 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Attention Empowered Graph Convolutional Network for Structure Learning and Node Embedding
Mar 06, 2024
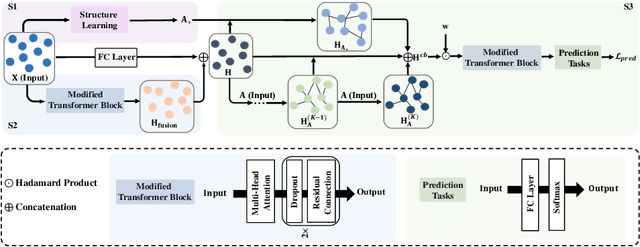
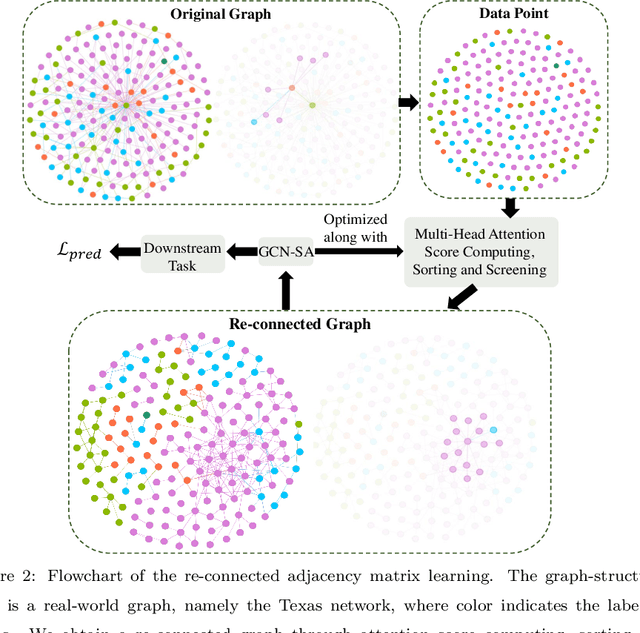
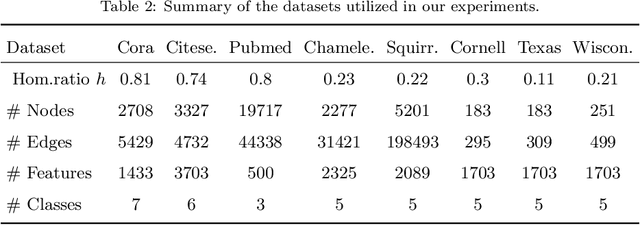
In representation learning on graph-structured data, many popular graph neural networks (GNNs) fail to capture long-range dependencies, leading to performance degradation. Furthermore, this weakness is magnified when the concerned graph is characterized by heterophily (low homophily). To solve this issue, this paper proposes a novel graph learning framework called the graph convolutional network with self-attention (GCN-SA). The proposed scheme exhibits an exceptional generalization capability in node-level representation learning. The proposed GCN-SA contains two enhancements corresponding to edges and node features. For edges, we utilize a self-attention mechanism to design a stable and effective graph-structure-learning module that can capture the internal correlation between any pair of nodes. This graph-structure-learning module can identify reliable neighbors for each node from the entire graph. Regarding the node features, we modify the transformer block to make it more applicable to enable GCN to fuse valuable information from the entire graph. These two enhancements work in distinct ways to help our GCN-SA capture long-range dependencies, enabling it to perform representation learning on graphs with varying levels of homophily. The experimental results on benchmark datasets demonstrate the effectiveness of the proposed GCN-SA. Compared to other outstanding GNN counterparts, the proposed GCN-SA is competitive.
