 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Digital Image Processing Applied To Object Segmentation By Intensity And Motion
Aug 26, 2022
The current technological development allows us to carry out tasks that some time ago were unthinkable if not impossible, digital image processing has been one of the major constants of development today, taking into account that its implementation dates from a short time ago, OpenCV [1] is a tool focused on machine vision, In this case implemented in an object-oriented programming platform based on Java language offered by the NetBeans development software, based on the above, a physical platform was proposed and implemented as a closed environment which through the development of an algorithm allowed detection and segmentation of objects by means of the RGB color model; In future works this algorithm will provide the information base for the autonomous robotic platform; this advance opens a wide spectrum for the development of applications and tools in the field of artificial vision.
A taxonomy of surprise definitions
Sep 02, 2022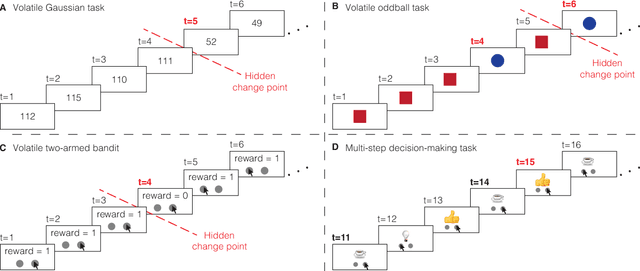
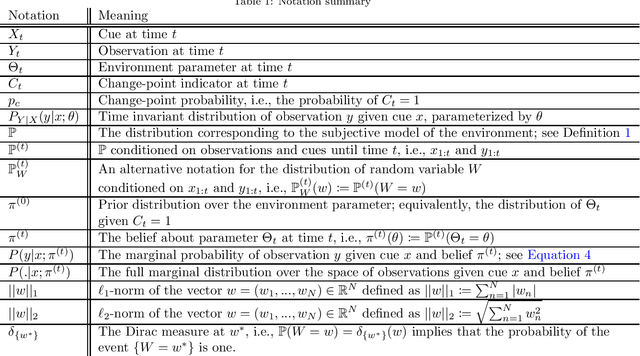
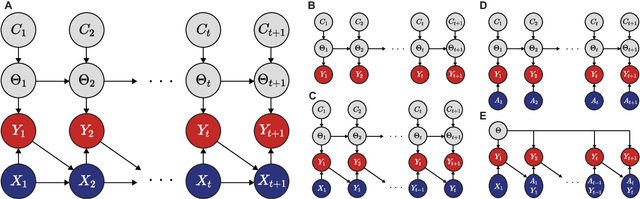

Surprising events trigger measurable brain activity and influence human behavior by affecting learning, memory, and decision-making. Currently there is, however, no consensus on the definition of surprise. Here we identify 18 mathematical definitions of surprise in a unifying framework. We first propose a technical classification of these definitions into three groups based on their dependence on an agent's belief, show how they relate to each other, and prove under what conditions they are indistinguishable. Going beyond this technical analysis, we propose a taxonomy of surprise definitions and classify them into four conceptual categories based on the quantity they measure: (i) 'prediction surprise' measures a mismatch between a prediction and an observation; (ii) 'change-point detection surprise' measures the probability of a change in the environment; (iii) 'confidence-corrected surprise' explicitly accounts for the effect of confidence; and (iv) 'information gain surprise' measures the belief-update upon a new observation. The taxonomy poses the foundation for principled studies of the functional roles and physiological signatures of surprise in the brain.
