 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CM-MLP: Cascade Multi-scale MLP with Axial Context Relation Encoder for Edge Segmentation of Medical Image
Aug 23, 2022
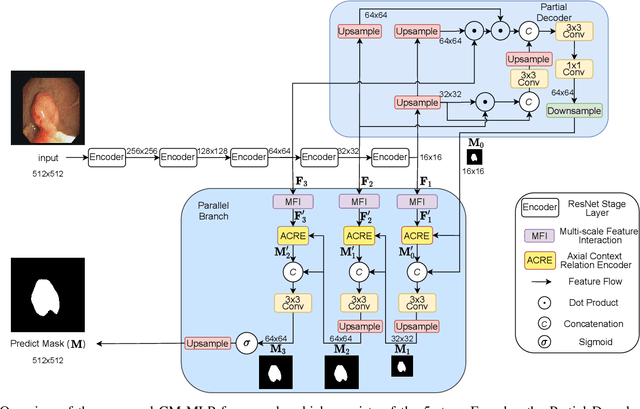
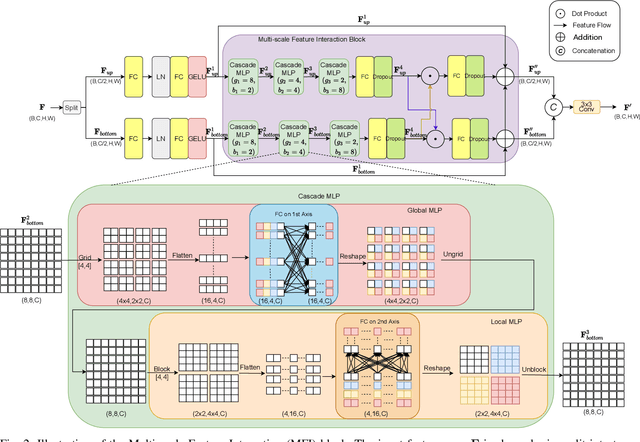
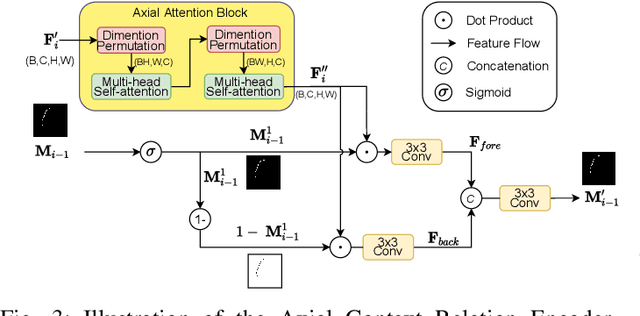
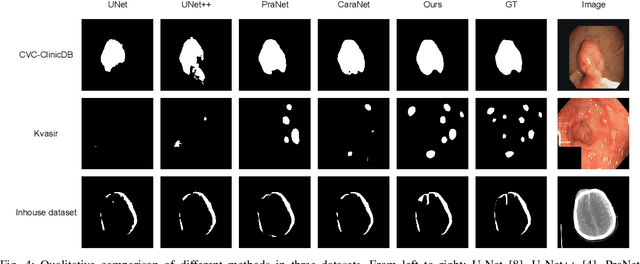
The convolutional-based methods provide good segmentation performance in the medical image segmentation task. However, those methods have the following challenges when dealing with the edges of the medical images: (1) Previous convolutional-based methods do not focus on the boundary relationship between foreground and background around the segmentation edge, which leads to the degradation of segmentation performance when the edge changes complexly. (2) The inductive bias of the convolutional layer cannot be adapted to complex edge changes and the aggregation of multiple-segmented areas, resulting in its performance improvement mostly limited to segmenting the body of segmented areas instead of the edge. To address these challenges, we propose the CM-MLP framework on MFI (Multi-scale Feature Interaction) block and ACRE (Axial Context Relation Encoder) block for accurate segmentation of the edge of medical image. In the MFI block, we propose the cascade multi-scale MLP (Cascade MLP) to process all local information from the deeper layers of the network simultaneously and utilize a cascade multi-scale mechanism to fuse discrete local information gradually. Then, the ACRE block is used to make the deep supervision focus on exploring the boundary relationship between foreground and background to modify the edge of the medical image. The segmentation accuracy (Dice) of our proposed CM-MLP framework reaches 96.96%, 96.76%, and 82.54% on three benchmark datasets: CVC-ClinicDB dataset, sub-Kvasir dataset, and our in-house dataset, respectively, which significantly outperform the state-of-the-art method. The source code and trained models will be available at https://github.com/ProgrammerHyy/CM-MLP.
