 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Sequence Models for Text Classification Tasks
Jul 18, 2022
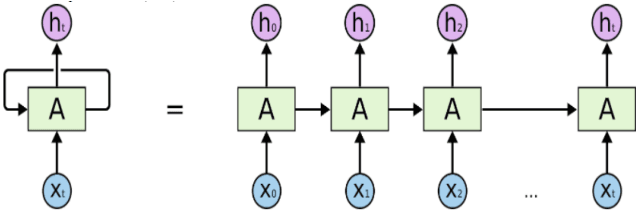
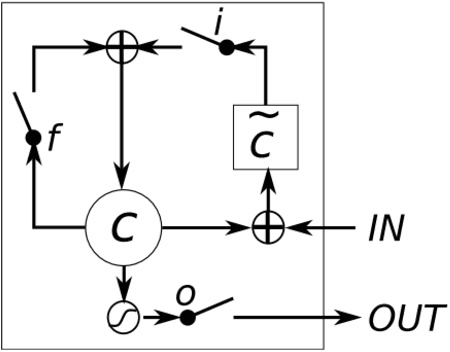
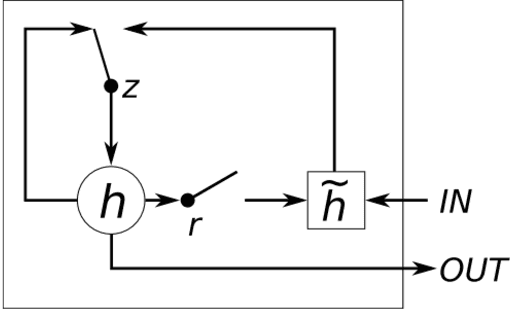
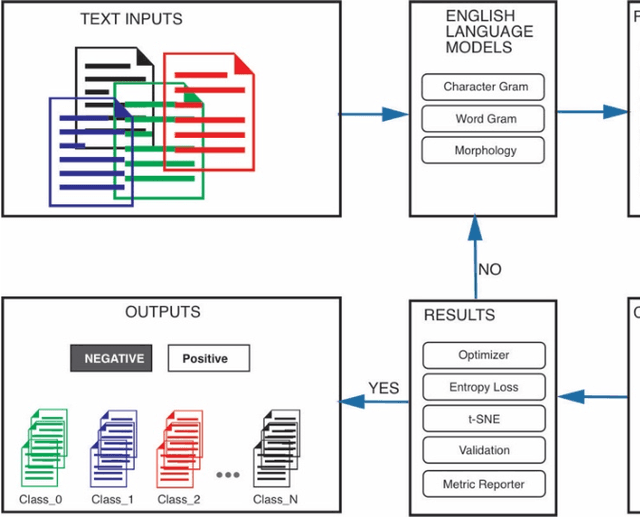
The exponential growth of data generated on the Internet in the current information age is a driving force for the digital economy. Extraction of information is the major value in an accumulated big data. Big data dependency on statistical analysis and hand-engineered rules machine learning algorithms are overwhelmed with vast complexities inherent in human languages. Natural Language Processing (NLP) is equipping machines to understand these human diverse and complicated languages. Text Classification is an NLP task which automatically identifies patterns based on predefined or undefined labeled sets. Common text classification application includes information retrieval, modeling news topic, theme extraction, sentiment analysis, and spam detection. In texts, some sequences of words depend on the previous or next word sequences to make full meaning; this is a challenging dependency task that requires the machine to be able to store some previous important information to impact future meaning. Sequence models such as RNN, GRU, and LSTM is a breakthrough for tasks with long-range dependencies. As such, we applied these models to Binary and Multi-class classification. Results generated were excellent with most of the models performing within the range of 80% and 94%. However, this result is not exhaustive as we believe there is room for improvement if machines are to compete with humans.
