 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Non-native Word-level Pronunciation Scoring with Phone-level Mixup Data Augmentation and Multi-source Information
Mar 01, 2022
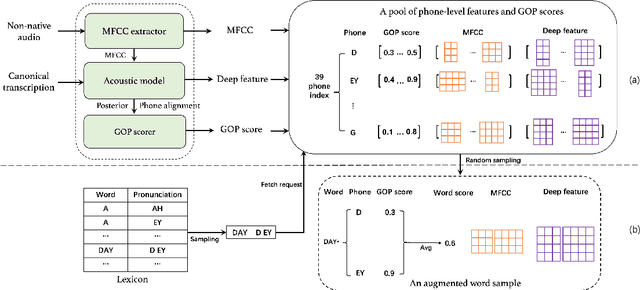

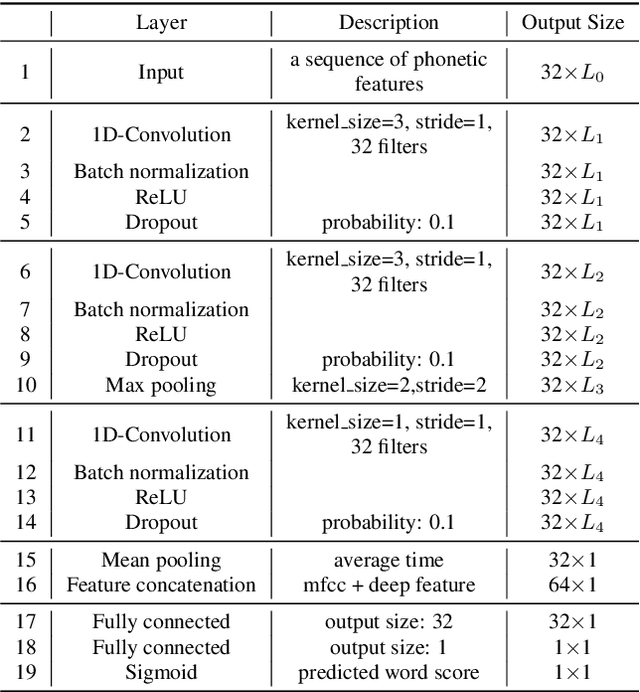
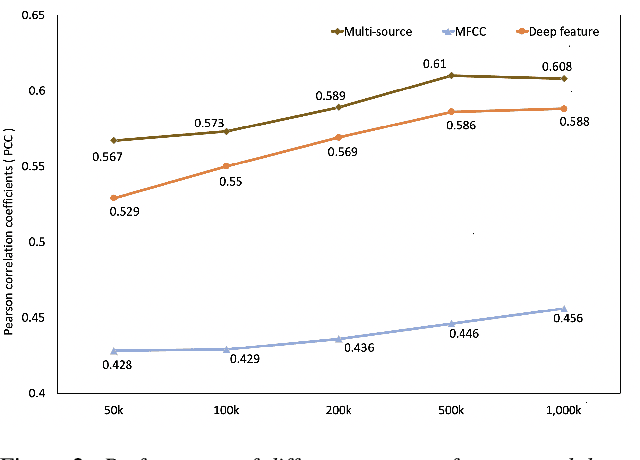
Deep learning-based pronunciation scoring models highly rely on the availability of the annotated non-native data, which is costly and has scalability issues. To deal with the data scarcity problem, data augmentation is commonly used for model pretraining. In this paper, we propose a phone-level mixup, a simple yet effective data augmentation method, to improve the performance of word-level pronunciation scoring. Specifically, given a phoneme sequence from lexicon, the artificial augmented word sample can be generated by randomly sampling from the corresponding phone-level features in training data, while the word score is the average of their GOP scores. Benefit from the arbitrary phone-level combination, the mixup is able to generate any word with various pronunciation scores. Moreover, we utilize multi-source information (e.g., MFCC and deep features) to further improve the scoring system performance. The experiments conducted on the Speechocean762 show that the proposed system outperforms the baseline by adding the mixup data for pretraining, with Pearson correlation coefficients (PCC) increasing from 0.567 to 0.61. The results also indicate that proposed method achieves similar performance by using 1/10 unlabeled data of baseline. In addition, the experimental results also demonstrate the efficiency of our proposed multi-source approach.
