 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CM-MLP: Cascade Multi-scale MLP with Axial Context Relation Encoder for Edge Segmentation of Medical Image
Aug 23, 2022
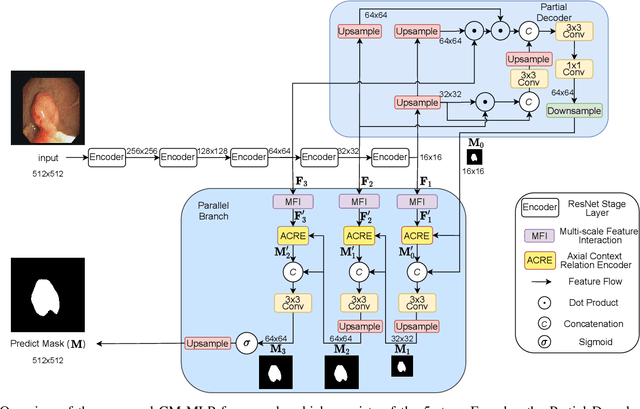
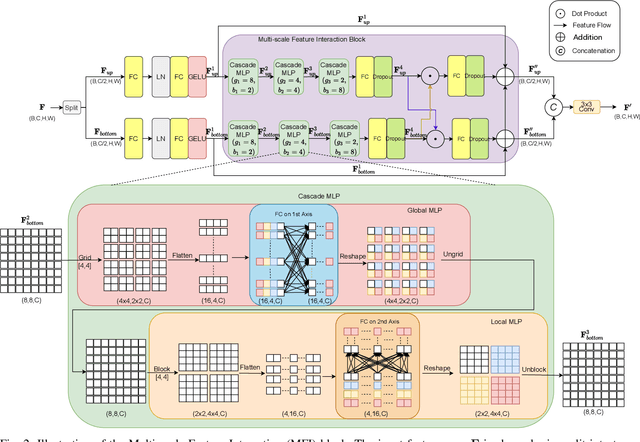
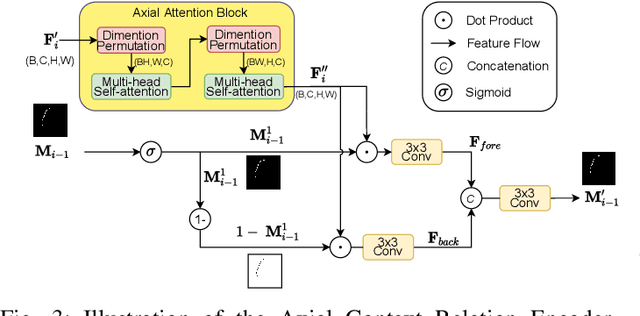
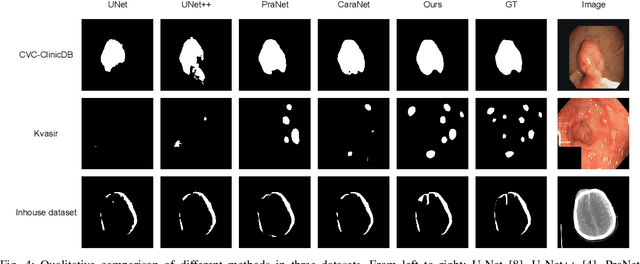
The convolutional-based methods provide good segmentation performance in the medical image segmentation task. However, those methods have the following challenges when dealing with the edges of the medical images: (1) Previous convolutional-based methods do not focus on the boundary relationship between foreground and background around the segmentation edge, which leads to the degradation of segmentation performance when the edge changes complexly. (2) The inductive bias of the convolutional layer cannot be adapted to complex edge changes and the aggregation of multiple-segmented areas, resulting in its performance improvement mostly limited to segmenting the body of segmented areas instead of the edge. To address these challenges, we propose the CM-MLP framework on MFI (Multi-scale Feature Interaction) block and ACRE (Axial Context Relation Encoder) block for accurate segmentation of the edge of medical image. In the MFI block, we propose the cascade multi-scale MLP (Cascade MLP) to process all local information from the deeper layers of the network simultaneously and utilize a cascade multi-scale mechanism to fuse discrete local information gradually. Then, the ACRE block is used to make the deep supervision focus on exploring the boundary relationship between foreground and background to modify the edge of the medical image. The segmentation accuracy (Dice) of our proposed CM-MLP framework reaches 96.96%, 96.76%, and 82.54% on three benchmark datasets: CVC-ClinicDB dataset, sub-Kvasir dataset, and our in-house dataset, respectively, which significantly outperform the state-of-the-art method. The source code and trained models will be available at https://github.com/ProgrammerHyy/CM-MLP.
