 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Depth Estimation in Laparoscopic Image using 3D Geometric Consistency
Aug 17, 2022
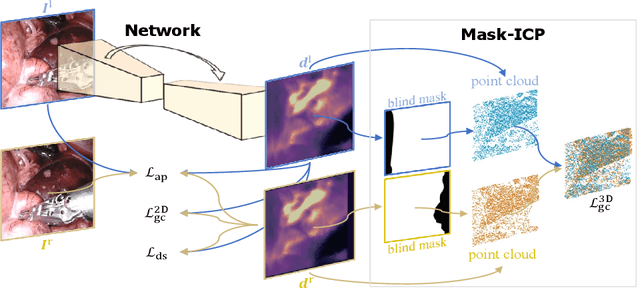
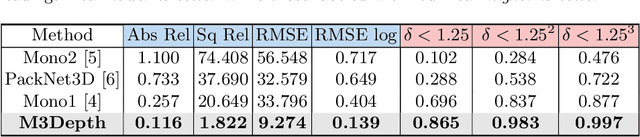
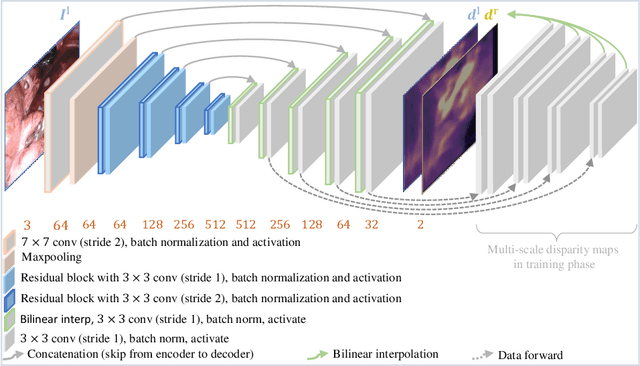

Depth estimation is a crucial step for image-guided intervention in robotic surgery and laparoscopic imaging system. Since per-pixel depth ground truth is difficult to acquire for laparoscopic image data, it is rarely possible to apply supervised depth estimation to surgical applications. As an alternative, self-supervised methods have been introduced to train depth estimators using only synchronized stereo image pairs. However, most recent work focused on the left-right consistency in 2D and ignored valuable inherent 3D information on the object in real world coordinates, meaning that the left-right 3D geometric structural consistency is not fully utilized. To overcome this limitation, we present M3Depth, a self-supervised depth estimator to leverage 3D geometric structural information hidden in stereo pairs while keeping monocular inference. The method also removes the influence of border regions unseen in at least one of the stereo images via masking, to enhance the correspondences between left and right images in overlapping areas. Intensive experiments show that our method outperforms previous self-supervised approaches on both a public dataset and a newly acquired dataset by a large margin, indicating a good generalization across different samples and laparoscopes.
