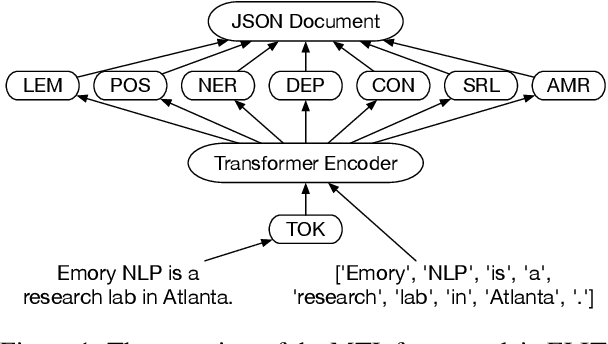
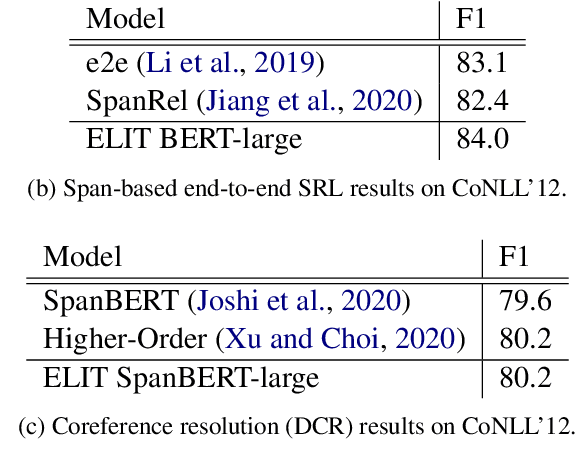

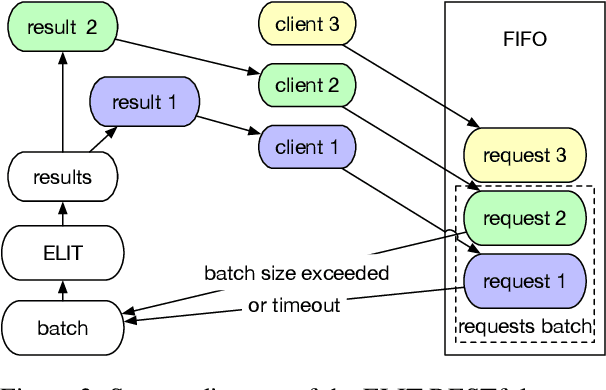
We introduce ELIT, the Emory Language and Information Toolkit, which is a comprehensive NLP framework providing transformer-based end-to-end models for core tasks with a special focus on memory efficiency while maintaining state-of-the-art accuracy and speed. Compared to existing toolkits, ELIT features an efficient Multi-Task Learning (MTL) model with many downstream tasks that include lemmatization, part-of-speech tagging, named entity recognition, dependency parsing, constituency parsing, semantic role labeling, and AMR parsing. The backbone of ELIT's MTL framework is a pre-trained transformer encoder that is shared across tasks to speed up their inference. ELIT provides pre-trained models developed on a remix of eight datasets. To scale up its service, ELIT also integrates a RESTful Client/Server combination. On the server side, ELIT extends its functionality to cover other tasks such as tokenization and coreference resolution, providing an end user with agile research experience. All resources including the source codes, documentation, and pre-trained models are publicly available at https://github.com/emorynlp/elit.
