 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Simple and Powerful Architecture for Inductive Recommendation Using Knowledge Graph Convolutions
Sep 12, 2022
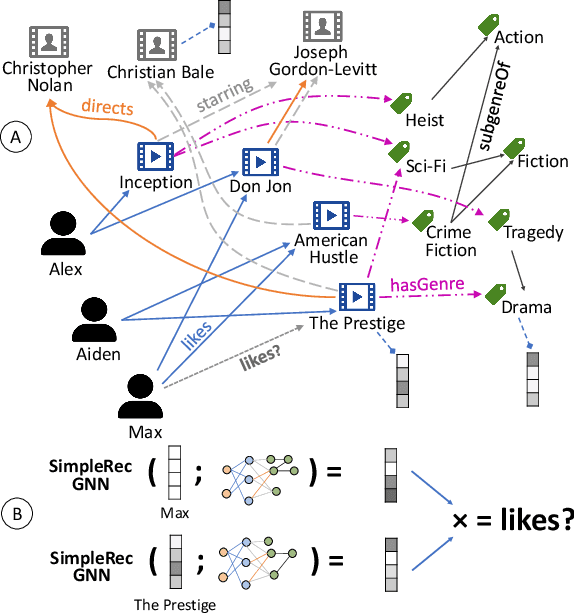
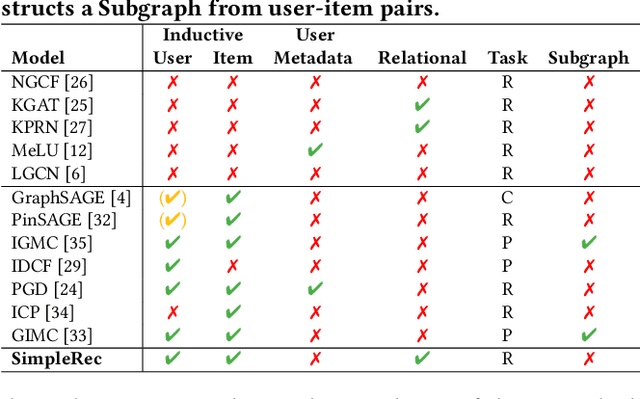
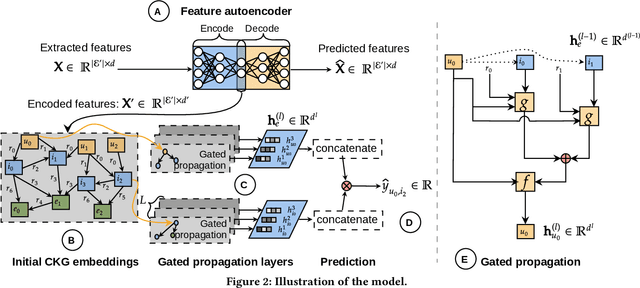
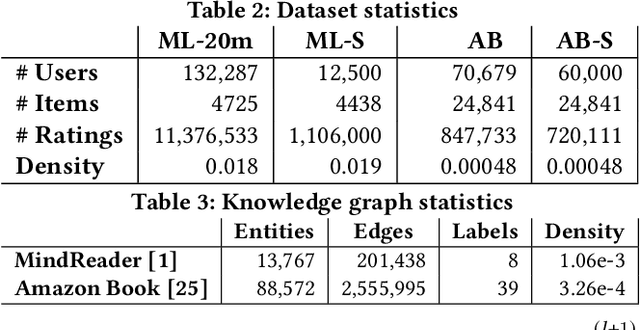
Using graph models with relational information in recommender systems has shown promising results. Yet, most methods are transductive, i.e., they are based on dimensionality reduction architectures. Hence, they require heavy retraining every time new items or users are added. Conversely, inductive methods promise to solve these issues. Nonetheless, all inductive methods rely only on interactions, making recommendations for users with few interactions sub-optimal and even impossible for new items. Therefore, we focus on inductive methods able to also exploit knowledge graphs (KGs). In this work, we propose SimpleRec, a strong baseline that uses a graph neural network and a KG to provide better recommendations than related inductive methods for new users and items. We show that it is unnecessary to create complex model architectures for user representations, but it is enough to allow users to be represented by the few ratings they provide and the indirect connections among them without any user metadata. As a result, we re-evaluate state-of-the-art methods, identify better evaluation protocols, highlight unwarranted conclusions from previous proposals, and showcase a novel, stronger baseline for this task.