Is Stochastic Gradient Descent Near Optimal?
Sep 18, 2022
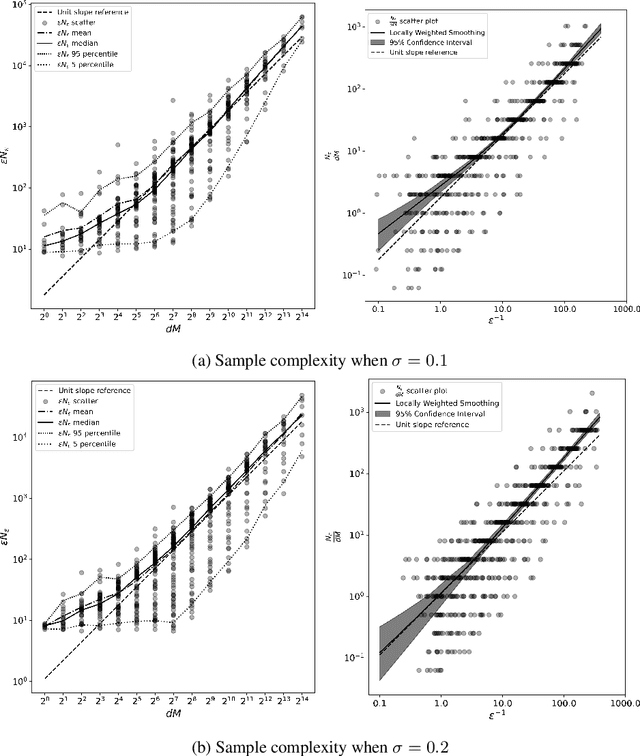

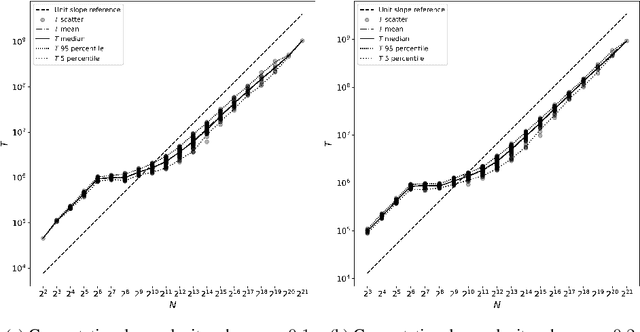
The success of neural networks over the past decade has established them as effective models for many relevant data generating processes. Statistical theory on neural networks indicates graceful scaling of sample complexity. For example, Joen & Van Roy (arXiv:2203.00246) demonstrate that, when data is generated by a ReLU teacher network with $W$ parameters, an optimal learner needs only $\tilde{O}(W/\epsilon)$ samples to attain expected error $\epsilon$. However, existing computational theory suggests that, even for single-hidden-layer teacher networks, to attain small error for all such teacher networks, the computation required to achieve this sample complexity is intractable. In this work, we fit single-hidden-layer neural networks to data generated by single-hidden-layer ReLU teacher networks with parameters drawn from a natural distribution. We demonstrate that stochastic gradient descent (SGD) with automated width selection attains small expected error with a number of samples and total number of queries both nearly linear in the input dimension and width. This suggests that SGD nearly achieves the information-theoretic sample complexity bounds of Joen & Van Roy (arXiv:2203.00246) in a computationally efficient manner. An important difference between our positive empirical results and the negative theoretical results is that the latter address worst-case error of deterministic algorithms, while our analysis centers on expected error of a stochastic algorithm.