Sonority Measurement Using System, Source, and Suprasegmental Information
Jul 01, 2021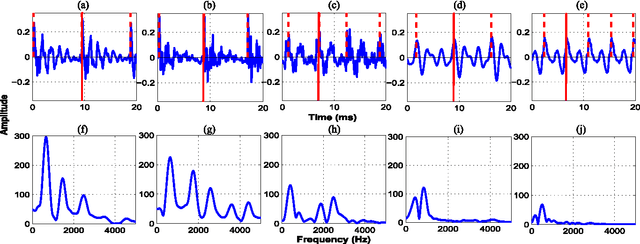
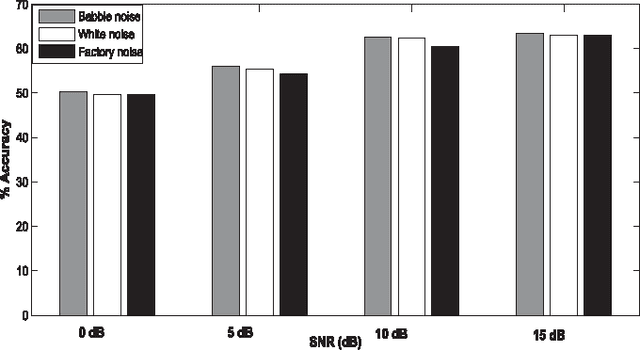
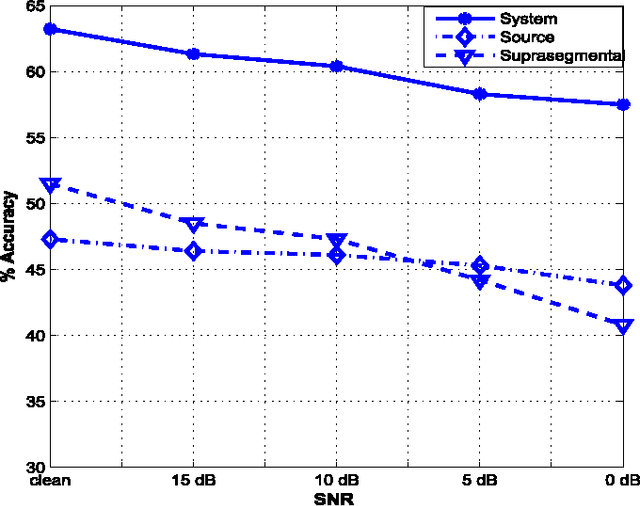
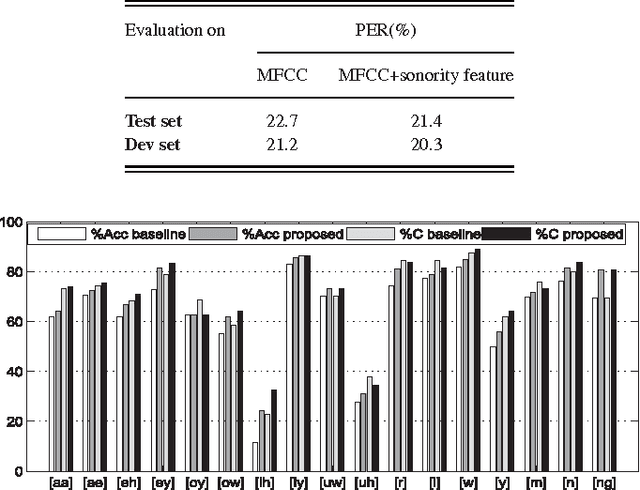
Sonorant sounds are characterized by regions with prominent formant structure, high energy and high degree of periodicity. In this work, the vocal-tract system, excitation source and suprasegmental features derived from the speech signal are analyzed to measure the sonority information present in each of them. Vocal-tract system information is extracted from the Hilbert envelope of numerator of group delay function. It is derived from zero time windowed speech signal that provides better resolution of the formants. A five-dimensional feature set is computed from the estimated formants to measure the prominence of the spectral peaks. A feature representing strength of excitation is derived from the Hilbert envelope of linear prediction residual, which represents the source information. Correlation of speech over ten consecutive pitch periods is used as the suprasegmental feature representing periodicity information. The combination of evidences from the three different aspects of speech provides better discrimination among different sonorant classes, compared to the baseline MFCC features. The usefulness of the proposed sonority feature is demonstrated in the tasks of phoneme recognition and sonorant classification.
