 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Power of Selecting Key Blocks with Local Pre-ranking for Long Document Information Retrieval
Nov 18, 2021
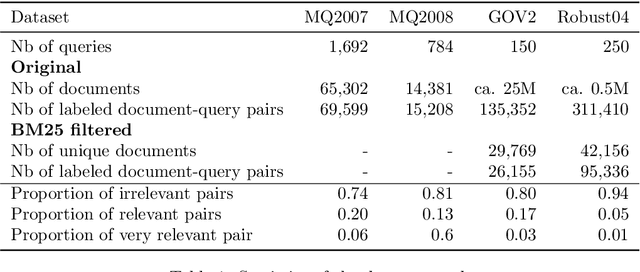
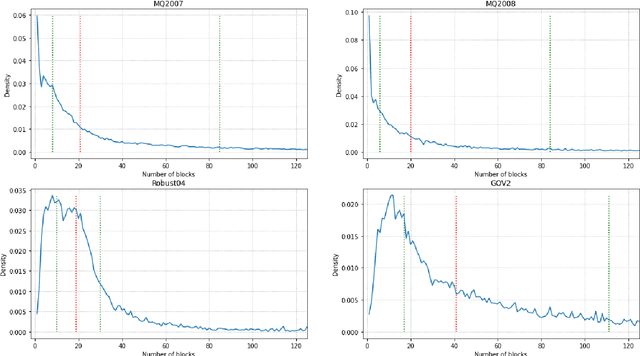
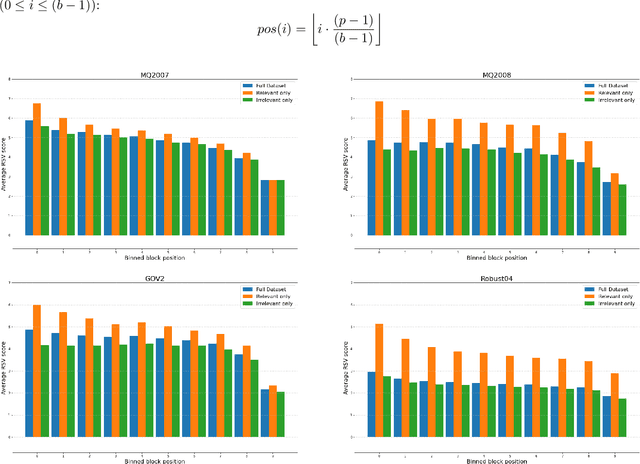
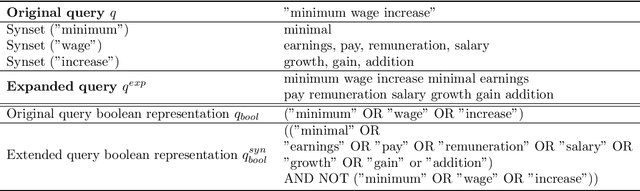
On a wide range of natural language processing and information retrieval tasks, transformer-based models, particularly pre-trained language models like BERT, have demonstrated tremendous effectiveness. Due to the quadratic complexity of the self-attention mechanism, however, such models have difficulties processing long documents. Recent works dealing with this issue include truncating long documents, segmenting them into passages that can be treated by a standard BERT model, or modifying the self-attention mechanism to make it sparser as in sparse-attention models. However, these approaches either lose information or have high computational complexity (and are both time, memory and energy consuming in this later case). We follow here a slightly different approach in which one first selects key blocks of a long document by local query-block pre-ranking, and then few blocks are aggregated to form a short document that can be processed by a model such as BERT. Experiments conducted on standard Information Retrieval datasets demonstrate the effectiveness of the proposed approach.