Efficient Real-world Testing of Causal Decision Making via Bayesian Experimental Design for Contextual Optimisation
Jul 12, 2022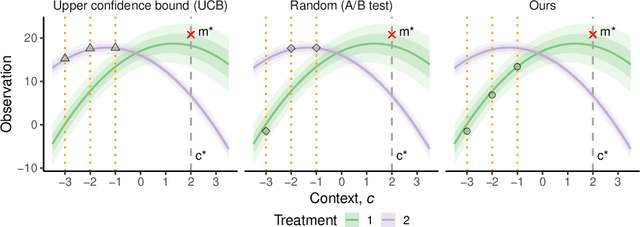
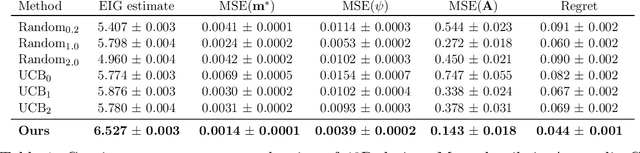
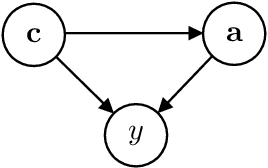
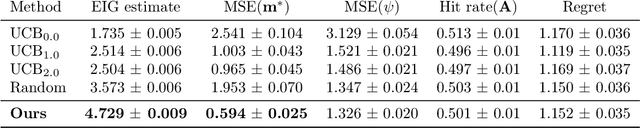
The real-world testing of decisions made using causal machine learning models is an essential prerequisite for their successful application. We focus on evaluating and improving contextual treatment assignment decisions: these are personalised treatments applied to e.g. customers, each with their own contextual information, with the aim of maximising a reward. In this paper we introduce a model-agnostic framework for gathering data to evaluate and improve contextual decision making through Bayesian Experimental Design. Specifically, our method is used for the data-efficient evaluation of the regret of past treatment assignments. Unlike approaches such as A/B testing, our method avoids assigning treatments that are known to be highly sub-optimal, whilst engaging in some exploration to gather pertinent information. We achieve this by introducing an information-based design objective, which we optimise end-to-end. Our method applies to discrete and continuous treatments. Comparing our information-theoretic approach to baselines in several simulation studies demonstrates the superior performance of our proposed approach.
CenterLineDet: Road Lane CenterLine Graph Detection With Vehicle-Mounted Sensors by Transformer for High-definition Map Creation
Sep 16, 2022



With the rapid development of autonomous vehicles, there witnesses a booming demand for high-definition maps (HD maps) that provide reliable and robust prior information of static surroundings in autonomous driving scenarios. As one of the main high-level elements in the HD map, the road lane centerline is critical for downstream tasks, such as prediction and planning. Manually annotating lane centerline HD maps by human annotators is labor-intensive, expensive and inefficient, severely restricting the wide application and fast deployment of autonomous driving systems. Previous works seldom explore the centerline HD map mapping problem due to the complicated topology and severe overlapping issues of road centerlines. In this paper, we propose a novel method named CenterLineDet to create the lane centerline HD map automatically. CenterLineDet is trained by imitation learning and can effectively detect the graph of lane centerlines by iterations with vehicle-mounted sensors. Due to the application of the DETR-like transformer network, CenterLineDet can handle complicated graph topology, such as lane intersections. The proposed approach is evaluated on a large publicly available dataset Nuscenes, and the superiority of CenterLineDet is well demonstrated by the comparison results. This paper is accompanied by a demo video and a supplementary document that are available at \url{https://tonyxuqaq.github.io/projects/CenterLineDet/}.
