 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reconstruction-guided attention improves the robustness and shape processing of neural networks
Sep 27, 2022
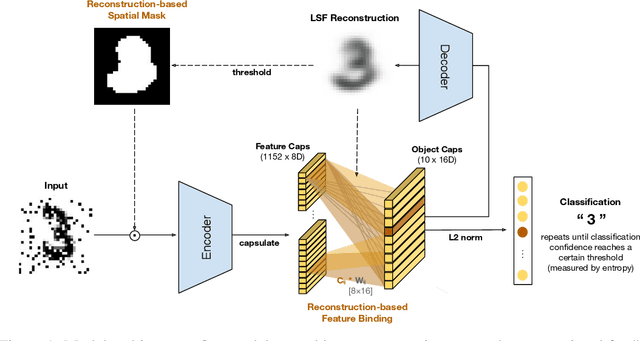
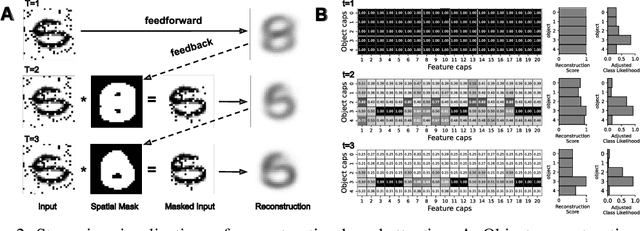
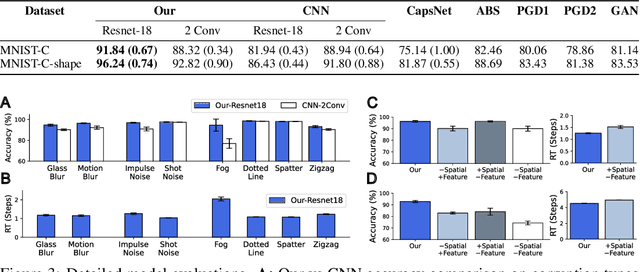
Many visual phenomena suggest that humans use top-down generative or reconstructive processes to create visual percepts (e.g., imagery, object completion, pareidolia), but little is known about the role reconstruction plays in robust object recognition. We built an iterative encoder-decoder network that generates an object reconstruction and used it as top-down attentional feedback to route the most relevant spatial and feature information to feed-forward object recognition processes. We tested this model using the challenging out-of-distribution digit recognition dataset, MNIST-C, where 15 different types of transformation and corruption are applied to handwritten digit images. Our model showed strong generalization performance against various image perturbations, on average outperforming all other models including feedforward CNNs and adversarially trained networks. Our model is particularly robust to blur, noise, and occlusion corruptions, where shape perception plays an important role. Ablation studies further reveal two complementary roles of spatial and feature-based attention in robust object recognition, with the former largely consistent with spatial masking benefits in the attention literature (the reconstruction serves as a mask) and the latter mainly contributing to the model's inference speed (i.e., number of time steps to reach a certain confidence threshold) by reducing the space of possible object hypotheses. We also observed that the model sometimes hallucinates a non-existing pattern out of noise, leading to highly interpretable human-like errors. Our study shows that modeling reconstruction-based feedback endows AI systems with a powerful attention mechanism, which can help us understand the role of generating perception in human visual processing.
Adding Context to Source Code Representations for Deep Learning
Jul 30, 2022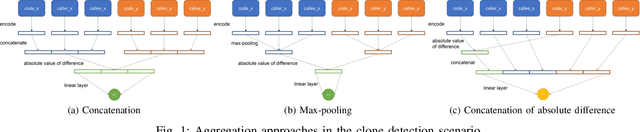
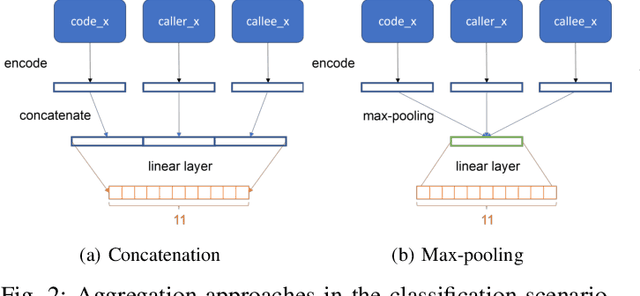
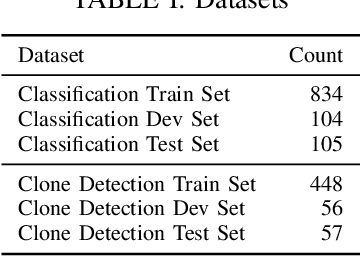
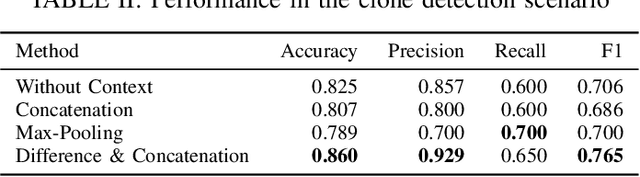
Deep learning models have been successfully applied to a variety of software engineering tasks, such as code classification, summarisation, and bug and vulnerability detection. In order to apply deep learning to these tasks, source code needs to be represented in a format that is suitable for input into the deep learning model. Most approaches to representing source code, such as tokens, abstract syntax trees (ASTs), data flow graphs (DFGs), and control flow graphs (CFGs) only focus on the code itself and do not take into account additional context that could be useful for deep learning models. In this paper, we argue that it is beneficial for deep learning models to have access to additional contextual information about the code being analysed. We present preliminary evidence that encoding context from the call hierarchy along with information from the code itself can improve the performance of a state-of-the-art deep learning model for two software engineering tasks. We outline our research agenda for adding further contextual information to source code representations for deep learning.
