 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Model-driven Learning for Generic MIMO Downlink Beamforming With Uplink Channel Information
Sep 16, 2021
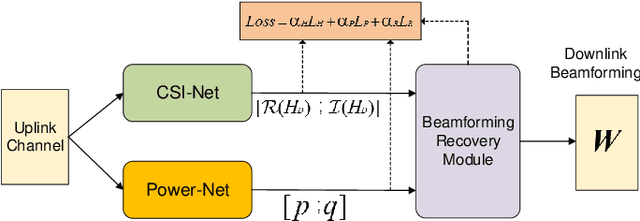
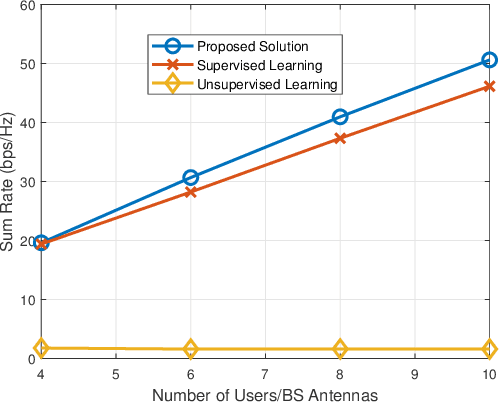
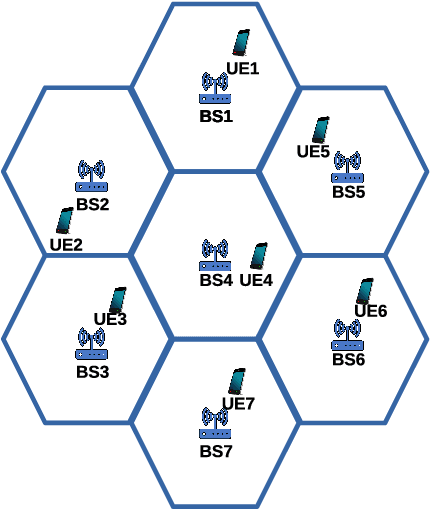
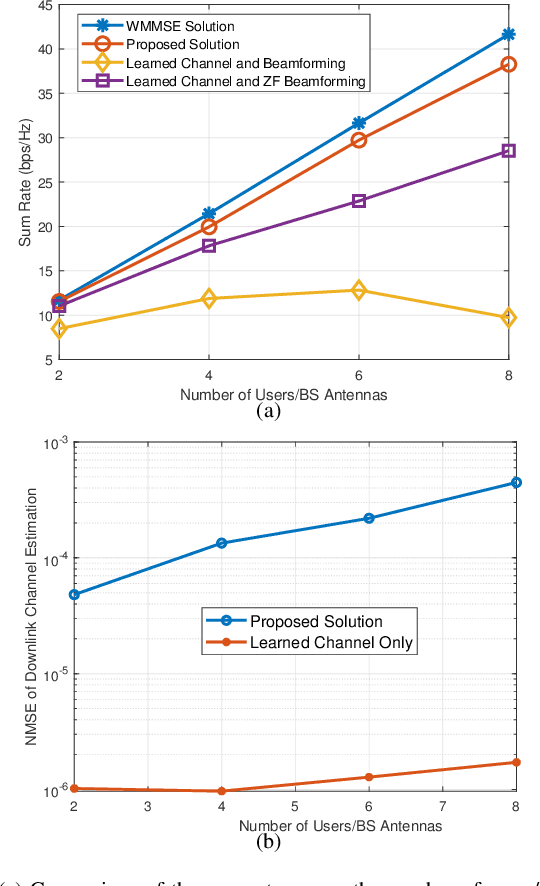
Accurate downlink channel information is crucial to the beamforming design, but it is difficult to obtain in practice. This paper investigates a deep learning-based optimization approach of the downlink beamforming to maximize the system sum rate, when only the uplink channel information is available. Our main contribution is to propose a model-driven learning technique that exploits the structure of the optimal downlink beamforming to design an effective hybrid learning strategy with the aim to maximize the sum rate performance. This is achieved by jointly considering the learning performance of the downlink channel, the power and the sum rate in the training stage. The proposed approach applies to generic cases in which the uplink channel information is available, but its relation to the downlink channel is unknown and does not require an explicit downlink channel estimation. We further extend the developed technique to massive multiple-input multiple-output scenarios and achieve a distributed learning strategy for multicell systems without an inter-cell signalling overhead. Simulation results verify that our proposed method provides the performance close to the state of the art numerical algorithms with perfect downlink channel information and significantly outperforms existing data-driven methods in terms of the sum rate.