Algorithmic Assistance with Recommendation-Dependent Preferences
Aug 16, 2022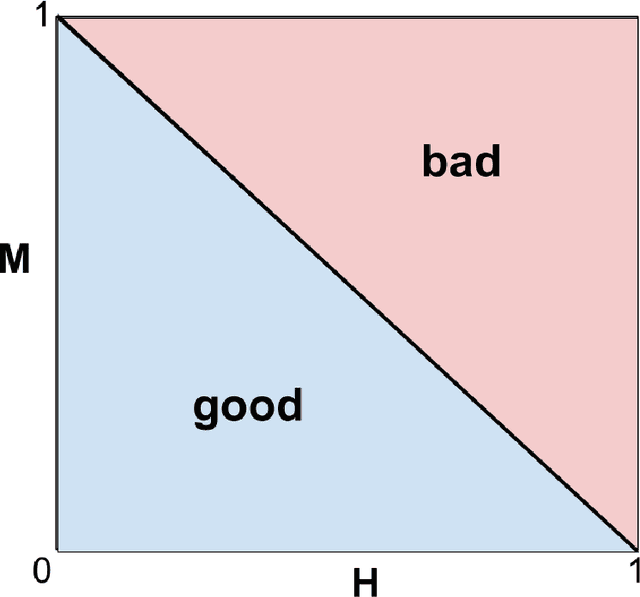
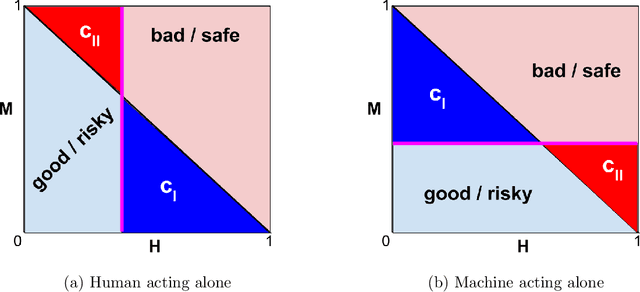
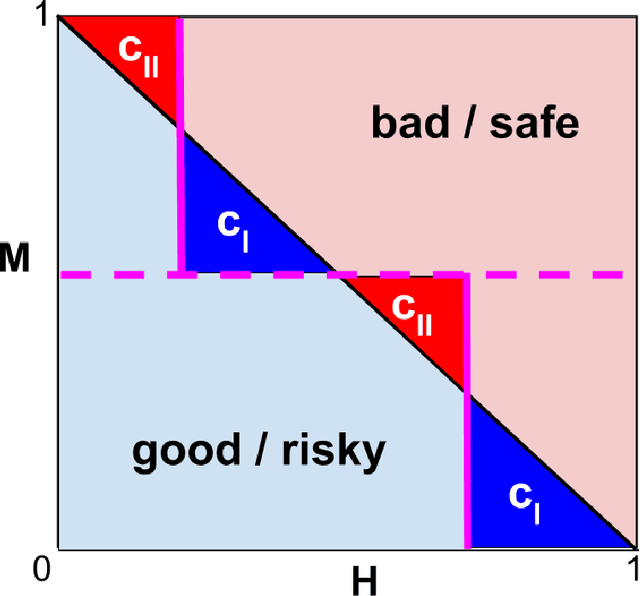
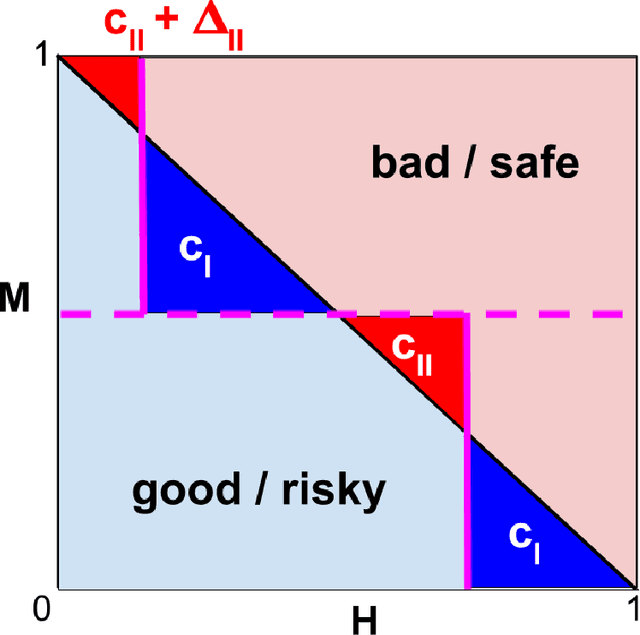
When we use algorithms to produce recommendations, we typically think of these recommendations as providing helpful information, such as when risk assessments are presented to judges or doctors. But when a decision-maker obtains a recommendation, they may not only react to the information. The decision-maker may view the recommendation as a default action, making it costly for them to deviate, for example when a judge is reluctant to overrule a high-risk assessment of a defendant or a doctor fears the consequences of deviating from recommended procedures. In this article, we consider the effect and design of recommendations when they affect choices not just by shifting beliefs, but also by altering preferences. We motivate our model from institutional factors, such as a desire to avoid audits, as well as from well-established models in behavioral science that predict loss aversion relative to a reference point, which here is set by the algorithm. We show that recommendation-dependent preferences create inefficiencies where the decision-maker is overly responsive to the recommendation, which changes the optimal design of the algorithm towards providing less conservative recommendations. As a potential remedy, we discuss an algorithm that strategically withholds recommendations, and show how it can improve the quality of final decisions.
