 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Simplifying Sparse Expert Recommendation by Revisiting Graph Diffusion
Aug 04, 2022

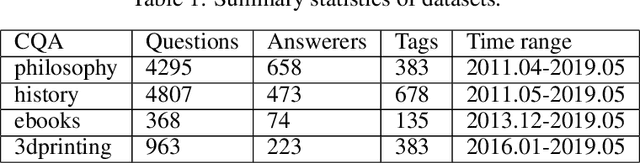
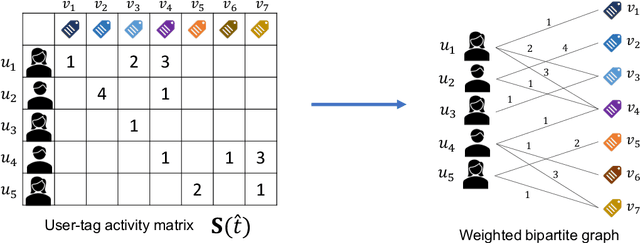
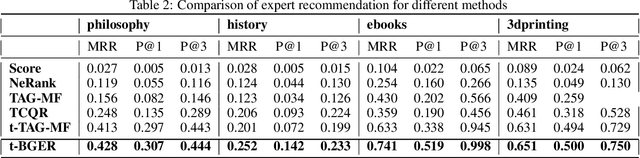
Community Question Answering (CQA) websites have become valuable knowledge repositories where individuals exchange information by asking and answering questions. With an ever-increasing number of questions and high migration of users in and out of communities, a key challenge is to design effective strategies for recommending experts for new questions. In this paper, we propose a simple graph-diffusion expert recommendation model for CQA, that can outperform state-of-the art deep learning representatives and collaborative models. Our proposed method learns users' expertise in the context of both semantic and temporal information to capture their changing interest and activity levels with time. Experiments on five real-world datasets from the Stack Exchange network demonstrate that our approach outperforms competitive baseline methods. Further, experiments on cold-start users (users with a limited historical record) show our model achieves an average of ~ 30% performance gain compared to the best baseline method.
Self-Supervised Masked Convolutional Transformer Block for Anomaly Detection
Sep 25, 2022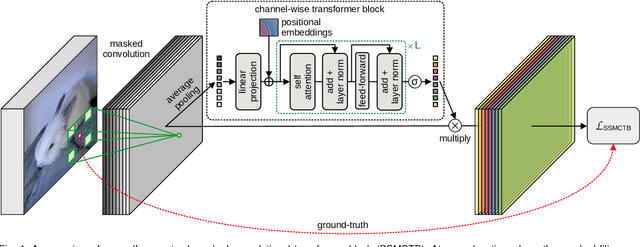

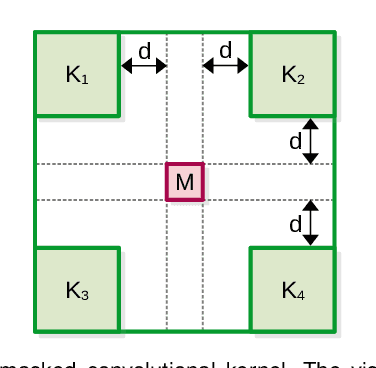
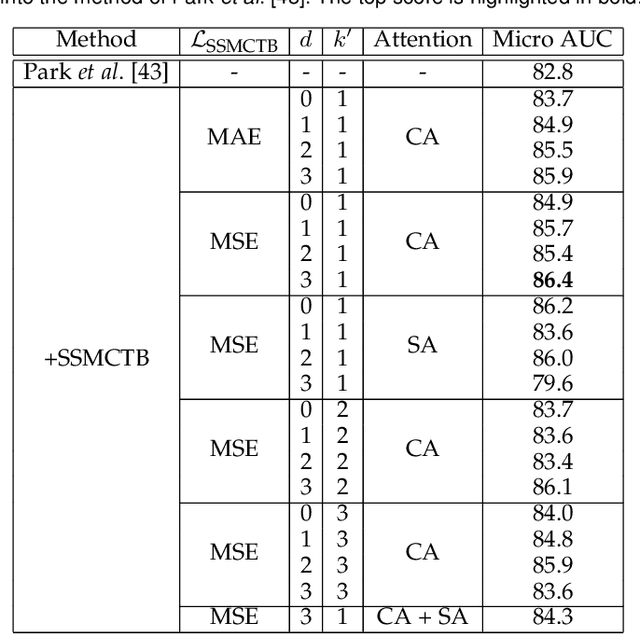
Anomaly detection has recently gained increasing attention in the field of computer vision, likely due to its broad set of applications ranging from product fault detection on industrial production lines and impending event detection in video surveillance to finding lesions in medical scans. Regardless of the domain, anomaly detection is typically framed as a one-class classification task, where the learning is conducted on normal examples only. An entire family of successful anomaly detection methods is based on learning to reconstruct masked normal inputs (e.g. patches, future frames, etc.) and exerting the magnitude of the reconstruction error as an indicator for the abnormality