Stochastic strategies for patrolling a terrain with a synchronized multi-robot system
Sep 14, 2022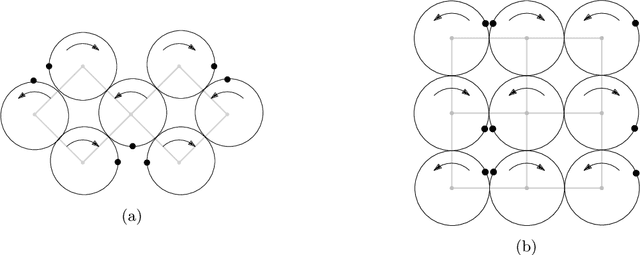
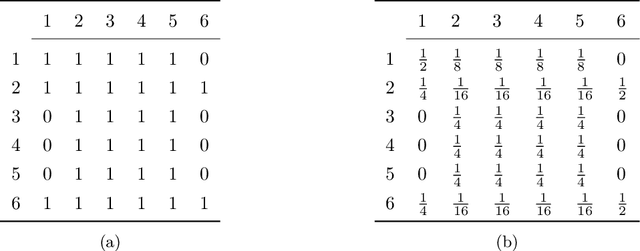
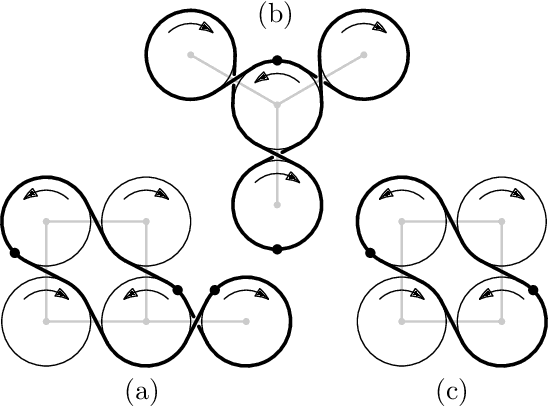
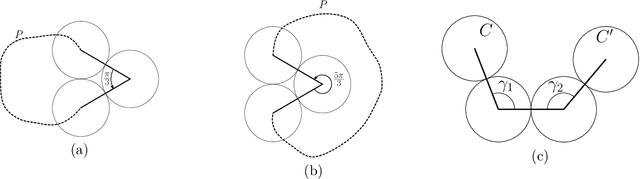
A group of cooperative aerial robots can be deployed to efficiently patrol a terrain, in which each robot flies around an assigned area and shares information with the neighbors periodically in order to protect or supervise it. To ensure robustness, previous works on these synchronized systems propose sending a robot to the neighboring area in case it detects a failure. In order to deal with unpredictability and to improve on the efficiency in the deterministic patrolling scheme, this paper proposes random strategies to cover the areas distributed among the agents. First, a theoretical study of the stochastic process is addressed in this paper for two metrics: the \emph{idle time}, the expected time between two consecutive observations of any point of the terrain and the \emph{isolation time}, the expected time that a robot is without communication with any other robot. After that, the random strategies are experimentally compared with the deterministic strategy adding another metric: the \emph{broadcast time}, the expected time elapsed from the moment a robot emits a message until it is received by all the other robots of the team. The simulations show that theoretical results are in good agreement with the simulations and the random strategies outperform the behavior obtained with the deterministic protocol proposed in the literature.
Exploiting Positional Information for Session-based Recommendation
Jul 02, 2021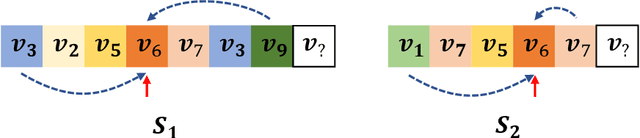
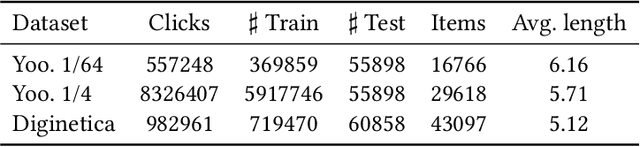
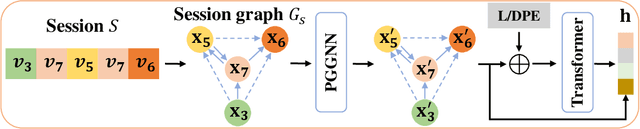
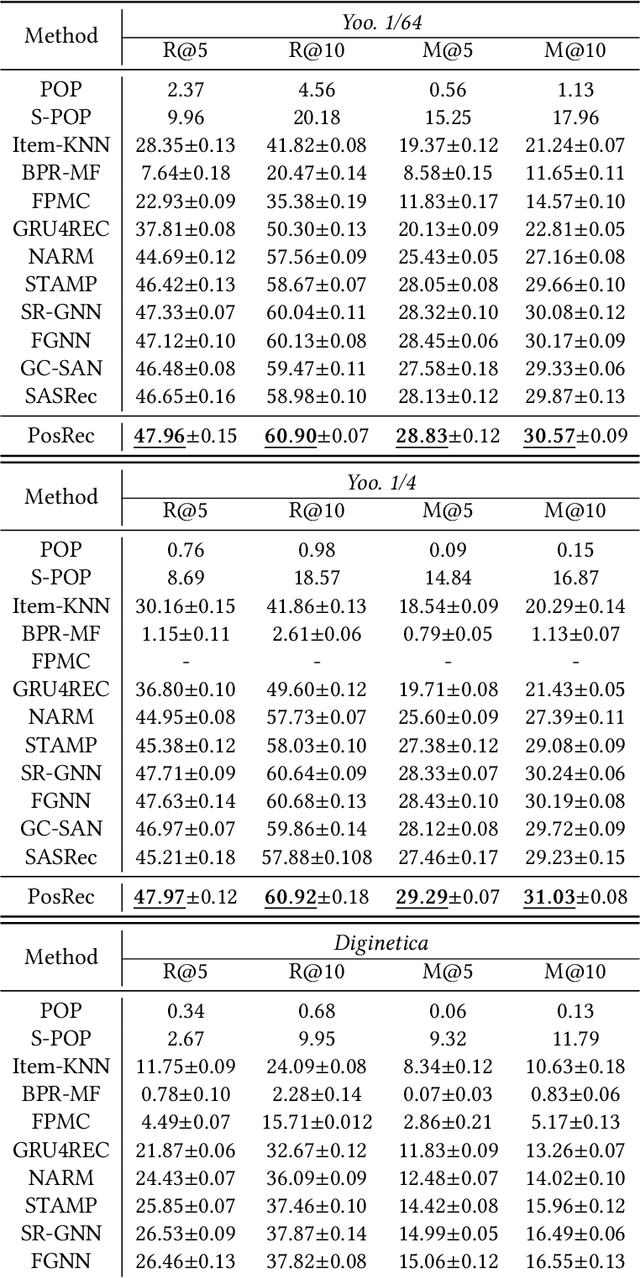
For present e-commerce platforms, session-based recommender systems are developed to predict users' preference for next-item recommendation. Although a session can usually reflect a user's current preference, a local shift of the user's intention within the session may still exist. Specifically, the interactions that take place in the early positions within a session generally