 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Attention GAN for Vehicle Motion Prediction
Sep 26, 2022
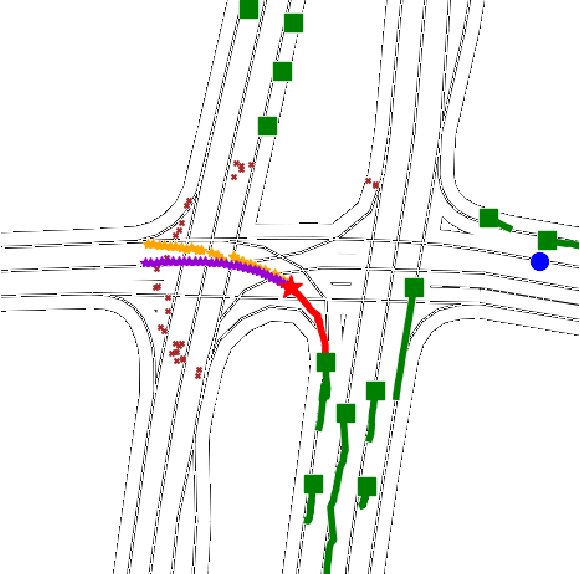
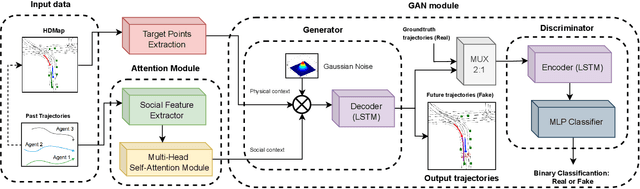
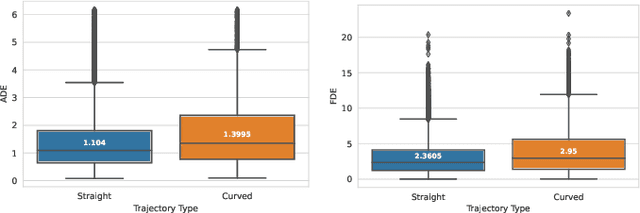
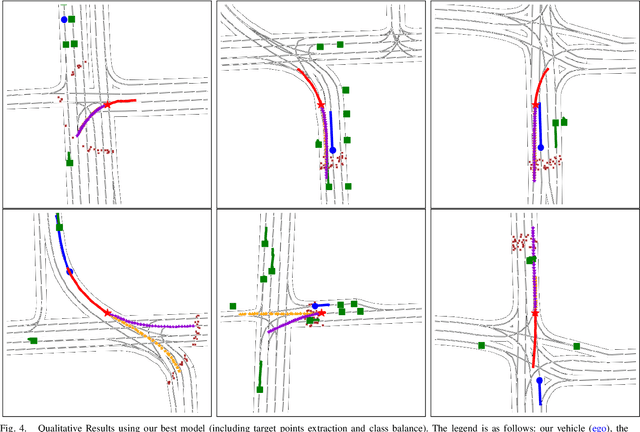
The design of a safe and reliable Autonomous Driving stack (ADS) is one of the most challenging tasks of our era. These ADS are expected to be driven in highly dynamic environments with full autonomy, and a reliability greater than human beings. In that sense, to efficiently and safely navigate through arbitrarily complex traffic scenarios, ADS must have the ability to forecast the future trajectories of surrounding actors. Current state-of-the-art models are typically based on Recurrent, Graph and Convolutional networks, achieving noticeable results in the context of vehicle prediction. In this paper we explore the influence of attention in generative models for motion prediction, considering both physical and social context to compute the most plausible trajectories. We first encode the past trajectories using a LSTM network, which serves as input to a Multi-Head Self-Attention module that computes the social context. On the other hand, we formulate a weighted interpolation to calculate the velocity and orientation in the last observation frame in order to calculate acceptable target points, extracted from the driveable of the HDMap information, which represents our physical context. Finally, the input of our generator is a white noise vector sampled from a multivariate normal distribution while the social and physical context are its conditions, in order to predict plausible trajectories. We validate our method using the Argoverse Motion Forecasting Benchmark 1.1, achieving competitive unimodal results.