KRACL: Contrastive Learning with Graph Context Modeling for Sparse Knowledge Graph Completion
Aug 16, 2022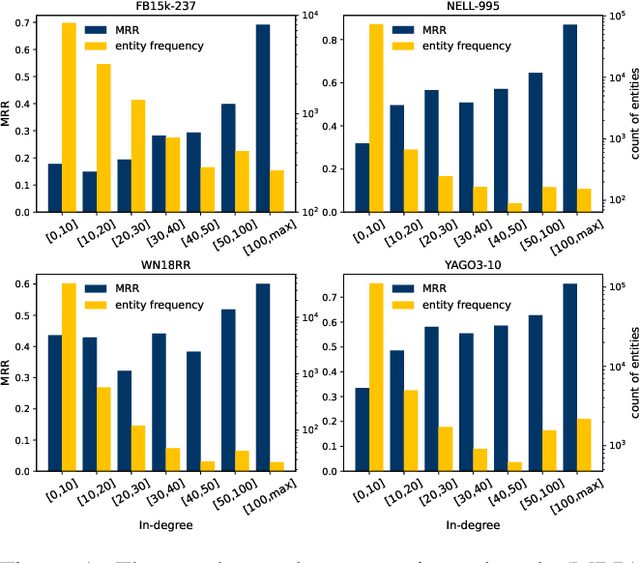
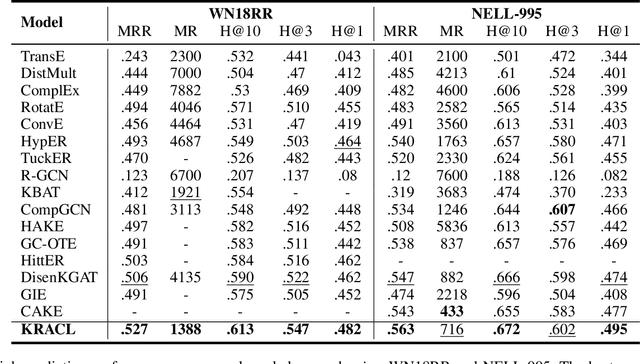
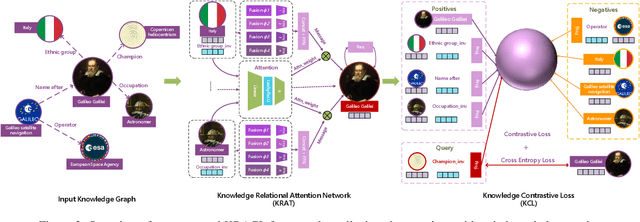
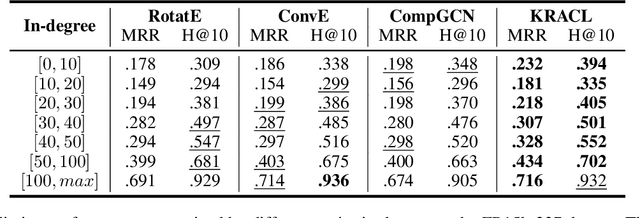
Knowledge Graph Embeddings (KGE) aim to map entities and relations to low dimensional spaces and have become the \textit{de-facto} standard for knowledge graph completion. Most existing KGE methods suffer from the sparsity challenge, where it is harder to predict entities that appear less frequently in knowledge graphs. In this work, we propose a novel framework KRACL to alleviate the widespread sparsity in KGs with graph context and contrastive learning. Firstly, we propose the Knowledge Relational Attention Network (KRAT) to leverage the graph context by simultaneously projecting neighboring triples to different latent spaces and jointly aggregating messages with the attention mechanism. KRAT is capable of capturing the subtle semantic information and importance of different context triples as well as leveraging multi-hop information in knowledge graphs. Secondly, we propose the knowledge contrastive loss by combining the contrastive loss with cross entropy loss, which introduces more negative samples and thus enriches the feedback to sparse entities. Our experiments demonstrate that KRACL achieves superior results across various standard knowledge graph benchmarks, especially on WN18RR and NELL-995 which have large numbers of low in-degree entities. Extensive experiments also bear out KRACL's effectiveness in handling sparse knowledge graphs and robustness against noisy triples.
