 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
3D Siamese Transformer Network for Single Object Tracking on Point Clouds
Jul 26, 2022
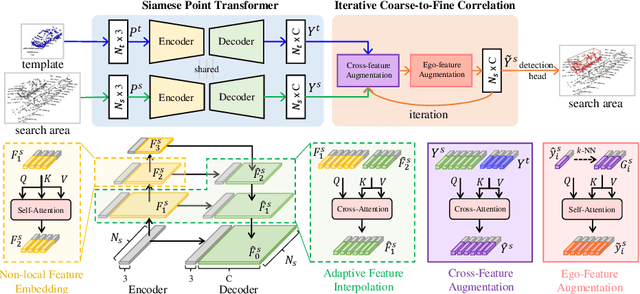
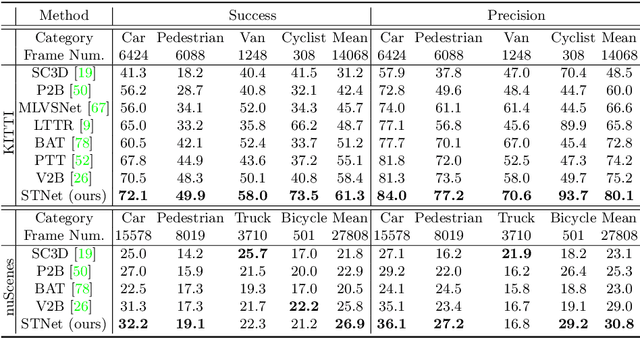
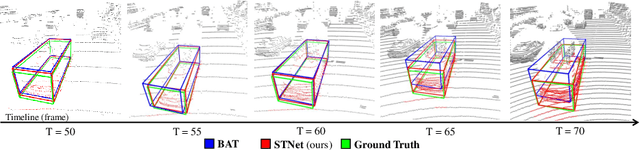
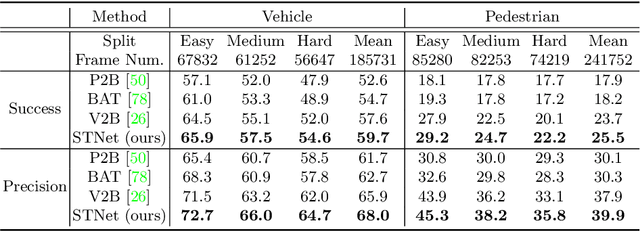
Siamese network based trackers formulate 3D single object tracking as cross-correlation learning between point features of a template and a search area. Due to the large appearance variation between the template and search area during tracking, how to learn the robust cross correlation between them for identifying the potential target in the search area is still a challenging problem. In this paper, we explicitly use Transformer to form a 3D Siamese Transformer network for learning robust cross correlation between the template and the search area of point clouds. Specifically, we develop a Siamese point Transformer network to learn shape context information of the target. Its encoder uses self-attention to capture non-local information of point clouds to characterize the shape information of the object, and the decoder utilizes cross-attention to upsample discriminative point features. After that, we develop an iterative coarse-to-fine correlation network to learn the robust cross correlation between the template and the search area. It formulates the cross-feature augmentation to associate the template with the potential target in the search area via cross attention. To further enhance the potential target, it employs the ego-feature augmentation that applies self-attention to the local k-NN graph of the feature space to aggregate target features. Experiments on the KITTI, nuScenes, and Waymo datasets show that our method achieves state-of-the-art performance on the 3D single object tracking task.
