 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Aggretriever: A Simple Approach to Aggregate Textual Representation for Robust Dense Passage Retrieval
Jul 31, 2022
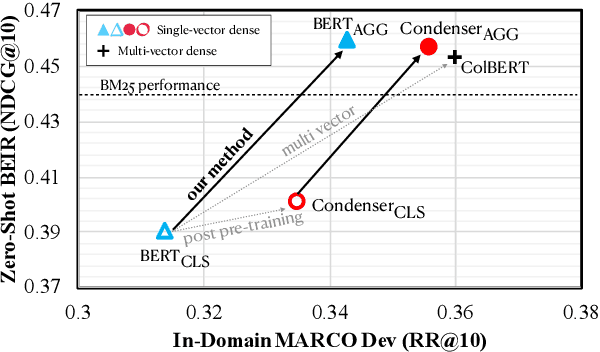
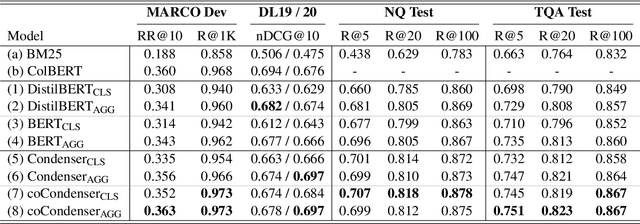
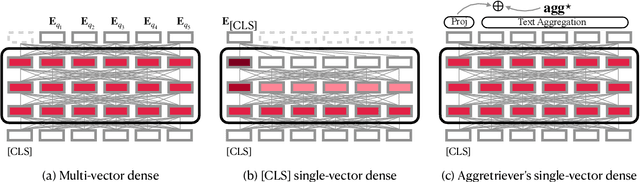
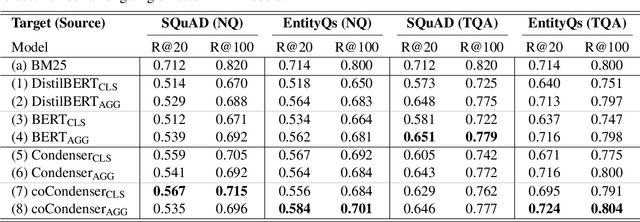
Pre-trained transformers has declared its success in many NLP tasks. One thread of work focuses on training bi-encoder models (i.e., dense retrievers) to effectively encode sentences or passages into single-vector dense vectors for efficient approximate nearest neighbor (ANN) search. However, recent work has demonstrated that transformers pre-trained with mask language modeling (MLM) are not capable of effectively aggregating text information into a single dense vector due to task-mismatch between pre-training and fine-tuning. Therefore, computationally expensive techniques have been adopted to train dense retrievers, such as large batch size, knowledge distillation or post pre-training. In this work, we present a simple approach to effectively aggregate textual representation from the pre-trained transformer into a dense vector. Extensive experiments show that our approach improves the robustness of the single-vector approach under both in-domain and zero-shot evaluations without any computationally expensive training techniques. Our work demonstrates that MLM pre-trained transformers can be used to effectively encode text information into a single-vector for dense retrieval. Code are available at: https://github.com/castorini/dhr
Invariant Information Bottleneck for Domain Generalization
Jun 14, 2021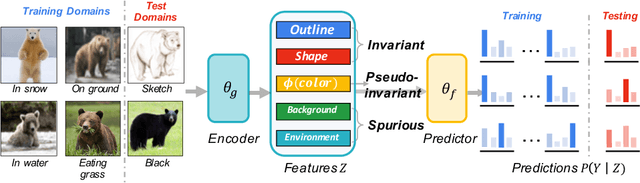
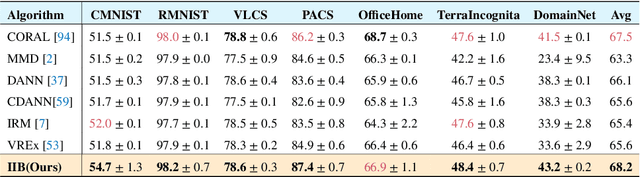
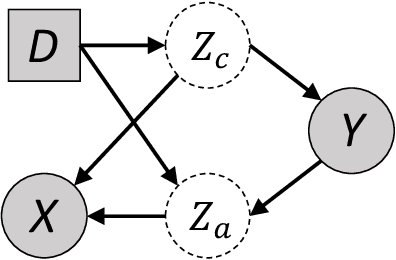
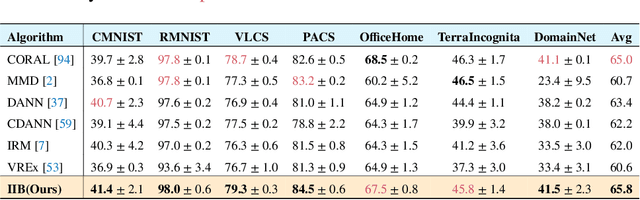