Distribution Aware Metrics for Conditional Natural Language Generation
Sep 15, 2022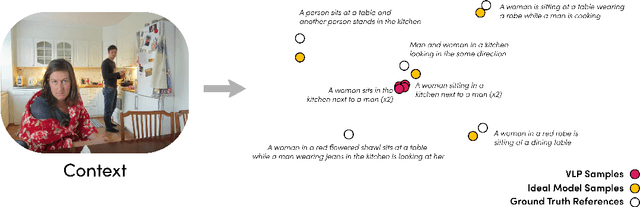

Traditional automated metrics for evaluating conditional natural language generation use pairwise comparisons between a single generated text and the best-matching gold-standard ground truth text. When multiple ground truths are available, scores are aggregated using an average or max operation across references. While this approach works well when diversity in the ground truth data (i.e. dispersion of the distribution of conditional texts) can be ascribed to noise, such as in automated speech recognition, it does not allow for robust evaluation in the case where diversity in the ground truths represents signal for the model. In this work we argue that existing metrics are not appropriate for domains such as visual description or summarization where ground truths are semantically diverse, and where the diversity in those captions captures useful additional information about the context. We propose a novel paradigm for multi-candidate evaluation of conditional language generation models, and a new family of metrics that compare the distributions of reference and model-generated caption sets using small sample sets of each. We demonstrate the utility of our approach with a case study in visual description: where we show that existing models optimize for single-description quality over diversity, and gain some insights into how sampling methods and temperature impact description quality and diversity.
A Zeroth-Order Momentum Method for Risk-Averse Online Convex Games
Sep 06, 2022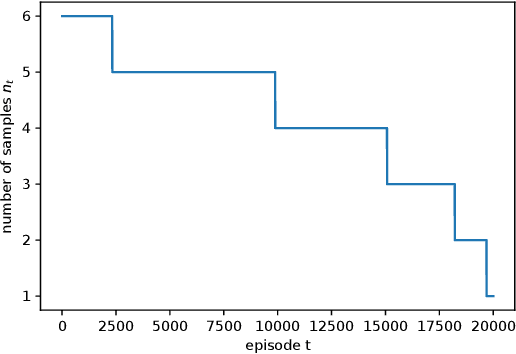
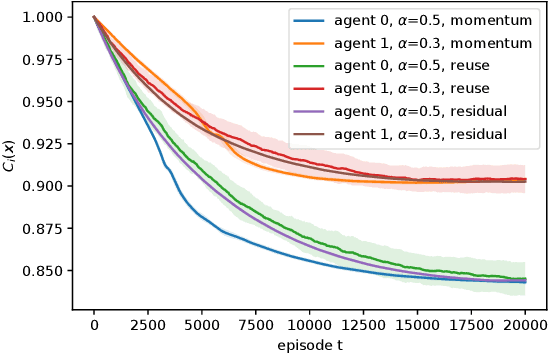
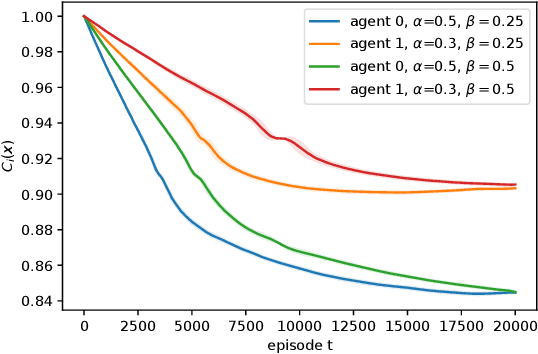
We consider risk-averse learning in repeated unknown games where the goal of the agents is to minimize their individual risk of incurring significantly high cost. Specifically, the agents use the conditional value at risk (CVaR) as a risk measure and rely on bandit feedback in the form of the cost values of the selected actions at every episode to estimate their CVaR values and update their actions. A major challenge in using bandit feedback to estimate CVaR is that the agents can only access their own cost values, which, however, depend on the actions of all agents. To address this challenge, we propose a new risk-averse learning algorithm with momentum that utilizes the full historical information on the cost values. We show that this algorithm achieves sub-linear regret and matches the best known algorithms in the literature. We provide numerical experiments for a Cournot game that show that our method outperforms existing methods.
