 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
IntereStyle: Encoding an Interest Region for Robust StyleGAN Inversion
Sep 22, 2022

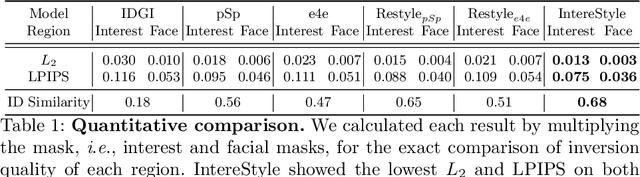

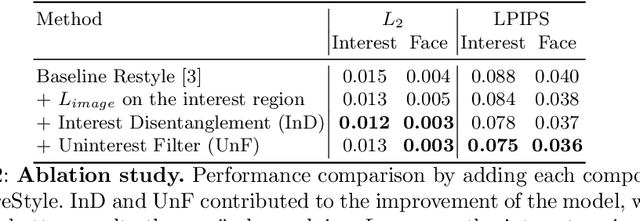
Recently, manipulation of real-world images has been highly elaborated along with the development of Generative Adversarial Networks (GANs) and corresponding encoders, which embed real-world images into the latent space. However, designing encoders of GAN still remains a challenging task due to the trade-off between distortion and perception. In this paper, we point out that the existing encoders try to lower the distortion not only on the interest region, e.g., human facial region but also on the uninterest region, e.g., background patterns and obstacles. However, most uninterest regions in real-world images are located at out-of-distribution (OOD), which are infeasible to be ideally reconstructed by generative models. Moreover, we empirically find that the uninterest region overlapped with the interest region can mangle the original feature of the interest region, e.g., a microphone overlapped with a facial region is inverted into the white beard. As a result, lowering the distortion of the whole image while maintaining the perceptual quality is very challenging. To overcome this trade-off, we propose a simple yet effective encoder training scheme, coined IntereStyle, which facilitates encoding by focusing on the interest region. IntereStyle steers the encoder to disentangle the encodings of the interest and uninterest regions. To this end, we filter the information of the uninterest region iteratively to regulate the negative impact of the uninterest region. We demonstrate that IntereStyle achieves both lower distortion and higher perceptual quality compared to the existing state-of-the-art encoders. Especially, our model robustly conserves features of the original images, which shows the robust image editing and style mixing results. We will release our code with the pre-trained model after the review.
Multimodal and Crossmodal AI for Smart Data Analysis
Sep 03, 2022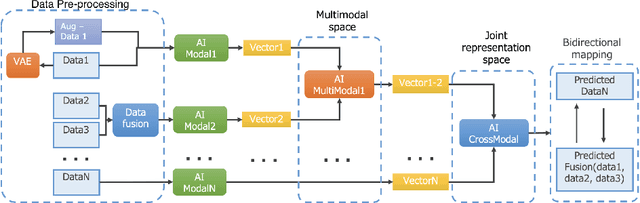

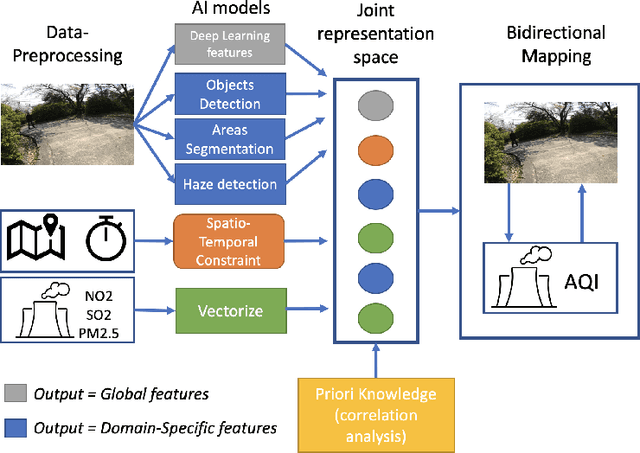
Recently, the multimodal and crossmodal AI techniques have attracted the attention of communities. The former aims to collect disjointed and heterogeneous data to compensate for complementary information to enhance robust prediction. The latter targets to utilize one modality to predict another modality by discovering the common attention sharing between them. Although both approaches share the same target: generate smart data from collected raw data, the former demands more modalities while the latter aims to decrease the variety of modalities. This paper first discusses the role of multimodal and crossmodal AI in smart data analysis in general. Then, we introduce the multimodal and crossmodal AI framework (MMCRAI) to balance the abovementioned approaches and make it easy to scale into different domains. This framework is integrated into xDataPF (the cross-data platform https://www.xdata.nict.jp/). We also introduce and discuss various applications built on this framework and xDataPF.