A Causal Intervention Scheme for Semantic Segmentation of Quasi-periodic Cardiovascular Signals
Sep 19, 2022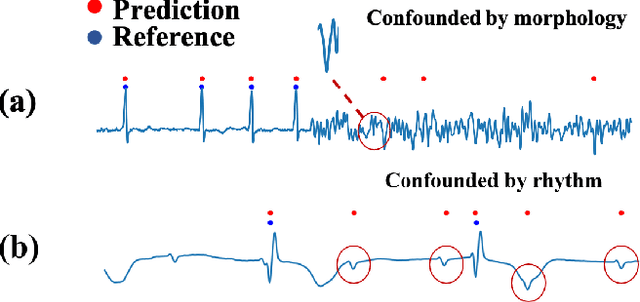
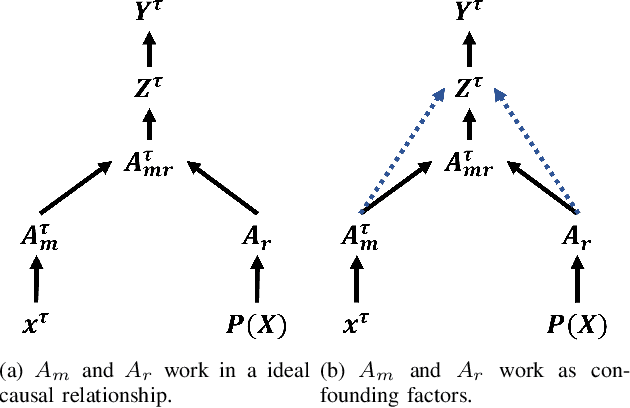
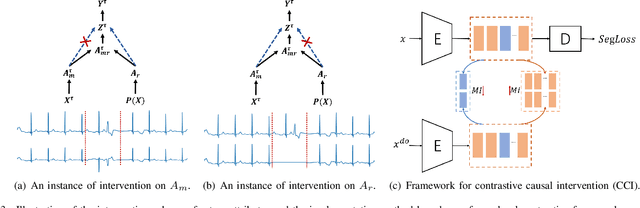
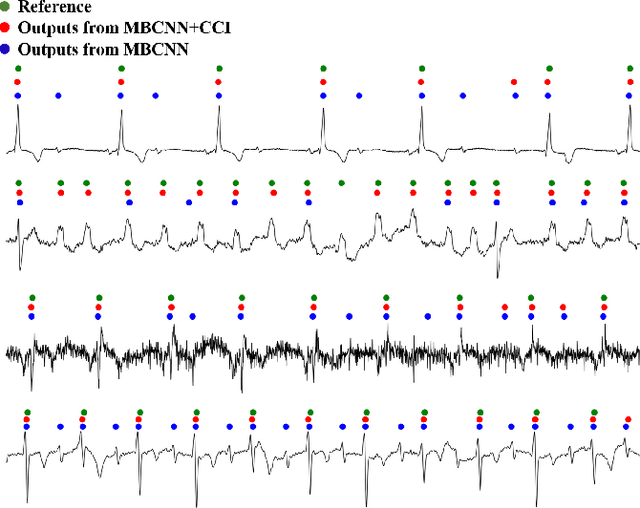
Precise segmentation is a vital first step to analyze semantic information of cardiac cycle and capture anomaly with cardiovascular signals. However, in the field of deep semantic segmentation, inference is often unilaterally confounded by the individual attribute of data. Towards cardiovascular signals, quasi-periodicity is the essential characteristic to be learned, regarded as the synthesize of the attributes of morphology (Am) and rhythm (Ar). Our key insight is to suppress the over-dependence on Am or Ar while the generation process of deep representations. To address this issue, we establish a structural causal model as the foundation to customize the intervention approaches on Am and Ar, respectively. In this paper, we propose contrastive causal intervention (CCI) to form a novel training paradigm under a frame-level contrastive framework. The intervention can eliminate the implicit statistical bias brought by the single attribute and lead to more objective representations. We conduct comprehensive experiments with the controlled condition for QRS location and heart sound segmentation. The final results indicate that our approach can evidently improve the performance by up to 0.41% for QRS location and 2.73% for heart sound segmentation. The efficiency of the proposed method is generalized to multiple databases and noisy signals.