User recommendation system based on MIND dataset
Sep 06, 2022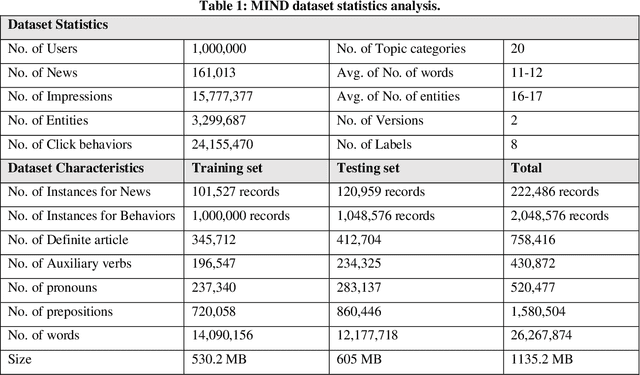
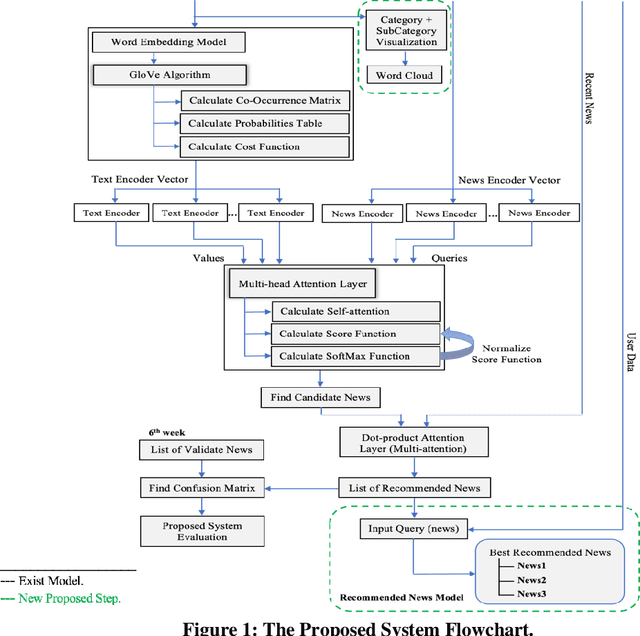
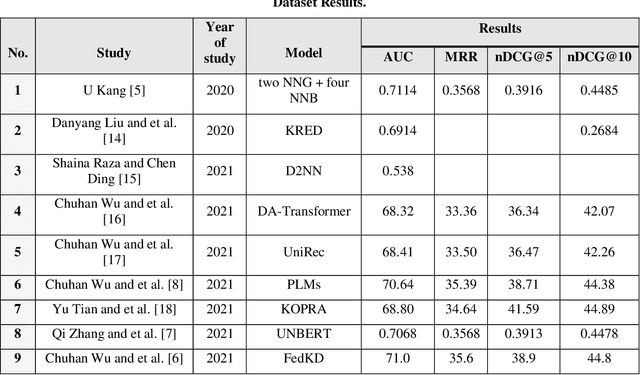
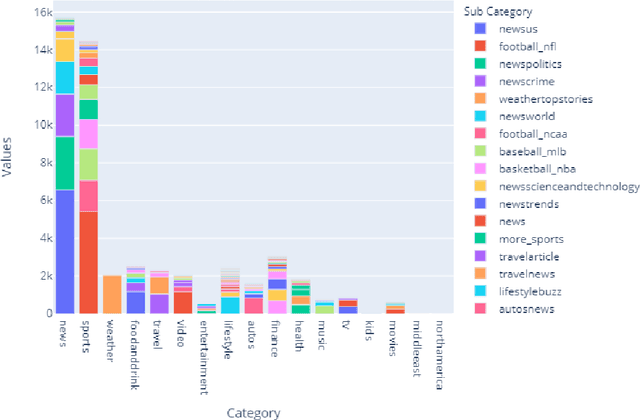
Nowadays, it's a very significant way for researchers and other individuals to achieve their interests because it provides short solutions to satisfy their demands. Because there are so many pieces of information on the internet, news recommendation systems allow us to filter content and deliver it to the user in proportion to his desires and interests. RSs have three techniques: content-based filtering, collaborative filtering, and hybrid filtering. We will use the MIND dataset with our system, which was collected in 2019, the big challenge in this dataset because there is a lot of ambiguity and complex text processing. In this paper, will present our proposed recommendation system. The core of our system we have used the GloVe algorithm for word embeddings and representation. Besides, the Multi-head Attention Layer calculates the attention of words, to generate a list of recommended news. Finally, we achieve good results more than some other related works in AUC 71.211, MRR 35.72, nDCG@5 38.05, and nDCG@10 44.45.