Variational Autoencoder Kernel Interpretation and Selection for Classification
Sep 10, 2022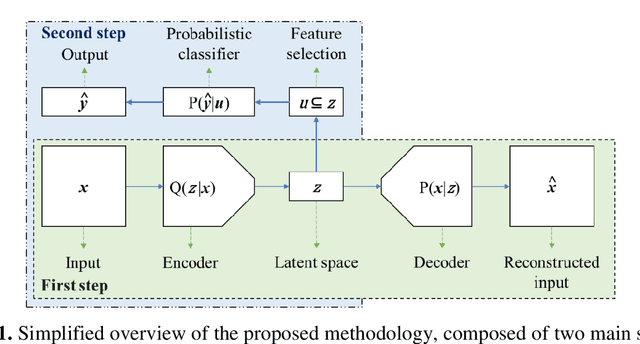
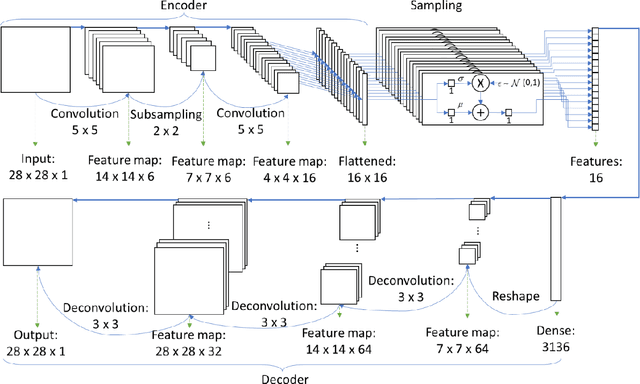
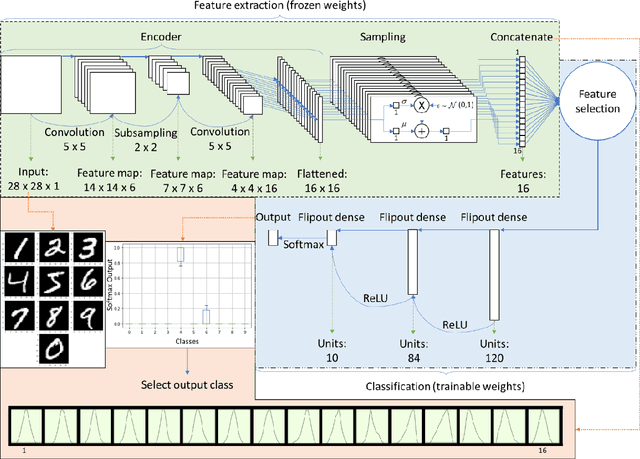
This work proposed kernel selection approaches for probabilistic classifiers based on features produced by the convolutional encoder of a variational autoencoder. Particularly, the developed methodologies allow the selection of the most relevant subset of latent variables. In the proposed implementation, each latent variable was sampled from the distribution associated with a single kernel of the last encoder's convolution layer, as an individual distribution was created for each kernel. Therefore, choosing relevant features on the sampled latent variables makes it possible to perform kernel selection, filtering the uninformative features and kernels. Such leads to a reduction in the number of the model's parameters. Both wrapper and filter methods were evaluated for feature selection. The second was of particular relevance as it is based only on the distributions of the kernels. It was assessed by measuring the Kullback-Leibler divergence between all distributions, hypothesizing that the kernels whose distributions are more similar can be discarded. This hypothesis was confirmed since it was observed that the most similar kernels do not convey relevant information and can be removed. As a result, the proposed methodology is suitable for developing applications for resource-constrained devices.
