 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the utility and protection of optimization with differential privacy and classic regularization techniques
Sep 07, 2022


Nowadays, owners and developers of deep learning models must consider stringent privacy-preservation rules of their training data, usually crowd-sourced and retaining sensitive information. The most widely adopted method to enforce privacy guarantees of a deep learning model nowadays relies on optimization techniques enforcing differential privacy. According to the literature, this approach has proven to be a successful defence against several models' privacy attacks, but its downside is a substantial degradation of the models' performance. In this work, we compare the effectiveness of the differentially-private stochastic gradient descent (DP-SGD) algorithm against standard optimization practices with regularization techniques. We analyze the resulting models' utility, training performance, and the effectiveness of membership inference and model inversion attacks against the learned models. Finally, we discuss differential privacy's flaws and limits and empirically demonstrate the often superior privacy-preserving properties of dropout and l2-regularization.
MAC: A Meta-Learning Approach for Feature Learning and Recombination
Sep 20, 2022
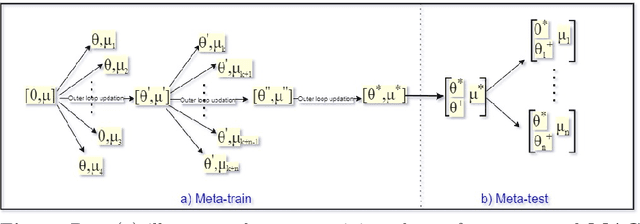

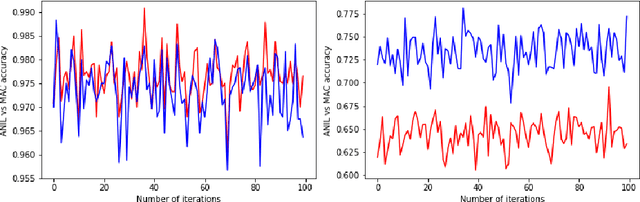
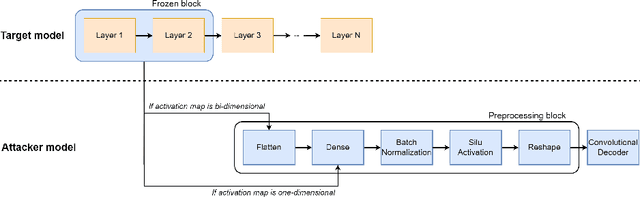
Optimization-based meta-learning aims to learn an initialization so that a new unseen task can be learned within a few gradient updates. Model Agnostic Meta-Learning (MAML) is a benchmark algorithm comprising two optimization loops. The inner loop is dedicated to learning a new task and the outer loop leads to meta-initialization. However, ANIL (almost no inner loop) algorithm shows that feature reuse is an alternative to rapid learning in MAML. Thus, the meta-initialization phase makes MAML primed for feature reuse and obviates the need for rapid learning. Contrary to ANIL, we hypothesize that there may be a need to learn new features during meta-testing. A new unseen