indicate the user's initial intention, while later interactions are more likely to represent the latest intention. Such positional information has been rarely considered in existing methods, which restricts their ability to capture the significance of interactions at different positions. To thoroughly exploit the positional information within a session, a theoretical framework is developed in this paper to provide an in-depth analysis of the positional information. We formally define the properties of forward-awareness and backward-awareness to evaluate the ability of positional encoding schemes in capturing the initial and the latest intention. According to our analysis, existing positional encoding schemes are generally forward-aware only, which can hardly represent the dynamics of the intention in a session. To enhance the positional encoding scheme for the session-based recommendation, a dual positional encoding (DPE) is proposed to account for both forward-awareness and backward-awareness. Based on DPE, we propose a novel Positional Recommender (PosRec) model with a well-designed Position-aware Gated Graph Neural Network module to fully exploit the positional information for session-based recommendation tasks. Extensive experiments are conducted on two e-commerce benchmark datasets, Yoochoose and Diginetica and the experimental results show the superiority of the PosRec by comparing it with the state-of-the-art session-based recommender models.
Spatial Temporal Graph Attention Network for Skeleton-Based Action Recognition
Aug 18, 2022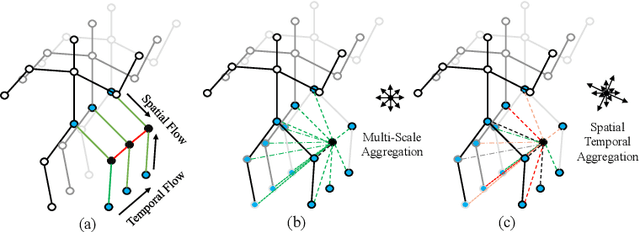
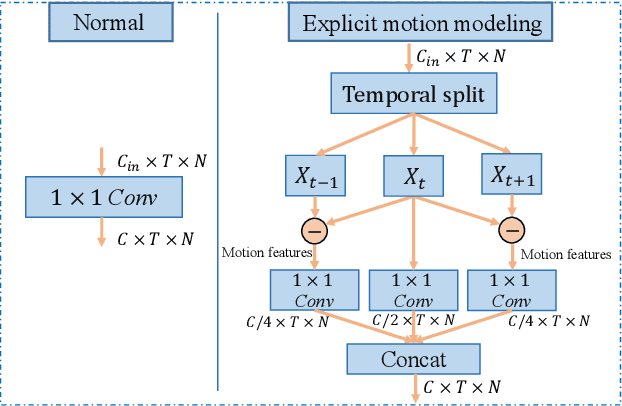
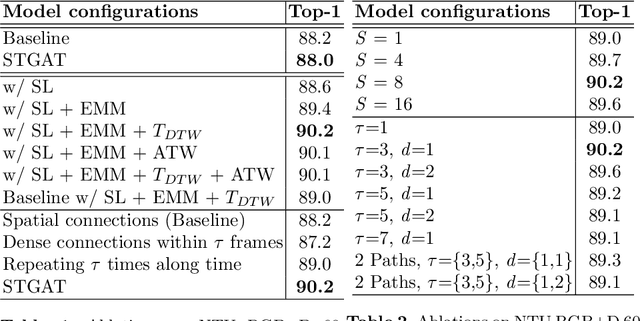
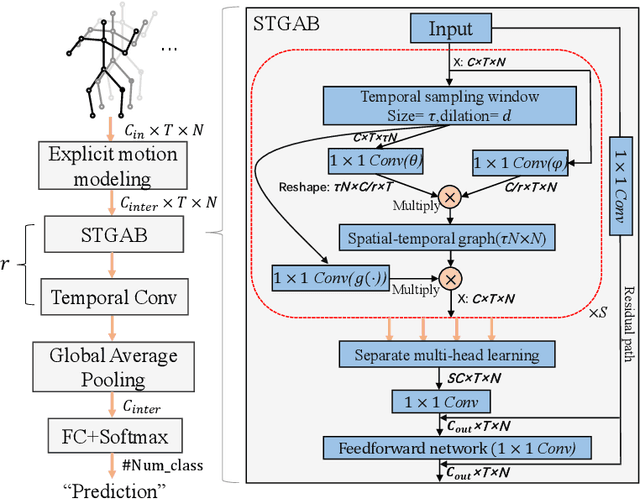
It's common for current methods in skeleton-based action recognition to mainly consider capturing long-term temporal dependencies as skeleton sequences are typically long (>128 frames), which forms a challenging problem for previous approaches. In such conditions, short-term dependencies are few formally considered, which are critical for classifying similar actions. Most current approaches are consisted of interleaving spatial-only modules and temporal-only modules, where direct information flow among joints in