Information Extraction from Visually Rich Documents with Font Style Embeddings
Nov 07, 2021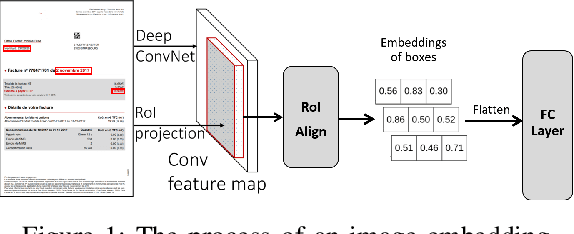
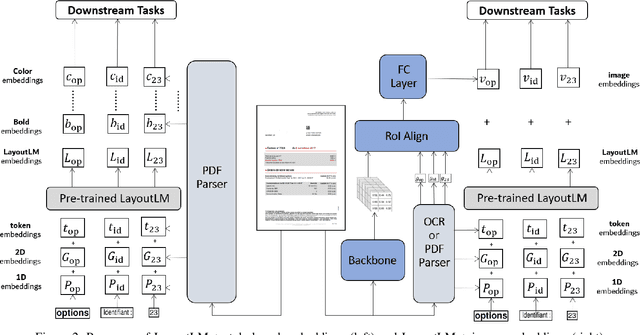

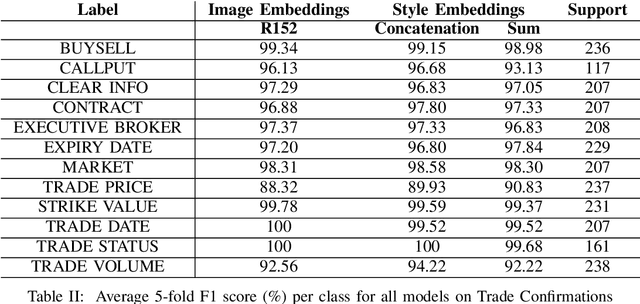
Information extraction (IE) from documents is an intensive area of research with a large set of industrial applications. Current state-of-the-art methods focus on scanned documents with approaches combining computer vision, natural language processing and layout representation. We propose to challenge the usage of computer vision in the case where both token style and visual representation are available (i.e native PDF documents). Our experiments on three real-world complex datasets demonstrate that using token style attributes based embedding instead of a raw visual embedding in LayoutLM model is beneficial. Depending on the dataset, such an embedding yields an improvement of 0.18% to 2.29% in the weighted F1-score with a decrease of 30.7% in the final number of trainable parameters of the model, leading to an improvement in both efficiency and effectiveness.
Improving Fine-tuning of Self-supervised Models with Contrastive Initialization
Jul 30, 2022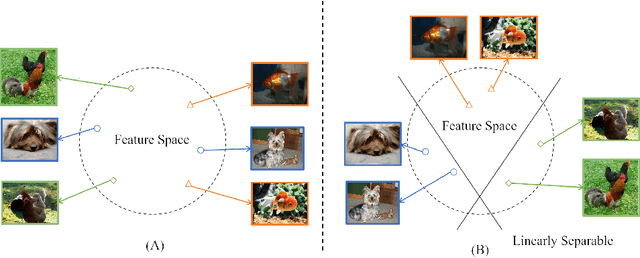
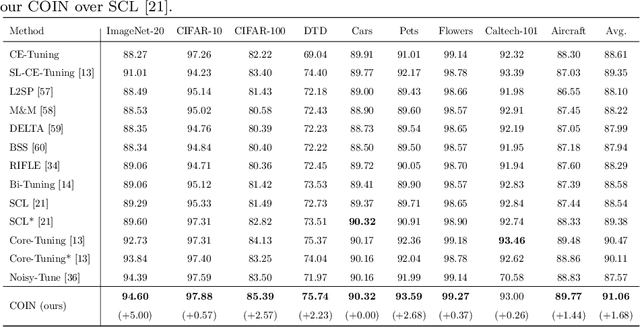
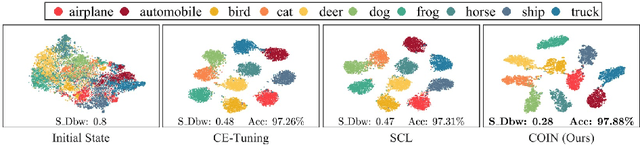
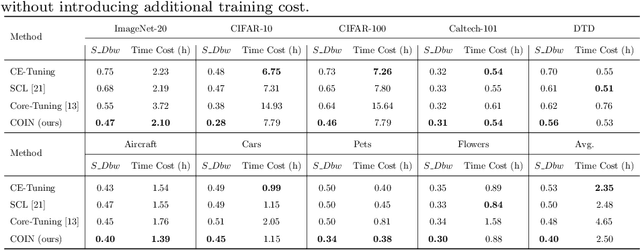
Self-supervised learning (SSL) has achieved remarkable performance in pretraining the models that can be further used in downstream tasks via fine-tuning. However, these self-supervised models may not capture meaningful semantic information since the images belonging to the same class are always regarded as negative pairs in the contrastive loss. Consequently, the images of the same class are often located far away from each other in learned feature space, which would inevitably hamper the fine-tuning process. To address this issue, we seek to provide a better initialization for the self-supervised models by enhancing the semantic information. To this end, we propose a Contrastive Initialization (COIN) method that breaks the standard fine-tuning pipeline by introducing an extra initialization stage before fine-tuning. Extensive experiments show that, with the enriched semantics, our COIN significantly outperforms existing methods without introducing extra training cost and sets new state-of-the-arts on multiple downstream tasks.
Active Learning for Non-Parametric Choice Models
Aug 05, 2022