Learning New Skills after Deployment: Improving open-domain internet-driven dialogue with human feedback
Aug 05, 2022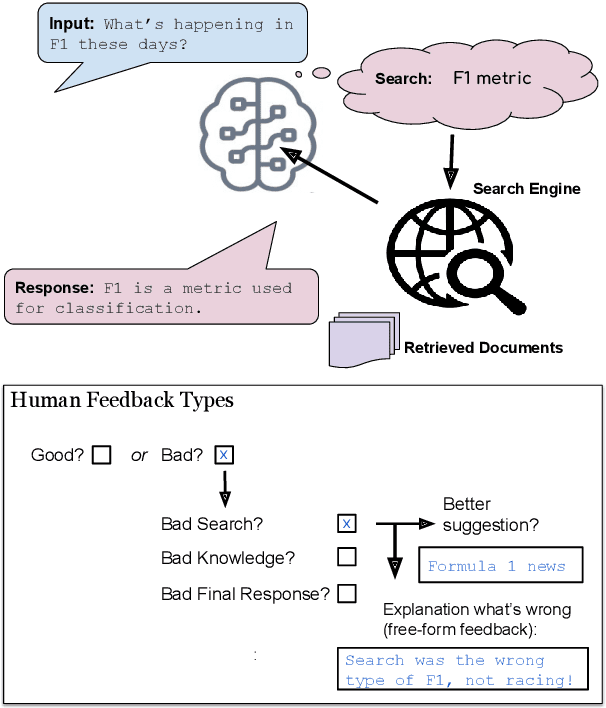
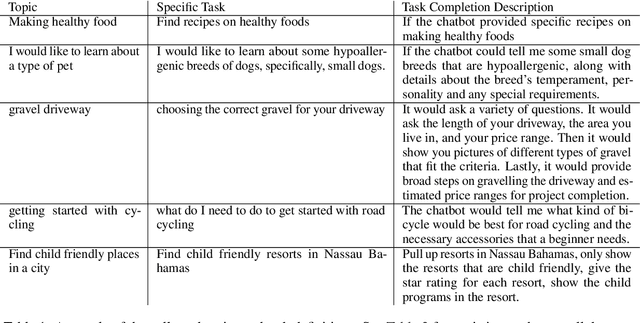
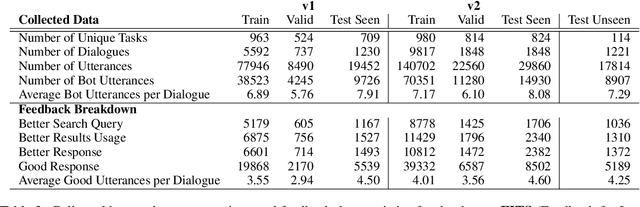
Frozen models trained to mimic static datasets can never improve their performance. Models that can employ internet-retrieval for up-to-date information and obtain feedback from humans during deployment provide the promise of both adapting to new information, and improving their performance. In this work we study how to improve internet-driven conversational skills in such a learning framework. We collect deployment data, which we make publicly available, of human interactions, and collect various types of human feedback -- including binary quality measurements, free-form text feedback, and fine-grained reasons for failure. We then study various algorithms for improving from such feedback, including standard supervised learning, rejection sampling, model-guiding and reward-based learning, in order to make recommendations on which type of feedback and algorithms work best. We find the recently introduced Director model (Arora et al., '22) shows significant improvements over other existing approaches.
Distributed Semi-supervised Fuzzy Regression with Interpolation Consistency Regularization
Sep 18, 2022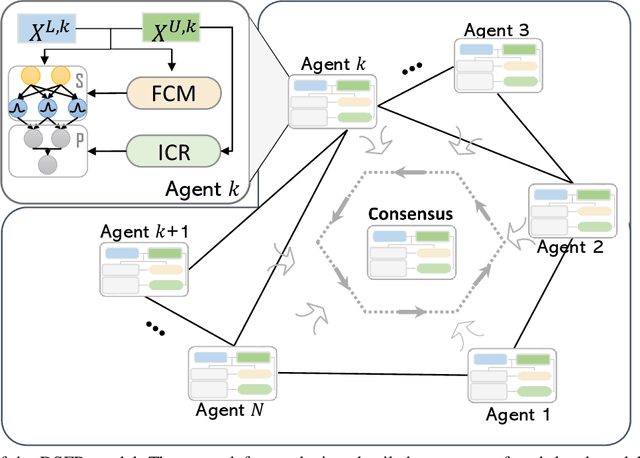
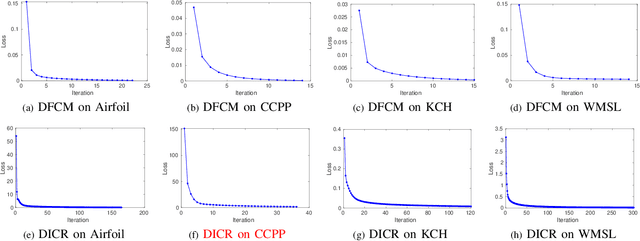
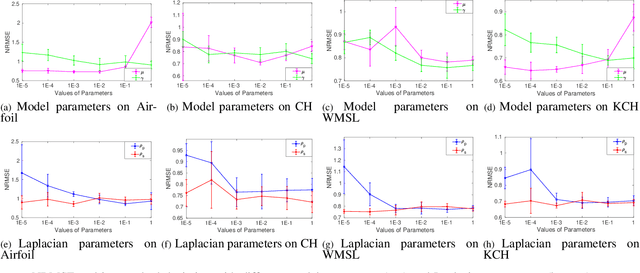
Recently, distributed semi-supervised learning (DSSL) algorithms have shown their effectiveness in leveraging unlabeled samples over interconnected networks, where agents cannot share their original data with each other and can only communicate non-sensitive information with their neighbors. However, existing DSSL algorithms cannot cope with data uncertainties and may suffer from high computation and communication overhead problems. To handle these issues, we propose a distributed semi-supervised fuzzy regression (DSFR) model with fuzzy if-then rules and interpolation consistency regularization (ICR). The ICR, which was proposed recently for semi-supervised problem, can force decision boundaries to pass through sparse data areas, thus increasing model robustness. However, its application in distributed scenarios has not been considered yet. In this work, we proposed a distributed