Data Valuation for Vertical Federated Learning: An Information-Theoretic Approach
Dec 15, 2021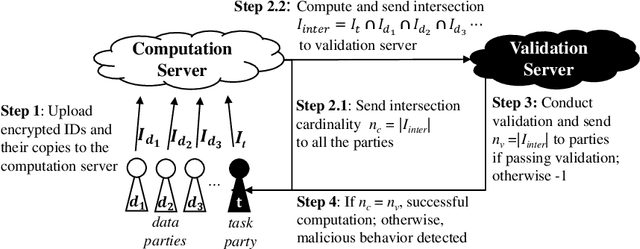
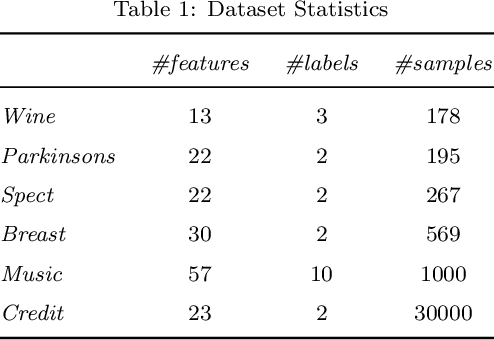
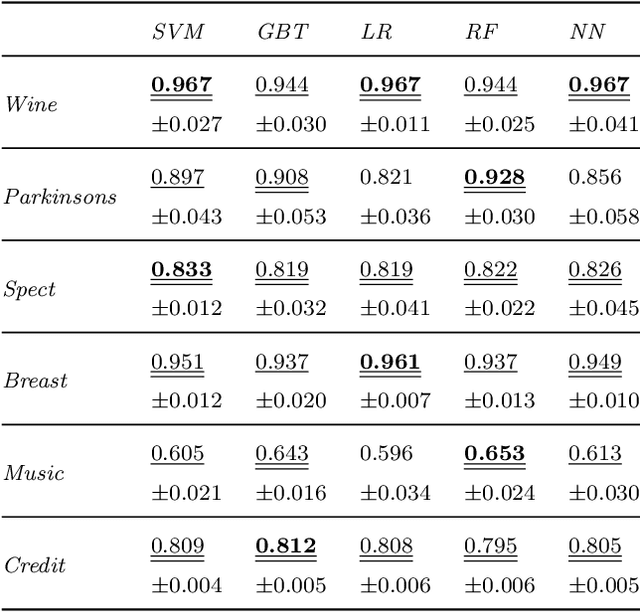
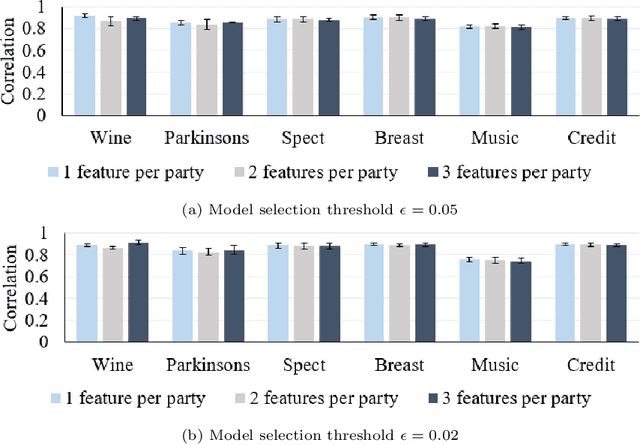
Federated learning (FL) is a promising machine learning paradigm that enables cross-party data collaboration for real-world AI applications in a privacy-preserving and law-regulated way. How to valuate parties' data is a critical but challenging FL issue. In the literature, data valuation either relies on running specific models for a given task or is just task irrelevant; however, it is often requisite for party selection given a specific task when FL models have not been determined yet. This work thus fills the gap and proposes \emph{FedValue}, to our best knowledge, the first privacy-preserving, task-specific but model-free data valuation method for vertical FL tasks. Specifically, FedValue incorporates a novel information-theoretic metric termed Shapley-CMI to assess data values of multiple parties from a game-theoretic perspective. Moreover, a novel server-aided federated computation mechanism is designed to compute Shapley-CMI and meanwhile protects each party from data leakage. We also propose several techniques to accelerate Shapley-CMI computation in practice. Extensive experiments on six open datasets validate the effectiveness and efficiency of FedValue for data valuation of vertical FL tasks. In particular, Shapley-CMI as a model-free metric performs comparably with the measures that depend on running an ensemble of well-performing models.