Zoom Text Detector
Sep 07, 2022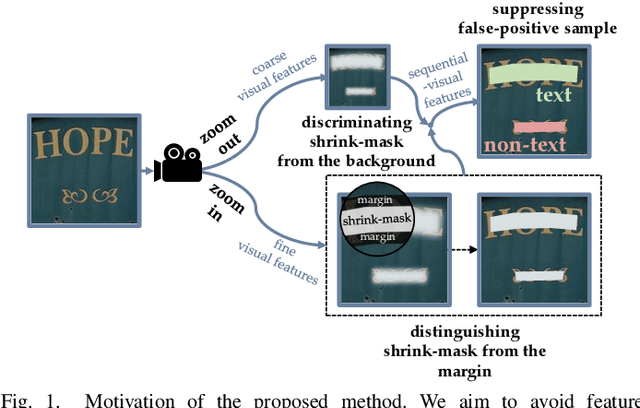
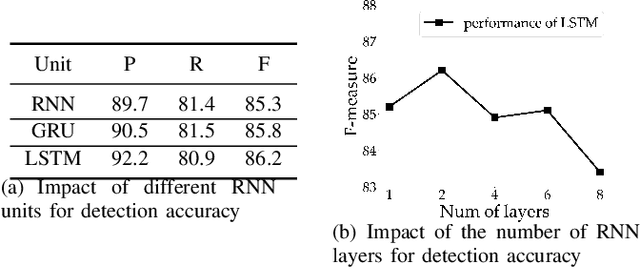
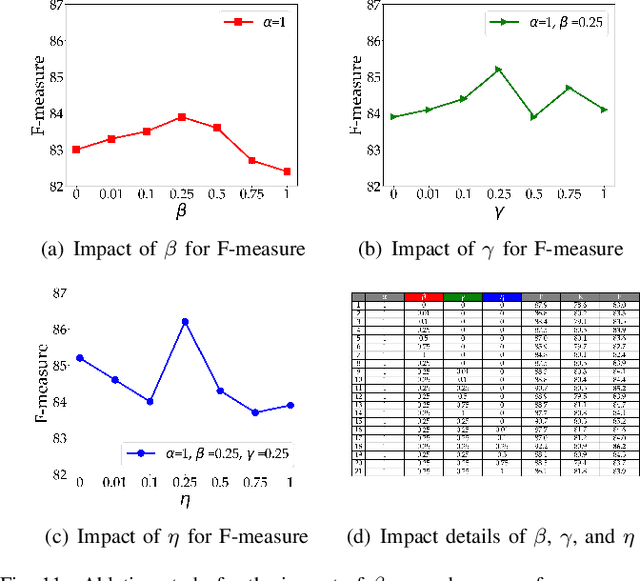

To pursue comprehensive performance, recent text detectors improve detection speed at the expense of accuracy. They adopt shrink-mask based text representation strategies, which leads to a high dependency of detection accuracy on shrink-masks. Unfortunately, three disadvantages cause unreliable shrink-masks. Specifically, these methods try to strengthen the discrimination of shrink-masks from the background by semantic information. However, the feature defocusing phenomenon that coarse layers are optimized by fine-grained objectives limits the extraction of semantic features. Meanwhile, since both shrink-masks and the margins belong to texts, the detail loss phenomenon that the margins are ignored hinders the distinguishment of shrink-masks from the margins, which causes ambiguous shrink-mask edges. Moreover, false-positive samples enjoy similar visual features with shrink-masks. They aggravate the decline of shrink-masks recognition. To avoid the above problems, we propose a Zoom Text Detector (ZTD) inspired by the zoom process of the camera. Specifically, Zoom Out Module (ZOM) is introduced to provide coarse-grained optimization objectives for coarse layers to avoid feature defocusing. Meanwhile, Zoom In Module (ZIM) is presented to enhance the margins recognition to prevent detail loss. Furthermore, Sequential-Visual Discriminator (SVD) is designed to suppress false-positive samples by sequential and visual features. Experiments verify the superior comprehensive performance of ZTD.
Estimation and Navigation Methods with Limited Information for Autonomous Urban Driving
Aug 11, 2021



Urban environments offer a challenging scenario for autonomous driving. Globally localizing information, such as a GPS signal, can be unreliable due to signal shadowing and multipath errors. Detailed a priori maps of the environment with sufficient information for autonomous navigation typically require driving the area multiple times to collect large amounts of data, substantial post-processing on that data to obtain the map, and then maintaining updates on the map as the environment changes. This dissertation addresses the issue of autonomous driving in an urban environment by investigating algorithms and an architecture to enable fully functional autonomous driving with limited information.