Clustering units in neural networks: upstream vs downstream information
Mar 22, 2022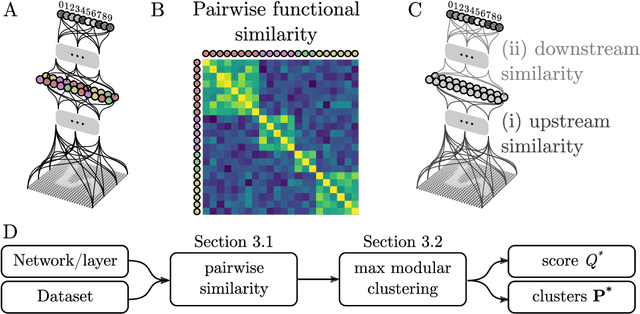
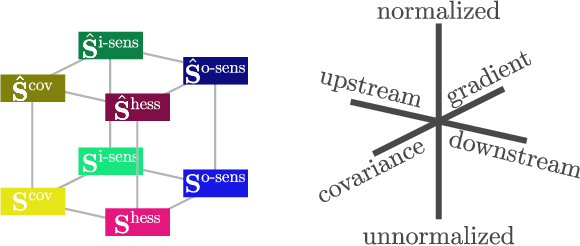
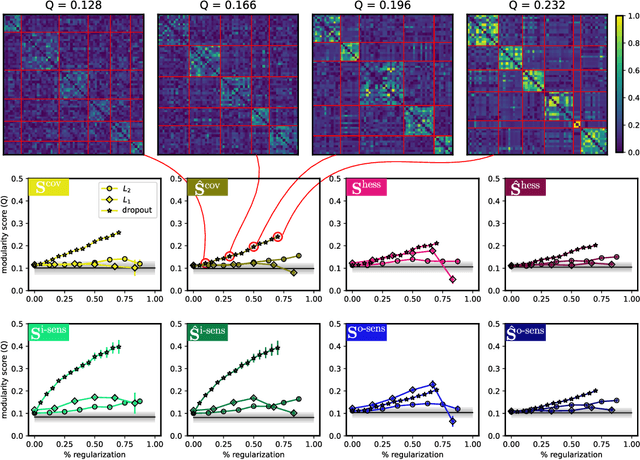
It has been hypothesized that some form of "modular" structure in artificial neural networks should be useful for learning, compositionality, and generalization. However, defining and quantifying modularity remains an open problem. We cast the problem of detecting functional modules into the problem of detecting clusters of similar-functioning units. This begs the question of what makes two units functionally similar. For this, we consider two broad families of methods: those that define similarity based on how units respond to structured variations in inputs ("upstream"), and those based on how variations in hidden unit activations affect outputs ("downstream"). We conduct an empirical study quantifying modularity of hidden layer representations of simple feedforward, fully connected networks, across a range of hyperparameters. For each model, we quantify pairwise associations between hidden units in each layer using a variety of both upstream and downstream measures, then cluster them by maximizing their "modularity score" using established tools from network science. We find two surprising results: first, dropout dramatically increased modularity, while other forms of weight regularization had more modest effects. Second, although we observe that there is usually good agreement about clusters within both upstream methods and downstream methods, there is little agreement about the cluster assignments across these two families of methods. This has important implications for representation-learning, as it suggests that finding modular representations that reflect structure in inputs (e.g. disentanglement) may be a distinct goal from learning modular representations that reflect structure in outputs (e.g. compositionality).
