 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AST-GIN: Attribute-Augmented Spatial-Temporal Graph Informer Network for Electric Vehicle Charging Station Availability Forecasting
Sep 07, 2022
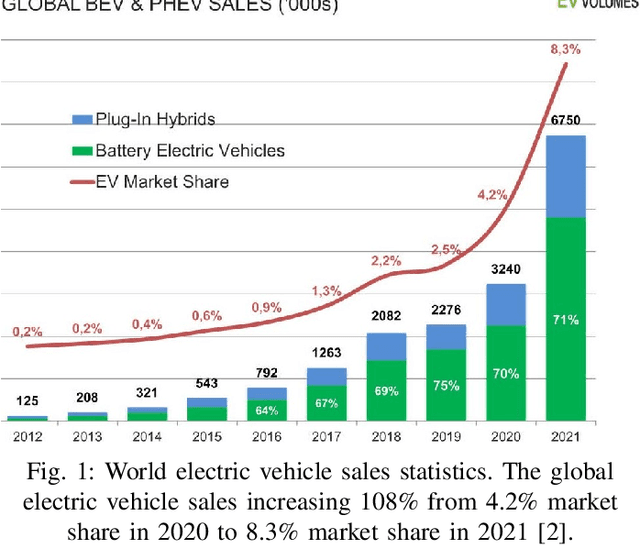
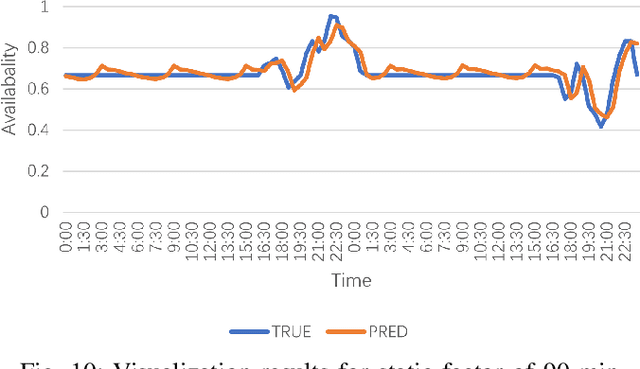
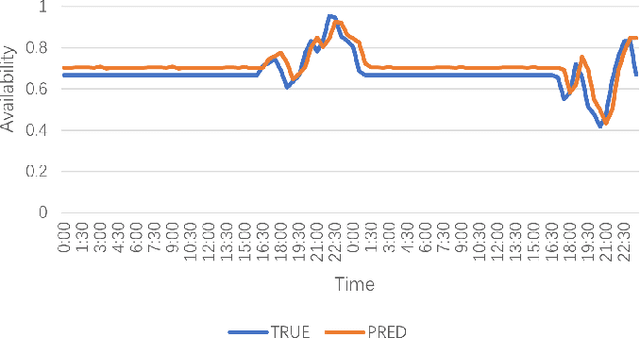
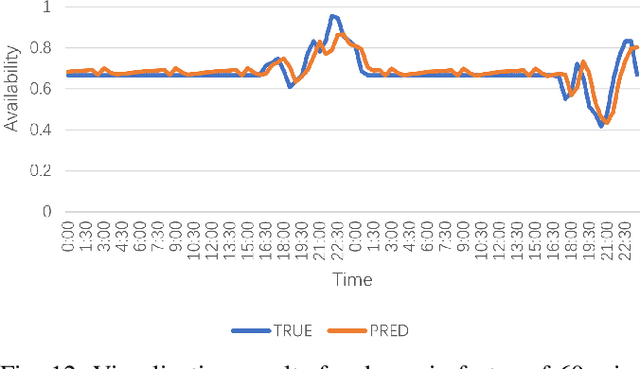
Electric Vehicle (EV) charging demand and charging station availability forecasting is one of the challenges in the intelligent transportation system. With the accurate EV station situation prediction, suitable charging behaviors could be scheduled in advance to relieve range anxiety. Many existing deep learning methods are proposed to address this issue, however, due to the complex road network structure and comprehensive external factors, such as point of interests (POIs) and weather effects, many commonly used algorithms could just extract the historical usage information without considering comprehensive influence of external factors. To enhance the prediction accuracy and interpretability, the Attribute-Augmented Spatial-Temporal Graph Informer (AST-GIN) structure is proposed in this study by combining the Graph Convolutional Network (GCN) layer and the Informer layer to extract both external and internal spatial-temporal dependence of relevant transportation data. And the external factors are modeled as dynamic attributes by the attribute-augmented encoder for training. AST-GIN model is tested on the data collected in Dundee City and experimental results show the effectiveness of our model considering external factors influence over various horizon settings compared with other baselines.