task from non-similar distribution would necessitate rapid learning in addition reuse and recombination of existing features. In this paper, we invoke the width-depth duality of neural networks, wherein, we increase the width of the network by adding extra computational units (ACU). The ACUs enable the learning of new atomic features in the meta-testing task, and the associated increased width facilitates information propagation in the forwarding pass. The newly learnt features combine with existing features in the last layer for meta-learning. Experimental results show that our proposed MAC method outperformed existing ANIL algorithm for non-similar task distribution by approximately 13% (5-shot task setting)
Encoding protein dynamic information in graph representation for functional residue identification
Dec 15, 2021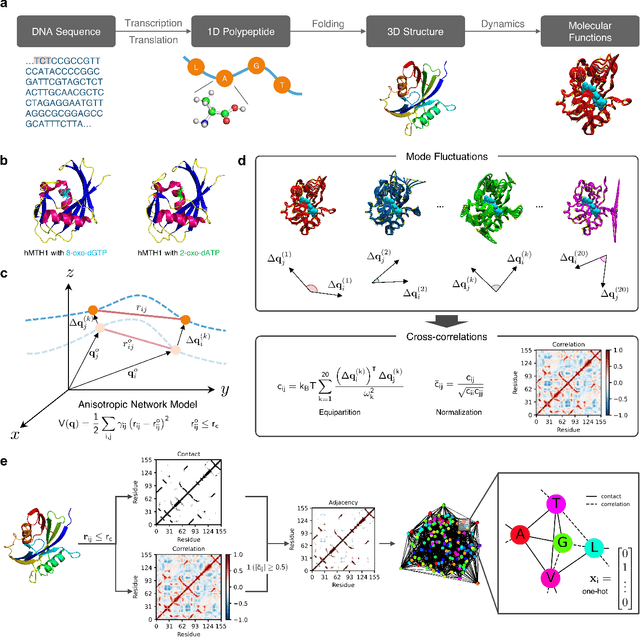

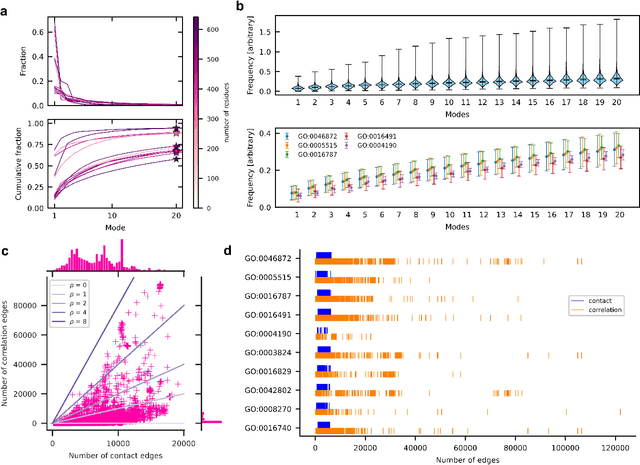
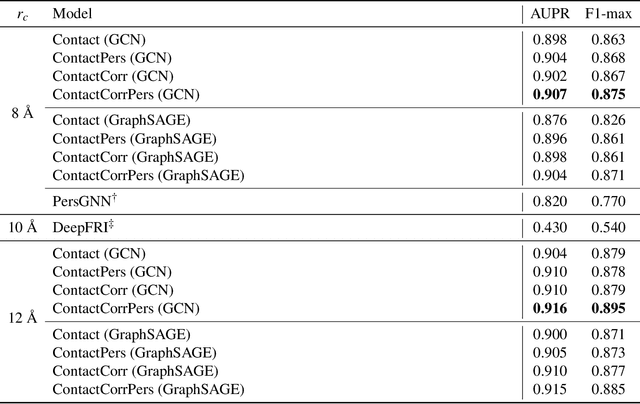
Recent advances in protein function prediction exploit graph-based deep learning approaches to correlate the structural and topological features of proteins with their molecular functions. However, proteins in vivo are not static but dynamic molecules that alter conformation for functional purposes. Here we apply normal mode analysis to native protein conformations and augment protein graphs by connecting edges between dynamically correlated residue pairs. In the multilabel function classification task, our method demonstrates a remarkable performance gain based on this dynamics-informed representation. The proposed graph neural network, ProDAR, increases the interpretability and generalizability of residue-level annotations and robustly reflects structural nuance in proteins. We elucidate the importance of dynamic information in graph representation by comparing class activation maps for the hMTH1, nitrophorin, and SARS-CoV-2 receptor binding domain. Our model successfully learns the dynamic fingerprints of proteins and provides molecular insights into protein functions, with vast untapped potential for broad biotechnology and pharmaceutical applications.