Towards Understanding Cross and Self-Attention in Stable Diffusion for Text-Guided Image Editing
Mar 06, 2024
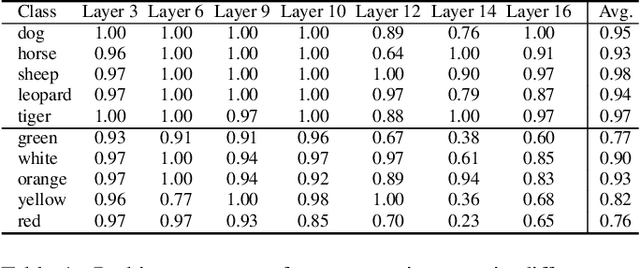
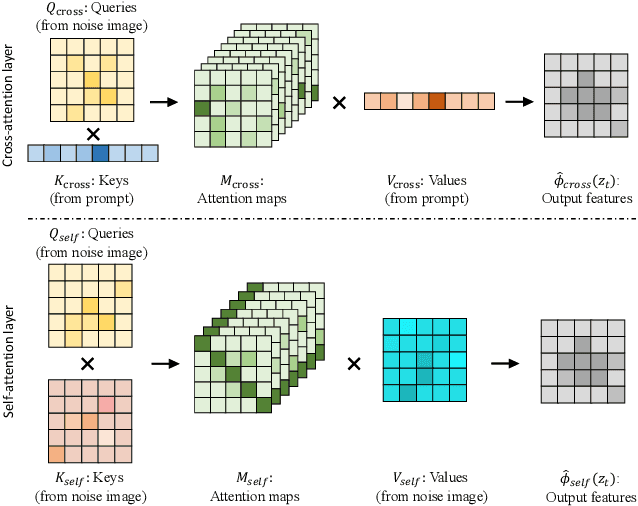
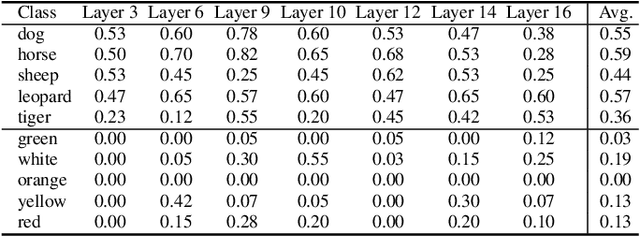
Deep Text-to-Image Synthesis (TIS) models such as Stable Diffusion have recently gained significant popularity for creative Text-to-image generation. Yet, for domain-specific scenarios, tuning-free Text-guided Image Editing (TIE) is of greater importance for application developers, which modify objects or object properties in images by manipulating feature components in attention layers during the generation process. However, little is known about what semantic meanings these attention layers have learned and which parts of the attention maps contribute to the success of image editing. In this paper, we conduct an in-depth probing analysis and demonstrate that cross-attention maps in Stable Diffusion often contain object attribution information that can result in editing failures. In contrast, self-attention maps play a crucial role in preserving the geometric and shape details of the source image during the transformation to the target image. Our analysis offers valuable insights into understanding cross and self-attention maps in diffusion models. Moreover, based on our findings, we simplify popular image editing methods and propose a more straightforward yet more stable and efficient tuning-free procedure that only modifies self-attention maps of the specified attention layers during the denoising process. Experimental results show that our simplified method consistently surpasses the performance of popular approaches on multiple datasets.
Introducing First-Principles Calculations: New Approach to Group Dynamics and Bridging Social Phenomena in TeNP-Chain Based Social Dynamics Simulations
Mar 06, 2024
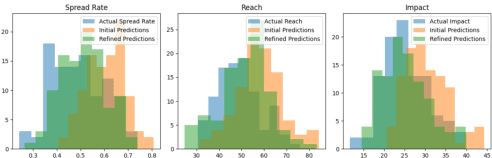
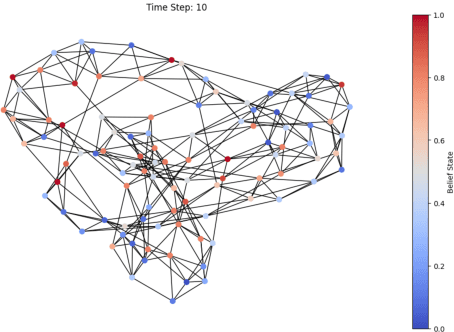
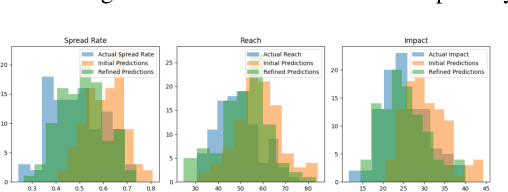
This note considers an innovative interdisciplinary methodology that bridges the gap between the fundamental principles of quantum mechanics applied to the study of materials such as tellurium nanoparticles (TeNPs) and graphene and the complex dynamics of social systems. The basis for this approach lies in the metaphorical parallels drawn between the structural features of TeNPs and graphene and the behavioral patterns of social groups in the face of misinformation. TeNPs exhibit unique properties such as the strengthening of covalent bonds within telluric chains and the disruption of secondary structure leading to the separation of these chains. This is analogous to increased cohesion within social groups and disruption of information flow between different subgroups, respectively. . Similarly, the outstanding properties of graphene, such as high electrical conductivity, strength, and flexibility, provide additional aspects for understanding the resilience and adaptability of social structures in response to external stimuli such as fake news. This research note proposes a novel metaphorical framework for analyzing the spread of fake news within social groups, analogous to the structural features of telluric nanoparticles (TeNPs). We investigate how the strengthening of covalent bonds within TeNPs reflects the strengthening of social cohesion in groups that share common beliefs and values.
