 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Perturbation-Based Gradient Estimation for Discrete Latent Variable Models
Sep 11, 2022
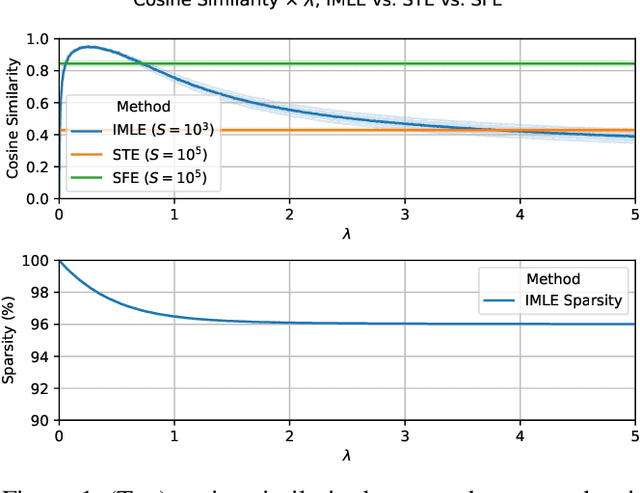
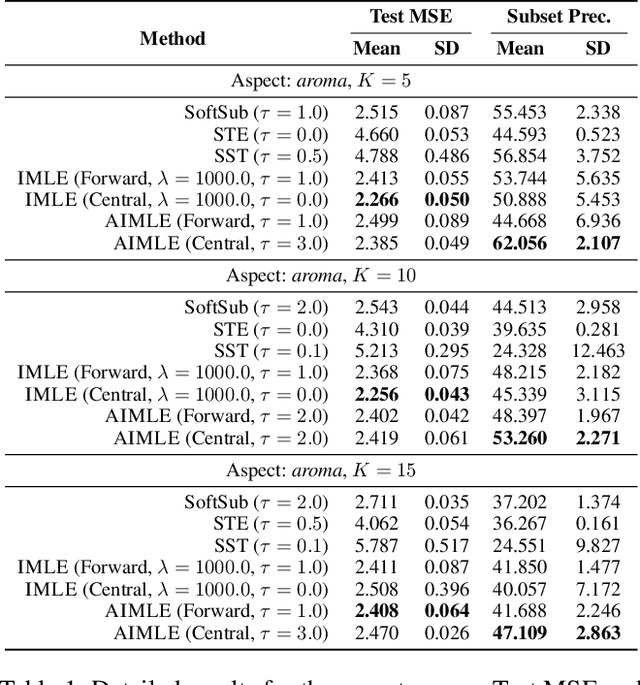
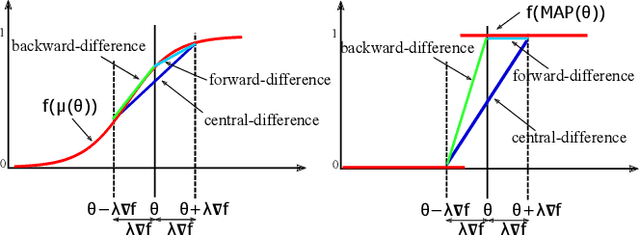

The integration of discrete algorithmic components in deep learning architectures has numerous applications. Recently, Implicit Maximum Likelihood Estimation (IMLE, Niepert, Minervini, and Franceschi 2021), a class of gradient estimators for discrete exponential family distributions, was proposed by combining implicit differentiation through perturbation with the path-wise gradient estimator. However, due to the finite difference approximation of the gradients, it is especially sensitive to the choice of the finite difference step size which needs to be specified by the user. In this work, we present Adaptive IMLE (AIMLE) the first adaptive gradient estimator for complex discrete distributions: it adaptively identifies the target distribution for IMLE by trading off the density of gradient information with the degree of bias in the gradient estimates. We empirically evaluate our estimator on synthetic examples, as well as on Learning to Explain, Discrete Variational Auto-Encoders, and Neural Relational Inference tasks. In our experiments, we show that our adaptive gradient estimator can produce faithful estimates while requiring orders of magnitude fewer samples than other gradient estimators.