Multi-Scale Attention-based Multiple Instance Learning for Classification of Multi-Gigapixel Histology Images
Sep 07, 2022
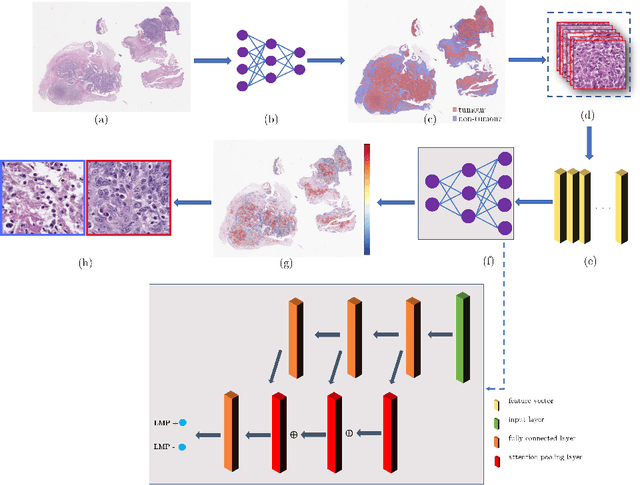
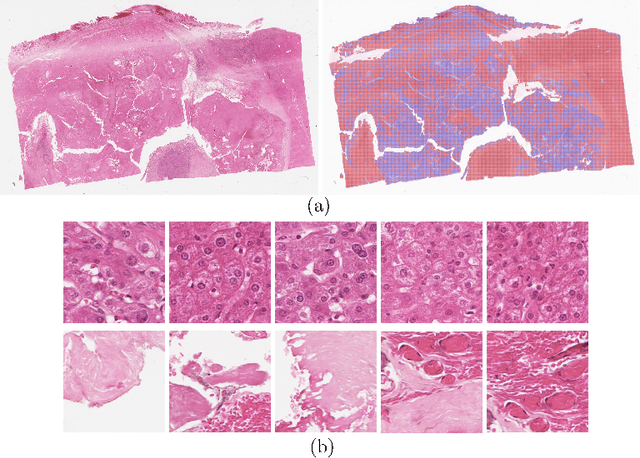

Histology images with multi-gigapixel of resolution yield rich information for cancer diagnosis and prognosis. Most of the time, only slide-level label is available because pixel-wise annotation is labour intensive task. In this paper, we propose a deep learning pipeline for classification in histology images. Using multiple instance learning, we attempt to predict the latent membrane protein 1 (LMP1) status of nasopharyngeal carcinoma (NPC) based on haematoxylin and eosin-stain (H&E) histology images. We utilised attention mechanism with residual connection for our aggregation layers. In our 3-fold cross-validation experiment, we achieved average accuracy, AUC and F1-score 0.936, 0.995 and 0.862, respectively. This method also allows us to examine the model interpretability by visualising attention scores. To the best of our knowledge, this is the first attempt to predict LMP1 status on NPC using deep learning.
Dynamic MDETR: A Dynamic Multimodal Transformer Decoder for Visual Grounding
Sep 28, 2022

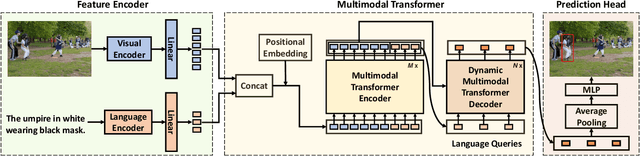
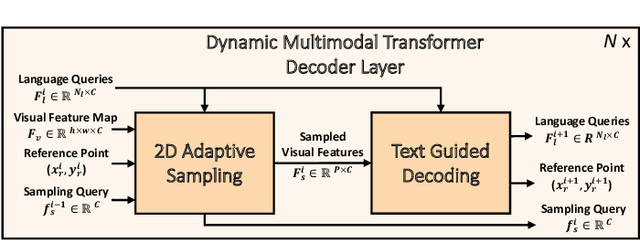
Multimodal transformer exhibits high capacity and flexibility to align image and text for visual grounding. However, the encoder-only grounding framework (e.g., TransVG) suffers from heavy computation due to the self-attention operation with quadratic time complexity. To address this issue, we present a new multimodal transformer architecture, coined as Dynamic MDETR, by decoupling the whole grounding process into encoding and decoding phases. The key observation is that there exists high spatial redundancy in images. Thus, we devise a new dynamic multimodal transformer decoder by exploiting this sparsity prior to speed up the visual grounding process. Specifically, our dynamic decoder is composed of a 2D adaptive sampling module and a text-guided decoding module. The sampling module aims to select these informative patches by predicting the offsets with respect to a reference point, while the decoding module works for extracting the grounded object information by performing cross attention between image features and text features. These two modules are stacked alternatively to gradually bridge the modality gap and iteratively refine the reference point of grounded object, eventually realizing the objective of visual grounding. Extensive experiments on five benchmarks demonstrate that our proposed Dynamic MDETR achieves competitive trade-offs between computation and accuracy. Notably, using only 9% feature points in the decoder, we can reduce ~44% GLOPs of the multimodal transformer, but still get higher accuracy than the encoder-only counterpart. In addition, to verify its generalization ability and scale up our Dynamic MDETR, we build the first one-stage CLIP empowered visual grounding framework, and achieve the state-of-the-art performance on these benchmarks.