Video Relationship Detection Using Mixture of Experts
Mar 06, 2024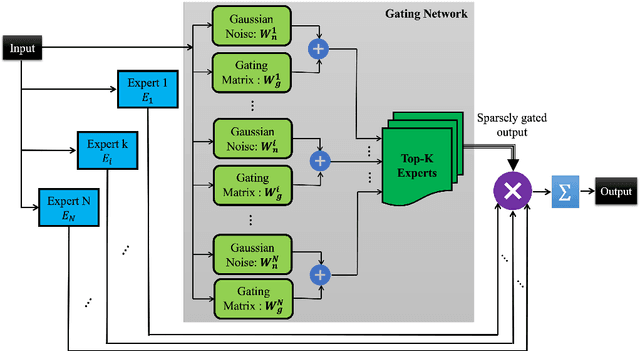
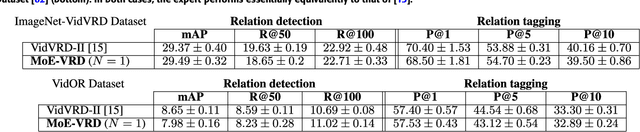
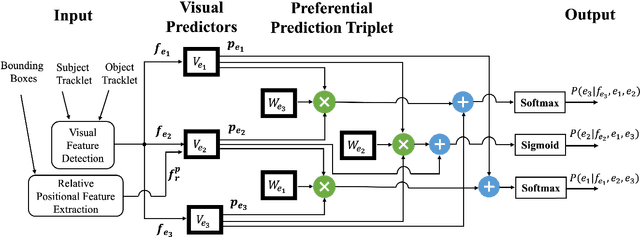
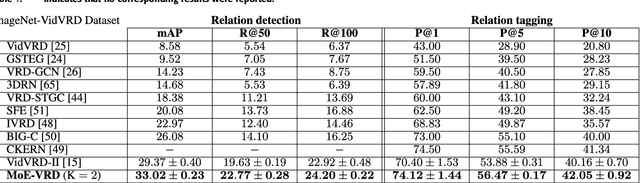
Machine comprehension of visual information from images and videos by neural networks faces two primary challenges. Firstly, there exists a computational and inference gap in connecting vision and language, making it difficult to accurately determine which object a given agent acts on and represent it through language. Secondly, classifiers trained by a single, monolithic neural network often lack stability and generalization. To overcome these challenges, we introduce MoE-VRD, a novel approach to visual relationship detection utilizing a mixture of experts. MoE-VRD identifies language triplets in the form of < subject, predicate, object> tuples to extract relationships from visual processing. Leveraging recent advancements in visual relationship detection, MoE-VRD addresses the requirement for action recognition in establishing relationships between subjects (acting) and objects (being acted upon). In contrast to single monolithic networks, MoE-VRD employs multiple small models as experts, whose outputs are aggregated. Each expert in MoE-VRD specializes in visual relationship learning and object tagging. By utilizing a sparsely-gated mixture of experts, MoE-VRD enables conditional computation and significantly enhances neural network capacity without increasing computational complexity. Our experimental results demonstrate that the conditional computation capabilities and scalability of the mixture-of-experts approach lead to superior performance in visual relationship detection compared to state-of-the-art methods.