Boosting the Discriminant Power of Naive Bayes
Sep 20, 2022



Naive Bayes has been widely used in many applications because of its simplicity and ability in handling both numerical data and categorical data. However, lack of modeling of correlations between features limits its performance. In addition, noise and outliers in the real-world dataset also greatly degrade the classification performance. In this paper, we propose a feature augmentation method employing a stack auto-encoder to reduce the noise in the data and boost the discriminant power of naive Bayes. The proposed stack auto-encoder consists of two auto-encoders for different purposes. The first encoder shrinks the initial features to derive a compact feature representation in order to remove the noise and redundant information. The second encoder boosts the discriminant power of the features by expanding them into a higher-dimensional space so that different classes of samples could be better separated in the higher-dimensional space. By integrating the proposed feature augmentation method with the regularized naive Bayes, the discrimination power of the model is greatly enhanced. The proposed method is evaluated on a set of machine-learning benchmark datasets. The experimental results show that the proposed method significantly and consistently outperforms the state-of-the-art naive Bayes classifiers.
Multi-modal Transformer Path Prediction for Autonomous Vehicle
Aug 15, 2022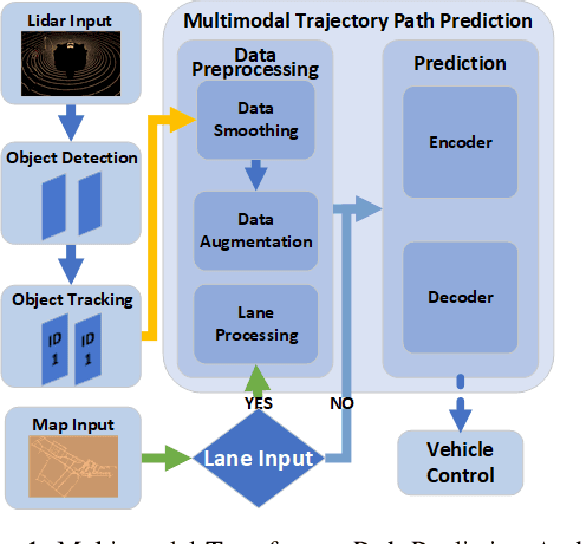
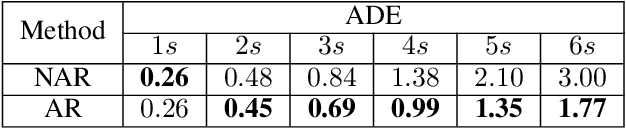
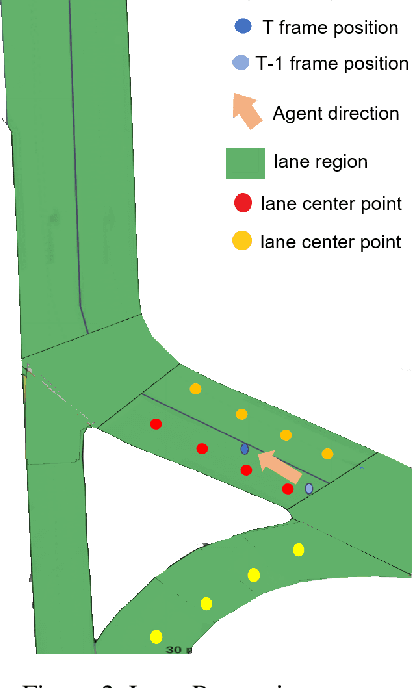
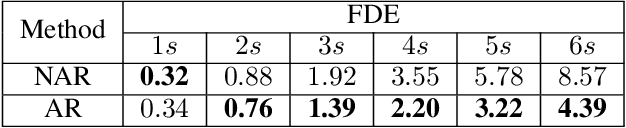
Reasoning about vehicle path prediction is an essential and challenging problem for the safe operation of autonomous driving systems. There exist many research works for path prediction. However, most of them do not use lane information and are not based on the Transformer architecture. By utilizing different types of data collected from sensors equipped on the self-driving vehicles, we propose a path prediction system named Multi-modal Transformer Path Prediction (MTPP) that aims to predict long-term future trajectory of target agents. To achieve more accurate path prediction, the Transformer architecture is adopted in our model. To better utilize the lane information, the lanes which are in opposite direction to target agent are not likely to be taken by the target agent and are consequently filtered out. In addition, consecutive lane chunks are combined to ensure the lane input to be long enough for path prediction. An extensive evaluation is conducted to show the efficacy of the proposed system using nuScene, a real-world trajectory forecasting dataset.