TMSS: An End-to-End Transformer-based Multimodal Network for Segmentation and Survival Prediction
Sep 12, 2022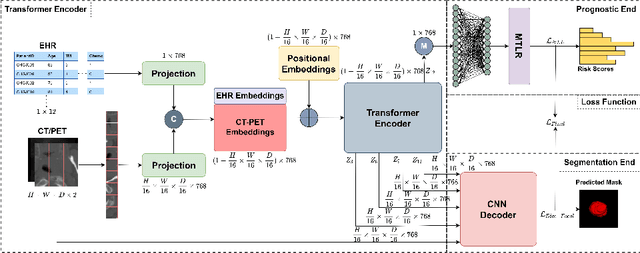

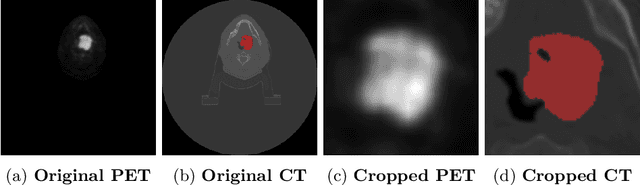
When oncologists estimate cancer patient survival, they rely on multimodal data. Even though some multimodal deep learning methods have been proposed in the literature, the majority rely on having two or more independent networks that share knowledge at a later stage in the overall model. On the other hand, oncologists do not do this in their analysis but rather fuse the information in their brain from multiple sources such as medical images and patient history. This work proposes a deep learning method that mimics oncologists' analytical behavior when quantifying cancer and estimating patient survival. We propose TMSS, an end-to-end Transformer based Multimodal network for Segmentation and Survival prediction that leverages the superiority of transformers that lies in their abilities to handle different modalities. The model was trained and validated for segmentation and prognosis tasks on the training dataset from the HEad & NeCK TumOR segmentation and the outcome prediction in PET/CT images challenge (HECKTOR). We show that the proposed prognostic model significantly outperforms state-of-the-art methods with a concordance index of 0.763+/-0.14 while achieving a comparable dice score of 0.772+/-0.030 to a standalone segmentation model. The code is publicly available.
Stochastic strategies for patrolling a terrain with a synchronized multi-robot system
Sep 14, 2022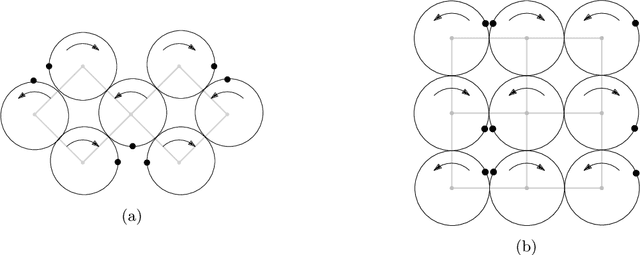
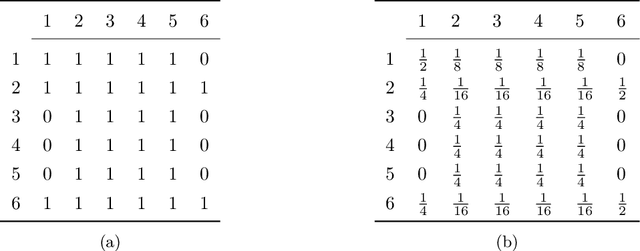
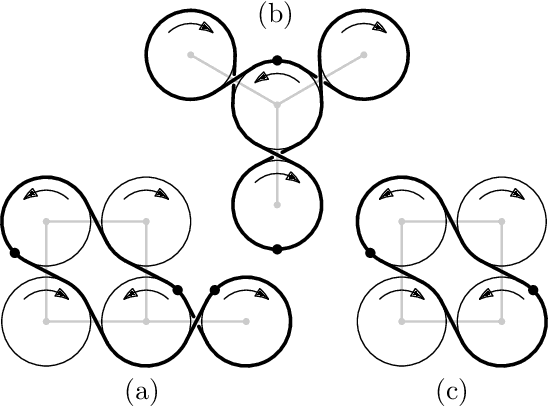
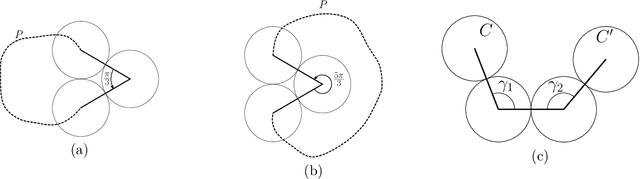