CRAFT: Camera-Radar 3D Object Detection with Spatio-Contextual Fusion Transformer
Sep 14, 2022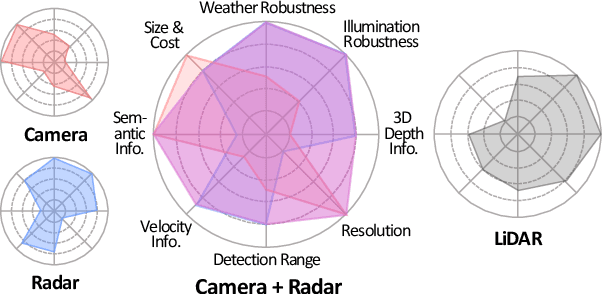
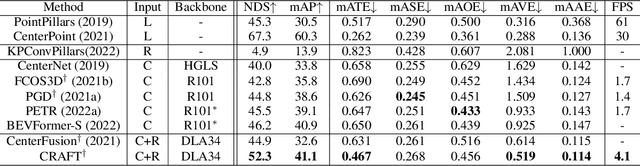
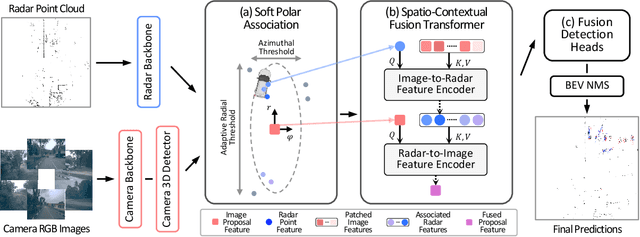

Camera and radar sensors have significant advantages in cost, reliability, and maintenance compared to LiDAR. Existing fusion methods often fuse the outputs of single modalities at the result-level, called the late fusion strategy. This can benefit from using off-the-shelf single sensor detection algorithms, but late fusion cannot fully exploit the complementary properties of sensors, thus having limited performance despite the huge potential of camera-radar fusion. Here we propose a novel proposal-level early fusion approach that effectively exploits both spatial and contextual properties of camera and radar for 3D object detection. Our fusion framework first associates image proposal with radar points in the polar coordinate system to efficiently handle the discrepancy between the coordinate system and spatial properties. Using this as a first stage, following consecutive cross-attention based feature fusion layers adaptively exchange spatio-contextual information between camera and radar, leading to a robust and attentive fusion. Our camera-radar fusion approach achieves the state-of-the-art 41.1% mAP and 52.3% NDS on the nuScenes test set, which is 8.7 and 10.8 points higher than the camera-only baseline, as well as yielding competitive performance on the LiDAR method.
Microwave QR Code: An IRS-Based Solution
Aug 05, 2022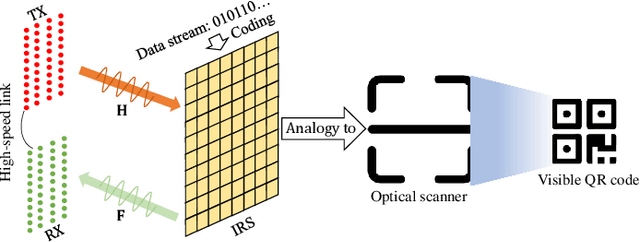
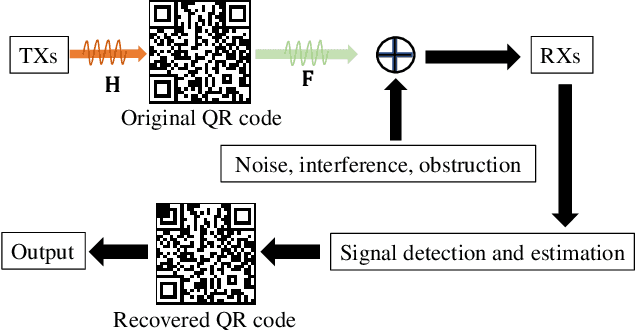
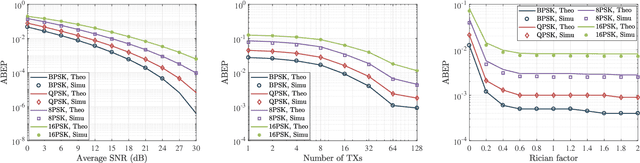
This letter proposes to employ intelligent reflecting surface (IRS) as an information media to display a microwave quick response (QR) code for Internet-of-Things applications. To be specific, an IRS is used to form a dynamic bitmap image thanks to its tunable elements. With a QR code shown on the IRS, the transmitting and receiving antenna arrays are jointly designed to scan it by radiating electromagnetic wave as well as receiving and detecting the reflected signal. Based on such an idea, an IRS enabled information and communication system is modelled. Accordingly, some fundamental systematic operating mechanisms are investigated, involving derivation of average bit error probability for signal modulation, QR code implementation on an IRS, transmission design, detection, etc. The simulations are performed to show the achievable communication performance of system and confirm the feasibility of IRS-based microwave QR code.