Human Pose Driven Object Effects Recommendation
Sep 17, 2022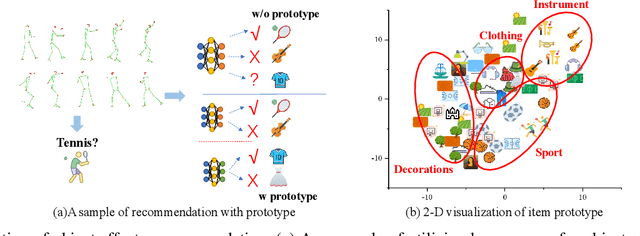
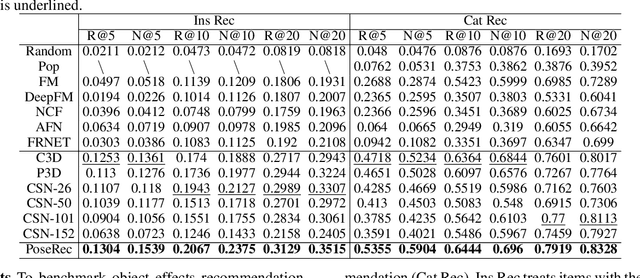
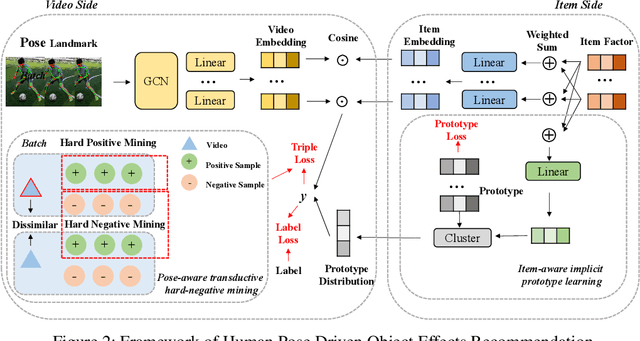
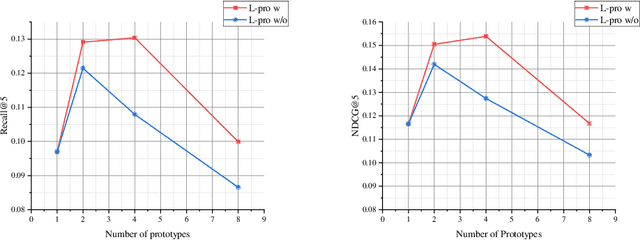
In this paper, we research the new topic of object effects recommendation in micro-video platforms, which is a challenging but important task for many practical applications such as advertisement insertion. To avoid the problem of introducing background bias caused by directly learning video content from image frames, we propose to utilize the meaningful body language hidden in 3D human pose for recommendation. To this end, in this work, a novel human pose driven object effects recommendation network termed PoseRec is introduced. PoseRec leverages the advantages of 3D human pose detection and learns information from multi-frame 3D human pose for video-item registration, resulting in high quality object effects recommendation performance. Moreover, to solve the inherent ambiguity and sparsity issues that exist in object effects recommendation, we further propose a novel item-aware implicit prototype learning module and a novel pose-aware transductive hard-negative mining module to better learn pose-item relationships. What's more, to benchmark methods for the new research topic, we build a new dataset for object effects recommendation named Pose-OBE. Extensive experiments on Pose-OBE demonstrate that our method can achieve superior performance than strong baselines.