A group of cooperative aerial robots can be deployed to efficiently patrol a terrain, in which each robot flies around an assigned area and shares information with the neighbors periodically in order to protect or supervise it. To ensure robustness, previous works on these synchronized systems propose sending a robot to the neighboring area in case it detects a failure. In order to deal with unpredictability and to improve on the efficiency in the deterministic patrolling scheme, this paper proposes random strategies to cover the areas distributed among the agents. First, a theoretical study of the stochastic process is addressed in this paper for two metrics: the \emph{idle time}, the expected time between two consecutive observations of any point of the terrain and the \emph{isolation time}, the expected time that a robot is without communication with any other robot. After that, the random strategies are experimentally compared with the deterministic strategy adding another metric: the \emph{broadcast time}, the expected time elapsed from the moment a robot emits a message until it is received by all the other robots of the team. The simulations show that theoretical results are in good agreement with the simulations and the random strategies outperform the behavior obtained with the deterministic protocol proposed in the literature.
CM-MLP: Cascade Multi-scale MLP with Axial Context Relation Encoder for Edge Segmentation of Medical Image
Aug 23, 2022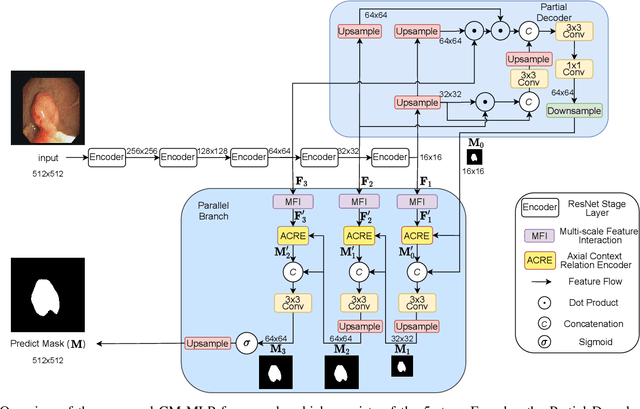
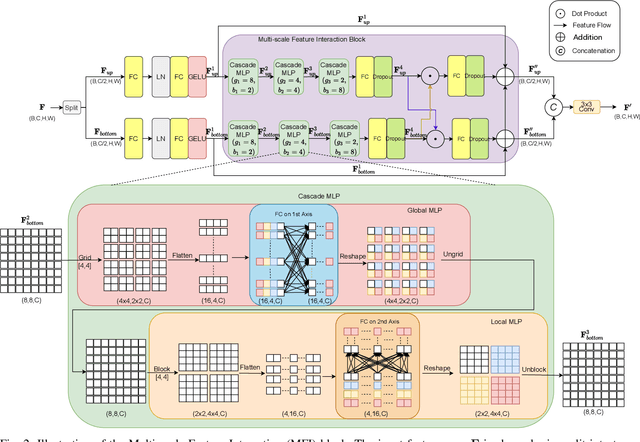
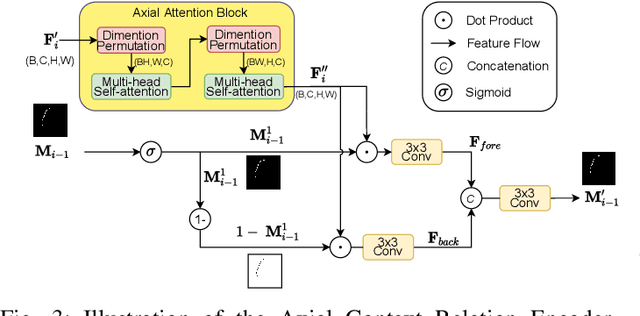
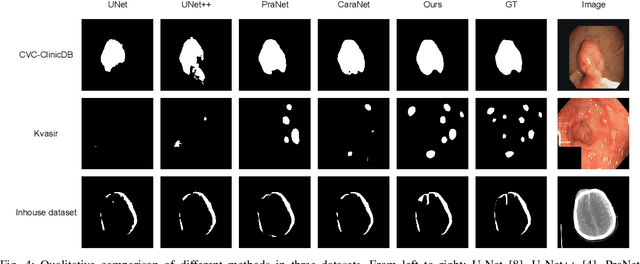
The convolutional-based methods provide good segmentation performance in the medical image segmentation task. However, those methods have the following challenges when dealing with the edges of the medical images: (1) Previous convolutional-based methods do not focus on the boundary relationship between foreground and background around the segmentation edge, which leads to the degradation of segmentation performance when the edge changes complexly. (2) The inductive bias of the convolutional layer cannot be adapted