Cross-Skeleton Interaction Graph Aggregation Network for Representation Learning of Mouse Social Behaviour
Aug 07, 2022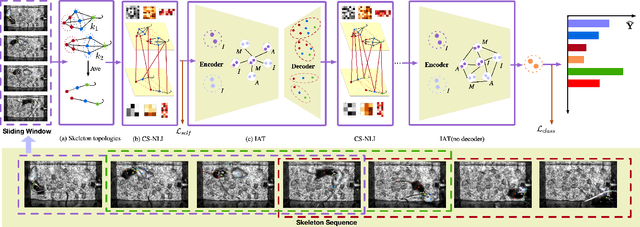
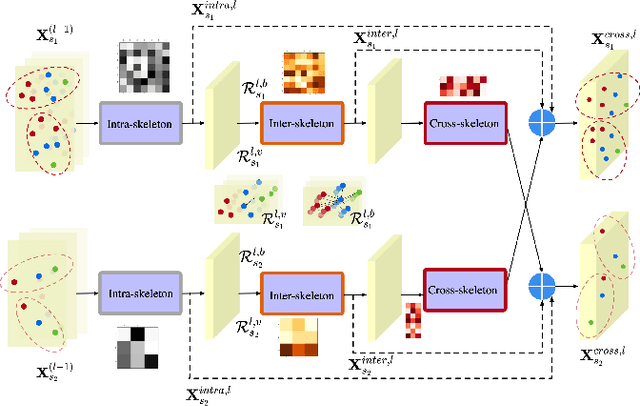
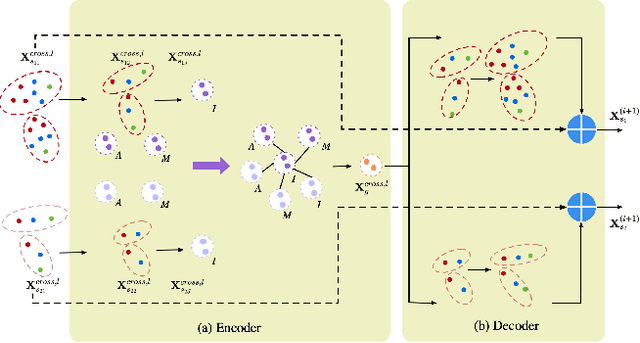
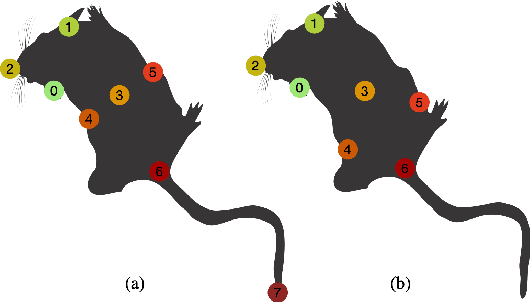
Automated social behaviour analysis of mice has become an increasingly popular research area in behavioural neuroscience. Recently, pose information (i.e., locations of keypoints or skeleton) has been used to interpret social behaviours of mice. Nevertheless, effective encoding and decoding of social interaction information underlying the keypoints of mice has been rarely investigated in the existing methods. In particular, it is challenging to model complex social interactions between mice due to highly deformable body shapes and ambiguous movement patterns. To deal with the interaction modelling problem, we here propose a Cross-Skeleton Interaction Graph Aggregation Network (CS-IGANet) to learn abundant dynamics of freely interacting mice, where a Cross-Skeleton Node-level Interaction module (CS-NLI) is used to model multi-level interactions (i.e., intra-, inter- and cross-skeleton interactions). Furthermore, we design a novel Interaction-Aware Transformer (IAT) to dynamically learn the graph-level representation of social behaviours and update the node-level representation, guided by our proposed interaction-aware self-attention mechanism. Finally, to enhance the representation ability of our model, an auxiliary self-supervised learning task is proposed for measuring the similarity between cross-skeleton nodes. Experimental results on the standard CRMI13-Skeleton and our PDMB-Skeleton datasets show that our proposed model outperforms several other state-of-the-art approaches.
Semantic Interactive Learning for Text Classification: A Constructive Approach for Contextual Interactions
Sep 07, 2022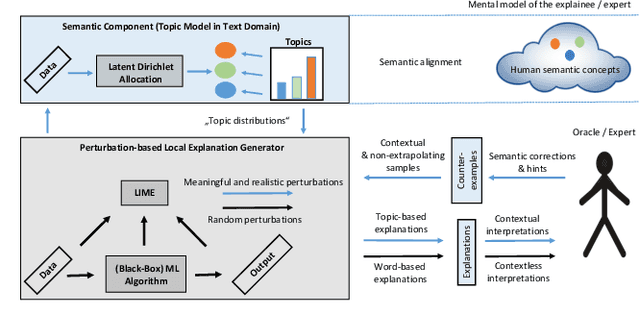
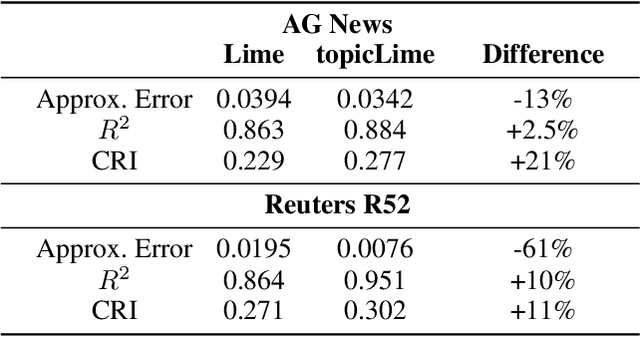
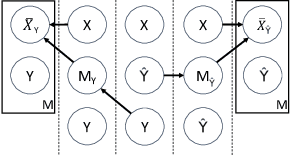
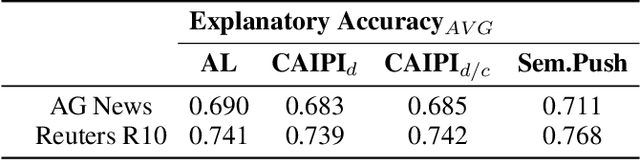
