 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Privacy-Preserving Distributed Optimization and Learning
Feb 29, 2024
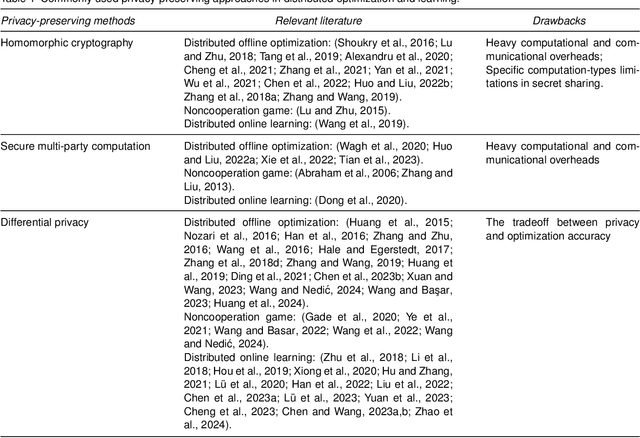
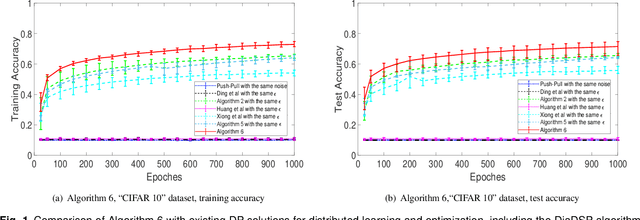
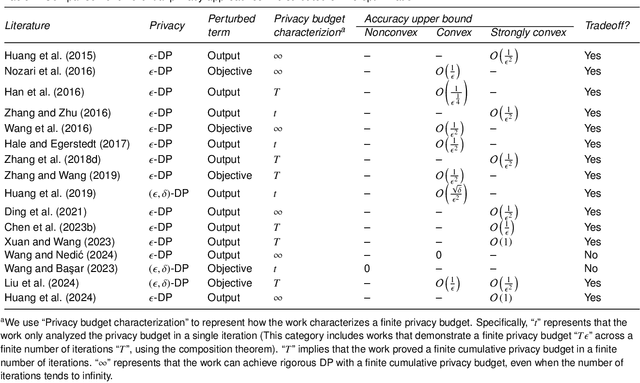

Distributed optimization and learning has recently garnered great attention due to its wide applications in sensor networks, smart grids, machine learning, and so forth. Despite rapid development, existing distributed optimization and learning algorithms require each agent to exchange messages with its neighbors, which may expose sensitive information and raise significant privacy concerns. In this survey paper, we overview privacy-preserving distributed optimization and learning methods. We first discuss cryptography, differential privacy, and other techniques that can be used for privacy preservation and indicate their pros and cons for privacy protection in distributed optimization and learning. We believe that among these approaches, differential privacy is most promising due to its low computational and communication complexities, which are extremely appealing for modern learning based applications with high dimensions of optimization variables. We then introduce several differential-privacy algorithms that can simultaneously ensure privacy and optimization accuracy. Moreover, we provide example applications in several machine learning problems to confirm the real-world effectiveness of these algorithms. Finally, we highlight some challenges in this research domain and discuss future directions.