Uncertainty Quantification of Collaborative Detection for Self-Driving
Sep 16, 2022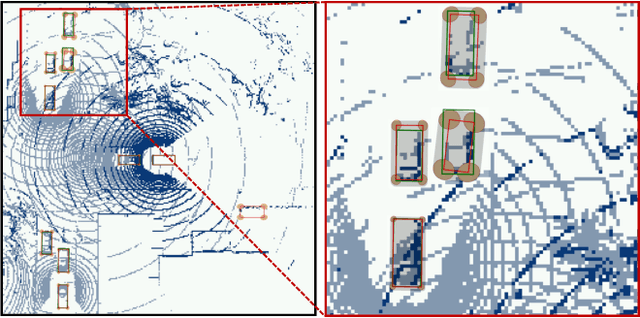
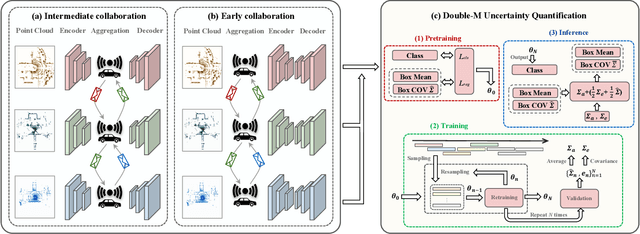
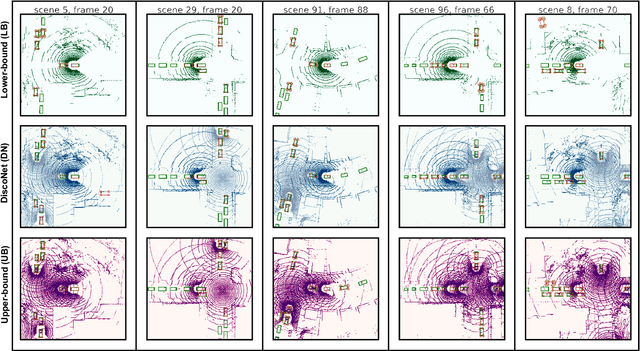
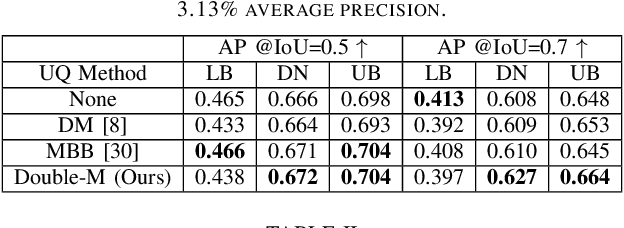
Sharing information between connected and autonomous vehicles (CAVs) fundamentally improves the performance of collaborative object detection for self-driving. However, CAVs still have uncertainties on object detection due to practical challenges, which will affect the later modules in self-driving such as planning and control. Hence, uncertainty quantification is crucial for safety-critical systems such as CAVs. Our work is the first to estimate the uncertainty of collaborative object detection. We propose a novel uncertainty quantification method, called Double-M Quantification, which tailors a moving block bootstrap (MBB) algorithm with direct modeling of the multivariant Gaussian distribution of each corner of the bounding box. Our method captures both the epistemic uncertainty and aleatoric uncertainty with one inference pass based on the offline Double-M training process. And it can be used with different collaborative object detectors. Through experiments on the comprehensive collaborative perception dataset, we show that our Double-M method achieves more than 4X improvement on uncertainty score and more than 3% accuracy improvement, compared with the state-of-the-art uncertainty quantification methods. Our code is public on https://coperception.github.io/double-m-quantification.