Blockwise Temporal-Spatial Pathway Network
Aug 05, 2022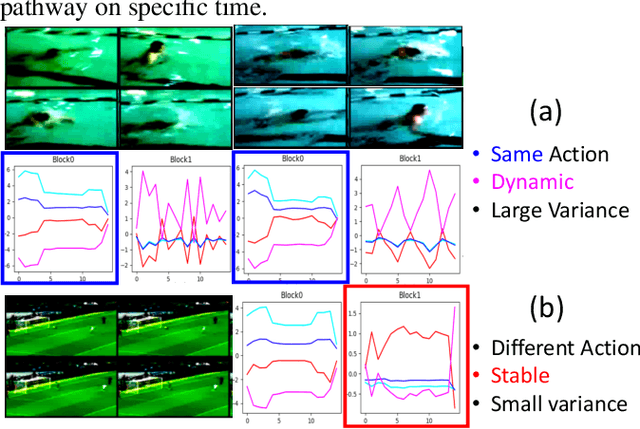
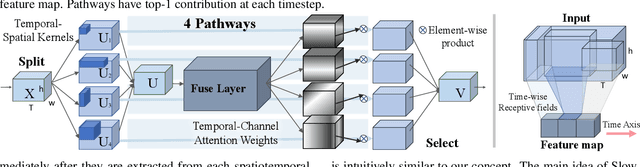
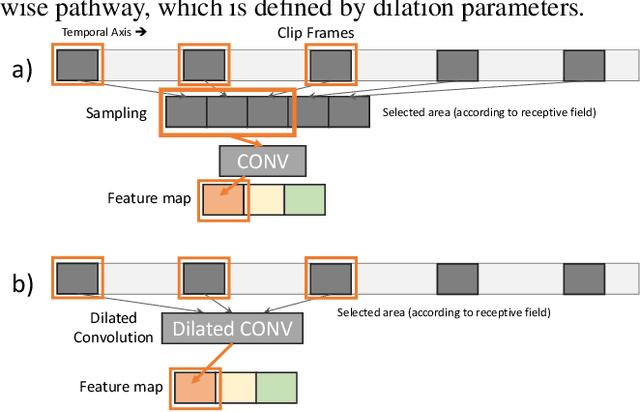
Algorithms for video action recognition should consider not only spatial information but also temporal relations, which remains challenging. We propose a 3D-CNN-based action recognition model, called the blockwise temporal-spatial path-way network (BTSNet), which can adjust the temporal and spatial receptive fields by multiple pathways. We designed a novel model inspired by an adaptive kernel selection-based model, which is an architecture for effective feature encoding that adaptively chooses spatial receptive fields for image recognition. Expanding this approach to the temporal domain, our model extracts temporal and channel-wise attention and fuses information on various candidate operations. For evaluation, we tested our proposed model on UCF-101, HMDB-51, SVW, and Epic-Kitchen datasets and showed that it generalized well without pretraining. BTSNet also provides interpretable visualization based on spatiotemporal channel-wise attention. We confirm that the blockwise temporal-spatial pathway supports a better representation for 3D convolutional blocks based on this visualization.
Visual Representations of Physiological Signals for Fake Video Detection
Jul 18, 2022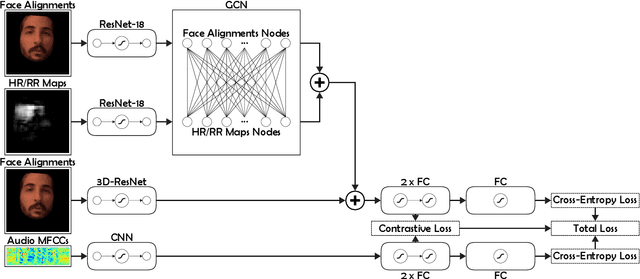
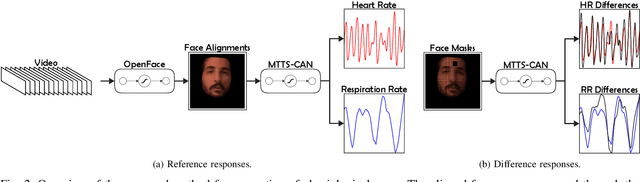
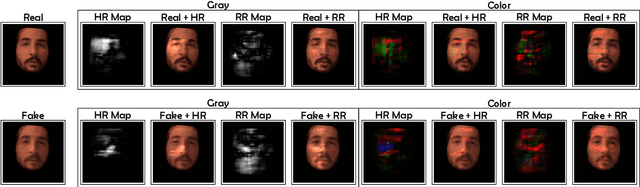

Realistic fake videos are a potential tool for spreading harmful misinformation given our increasing online presence and information intake. This paper presents a multimodal learning-based method for detection of real and fake videos. The method combines information from three modalities - audio, video, and physiology. We investigate two strategies for combining the video and physiology modalities, either by augmenting the video with information from the physiology or by novelly learning the fusion of those two modalities with a proposed Graph Convolutional Network architecture. Both strategies for combining the two modalities rely on a novel method for generation of visual representations of physiological signals. The detection of real and fake videos is then based on the dissimilarity between the audio and modified video modalities. The proposed method is evaluated on two benchmark datasets and the results show significant increase in detection performance compared to previous methods.