We study the problem of actively learning a non-parametric choice model based on consumers' decisions. We present a negative result showing that such choice models may not be identifiable. To overcome the identifiability problem, we introduce a directed acyclic graph (DAG) representation of the choice model, which in a sense captures as much information about the choice model as could information-theoretically be identified. We then consider the problem of learning an approximation to this DAG representation in an active-learning setting. We design an efficient active-learning algorithm to estimate the DAG representation of the non-parametric choice model, which runs in polynomial time when the set of frequent rankings is drawn uniformly at random. Our algorithm learns the distribution over the most popular items of frequent preferences by actively and repeatedly offering assortments of items and observing the item chosen. We show that our algorithm can better recover a set of frequent preferences on both a synthetic and publicly available dataset on consumers' preferences, compared to the corresponding non-active learning estimation algorithms. This demonstrates the value of our algorithm and active-learning approaches more generally.
Mapping the ocular surface from monocular videos with an application to dry eye disease grading
Sep 05, 2022With a prevalence of 5 to 50%, Dry Eye Disease (DED) is one of the leading reasons for ophthalmologist consultations. The diagnosis and quantification of DED usually rely on ocular surface analysis through slit-lamp examinations. However, evaluations are subjective and non-reproducible. To improve the diagnosis, we propose to 1) track the ocular surface in 3-D using video recordings acquired during examinations, and 2) grade the severity using registered frames. Our registration method uses unsupervised image-to-depth learning. These methods learn depth from lights and shadows and estimate pose based on depth maps. However, DED examinations undergo unresolved challenges including a moving light source, transparent ocular tissues, etc. To overcome these and estimate the ego-motion, we implement joint CNN architectures with multiple losses incorporating prior known information, namely the shape of the eye, through semantic segmentation as well as sphere fitting. The achieved tracking errors outperform the state-of-the-art, with a mean Euclidean distance as low as 0.48% of the image width on our test set. This registration improves the DED severity classification by a 0.20 AUC difference. The proposed approach is the first to address DED diagnosis with supervision from monocular videos
M^4I: Multi-modal Models Membership Inference
Sep 15, 2022
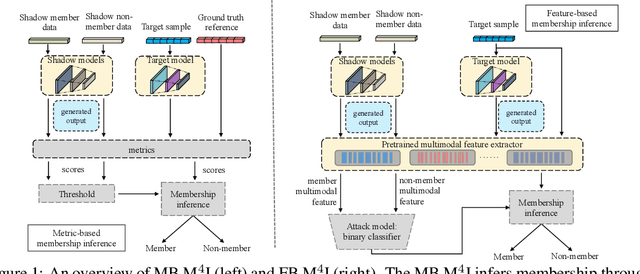
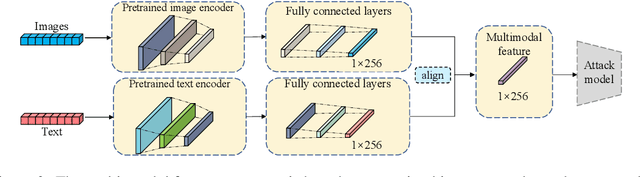
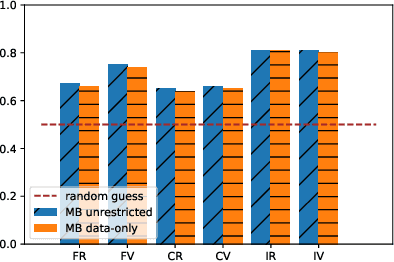