Visual Object Tracking in First Person Vision
Sep 27, 2022
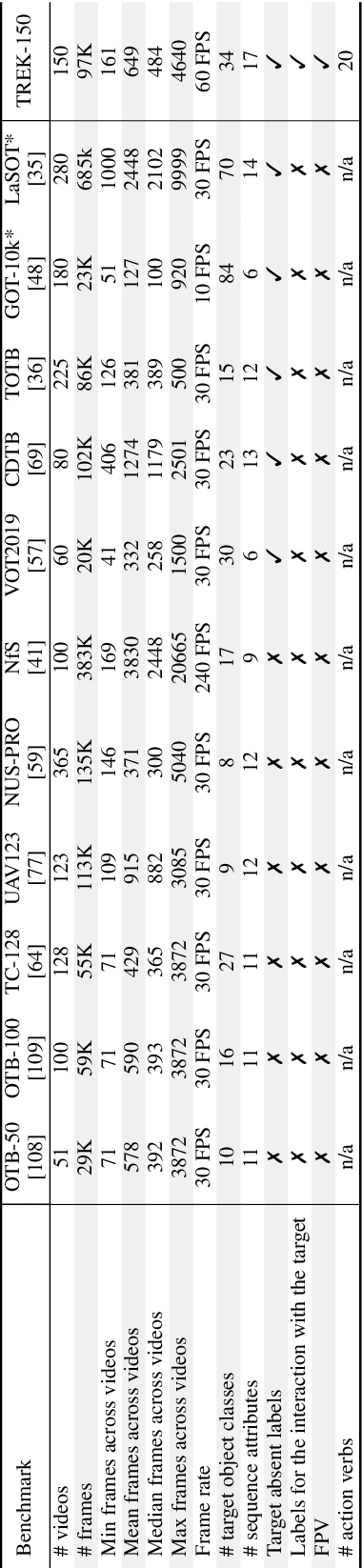
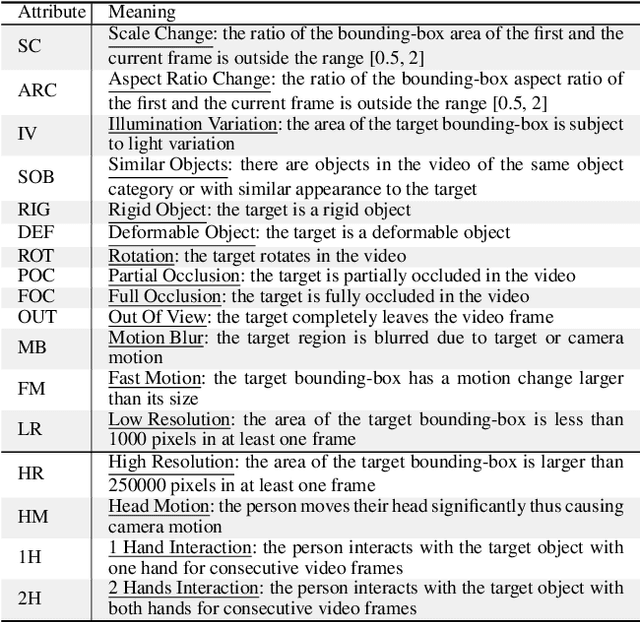
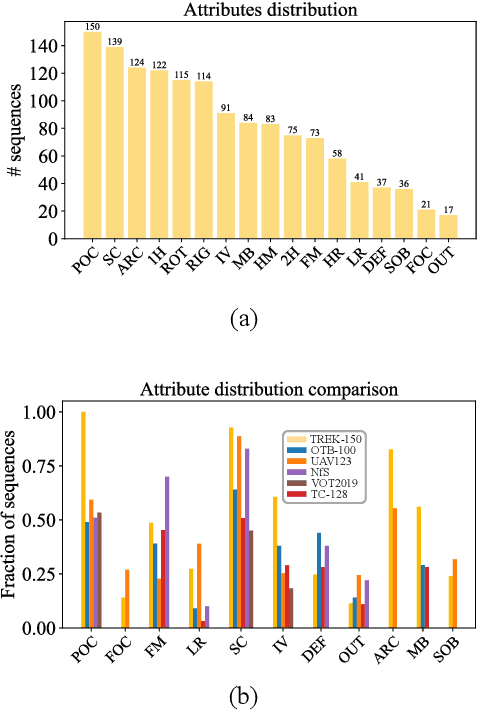
The understanding of human-object interactions is fundamental in First Person Vision (FPV). Visual tracking algorithms which follow the objects manipulated by the camera wearer can provide useful information to effectively model such interactions. In the last years, the computer vision community has significantly improved the performance of tracking algorithms for a large variety of target objects and scenarios. Despite a few previous attempts to exploit trackers in the FPV domain, a methodical analysis of the performance of state-of-the-art trackers is still missing. This research gap raises the question of whether current solutions can be used ``off-the-shelf'' or more domain-specific investigations should be carried out. This paper aims to provide answers to such questions. We present the first systematic investigation of single object tracking in FPV. Our study extensively analyses the performance of 42 algorithms including generic object trackers and baseline FPV-specific trackers. The analysis is carried out by focusing on different aspects of the FPV setting, introducing new performance measures, and in relation to FPV-specific tasks. The study is made possible through the introduction of TREK-150, a novel benchmark dataset composed of 150 densely annotated video sequences. Our results show that object tracking in FPV poses new challenges to current visual trackers. We highlight the factors causing such behavior and point out possible research directions. Despite their difficulties, we prove that trackers bring benefits to FPV downstream tasks requiring short-term object tracking. We expect that generic object tracking will gain popularity in FPV as new and FPV-specific methodologies are investigated.