Hierarchical Graph Pooling is an Effective Citywide Traffic Condition Prediction Model
Sep 08, 2022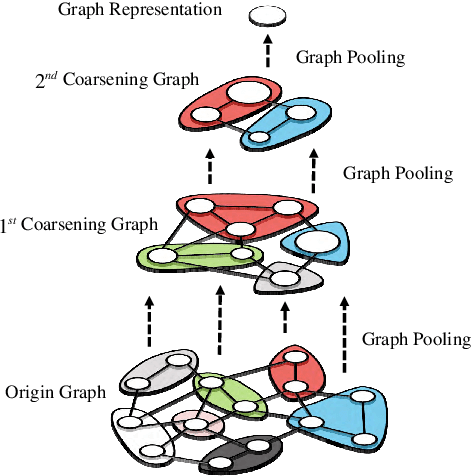
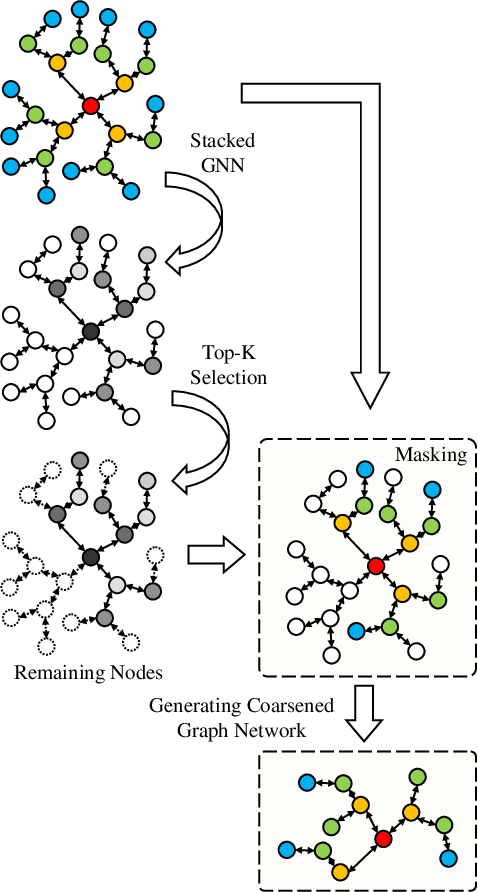
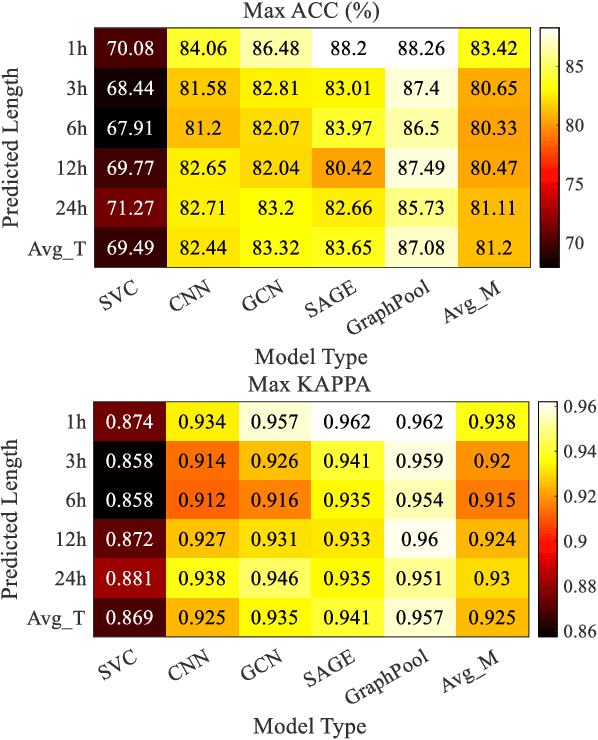
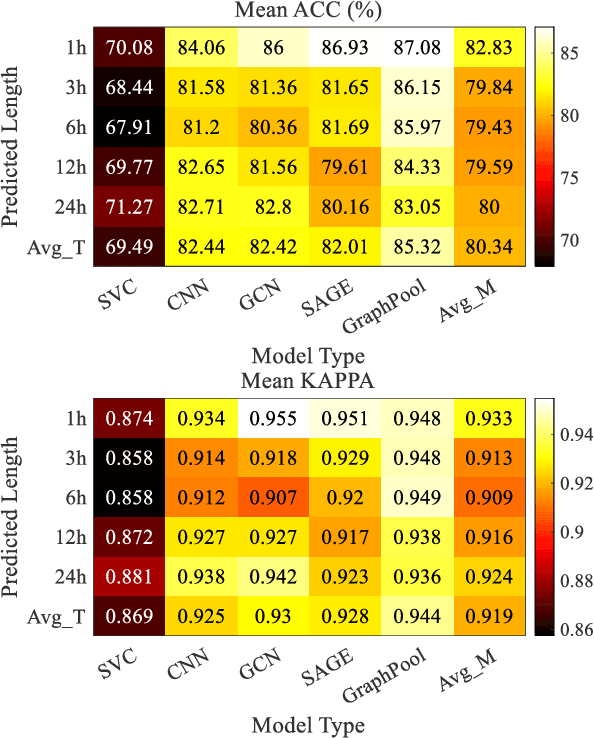
Accurate traffic conditions prediction provides a solid foundation for vehicle-environment coordination and traffic control tasks. Because of the complexity of road network data in spatial distribution and the diversity of deep learning methods, it becomes challenging to effectively define traffic data and adequately capture the complex spatial nonlinear features in the data. This paper applies two hierarchical graph pooling approaches to the traffic prediction task to reduce graph information redundancy. First, this paper verifies the effectiveness of hierarchical graph pooling methods in traffic prediction tasks. The hierarchical graph pooling methods are contrasted with the other baselines on predictive performance. Second, two mainstream hierarchical graph pooling methods, node clustering pooling and node drop pooling, are applied to analyze advantages and weaknesses in traffic prediction. Finally, for the mentioned graph neural networks, this paper compares the predictive effects of different graph network inputs on traffic prediction accuracy. The efficient ways of defining graph networks are analyzed and summarized.
Extracting Medication Changes in Clinical Narratives using Pre-trained Language Models
Aug 17, 2022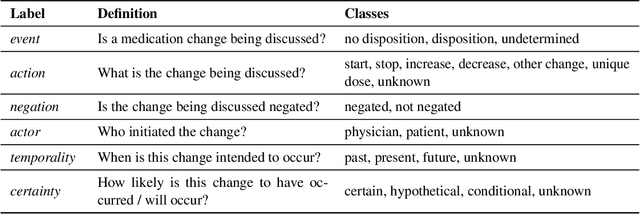
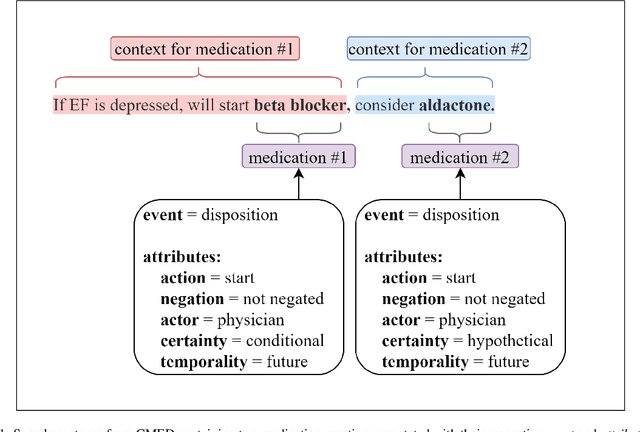