With the development of machine learning techniques, the attention of research has been moved from single-modal learning to multi-modal learning, as real-world data exist in the form of different modalities. However, multi-modal models often carry more information than single-modal models and they are usually applied in sensitive scenarios, such as medical report generation or disease identification. Compared with the existing membership inference against machine learning classifiers, we focus on the problem that the input and output of the multi-modal models are in different modalities, such as image captioning. This work studies the privacy leakage of multi-modal models through the lens of membership inference attack, a process of determining whether a data record involves in the model training process or not. To achieve this, we propose Multi-modal Models Membership Inference (M^4I) with two attack methods to infer the membership status, named metric-based (MB) M^4I and feature-based (FB) M^4I, respectively. More specifically, MB M^4I adopts similarity metrics while attacking to infer target data membership. FB M^4I uses a pre-trained shadow multi-modal feature extractor to achieve the purpose of data inference attack by comparing the similarities from extracted input and output features. Extensive experimental results show that both attack methods can achieve strong performances. Respectively, 72.5% and 94.83% of attack success rates on average can be obtained under unrestricted scenarios. Moreover, we evaluate multiple defense mechanisms against our attacks. The source code of M^4I attacks is publicly available at https://github.com/MultimodalMI/Multimodal-membership-inference.git.
Exploring and Exploiting Multi-Granularity Representations for Machine Reading Comprehension
Aug 18, 2022
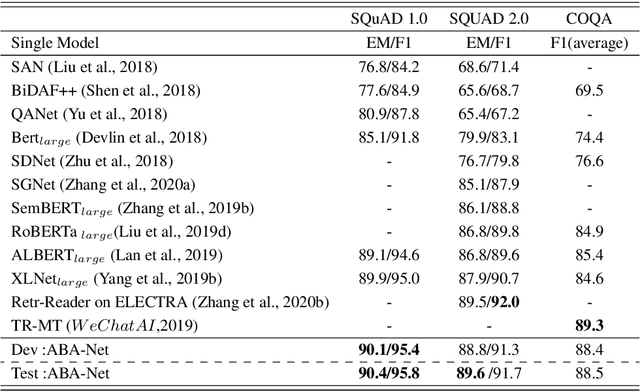
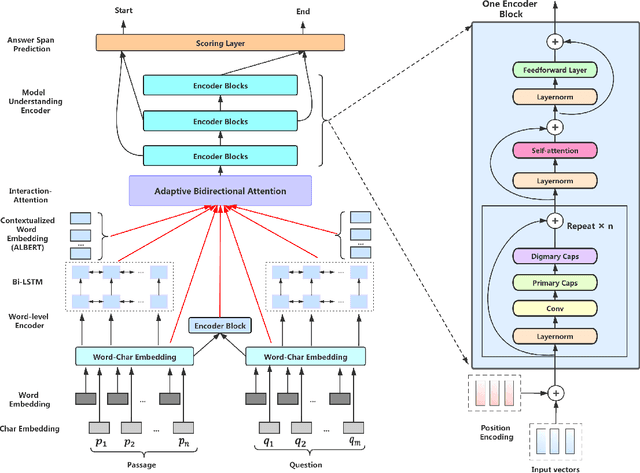

Recently, the attention-enhanced multi-layer encoder, such as Transformer, has been extensively studied in Machine Reading Comprehension (MRC). To predict the answer, it is common practice to employ a predictor to draw information only from the final encoder layer which generates the coarse-grained representations of the source sequences, i.e., passage and question. The analysis shows that the representation of source sequence becomes more coarse-grained from finegrained as the encoding layer increases. It is generally believed that with the growing number of layers in deep neural networks, the encoding process will gather relevant information for each location increasingly, resulting in more coarse-grained representations, which adds the likelihood of similarity to other locations (referring to homogeneity). Such