Tree species classification from hyperspectral data using graph-regularized neural networks
Aug 18, 2022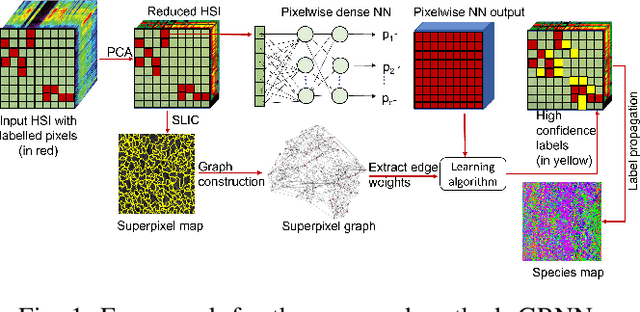
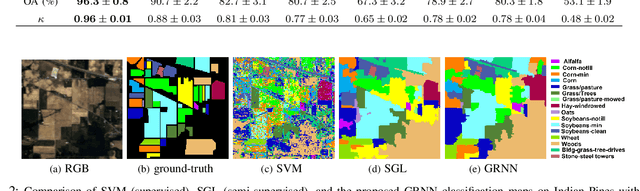
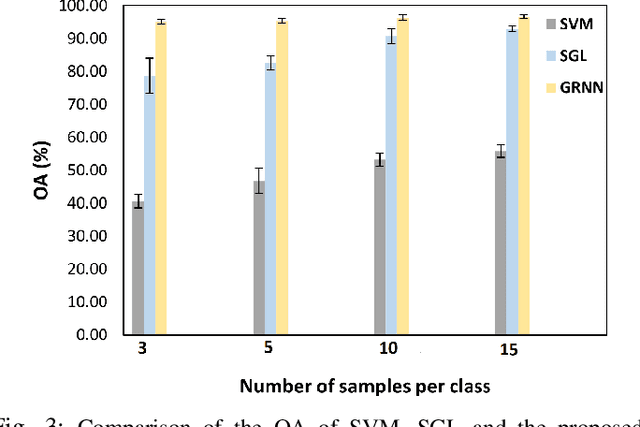
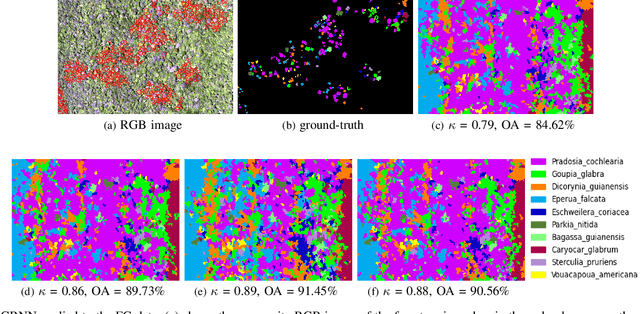
Manual labeling of tree species remains a challenging task, especially in tropical regions, owing to inaccessibility and labor-intensive ground-based surveys. Hyperspectral images (HSIs), through their narrow and contiguous bands, can assist in distinguishing tree species based on their spectral properties. Therefore, automated classification algorithms on HSI images can help augment the limited labeled information and generate a real-time classification map for various tree species. Achieving high classification accuracy with a limited amount of labeled information in an image is one of the key challenges that researchers have started addressing in recent years. We propose a novel graph-regularized neural network (GRNN) algorithm that encompasses the superpixel-based segmentation for graph construction, a pixel-wise neural network classifier, and the label propagation technique to generate an accurate classification map. GRNN outperforms several state-of-the-art techniques not only for the standard Indian Pines HSI but also achieves a high classification accuracy (approx. 92%) on a new HSI data set collected over the forests of French Guiana (FG) even when less than 1% of the pixels are labeled. We show that GRNN is not only competitive with the state-of-the-art semi-supervised methods, but also exhibits lower variance in accuracy for different number of training samples and over different independent random sampling of the labeled pixels for training.
Improving Non-native Word-level Pronunciation Scoring with Phone-level Mixup Data Augmentation and Multi-source Information
Mar 01, 2022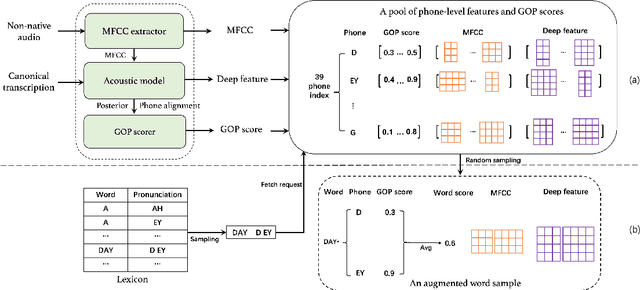

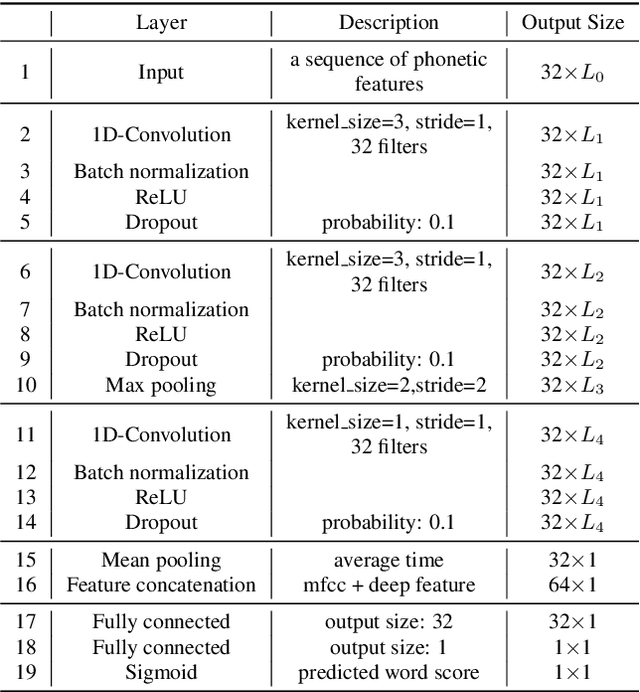
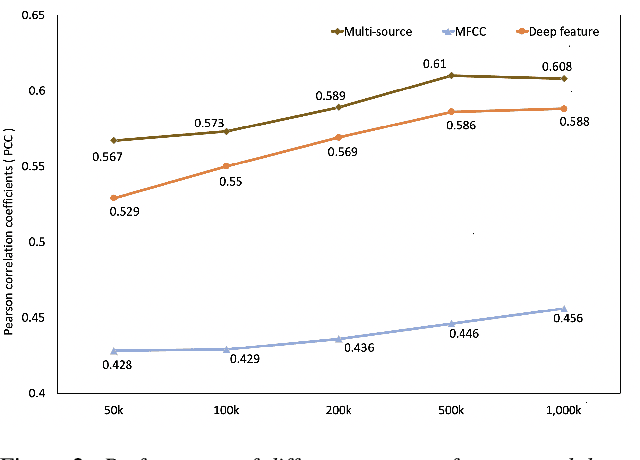