Graph Neural Pre-training for Enhancing Recommendations using Side Information
Jul 09, 2021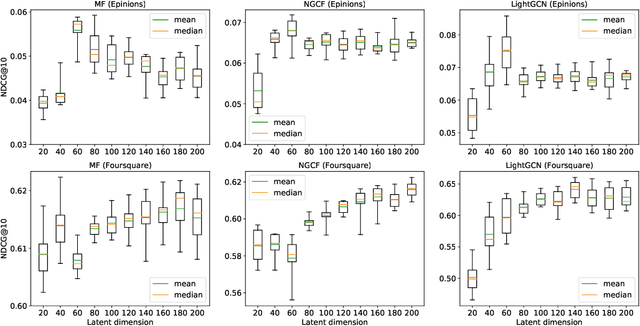

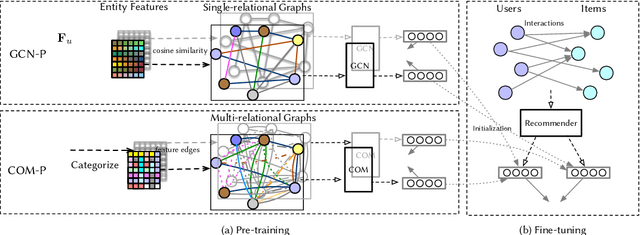
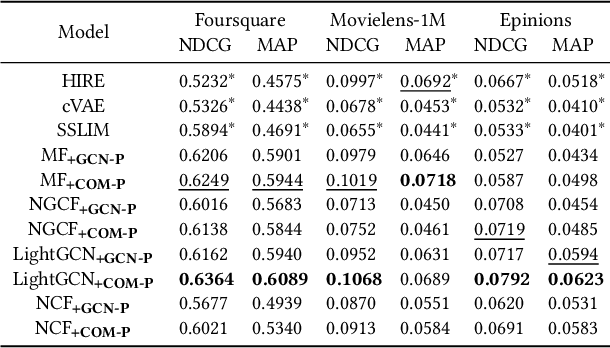
Leveraging the side information associated with entities (i.e. users and items) to enhance the performance of recommendation systems has been widely recognized as an important modelling dimension. While many existing approaches focus on the integration scheme to incorporate entity side information -- by combining the recommendation loss function with an extra side information-aware loss -- in this paper, we propose instead a novel pre-training scheme for leveraging the side information. In particular, we first pre-train a representation model using the side information of the entities, and then fine-tune it using an existing general representation-based recommendation model. Specifically, we propose two pre-training models, named GCN-P and COM-P, by considering the entities and their relations constructed from side information as two different types of graphs respectively, to pre-train entity embeddings. For the GCN-P model, two single-relational graphs are constructed from all the users' and items' side information respectively, to pre-train entity representations by using the Graph Convolutional Networks. For the COM-P model, two multi-relational graphs are constructed to pre-train the entity representations by using the Composition-based Graph Convolutional Networks. An extensive evaluation of our pre-training models fine-tuned under four general representation-based recommender models, i.e. MF, NCF, NGCF and LightGCN, shows that effectively pre-training embeddings with both the user's and item's side information can significantly improve these original models in terms of both effectiveness and stability.