HPPNet: Modeling the Harmonic Structure and Pitch Invariance in Piano Transcription
Aug 31, 2022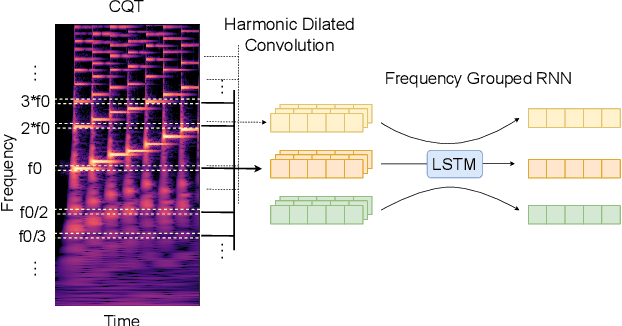
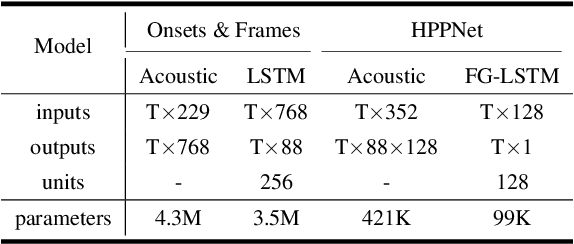
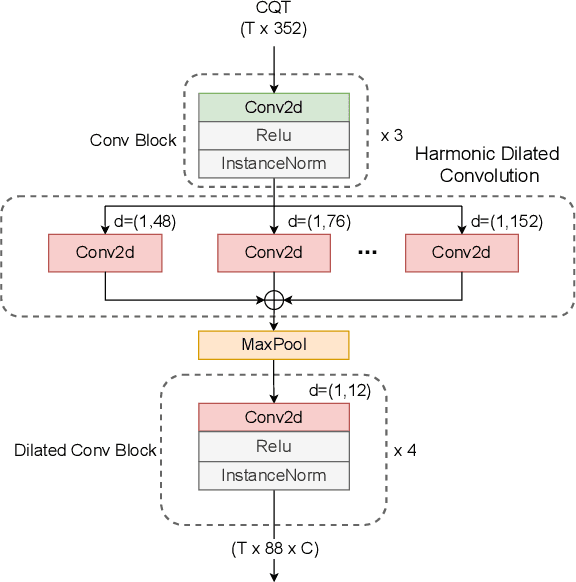
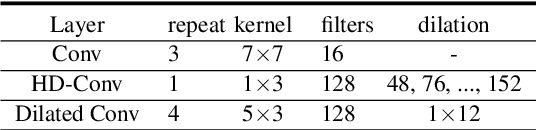
While neural network models are making significant progress in piano transcription, they are becoming more resource-consuming due to requiring larger model size and more computing power. In this paper, we attempt to apply more prior about piano to reduce model size and improve the transcription performance. The sound of a piano note contains various overtones, and the pitch of a key does not change over time. To make full use of such latent information, we propose HPPNet that using the Harmonic Dilated Convolution to capture the harmonic structures and the Frequency Grouped Recurrent Neural Network to model the pitch-invariance over time. Experimental results on the MAESTRO dataset show that our piano transcription system achieves state-of-the-art performance both in frame and note scores (frame F1 93.15%, note F1 97.18%). Moreover, the model size is much smaller than the previous state-of-the-art deep learning models.
Distributed Learning over a Wireless Network with Non-coherent Majority Vote Computation
Sep 10, 2022
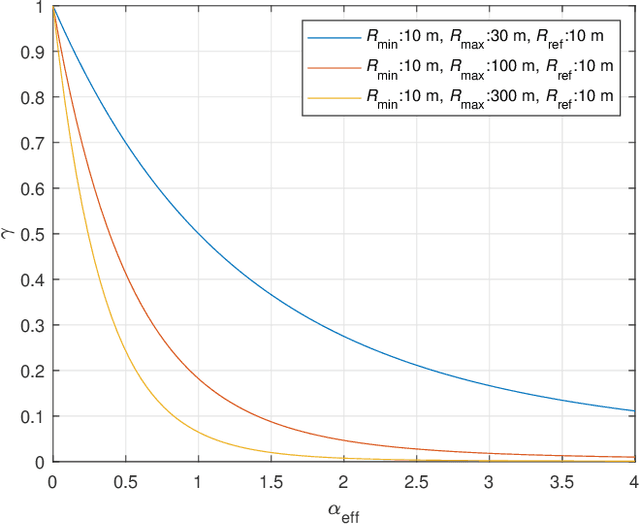
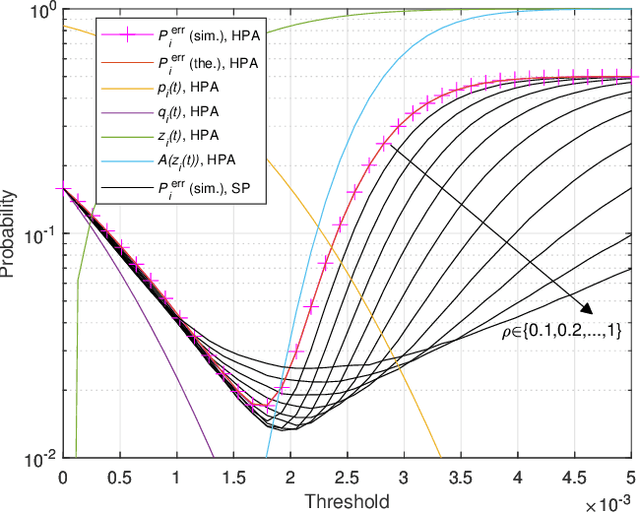

In this study, we propose an over-the-air computation (OAC) scheme to calculate the majority vote (MV) for federated edge learning (FEEL). With the proposed approach, edge devices (EDs) transmit the signs of local stochastic gradients, i.e., votes, by activating one of two orthogonal resources. The MVs at the edge server (ES) are obtained with non-coherent detectors by exploiting the accumulations on the resources. Hence, the proposed scheme eliminates the need for channel state information (CSI) at the EDs and ES. In this study, we analyze various gradient-encoding strategies through the weight functions and waveform configurations over orthogonal frequency division multiplexing (OFDM). We show that specific weight functions that enable absentee EDs (i.e., hard-coded participation with absentees (HPA)) or weighted votes (i.e., soft-coded participation (SP)) can substantially reduce the probability of detecting the incorrect MV. By taking path loss, power control, cell size, and fading channel into account, we prove the convergence of the distributed learning for a non-convex function for HPA. Through simulations, we show that the proposed scheme with HPA and SP can provide high test accuracy even when the time-synchronization and the power control are not ideal under heterogeneous data distribution scenarios.