Interactive Machine Learning (IML) shall enable intelligent systems to interactively learn from their end-users, and is quickly becoming more and more important. Although it puts the human in the loop, interactions are mostly performed via mutual explanations that miss contextual information. Furthermore, current model-agnostic IML strategies like CAIPI are limited to 'destructive' feedback, meaning they solely allow an expert to prevent a learner from using irrelevant features. In this work, we propose a novel interaction framework called Semantic Interactive Learning for the text domain. We frame the problem of incorporating constructive and contextual feedback into the learner as a task to find an architecture that (a) enables more semantic alignment between humans and machines and (b) at the same time helps to maintain statistical characteristics of the input domain when generating user-defined counterexamples based on meaningful corrections. Therefore, we introduce a technique called SemanticPush that is effective for translating conceptual corrections of humans to non-extrapolating training examples such that the learner's reasoning is pushed towards the desired behavior. In several experiments, we show that our method clearly outperforms CAIPI, a state of the art IML strategy, in terms of Predictive Performance as well as Local Explanation Quality in downstream multi-class classification tasks.
CoVA: Context-aware Visual Attention for Webpage Information Extraction
Oct 24, 2021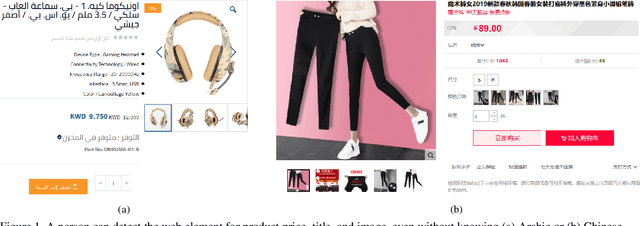
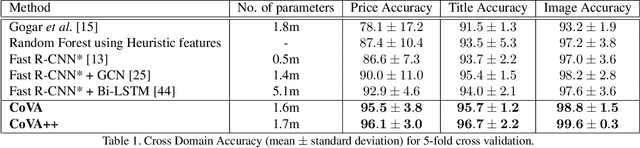
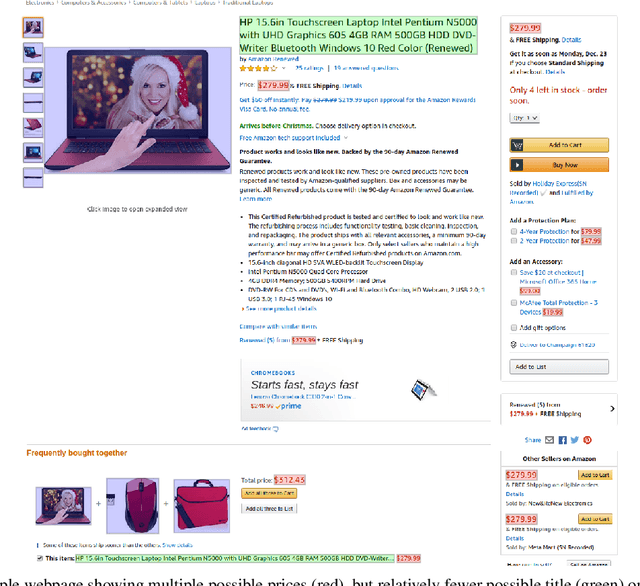
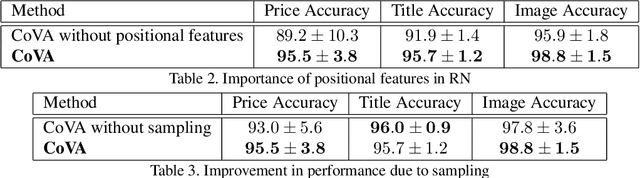
Webpage information extraction (WIE) is an important step to create knowledge bases. For this, classical WIE methods leverage the Document Object Model (DOM) tree of a website. However, use of the DOM tree poses significant challenges as context and appearance are encoded in an abstract manner. To address this challenge we propose to reformulate WIE as a context-aware Webpage Object Detection task. Specifically, we develop a Context-aware Visual Attention-based (CoVA) detection pipeline which combines appearance features with syntactical structure from the DOM tree. To study the approach we collect a new large-scale dataset of e-commerce websites for which we manually annotate every web element with four labels: product price, product title, product image and background. On this dataset we show that the proposed CoVA approach is a new challenging baseline which improves upon prior state-of-the-art methods.