A Distributed Acoustic Sensor System for Intelligent Transportation using Deep Learning
Sep 13, 2022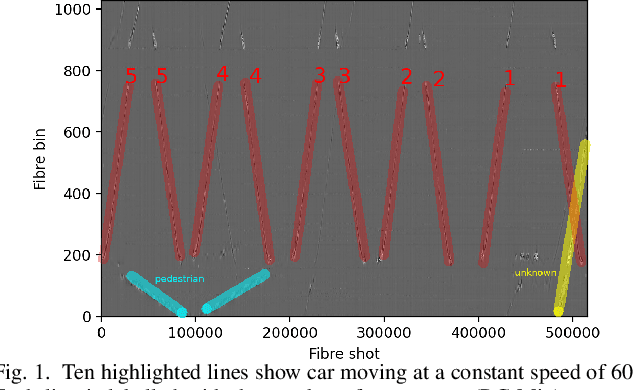
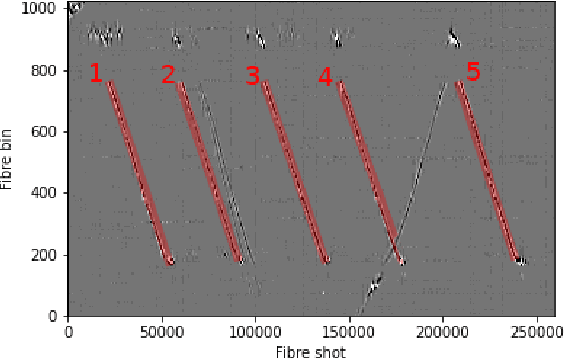
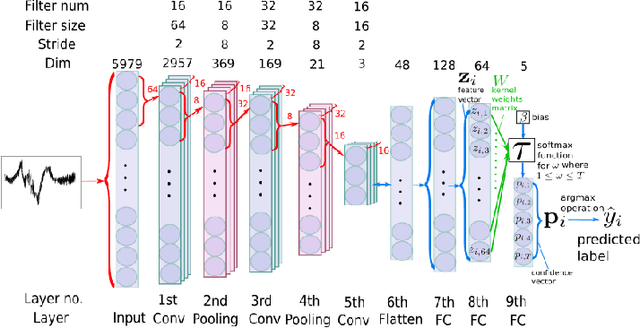
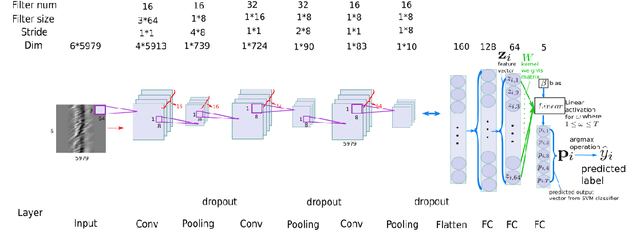
Intelligent transport systems (ITS) are pivotal in the development of sustainable and green urban living. ITS is data-driven and enabled by the profusion of sensors ranging from pneumatic tubes to smart cameras. This work explores a novel data source based on optical fibre-based distributed acoustic sensors (DAS) for traffic analysis. Detecting the type of vehicle and estimating the occupancy of vehicles are prime concerns in ITS. The first is motivated by the need for tracking, controlling, and forecasting traffic flow. The second targets the regulation of high occupancy vehicle lanes in an attempt to reduce emissions and congestion. These tasks are often conducted by individuals inspecting vehicles or through the use of emerging computer vision technologies. The former is not scale-able nor efficient whereas the latter is intrusive to passengers' privacy. To this end, we propose a deep learning technique to analyse DAS signals to address this challenge through continuous sensing and without exposing personal information. We propose a deep learning method for processing DAS signals and achieve 92% vehicle classification accuracy and 92-97% in occupancy detection based on DAS data collected under controlled conditions.