Age of Semantics in Cooperative Communications: To Expedite Simulation Towards Real via Offline Reinforcement Learning
Sep 19, 2022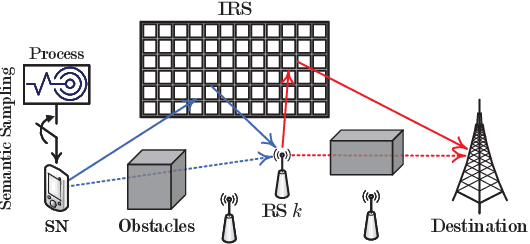
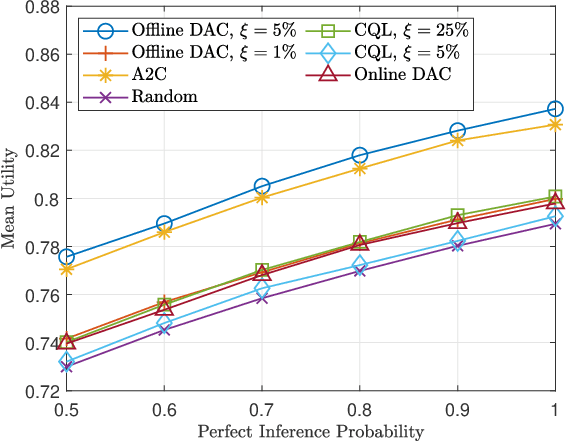
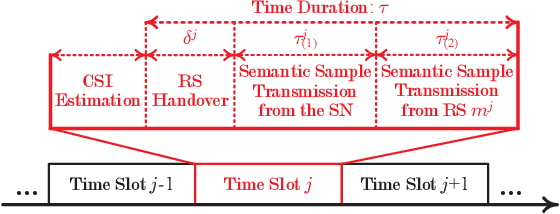
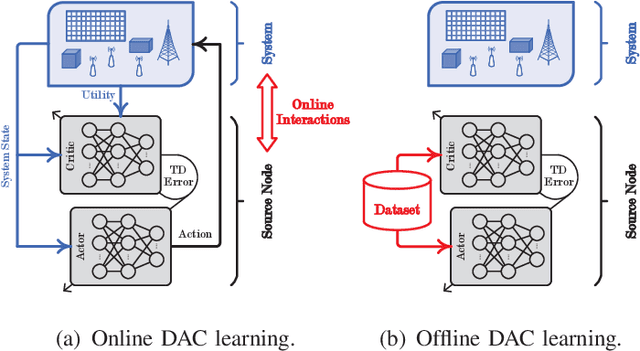
The age of information metric fails to correctly describe the intrinsic semantics of a status update. In an intelligent reflecting surface-aided cooperative relay communication system, we propose the age of semantics (AoS) for measuring semantics freshness of the status updates. Specifically, we focus on the status updating from a source node (SN) to the destination, which is formulated as a Markov decision process (MDP). The objective of the SN is to maximize the expected satisfaction of AoS and energy consumption under the maximum transmit power constraint. To seek the optimal control policy, we first derive an online deep actor-critic (DAC) learning scheme under the on-policy temporal difference learning framework. However, implementing the online DAC in practice poses the key challenge in infinitely repeated interactions between the SN and the system, which can be dangerous particularly during the exploration. We then put forward a novel offline DAC scheme, which estimates the optimal control policy from a previously collected dataset without any further interactions with the system. Numerical experiments verify the theoretical results and show that our offline DAC scheme significantly outperforms the online DAC scheme and the most representative baselines in terms of mean utility, demonstrating strong robustness to dataset quality.