level. Unlike other reconstruction-based methods, we present a novel self-supervised masked convolutional transformer block (SSMCTB) that comprises the reconstruction-based functionality at a core architectural level. The proposed self-supervised block is extremely flexible, enabling information masking at any layer of a neural network and being compatible with a wide range of neural architectures. In this work, we extend our previous self-supervised predictive convolutional attentive block (SSPCAB) with a 3D masked convolutional layer, as well as a transformer for channel-wise attention. Furthermore, we show that our block is applicable to a wider variety of tasks, adding anomaly detection in medical images and thermal videos to the previously considered tasks based on RGB images and surveillance videos. We exhibit the generality and flexibility of SSMCTB by integrating it into multiple state-of-the-art neural models for anomaly detection, bringing forth empirical results that confirm considerable performance improvements on five benchmarks: MVTec AD, BRATS, Avenue, ShanghaiTech, and Thermal Rare Event. We release our code and data as open source at https://github.com/ristea/ssmctb.
gBuilder: A Scalable Knowledge Graph Construction System for Unstructured Corpus
Aug 27, 2022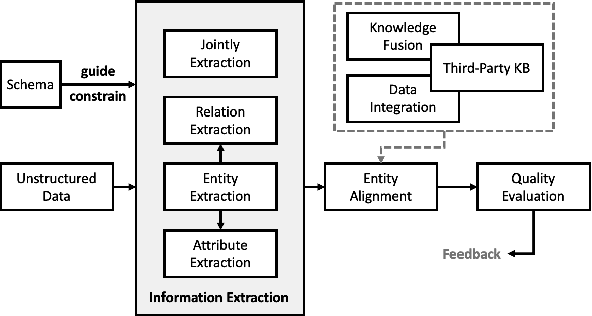

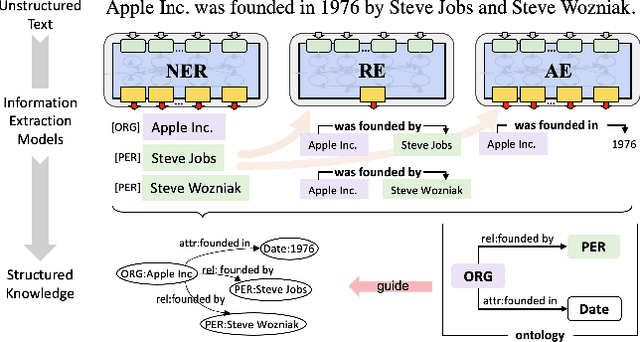
We design a user-friendly and scalable knowledge graph construction (KGC) system for extracting structured knowledge from the unstructured corpus. Different from existing KGC systems, gBuilder provides a flexible and user-defined pipeline to embrace the rapid development of IE models. More built-in template-based or heuristic operators and programmable operators are available for adapting to data from different domains. Furthermore, we also design a cloud-based self-adaptive task scheduling for gBuilder to ensure its scalability on large-scale knowledge graph construction. Experimental evaluation demonstrates the ability of gBuilder to organize multiple information extraction models for knowledge graph construction in a uniform platform, and confirms its high scalability on large-scale KGC tasks.