Fine-grained Classification of Solder Joints with α-skew Jensen-Shannon Divergence
Sep 20, 2022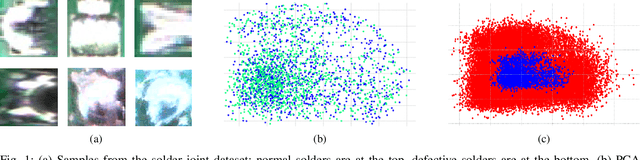
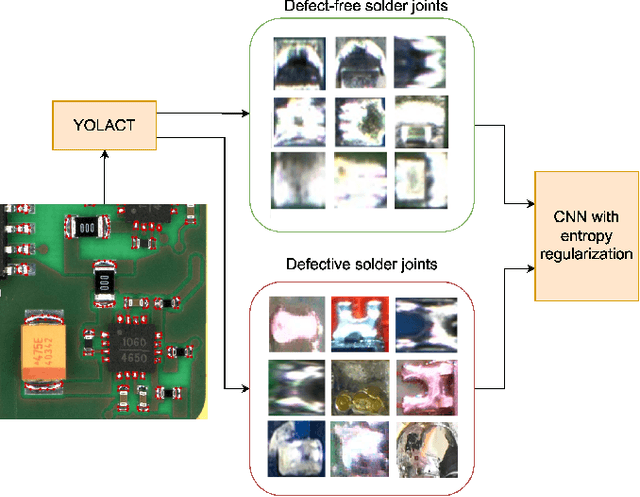
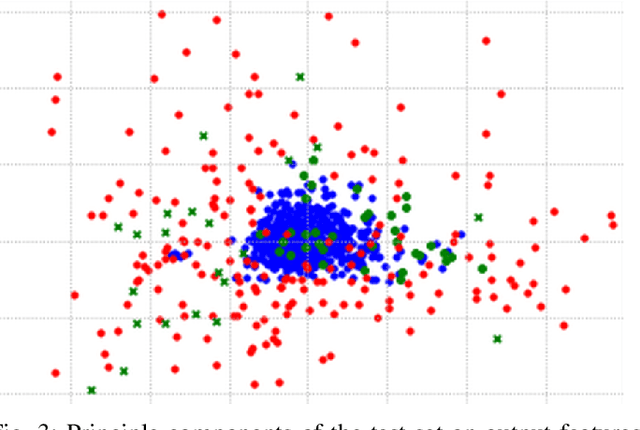
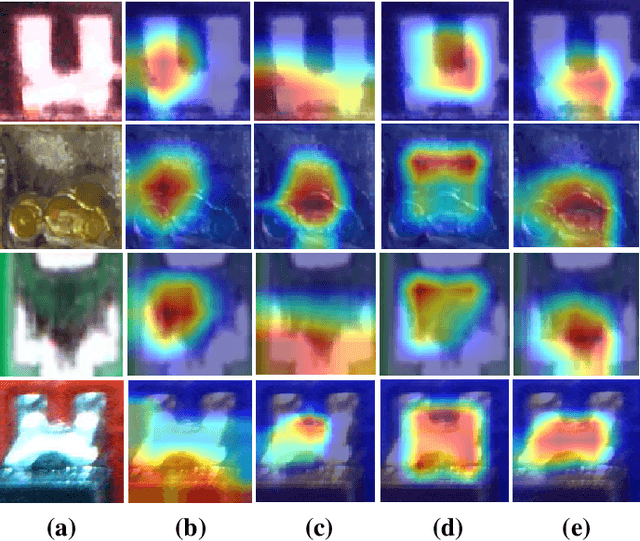
Solder joint inspection (SJI) is a critical process in the production of printed circuit boards (PCB). Detection of solder errors during SJI is quite challenging as the solder joints have very small sizes and can take various shapes. In this study, we first show that solders have low feature diversity, and that the SJI can be carried out as a fine-grained image classification task which focuses on hard-to-distinguish object classes. To improve the fine-grained classification accuracy, penalizing confident model predictions by maximizing entropy was found useful in the literature. Inline with this information, we propose using the {\alpha}-skew Jensen-Shannon divergence ({\alpha}-JS) for penalizing the confidence in model predictions. We compare the {\alpha}-JS regularization with both existing entropyregularization based methods and the methods based on attention mechanism, segmentation techniques, transformer models, and specific loss functions for fine-grained image classification tasks. We show that the proposed approach achieves the highest F1-score and competitive accuracy for different models in the finegrained solder joint classification task. Finally, we visualize the activation maps and show that with entropy-regularization, more precise class-discriminative regions are localized, which are also more resilient to noise. Code will be made available here upon acceptance.