Efficient Surfel Fusion Using Normalised Information Distance
Aug 11, 2021
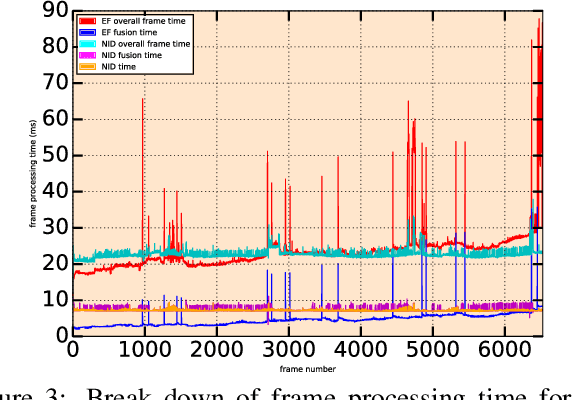
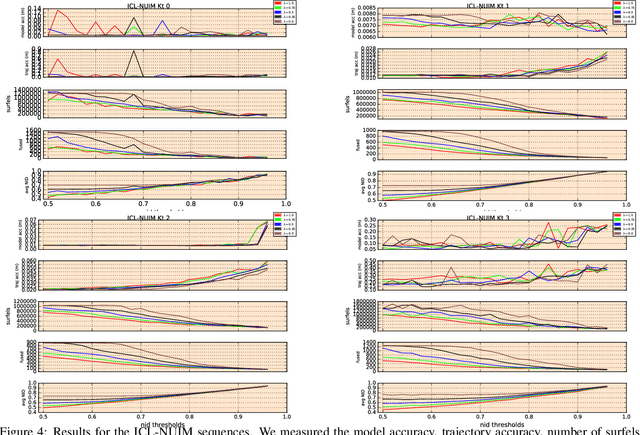
We present a new technique that achieves a significant reduction in the quantity of measurements required for a fusion based dense 3D mapping system to converge to an accurate, de-noised surface reconstruction. This is achieved through the use of a Normalised Information Distance metric, that computes the novelty of the information contained in each incoming frame with respect to the reconstruction, and avoids fusing those frames that exceed a redundancy threshold. This provides a principled approach for opitmising the trade-off between surface reconstruction accuracy and the computational cost of processing frames. The technique builds upon the ElasticFusion (EF) algorithm where we report results of the technique's scalability and the accuracy of the resultant maps by applying it to both the ICL-NUIM and TUM RGB-D datasets. These results demonstrate the capabilities of the approach in performing accurate surface reconstructions whilst utilising a fraction of the frames when compared to the original EF algorithm.
Continual Learning for Pose-Agnostic Object Recognition in 3D Point Clouds
Sep 11, 2022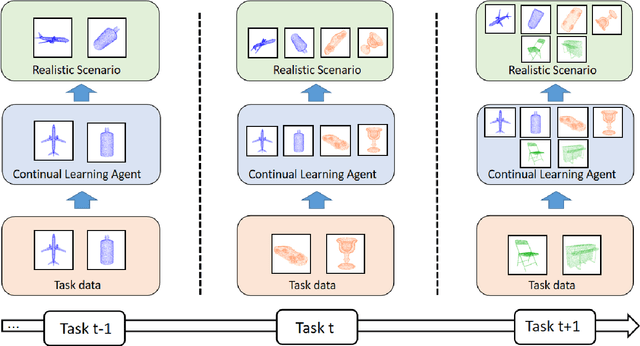
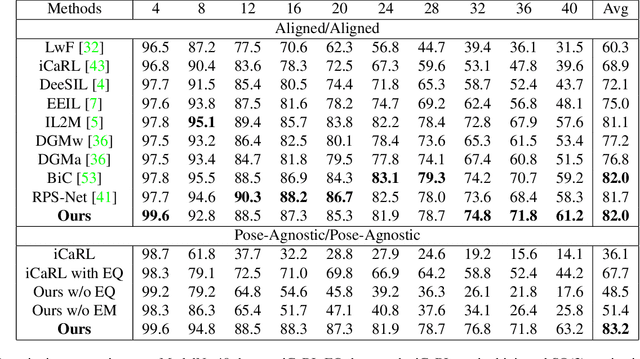
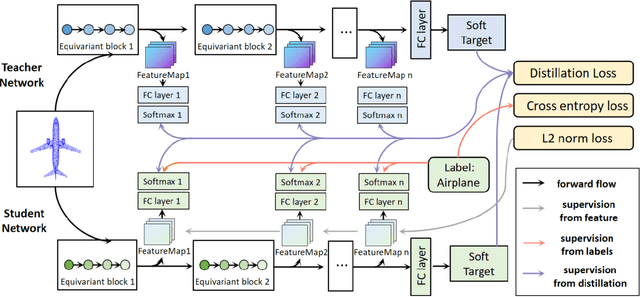
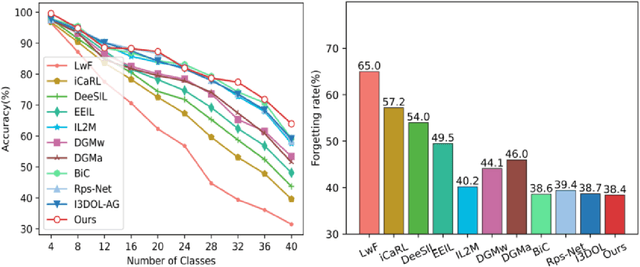
Continual Learning aims to learn multiple incoming new tasks continually, and to keep the performance of learned tasks at a consistent level. However, existing research on continual learning assumes the pose of the object is pre-defined and well-aligned. For practical application, this work focuses on pose-agnostic continual learning tasks, where the object's pose changes dynamically and unpredictably. The