OLIVES Dataset: Ophthalmic Labels for Investigating Visual Eye Semantics
Sep 22, 2022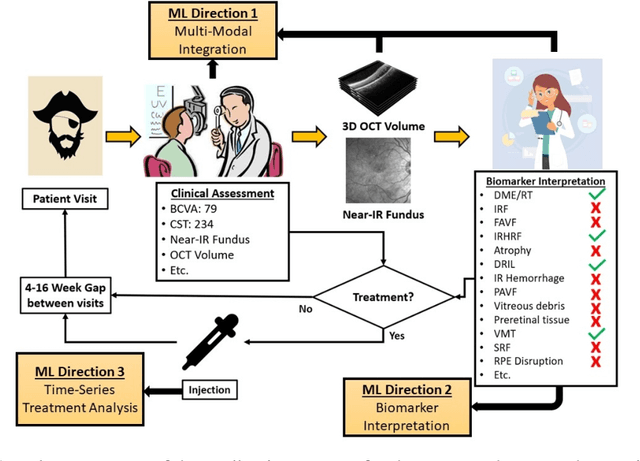
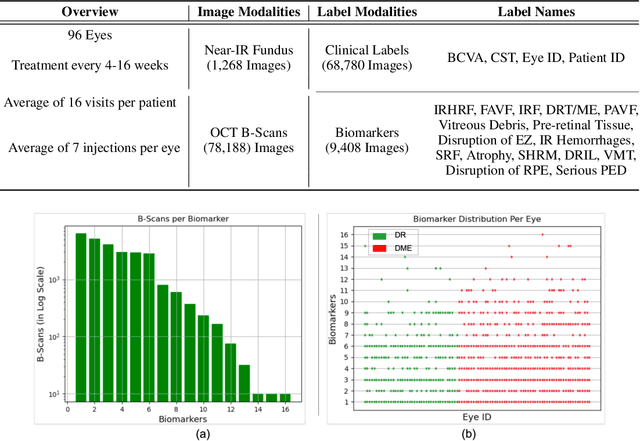
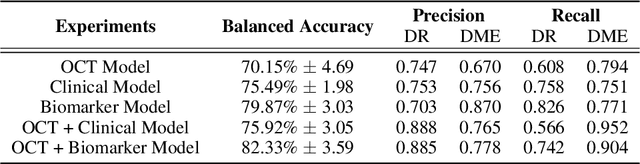
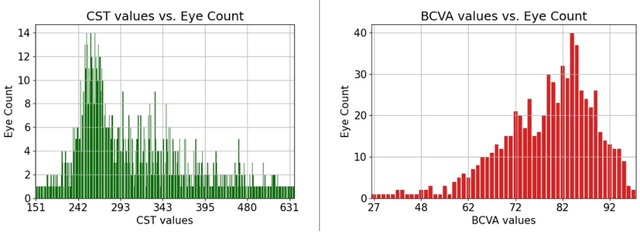
Clinical diagnosis of the eye is performed over multifarious data modalities including scalar clinical labels, vectorized biomarkers, two-dimensional fundus images, and three-dimensional Optical Coherence Tomography (OCT) scans. Clinical practitioners use all available data modalities for diagnosing and treating eye diseases like Diabetic Retinopathy (DR) or Diabetic Macular Edema (DME). Enabling usage of machine learning algorithms within the ophthalmic medical domain requires research into the relationships and interactions between all relevant data over a treatment period. Existing datasets are limited in that they neither provide data nor consider the explicit relationship modeling between the data modalities. In this paper, we introduce the Ophthalmic Labels for Investigating Visual Eye Semantics (OLIVES) dataset that addresses the above limitation. This is the first OCT and near-IR fundus dataset that includes clinical labels, biomarker labels, disease labels, and time-series patient treatment information from associated clinical trials. The dataset consists of 1268 near-IR fundus images each with at least 49 OCT scans, and 16 biomarkers, along with 4 clinical labels and a disease diagnosis of DR or DME. In total, there are 96 eyes' data averaged over a period of at least two years with each eye treated for an average of 66 weeks and 7 injections. We benchmark the utility of OLIVES dataset for ophthalmic data as well as provide benchmarks and concrete research directions for core and emerging machine learning paradigms within medical image analysis.