RIS-Aided MIMO Systems with Hardware Impairments: Robust Beamforming Design and Analysis
Sep 23, 2022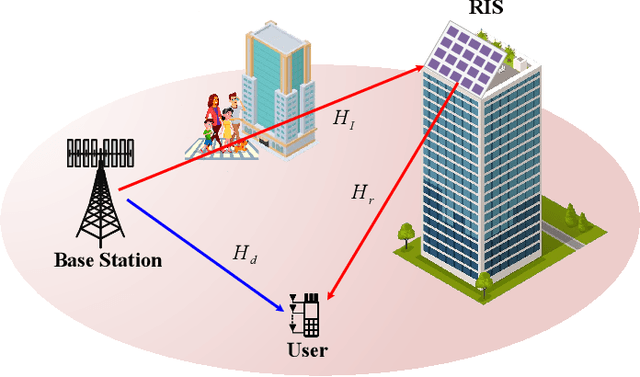
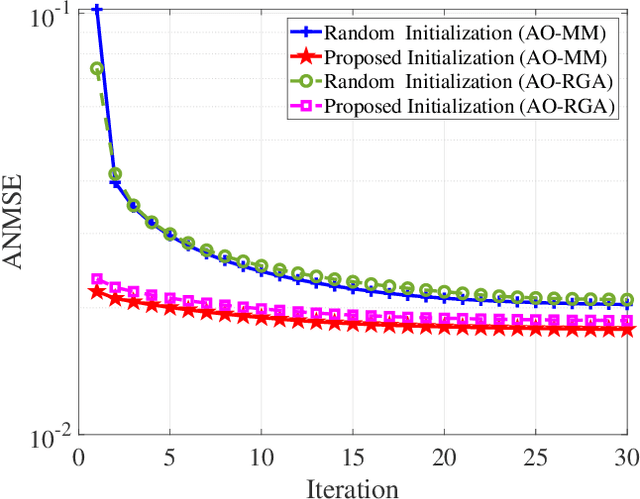
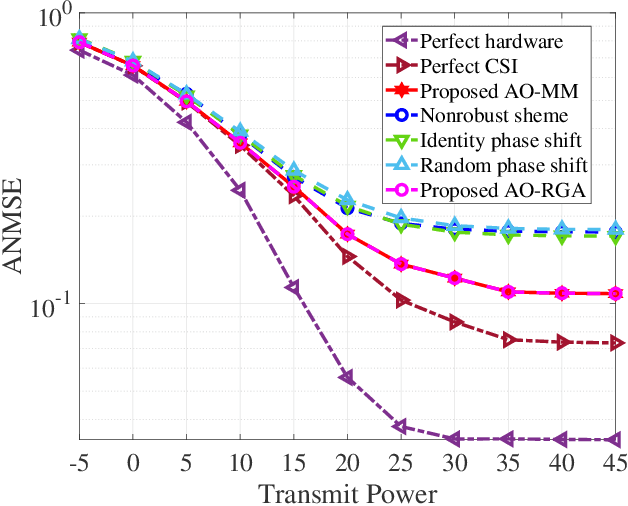
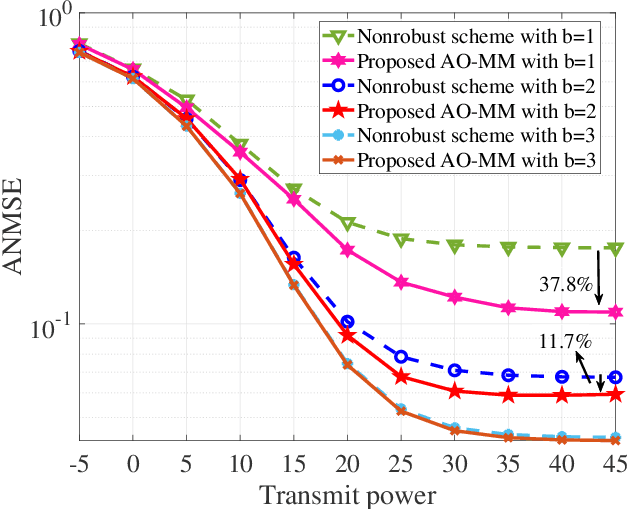
Reconfigurable intelligent surface (RIS) has been anticipated to be a novel cost-effective technology to improve the performance of future wireless systems. In this paper, we investigate a practical RIS-aided multiple-input-multiple-output (MIMO) system in the presence of transceiver hardware impairments, RIS phase noise and imperfect channel state information (CSI). Joint design of the MIMO transceiver and RIS reflection matrix to minimize the total average mean-square-error (MSE) of all data streams is particularly considered. This joint design problem is non-convex and challenging to solve due to the newly considered practical imperfections. To tackle the issue, we first analyze the total average MSE by incorporating the impacts of the above system imperfections. Then, in order to handle the tightly coupled optimization variables and non-convex NP-hard constraints, an efficient iterative algorithm based on alternating optimization (AO) framework is proposed with guaranteed convergence, where each subproblem admits a closed-form optimal solution by leveraging the majorization-minimization (MM) technique. Moreover, via exploiting the special structure of the unit-modulus constraints, we propose a modified Riemannian gradient ascent (RGA) algorithm for the discrete RIS phase shift optimization. Furthermore, the optimality of the proposed algorithm is validated under line-of-sight (LoS) channel conditions, and the irreducible MSE floor effect induced by imperfections of both hardware and CSI is also revealed in the high signal-to-noise ratio (SNR) regime. Numerical results show the superior MSE performance of our proposed algorithm over the adopted benchmark schemes, and demonstrate that increasing the number of RIS elements is not always beneficial under the above system imperfections.
Towards Proper Contrastive Self-supervised Learning Strategies For Music Audio Representation
Jul 10, 2022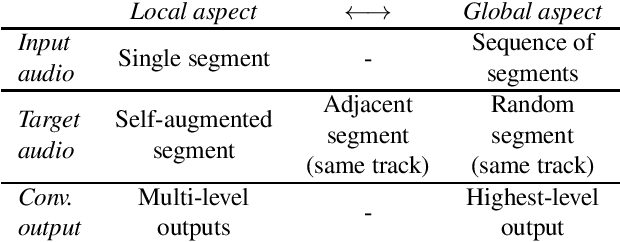

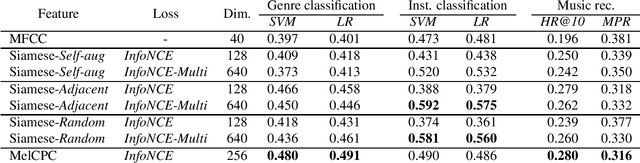
The common research goal of self-supervised learning is to extract a general representation which an arbitrary downstream task would benefit from. In this work, we investigate music audio representation learned from different contrastive self-supervised learning schemes and empirically evaluate the embedded vectors on various music information retrieval (MIR) tasks where different levels of the music perception are concerned. We analyze the results to discuss the proper direction of contrastive learning strategies for different MIR tasks. We show that these representations convey a comprehensive information about the auditory characteristics of music in general, although each of the self-supervision strategies has its own effectiveness in certain aspect of information.