Re-Imagen: Retrieval-Augmented Text-to-Image Generator
Oct 01, 2022

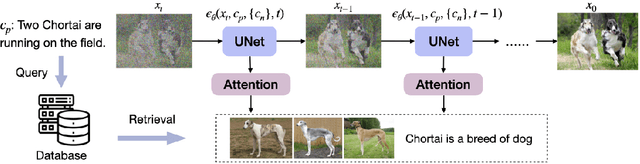
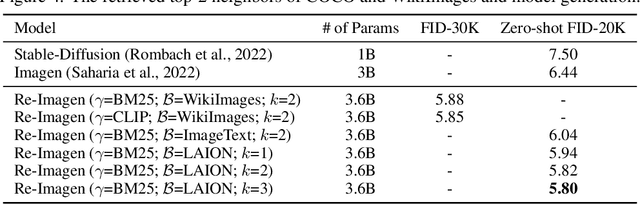
Research on text-to-image generation has witnessed significant progress in generating diverse and photo-realistic images, driven by diffusion and auto-regressive models trained on large-scale image-text data. Though state-of-the-art models can generate high-quality images of common entities, they often have difficulty generating images of uncommon entities, such as `Chortai (dog)' or `Picarones (food)'. To tackle this issue, we present the Retrieval-Augmented Text-to-Image Generator (Re-Imagen), a generative model that uses retrieved information to produce high-fidelity and faithful images, even for rare or unseen entities. Given a text prompt, Re-Imagen accesses an external multi-modal knowledge base to retrieve relevant (image, text) pairs, and uses them as references to generate the image. With this retrieval step, Re-Imagen is augmented with the knowledge of high-level semantics and low-level visual details of the mentioned entities, and thus improves its accuracy in generating the entities' visual appearances. We train Re-Imagen on a constructed dataset containing (image, text, retrieval) triples to teach the model to ground on both text prompt and retrieval. Furthermore, we develop a new sampling strategy to interleave the classifier-free guidance for text and retrieval condition to balance the text and retrieval alignment. Re-Imagen achieves new SoTA FID results on two image generation benchmarks, such as COCO (ie, FID = 5.25) and WikiImage (ie, FID = 5.82) without fine-tuning. To further evaluate the capabilities of the model, we introduce EntityDrawBench, a new benchmark that evaluates image generation for diverse entities, from frequent to rare, across multiple visual domains. Human evaluation on EntityDrawBench shows that Re-Imagen performs on par with the best prior models in photo-realism, but with significantly better faithfulness, especially on less frequent entities.
Cascaded Multi-Modal Mixing Transformers for Alzheimer's Disease Classification with Incomplete Data
Oct 01, 2022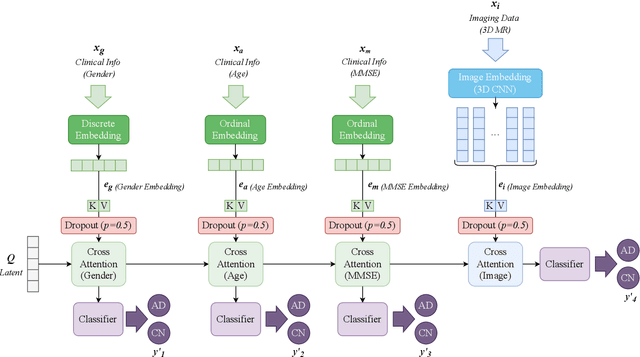
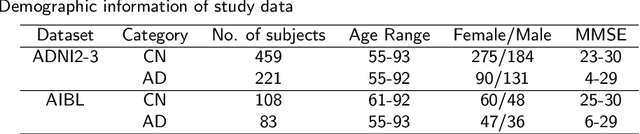
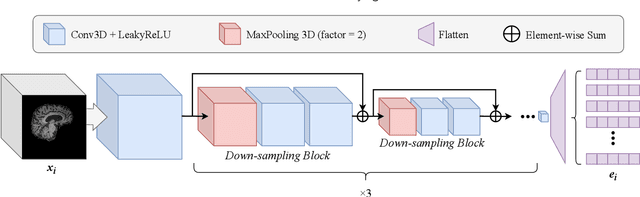
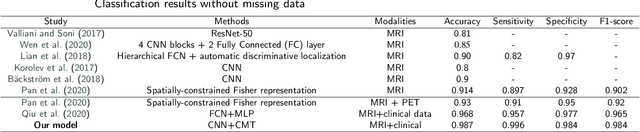
Accurate medical classification requires a large number of multi-modal data, and in many cases, in different formats. Previous studies have shown promising results when using multi-modal data, outperforming single-modality models on when classifying disease such as AD. However, those models are usually not flexible enough to handle missing modalities. Currently, the most common workaround is excluding samples with missing modalities which leads to considerable data under-utilisation. Adding to the fact that labelled medical images are already scarce, the performance of data-driven methods like deep learning is severely hampered. Therefore, a multi-modal method that can gracefully handle missing data in various clinical settings is highly desirable. In this paper, we present the Multi-Modal Mixing