point cloud augmentation adopted from past approaches would sharply rise with the task increment in the continual learning process. To address this problem, we inject the equivariance as the additional prior knowledge into the networks. We proposed a novel continual learning model that effectively distillates previous tasks' geometric equivariance information. The experiments show that our method overcomes the challenge of pose-agnostic scenarios in several mainstream point cloud datasets. We further conduct ablation studies to evaluate the validation of each component of our approach.
Dual Stream Computer-Generated Image Detection Network Based On Channel Joint And Softpool
Jul 07, 2022
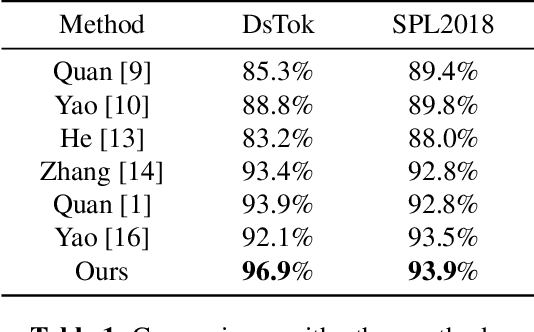
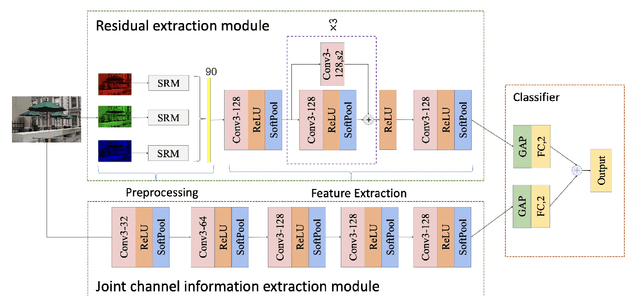
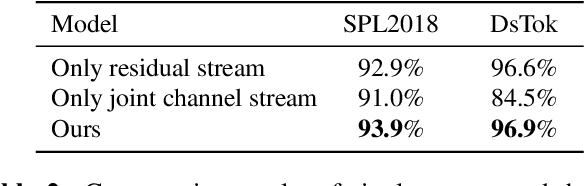
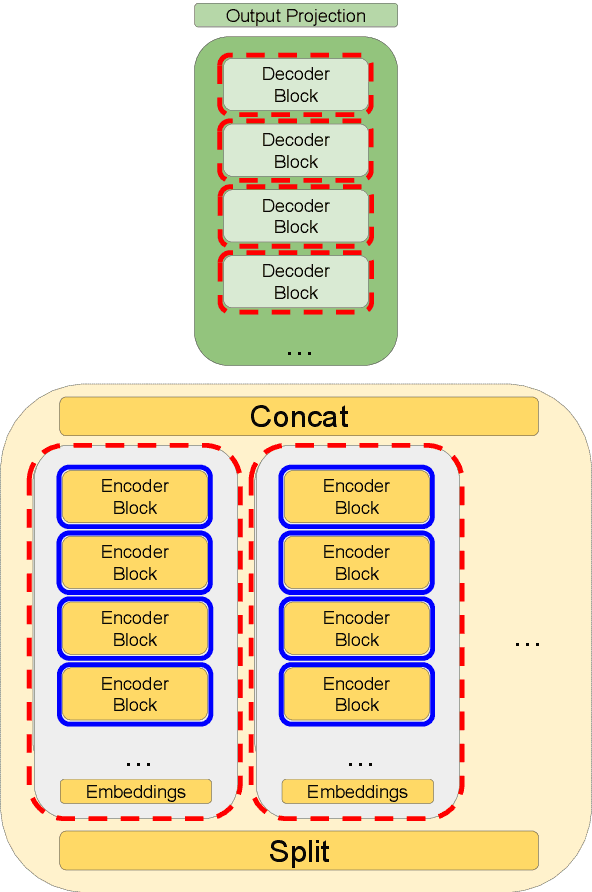
With the development of computer graphics technology, the images synthesized by computer software become more and more closer to the photographs. While computer graphics technology brings us a grand visual feast in the field of games and movies, it may also be utilized by someone with bad intentions to guide public opinions and cause political crisis or social unrest. Therefore, how to distinguish the computer-generated graphics (CG) from the photographs (PG) has become an important topic in the field of digital image forensics. This paper proposes a dual stream convolutional neural network based on channel joint and softpool. The proposed network architecture includes a residual module for extracting image noise information and a joint channel information extraction module for capturing the shallow semantic information of image. In addition, we also design a residual structure to enhance feature extraction and reduce the loss of information in residual flow. The joint channel