Subclass Knowledge Distillation with Known Subclass Labels
Jul 17, 2022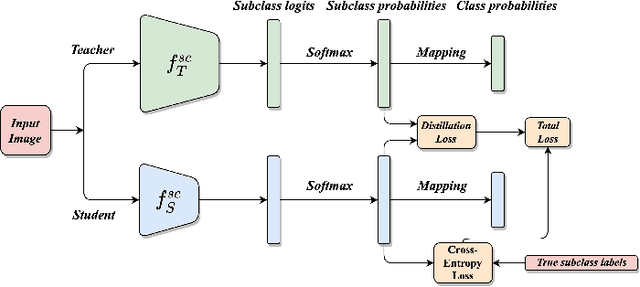
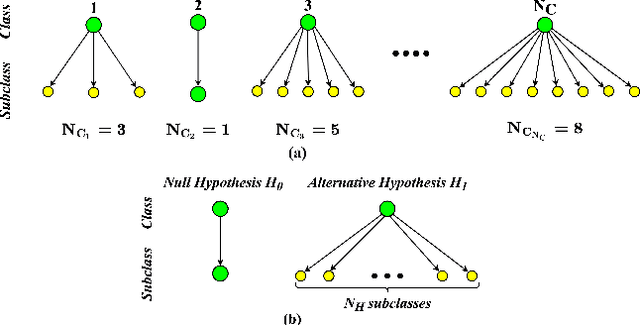
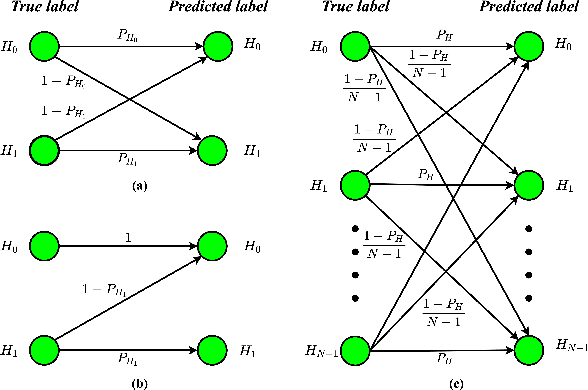
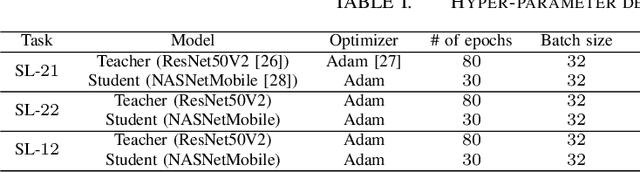
This work introduces a novel knowledge distillation framework for classification tasks where information on existing subclasses is available and taken into consideration. In classification tasks with a small number of classes or binary detection, the amount of information transferred from the teacher to the student is restricted, thus limiting the utility of knowledge distillation. Performance can be improved by leveraging information of possible subclasses within the classes. To that end, we propose the so-called Subclass Knowledge Distillation (SKD), a process of transferring the knowledge of predicted subclasses from a teacher to a smaller student. Meaningful information that is not in the teacher's class logits but exists in subclass logits (e.g., similarities within classes) will be conveyed to the student through the SKD, which will then boost the student's performance. Analytically, we measure how much extra information the teacher can provide the student via the SKD to demonstrate the efficacy of our work. The framework developed is evaluated in clinical application, namely colorectal polyp binary classification. It is a practical problem with two classes and a number of subclasses per class. In this application, clinician-provided annotations are used to define subclasses based on the annotation label's variability in a curriculum style of learning. A lightweight, low-complexity student trained with the SKD framework achieves an F1-score of 85.05%, an improvement of 1.47%, and a 2.10% gain over the student that is trained with and without conventional knowledge distillation, respectively. The 2.10% F1-score gap between students trained with and without the SKD can be explained by the extra subclass knowledge, i.e., the extra 0.4656 label bits per sample that the teacher can transfer in our experiment.