Infusing Future Information into Monotonic Attention Through Language Models
Sep 07, 2021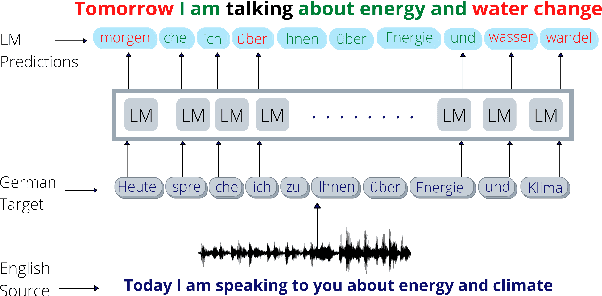

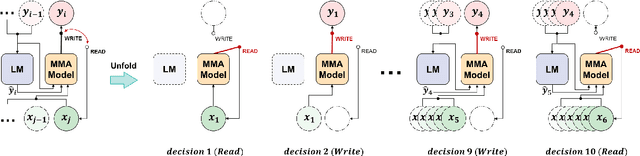
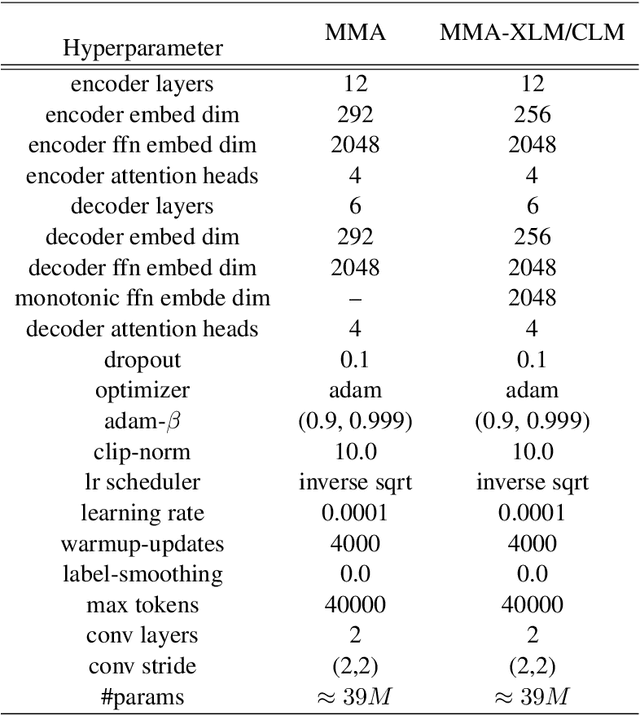
Simultaneous neural machine translation(SNMT) models start emitting the target sequence before they have processed the source sequence. The recent adaptive policies for SNMT use monotonic attention to perform read/write decisions based on the partial source and target sequences. The lack of sufficient information might cause the monotonic attention to take poor read/write decisions, which in turn negatively affects the performance of the SNMT model. On the other hand, human translators make better read/write decisions since they can anticipate the immediate future words using linguistic information and domain knowledge.Motivated by human translators, in this work, we propose a framework to aid monotonic attention with an external language model to improve its decisions.We conduct experiments on the MuST-C English-German and English-French speech-to-text translation tasks to show the effectiveness of the proposed framework.The proposed SNMT method improves the quality-latency trade-off over the state-of-the-art monotonic multihead attention.
On Curating Responsible and Representative Healthcare Video Recommendations for Patient Education and Health Literacy: An Augmented Intelligence Approach
Jul 13, 2022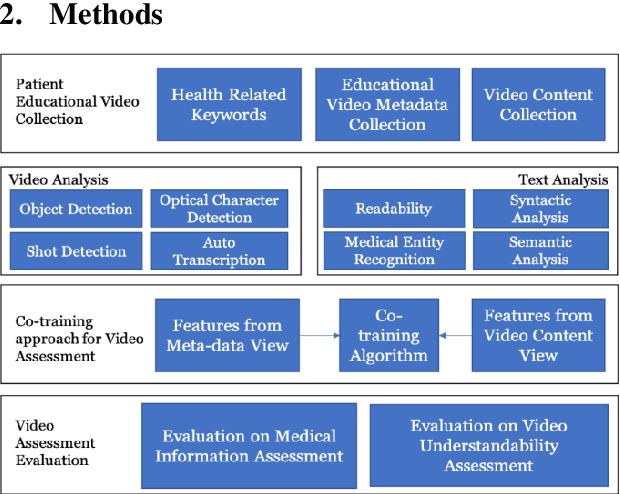
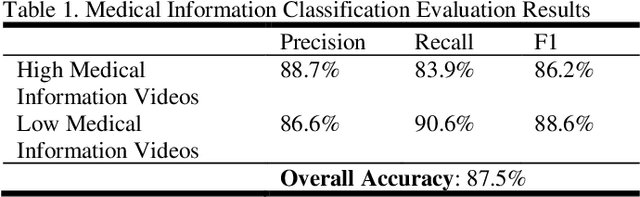
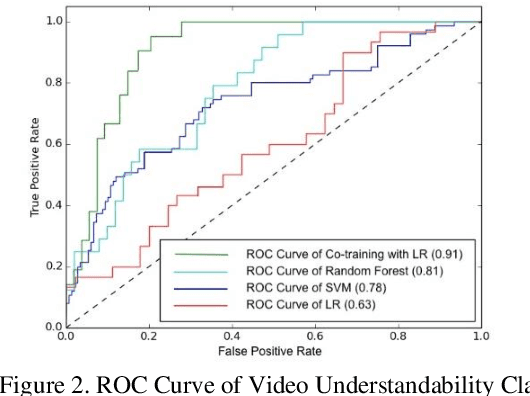
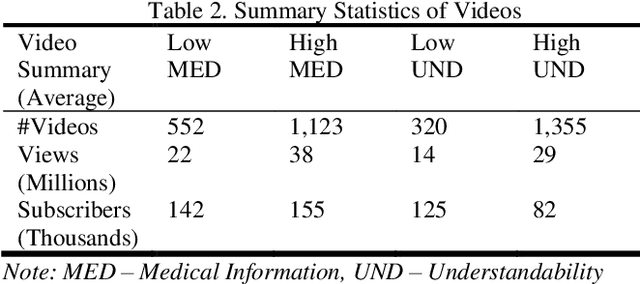
Studies suggest that one in three US adults use the Internet to diagnose or learn about a health concern. However, such access to health information online could exacerbate the disparities in health information availability and use. Health information seeking behavior (HISB) refers to the ways in which individuals seek information about their health, risks, illnesses, and health-protective behaviors. For patients engaging in searches for health information on digital media platforms, health literacy divides can be exacerbated both by their own lack of knowledge and by algorithmic