Recognizing and Extracting Cybersecurtity-relevant Entities from Text
Aug 02, 2022
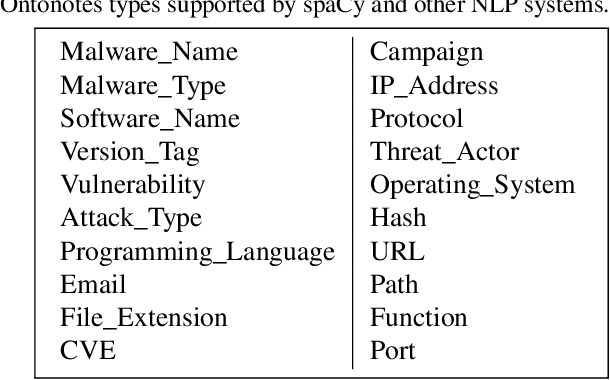
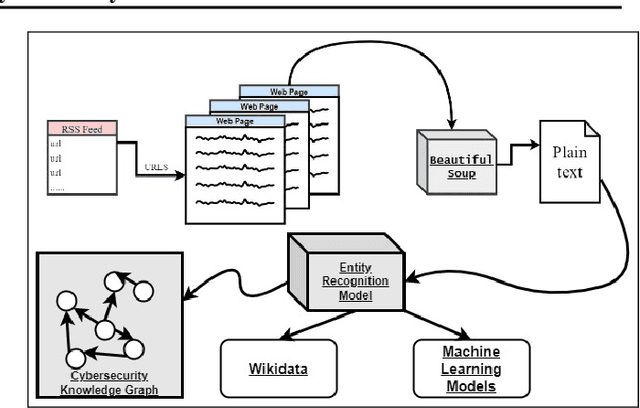
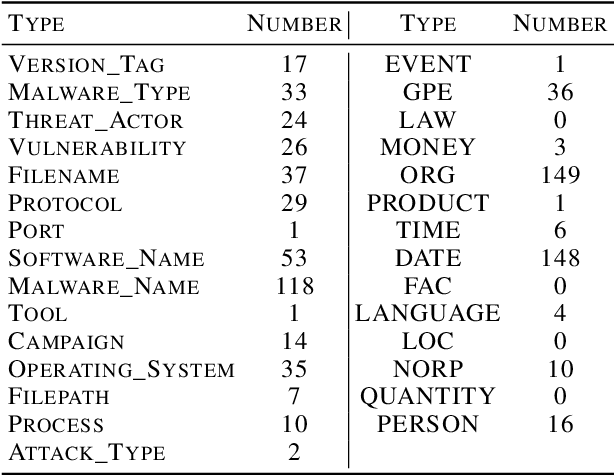
Cyber Threat Intelligence (CTI) is information describing threat vectors, vulnerabilities, and attacks and is often used as training data for AI-based cyber defense systems such as Cybersecurity Knowledge Graphs (CKG). There is a strong need to develop community-accessible datasets to train existing AI-based cybersecurity pipelines to efficiently and accurately extract meaningful insights from CTI. We have created an initial unstructured CTI corpus from a variety of open sources that we are using to train and test cybersecurity entity models using the spaCy framework and exploring self-learning methods to automatically recognize cybersecurity entities. We also describe methods to apply cybersecurity domain entity linking with existing world knowledge from Wikidata. Our future work will survey and test spaCy NLP tools and create methods for continuous integration of new information extracted from text.
Label-Only Membership Inference Attack against Node-Level Graph Neural Networks
Jul 27, 2022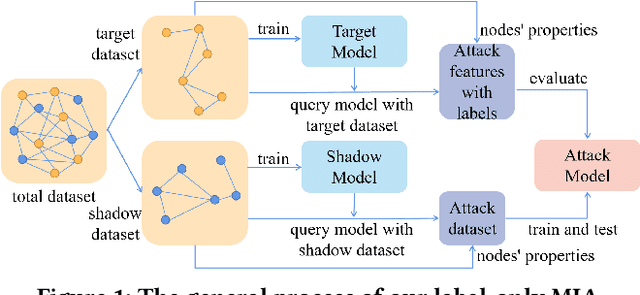
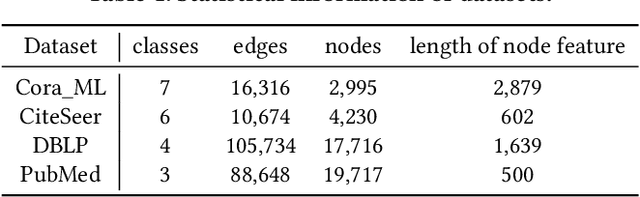
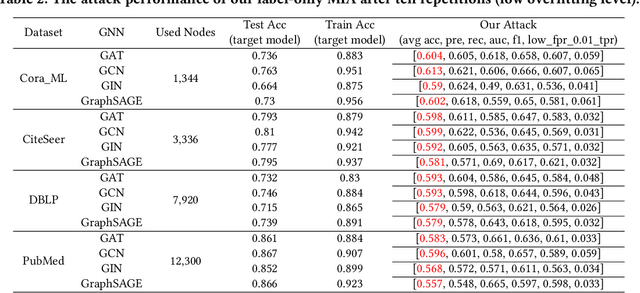
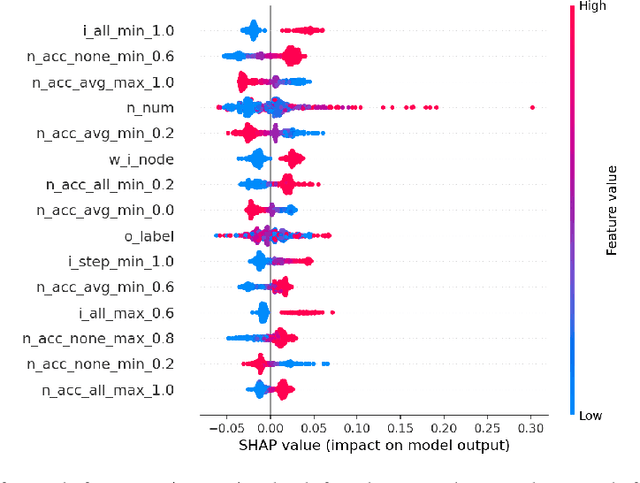