information extraction module can obtain the shallow semantic information of the input image which can be used as the information supplement block of the residual module. The whole network uses SoftPool to reduce the information loss of down-sampling for image. Finally, we fuse the two flows to get the classification results. Experiments on SPL2018 and DsTok show that the proposed method outperforms existing methods, especially on the DsTok dataset. For example, the performance of our model surpasses the state-of-the-art by a large margin of 3%.
Doc2Dict: Information Extraction as Text Generation
May 16, 2021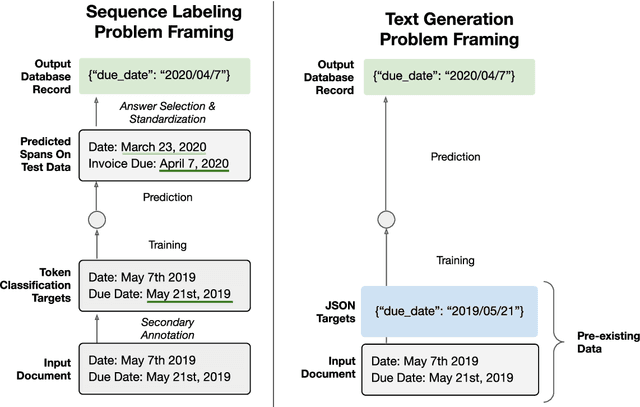
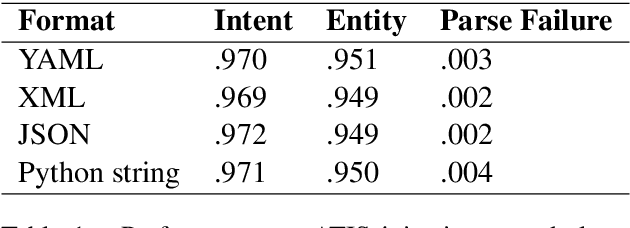
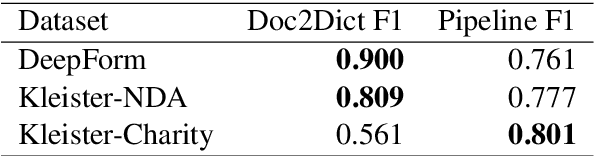
Typically, information extraction (IE) requires a pipeline approach: first, a sequence labeling model is trained on manually annotated documents to extract relevant spans; then, when a new document arrives, a model predicts spans which are then post-processed and standardized to convert the information into a database entry. We replace this labor-intensive workflow with a transformer language model trained on existing database records to directly generate structured JSON. Our solution removes the workload associated with producing token-level annotations and takes advantage of a data source which is generally quite plentiful (e.g. database records). As long documents are common in information extraction tasks, we use gradient checkpointing and chunked encoding to apply our method to sequences of up to 32,000 tokens on a single GPU. Our Doc2Dict approach is competitive with more complex, hand-engineered pipelines and offers a simple but effective baseline for document-level information extraction. We release our Doc2Dict model and code to reproduce our experiments and facilitate future work.