recommendations, with results that disproportionately impact disadvantaged populations, minorities, and low health literacy users. This study reports on an exploratory investigation of the above challenges by examining whether responsible and representative recommendations can be generated using advanced analytic methods applied to a large corpus of videos and their metadata on a chronic condition (diabetes) from the YouTube social media platform. The paper focusses on biases associated with demographic characters of actors using videos on diabetes that were retrieved and curated for multiple criteria such as encoded medical content and their understandability to address patient education and population health literacy needs. This approach offers an immense opportunity for innovation in human-in-the-loop, augmented-intelligence, bias-aware and responsible algorithmic recommendations by combining the perspectives of health professionals and patients into a scalable and generalizable machine learning framework for patient empowerment and improved health outcomes.
Hierarchical Interdisciplinary Topic Detection Model for Research Proposal Classification
Sep 16, 2022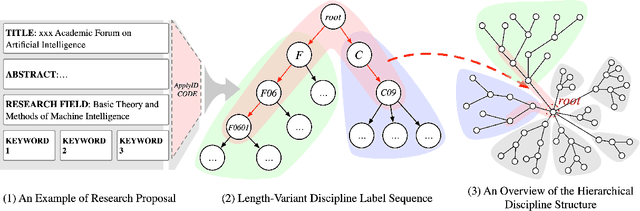
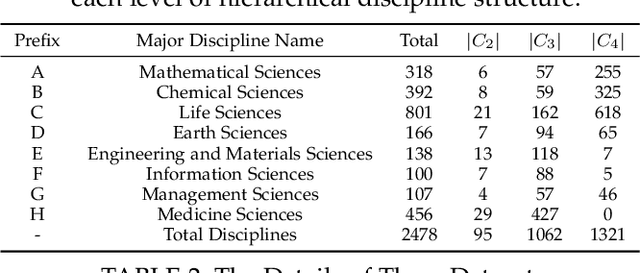
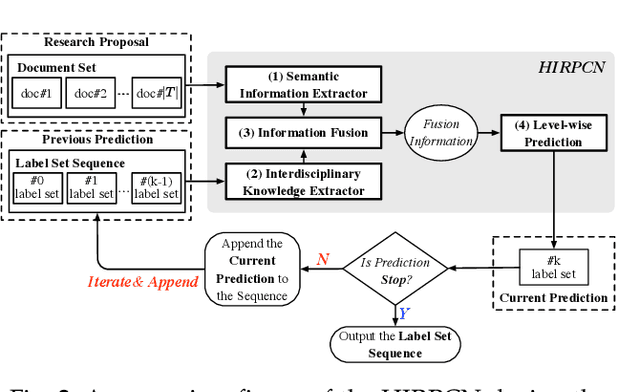
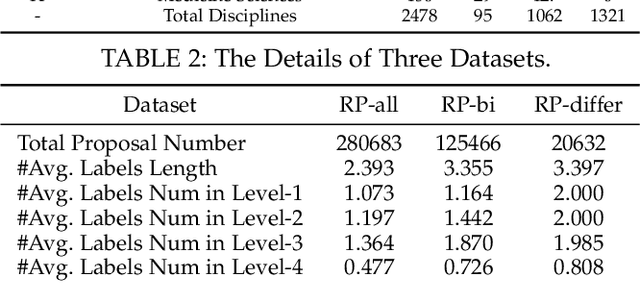
The peer merit review of research proposals has been the major mechanism for deciding grant awards. However, research proposals have become increasingly interdisciplinary. It has been a longstanding challenge to assign interdisciplinary proposals to appropriate reviewers, so proposals are fairly evaluated. One of the critical steps in reviewer assignment is to generate accurate interdisciplinary topic labels for proposal-reviewer matching. Existing systems mainly collect topic labels manually generated by principal investigators. However, such human-reported labels can be non-accurate, incomplete, labor intensive, and time costly. What role can AI play in developing a fair and precise proposal reviewer assignment system? In this study, we collaborate with the National Science Foundation of China to address the task of automated