Explaining Representation by Mutual Information
Mar 28, 2021


Science is used to discover the law of world. Machine learning can be used to discover the law of data. In recent years, there are more and more research about interpretability in machine learning community. We hope the machine learning methods are safe, interpretable, and they can help us to find meaningful pattern in data. In this paper, we focus on interpretability of deep representation. We propose a interpretable method of representation based on mutual information, which summarizes the interpretation of representation into three types of information between input data and representation. We further proposed MI-LR module, which can be inserted into the model to estimate the amount of information to explain the model's representation. Finally, we verify the method through the visualization of the prototype network.
Decentralized Machine Learning for Intelligent Health Care Systems on the Computing Continuum
Jul 29, 2022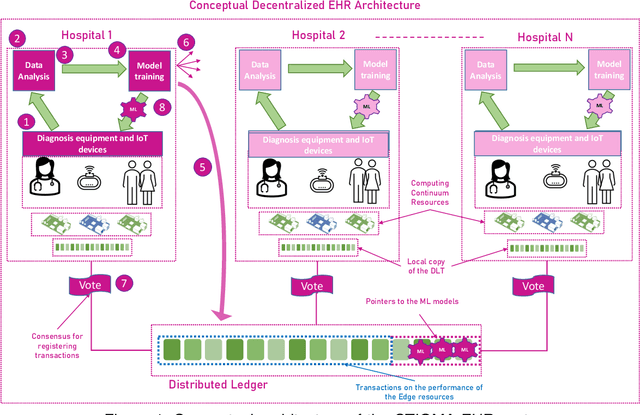
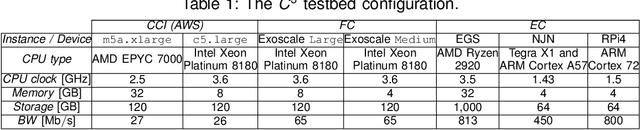
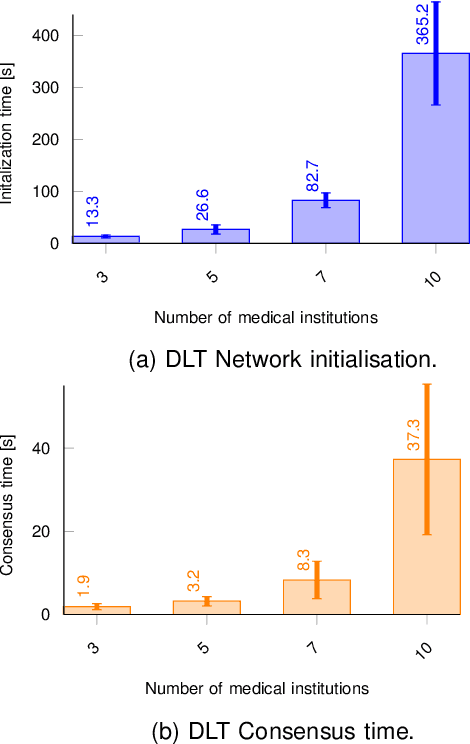
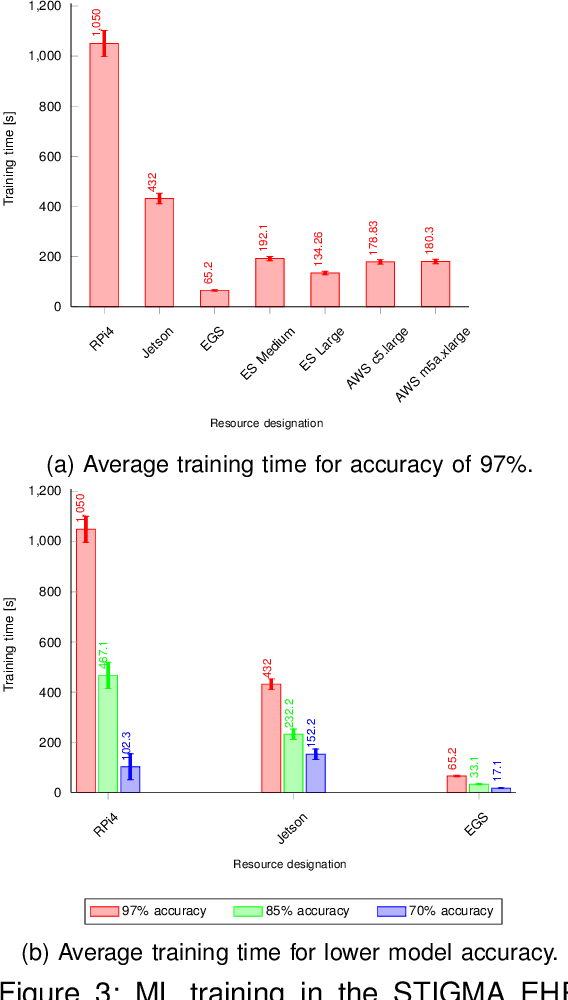
The introduction of electronic personal health records (EHR) enables nationwide information exchange and curation among different health care systems. However, the current EHR systems do not provide transparent means for diagnosis support, medical research or can utilize the omnipresent data