FedToken: Tokenized Incentives for Data Contribution in Federated Learning
Sep 20, 2022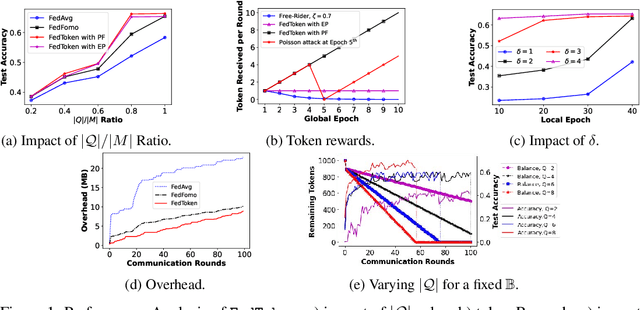
Incentives that compensate for the involved costs in the decentralized training of a Federated Learning (FL) model act as a key stimulus for clients' long-term participation. However, it is challenging to convince clients for quality participation in FL due to the absence of: (i) full information on the client's data quality and properties; (ii) the value of client's data contributions; and (iii) the trusted mechanism for monetary incentive offers. This often leads to poor efficiency in training and communication. While several works focus on strategic incentive designs and client selection to overcome this problem, there is a major knowledge gap in terms of an overall design tailored to the foreseen digital economy, including Web 3.0, while simultaneously meeting the learning objectives. To address this gap, we propose a contribution-based tokenized incentive scheme, namely \texttt{FedToken}, backed by blockchain technology that ensures fair allocation of tokens amongst the clients that corresponds to the valuation of their data during model training. Leveraging the engineered Shapley-based scheme, we first approximate the contribution of local models during model aggregation, then strategically schedule clients lowering the communication rounds for convergence and anchor ways to allocate \emph{affordable} tokens under a constrained monetary budget. Extensive simulations demonstrate the efficacy of our proposed method.
How Much Privacy Does Federated Learning with Secure Aggregation Guarantee?