Improving Mandarin Speech Recogntion with Block-augmented Transformer
Jul 24, 2022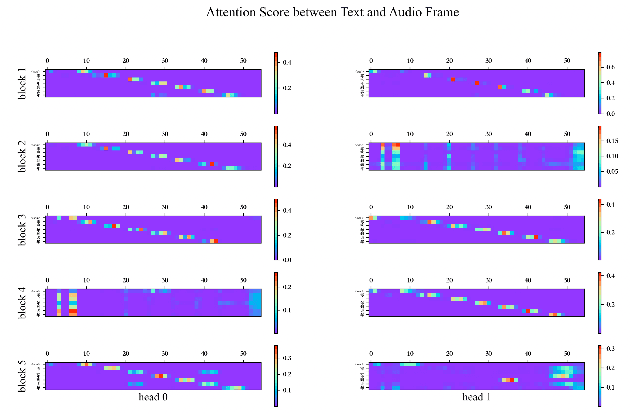
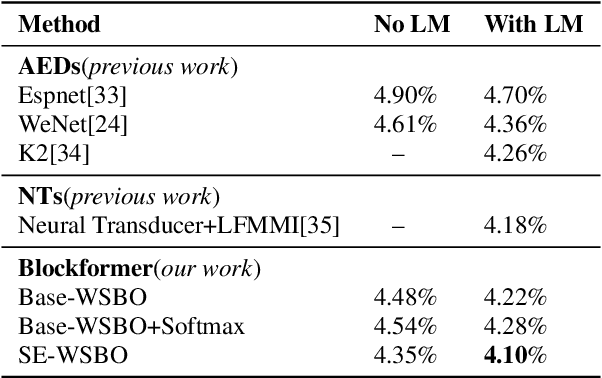
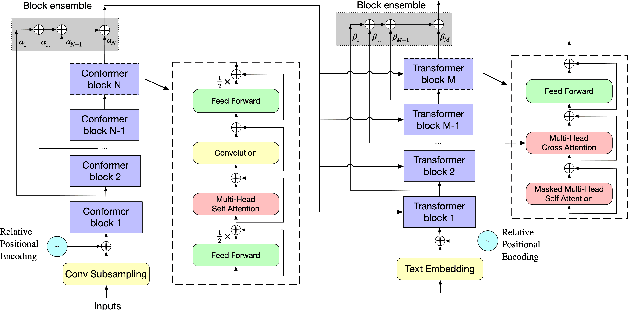

Recently Convolution-augmented Transformer (Conformer) has shown promising results in Automatic Speech Recognition (ASR), outperforming the previous best published Transformer Transducer. In this work, we believe that the output information of each block in the encoder and decoder is not completely inclusive, in other words, their output information may be complementary. We study how to take advantage of the complementary information of each block in a parameter-efficient way, and it is expected that this may lead to more robust performance. Therefore we propose the Block-augmented Transformer for speech recognition, named Blockformer. We have implemented two block ensemble methods: the base Weighted Sum of the Blocks Output (Base-WSBO), and the Squeeze-and-Excitation module to Weighted Sum of the Blocks Output (SE-WSBO). Experiments have proved that the Blockformer significantly outperforms the state-of-the-art Conformer-based models on AISHELL-1, our model achieves a CER of 4.35\% without using a language model and 4.10\% with an external language model on the testset.
Expected Worst Case Regret via Stochastic Sequential Covering
Sep 17, 2022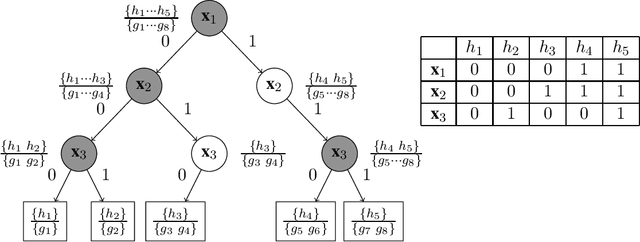
We study the problem of sequential prediction and online minimax regret with stochastically generated features under a general loss function. We introduce a notion of expected worst case minimax regret that generalizes and encompasses prior known minimax regrets. For such minimax regrets we establish tight upper bounds via a novel concept of stochastic global sequential covering. We show that for a hypothesis class of VC-dimension $\mathsf{VC}$ and $i.i.d.$ generated features of length $T$, the cardinality of the stochastic global sequential covering can be upper bounded with high probability (whp) by $e^{O(\mathsf{VC} \cdot \log^2 T)}$. We then improve this bound by introducing a new complexity measure called the Star-Littlestone dimension, and show that classes with Star-Littlestone dimension $\mathsf{SL}$ admit a stochastic global sequential covering of order $e^{O(\mathsf{SL} \cdot \log T)}$. We further establish upper bounds for real valued classes with finite fat-shattering numbers. Finally, by applying information-theoretic tools of the fixed design minimax regrets, we provide lower bounds for the expected worst case minimax regret. We demonstrate the effectiveness of our approach by establishing tight bounds on the expected worst case minimax regrets for logarithmic loss and general mixable losses.