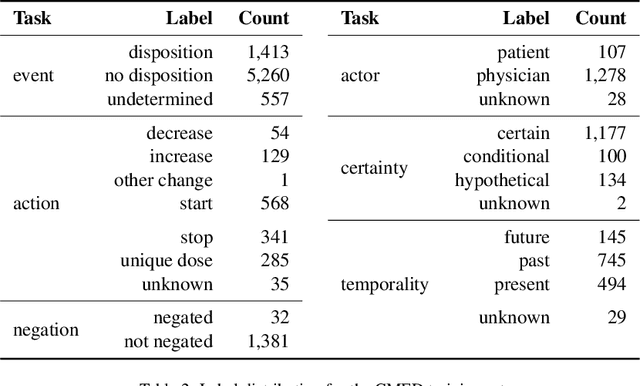
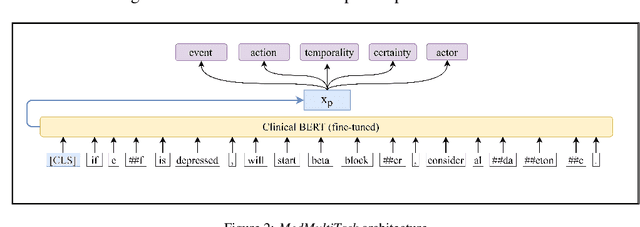
An accurate and detailed account of patient medications, including medication changes within the patient timeline, is essential for healthcare providers to provide appropriate patient care. Healthcare providers or the patients themselves may initiate changes to patient medication. Medication changes take many forms, including prescribed medication and associated dosage modification. These changes provide information about the overall health of the patient and the rationale that led to the current care. Future care can then build on the resulting state of the patient. This work explores the automatic extraction of medication change information from free-text clinical notes. The Contextual Medication Event Dataset (CMED) is a corpus of clinical notes with annotations that characterize medication changes through multiple change-related attributes, including the type of change (start, stop, increase, etc.), initiator of the change, temporality, change likelihood, and negation. Using CMED, we identify medication mentions in clinical text and propose three novel high-performing BERT-based systems that resolve the annotated medication change characteristics. We demonstrate that our proposed architectures improve medication change classification performance over the initial work exploring CMED. We identify medication mentions with high performance at 0.959 F1, and our proposed systems classify medication changes and their attributes at an overall average of 0.827 F1.