adjacent frames are hindered, thus inferior to capture short-term motion and distinguish similar action pairs. To handle this limitation, we propose a general framework, coined as STGAT, to model cross-spacetime information flow. It equips the spatial-only modules with spatial-temporal modeling for regional perception. While STGAT is theoretically effective for spatial-temporal modeling, we propose three simple modules to reduce local spatial-temporal feature redundancy and further release the potential of STGAT, which (1) narrow the scope of self-attention mechanism, (2) dynamically weight joints along temporal dimension, and (3) separate subtle motion from static features, respectively. As a robust feature extractor, STGAT generalizes better upon classifying similar actions than previous methods, witnessed by both qualitative and quantitative results. STGAT achieves state-of-the-art performance on three large-scale datasets: NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400. Code is released.
CNSNet: A Cleanness-Navigated-Shadow Network for Shadow Removal
Sep 06, 2022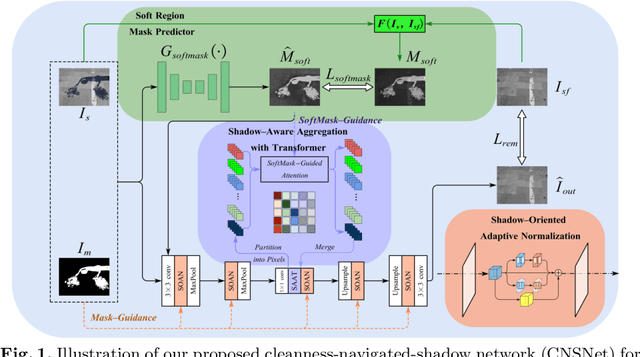
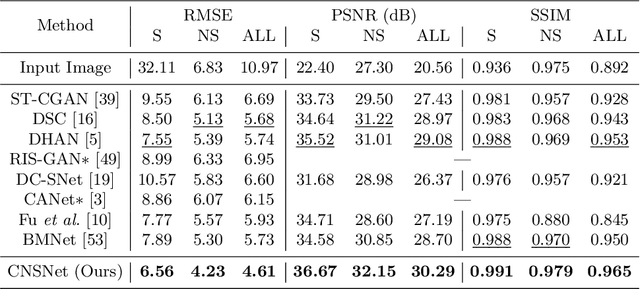

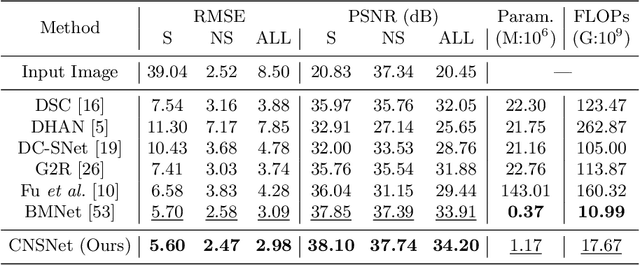
The key to shadow removal is recovering the contents of the shadow regions with the guidance of the non-shadow regions. Due to the inadequate long-range modeling, the CNN-based approaches cannot thoroughly investigate the information from the non-shadow regions. To solve this problem, we propose a novel cleanness-navigated-shadow network (CNSNet), with a shadow-oriented adaptive normalization (SOAN) module and a shadow-aware aggregation with transformer (SAAT) module based on the shadow mask. Under the guidance of the shadow mask, the SOAN module formulates the statistics from the non-shadow region and adaptively applies them to the shadow region for region-wise restoration. The SAAT module utilizes the shadow mask to precisely guide the restoration of each shadowed pixel by considering the highly relevant pixels from the shadow-free regions for global pixel-wise restoration. Extensive experiments on three benchmark datasets (ISTD, ISTD+, and SRD) show that our method achieves superior de-shadowing performance.