Towards Explaining Deep Neural Network Compression Through a Probabilistic Latent Space
Feb 29, 2024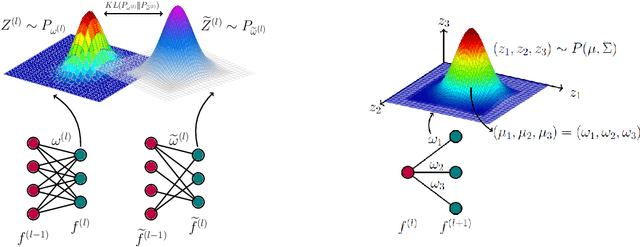
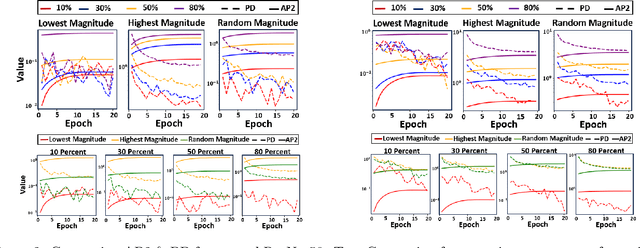
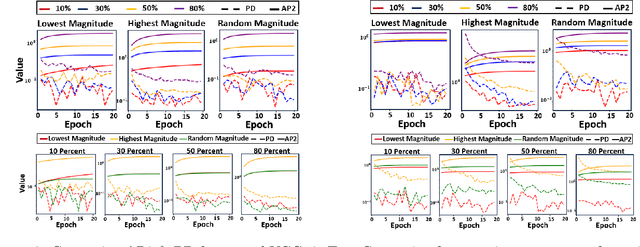
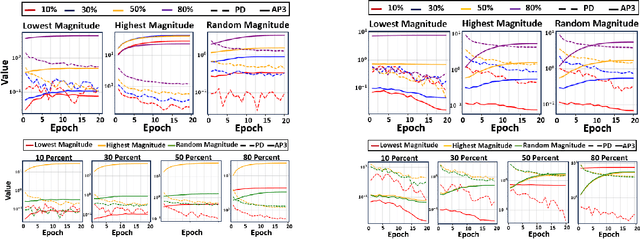
Despite the impressive performance of deep neural networks (DNNs), their computational complexity and storage space consumption have led to the concept of network compression. While DNN compression techniques such as pruning and low-rank decomposition have been extensively studied, there has been insufficient attention paid to their theoretical explanation. In this paper, we propose a novel theoretical framework that leverages a probabilistic latent space of DNN weights and explains the optimal network sparsity by using the information-theoretic divergence measures. We introduce new analogous projected patterns (AP2) and analogous-in-probability projected patterns (AP3) notions for DNNs and prove that there exists a relationship between AP3/AP2 property of layers in the network and its performance. Further, we provide a theoretical analysis that explains the training process of the compressed network. The theoretical results are empirically validated through experiments conducted on standard pre-trained benchmarks, including AlexNet, ResNet50, and VGG16, using CIFAR10 and CIFAR100 datasets. Through our experiments, we highlight the relationship of AP3 and AP2 properties with fine-tuning pruned DNNs and sparsity levels.
GEM3D: GEnerative Medial Abstractions for 3D Shape Synthesis
Feb 26, 2024We introduce GEM3D -- a new deep, topology-aware generative model of 3D shapes. The key ingredient of our method is a neural skeleton-based representation encoding information on both shape topology and geometry. Through a denoising diffusion probabilistic model, our method first generates skeleton-based representations following the Medial Axis Transform (MAT), then generates surfaces through a skeleton-driven neural implicit formulation. The neural implicit takes into account the topological and geometric information stored in the generated skeleton representations to yield surfaces that are more topologically and geometrically accurate compared to previous neural field formulations. We discuss applications of our method in shape synthesis and point cloud reconstruction tasks, and evaluate our method both qualitatively and quantitatively. We demonstrate significantly more faithful surface reconstruction and diverse shape generation results compared to the state-of-the-art, also involving challenging scenarios of reconstructing and synthesizing structurally complex, high-genus shape surfaces from Thingi10K and ShapeNet.
RetrievalQA: Assessing Adaptive Retrieval-Augmented Generation for Short-form Open-Domain Question Answering
Feb 26, 2024Adaptive retrieval-augmented generation (ARAG) aims to dynamically determine the necessity of retrieval for queries instead of retrieving indiscriminately to enhance the efficiency and relevance of the sourced information. However, previous works largely overlook the evaluation of ARAG approaches, leading to their effectiveness being understudied. This work presents a benchmark, RetrievalQA, comprising 1,271 short-form questions covering new world and long-tail knowledge. The knowledge necessary to answer the questions is absent from LLMs; therefore, external information must be retrieved to answer correctly. This makes RetrievalQA a suitable testbed to evaluate existing ARAG methods. We observe that calibration-based methods heavily rely on threshold tuning, while vanilla prompting is inadequate for guiding LLMs to make reliable retrieval decisions. Based on our findings, we propose Time-Aware Adaptive Retrieval (TA-ARE), a simple yet effective method that helps LLMs assess the necessity of retrieval without calibration or additional training. The dataset and code will be available at \url{https://github.com/hyintell/RetrievalQA}
More Than Routing: Joint GPS and Route Modeling for Refine Trajectory Representation Learning
Feb 25, 2024Trajectory representation learning plays a pivotal role in supporting various downstream tasks. Traditional methods in order to filter the noise in GPS trajectories tend to focus on routing-based methods used to simplify the trajectories. However, this approach ignores the motion details contained in the GPS data, limiting the representation capability of trajectory representation learning. To fill this gap, we propose a novel representation learning framework that Joint GPS and Route Modelling based on self-supervised technology, namely JGRM. We consider GPS trajectory and route as the two modes of a single movement observation and fuse information through inter-modal information interaction. Specifically, we develop two encoders, each tailored to capture representations of route and GPS trajectories respectively. The representations from the two modalities are fed into a shared transformer for inter-modal information interaction. Eventually, we design three self-supervised tasks to train the model. We validate the effectiveness of the proposed method on two real datasets based on extensive experiments. The experimental results demonstrate that JGRM outperforms existing methods in both road segment representation and trajectory representation tasks. Our source code is available at Anonymous Github.