Geometry of EM and related iterative algorithms
Sep 03, 2022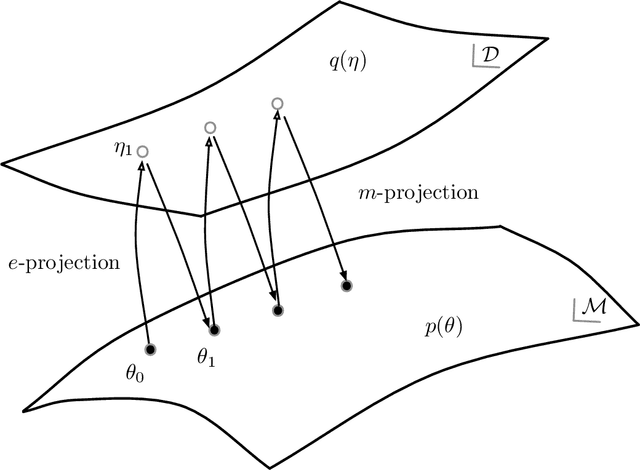
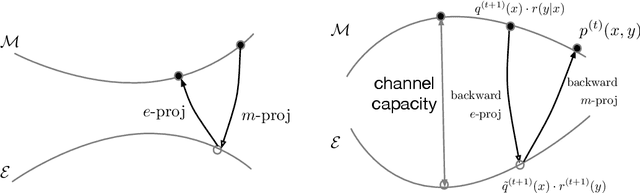
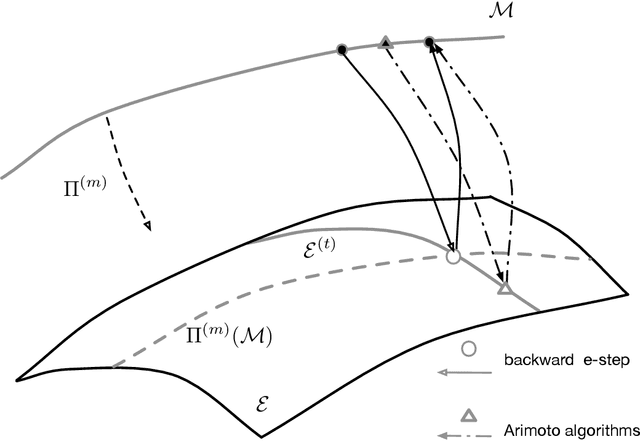
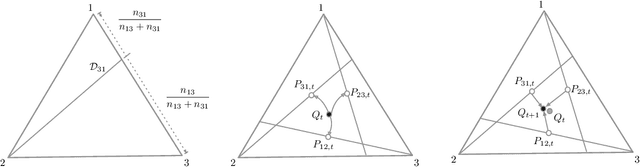
The Expectation--Maximization (EM) algorithm is a simple meta-algorithm that has been used for many years as a methodology for statistical inference when there are missing measurements in the observed data or when the data is composed of observables and unobservables. Its general properties are well studied, and also, there are countless ways to apply it to individual problems. In this paper, we introduce the $em$ algorithm, an information geometric formulation of the EM algorithm, and its extensions and applications to various problems. Specifically, we will see that it is possible to formulate an outlier-robust inference algorithm, an algorithm for calculating channel capacity, parameter estimation methods on probability simplex, particular multivariate analysis methods such as principal component analysis in a space of probability models and modal regression, matrix factorization, and learning generative models, which have recently attracted attention in deep learning, from the geometric perspective.