Fuzzy C-means (DFCM) method and a distributed interpolation consistency regularization (DICR) built on the well-known alternating direction method of multipliers to respectively locate parameters in antecedent and consequent components of DSFR. Notably, the DSFR model converges very fast since it does not involve back-propagation procedure and is scalable to large-scale datasets benefiting from the utilization of DFCM and DICR. Experiments results on both artificial and real-world datasets show that the proposed DSFR model can achieve much better performance than the state-of-the-art DSSL algorithm in terms of both loss value and computational cost.
Deep Convolutional Architectures for Extrapolative Forecast in Time-dependent Flow Problems
Sep 18, 2022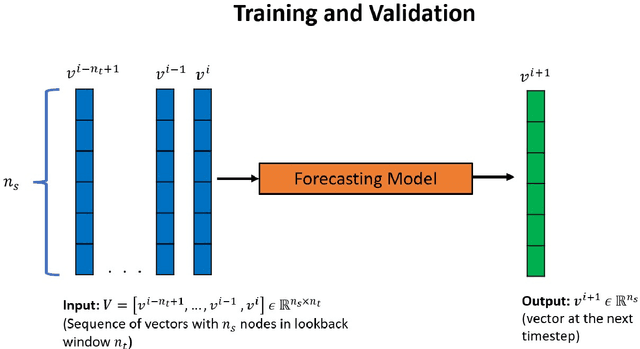

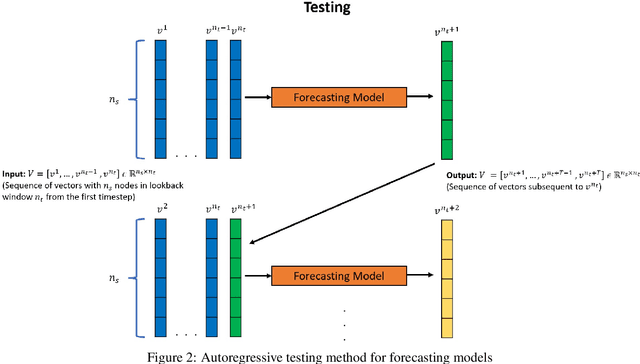

Physical systems whose dynamics are governed by partial differential equations (PDEs) find applications in numerous fields, from engineering design to weather forecasting. The process of obtaining the solution from such PDEs may be computationally expensive for large-scale and parameterized problems. In this work, deep learning techniques developed especially for time-series forecasts, such as LSTM and TCN, or for spatial-feature extraction such as CNN, are employed to model the system dynamics for advection dominated problems. These models take as input a sequence of high-fidelity vector solutions for consecutive time-steps obtained from the PDEs and forecast the solutions for the subsequent time-steps using auto-regression; thereby reducing the computation time and power needed to obtain such high-fidelity solutions. The models are tested on numerical benchmarks (1D Burgers' equation and Stoker's dam break problem) to assess the long-term prediction accuracy, even outside the training domain (extrapolation). Non-intrusive reduced-order modelling techniques such as deep auto-encoder networks are utilized to compress the high-fidelity snapshots before feeding them as input to the forecasting models in order to reduce the complexity and the required computations in the online and offline stages. Deep ensembles are employed to perform uncertainty quantification of the forecasting models, which provides information about the variance of the predictions as a result of the epistemic uncertainties.