Robust Motion Averaging for Multi-view Registration of Point Sets Based Maximum Correntropy Criterion
Aug 24, 2022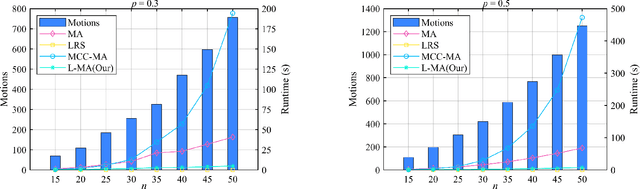
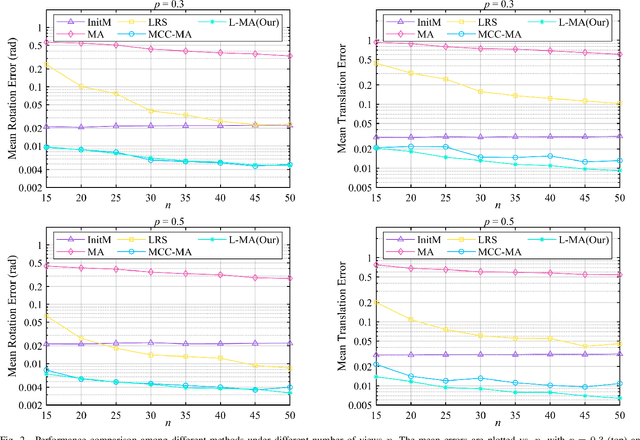
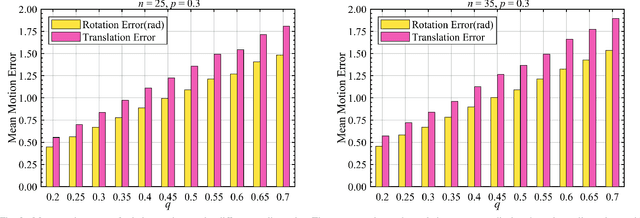
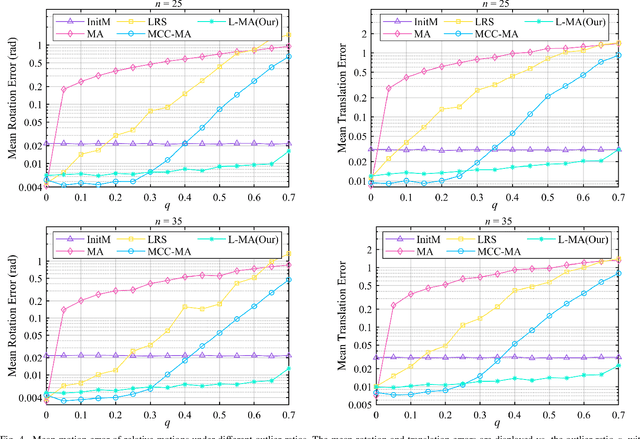
As an efficient algorithm to solve the multi-view registration problem,the motion averaging (MA) algorithm has been extensively studied and many MA-based algorithms have been introduced. They aim at recovering global motions from relative motions and exploiting information redundancy to average accumulative errors. However, one property of these methods is that they use Guass-Newton method to solve a least squares problem for the increment of global motions, which may lead to low efficiency and poor robustness to outliers. In this paper, we propose a novel motion averaging framework for the multi-view registration with Laplacian kernel-based maximum correntropy criterion (LMCC). Utilizing the Lie algebra motion framework and the correntropy measure, we propose a new cost function that takes all constraints supplied by relative motions into account. Obtaining the increment used to correct the global motions, can further be formulated as an optimization problem aimed at maximizing the cost function. By virtue of the quadratic technique, the optimization problem can be solved by dividing into two subproblems, i.e., computing the weight for each relative motion according to the current residuals and solving a second-order cone program problem (SOCP) for the increment in the next iteration. We also provide a novel strategy for determining the kernel width which ensures that our method can efficiently exploit information redundancy supplied by relative motions in the presence of many outliers. Finally, we compare the proposed method with other MA-based multi-view registration methods to verify its performance. Experimental tests on synthetic and real data demonstrate that our method achieves superior performance in terms of efficiency, accuracy and robustness.