OCR for TIFF Compressed Document Images Directly in Compressed Domain Using Text segmentation and Hidden Markov Model
Sep 13, 2022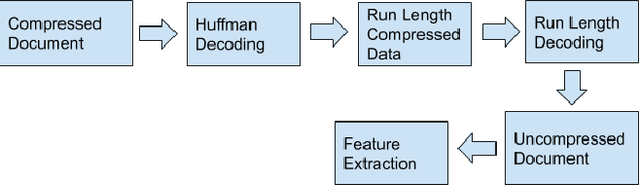

In today's technological era, document images play an important and integral part in our day to day life, and specifically with the surge of Covid-19, digitally scanned documents have become key source of communication, thus avoiding any sort of infection through physical contact. Storage and transmission of scanned document images is a very memory intensive task, hence compression techniques are being used to reduce the image size before archival and transmission. To extract information or to operate on the compressed images, we have two ways of doing it. The first way is to decompress the image and operate on it and subsequently compress it again for the efficiency of storage and transmission. The other way is to use the characteristics of the underlying compression algorithm to directly process the images in their compressed form without involving decompression and re-compression. In this paper, we propose a novel idea of developing an OCR for CCITT (The International Telegraph and Telephone Consultative Committee) compressed machine printed TIFF document images directly in the compressed domain. After segmenting text regions into lines and words, HMM is applied for recognition using three coding modes of CCITT- horizontal, vertical and the pass mode. Experimental results show that OCR on pass modes give a promising results.
Picking Up Speed: Continuous-Time Lidar-Only Odometry using Doppler Velocity Measurements
Sep 07, 2022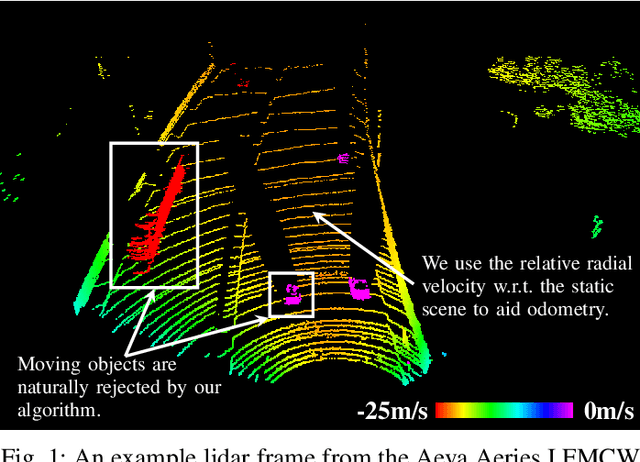
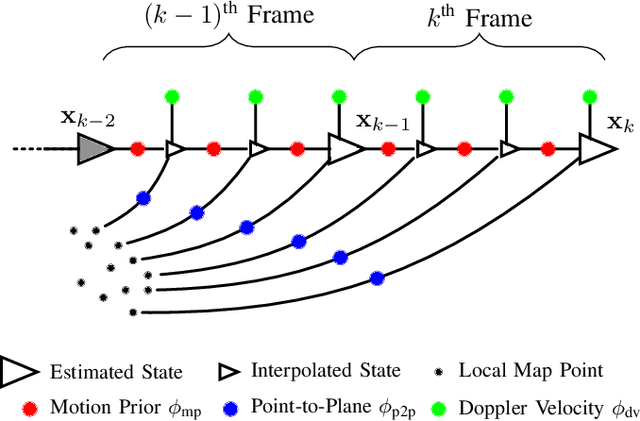
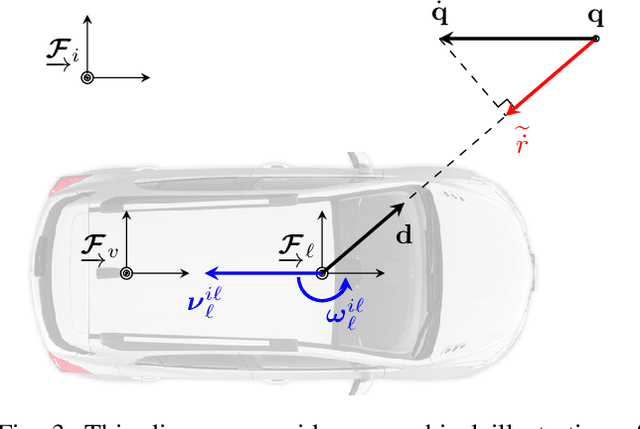

Frequency-Modulated Continuous-Wave (FMCW) lidar is a recently emerging technology that additionally enables per-return instantaneous relative radial velocity measurements via the Doppler effect. In this letter, we present the first continuous-time lidar-only odometry algorithm using these Doppler velocity measurements from an FMCW lidar to aid odometry in geometrically degenerate environments. We apply an existing continuous-time