Using Multi-Encoder Fusion Strategies to Improve Personalized Response Selection
Aug 30, 2022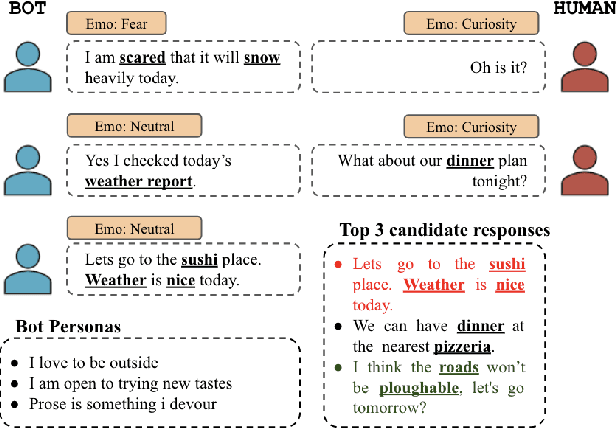

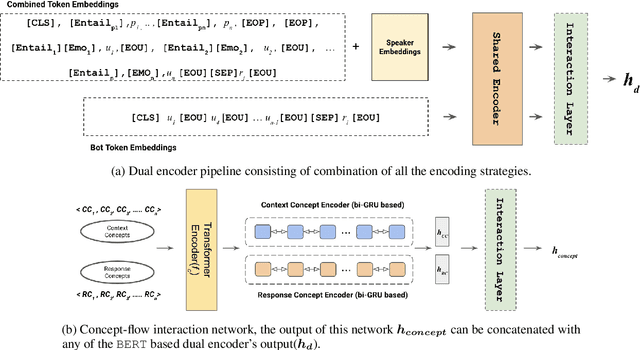
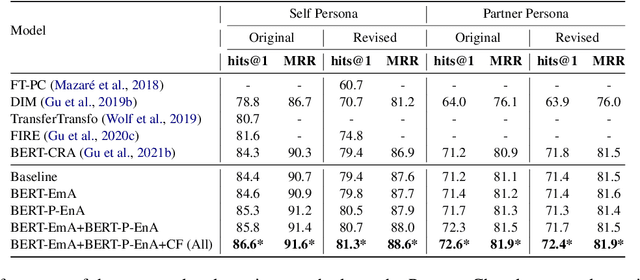
Personalized response selection systems are generally grounded on persona. However, there exists a co-relation between persona and empathy, which is not explored well in these systems. Also, faithfulness to the conversation context plunges when a contradictory or an off-topic response is selected. This paper attempts to address these issues by proposing a suite of fusion strategies that capture the interaction between persona, emotion, and entailment information of the utterances. Ablation studies on the Persona-Chat dataset show that incorporating emotion and entailment improves the accuracy of response selection. We combine our fusion strategies and concept-flow encoding to train a BERT-based model which outperforms the previous methods by margins larger than 2.3 % on original personas and 1.9 % on revised personas in terms of hits@1 (top-1 accuracy), achieving a new state-of-the-art performance on the Persona-Chat dataset.
Elly: A Real-Time Failure Recovery and Data Collection System for Robotic Manipulation
Aug 25, 2022
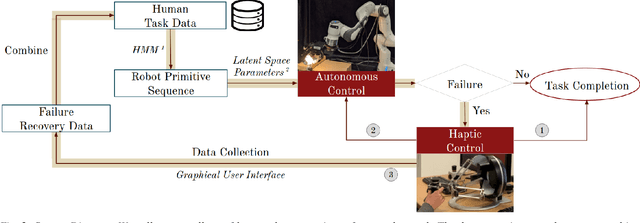
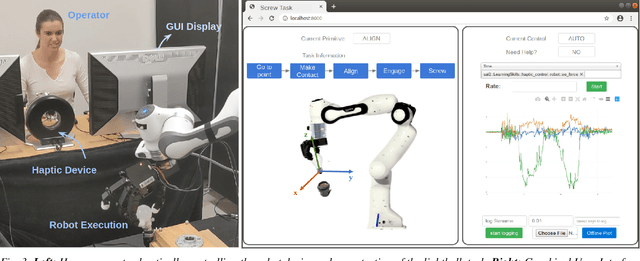

Even the most robust autonomous behaviors can fail. The goal of this research is to both recover and collect data from failures, during autonomous task execution, so they can be prevented in the future. We propose haptic intervention for real-time failure recovery and data collection. Elly is a system that allows for seamless transitions between autonomous robot behaviors and human intervention while collecting sensory information from the human's recovery strategy. The system and our design choices were experimentally validated on a single arm task -- installing a lightbulb in a socket -- and a bimanual task -- screwing a cap on a bottle -- using two 7-DOF manipulators equipped 4-finger grippers. In these examples, Elly achieved over 80% task completion during a total of 40 runs.