Weakly Supervised Video Salient Object Detection via Point Supervision
Jul 15, 2022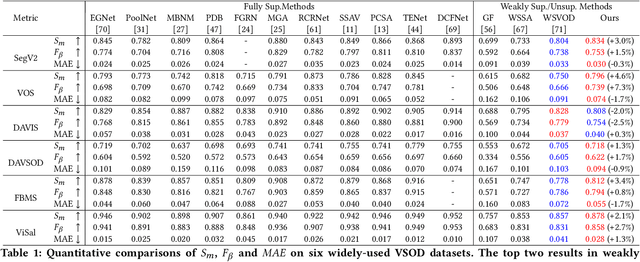
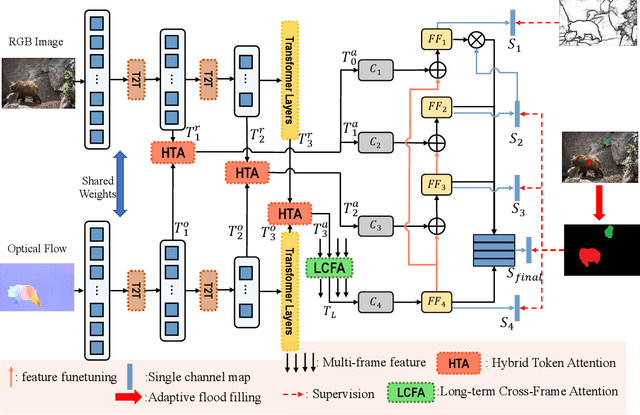
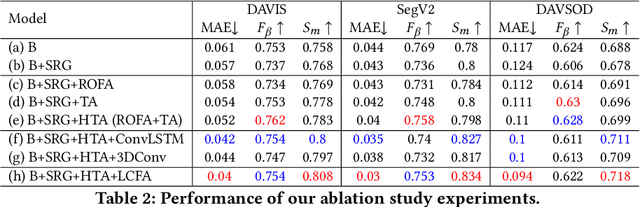
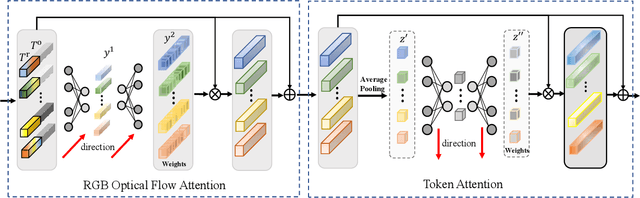
Video salient object detection models trained on pixel-wise dense annotation have achieved excellent performance, yet obtaining pixel-by-pixel annotated datasets is laborious. Several works attempt to use scribble annotations to mitigate this problem, but point supervision as a more labor-saving annotation method (even the most labor-saving method among manual annotation methods for dense prediction), has not been explored. In this paper, we propose a strong baseline model based on point supervision. To infer saliency maps with temporal information, we mine inter-frame complementary information from short-term and long-term perspectives, respectively. Specifically, we propose a hybrid token attention module, which mixes optical flow and image information from orthogonal directions, adaptively highlighting critical optical flow information (channel dimension) and critical token information (spatial dimension). To exploit long-term cues, we develop the Long-term Cross-Frame Attention module (LCFA), which assists the current frame in inferring salient objects based on multi-frame tokens. Furthermore, we label two point-supervised datasets, P-DAVIS and P-DAVSOD, by relabeling the DAVIS and the DAVSOD dataset. Experiments on the six benchmark datasets illustrate our method outperforms the previous state-of-the-art weakly supervised methods and even is comparable with some fully supervised approaches. Source code and datasets are available.