The main challenge for domain generalization (DG) is to overcome the potential distributional shift between multiple training domains and unseen test domains. One popular class of DG algorithms aims to learn representations that have an invariant causal relation across the training domains. However, certain features, called \emph{pseudo-invariant features}, may be invariant in the training domain but not the test domain and can substantially decreases the performance of existing algorithms. To address this issue, we propose a novel algorithm, called Invariant Information Bottleneck (IIB), that learns a minimally sufficient representation that is invariant across training and testing domains. By minimizing the mutual information between the representation and inputs, IIB alleviates its reliance on pseudo-invariant features, which is desirable for DG. To verify the effectiveness of the IIB principle, we conduct extensive experiments on large-scale DG benchmarks. The results show that IIB outperforms invariant learning baseline (e.g. IRM) by an average of 2.8\% and 3.8\% accuracy over two evaluation metrics.
Over-the-Air Computation with Multiple Receivers: A Space-Time Approach
Aug 24, 2022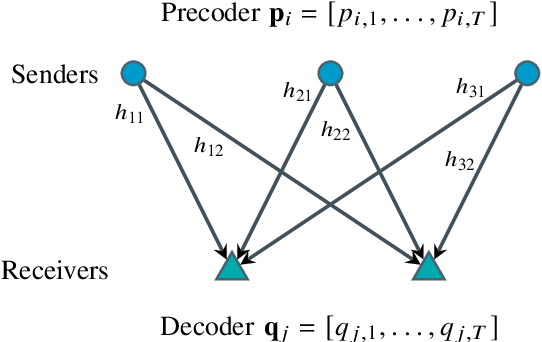
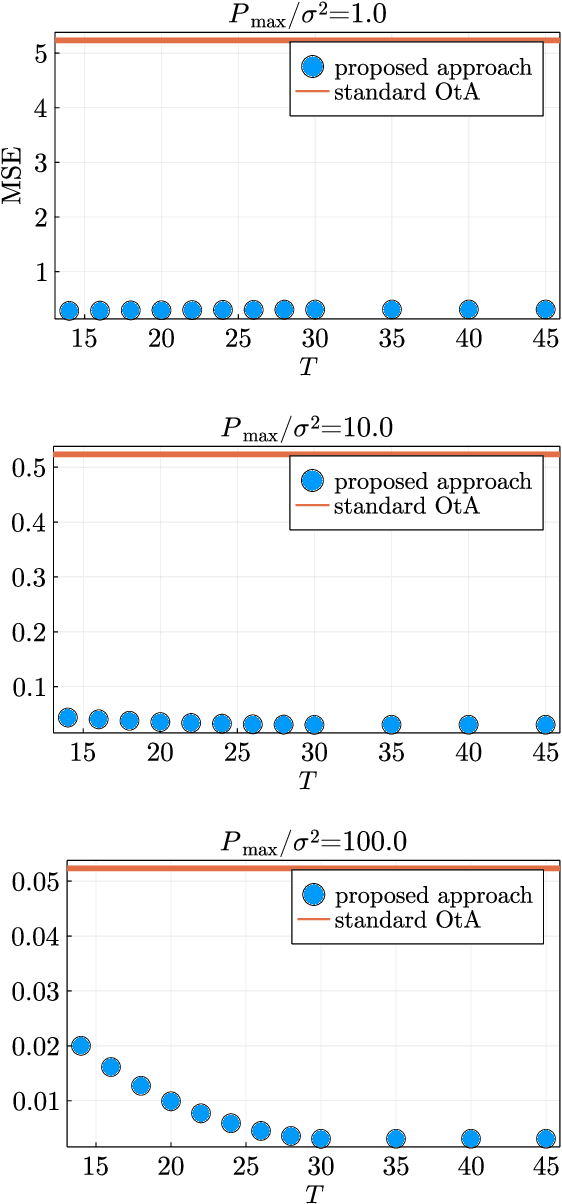
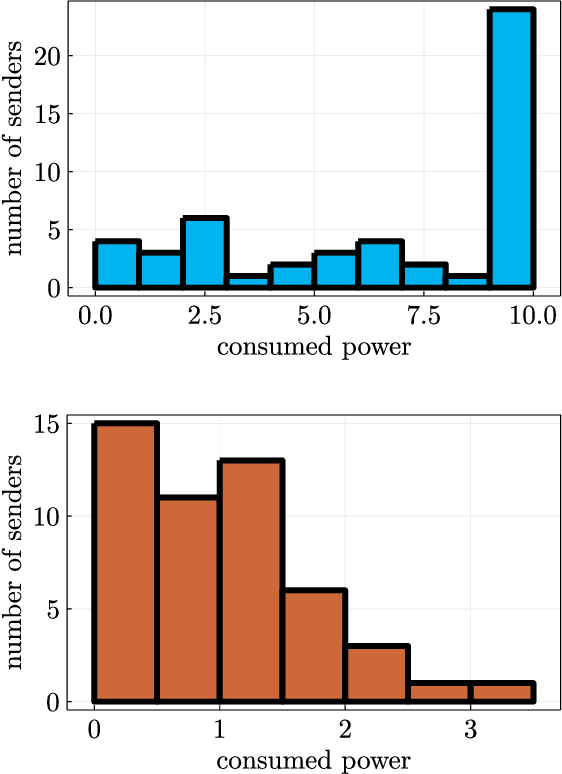
Over-the-air (OtA) computation is a newly emerged concept for achieving resource-efficient data aggregation over a large number of wireless nodes. Current research on this topic only considers the standard star topology with multiple senders transmitting information to one receiver. In this work, we investigate how to achieve OtA computation with multiple receivers, and we propose a novel communication design by exploiting joint precoding and decoding over multiple time slots. The optimal precoding and decoding vectors are determined by solving an optimization problem that aims at