Deep learning-based pronunciation scoring models highly rely on the availability of the annotated non-native data, which is costly and has scalability issues. To deal with the data scarcity problem, data augmentation is commonly used for model pretraining. In this paper, we propose a phone-level mixup, a simple yet effective data augmentation method, to improve the performance of word-level pronunciation scoring. Specifically, given a phoneme sequence from lexicon, the artificial augmented word sample can be generated by randomly sampling from the corresponding phone-level features in training data, while the word score is the average of their GOP scores. Benefit from the arbitrary phone-level combination, the mixup is able to generate any word with various pronunciation scores. Moreover, we utilize multi-source information (e.g., MFCC and deep features) to further improve the scoring system performance. The experiments conducted on the Speechocean762 show that the proposed system outperforms the baseline by adding the mixup data for pretraining, with Pearson correlation coefficients (PCC) increasing from 0.567 to 0.61. The results also indicate that proposed method achieves similar performance by using 1/10 unlabeled data of baseline. In addition, the experimental results also demonstrate the efficiency of our proposed multi-source approach.
Information Harvesting for Far-Field Wireless Power Transfer
May 26, 2021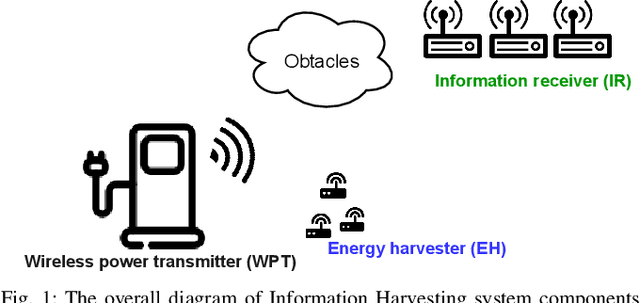
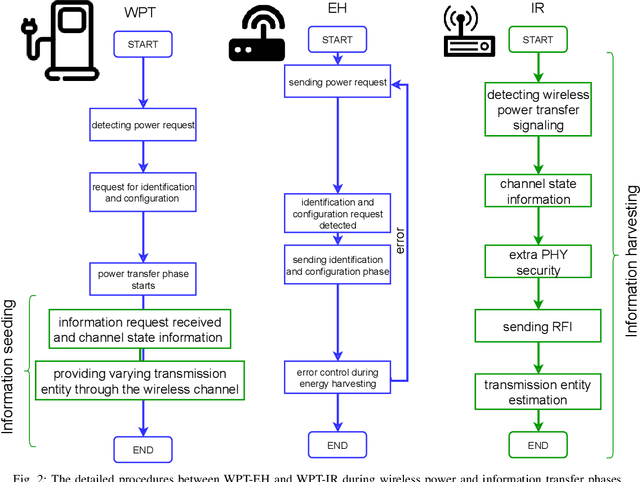
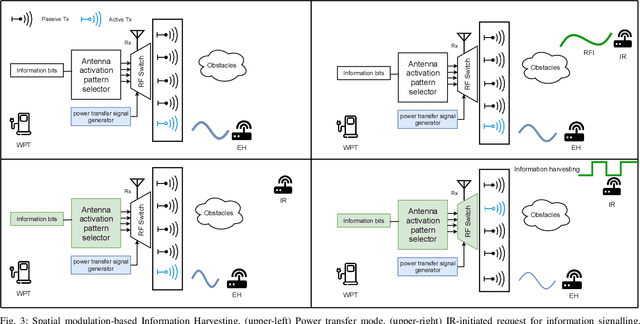
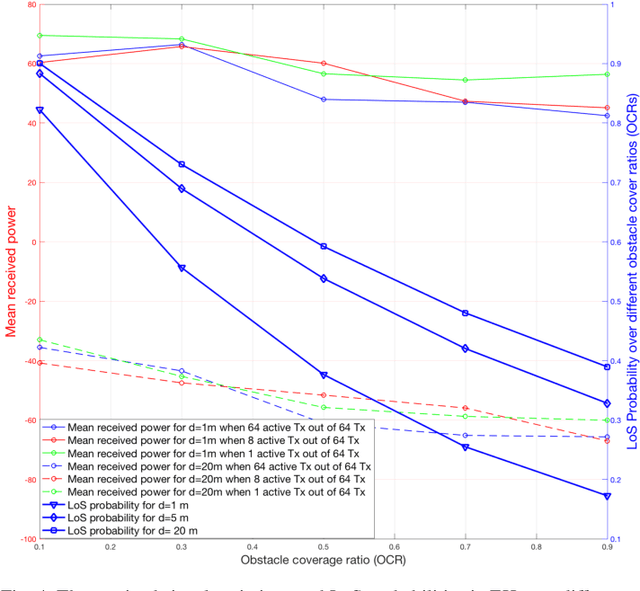
Considering ubiquitous connectivity and advanced information processing capability, huge amount of low-power IoT devices are deployed nowadays and the maintenance of those devices which includes firmware/software updates and recharging the units has become a bottleneck for IoT systems. For addressing limited battery constraints, wireless power transfer is a promising approach such that it does not require any physical link between energy harvester and power transfer. Furthermore, combining wireless power transfer with information transmission has become more appealing. In the systems that apply radio signals the wireless power transfer has become a popular trend to harvest RF-radiated energy from received information signal in IoT devices. For those systems, design frameworks mainly deal with the trade-off between information capacity and energy harvesting efficiency. Therein various signaling design frameworks have been proposed for different system preferences between power and information. In addition to this, protecting the information part from potential eavesdropping