Summarizing Patients Problems from Hospital Progress Notes Using Pre-trained Sequence-to-Sequence Models
Aug 17, 2022

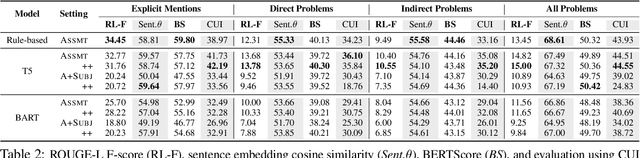

Automatically summarizing patients' main problems from daily progress notes using natural language processing methods helps to battle against information and cognitive overload in hospital settings and potentially assists providers with computerized diagnostic decision support. Problem list summarization requires a model to understand, abstract, and generate clinical documentation. In this work, we propose a new NLP task that aims to generate a list of problems in a patient's daily care plan using input from the provider's progress notes during hospitalization. We investigate the performance of T5 and BART, two state-of-the-art seq2seq transformer architectures, in solving this problem. We provide a corpus built on top of progress notes from publicly available electronic health record progress notes in the Medical Information Mart for Intensive Care (MIMIC)-III. T5 and BART are trained on general domain text, and we experiment with a data augmentation method and a domain adaptation pre-training method to increase exposure to medical vocabulary and knowledge. Evaluation methods include ROUGE, BERTScore, cosine similarity on sentence embedding, and F-score on medical concepts. Results show that T5 with domain adaptive pre-training achieves significant performance gains compared to a rule-based system and general domain pre-trained language models, indicating a promising direction for tackling the problem summarization task.
Anomaly Detection in Aerial Videos with Transformers
Sep 25, 2022

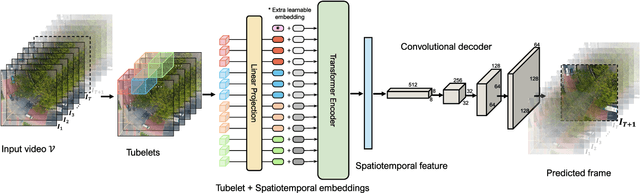
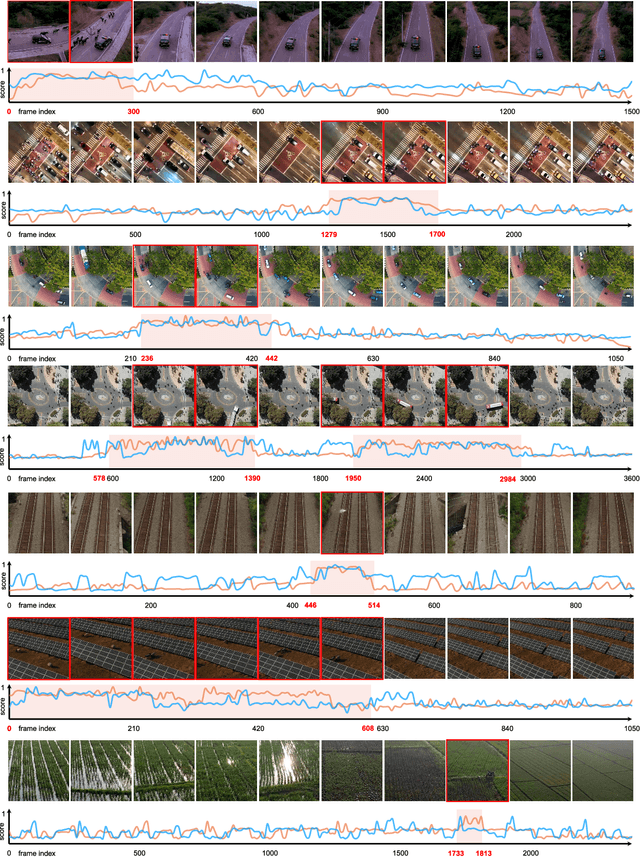
Unmanned aerial vehicles (UAVs) are widely applied for purposes of inspection, search, and rescue operations by the virtue of low-cost, large-coverage, real-time, and high-resolution data acquisition capacities. Massive volumes of aerial videos are produced in these processes, in which normal events often account for an overwhelming proportion. It is extremely difficult to localize and extract abnormal events containing potentially valuable information from long video streams manually. Therefore, we are dedicated to developing anomaly detection methods to solve this issue. In this paper, we create a new dataset, named DroneAnomaly, for anomaly detection in aerial videos. This dataset provides 37 training video sequences and 22 testing video sequences from 7 different realistic scenes with various anomalous events. There are 