Aug 03, 2022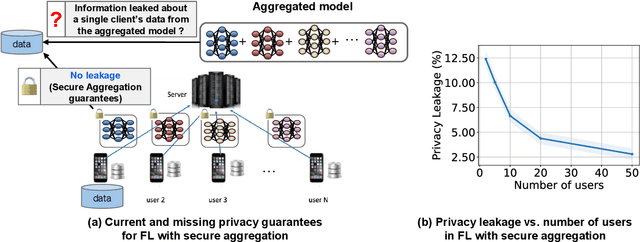
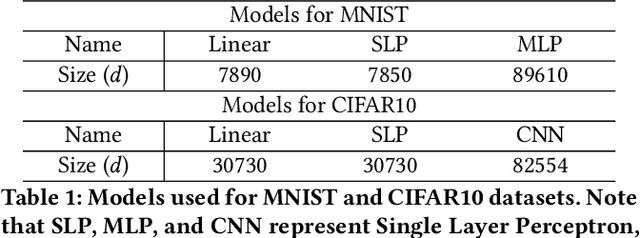
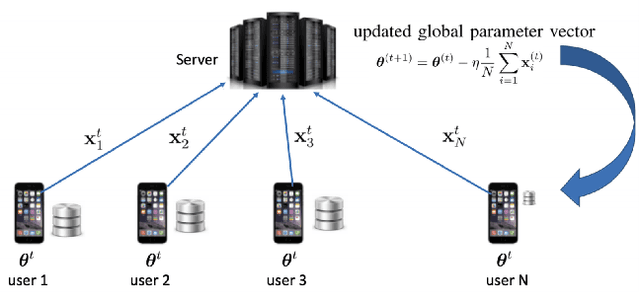
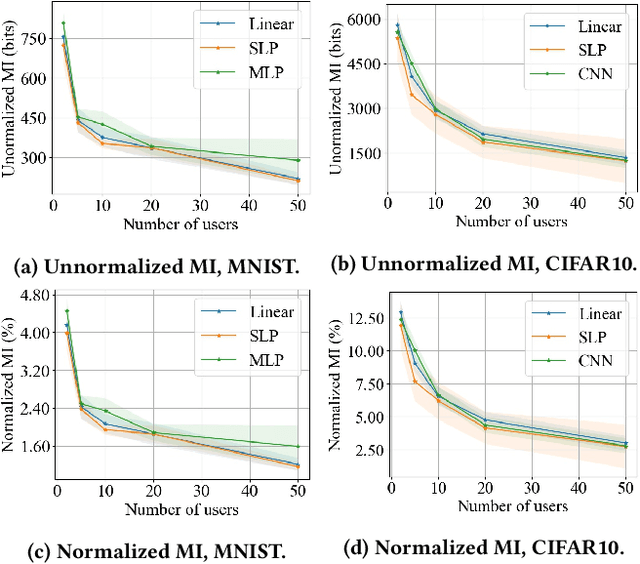
Federated learning (FL) has attracted growing interest for enabling privacy-preserving machine learning on data stored at multiple users while avoiding moving the data off-device. However, while data never leaves users' devices, privacy still cannot be guaranteed since significant computations on users' training data are shared in the form of trained local models. These local models have recently been shown to pose a substantial privacy threat through different privacy attacks such as model inversion attacks. As a remedy, Secure Aggregation (SA) has been developed as a framework to preserve privacy in FL, by guaranteeing the server can only learn the global aggregated model update but not the individual model updates. While SA ensures no additional information is leaked about the individual model update beyond the aggregated model update, there are no formal guarantees on how much privacy FL with SA can actually offer; as information about the individual dataset can still potentially leak through the aggregated model computed at the server. In this work, we perform a first analysis of the formal privacy guarantees for FL with SA. Specifically, we use Mutual Information (MI) as a quantification metric and derive upper bounds on how much information about each user's dataset can leak through the aggregated model update. When using the FedSGD aggregation algorithm, our theoretical bounds show that the amount of privacy leakage reduces linearly with the number of users participating in FL with SA. To validate our theoretical bounds, we use an MI Neural Estimator to empirically evaluate the privacy leakage under different FL setups on both the MNIST and CIFAR10 datasets. Our experiments verify our theoretical bounds for FedSGD, which show a reduction in privacy leakage as the number of users and local batch size grow, and an increase in privacy leakage with the number of training rounds.