Deep Learning-Based Rate-Splitting Multiple Access for Reconfigurable Intelligent Surface-Aided Tera-Hertz Massive MIMO
Sep 18, 2022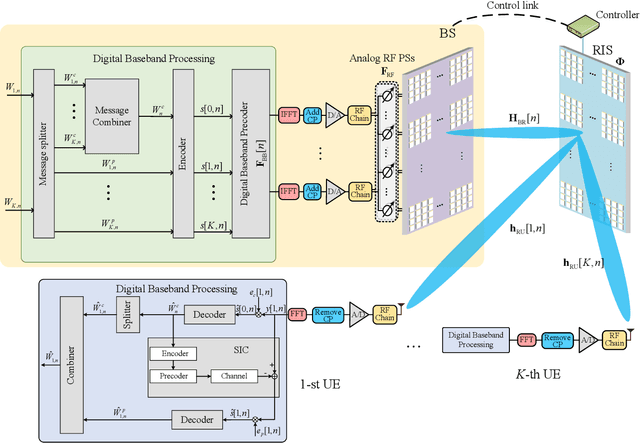
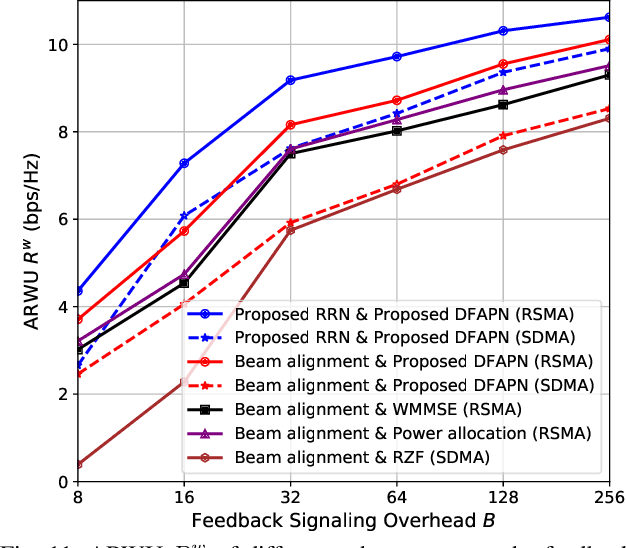
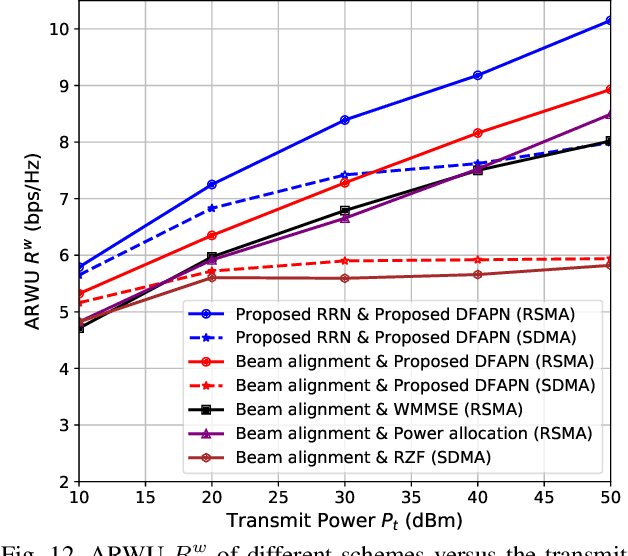

Reconfigurable intelligent surface (RIS) can significantly enhance the service coverage of Tera-Hertz massive multiple-input multiple-output (MIMO) communication systems. However, obtaining accurate high-dimensional channel state information (CSI) with limited pilot and feedback signaling overhead is challenging, severely degrading the performance of conventional spatial division multiple access. To improve the robustness against CSI imperfection, this paper proposes a deep learning (DL)-based rate-splitting multiple access (RSMA) scheme for RIS-aided Tera-Hertz multi-user MIMO systems. Specifically, we first propose a hybrid data-model driven DL-based RSMA precoding scheme, including the passive precoding at the RIS as well as the analog active precoding and the RSMA digital active precoding at the base station (BS). To realize the passive precoding at the RIS, we propose a Transformer-based data-driven RIS reflecting network (RRN). As for the analog active precoding at the BS, we propose a match-filter based analog precoding scheme considering that the BS and RIS adopt the LoS-MIMO antenna array architecture. As for the RSMA digital active precoding at the BS, we propose a low-complexity approximate weighted minimum mean square error (AWMMSE) digital precoding scheme. Furthermore, for better precoding performance as well as lower computational complexity, a model-driven deep unfolding active precoding network (DFAPN) is also designed by combining the proposed AWMMSE scheme with DL. Then, to acquire accurate CSI at the BS for the investigated RSMA precoding scheme to achieve higher spectral efficiency, we propose a CSI acquisition network (CAN) with low pilot and feedback signaling overhead, where the downlink pilot transmission, CSI feedback at the user equipments (UEs), and CSI reconstruction at the BS are modeled as an end-to-end neural network based on Transformer.