87,488 color video frames (51,635 for training and 35,853 for testing) with the size of $640 \times 640$ at 30 frames per second. Based on this dataset, we evaluate existing methods and offer a benchmark for this task. Furthermore, we present a new baseline model, ANomaly Detection with Transformers (ANDT), which treats consecutive video frames as a sequence of tubelets, utilizes a Transformer encoder to learn feature representations from the sequence, and leverages a decoder to predict the next frame. Our network models normality in the training phase and identifies an event with unpredictable temporal dynamics as an anomaly in the test phase. Moreover, To comprehensively evaluate the performance of our proposed method, we use not only our Drone-Anomaly dataset but also another dataset. We will make our dataset and code publicly available. A demo video is available at https://youtu.be/ancczYryOBY. We make our dataset and code publicly available .
A model-agnostic approach for generating Saliency Maps to explain inferred decisions of Deep Learning Models
Sep 19, 2022
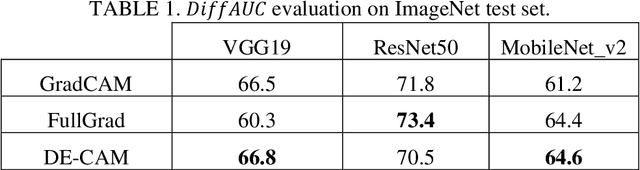

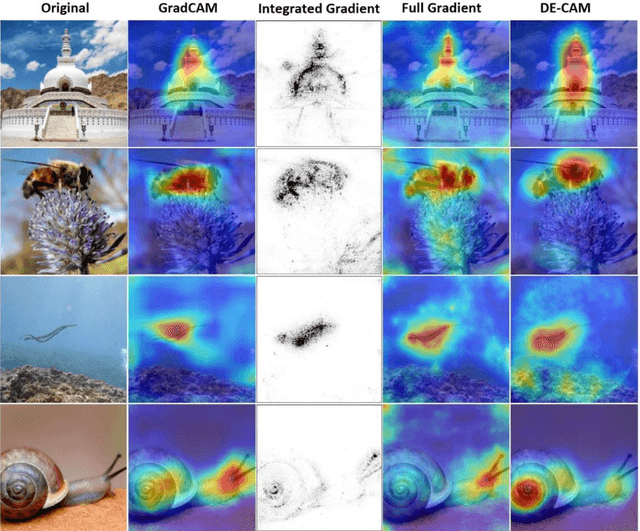
The widespread use of black-box AI models has raised the need for algorithms and methods that explain the decisions made by these models. In recent years, the AI research community is increasingly interested in models' explainability since black-box models take over more and more complicated and challenging tasks. Explainability becomes critical considering the dominance of deep learning techniques for a wide range of applications, including but not limited to computer vision. In the direction of understanding the inference process of deep learning models, many methods that provide human comprehensible evidence for the decisions of AI models have been developed, with the vast majority relying their operation on having access to the internal architecture and parameters of these models (e.g., the weights of neural networks). We propose a model-agnostic method for generating saliency maps that has access only to the output of the model and does not require additional information such as gradients. We use Differential Evolution (DE) to identify which image pixels are the most influential in a model's decision-making process and produce class activation maps (CAMs) whose quality is comparable to the quality of CAMs created with model-specific algorithms. DE-CAM achieves good performance without requiring access to the internal details of the model's architecture at the cost of more computational complexity.