interdisciplinary topic path detection. For this purpose, we develop a deep Hierarchical Interdisciplinary Research Proposal Classification Network (HIRPCN). Specifically, we first propose a hierarchical transformer to extract the textual semantic information of proposals. We then design an interdisciplinary graph and leverage GNNs for learning representations of each discipline in order to extract interdisciplinary knowledge. After extracting the semantic and interdisciplinary knowledge, we design a level-wise prediction component to fuse the two types of knowledge representations and detect interdisciplinary topic paths for each proposal. We conduct extensive experiments and expert evaluations on three real-world datasets to demonstrate the effectiveness of our proposed model.
Lightweight Long-Range Generative Adversarial Networks
Sep 08, 2022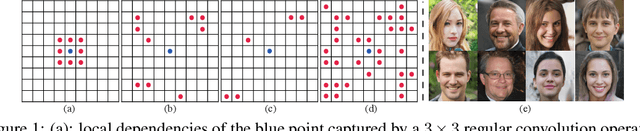
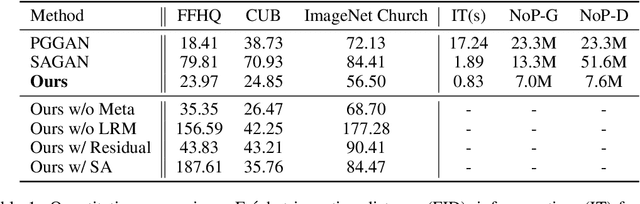
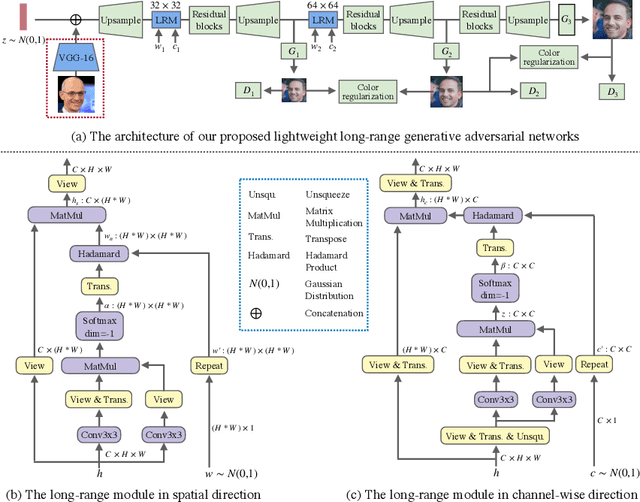

In this paper, we introduce novel lightweight generative adversarial networks, which can effectively capture long-range dependencies in the image generation process, and produce high-quality results with a much simpler architecture. To achieve this, we first introduce a long-range module, allowing the network to dynamically adjust the number of focused sampling pixels and to also augment sampling locations. Thus, it can break the limitation of the fixed geometric structure of the convolution operator, and capture long-range dependencies in both spatial and channel-wise directions. Also, the proposed long-range module can highlight negative relations between pixels, working as a regularization to stabilize training. Furthermore, we propose a new generation strategy through which we introduce metadata into the image generation process to provide basic information about target images, which can stabilize and speed up the training process. Our novel long-range module only introduces few additional parameters and is easily inserted into existing models to capture long-range dependencies. Extensive experiments demonstrate the competitive performance of our method with a lightweight architecture.