framework that efficiently estimates the vehicle trajectory using Gaussian process regression to compensate for motion distortion due to the scanning-while-moving nature of any mechanically actuated lidar (FMCW and non-FMCW). We evaluate our proposed algorithm on several real-world datasets, including publicly available ones and datasets we collected. Our algorithm outperforms the only existing method that also uses Doppler velocity measurements, and we study difficult conditions where including this extra information greatly improves performance. We additionally demonstrate state-of-the-art performance of lidar-only odometry with and without using Doppler velocity measurements in nominal conditions. Code for this project can be found at: https://github.com/utiasASRL/steam_icp.
Cooperative trajectory planning algorithm of USV-UAV with hull dynamic constraints
Sep 07, 2022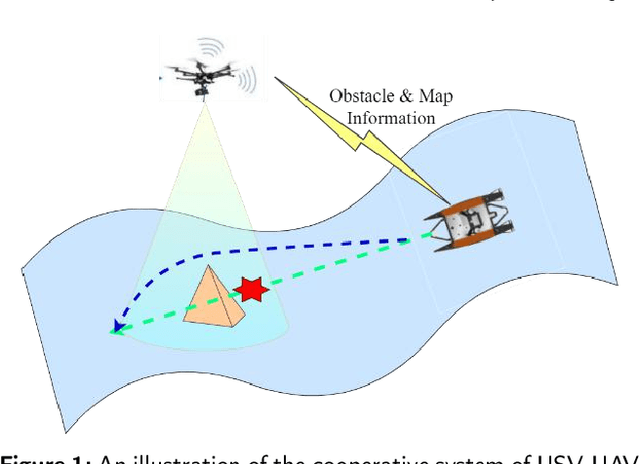

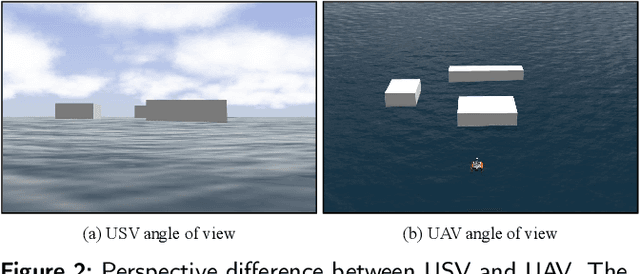
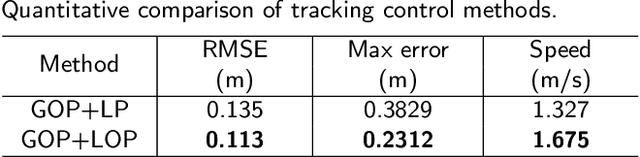
Efficient trajectory generation in complex dynamic environment stills remains an open problem in the unmanned surface vehicle (USV) domain. In this paper, a cooperative trajectory planning algorithm for the coupled USV-UAV system is proposed, to ensure that USV can execute safe and smooth path in the process of autonomous advance in multi obstacle maps. Specifically, the unmanned aerial vehicle (UAV) plays the role as a flight sensor, and it provides real-time global map and obstacle information with lightweight semantic segmentation network and 3D projection transformation. And then an initial obstacle avoidance trajectory is generated by a graph-based search method. Concerning the unique under-actuated kinematic characteristics of the USV, a numerical optimization method based on hull dynamic constraints is introduced to make the trajectory easier to be tracked for motion control. Finally, a motion control method based on NMPC with the lowest energy consumption constraint during execution is proposed. Experimental results verify the effectiveness of whole system, and the generated trajectory is locally optimal for USV with considerable tracking accuracy.