Adjusted Asymmetric Accuracy: A Well-Behaving External Cluster Validity Measure
Sep 07, 2022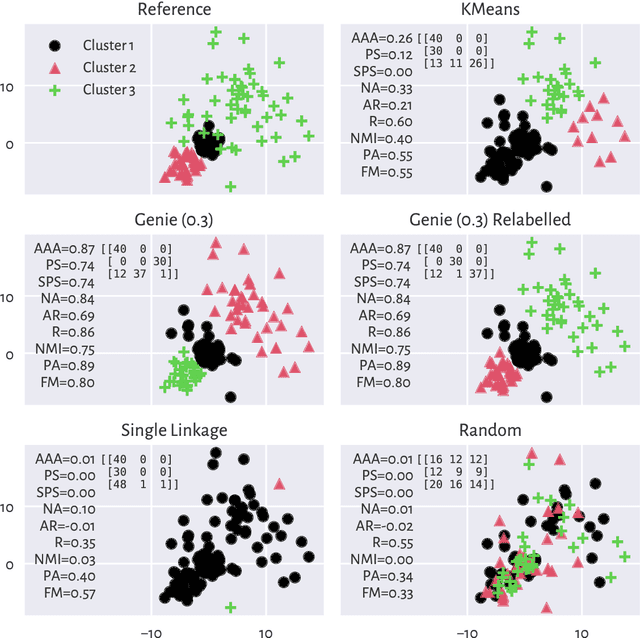
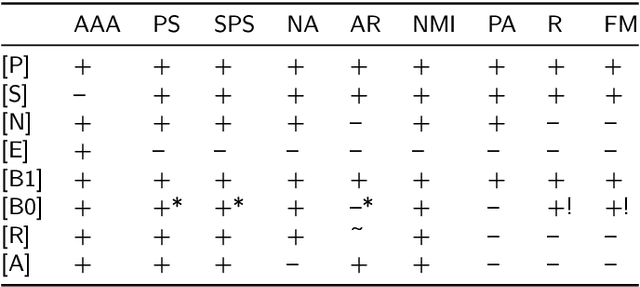
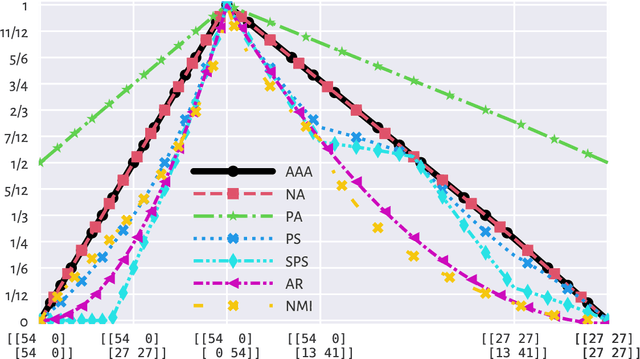
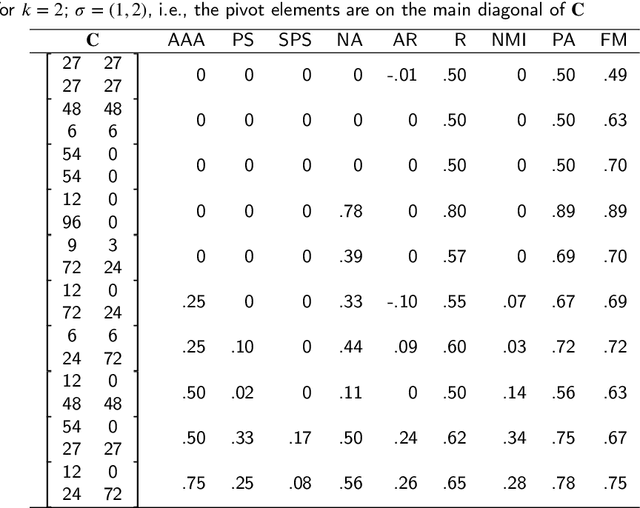
There is no, nor will there ever be, single best clustering algorithm, but we would still like to be able to pinpoint those which are well-performing on certain task types and filter out the systematically disappointing ones. Clustering algorithms are traditionally evaluated using either internal or external validity measures. Internal measures quantify different aspects of the obtained partitions, e.g., the average degree of cluster compactness or point separability. Yet, their validity is questionable because the clusterings they promote can sometimes be meaningless. External measures, on the other hand, compare the algorithms' outputs to the reference, ground truth groupings that are provided by experts. The commonly-used classical partition similarity scores, such as the normalised mutual information, Fowlkes-Mallows, or adjusted Rand index, might not possess all the desirable properties, e.g., they do not identify pathological edge cases correctly. Furthermore, they are not nicely interpretable: it is hard to say what a score of 0.8 really means. Its behaviour might also vary as the number of true clusters changes. This makes comparing clustering algorithms across many benchmark datasets difficult. To remedy this, we propose and analyse a new measure: an asymmetric version of the optimal set-matching accuracy. It is corrected for chance and the imbalancedness of cluster sizes.