to complex edge changes and the aggregation of multiple-segmented areas, resulting in its performance improvement mostly limited to segmenting the body of segmented areas instead of the edge. To address these challenges, we propose the CM-MLP framework on MFI (Multi-scale Feature Interaction) block and ACRE (Axial Context Relation Encoder) block for accurate segmentation of the edge of medical image. In the MFI block, we propose the cascade multi-scale MLP (Cascade MLP) to process all local information from the deeper layers of the network simultaneously and utilize a cascade multi-scale mechanism to fuse discrete local information gradually. Then, the ACRE block is used to make the deep supervision focus on exploring the boundary relationship between foreground and background to modify the edge of the medical image. The segmentation accuracy (Dice) of our proposed CM-MLP framework reaches 96.96%, 96.76%, and 82.54% on three benchmark datasets: CVC-ClinicDB dataset, sub-Kvasir dataset, and our in-house dataset, respectively, which significantly outperform the state-of-the-art method. The source code and trained models will be available at https://github.com/ProgrammerHyy/CM-MLP.
Does Structure Matter? Leveraging Data-to-Text Generation for Answering Complex Information Needs
Dec 08, 2021

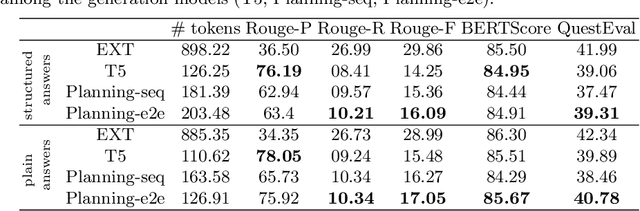

In this work, our aim is to provide a structured answer in natural language to a complex information need. Particularly, we envision using generative models from the perspective of data-to-text generation. We propose the use of a content selection and planning pipeline which aims at structuring the answer by generating intermediate plans. The experimental evaluation is performed using the TREC Complex Answer Retrieval (CAR) dataset. We evaluate both the generated answer and its corresponding structure and show the effectiveness of planning-based models in comparison to a text-to-text model.