minimizing the mean squared error of aggregated data under the unbiasedness condition and the power constraints. We show that with our proposed multi-slot design, we can save communication resources (e.g., time slots) and achieve smaller estimation error as compared to the baseline approach of separating different receivers over time.
Algorithmic Information Design in Multi-Player Games: Possibility and Limits in Singleton Congestion
Sep 25, 2021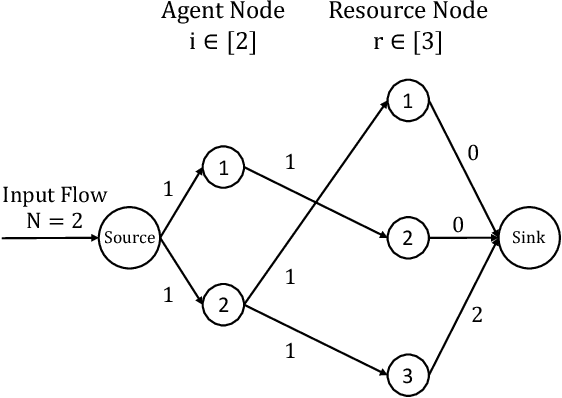


Most algorithmic studies on multi-agent information design so far have focused on the restricted situation with no inter-agent externalities; a few exceptions investigated special game classes such as zero-sum games and second-price auctions but have all focused only on optimal public signaling and exhibit sweepingly negative results. This paper initiates the algorithmic information design of both \emph{public} and \emph{private} signaling in a fundamental class of games with negative externalities, i.e., atomic singleton congestion games, with wide application in today's digital economy, machine scheduling, routing, etc. For both public and private signaling, we show that the optimal information design can be efficiently computed when the number of resources is a constant. To our knowledge, this is the first set of computationally efficient algorithms for information design in succinctly representable many-player games. Our results hinge on novel techniques such as developing ``reduced forms'' to compactly represent players' marginal beliefs. When there are many resources, we show computational intractability results. To overcome the challenge of multiple equilibria, here we introduce a new notion of equilibrium-\emph{oblivious} NP-hardness, which rules out any possibility of computing a good signaling scheme, irrespective of the equilibrium selection rule.