FaRO 2: an Open Source, Configurable Smart City Framework for Real-Time Distributed Vision and Biometric Systems
Sep 26, 2022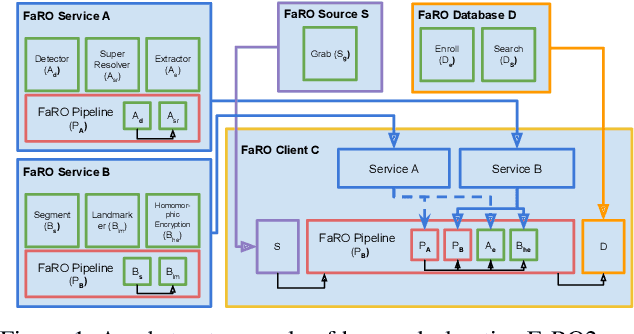
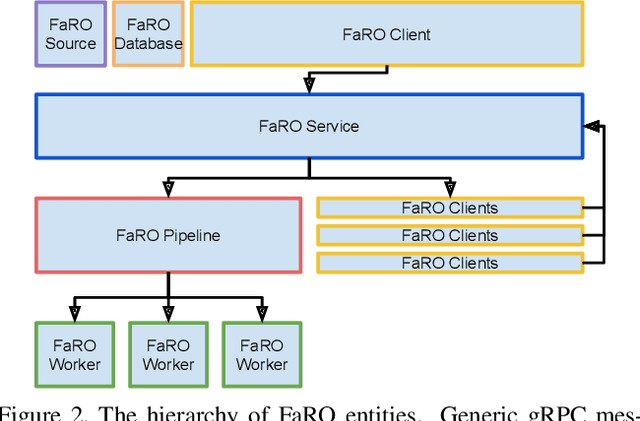
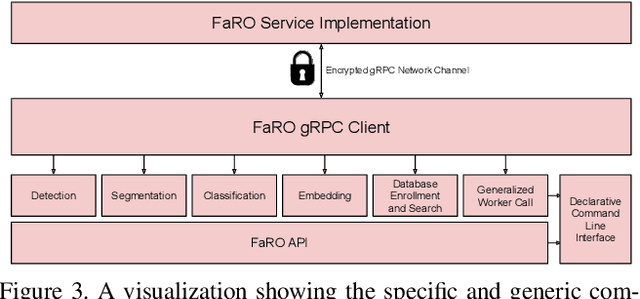
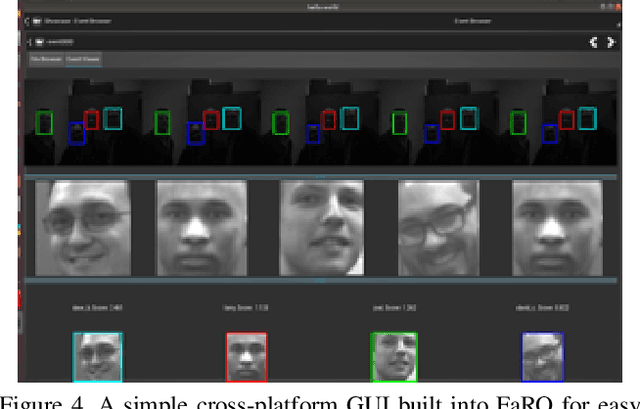
Recent global growth in the interest of smart cities has led to trillions of dollars of investment toward research and development. These connected cities have the potential to create a symbiosis of technology and society and revolutionize the cost of living, safety, ecological sustainability, and quality of life of societies on a world-wide scale. Some key components of the smart city construct are connected smart grids, self-driving cars, federated learning systems, smart utilities, large-scale public transit, and proactive surveillance systems. While exciting in prospect, these technologies and their subsequent integration cannot be attempted without addressing the potential societal impacts of such a high degree of automation and data sharing. Additionally, the feasibility of coordinating so many disparate tasks will require a fast, extensible, unifying framework. To that end, we propose FaRO2, a completely reimagined successor to FaRO1, built from the ground up. FaRO2 affords all of the same functionality as its predecessor, serving as a unified biometric API harness that allows for seamless evaluation, deployment, and simple pipeline creation for heterogeneous biometric software. FaRO2 additionally provides a fully declarative capability for defining and coordinating custom machine learning and sensor pipelines, allowing the distribution of processes across otherwise incompatible hardware and networks. FaRO2 ultimately provides a way to quickly configure, hot-swap, and expand large coordinated or federated systems online without interruptions for maintenance. Because much of the data collected in a smart city contains Personally Identifying Information (PII), FaRO2 also provides built-in tools and layers to ensure secure and encrypted streaming, storage, and access of PII data across distributed systems.