Cerberus: Exploring Federated Prediction of Security Events
Sep 07, 2022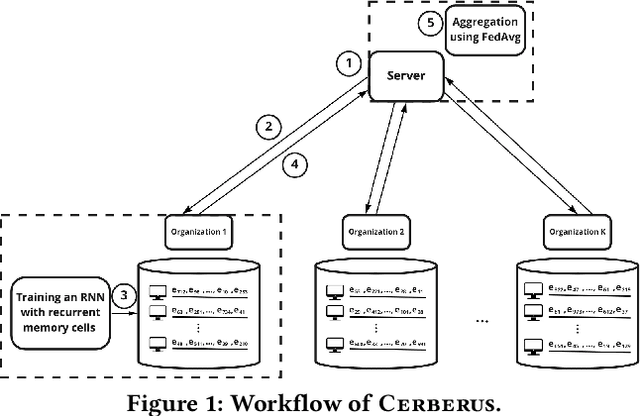
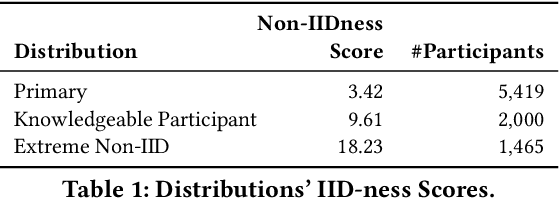
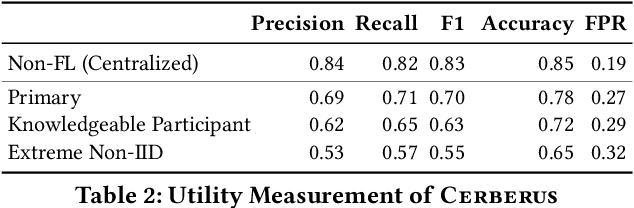
Modern defenses against cyberattacks increasingly rely on proactive approaches, e.g., to predict the adversary's next actions based on past events. Building accurate prediction models requires knowledge from many organizations; alas, this entails disclosing sensitive information, such as network structures, security postures, and policies, which might often be undesirable or outright impossible. In this paper, we explore the feasibility of using Federated Learning (FL) to predict future security events. To this end, we introduce Cerberus, a system enabling collaborative training of Recurrent Neural Network (RNN) models for participating organizations. The intuition is that FL could potentially offer a middle-ground between the non-private approach where the training data is pooled at a central server and the low-utility alternative of only training local models. We instantiate Cerberus on a dataset obtained from a major security company's intrusion prevention product and evaluate it vis-a-vis utility, robustness, and privacy, as well as how participants contribute to and benefit from the system. Overall, our work sheds light on both the positive aspects and the challenges of using FL for this task and paves the way for deploying federated approaches to predictive security.