Generalization Bounds For Meta-Learning: An Information-Theoretic Analysis
Sep 29, 2021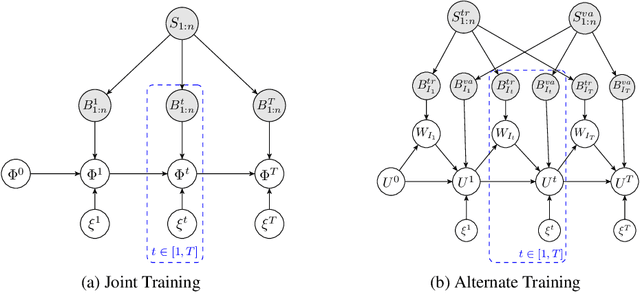
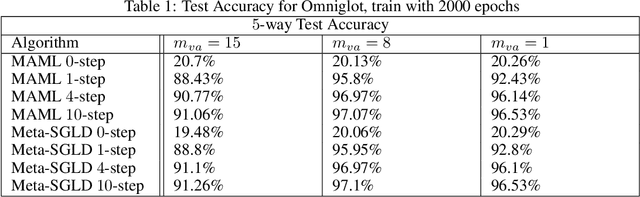
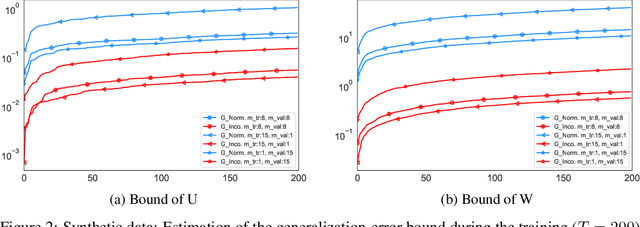
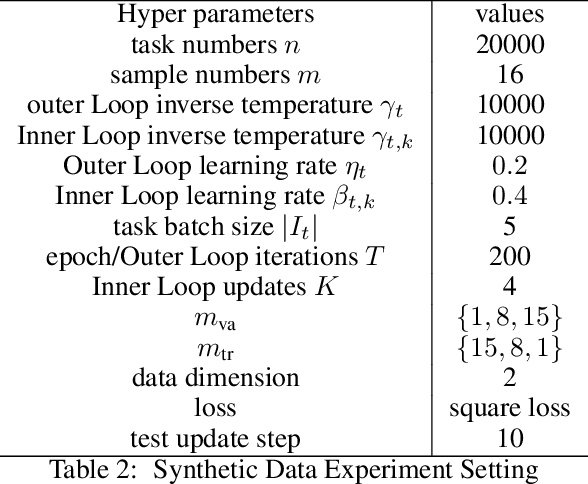
We derive a novel information-theoretic analysis of the generalization property of meta-learning algorithms. Concretely, our analysis proposes a generic understanding of both the conventional learning-to-learn framework and the modern model-agnostic meta-learning (MAML) algorithms. Moreover, we provide a data-dependent generalization bound for a stochastic variant of MAML, which is non-vacuous for deep few-shot learning. As compared to previous bounds that depend on the square norm of gradients, empirical validations on both simulated data and a well-known few-shot benchmark show that our bound is orders of magnitude tighter in most situations.