Blockwise Temporal-Spatial Pathway Network
Aug 05, 2022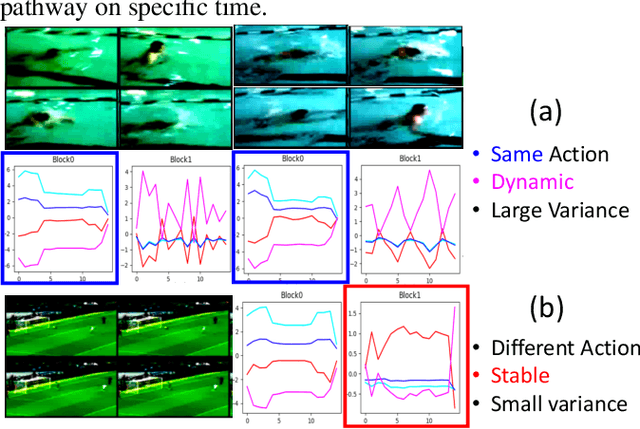
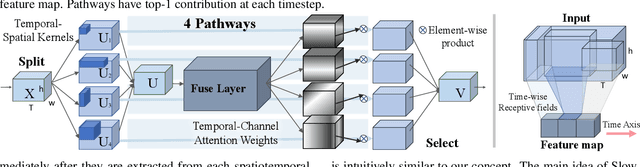
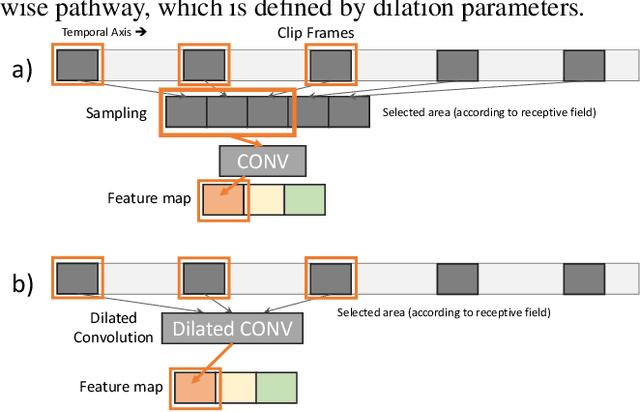
Algorithms for video action recognition should consider not only spatial information but also temporal relations, which remains challenging. We propose a 3D-CNN-based action recognition model, called the blockwise temporal-spatial path-way network (BTSNet), which can adjust the temporal and spatial receptive fields by multiple pathways. We designed a novel model inspired by an adaptive kernel selection-based model, which is an architecture for effective feature encoding that adaptively chooses spatial receptive fields for image recognition. Expanding this approach to the temporal domain, our model extracts temporal and channel-wise attention and fuses information on various candidate operations. For evaluation, we tested our proposed model on UCF-101, HMDB-51, SVW, and Epic-Kitchen datasets and showed that it generalized well without pretraining. BTSNet also provides interpretable visualization based on spatiotemporal channel-wise attention. We confirm that the blockwise temporal-spatial pathway supports a better representation for 3D convolutional blocks based on this visualization.