CNSNet: A Cleanness-Navigated-Shadow Network for Shadow Removal
Sep 06, 2022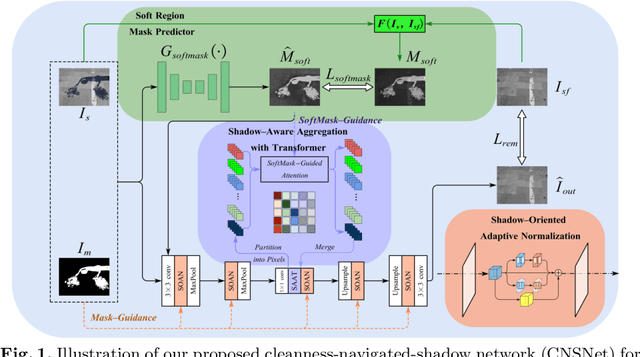
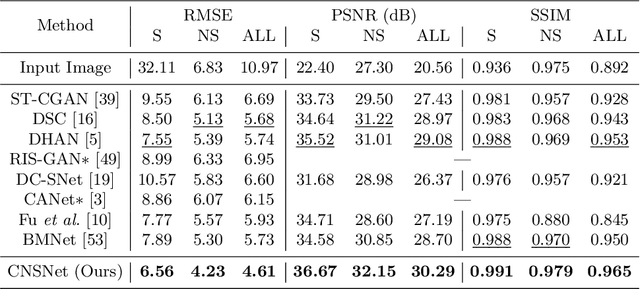

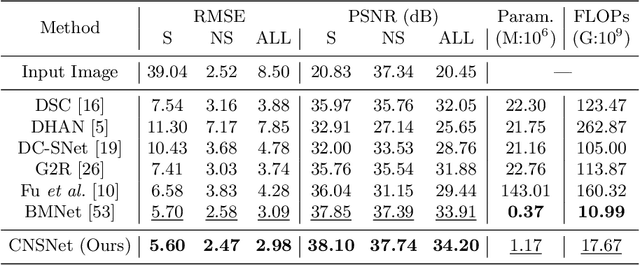
The key to shadow removal is recovering the contents of the shadow regions with the guidance of the non-shadow regions. Due to the inadequate long-range modeling, the CNN-based approaches cannot thoroughly investigate the information from the non-shadow regions. To solve this problem, we propose a novel cleanness-navigated-shadow network (CNSNet), with a shadow-oriented adaptive normalization (SOAN) module and a shadow-aware aggregation with transformer (SAAT) module based on the shadow mask. Under the guidance of the shadow mask, the SOAN module formulates the statistics from the non-shadow region and adaptively applies them to the shadow region for region-wise restoration. The SAAT module utilizes the shadow mask to precisely guide the restoration of each shadowed pixel by considering the highly relevant pixels from the shadow-free regions for global pixel-wise restoration. Extensive experiments on three benchmark datasets (ISTD, ISTD+, and SRD) show that our method achieves superior de-shadowing performance.
Out of One, Many: Using Language Models to Simulate Human Samples
Sep 14, 2022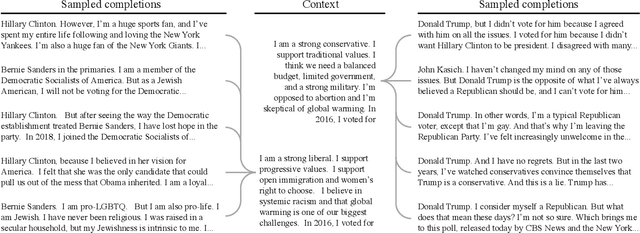
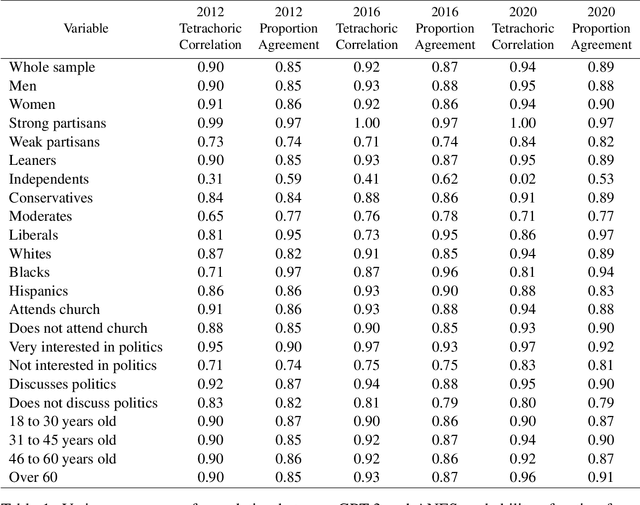
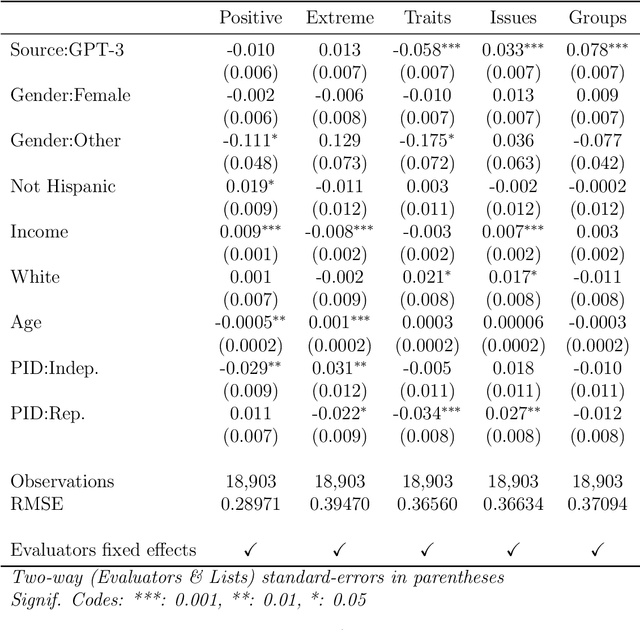

We propose and explore the possibility that language models can be studied as effective proxies for specific human sub-populations in social science research. Practical and research applications of artificial intelligence tools have sometimes been limited by problematic biases (such as racism or sexism), which are often treated as uniform properties of the models. We show that the "algorithmic bias" within one such tool -- the GPT-3 language model -- is instead both fine-grained and demographically correlated, meaning that proper conditioning will cause it to accurately emulate response distributions