An AFDM-Based Integrated Sensing and Communications
Aug 29, 2022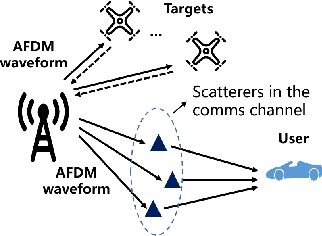
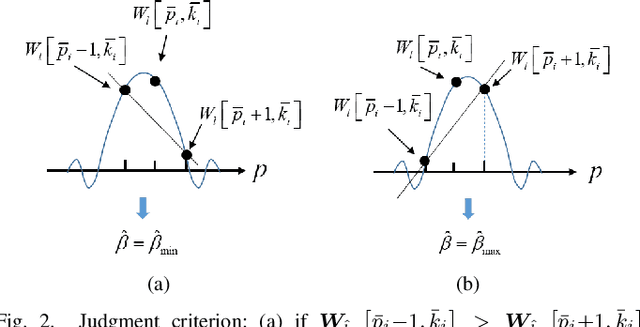
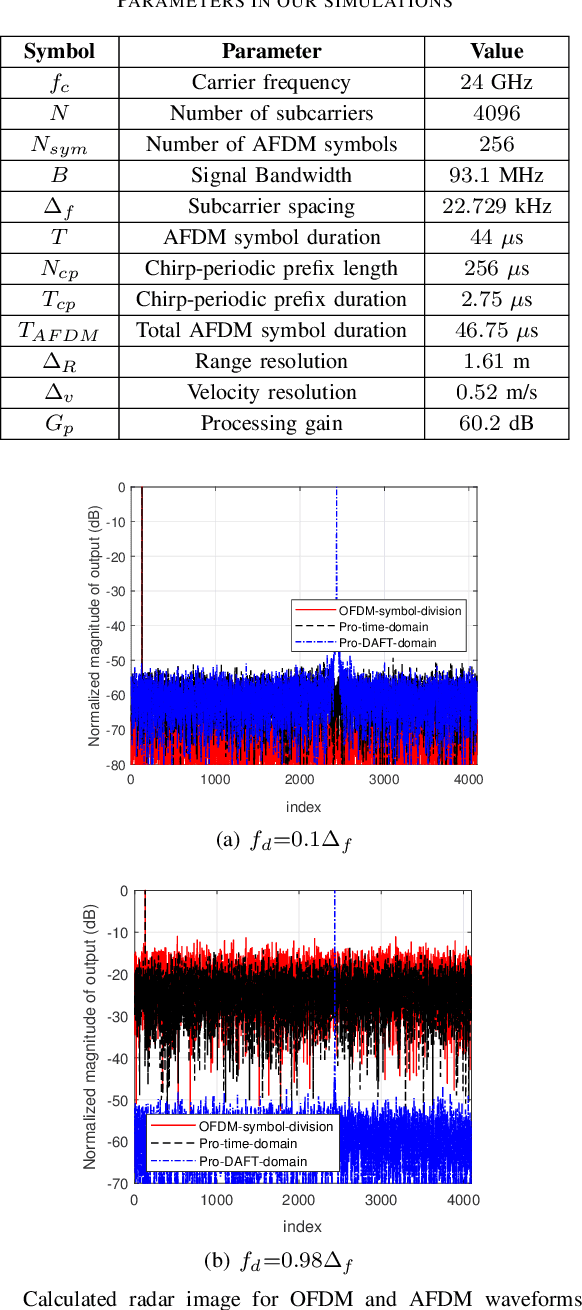
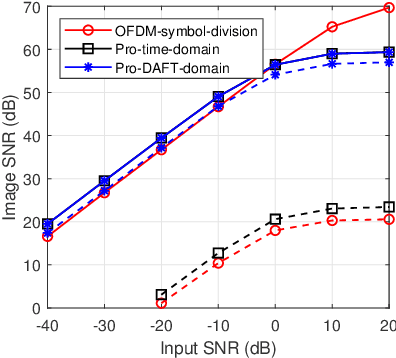
This paper considers an affine frequency division multiplexing (AFDM)-based integrated sensing and communications (ISAC) system, where the AFDM waveform is used to simultaneously carry communications information and sense targets. To realize AFDM-based sensing functionality, two parameter estimation methods are designed to process echoes in the time domain and the discrete affine Fourier transform (DAFT) domain, respectively. It allows us to decouple delay and Doppler shift in the fast time axis and can maintain good sensing performance even in large Doppler shift scenarios. Numerical results verify the effectiveness of our proposed AFDM-based system in high mobility scenarios.