activity in a service area introduces security considerations for those systems. In this paper, we propose a novel concept, Information Harvesting, for wireless power transfer systems. It introduces a novel protocol design from opposite perspective compared to the existing studies. Particularly, Information Harvesting aims to transmit information through existing wireless power transfer mechanism without interfering/interrupting power transfer.
Hierarchical Interdisciplinary Topic Detection Model for Research Proposal Classification
Sep 16, 2022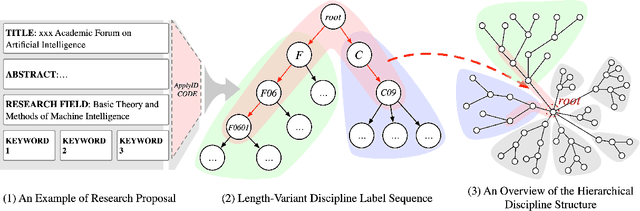
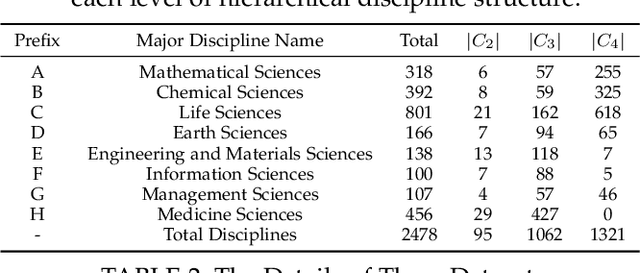
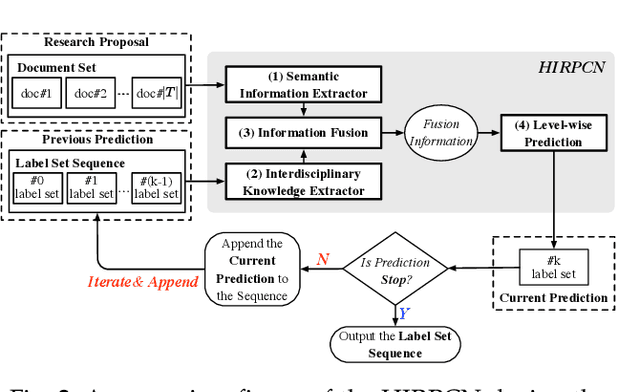
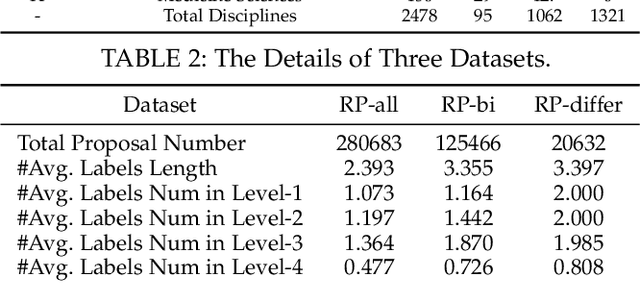
The peer merit review of research proposals has been the major mechanism for deciding grant awards. However, research proposals have become increasingly interdisciplinary. It has been a longstanding challenge to assign interdisciplinary proposals to appropriate reviewers, so proposals are fairly evaluated. One of the critical steps in reviewer assignment is to generate accurate interdisciplinary topic labels for proposal-reviewer matching. Existing systems mainly collect topic labels manually generated by principal investigators. However, such human-reported labels can be non-accurate, incomplete, labor intensive, and time costly. What role can AI play in developing a fair and precise proposal reviewer assignment system? In this study, we collaborate with the National Science Foundation of China to address the task of automated interdisciplinary topic path detection. For this purpose, we develop a deep Hierarchical Interdisciplinary Research Proposal Classification Network (HIRPCN). Specifically, we first propose a hierarchical transformer to extract the textual semantic information of proposals. We then design an interdisciplinary graph and leverage GNNs for learning representations of each discipline in order to extract interdisciplinary knowledge. After extracting the semantic and interdisciplinary knowledge, we design a level-wise prediction component to fuse the two types of knowledge representations and detect interdisciplinary topic paths for each proposal. We conduct extensive experiments and expert evaluations on three real-world datasets to demonstrate the effectiveness of our proposed model.