KIWI: A Dataset of Knowledge-Intensive Writing Instructions for Answering Research Questions
Mar 06, 2024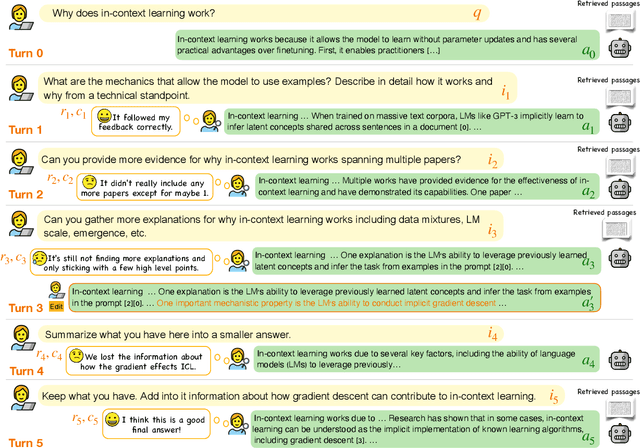

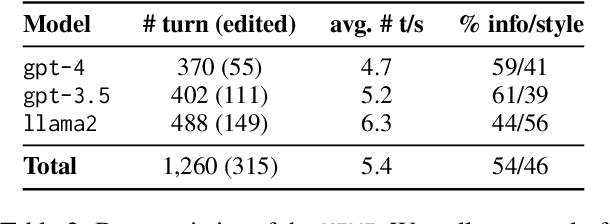
Large language models (LLMs) adapted to follow user instructions are now widely deployed as conversational agents. In this work, we examine one increasingly common instruction-following task: providing writing assistance to compose a long-form answer. To evaluate the capabilities of current LLMs on this task, we construct KIWI, a dataset of knowledge-intensive writing instructions in the scientific domain. Given a research question, an initial model-generated answer and a set of relevant papers, an expert annotator iteratively issues instructions for the model to revise and improve its answer. We collect 1,260 interaction turns from 234 interaction sessions with three state-of-the-art LLMs. Each turn includes a user instruction, a model response, and a human evaluation of the model response. Through a detailed analysis of the collected responses, we find that all models struggle to incorporate new information into an existing answer, and to perform precise and unambiguous edits. Further, we find that models struggle to judge whether their outputs successfully followed user instructions, with accuracy at least 10 points short of human agreement. Our findings indicate that KIWI will be a valuable resource to measure progress and improve LLMs' instruction-following capabilities for knowledge intensive writing tasks.
Temporal Enhanced Floating Car Observers
Mar 06, 2024
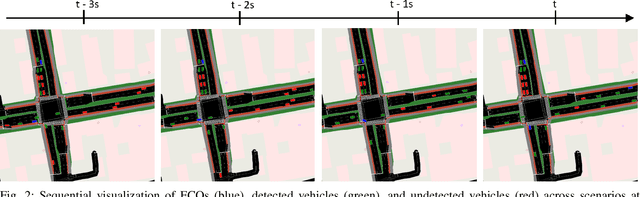
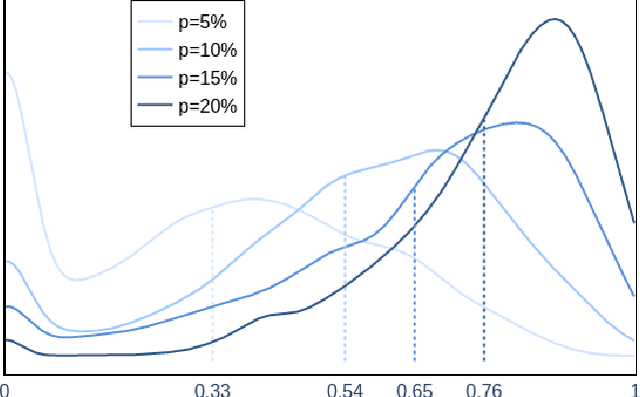
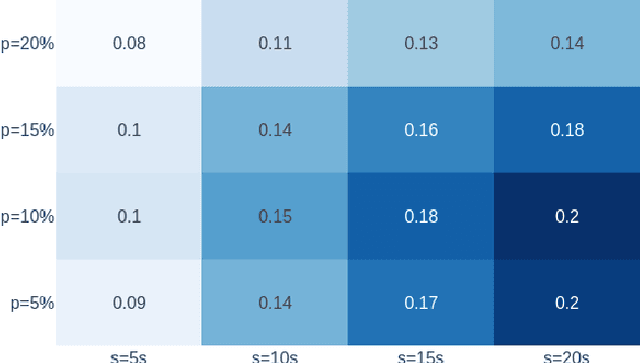
Floating Car Observers (FCOs) are an innovative method to collect traffic data by deploying sensor-equipped vehicles to detect and locate other vehicles. We demonstrate that even a small penetration rate of FCOs can identify a significant amount of vehicles at a given intersection. This is achieved through the emulation of detection within a microscopic traffic simulation. Additionally, leveraging data from previous moments can enhance the detection of vehicles in the current frame. Our findings indicate that, with a 20-second observation window, it is possible to recover up to 20\% of vehicles that are not visible by FCOs in the current timestep. To exploit this, we developed a data-driven strategy, utilizing sequences of Bird's Eye View (BEV) representations of detected vehicles and deep learning models. This approach aims to bring currently undetected vehicles into view in the present moment, enhancing the currently detected vehicles. Results of different spatiotemporal architectures show that up to 41\% of the vehicles can be recovered into the current timestep at their current position. This enhancement enriches the information initially available by the FCO, allowing an improved estimation of traffic states and metrics (e.g. density and queue length) for improved implementation of traffic management strategies.