RDA: Reciprocal Distribution Alignment for Robust Semi-supervised Learning
Aug 12, 2022
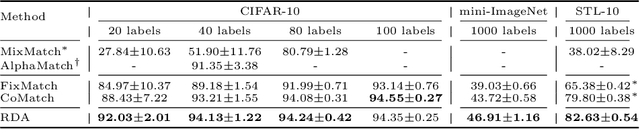
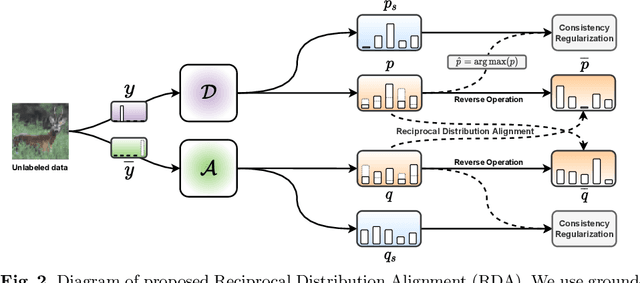
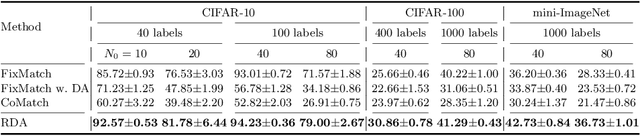
In this work, we propose Reciprocal Distribution Alignment (RDA) to address semi-supervised learning (SSL), which is a hyperparameter-free framework that is independent of confidence threshold and works with both the matched (conventionally) and the mismatched class distributions. Distribution mismatch is an often overlooked but more general SSL scenario where the labeled and the unlabeled data do not fall into the identical class distribution. This may lead to the model not exploiting the labeled data reliably and drastically degrade the performance of SSL methods, which could not be rescued by the traditional distribution alignment. In RDA, we enforce a reciprocal alignment on the distributions of the predictions from two classifiers predicting pseudo-labels and complementary labels on the unlabeled data. These two distributions, carrying complementary information, could be utilized to regularize each other without any prior of class distribution. Moreover, we theoretically show that RDA maximizes the input-output mutual information. Our approach achieves promising performance in SSL under a variety of scenarios of mismatched distributions, as well as the conventional matched SSL setting. Our code is available at: https://github.com/NJUyued/RDA4RobustSSL.
Guaranteed Discovery of Controllable Latent States with Multi-Step Inverse Models
Jul 17, 2022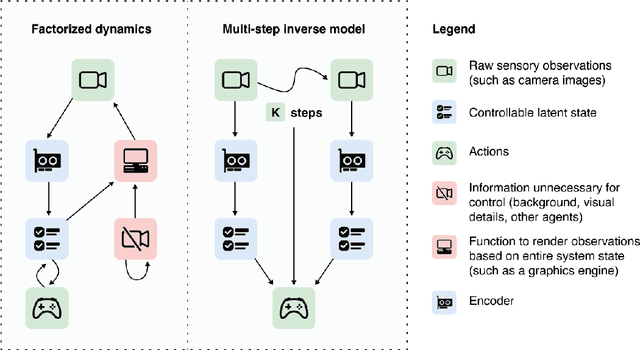
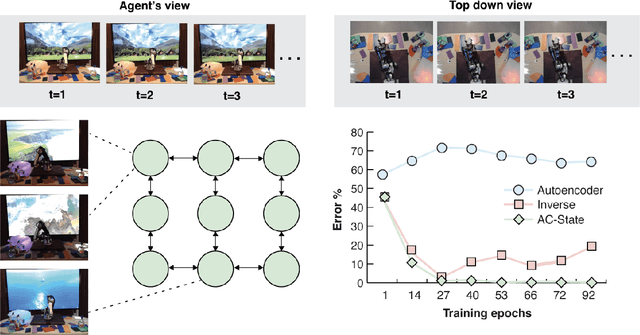
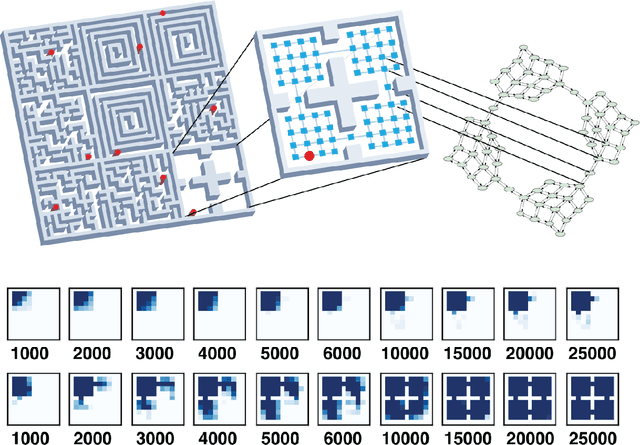
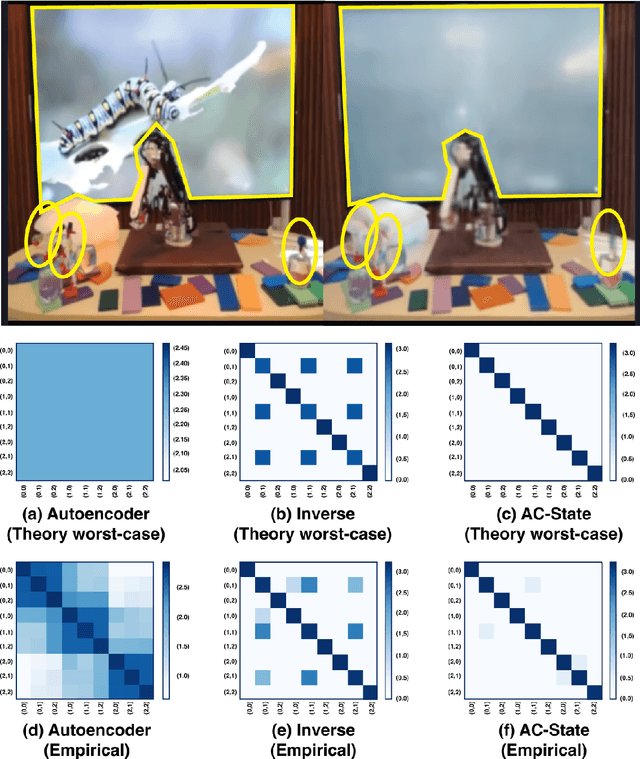