produced by the personal medical devices. Besides, the EHR systems are centrally orchestrated, which could potentially lead to a single point of failure. Therefore, in this article, we explore novel approaches for decentralizing machine learning over distributed ledgers to create intelligent EHR systems that can utilize information from personal medical devices for improved knowledge extraction. Consequently, we proposed and evaluated a conceptual EHR to enable anonymous predictive analysis across multiple medical institutions. The evaluation results indicate that the decentralized EHR can be deployed over the computing continuum with reduced machine learning time of up to 60% and consensus latency of below 8 seconds.
SDA-$x$Net: Selective Depth Attention Networks for Adaptive Multi-scale Feature Representation
Sep 21, 2022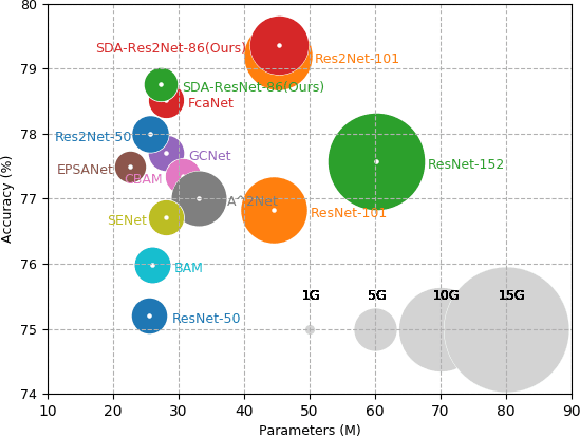
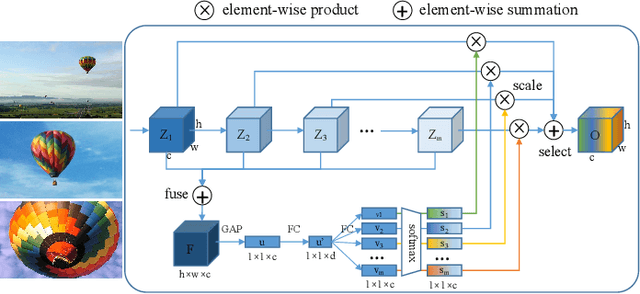
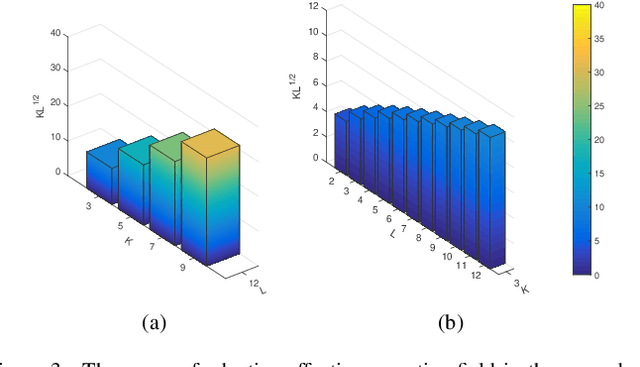
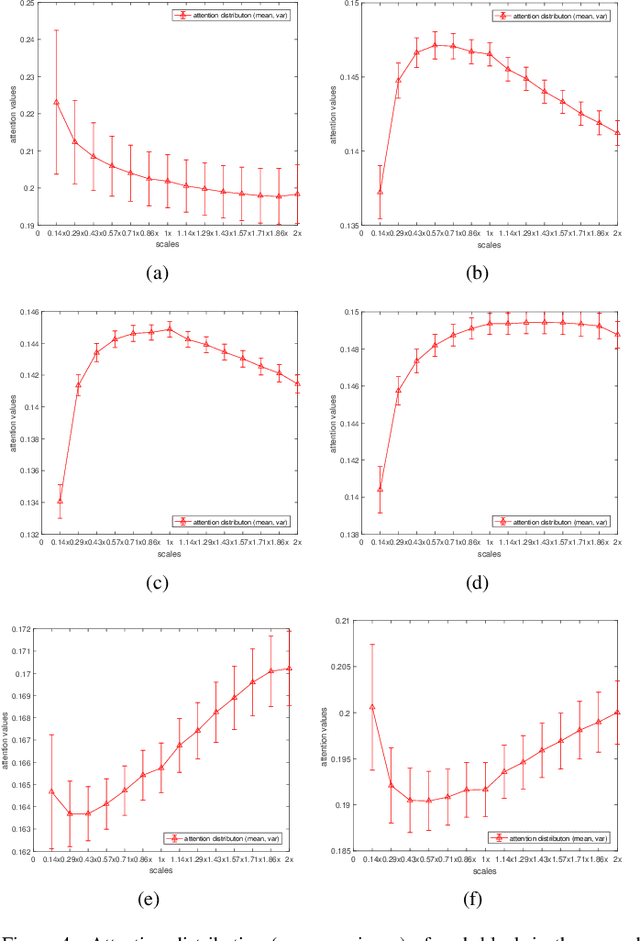
Existing multi-scale solutions lead to a risk of just increasing the receptive field sizes while neglecting small receptive fields. Thus, it is a challenging problem to effectively construct adaptive neural networks for recognizing various spatial-scale objects. To tackle this issue, we first introduce a new attention dimension, i.e., depth, in addition to existing attention dimensions such as channel, spatial, and branch, and present a novel selective depth attention network to symmetrically handle multi-scale objects in various vision tasks. Specifically, the blocks within each stage of a given neural network, i.e., ResNet, output hierarchical feature maps sharing the same resolution but with different receptive field sizes. Based on this structural property, we design a stage-wise building module, namely SDA, which includes a trunk branch and a SE-like attention branch. The block outputs of the trunk branch are fused to globally guide their depth attention allocation through the attention branch. According to the proposed attention mechanism, we can dynamically select different depth features, which contributes to adaptively adjusting the receptive field sizes for the variable-sized input objects. In this way, the cross-block information interaction leads to a long-range dependency along the depth direction. Compared with other multi-scale approaches, our SDA method combines multiple receptive fields from previous blocks into the stage output, thus offering a wider and richer range of effective receptive fields. Moreover, our method can be served as a pluggable module to other multi-scale networks as well as attention networks, coined as SDA-$x$Net. Their combination further extends the range of the effective receptive fields towards small receptive fields, enabling interpretable neural networks. Our source code is available at \url{https://github.com/QingbeiGuo/SDA-xNet.git}.