Learning using privileged information for segmenting tumors on digital mammograms
Feb 09, 2024Limited amount of data and data sharing restrictions, due to GDPR compliance, constitute two common factors leading to reduced availability and accessibility when referring to medical data. To tackle these issues, we introduce the technique of Learning Using Privileged Information. Aiming to substantiate the idea, we attempt to build a robust model that improves the segmentation quality of tumors on digital mammograms, by gaining privileged information knowledge during the training procedure. Towards this direction, a baseline model, called student, is trained on patches extracted from the original mammograms, while an auxiliary model with the same architecture, called teacher, is trained on the corresponding enhanced patches accessing, in this way, privileged information. We repeat the student training procedure by providing the assistance of the teacher model this time. According to the experimental results, it seems that the proposed methodology performs better in the most of the cases and it can achieve 10% higher F1 score in comparison with the baseline.
Solution Simplex Clustering for Heterogeneous Federated Learning
Mar 05, 2024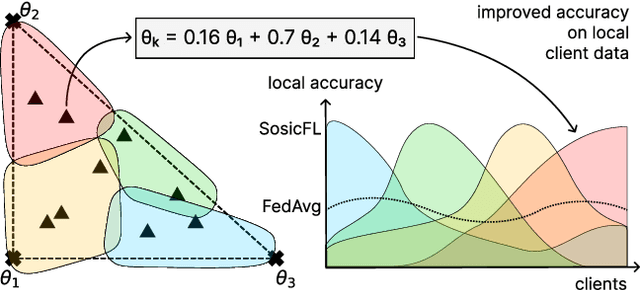

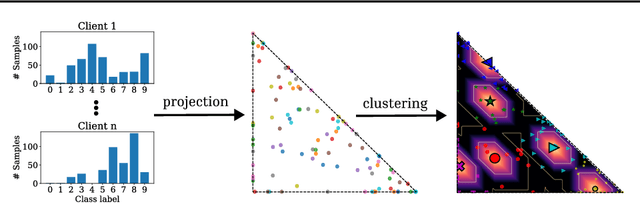
We tackle a major challenge in federated learning (FL) -- achieving good performance under highly heterogeneous client distributions. The difficulty partially arises from two seemingly contradictory goals: learning a common model by aggregating the information from clients, and learning local personalized models that should be adapted to each local distribution. In this work, we propose Solution Simplex Clustered Federated Learning (SosicFL) for dissolving such contradiction. Based on the recent ideas of learning solution simplices, SosicFL assigns a subregion in a simplex to each client, and performs FL to learn a common solution simplex. This allows the client models to possess their characteristics within the degrees of freedom in the solution simplex, and at the same time achieves the goal of learning a global common model. Our experiments show that SosicFL improves the performance and accelerates the training process for global and personalized FL with minimal computational overhead.