Review of data types and model dimensionality for cardiac DTI SMS-related artefact removal
Sep 20, 2022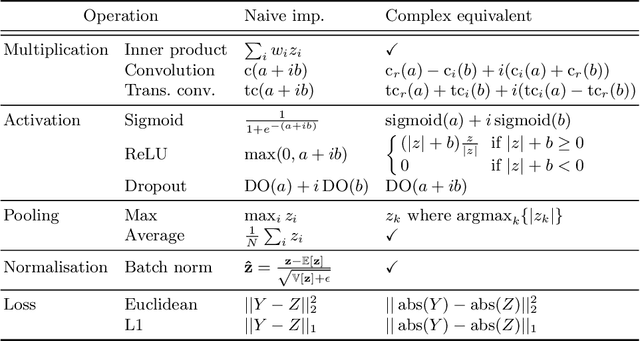
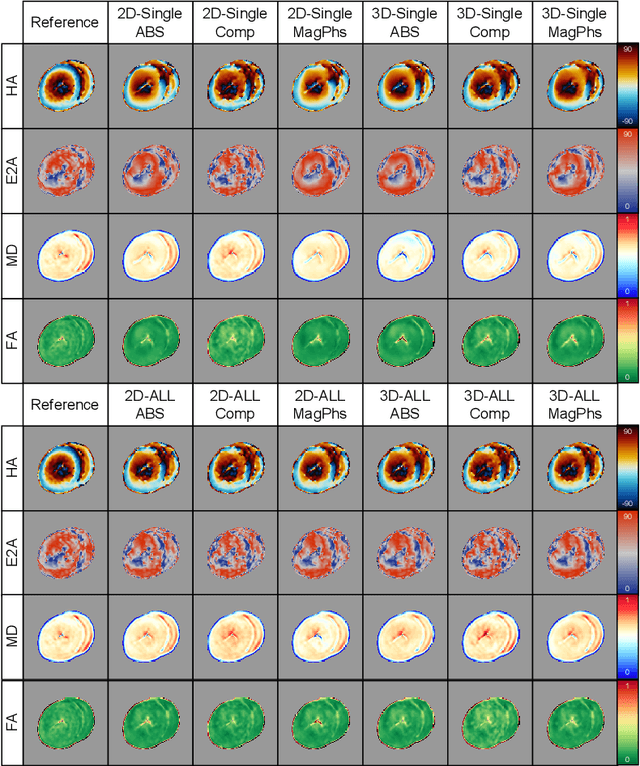
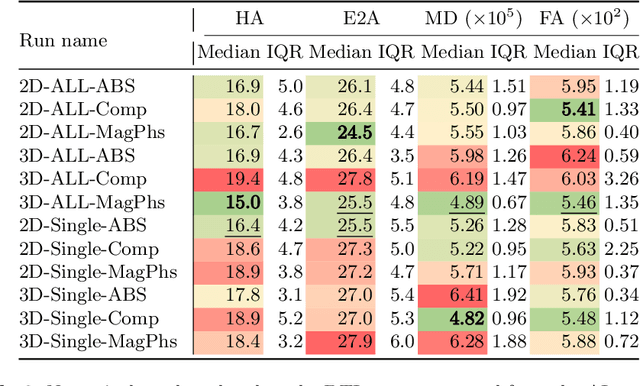
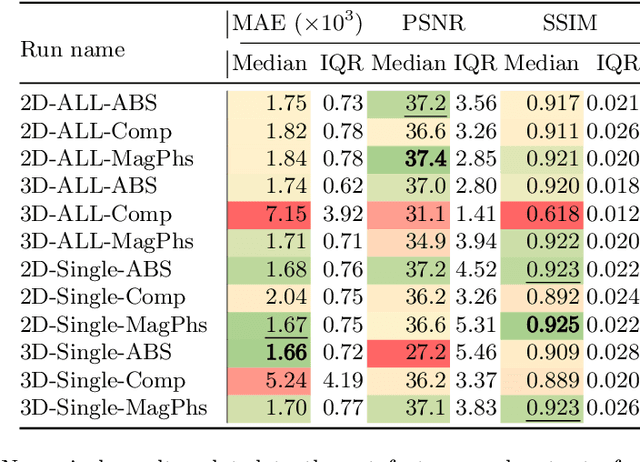
As diffusion tensor imaging (DTI) gains popularity in cardiac imaging due to its unique ability to non-invasively assess the cardiac microstructure, deep learning-based Artificial Intelligence is becoming a crucial tool in mitigating some of its drawbacks, such as the long scan times. As it often happens in fast-paced research environments, a lot of emphasis has been put on showing the capability of deep learning while often not enough time has been spent investigating what input and architectural properties would benefit cardiac DTI acceleration the most. In this work, we compare the effect of several input types (magnitude images vs complex images), multiple dimensionalities (2D vs 3D operations), and multiple input types (single slice vs multi-slice) on the performance of a model trained to remove artefacts caused by a simultaneous multi-slice (SMS) acquisition. Despite our initial intuition, our experiments show that, for a fixed number of parameters, simpler 2D real-valued models outperform their more advanced 3D or complex counterparts. The best performance is although obtained by a real-valued model trained using both the magnitude and phase components of the acquired data. We believe this behaviour to be due to real-valued models making better use of the lower number of parameters, and to 3D models not being able to exploit the spatial information because of the low SMS acceleration factor used in our experiments.