from a wide variety of human subgroups. We term this property "algorithmic fidelity" and explore its extent in GPT-3. We create "silicon samples" by conditioning the model on thousands of socio-demographic backstories from real human participants in multiple large surveys conducted in the United States. We then compare the silicon and human samples to demonstrate that the information contained in GPT-3 goes far beyond surface similarity. It is nuanced, multifaceted, and reflects the complex interplay between ideas, attitudes, and socio-cultural context that characterize human attitudes. We suggest that language models with sufficient algorithmic fidelity thus constitute a novel and powerful tool to advance understanding of humans and society across a variety of disciplines.
Spatial Temporal Graph Attention Network for Skeleton-Based Action Recognition
Aug 18, 2022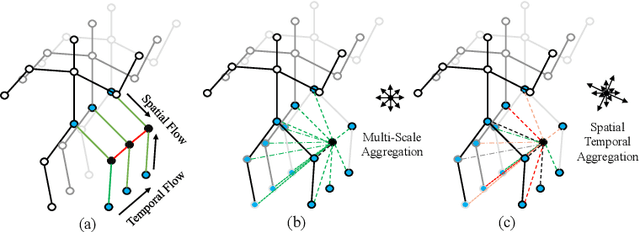
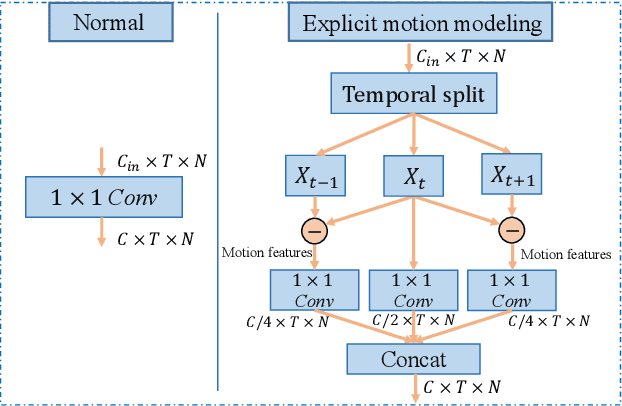
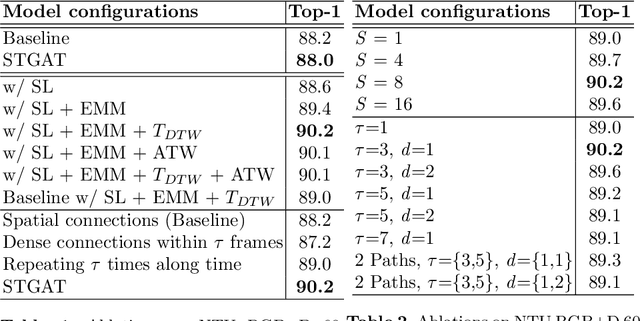
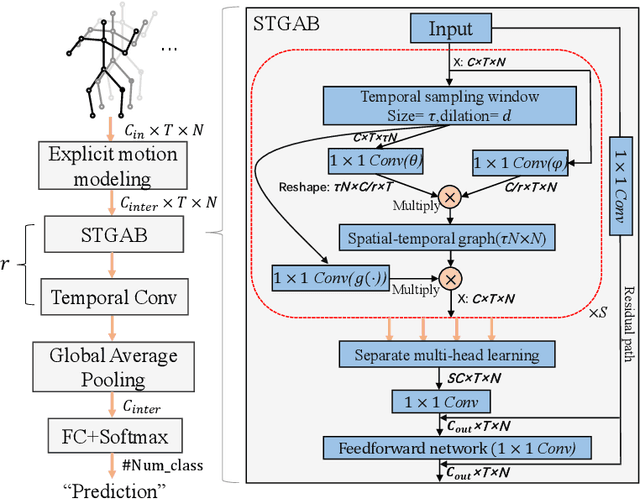
It's common for current methods in skeleton-based action recognition to mainly consider capturing long-term temporal dependencies as skeleton sequences are typically long (>128 frames), which forms a challenging problem for previous approaches. In such conditions, short-term dependencies are few formally considered, which are critical for classifying similar actions. Most current approaches are consisted of interleaving spatial-only modules and temporal-only modules, where direct information flow among joints in adjacent frames are hindered, thus inferior to capture short-term motion and distinguish similar action pairs. To handle this limitation, we propose a general framework, coined as STGAT, to model cross-spacetime information flow. It equips the spatial-only modules with spatial-temporal modeling for regional perception. While STGAT is theoretically effective for spatial-temporal modeling, we propose three simple modules to reduce local spatial-temporal feature redundancy