Audio-Visual Fusion for Emotion Recognition in the Valence-Arousal Space Using Joint Cross-Attention
Sep 19, 2022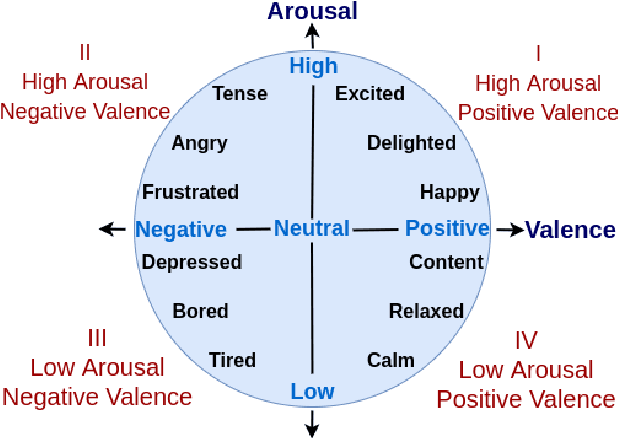
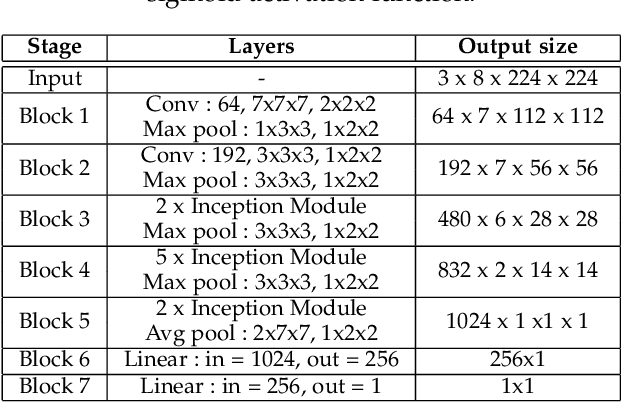
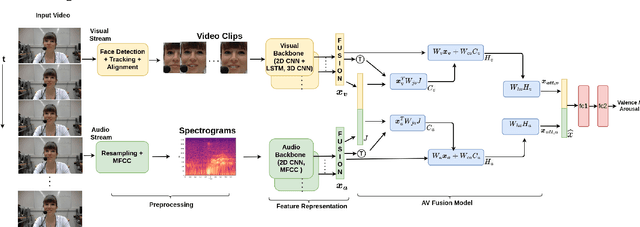
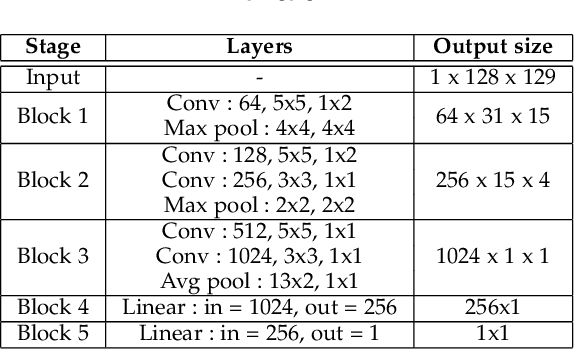
Automatic emotion recognition (ER) has recently gained lot of interest due to its potential in many real-world applications. In this context, multimodal approaches have been shown to improve performance (over unimodal approaches) by combining diverse and complementary sources of information, providing some robustness to noisy and missing modalities. In this paper, we focus on dimensional ER based on the fusion of facial and vocal modalities extracted from videos, where complementary audio-visual (A-V) relationships are explored to predict an individual's emotional states in valence-arousal space. Most state-of-the-art fusion techniques rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complementary nature of A-V modalities. To address this problem, we introduce a joint cross-attentional model for A-V fusion that extracts the salient features across A-V modalities, that allows to effectively leverage the inter-modal relationships, while retaining the intra-modal relationships. In particular, it computes the cross-attention weights based on correlation between the joint feature representation and that of the individual modalities. By deploying the joint A-V feature representation into the cross-attention module, it helps to simultaneously leverage both the intra and inter modal relationships, thereby significantly improving the performance of the system over the vanilla cross-attention module. The effectiveness of our proposed approach is validated experimentally on challenging videos from the RECOLA and AffWild2 datasets. Results indicate that our joint cross-attentional A-V fusion model provides a cost-effective solution that can outperform state-of-the-art approaches, even when the modalities are noisy or absent.
Bounding Information Leakage in Machine Learning
May 09, 2021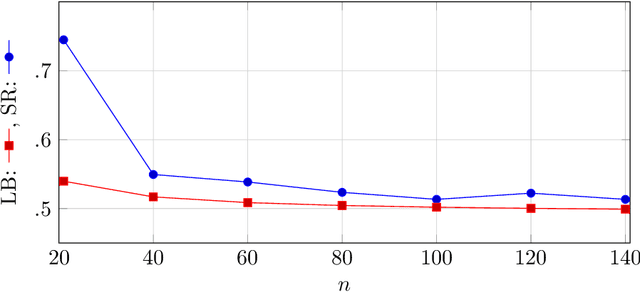
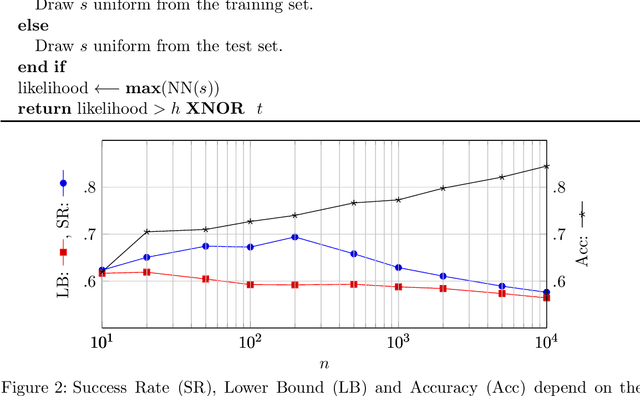
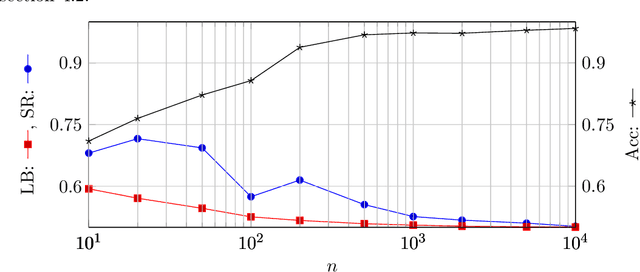