The Power of Selecting Key Blocks with Local Pre-ranking for Long Document Information Retrieval
Nov 18, 2021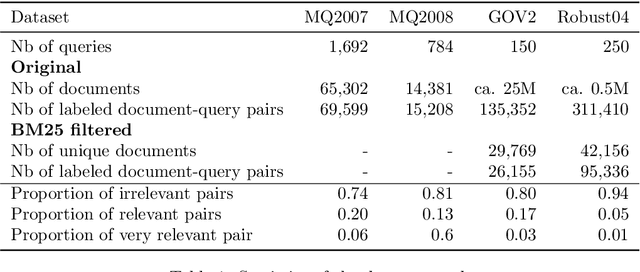
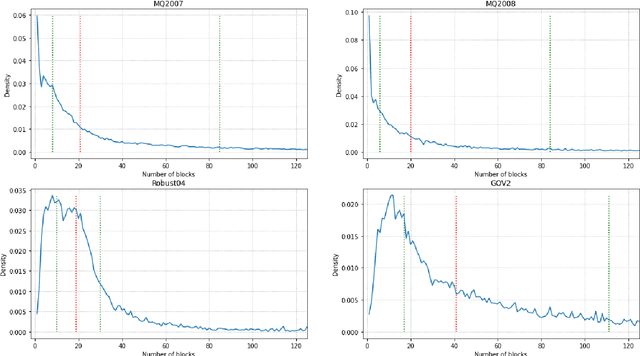
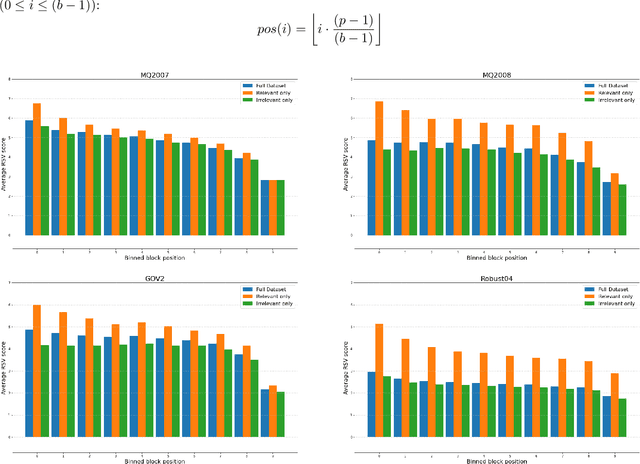
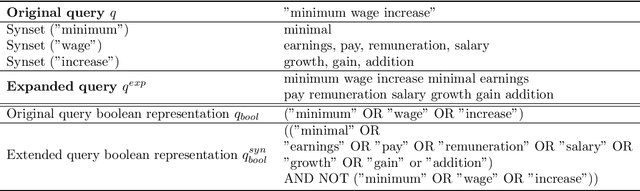
On a wide range of natural language processing and information retrieval tasks, transformer-based models, particularly pre-trained language models like BERT, have demonstrated tremendous effectiveness. Due to the quadratic complexity of the self-attention mechanism, however, such models have difficulties processing long documents. Recent works dealing with this issue include truncating long documents, segmenting them into passages that can be treated by a standard BERT model, or modifying the self-attention mechanism to make it sparser as in sparse-attention models. However, these approaches either lose information or have high computational complexity (and are both time, memory and energy consuming in this later case). We follow here a slightly different approach in which one first selects key blocks of a long document by local query-block pre-ranking, and then few blocks are aggregated to form a short document that can be processed by a model such as BERT. Experiments conducted on standard Information Retrieval datasets demonstrate the effectiveness of the proposed approach.
pFedDef: Defending Grey-Box Attacks for Personalized Federated Learning
Sep 17, 2022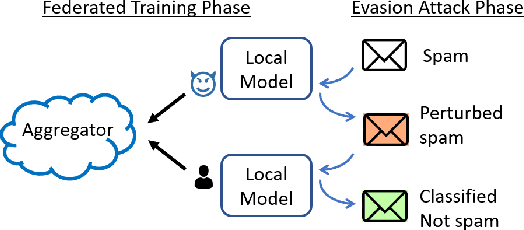
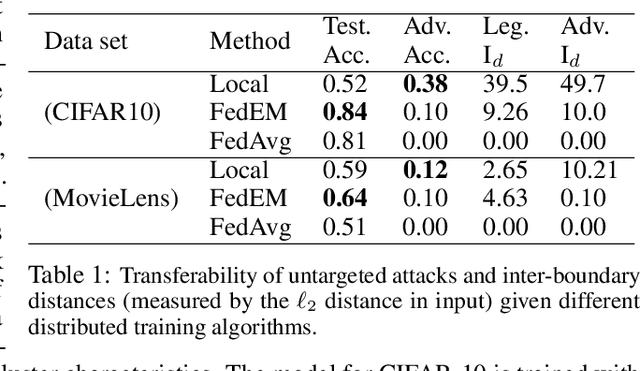
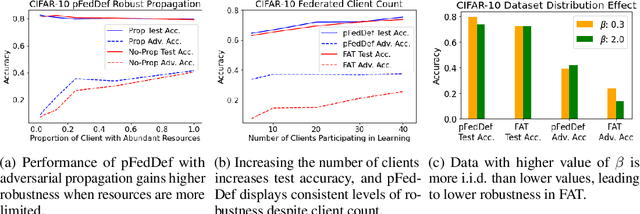

Personalized federated learning allows for clients in a distributed system to train a neural network tailored to their unique local data while leveraging information at other clients. However, clients' models are vulnerable to attacks during both the training and testing phases. In this paper we address the issue of adversarial clients crafting evasion attacks at test time to deceive other clients. For example, adversaries may aim to deceive spam filters and recommendation systems trained with personalized federated learning for monetary gain. The adversarial clients have varying degrees of personalization based on the method of distributed learning, leading to a "grey-box" situation. We are the first to characterize the transferability of such internal evasion attacks for different learning methods and analyze the trade-off between model accuracy and robustness depending on the degree of personalization and similarities in client data. We introduce a defense mechanism, pFedDef, that performs personalized federated adversarial training while respecting resource limitations at clients that inhibit adversarial training. Overall, pFedDef increases relative grey-box adversarial robustness by 62% compared to federated adversarial training and performs well even under limited system resources.