Graph Neural Networks (GNNs), inspired by Convolutional Neural Networks (CNNs), aggregate the message of nodes' neighbors and structure information to acquire expressive representations of nodes for node classification, graph classification, and link prediction. Previous studies have indicated that GNNs are vulnerable to Membership Inference Attacks (MIAs), which infer whether a node is in the training data of GNNs and leak the node's private information, like the patient's disease history. The implementation of previous MIAs takes advantage of the models' probability output, which is infeasible if GNNs only provide the prediction label (label-only) for the input. In this paper, we propose a label-only MIA against GNNs for node classification with the help of GNNs' flexible prediction mechanism, e.g., obtaining the prediction label of one node even when neighbors' information is unavailable. Our attacking method achieves around 60\% accuracy, precision, and Area Under the Curve (AUC) for most datasets and GNN models, some of which are competitive or even better than state-of-the-art probability-based MIAs implemented under our environment and settings. Additionally, we analyze the influence of the sampling method, model selection approach, and overfitting level on the attack performance of our label-only MIA. Both of those factors have an impact on the attack performance. Then, we consider scenarios where assumptions about the adversary's additional dataset (shadow dataset) and extra information about the target model are relaxed. Even in those scenarios, our label-only MIA achieves a better attack performance in most cases. Finally, we explore the effectiveness of possible defenses, including Dropout, Regularization, Normalization, and Jumping knowledge. None of those four defenses prevent our attack completely.