Performance Analysis for Reconfigurable Intelligent Surface Assisted MIMO Systems
Aug 25, 2022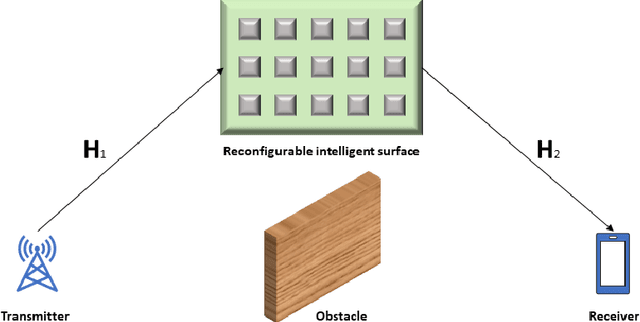
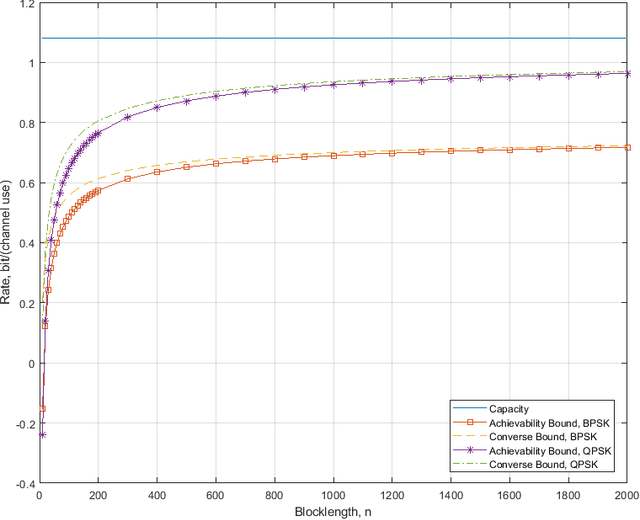
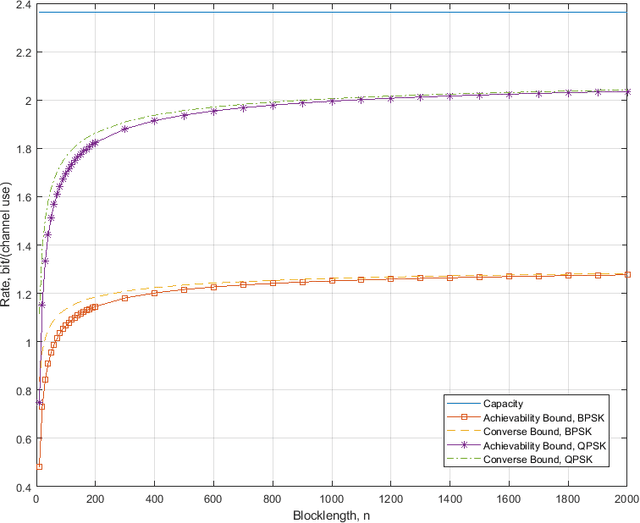
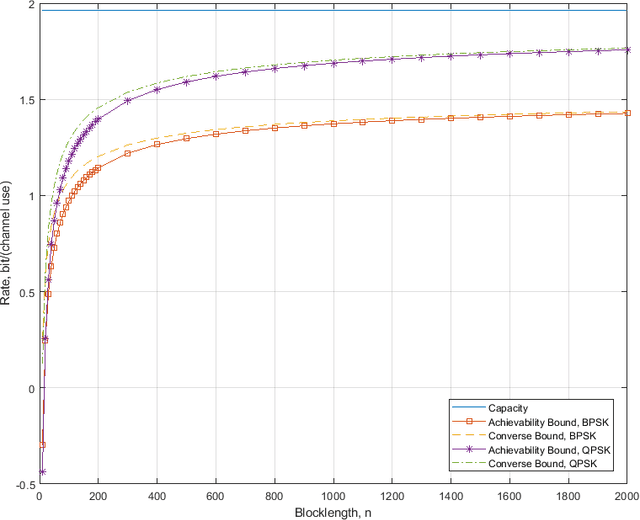
This paper investigates the maximal achievable rate for a given average error probability and blocklength for the reconfigurable intelligent surface (RIS) assisted multiple-input and multiple-output (MIMO) system. The result consists of a finite blocklength channel coding achievability bound and a converse bound based on the Berry-Esseen theorem, the Mellin transform and the mutual information. Numerical evaluation shows fast speed of convergence to the maximal achievable rate as the blocklength increases and also proves that the channel variance is a sound measurement of the backoff from the maximal achievable rate due to finite blocklength.