Social Media as a Sensor: Analyzing Twitter Data for Breast Cancer Medication Effects Using Natural Language Processing
Feb 26, 2024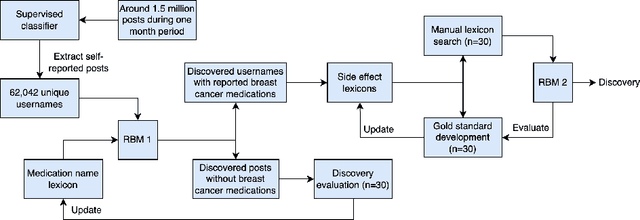
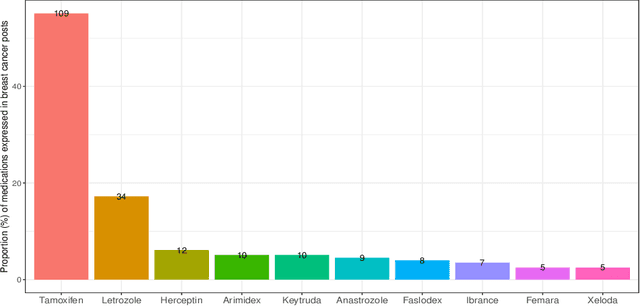
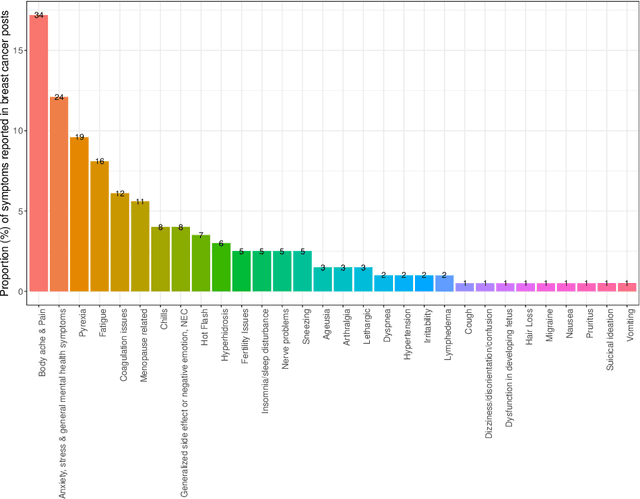
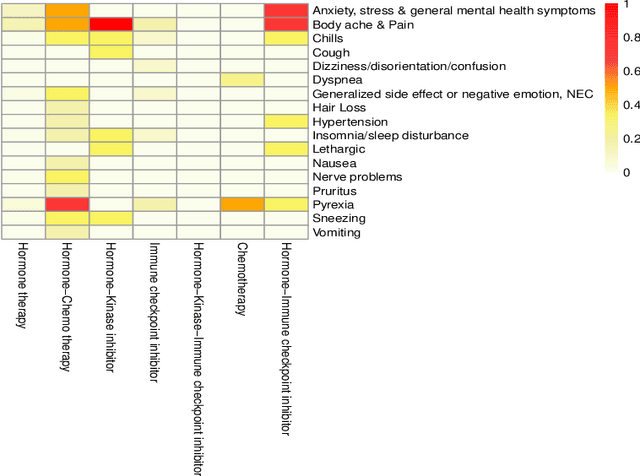
Breast cancer is a significant public health concern and is the leading cause of cancer-related deaths among women. Despite advances in breast cancer treatments, medication non-adherence remains a major problem. As electronic health records do not typically capture patient-reported outcomes that may reveal information about medication-related experiences, social media presents an attractive resource for enhancing our understanding of the patients' treatment experiences. In this paper, we developed natural language processing (NLP) based methodologies to study information posted by an automatically curated breast cancer cohort from social media. We employed a transformer-based classifier to identify breast cancer patients/survivors on X (Twitter) based on their self-reported information, and we collected longitudinal data from their profiles. We then designed a multi-layer rule-based model to develop a breast cancer therapy-associated side effect lexicon and detect patterns of medication usage and associated side effects among breast cancer patients. 1,454,637 posts were available from 583,962 unique users, of which 62,042 were detected as breast cancer members using our transformer-based model. 198 cohort members mentioned breast cancer medications with tamoxifen as the most common. Our side effect lexicon identified well-known side effects of hormone and chemotherapy. Furthermore, it discovered a subject feeling towards cancer and medications, which may suggest a pre-clinical phase of side effects or emotional distress. This analysis highlighted not only the utility of NLP techniques in unstructured social media data to identify self-reported breast cancer posts, medication usage patterns, and treatment side effects but also the richness of social data on such clinical questions.