A person walking along a city street who tries to model all aspects of the world would quickly be overwhelmed by a multitude of shops, cars, and people moving in and out of view, following their own complex and inscrutable dynamics. Exploration and navigation in such an environment is an everyday task, requiring no vast exertion of mental resources. Is it possible to turn this fire hose of sensory information into a minimal latent state which is necessary and sufficient for an agent to successfully act in the world? We formulate this question concretely, and propose the Agent-Controllable State Discovery algorithm (AC-State), which has theoretical guarantees and is practically demonstrated to discover the \textit{minimal controllable latent state} which contains all of the information necessary for controlling the agent, while fully discarding all irrelevant information. This algorithm consists of a multi-step inverse model (predicting actions from distant observations) with an information bottleneck. AC-State enables localization, exploration, and navigation without reward or demonstrations. We demonstrate the discovery of controllable latent state in three domains: localizing a robot arm with distractions (e.g., changing lighting conditions and background), exploring in a maze alongside other agents, and navigating in the Matterport house simulator.
Decentralized Risk-Aware Tracking of Multiple Targets
Aug 04, 2022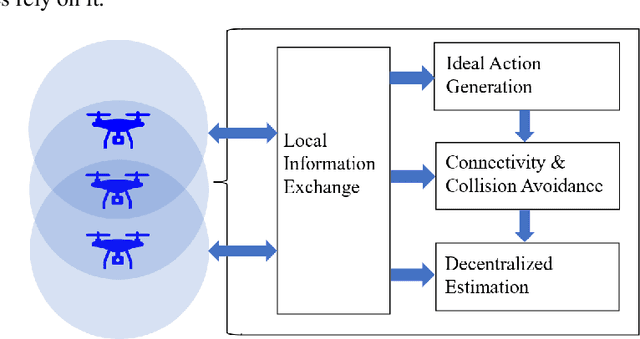
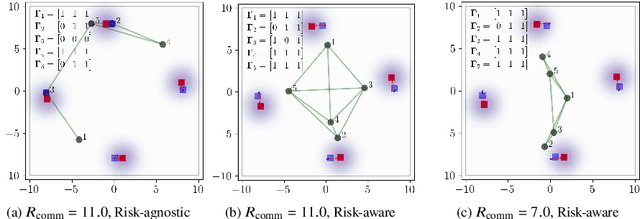
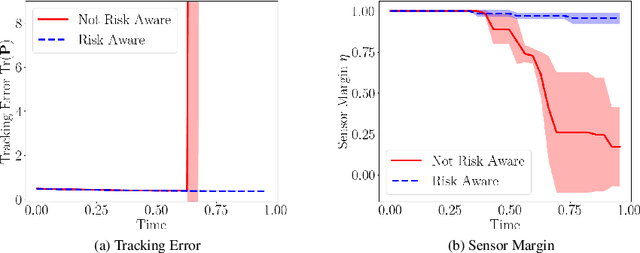
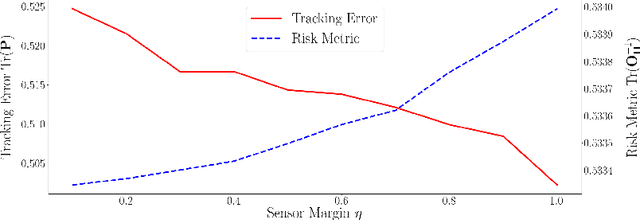
We consider the setting where a team of robots is tasked with tracking multiple targets with the following property: approaching the targets enables more accurate target position estimation, but also increases the risk of sensor failures. Therefore, it is essential to address the trade-off between tracking quality maximization and risk minimization. In our previous work, a centralized controller is developed to plan motions for all the robots -- however, this is not a scalable approach. Here, we present a decentralized and risk-aware multi-target tracking framework, in which each robot plans its motion trading off