phenomenon will mislead the model to make wrong judgement and degrade the performance. In this paper, we argue that it would be better if the predictor could exploit representations of different granularity from the encoder, providing different views of the source sequences, such that the expressive power of the model could be fully utilized. To this end, we propose a novel approach called Adaptive Bidirectional Attention-Capsule Network (ABA-Net), which adaptively exploits the source representations of different levels to the predictor. Furthermore, due to the better representations are at the core for boosting MRC performance, the capsule network and self-attention module are carefully designed as the building blocks of our encoders, which provides the capability to explore the local and global representations, respectively. Experimental results on three benchmark datasets, i.e., SQuAD 1.0, SQuAD 2.0 and COQA, demonstrate the effectiveness of our approach. In particular, we set the new state-of-the-art performance on the SQuAD 1.0 dataset
Intrusion Detection Systems Using Support Vector Machines on the KDDCUP'99 and NSL-KDD Datasets: A Comprehensive Survey
Sep 12, 2022With the growing rates of cyber-attacks and cyber espionage, the need for better and more powerful intrusion detection systems (IDS) is even more warranted nowadays. The basic task of an IDS is to act as the first line of defense, in detecting attacks on the internet. As intrusion tactics from intruders become more sophisticated and difficult to detect, researchers have started to apply novel Machine Learning (ML) techniques to effectively detect intruders and hence preserve internet users' information and overall trust in the entire internet network security. Over the last decade, there has been an explosion of research on intrusion detection techniques based on ML and Deep Learning (DL) architectures on various cyber security-based datasets such as the DARPA, KDDCUP'99, NSL-KDD, CAIDA, CTU-13, UNSW-NB15. In this research, we review contemporary literature and provide a comprehensive survey of different types of intrusion detection technique that applies Support Vector Machines (SVMs) algorithms as a classifier. We focus only on studies that have been evaluated on the two most widely used datasets in cybersecurity namely: the KDDCUP'99 and the NSL-KDD datasets. We provide a summary of each method, identifying the role of the SVMs classifier, and all other algorithms involved in the studies. Furthermore, we present a critical review of each method, in tabular form, highlighting the performance measures, strengths, and limitations of each of the methods surveyed.