and further release the potential of STGAT, which (1) narrow the scope of self-attention mechanism, (2) dynamically weight joints along temporal dimension, and (3) separate subtle motion from static features, respectively. As a robust feature extractor, STGAT generalizes better upon classifying similar actions than previous methods, witnessed by both qualitative and quantitative results. STGAT achieves state-of-the-art performance on three large-scale datasets: NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400. Code is released.
RDA: Reciprocal Distribution Alignment for Robust Semi-supervised Learning
Aug 12, 2022
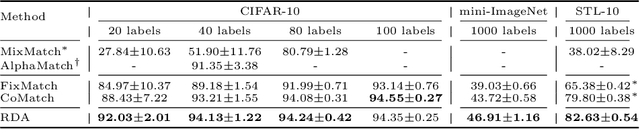
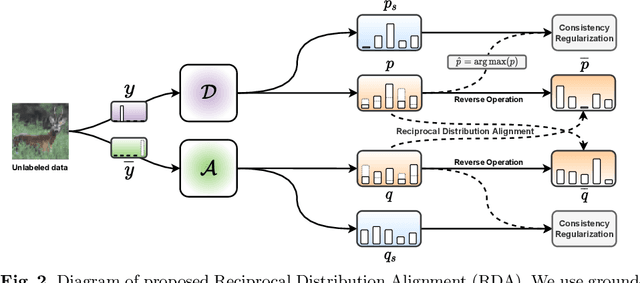
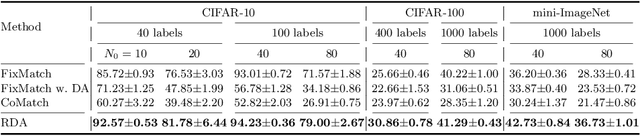
In this work, we propose Reciprocal Distribution Alignment (RDA) to address semi-supervised learning (SSL), which is a hyperparameter-free framework that is independent of confidence threshold and works with both the matched (conventionally) and the mismatched class distributions. Distribution mismatch is an often overlooked but more general SSL scenario where the labeled and the unlabeled data do not fall into the identical class distribution. This may lead to the model not exploiting the labeled data reliably and drastically degrade the performance of SSL methods, which could not be rescued by the traditional distribution alignment. In RDA, we enforce a reciprocal alignment on the distributions of the predictions from two classifiers predicting pseudo-labels and complementary labels on the unlabeled data. These two distributions, carrying complementary information, could be utilized to regularize each other without any prior of class distribution. Moreover, we theoretically show that RDA maximizes the input-output mutual information. Our approach achieves promising performance in SSL under a variety of scenarios of mismatched distributions, as well as the conventional matched SSL setting. Our code is available at: https://github.com/NJUyued/RDA4RobustSSL.