Attitude-Guided Loop Closure for Cameras with Negative Plane
Sep 12, 2022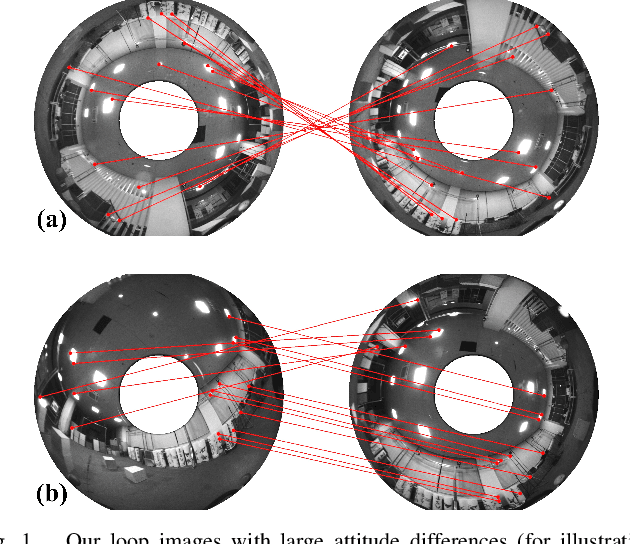

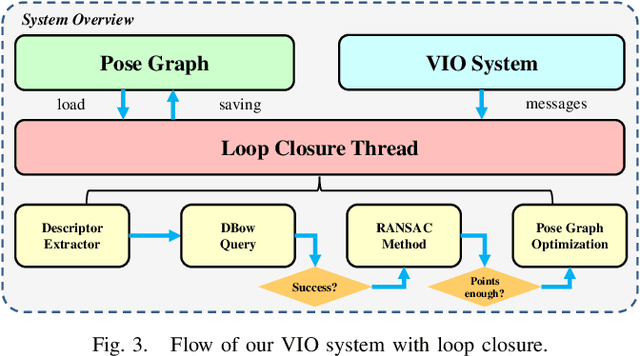

Loop closure is an important component of Simultaneous Localization and Mapping (SLAM) systems. Large Field-of-View (FoV) cameras have received extensive attention in the SLAM field as they can exploit more surrounding features on the panoramic image. In large-FoV VIO, for incorporating the informative cues located on the negative plane of the panoramic lens, image features are represented by a three-dimensional vector with a unit length. While the panoramic FoV is seemingly advantageous for loop closure, the benefits cannot easily be materialized under large-attitude-angle differences, where loop-closure frames can hardly be matched by existing methods. In this work, to fully unleash the potential of ultra-wide FoV, we propose to leverage the attitude information of a VIO system to guide the feature point detection of the loop closure. As loop closure on wide-FoV panoramic data further comes with a large number of outliers, traditional outlier rejection methods are not directly applicable. To tackle this issue, we propose a loop closure framework with a new outlier rejection method based on the unit length representation, to improve the accuracy of LF-VIO. On the public PALVIO dataset, a comprehensive set of experiments is carried out and the proposed LF-VIO-Loop outperforms state-of-the-art visual-inertial-odometry methods. Our code will be open-sourced at https://github.com/flysoaryun/LF-VIO-Loop.