Online Metro Origin-Destination Prediction via Heterogeneous Information Aggregation
Jul 05, 2021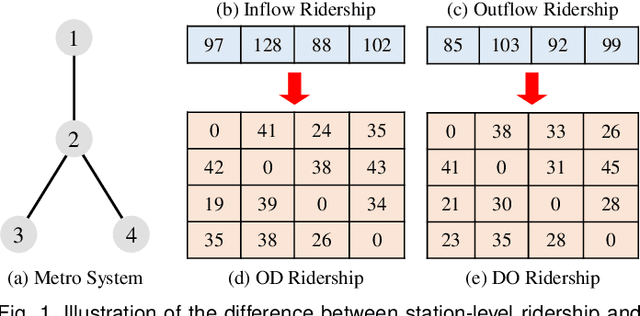
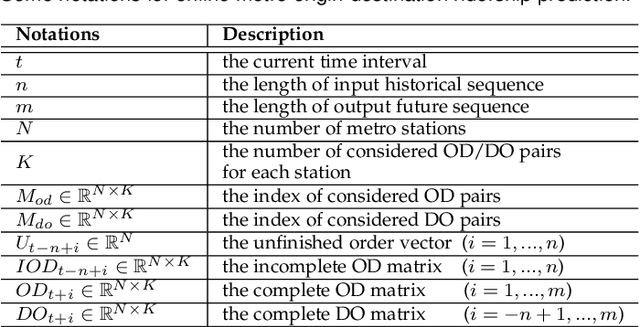
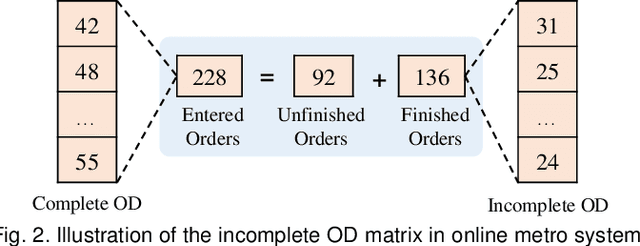
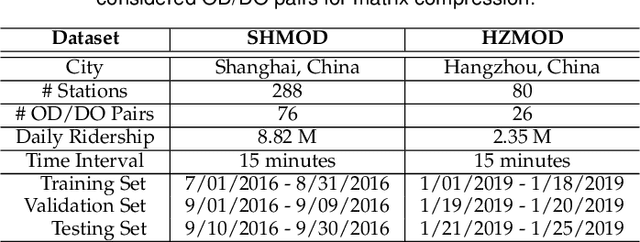
Metro origin-destination prediction is a crucial yet challenging task for intelligent transportation management, which aims to accurately forecast two specific types of cross-station ridership, i.e., Origin-Destination (OD) one and Destination-Origin (DO) one. However, complete OD matrices of previous time intervals can not be obtained immediately in online metro systems, and conventional methods only used limited information to forecast the future OD and DO ridership separately. In this work, we proposed a novel neural network module termed Heterogeneous Information Aggregation Machine (HIAM), which fully exploits heterogeneous information of historical data (e.g., incomplete OD matrices, unfinished order vectors, and DO matrices) to jointly learn the evolutionary patterns of OD and DO ridership. Specifically, an OD modeling branch estimates the potential destinations of unfinished orders explicitly to complement the information of incomplete OD matrices, while a DO modeling branch takes DO matrices as input to capture the spatial-temporal distribution of DO ridership. Moreover, a Dual Information Transformer is introduced to propagate the mutual information among OD features and DO features for modeling the OD-DO causality and correlation. Based on the proposed HIAM, we develop a unified Seq2Seq network to forecast the future OD and DO ridership simultaneously. Extensive experiments conducted on two large-scale benchmarks demonstrate the effectiveness of our method for online metro origin-destination prediction.
Associative Learning for Network Embedding
Aug 30, 2022
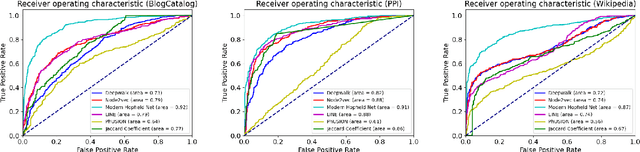

The network embedding task is to represent the node in the network as a low-dimensional vector while incorporating the topological and structural information. Most existing approaches solve this problem by factorizing a proximity matrix, either directly or implicitly. In this work, we introduce a network embedding method from a new perspective, which leverages Modern Hopfield Networks (MHN) for associative learning. Our network learns associations between the content of each node and that node's neighbors. These associations serve as memories in the MHN. The recurrent dynamics of the network make it possible to recover the masked node, given that node's neighbors. Our proposed method is evaluated on different downstream tasks such as node classification and linkage prediction. The results show competitive performance compared to the common matrix factorization techniques and deep learning based methods.