Ethical and Social Considerations in Automatic Expert Identification and People Recommendation in Organizational Knowledge Management Systems
Sep 08, 2022Organizational knowledge bases are moving from passive archives to active entities in the flow of people's work. We are seeing machine learning used to enable systems that both collect and surface information as people are working, making it possible to bring out connections between people and content that were previously much less visible in order to automatically identify and highlight experts on a given topic. When these knowledge bases begin to actively bring attention to people and the content they work on, especially as that work is still ongoing, we run into important challenges at the intersection of work and the social. While such systems have the potential to make certain parts of people's work more productive or enjoyable, they may also introduce new workloads, for instance by putting people in the role of experts for others to reach out to. And these knowledge bases can also have profound social consequences by changing what parts of work are visible and, therefore, acknowledged. We pose a number of open questions that warrant attention and engagement across industry and academia. Addressing these questions is an essential step in ensuring that the future of work becomes a good future for those doing the work. With this position paper, we wish to enter into the cross-disciplinary discussion we believe is required to tackle the challenge of developing recommender systems that respect social values.
Selective manipulation of disentangled representations for privacy-aware facial image processing
Aug 26, 2022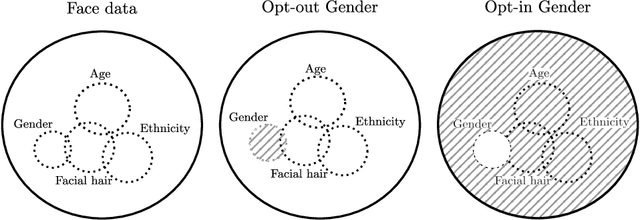
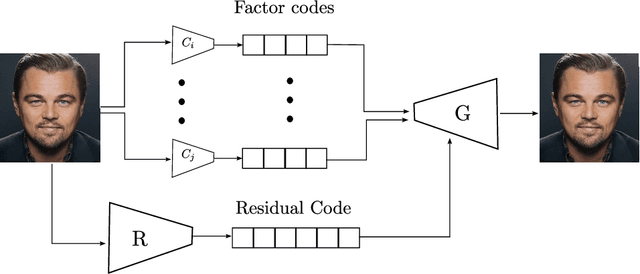
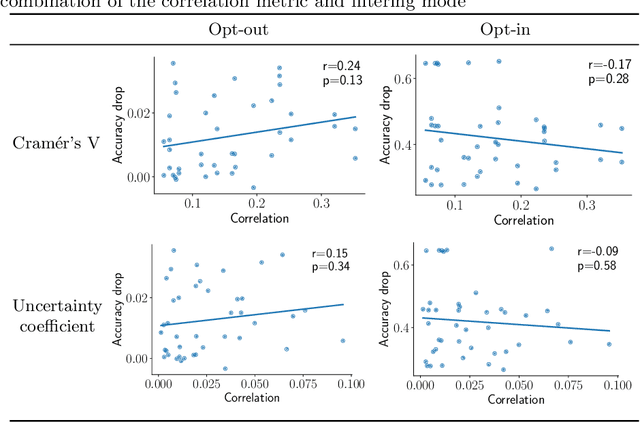
Camera sensors are increasingly being combined with machine learning to perform various tasks such as intelligent surveillance. Due to its computational complexity, most of these machine learning algorithms are offloaded to the cloud for processing. However, users are increasingly concerned about privacy issues such as function creep and malicious usage by third-party cloud providers. To alleviate this, we propose an edge-based filtering stage that removes privacy-sensitive attributes before the sensor data are transmitted to the cloud. We use state-of-the-art image manipulation techniques that leverage disentangled representations to achieve privacy filtering. We define opt-in and opt-out filter operations and evaluate their effectiveness for filtering private attributes from face images. Additionally, we examine the effect of naturally occurring correlations and residual information on filtering. We find the results promising and believe this elicits further research on how image manipulation can be used for privacy preservation.