Transformer (3MT), a novel Transformer for disease classification based on multi-modal data. In this work, we test it for \ac{AD} or \ac{CN} classification using neuroimaging data, gender, age and MMSE scores. The model uses a novel Cascaded Modality Transformers architecture with cross-attention to incorporate multi-modal information for more informed predictions. Auxiliary outputs and a novel modality dropout mechanism were incorporated to ensure an unprecedented level of modality independence and robustness. The result is a versatile network that enables the mixing of an unlimited number of modalities with different formats and full data utilization. 3MT was first tested on the ADNI dataset and achieved state-of-the-art test accuracy of $0.987\pm0.0006$. To test its generalisability, 3MT was directly applied to the AIBL after training on the ADNI dataset, and achieved a test accuracy of $0.925\pm0.0004$ without fine-tuning. Finally, we show that Grad-CAM visualizations are also possible with our model for explainable results.
(Non)-Coherent MU-MIMO Block Fading Channels with Finite Blocklength and Linear Processing
Oct 01, 2022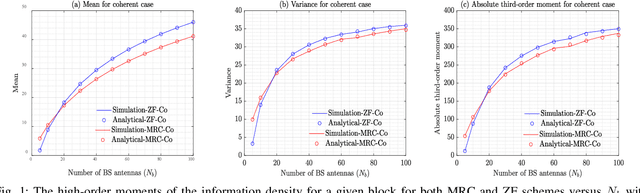
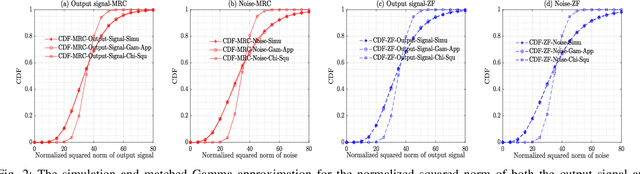
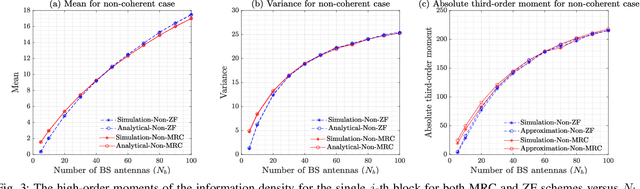
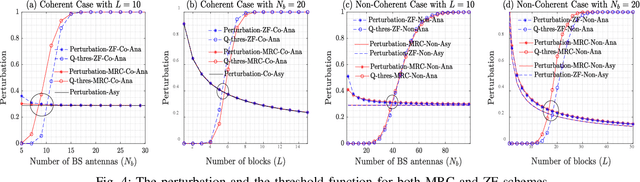
This paper studies the coherent and non-coherent multiuser multiple-input multiple-output (MU-MIMO) uplink system in the finite blocklength regime. The i.i.d. Gaussian codebook is assumed for each user. To be more specific, the BS first uses two popular linear processing schemes to combine the signals transmitted from all users, namely, MRC and ZF. Following it, the matched maximum-likelihood (ML) and mismatched nearest-neighbour (NN) decoding metric for the coherent and non-coherent cases are respectively employed at the BS. Under these conditions, the refined third-order achievable coding rate, expressed as a function of the blocklength, average error probability, and the third-order term of the information density (called as the channel perturbation), is derived. With this result in hand, a detailed performance analysis is then pursued, through which, we derive the asymptotic results of the channel perturbation, achievable coding rate, channel capacity, and the channel dispersion. These theoretical results enable us to obtain a number of interesting insights related to the impact of the finite blocklength: i) in our system setting, massive MIMO helps to reduce the channel perturbation of the achievable coding rate, which can even be discarded without affecting the performance with just a small-to-moderate number of BS antennas and number of blocks; ii) under the non-coherent case, even with massive MIMO, the channel estimation errors cannot be eliminated unless the transmit powers in both the channel estimation and data transmission phases for each user are made inversely proportional to the square root of the number of BS antennas; iii) in the non-coherent case and for fixed total blocklength, the scenarios with longer coherence intervals and smaller number of blocks offer higher achievable coding rate.