MATT: A Multiple-instance Attention Mechanism for Long-tail Music Genre Classification
Sep 09, 2022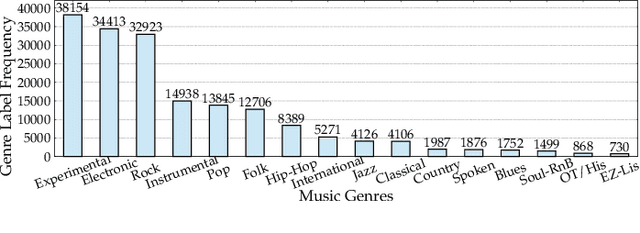
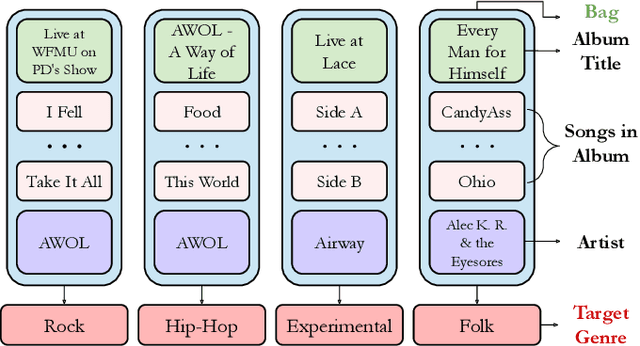
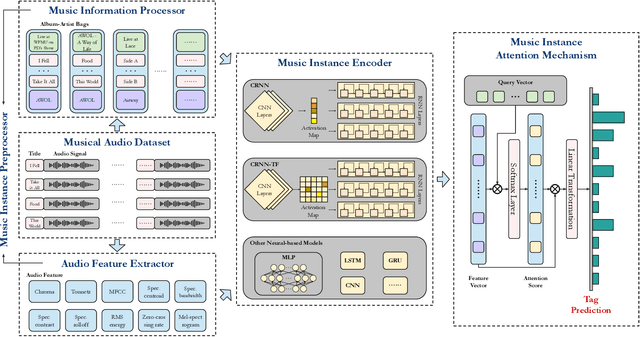
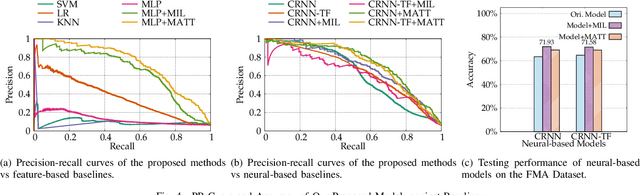
Imbalanced music genre classification is a crucial task in the Music Information Retrieval (MIR) field for identifying the long-tail, data-poor genre based on the related music audio segments, which is very prevalent in real-world scenarios. Most of the existing models are designed for class-balanced music datasets, resulting in poor performance in accuracy and generalization when identifying the music genres at the tail of the distribution. Inspired by the success of introducing Multi-instance Learning (MIL) in various classification tasks, we propose a novel mechanism named Multi-instance Attention (MATT) to boost the performance for identifying tail classes. Specifically, we first construct the bag-level datasets by generating the album-artist pair bags. Second, we leverage neural networks to encode the music audio segments. Finally, under the guidance of a multi-instance attention mechanism, the neural network-based models could select the most informative genre to match the given music segment. Comprehensive experimental results on a large-scale music genre benchmark dataset with long-tail distribution demonstrate MATT significantly outperforms other state-of-the-art baselines.