DevNet: Self-supervised Monocular Depth Learning via Density Volume Construction
Sep 20, 2022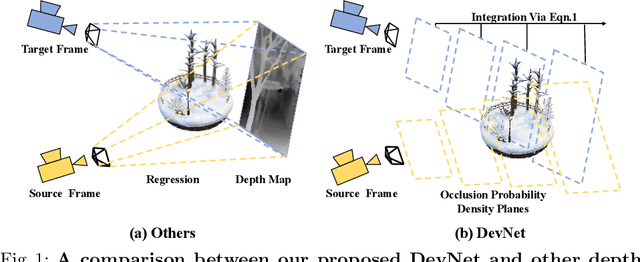
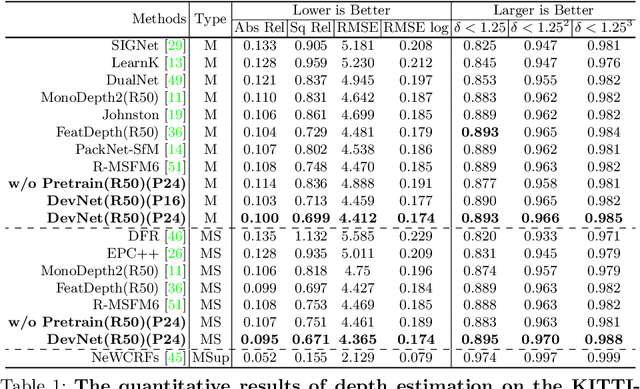
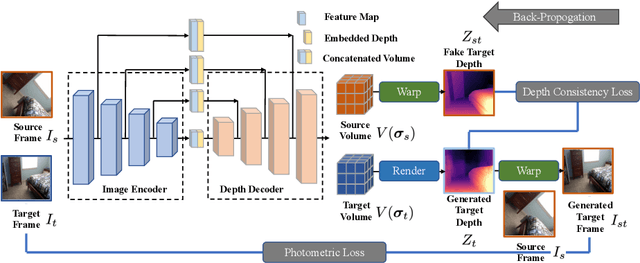

Self-supervised depth learning from monocular images normally relies on the 2D pixel-wise photometric relation between temporally adjacent image frames. However, they neither fully exploit the 3D point-wise geometric correspondences, nor effectively tackle the ambiguities in the photometric warping caused by occlusions or illumination inconsistency. To address these problems, this work proposes Density Volume Construction Network (DevNet), a novel self-supervised monocular depth learning framework, that can consider 3D spatial information, and exploit stronger geometric constraints among adjacent camera frustums. Instead of directly regressing the pixel value from a single image, our DevNet divides the camera frustum into multiple parallel planes and predicts the pointwise occlusion probability density on each plane. The final depth map is generated by integrating the density along corresponding rays. During the training process, novel regularization strategies and loss functions are introduced to mitigate photometric ambiguities and overfitting. Without obviously enlarging model parameters size or running time, DevNet outperforms several representative baselines on both the KITTI-2015 outdoor dataset and NYU-V2 indoor dataset. In particular, the root-mean-square-deviation is reduced by around 4% with DevNet on both KITTI-2015 and NYU-V2 in the task of depth estimation. Code is available at https://github.com/gitkaichenzhou/DevNet.