ReplaceBlock: An improved regularization method based on background information
Mar 30, 2022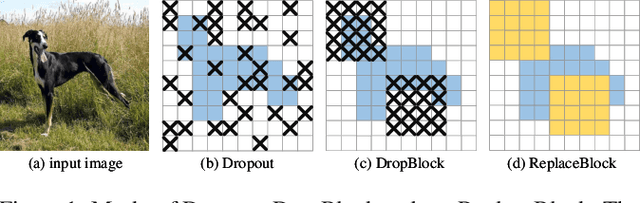
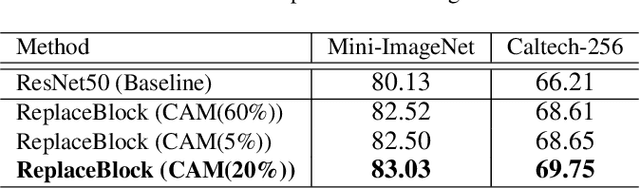
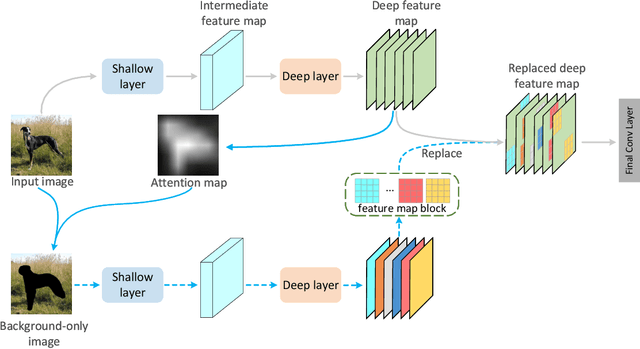
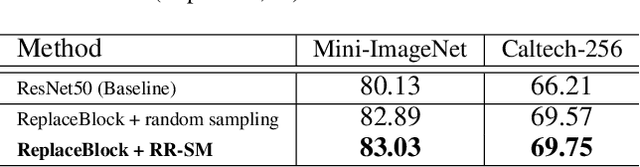
Attention mechanism, being frequently used to train networks for better feature representations, can effectively disentangle the target object from irrelevant objects in the background. Given an arbitrary image, we find that the background's irrelevant objects are most likely to occlude/block the target object. We propose, based on this finding, a ReplaceBlock to simulate the situations when the target object is partially occluded by the objects that are deemed as background. Specifically, ReplaceBlock erases the target object in the image, and then generates a feature map with only irrelevant objects and background by the model. Finally, some regions in the background feature map are used to replace some regions of the target object in the original image feature map. In this way, ReplaceBlock can effectively simulate the feature map of the occluded image. The experimental results show that ReplaceBlock works better than DropBlock in regularizing convolutional networks.
Ask Before You Act: Generalising to Novel Environments by Asking Questions
Sep 10, 2022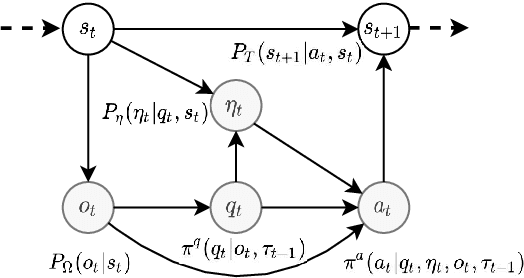
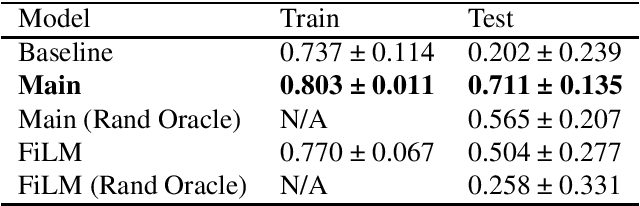

Solving temporally-extended tasks is a challenge for most reinforcement learning (RL) algorithms [arXiv:1906.07343]. We investigate the ability of an RL agent to learn to ask natural language questions as a tool to understand its environment and achieve greater generalisation performance in novel, temporally-extended environments. We do this by endowing this agent with the ability of asking "yes-no" questions to an all-knowing Oracle. This allows the agent to obtain guidance regarding the task at hand, while limiting the access to new information. To study the emergence of such natural language questions in the context of temporally-extended tasks we first train our agent in a Mini-Grid environment. We then transfer the trained agent to a different, harder environment. We observe a significant increase in generalisation performance compared to a baseline agent unable to ask questions. Through grounding its understanding of natural language in its environment, the agent can reason about the dynamics of its environment to the point that it can ask new, relevant questions when deployed in a novel environment.