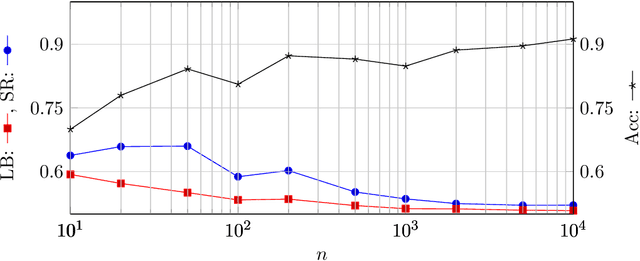
Machine Learning services are being deployed in a large range of applications that make it easy for an adversary, using the algorithm and/or the model, to gain access to sensitive data. This paper investigates fundamental bounds on information leakage. First, we identify and bound the success rate of the worst-case membership inference attack, connecting it to the generalization error of the target model. Second, we study the question of how much sensitive information is stored by the algorithm about the training set and we derive bounds on the mutual information between the sensitive attributes and model parameters. Although our contributions are mostly of theoretical nature, the bounds and involved concepts are of practical relevance. Inspired by our theoretical analysis, we study linear regression and DNN models to illustrate how these bounds can be used to assess the privacy guarantees of ML models.
Johnson-Lindenstrauss embeddings for noisy vectors -- taking advantage of the noise
Sep 01, 2022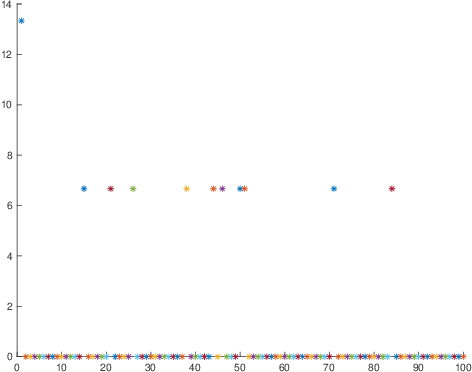
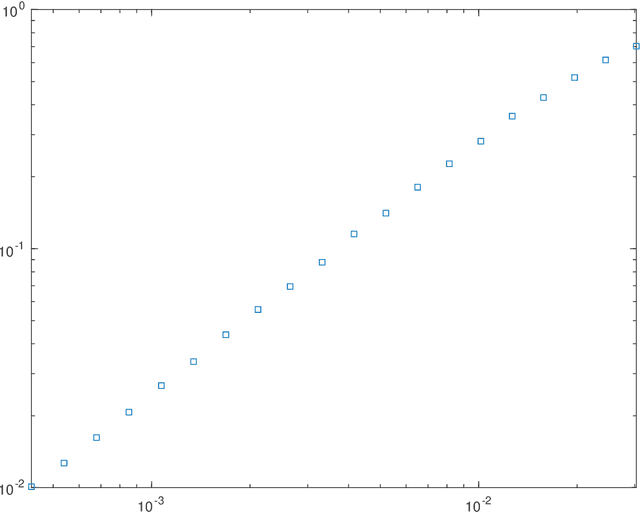
This paper investigates theoretical properties of subsampling and hashing as tools for approximate Euclidean norm-preserving embeddings for vectors with (unknown) additive Gaussian noises. Such embeddings are sometimes called Johnson-lindenstrauss embeddings due to their celebrated lemma. Previous work shows that as sparse embeddings, the success of subsampling and hashing closely depends on the $l_\infty$ to $l_2$ ratios of the vector to be mapped. This paper shows that the presence of noise removes such constrain in high-dimensions, in other words, sparse embeddings such as subsampling and hashing with comparable embedding dimensions to dense embeddings have similar approximate norm-preserving dimensionality-reduction properties. The key is that the noise should be treated as an information to be exploited, not simply something to be removed. Theoretical bounds for subsampling and hashing to recover the approximate norm of a high dimension vector in the presence of noise are derived, with numerical illustrations showing better performances are achieved in the presence of noise.