A Comprehensive Survey on Video Saliency Detection with Auditory Information: the Audio-visual Consistency Perceptual is the Key!
Jun 20, 2022
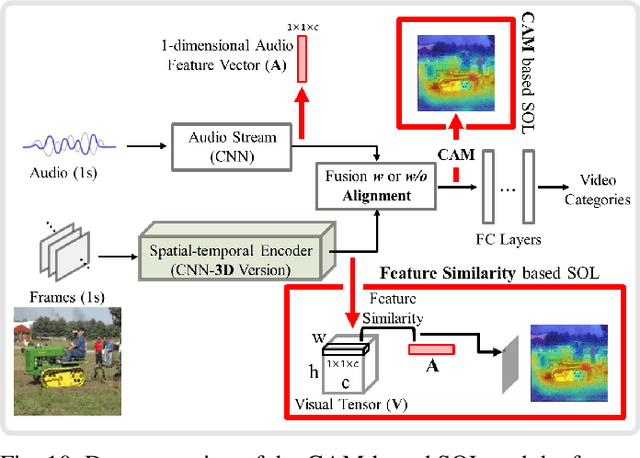
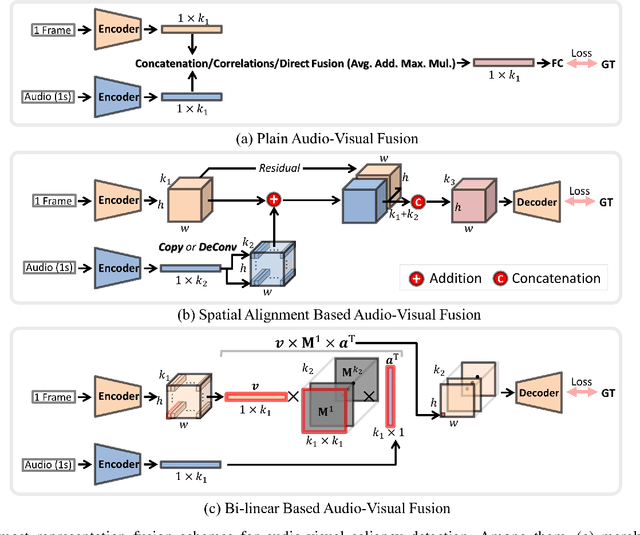
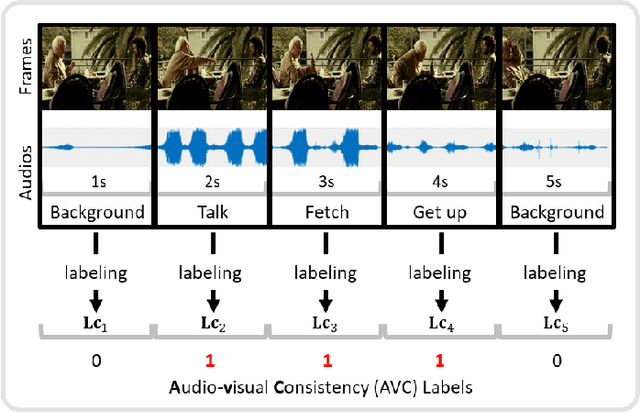
Video saliency detection (VSD) aims at fast locating the most attractive objects/things/patterns in a given video clip. Existing VSD-related works have mainly relied on the visual system but paid less attention to the audio aspect, while, actually, our audio system is the most vital complementary part to our visual system. Also, audio-visual saliency detection (AVSD), one of the most representative research topics for mimicking human perceptual mechanisms, is currently in its infancy, and none of the existing survey papers have touched on it, especially from the perspective of saliency detection. Thus, the ultimate goal of this paper is to provide an extensive review to bridge the gap between audio-visual fusion and saliency detection. In addition, as another highlight of this review, we have provided a deep insight into key factors which could directly determine the performances of AVSD deep models, and we claim that the audio-visual consistency degree (AVC) -- a long-overlooked issue, can directly influence the effectiveness of using audio to benefit its visual counterpart when performing saliency detection. Moreover, in order to make the AVC issue more practical and valuable for future followers, we have newly equipped almost all existing publicly available AVSD datasets with additional frame-wise AVC labels. Based on these upgraded datasets, we have conducted extensive quantitative evaluations to ground our claim on the importance of AVC in the AVSD task. In a word, both our ideas and new sets serve as a convenient platform with preliminaries and guidelines, all of which are very potential to facilitate future works in promoting state-of-the-art (SOTA) performance further.