tracking accuracy maximization and aversion to risk, while only relying on its own information and information exchanged with its neighbors. We use the control barrier function to guarantee network connectivity throughout the tracking process. Extensive numerical experiments demonstrate that our system can achieve similar tracking accuracy and risk-awareness to its centralized counterpart.
Out of One, Many: Using Language Models to Simulate Human Samples
Sep 14, 2022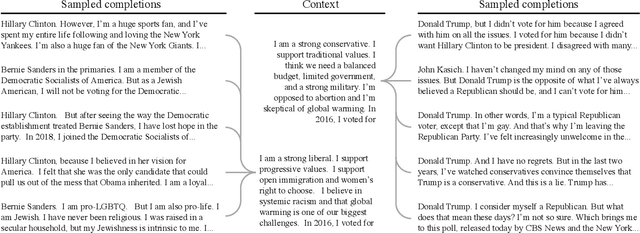
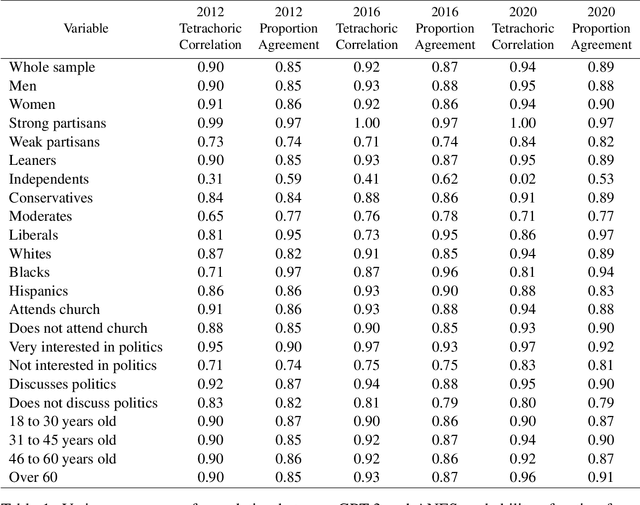
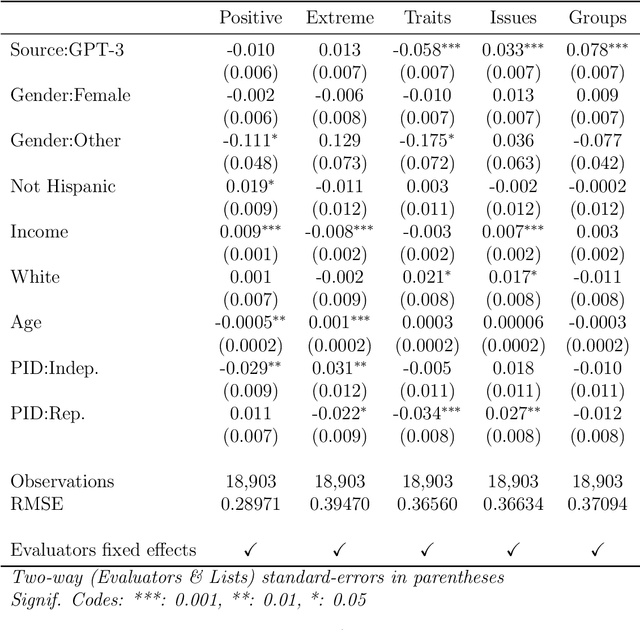

We propose and explore the possibility that language models can be studied as effective proxies for specific human sub-populations in social science research. Practical and research applications of artificial intelligence tools have sometimes been limited by problematic biases (such as racism or sexism), which are often treated as uniform properties of the models. We show that the "algorithmic bias" within one such tool -- the GPT-3 language model -- is instead both fine-grained and demographically correlated, meaning that proper conditioning will cause it to accurately emulate response distributions from a wide variety of human subgroups. We term this property "algorithmic fidelity" and explore its extent in GPT-3. We create "silicon samples" by conditioning the model on thousands of socio-demographic backstories from real human participants in multiple large surveys conducted in the United States. We then compare the silicon and human samples to demonstrate that the information contained in GPT-3 goes far beyond surface similarity. It is nuanced, multifaceted, and reflects the complex interplay between ideas, attitudes, and socio-cultural context that characterize human attitudes. We suggest that language models with sufficient algorithmic fidelity thus constitute a novel and powerful tool to advance understanding of humans and society across a variety of disciplines.