Semi-supervised Training for Knowledge Base Graph Self-attention Networks on Link Prediction
Sep 03, 2022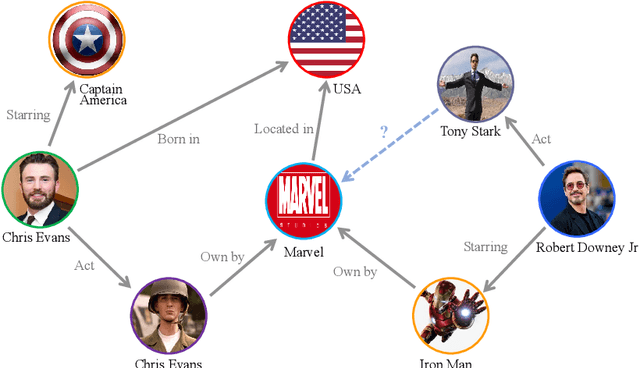
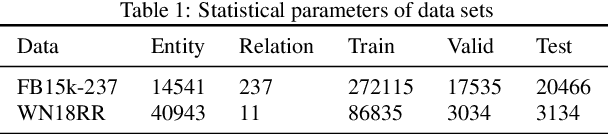
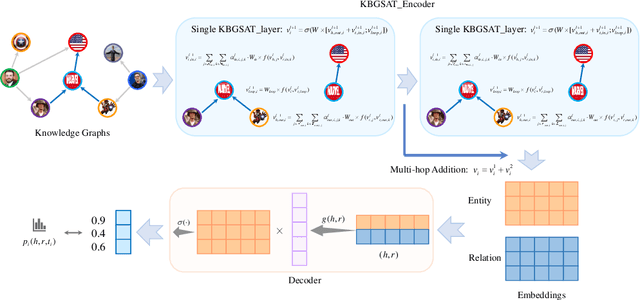
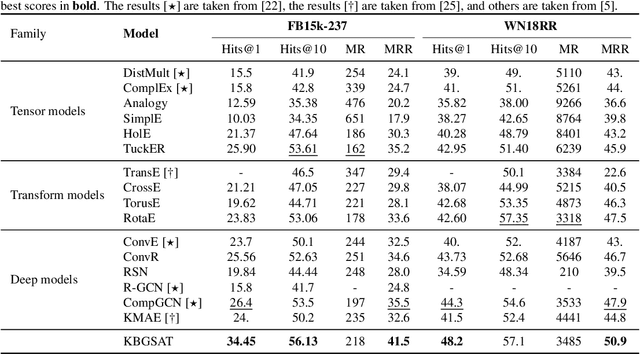
The task of link prediction aims to solve the problem of incomplete knowledge caused by the difficulty of collecting facts from the real world. GCNs-based models are widely applied to solve link prediction problems due to their sophistication, but GCNs-based models are suffering from two problems in the structure and training process. 1) The transformation methods of GCN layers become increasingly complex in GCN-based knowledge representation models; 2) Due to the incompleteness of the knowledge graph collection process, there are many uncollected true facts in the labeled negative samples. Therefore, this paper investigates the characteristic of the information aggregation coefficient (self-attention) of adjacent nodes and redesigns the self-attention mechanism of the GAT structure. Meanwhile, inspired by human thinking habits, we designed a semi-supervised self-training method over pre-trained models. Experimental results on the benchmark datasets FB15k-237 and WN18RR show that our proposed self-attention mechanism and semi-supervised self-training method can effectively improve the performance of the link prediction task. If you look at FB15k-237, for example, the proposed method improves Hits@1 by about 30%.
Multiobjective Ranking and Selection Using Stochastic Kriging
Sep 05, 2022
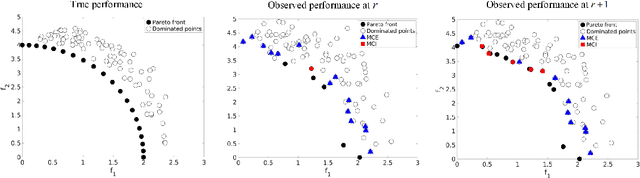

We consider multiobjective simulation optimization problems, where several conflicting objectives are optimized simultaneously, and can only be observed via stochastic simulation. The goal is to find or approximate a (discrete) set of Pareto-optimal solutions that reveal the essential trade-offs between the objectives, where optimality means that no objective can be improved without deteriorating the quality of any other objective. The noise in the observed performance may lead to two possible misclassification errors: solutions that are truly Pareto-optimal can be wrongly considered dominated, and solutions that are truly dominated can be wrongly considered Pareto-optimal. We propose a Bayesian multiobjective ranking and selection method to reduce the number of errors when identifying the solutions with the true best expected performance. We use stochastic kriging metamodels to build reliable predictive distributions of the objectives, and exploit this information in two efficient screening procedures and two novel sampling criteria. We use these in a sequential sampling algorithm to decide how to allocate samples. Experimental results show that the proposed method only requires a small fraction of samples compared to the standard allocation method, and it's competitive against the state-of-the-art, with the exploitation of the correlation structure being the dominant contributor to the improvement.