Variance Reduction based Experience Replay for Policy Optimization
Aug 25, 2022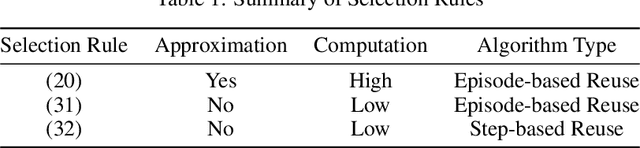
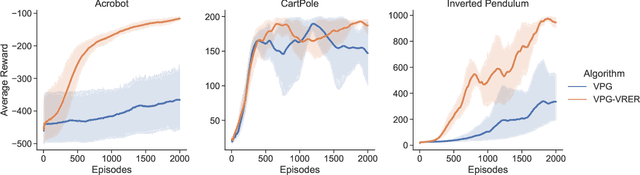
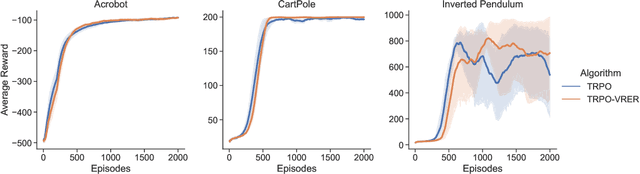
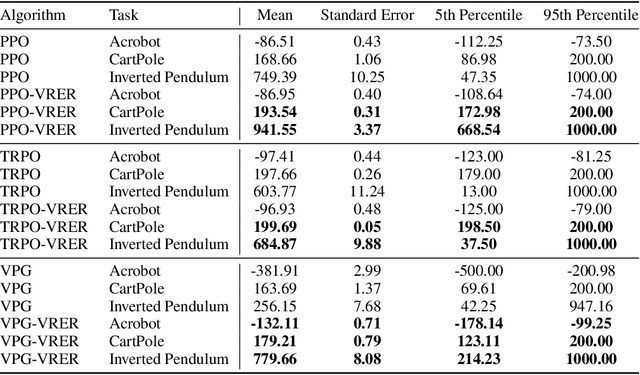
For reinforcement learning on complex stochastic systems where many factors dynamically impact the output trajectories, it is desirable to effectively leverage the information from historical samples collected in previous iterations to accelerate policy optimization. Classical experience replay allows agents to remember by reusing historical observations. However, the uniform reuse strategy that treats all observations equally overlooks the relative importance of different samples. To overcome this limitation, we propose a general variance reduction based experience replay (VRER) framework that can selectively reuse the most relevant samples to improve policy gradient estimation. This selective mechanism can adaptively put more weight on past samples that are more likely to be generated by the current target distribution. Our theoretical and empirical studies show that the proposed VRER can accelerate the learning of optimal policy and enhance the performance of state-of-the-art policy optimization approaches.