Location Sensing and Beamforming Design for IRS-Enabled Multi-User ISAC Systems
Aug 10, 2022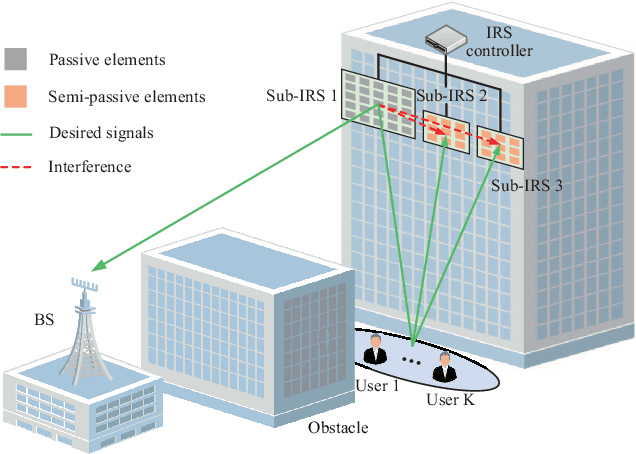
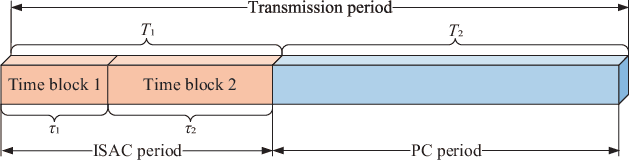
This paper explores the potential of the intelligent reflecting surface (IRS) in realizing multi-user concurrent communication and localization, using the same time-frequency resources. Specifically, we propose an IRS-enabled multi-user integrated sensing and communication (ISAC) framework, where a distributed semi-passive IRS assists the uplink data transmission from multiple users to the base station (BS) and conducts multi-user localization, simultaneously. We first design an ISAC transmission protocol, where the whole transmission period consists of two periods, i.e., the ISAC period for simultaneous uplink communication and multi-user localization, and the pure communication (PC) period for only uplink data transmission. For the ISAC period, we propose a multi-user location sensing algorithm, which utilizes the uplink communication signals unknown to the IRS, thus removing the requirement of dedicated positioning reference signals in conventional location sensing methods. Based on the sensed users' locations, we propose two novel beamforming algorithms for the ISAC period and PC period, respectively, which can work with discrete phase shifts and require no channel state information (CSI) acquisition. Numerical results show that the proposed multi-user location sensing algorithm can achieve up to millimeter-level positioning accuracy, indicating the advantage of the IRS-enabled ISAC framework. Moreover, the proposed beamforming algorithms with sensed location information and discrete phase shifts can achieve comparable performance to the benchmark considering perfect CSI acquisition and continuous phase shifts, demonstrating how the location information can ensure the communication performance.