Decentralized Machine Learning for Intelligent Health Care Systems on the Computing Continuum
Jul 29, 2022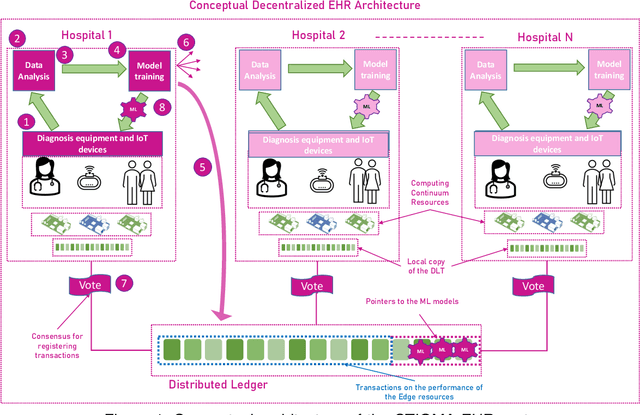
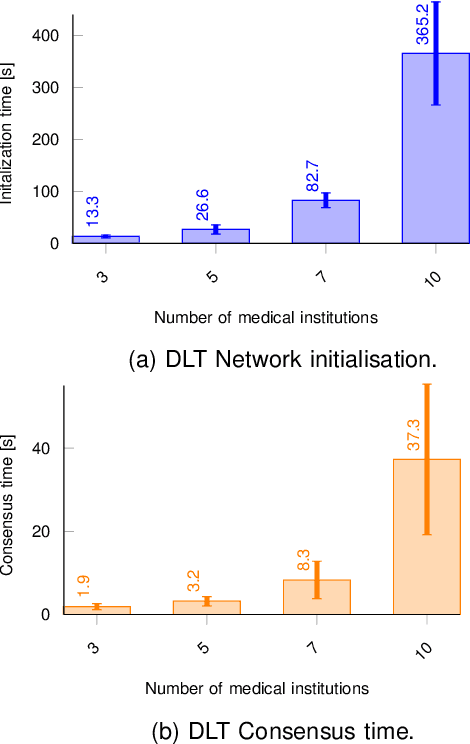
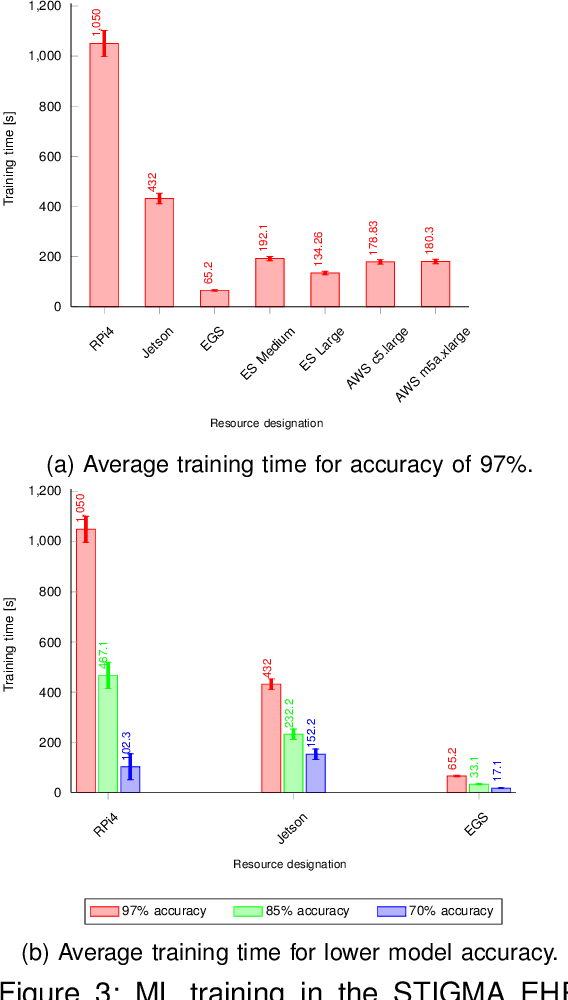
The introduction of electronic personal health records (EHR) enables nationwide information exchange and curation among different health care systems. However, the current EHR systems do not provide transparent means for diagnosis support, medical research or can utilize the omnipresent data produced by the personal medical devices. Besides, the EHR systems are centrally orchestrated, which could potentially lead to a single point of failure. Therefore, in this article, we explore novel approaches for decentralizing machine learning over distributed ledgers to create intelligent EHR systems that can utilize information from personal medical devices for improved knowledge extraction. Consequently, we proposed and evaluated a conceptual EHR to enable anonymous predictive analysis across multiple medical institutions. The evaluation results indicate that the decentralized EHR can be deployed over the computing continuum with reduced machine learning time of up to 60% and consensus latency of below 8 seconds.