State Definition for Conflict Analysis with Four-valued Logic
Jul 24, 2022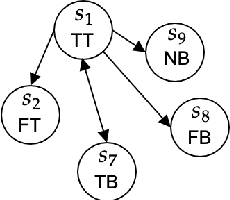
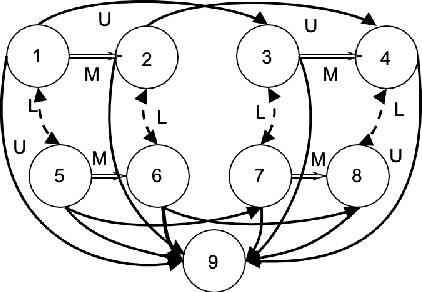
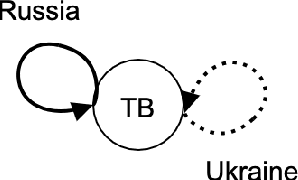
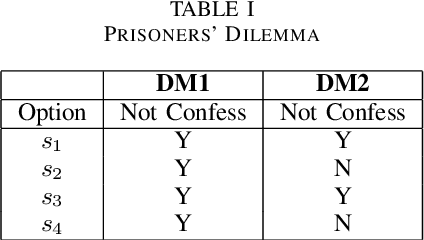
We examined a four-valued logic method for state settings in conflict resolution models. Decision-making models of conflict resolution, such as game theory and graph model for conflict resolution (GMCR), assume the description of a state to be the outcome of a combination of strategies or the consequence of option selection by the decision-makers. However, for a framework to function as a decision-making system, unless a clear definition of the task of placing information out of an infinite world exists, logical consistency cannot be ensured, and thus, the function may be incomputable. The introduction of paraconsistent four-valued logic can prevent incorrect state setting and analysis with insufficient information and provide logical validity to analytical methods that vary the analysis resolution depending on the degree of coarseness of the available information. This study proposes a GMCR stability analysis with state configuration based on Belnap's four-valued logic.
Finding neural signatures for obesity using source-localized EEG features
Aug 30, 2022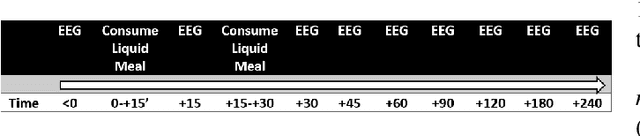
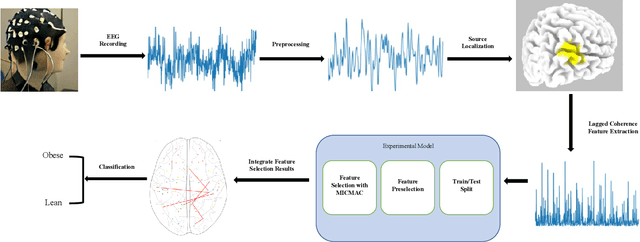
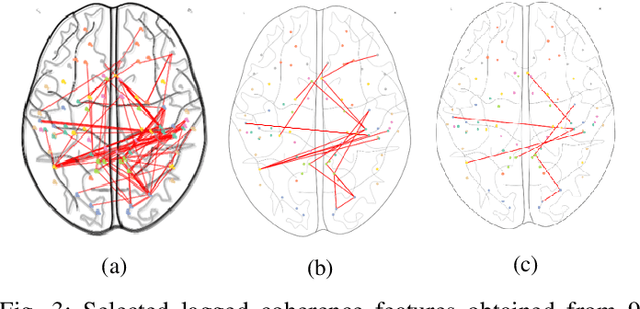
Obesity is a serious issue in the modern society since it associates to a significantly reduced quality of life. Current research conducted to explore the obesity-related neurological evidences using electroencephalography (EEG) data are limited to traditional approaches. In this study, we developed a novel machine learning model to identify brain networks of obese females using alpha band functional connectivity features derived from EEG data. An overall classification accuracy of 90% is achieved. Our finding suggests that the obese brain is characterized by a dysfunctional network in which the areas that are responsible for processing self-referential information such as energy requirement are impaired.