Motion and Appearance Adaptation for Cross-Domain Motion Transfer
Sep 29, 2022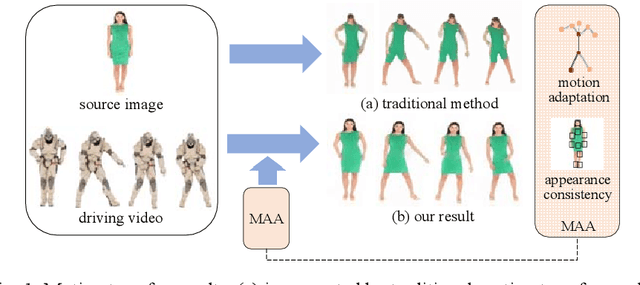
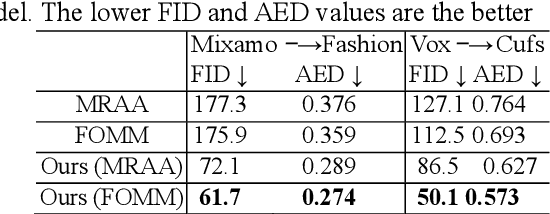
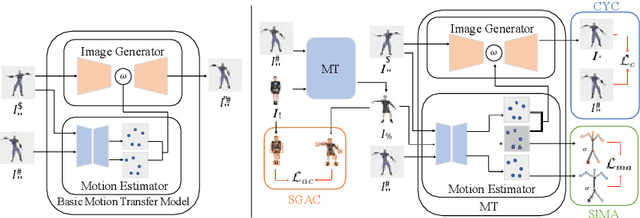
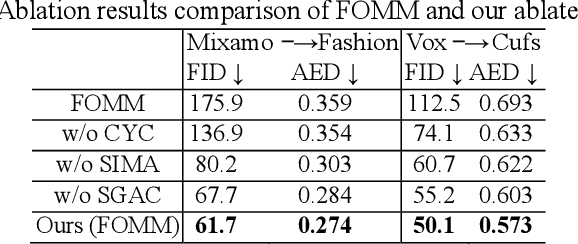
Motion transfer aims to transfer the motion of a driving video to a source image. When there are considerable differences between object in the driving video and that in the source image, traditional single domain motion transfer approaches often produce notable artifacts; for example, the synthesized image may fail to preserve the human shape of the source image (cf . Fig. 1 (a)). To address this issue, in this work, we propose a Motion and Appearance Adaptation (MAA) approach for cross-domain motion transfer, in which we regularize the object in the synthesized image to capture the motion of the object in the driving frame, while still preserving the shape and appearance of the object in the source image. On one hand, considering the object shapes of the synthesized image and the driving frame might be different, we design a shape-invariant motion adaptation module that enforces the consistency of the angles of object parts in two images to capture the motion information. On the other hand, we introduce a structure-guided appearance consistency module designed to regularize the similarity between the corresponding patches of the synthesized image and the source image without affecting the learned motion in the synthesized image. Our proposed MAA model can be trained in an end-to-end manner with a cyclic reconstruction loss, and ultimately produces a satisfactory motion transfer result (cf . Fig. 1 (b)). We conduct extensive experiments on human dancing dataset Mixamo-Video to Fashion-Video and human face dataset Vox-Celeb to Cufs; on both of these, our MAA model outperforms existing methods both quantitatively and qualitatively.