MulBot: Unsupervised Bot Detection Based on Multivariate Time Series
Sep 21, 2022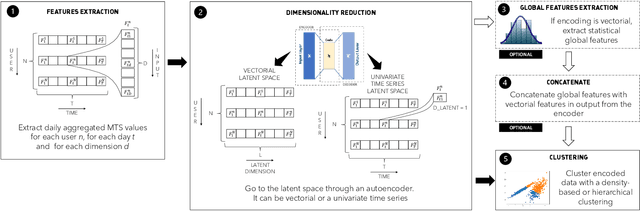

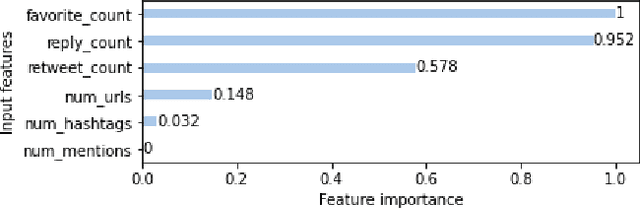

Online social networks are actively involved in the removal of malicious social bots due to their role in the spread of low quality information. However, most of the existing bot detectors are supervised classifiers incapable of capturing the evolving behavior of sophisticated bots. Here we propose MulBot, an unsupervised bot detector based on multivariate time series (MTS). For the first time, we exploit multidimensional temporal features extracted from user timelines. We manage the multidimensionality with an LSTM autoencoder, which projects the MTS in a suitable latent space. Then, we perform a clustering step on this encoded representation to identify dense groups of very similar users -- a known sign of automation. Finally, we perform a binary classification task achieving f1-score $= 0.99$, outperforming state-of-the-art methods (f1-score $\le 0.97$). Not only does MulBot achieve excellent results in the binary classification task, but we also demonstrate its strengths in a novel and practically-relevant task: detecting and separating different botnets. In this multi-class classification task we achieve f1-score $= 0.96$. We conclude by estimating the importance of the different features used in our model and by evaluating MulBot's capability to generalize to new unseen bots, thus proposing a solution to the generalization deficiencies of supervised bot detectors.
Robust Category-Level 6D Pose Estimation with Coarse-to-Fine Rendering of Neural Features
Sep 12, 2022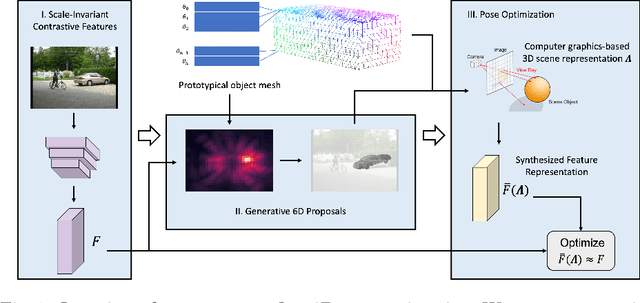
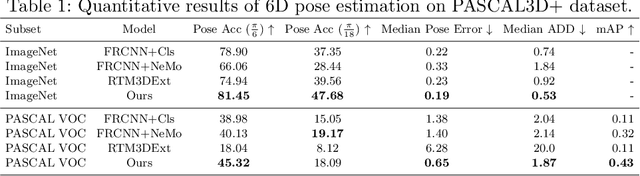


We consider the problem of category-level 6D pose estimation from a single RGB image. Our approach represents an object category as a cuboid mesh and learns a generative model of the neural feature activations at each mesh vertex to perform pose estimation through differentiable rendering. A common problem of rendering-based approaches is that they rely on bounding box proposals, which do not convey information about the 3D rotation of the object and are not reliable when objects are partially occluded. Instead, we introduce a coarse-to-fine optimization strategy that utilizes the rendering process to estimate a sparse set of 6D object proposals, which are subsequently refined with gradient-based optimization. The key to enabling the convergence of our approach is a neural feature representation that is trained to be scale- and rotation-invariant using contrastive learning. Our experiments demonstrate an enhanced category-level 6D pose estimation performance compared to prior work, particularly under strong partial occlusion.