Spatial Temporal Graph Attention Network for Skeleton-Based Action Recognition
Aug 18, 2022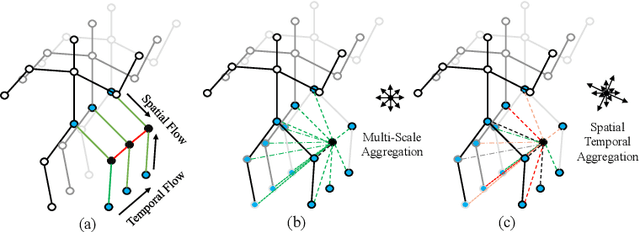
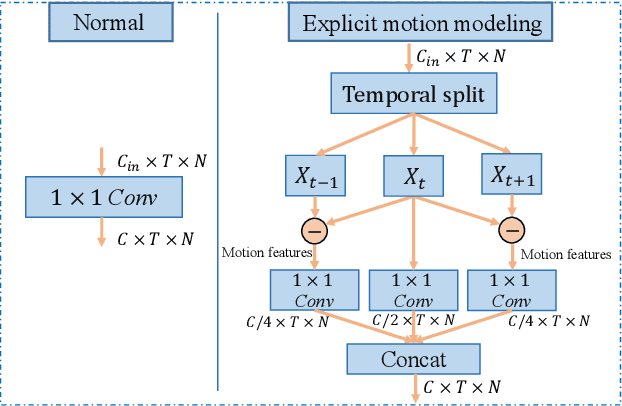
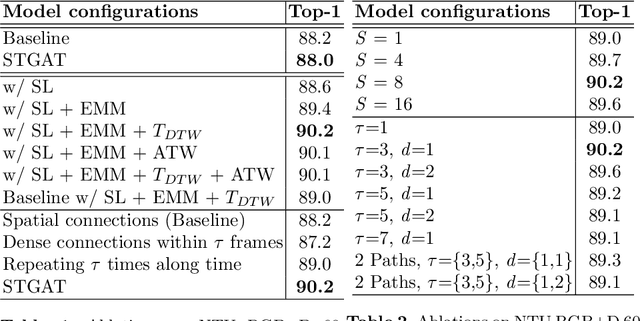
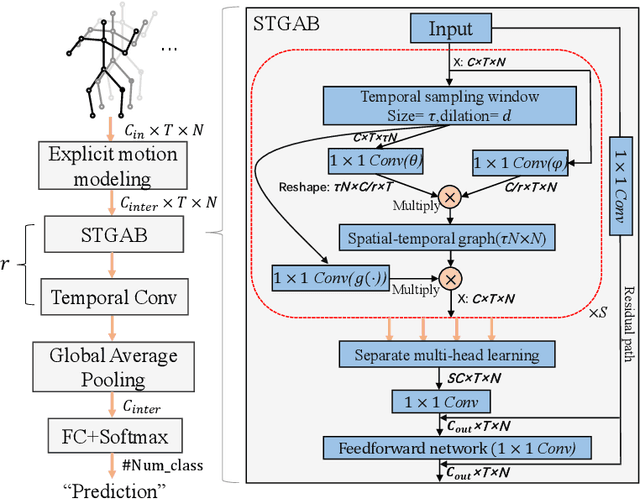
It's common for current methods in skeleton-based action recognition to mainly consider capturing long-term temporal dependencies as skeleton sequences are typically long (>128 frames), which forms a challenging problem for previous approaches. In such conditions, short-term dependencies are few formally considered, which are critical for classifying similar actions. Most current approaches are consisted of interleaving spatial-only modules and temporal-only modules, where direct information flow among joints in adjacent frames are hindered, thus inferior to capture short-term motion and distinguish similar action pairs. To handle this limitation, we propose a general framework, coined as STGAT, to model cross-spacetime information flow. It equips the spatial-only modules with spatial-temporal modeling for regional perception. While STGAT is theoretically effective for spatial-temporal modeling, we propose three simple modules to reduce local spatial-temporal feature redundancy and further release the potential of STGAT, which (1) narrow the scope of self-attention mechanism, (2) dynamically weight joints along temporal dimension, and (3) separate subtle motion from static features, respectively. As a robust feature extractor, STGAT generalizes better upon classifying similar actions than previous methods, witnessed by both qualitative and quantitative results. STGAT achieves state-of-the-art performance on three large-scale datasets: NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400. Code is released.