Data Valuation for Vertical Federated Learning: An Information-Theoretic Approach
Dec 15, 2021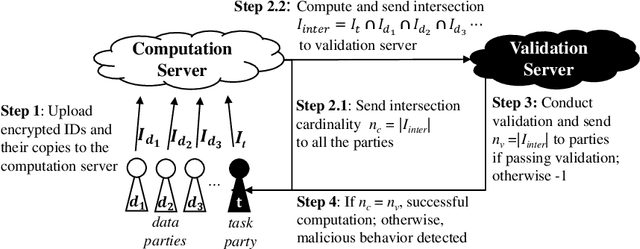
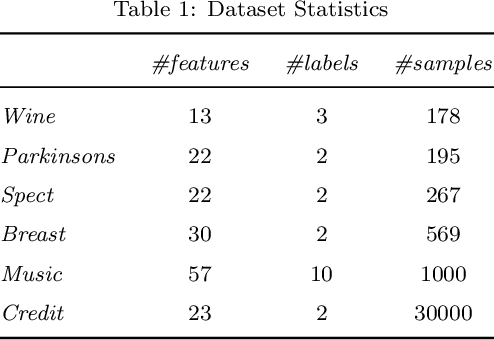
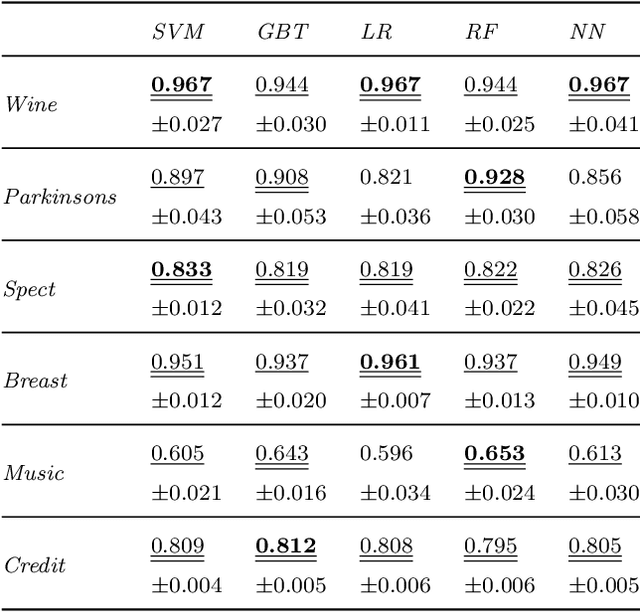
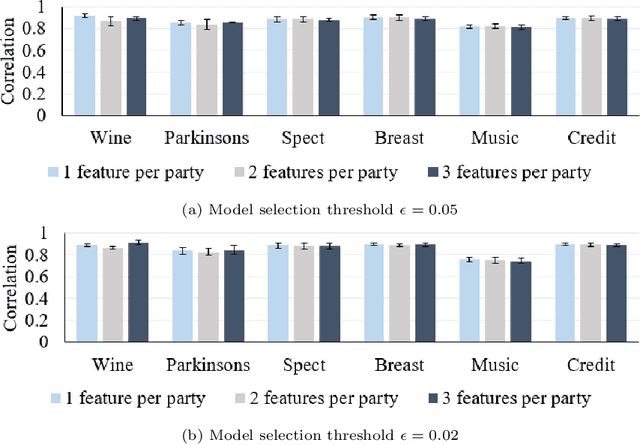
Federated learning (FL) is a promising machine learning paradigm that enables cross-party data collaboration for real-world AI applications in a privacy-preserving and law-regulated way. How to valuate parties' data is a critical but challenging FL issue. In the literature, data valuation either relies on running specific models for a given task or is just task irrelevant; however, it is often requisite for party selection given a specific task when FL models have not been determined yet. This work thus fills the gap and proposes \emph{FedValue}, to our best knowledge, the first privacy-preserving, task-specific but model-free data valuation method for vertical FL tasks. Specifically, FedValue incorporates a novel information-theoretic metric termed Shapley-CMI to assess data values of multiple parties from a game-theoretic perspective. Moreover, a novel server-aided federated computation mechanism is designed to compute Shapley-CMI and meanwhile protects each party from data leakage. We also propose several techniques to accelerate Shapley-CMI computation in practice. Extensive experiments on six open datasets validate the effectiveness and efficiency of FedValue for data valuation of vertical FL tasks. In particular, Shapley-CMI as a model-free metric performs comparably with the measures that depend on running an ensemble of well-performing models.