MatchU: Matching Unseen Objects for 6D Pose Estimation from RGB-D Images
Mar 03, 2024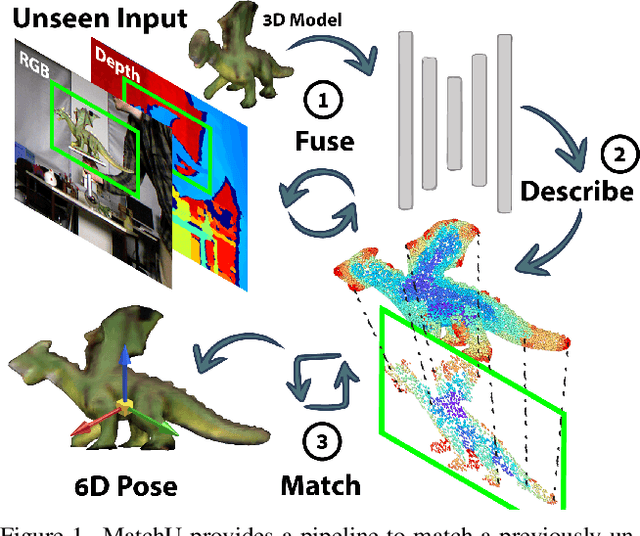
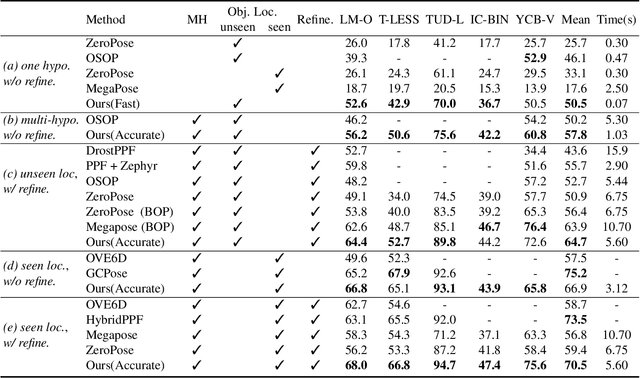
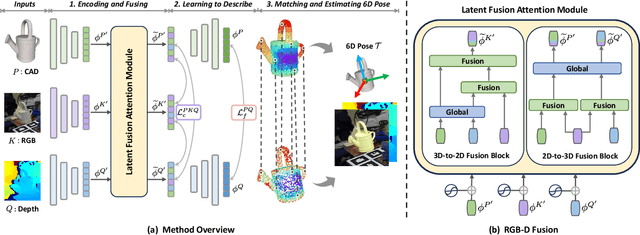
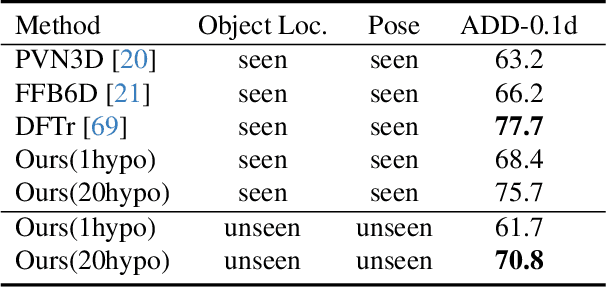
Recent learning methods for object pose estimation require resource-intensive training for each individual object instance or category, hampering their scalability in real applications when confronted with previously unseen objects. In this paper, we propose MatchU, a Fuse-Describe-Match strategy for 6D pose estimation from RGB-D images. MatchU is a generic approach that fuses 2D texture and 3D geometric cues for 6D pose prediction of unseen objects. We rely on learning geometric 3D descriptors that are rotation-invariant by design. By encoding pose-agnostic geometry, the learned descriptors naturally generalize to unseen objects and capture symmetries. To tackle ambiguous associations using 3D geometry only, we fuse additional RGB information into our descriptor. This is achieved through a novel attention-based mechanism that fuses cross-modal information, together with a matching loss that leverages the latent space learned from RGB data to guide the descriptor learning process. Extensive experiments reveal the generalizability of both the RGB-D fusion strategy as well as the descriptor efficacy. Benefiting from the novel designs, MatchU surpasses all existing methods by a significant margin in terms of both accuracy and speed, even without the requirement of expensive re-training or rendering.
When does word order matter and when doesn't it?
Mar 01, 2024Language models (LMs) may appear insensitive to word order changes in natural language understanding (NLU) tasks. In this paper, we propose that linguistic redundancy can explain this phenomenon, whereby word order and other linguistic cues such as case markers provide overlapping and thus redundant information. Our hypothesis is that models exhibit insensitivity to word order when the order provides redundant information, and the degree of insensitivity varies across tasks. We quantify how informative word order is using mutual information (MI) between unscrambled and scrambled sentences. Our results show the effect that the less informative word order is, the more consistent the model's predictions are between unscrambled and scrambled sentences. We also find that the effect varies across tasks: for some tasks, like SST-2, LMs' prediction is almost always consistent with the original one even if the Pointwise-MI (PMI) changes, while for others, like RTE, the consistency is near random when the PMI gets lower, i.e., word order is really important.