MultiContrievers: Analysis of Dense Retrieval Representations
Feb 24, 2024Dense retrievers compress source documents into (possibly lossy) vector representations, yet there is little analysis of what information is lost versus preserved, and how it affects downstream tasks. We conduct the first analysis of the information captured by dense retrievers compared to the language models they are based on (e.g., BERT versus Contriever). We use 25 MultiBert checkpoints as randomized initialisations to train MultiContrievers, a set of 25 contriever models. We test whether specific pieces of information -- such as gender and occupation -- can be extracted from contriever vectors of wikipedia-like documents. We measure this extractability via information theoretic probing. We then examine the relationship of extractability to performance and gender bias, as well as the sensitivity of these results to many random initialisations and data shuffles. We find that (1) contriever models have significantly increased extractability, but extractability usually correlates poorly with benchmark performance 2) gender bias is present, but is not caused by the contriever representations 3) there is high sensitivity to both random initialisation and to data shuffle, suggesting that future retrieval research should test across a wider spread of both.
A Heterogeneous Dynamic Convolutional Neural Network for Image Super-resolution
Feb 24, 2024Convolutional neural networks can automatically learn features via deep network architectures and given input samples. However, robustness of obtained models may have challenges in varying scenes. Bigger differences of a network architecture are beneficial to extract more complementary structural information to enhance robustness of an obtained super-resolution model. In this paper, we present a heterogeneous dynamic convolutional network in image super-resolution (HDSRNet). To capture more information, HDSRNet is implemented by a heterogeneous parallel network. The upper network can facilitate more contexture information via stacked heterogeneous blocks to improve effects of image super-resolution. Each heterogeneous block is composed of a combination of a dilated, dynamic, common convolutional layers, ReLU and residual learning operation. It can not only adaptively adjust parameters, according to different inputs, but also prevent long-term dependency problem. The lower network utilizes a symmetric architecture to enhance relations of different layers to mine more structural information, which is complementary with a upper network for image super-resolution. The relevant experimental results show that the proposed HDSRNet is effective to deal with image resolving. The code of HDSRNet can be obtained at https://github.com/hellloxiaotian/HDSRNet.
Embodied Supervision: Haptic Display of Automation Command to Improve Supervisory Performance
Feb 28, 2024A human operator using a manual control interface has ready access to their own command signal, both by efference copy and proprioception. In contrast, a human supervisor typically relies on visual information alone. We propose supplying a supervisor with a copy of the operators command signal, hypothesizing improved performance, especially when that copy is provided through haptic display. We experimentally compared haptic with visual access to the command signal, quantifying the performance of N equals 10 participants attempting to determine which of three reference signals was being tracked by an operator. Results indicate an improved accuracy in identifying the tracked target when haptic display was available relative to visual display alone. We conjecture the benefit follows from the relationship of haptics to the supervisor's own experience, perhaps muscle memory, as an operator.
Approaching Human-Level Forecasting with Language Models
Feb 28, 2024Forecasting future events is important for policy and decision making. In this work, we study whether language models (LMs) can forecast at the level of competitive human forecasters. Towards this goal, we develop a retrieval-augmented LM system designed to automatically search for relevant information, generate forecasts, and aggregate predictions. To facilitate our study, we collect a large dataset of questions from competitive forecasting platforms. Under a test set published after the knowledge cut-offs of our LMs, we evaluate the end-to-end performance of our system against the aggregates of human forecasts. On average, the system nears the crowd aggregate of competitive forecasters, and in some settings surpasses it. Our work suggests that using LMs to forecast the future could provide accurate predictions at scale and help to inform institutional decision making.