Towards Multilingual Transitivity and Bidirectional Multilingual Agreement for Multilingual Document-level Machine Translation
Sep 28, 2022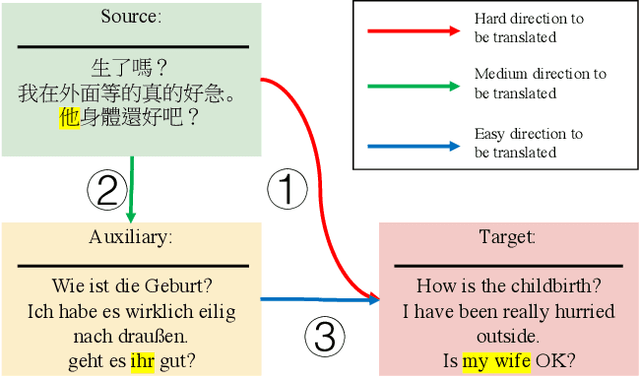
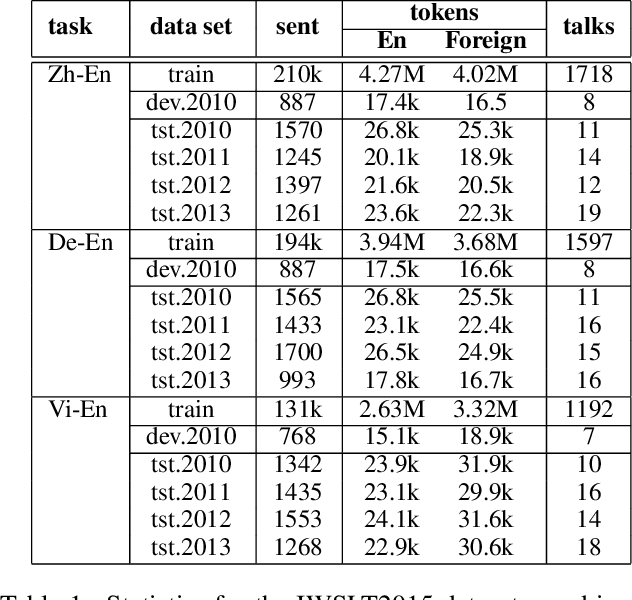
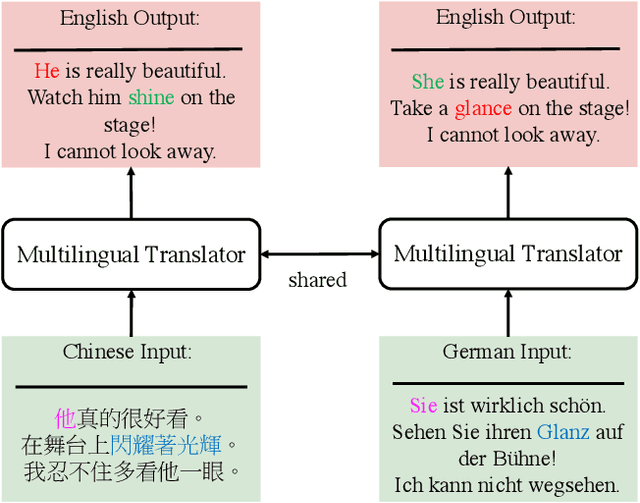

Multilingual machine translation has been proven an effective strategy to support translation between multiple languages with a single model. However, most studies focus on multilingual sentence translation without considering generating long documents across different languages, which requires an understanding of multilingual context dependency and is typically harder. In this paper, we first spot that naively incorporating auxiliary multilingual data either auxiliary-target or source-auxiliary brings no improvement to the source-target language pair in our interest. Motivated by this observation, we propose a novel framework called Multilingual Transitivity (MTrans) to find an implicit optimal route via source-auxiliary-target within the multilingual model. To encourage MTrans, we propose a novel method called Triplet Parallel Data (TPD), which uses parallel triplets that contain (source-auxiliary, auxiliary-target, and source-target) for training. The auxiliary language then serves as a pivot and automatically facilitates the implicit information transition flow which is easier to translate. We further propose a novel framework called Bidirectional Multilingual Agreement (Bi-MAgree) that encourages the bidirectional agreement between different languages. To encourage Bi-MAgree, we propose a novel method called Multilingual Kullback-Leibler Divergence (MKL) that forces the output distribution of the inputs with the same meaning but in different languages to be consistent with each other. The experimental results indicate that our methods bring consistent improvements over strong baselines on three document translation tasks: IWSLT2015 Zh-En, De-En, and Vi-En. Our analysis validates the usefulness and existence of MTrans and Bi-MAgree, and our frameworks and methods are effective on synthetic auxiliary data.