A Large-scale Multiple-objective Method for Black-box Attack against Object Detection
Sep 16, 2022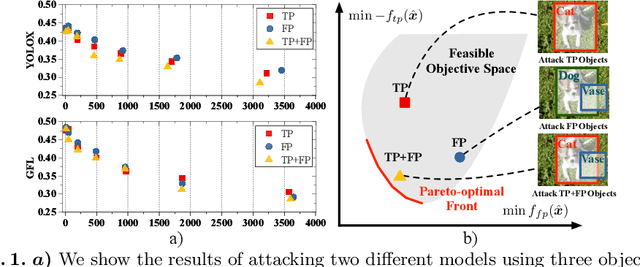
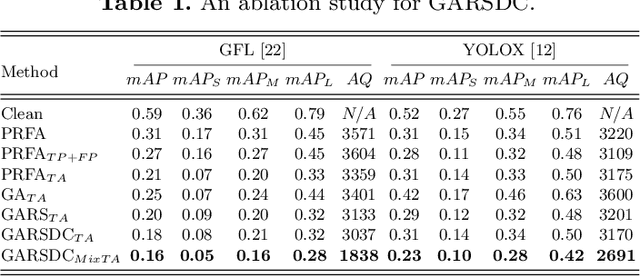
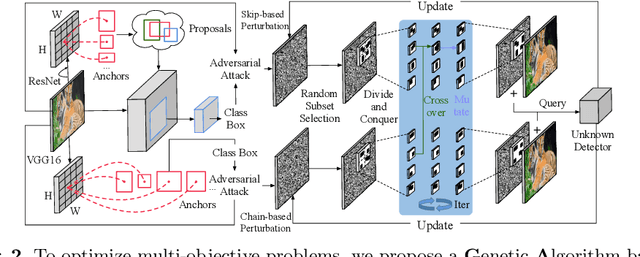
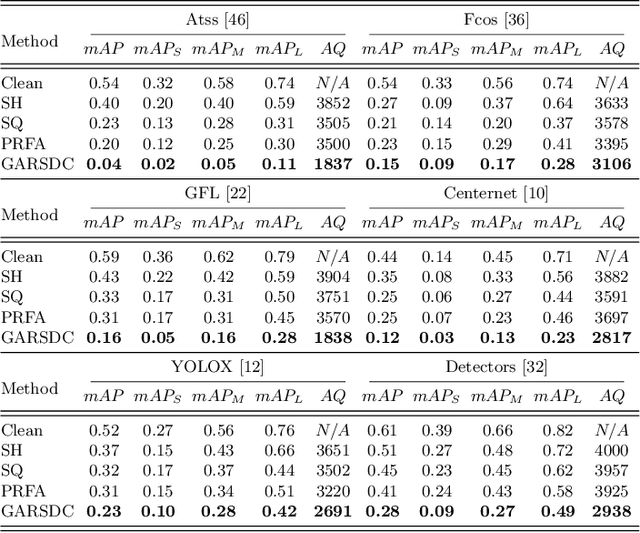
Recent studies have shown that detectors based on deep models are vulnerable to adversarial examples, even in the black-box scenario where the attacker cannot access the model information. Most existing attack methods aim to minimize the true positive rate, which often shows poor attack performance, as another sub-optimal bounding box may be detected around the attacked bounding box to be the new true positive one. To settle this challenge, we propose to minimize the true positive rate and maximize the false positive rate, which can encourage more false positive objects to block the generation of new true positive bounding boxes. It is modeled as a multi-objective optimization (MOP) problem, of which the generic algorithm can search the Pareto-optimal. However, our task has more than two million decision variables, leading to low searching efficiency. Thus, we extend the standard Genetic Algorithm with Random Subset selection and Divide-and-Conquer, called GARSDC, which significantly improves the efficiency. Moreover, to alleviate the sensitivity to population quality in generic algorithms, we generate a gradient-prior initial population, utilizing the transferability between different detectors with similar backbones. Compared with the state-of-art attack methods, GARSDC decreases by an average 12.0 in the mAP and queries by about 1000 times in extensive experiments. Our codes can be found at https://github.com/LiangSiyuan21/ GARSDC.