Exploiting Positional Information for Session-based Recommendation
Jul 09, 2021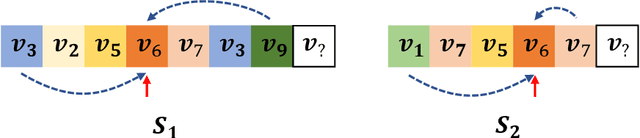
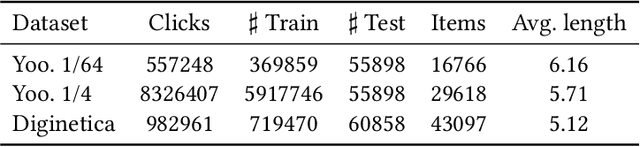
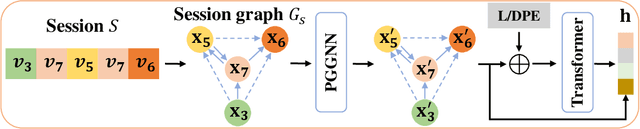
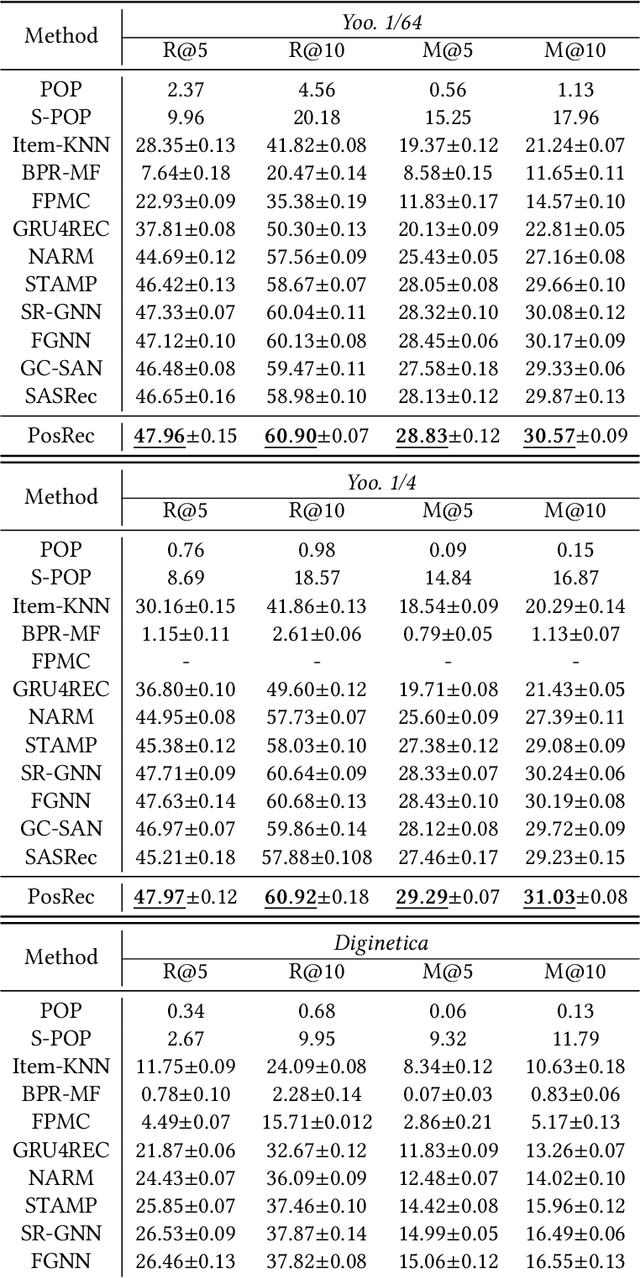
For present e-commerce platforms, session-based recommender systems are developed to predict users' preference for next-item recommendation. Although a session can usually reflect a user's current preference, a local shift of the user's intention within the session may still exist. Specifically, the interactions that take place in the early positions within a session generally indicate the user's initial intention, while later interactions are more likely to represent the latest intention. Such positional information has been rarely considered in existing methods, which restricts their ability to capture the significance of interactions at different positions. To thoroughly exploit the positional information within a session, a theoretical framework is developed in this paper to provide an in-depth analysis of the positional information. We formally define the properties of forward-awareness and backward-awareness to evaluate the ability of positional encoding schemes in capturing the initial and the latest intention. According to our analysis, existing positional encoding schemes are generally forward-aware only, which can hardly represent the dynamics of the intention in a session. To enhance the positional encoding scheme for the session-based recommendation, a dual positional encoding (DPE) is proposed to account for both forward-awareness and backward-awareness. Based on DPE, we propose a novel Positional Recommender (PosRec) model with a well-designed Position-aware Gated Graph Neural Network module to fully exploit the positional information for session-based recommendation tasks. Extensive experiments are conducted on two e-commerce benchmark datasets, Yoochoose and Diginetica and the experimental results show the superiority of the PosRec by comparing it with the state-of-the-art session-based recommender models.