Visual Grounding of Inter-lingual Word-Embeddings
Sep 08, 2022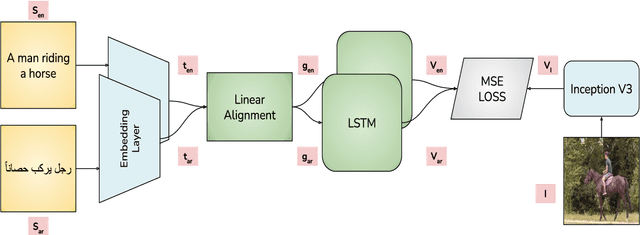
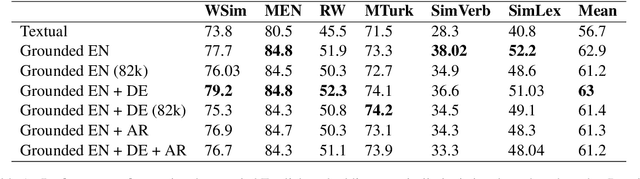
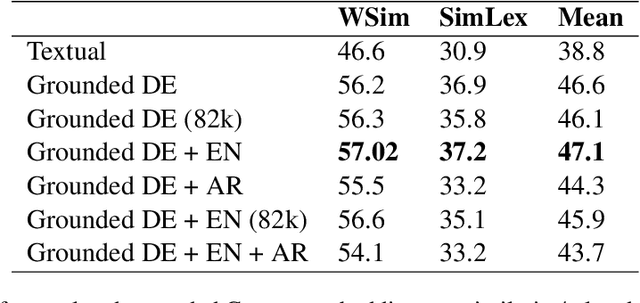
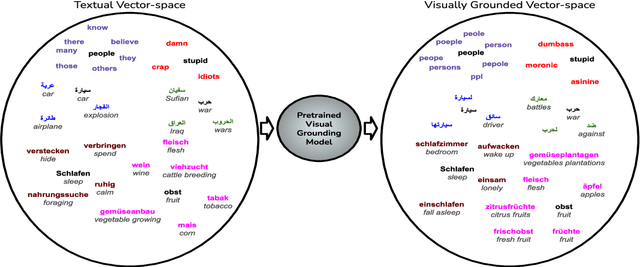
Visual grounding of Language aims at enriching textual representations of language with multiple sources of visual knowledge such as images and videos. Although visual grounding is an area of intense research, inter-lingual aspects of visual grounding have not received much attention. The present study investigates the inter-lingual visual grounding of word embeddings. We propose an implicit alignment technique between the two spaces of vision and language in which inter-lingual textual information interacts in order to enrich pre-trained textual word embeddings. We focus on three languages in our experiments, namely, English, Arabic, and German. We obtained visually grounded vector representations for these languages and studied whether visual grounding on one or multiple languages improved the performance of embeddings on word similarity and categorization benchmarks. Our experiments suggest that inter-lingual knowledge improves the performance of grounded embeddings in similar languages such as German and English. However, inter-lingual grounding of German or English with Arabic led to a slight degradation in performance on word similarity benchmarks. On the other hand, we observed an opposite trend on categorization benchmarks where Arabic had the most improvement on English. In the discussion section, several reasons for those findings are laid out. We hope that our experiments provide a baseline for further research on inter-lingual visual grounding.