I Know What You Do Not Know: Knowledge Graph Embedding via Co-distillation Learning
Aug 21, 2022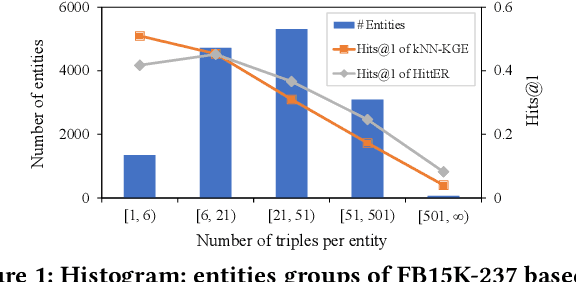

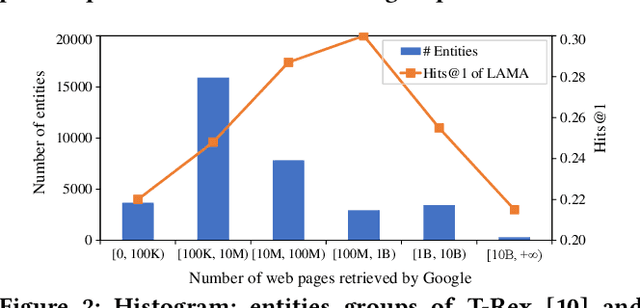

Knowledge graph (KG) embedding seeks to learn vector representations for entities and relations. Conventional models reason over graph structures, but they suffer from the issues of graph incompleteness and long-tail entities. Recent studies have used pre-trained language models to learn embeddings based on the textual information of entities and relations, but they cannot take advantage of graph structures. In the paper, we show empirically that these two kinds of features are complementary for KG embedding. To this end, we propose CoLE, a Co-distillation Learning method for KG Embedding that exploits the complementarity of graph structures and text information. Its graph embedding model employs Transformer to reconstruct the representation of an entity from its neighborhood subgraph. Its text embedding model uses a pre-trained language model to generate entity representations from the soft prompts of their names, descriptions, and relational neighbors. To let the two model promote each other, we propose co-distillation learning that allows them to distill selective knowledge from each other's prediction logits. In our co-distillation learning, each model serves as both a teacher and a student. Experiments on benchmark datasets demonstrate that the two models outperform their related baselines, and the ensemble method CoLE with co-distillation learning advances the state-of-the-art of KG embedding.
Recurrent networks, hidden states and beliefs in partially observable environments
Aug 06, 2022

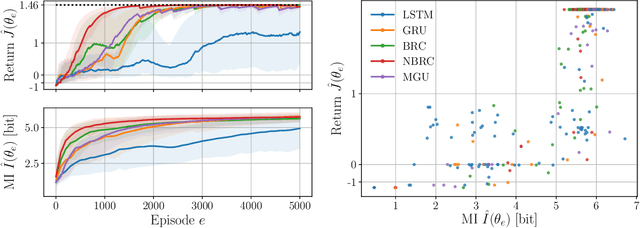

Reinforcement learning aims to learn optimal policies from interaction with environments whose dynamics are unknown. Many methods rely on the approximation of a value function to derive near-optimal policies. In partially observable environments, these functions depend on the complete sequence of observations and past actions, called the history. In this work, we show empirically that recurrent neural networks trained to approximate such value functions internally filter the posterior probability distribution of the current state given the history, called the belief. More precisely, we show that, as a recurrent neural network learns the Q-function, its hidden states become more and more correlated with the beliefs of state variables that are relevant to optimal control. This correlation is measured through their mutual information. In addition, we show that the expected return of an agent increases with the ability of its recurrent architecture to reach a high mutual information between its hidden states and the beliefs. Finally, we show that the mutual information between the hidden states and the beliefs of variables that are irrelevant for optimal control decreases through the learning process. In summary, this work shows that in its hidden states, a recurrent neural network approximating the Q-function of a partially observable environment reproduces a sufficient statistic from the history that is correlated to the relevant part of the belief for taking optimal actions.