Graph Distance Neural Networks for Predicting Multiple Drug Interactions
Aug 30, 2022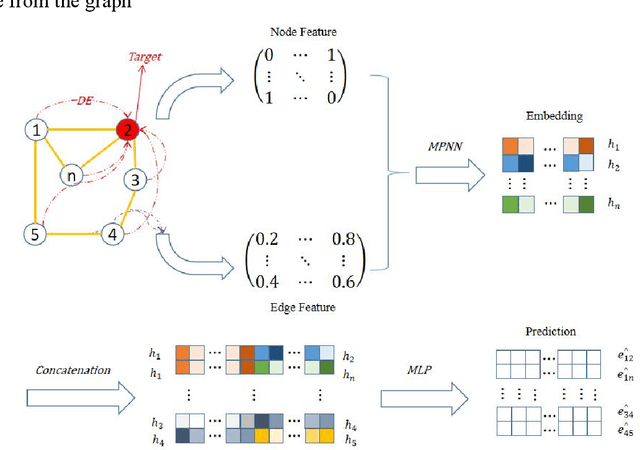
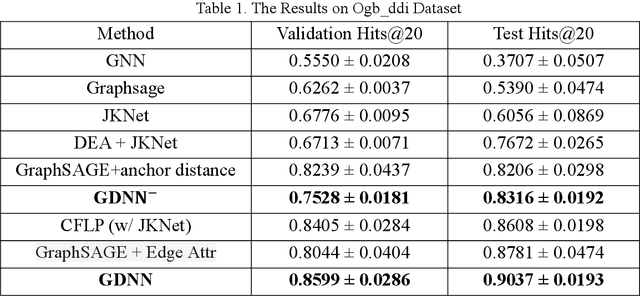
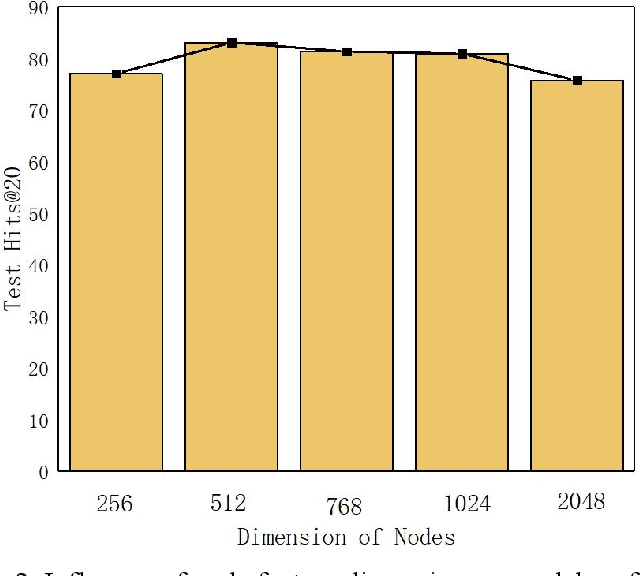
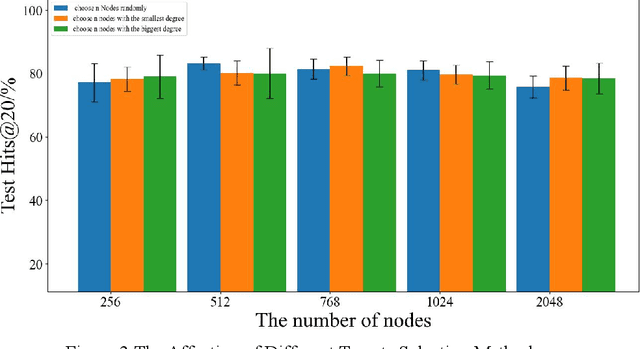
Since multidrug combination is widely applied, the accurate prediction of drug-drug interaction (DDI) is becoming more and more critical. In our method, we use graph to represent drug-drug interaction: nodes represent drug; edges represent drug-drug interactions. Based on our assumption, we convert the prediction of DDI to link prediction problem, utilizing known drug node characteristics and DDI types to predict unknown DDI types. This work proposes a Graph Distance Neural Network (GDNN) to predict drug-drug interactions. Firstly, GDNN generates initial features for nodes via target point method, fully including the distance information in the graph. Secondly, GDNN adopts an improved message passing framework to better generate each drug node embedded expression, comprehensively considering the nodes and edges characteristics synchronously. Thirdly, GDNN aggregates the embedded expressions, undergoing MLP processing to generate the final predicted drug interaction type. GDNN achieved Test Hits@20=0.9037 on the ogb-ddi dataset, proving GDNN can predict DDI efficiently.