Multi-Modal Mutual Information Maximization: A Novel Approach for Unsupervised Deep Cross-Modal Hashing
Dec 13, 2021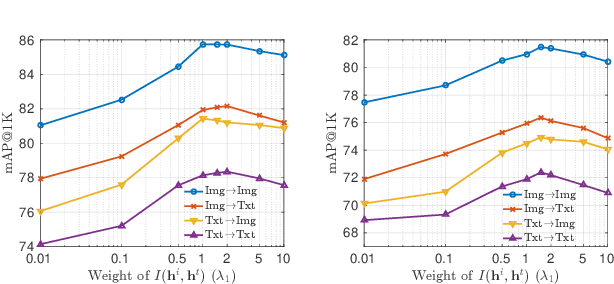
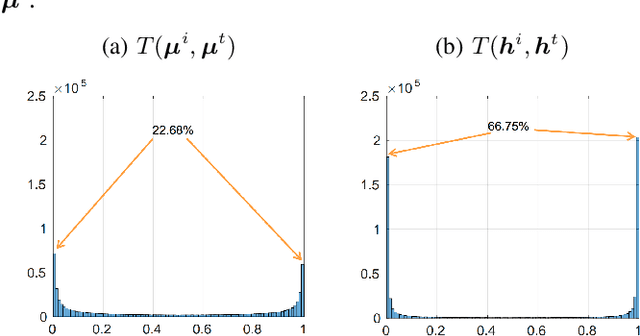
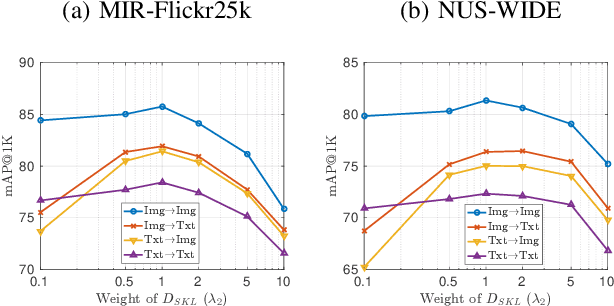
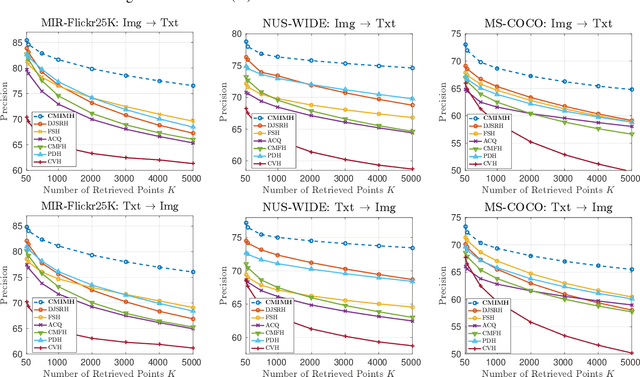
In this paper, we adopt the maximizing mutual information (MI) approach to tackle the problem of unsupervised learning of binary hash codes for efficient cross-modal retrieval. We proposed a novel method, dubbed Cross-Modal Info-Max Hashing (CMIMH). First, to learn informative representations that can preserve both intra- and inter-modal similarities, we leverage the recent advances in estimating variational lower-bound of MI to maximize the MI between the binary representations and input features and between binary representations of different modalities. By jointly maximizing these MIs under the assumption that the binary representations are modelled by multivariate Bernoulli distributions, we can learn binary representations, which can preserve both intra- and inter-modal similarities, effectively in a mini-batch manner with gradient descent. Furthermore, we find out that trying to minimize the modality gap by learning similar binary representations for the same instance from different modalities could result in less informative representations. Hence, balancing between reducing the modality gap and losing modality-private information is important for the cross-modal retrieval tasks. Quantitative evaluations on standard benchmark datasets demonstrate that the proposed method consistently outperforms other state-of-the-art cross-modal retrieval methods.