Answering Numerical Reasoning Questions in Table-Text Hybrid Contents with Graph-based Encoder and Tree-based Decoder
Sep 16, 2022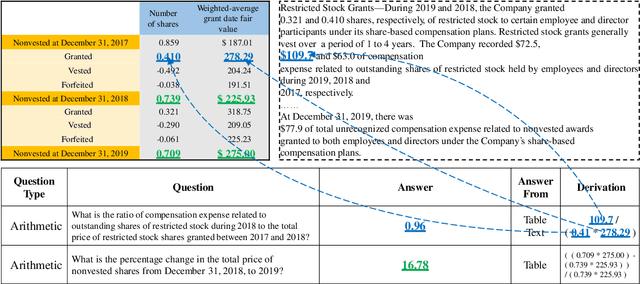
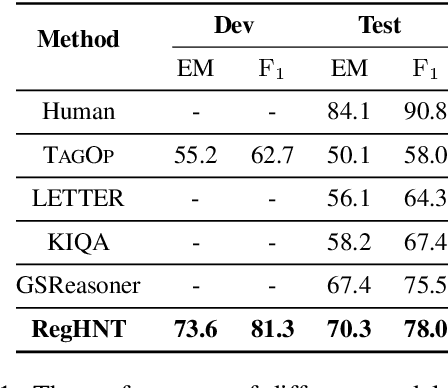
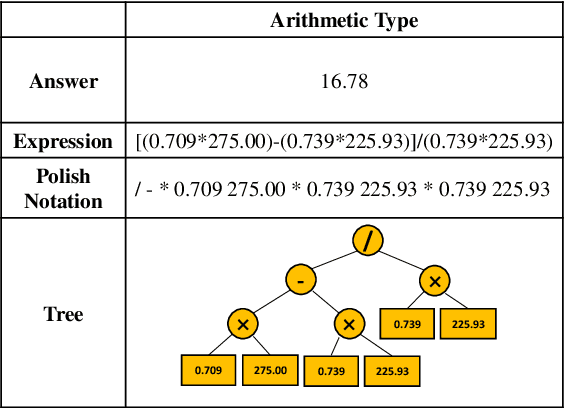
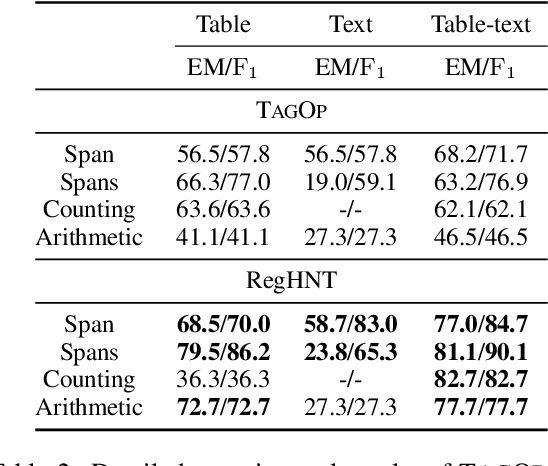
In the real-world question answering scenarios, hybrid form combining both tabular and textual contents has attracted more and more attention, among which numerical reasoning problem is one of the most typical and challenging problems. Existing methods usually adopt encoder-decoder framework to represent hybrid contents and generate answers. However, it can not capture the rich relationship among numerical value, table schema, and text information on the encoder side. The decoder uses a simple predefined operator classifier which is not flexible enough to handle numerical reasoning processes with diverse expressions. To address these problems, this paper proposes a \textbf{Re}lational \textbf{G}raph enhanced \textbf{H}ybrid table-text \textbf{N}umerical reasoning model with \textbf{T}ree decoder (\textbf{RegHNT}). It models the numerical question answering over table-text hybrid contents as an expression tree generation task. Moreover, we propose a novel relational graph modeling method, which models alignment between questions, tables, and paragraphs. We validated our model on the publicly available table-text hybrid QA benchmark (TAT-QA). The proposed RegHNT significantly outperform the baseline model and achieve state-of-the-art results\footnote{We openly released the source code and data at~\url{https://github.com/lfy79001/RegHNT}}~(2022-05-05).