Sonority Measurement Using System, Source, and Suprasegmental Information
Jul 01, 2021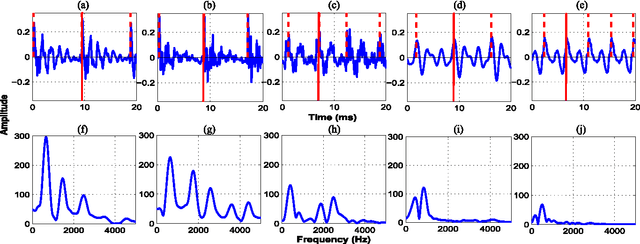
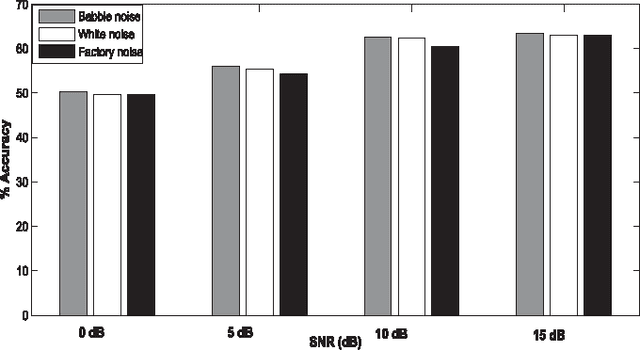
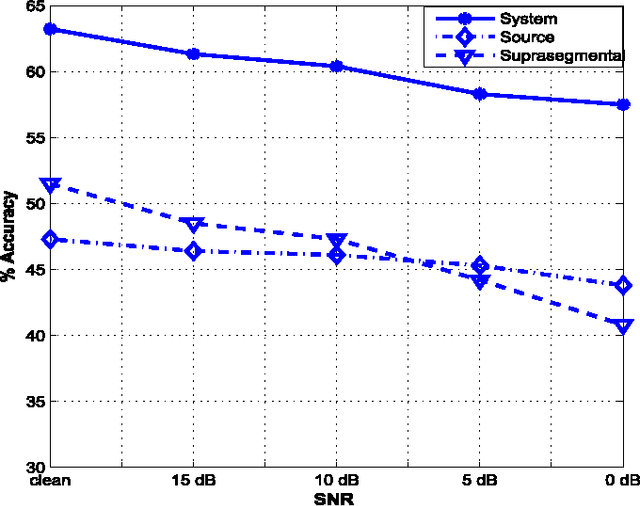
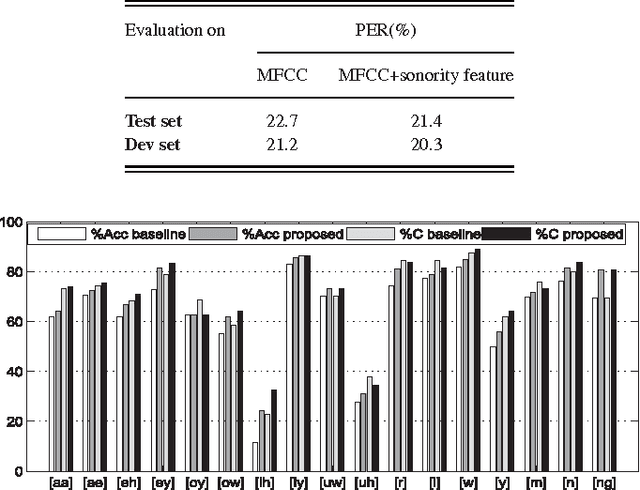
Sonorant sounds are characterized by regions with prominent formant structure, high energy and high degree of periodicity. In this work, the vocal-tract system, excitation source and suprasegmental features derived from the speech signal are analyzed to measure the sonority information present in each of them. Vocal-tract system information is extracted from the Hilbert envelope of numerator of group delay function. It is derived from zero time windowed speech signal that provides better resolution of the formants. A five-dimensional feature set is computed from the estimated formants to measure the prominence of the spectral peaks. A feature representing strength of excitation is derived from the Hilbert envelope of linear prediction residual, which represents the source information. Correlation of speech over ten consecutive pitch periods is used as the suprasegmental feature representing periodicity information. The combination of evidences from the three different aspects of speech provides better discrimination among different sonorant classes, compared to the baseline MFCC features. The usefulness of the proposed sonority feature is demonstrated in the tasks of phoneme recognition and sonorant classification.