An Energy Activity Dataset for Smart Homes
Aug 29, 2022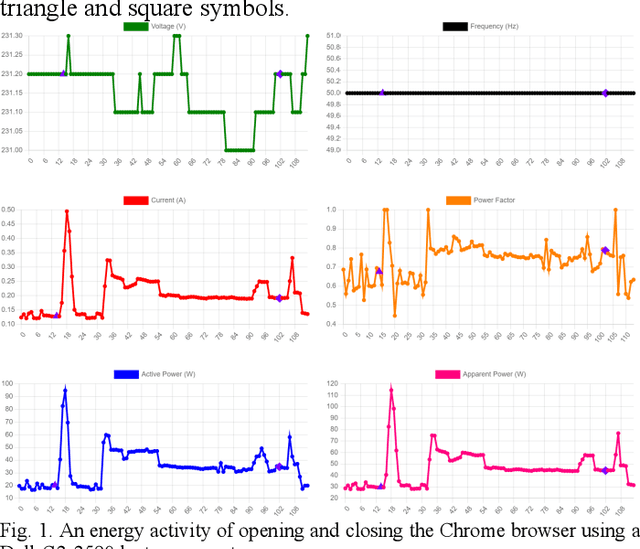
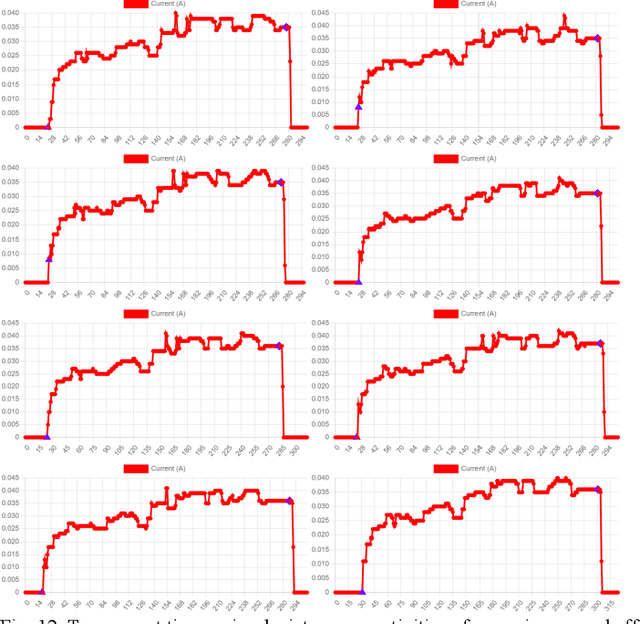
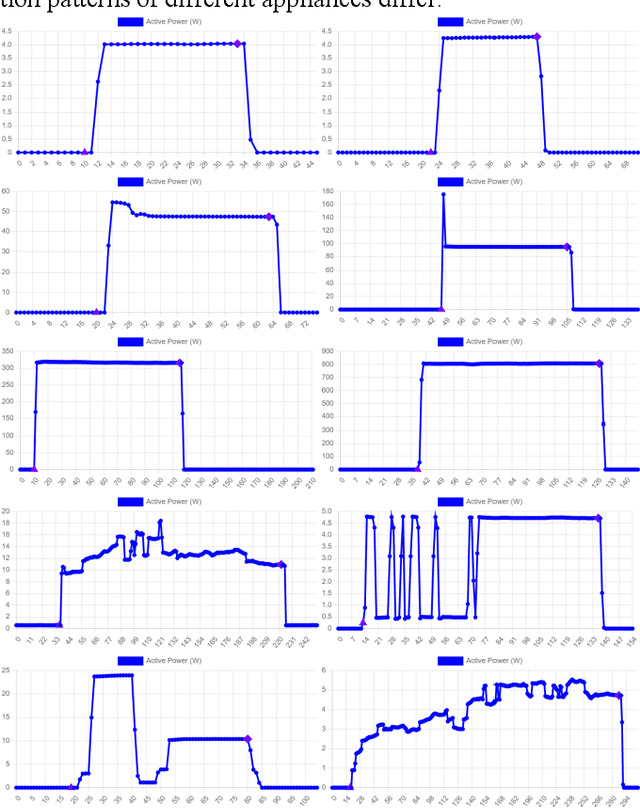
This paper provides a public energy dataset that records miscel-laneous energy usage data collected from smart homes. The pro-posed energy activity dataset (EAD) has a high data diversity in contrast to existing load monitoring datasets. In EAD, a simple data point is labeled with the appliance, brand, and event infor-mation, whereas a complex data point has an extra application label. Several discoveries have been made on the energy con-sumption patterns of various appliances operated under different events and applications. A revised longest-common-subsequence (LCS) similarity measurement algorithm is proposed to quantify the energy dataset similarities so that data quality information is provided before training deep learning models. In addition, a subsample convolutional neural network (CNN) is put forward as a flexible optical character recognition (OCR) approach to obtain energy data directly from monitors of power meters. The energy activity dataset can be downloaded from: https://drive.google.com/drive/folders/1zn0V6Q8eXXSKxKgcs8ZRValL5VEn3anD