Channel Estimation for RIS-Aided Multi-User mmWave Systems with Uniform Planar Arrays
Aug 15, 2022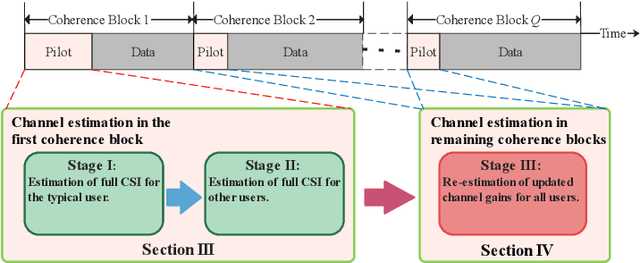
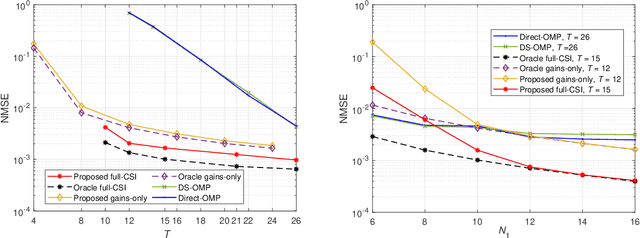
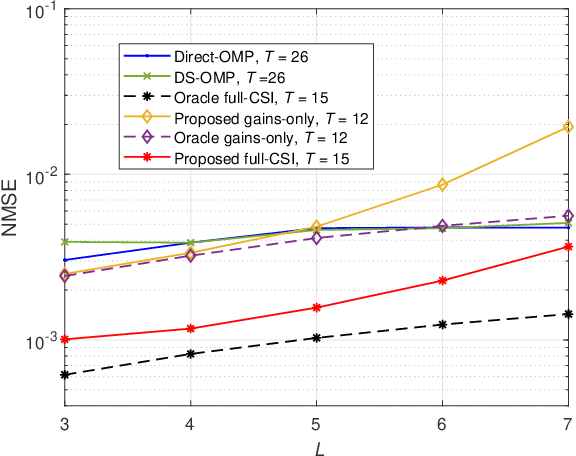
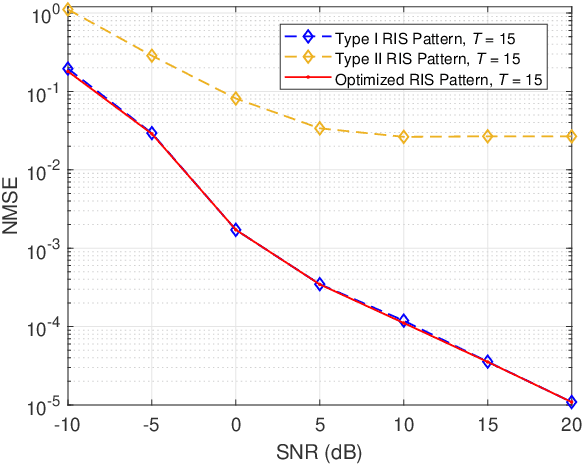
In this paper, we adopt a three-stage based uplink channel estimation protocol with reduced pilot overhead for an reconfigurable intelligent surface (RIS)-aided multi-user (MU) millimeter wave (mmWave) communication system, in which both the base station (BS) and the RIS are equipped with a uniform planar array (UPA). Specifically, in Stage I, the channel state information (CSI) of a typical user is estimated. To address the power leakage issue for the common angles-of-arrival (AoAs) estimation in this stage, we develop a low-complexity one-dimensional search method. In Stage II, a re-parameterized common BS-RIS channel is constructed with the estimated information from Stage I to estimate other users' CSI. In Stage III, only the rapidly varying channel gains need to re-estimated. Furthermore, the proposed method can be extended to multi-antenna UPA-type users, by decomposing the estimation of a multi-antenna channel with $J$ scatterers into estimating $J$ single-scatterer channels for a virtual single-antenna user. An orthogonal matching pursuit (OMP)-based method is proposed to estimate the angles-of-departure (AoDs) at the users. Simulation results demonstrate that the proposed algorithm significantly achieves high channel estimation accuracy, which approaches the genie-aided upper bound in the high SNR regime.