Adam Mickiewicz University at WMT 2022: NER-Assisted and Quality-Aware Neural Machine Translation
Sep 07, 2022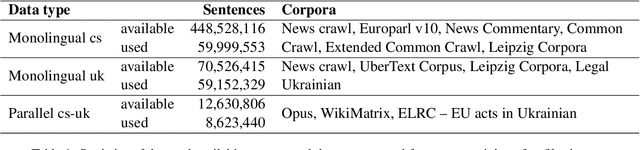
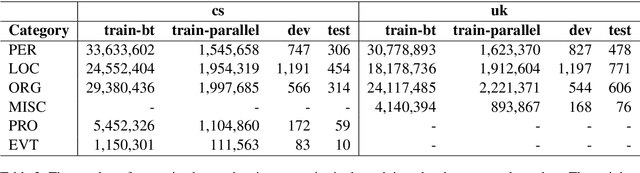
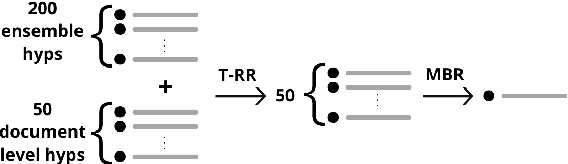
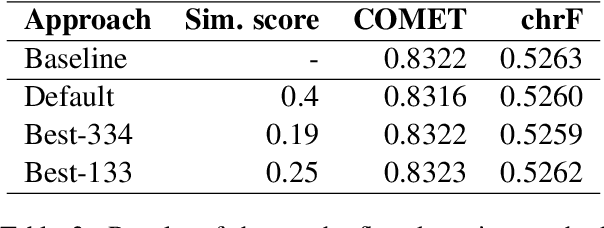
This paper presents Adam Mickiewicz University's (AMU) submissions to the constrained track of the WMT 2022 General MT Task. We participated in the Ukrainian $\leftrightarrow$ Czech translation directions. The systems are a weighted ensemble of four models based on the Transformer (big) architecture. The models use source factors to utilize the information about named entities present in the input. Each of the models in the ensemble was trained using only the data provided by the shared task organizers. A noisy back-translation technique was used to augment the training corpora. One of the models in the ensemble is a document-level model, trained on parallel and synthetic longer sequences. During the sentence-level decoding process, the ensemble generated the n-best list. The n-best list was merged with the n-best list generated by a single document-level model which translated multiple sentences at a time. Finally, existing quality estimation models and minimum Bayes risk decoding were used to rerank the n-best list so that the best hypothesis was chosen according to the COMET evaluation metric. According to the automatic evaluation results, our systems rank first in both translation directions.
Automatically Score Tissue Images Like a Pathologist by Transfer Learning
Sep 09, 2022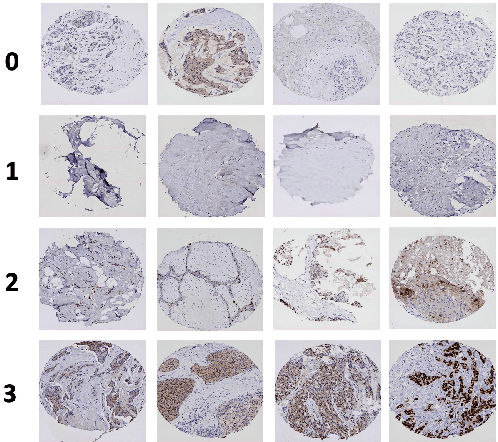
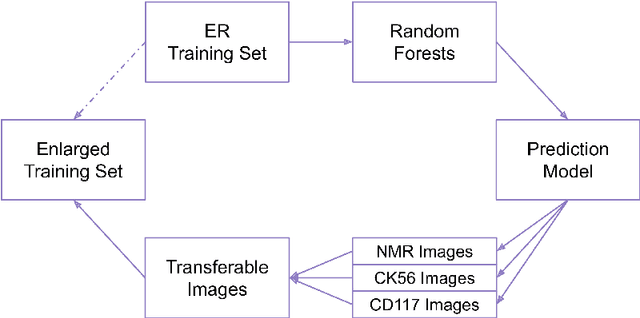
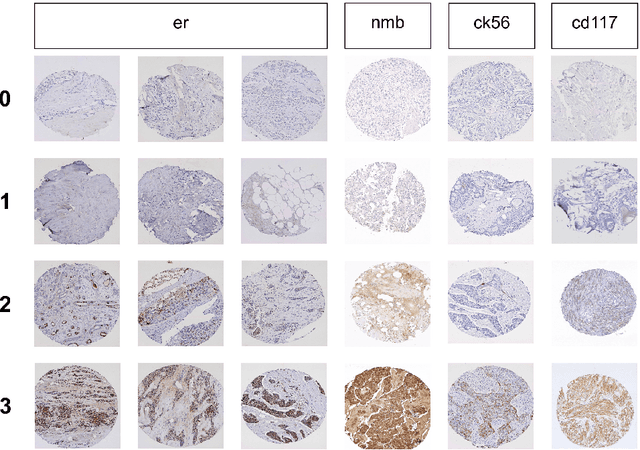
Cancer is the second leading cause of death in the world. Diagnosing cancer early on can save many lives. Pathologists have to look at tissue microarray (TMA) images manually to identify tumors, which can be time-consuming, inconsistent and subjective. Existing algorithms that automatically detect tumors have either not achieved the accuracy level of a pathologist or require substantial human involvements. A major challenge is that TMA images with different shapes, sizes, and locations can have the same score. Learning staining patterns in TMA images requires a huge number of images, which are severely limited due to privacy concerns and regulations in medical organizations. TMA images from different cancer types may have common characteristics that could provide valuable information, but using them directly harms the accuracy. Transfer learning is adopted to increase the training sample size by extracting knowledge from tissue images from different cancer types. Transfer learning has made it possible for the algorithm to break the critical accuracy barrier. The proposed algorithm reports an accuracy of 75.9% on breast cancer TMA images from the Stanford Tissue Microarray Database, achieving the 75% accuracy level of pathologists. This will allow pathologists to confidently use automatic algorithms to assist them in recognizing tumors consistently with a higher accuracy in real time.