Visual Anomaly Detection Via Partition Memory Bank Module and Error Estimation
Sep 26, 2022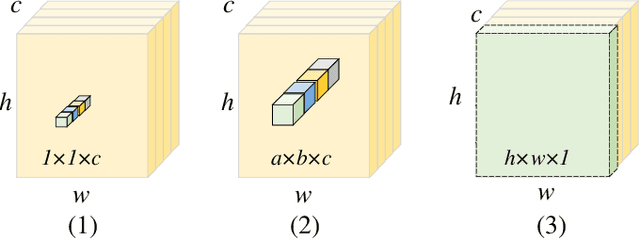
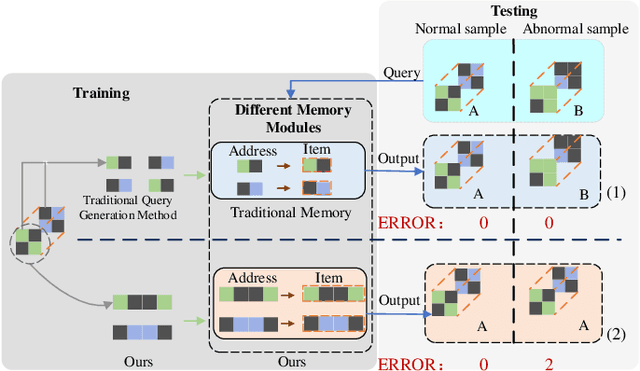
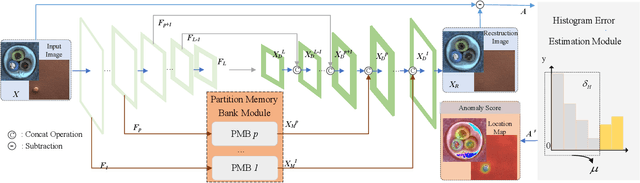
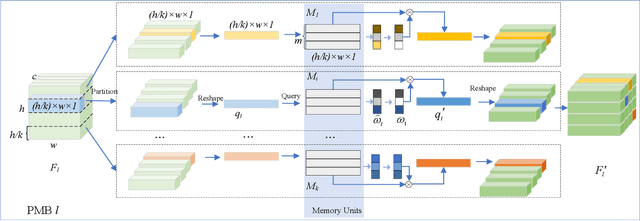
Reconstruction method based on the memory module for visual anomaly detection attempts to narrow the reconstruction error for normal samples while enlarging it for anomalous samples. Unfortunately, the existing memory module is not fully applicable to the anomaly detection task, and the reconstruction error of the anomaly samples remains small. Towards this end, this work proposes a new unsupervised visual anomaly detection method to jointly learn effective normal features and eliminate unfavorable reconstruction errors. Specifically, a novel Partition Memory Bank (PMB) module is proposed to effectively learn and store detailed features with semantic integrity of normal samples. It develops a new partition mechanism and a unique query generation method to preserve the context information and then improves the learning ability of the memory module. The proposed PMB and the skip connection are alternatively explored to make the reconstruction of abnormal samples worse. To obtain more precise anomaly localization results and solve the problem of cumulative reconstruction error, a novel Histogram Error Estimation module is proposed to adaptively eliminate the unfavorable errors by the histogram of the difference image. It improves the anomaly localization performance without increasing the cost. To evaluate the effectiveness of the proposed method for anomaly detection and localization, extensive experiments are conducted on three widely-used anomaly detection datasets. The encouraging performance of the proposed method compared to the recent approaches based on the memory module demonstrates its superiority.