Joint User and Data Detection in Grant-Free NOMA with Attention-based BiLSTM Network
Sep 14, 2022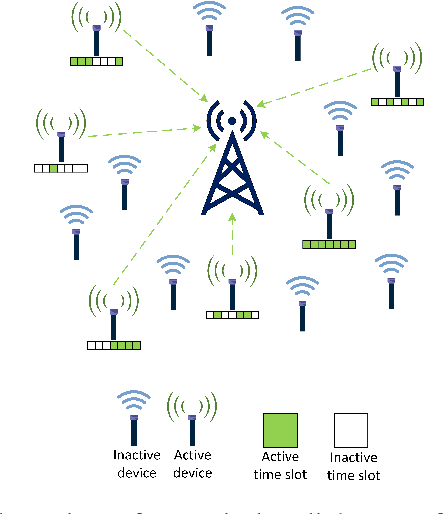
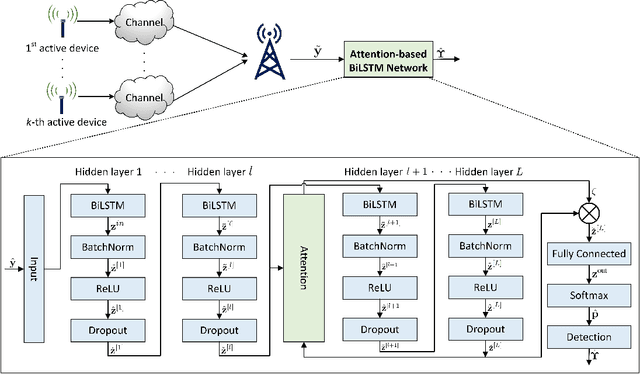
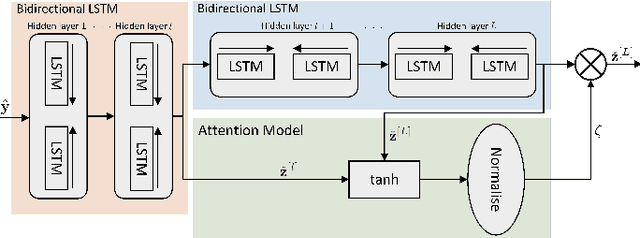
We consider the multi-user detection (MUD) problem in uplink grant-free non-orthogonal multiple access (NOMA), where the access point has to identify the total number and correct identity of the active Internet of Things (IoT) devices and decode their transmitted data. We assume that IoT devices use complex spreading sequences and transmit information in a random-access manner following the burst-sparsity model, where some IoT devices transmit their data in multiple adjacent time slots with a high probability, while others transmit only once during a frame. Exploiting the temporal correlation, we propose an attention-based bidirectional long short-term memory (BiLSTM) network to solve the MUD problem. The BiLSTM network creates a pattern of the device activation history using forward and reverse pass LSTMs, whereas the attention mechanism provides essential context to the device activation points. By doing so, a hierarchical pathway is followed for detecting active devices in a grant-free scenario. Then, by utilising the complex spreading sequences, blind data detection for the estimated active devices is performed. The proposed framework does not require prior knowledge of device sparsity levels and channels for performing MUD. The results show that the proposed network achieves better performance compared to existing benchmark schemes.