Understanding Tieq Viet with Deep Learning Models
Jul 03, 2022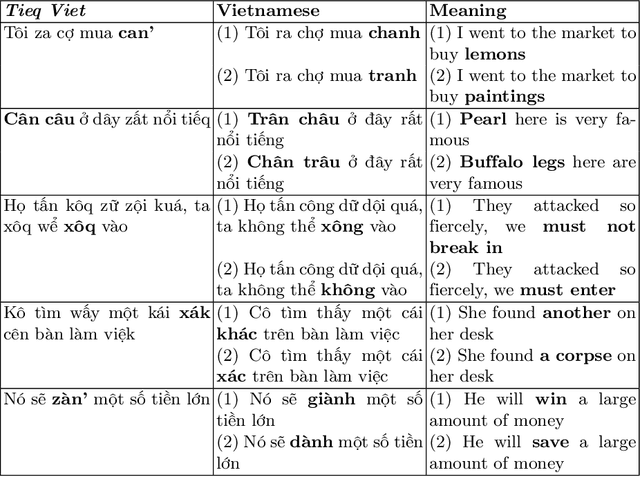
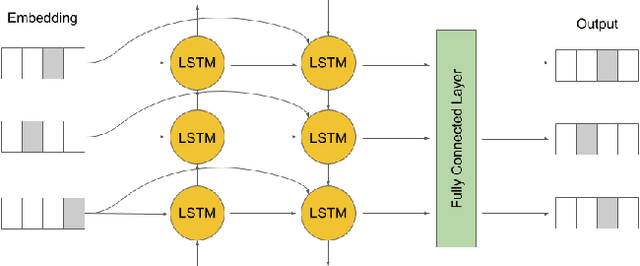

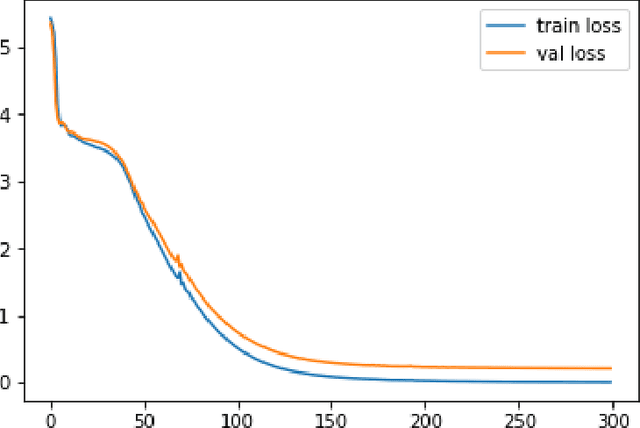
Deep learning is a powerful approach in recovering lost information as well as harder inverse function computation problems. When applied in natural language processing, this approach is essentially making use of context as a mean to recover information through likelihood maximization. Not long ago, a linguistic study called Tieq Viet was controversial among both researchers and society. We find this a great example to demonstrate the ability of deep learning models to recover lost information. In the proposal of Tieq Viet, some consonants in the standard Vietnamese are replaced. A sentence written in this proposal can be interpreted into multiple sentences in the standard version, with different meanings. The hypothesis that we want to test is whether a deep learning model can recover the lost information if we translate the text from Vietnamese to Tieq Viet.