Anisotropic mesh adaptation for region-based segmentation accounting for image spatial information
Dec 19, 2021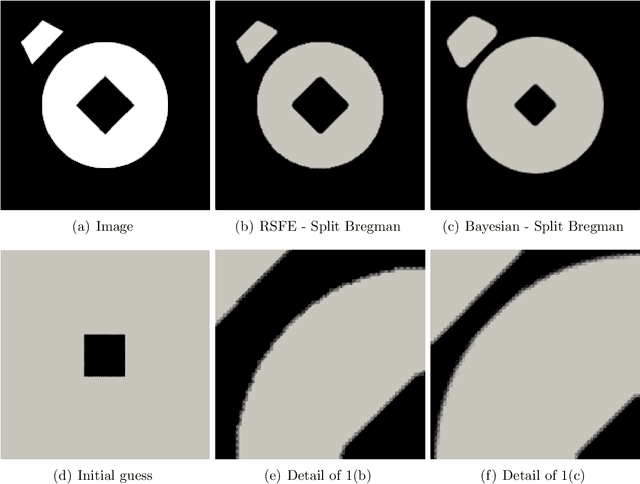


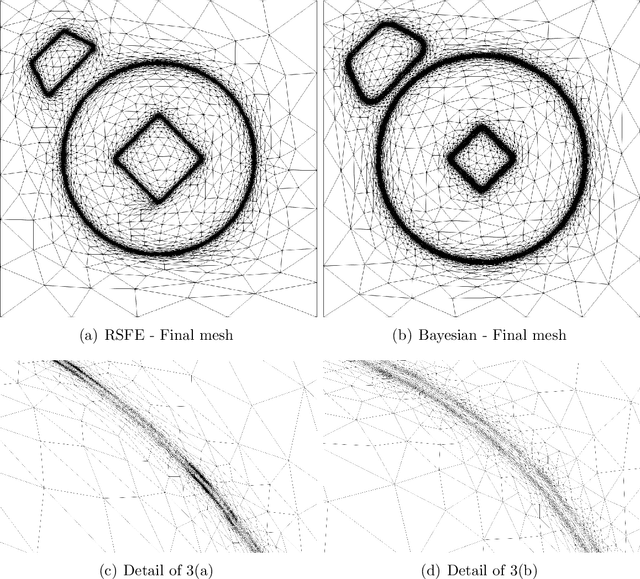
A finite element-based image segmentation strategy enhanced by an anisotropic mesh adaptation procedure is presented. The methodology relies on a split Bregman algorithm for the minimisation of a region-based energy functional and on an anisotropic recovery-based error estimate to drive mesh adaptation. More precisely, a Bayesian energy functional is considered to account for image spatial information, ensuring that the methodology is able to identify inhomogeneous spatial patterns in complex images. In addition, the anisotropic mesh adaptation guarantees a sharp detection of the interface between background and foreground of the image, with a reduced number of degrees of freedom. The resulting split-adapt Bregman algorithm is tested on a set of real images showing the accuracy and robustness of the method, even in the presence of Gaussian, salt and pepper and speckle noise.