Evaluating and improving social awareness of energy communities through semantic network analysis of online news
Aug 03, 2022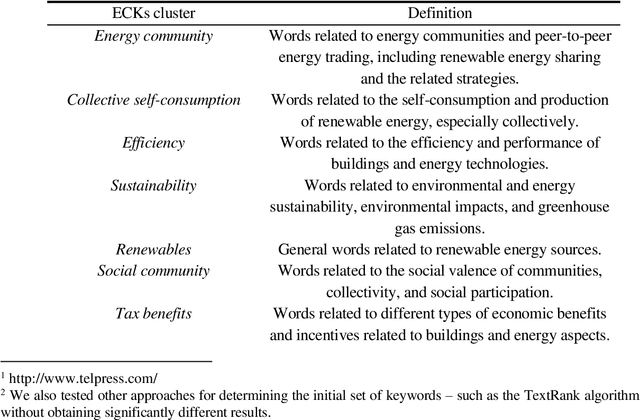
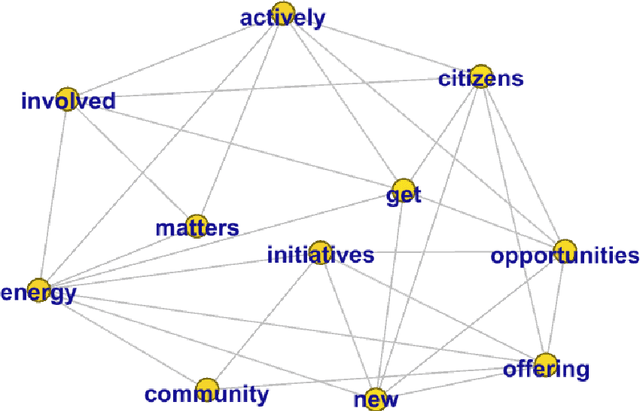
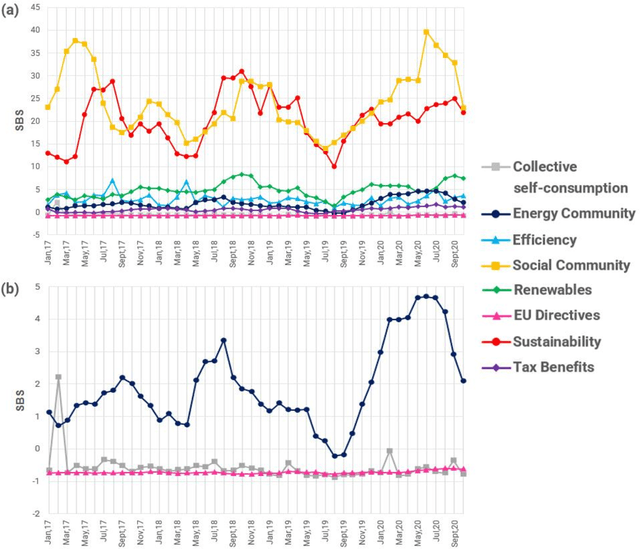
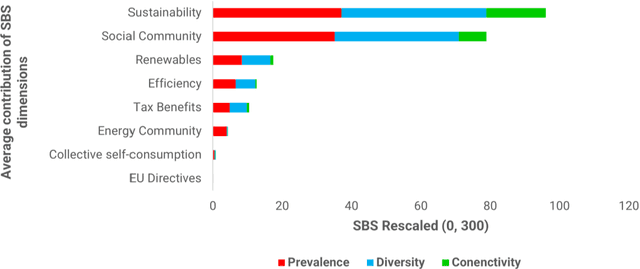
The implementation of energy communities represents a cross-disciplinary phenomenon that has the potential to support the energy transition while fostering citizens' participation throughout the energy system and their exploitation of renewables. An important role is played by online information sources in engaging people in this process and increasing their awareness of associated benefits. In this view, this work analyses online news data on energy communities to understand people's awareness and the media importance of this topic. We use the Semantic Brand Score (SBS) indicator as an innovative measure of semantic importance, combining social network analysis and text mining methods. Results show different importance trends for energy communities and other energy and society-related topics, also allowing the identification of their connections. Our approach gives evidence to information gaps and possible actions that could be taken to promote a low-carbon energy transition.
PSM: A Predictive Safety Model for Body Motion Based On the Spring-Damper Pendulum
Jul 29, 2022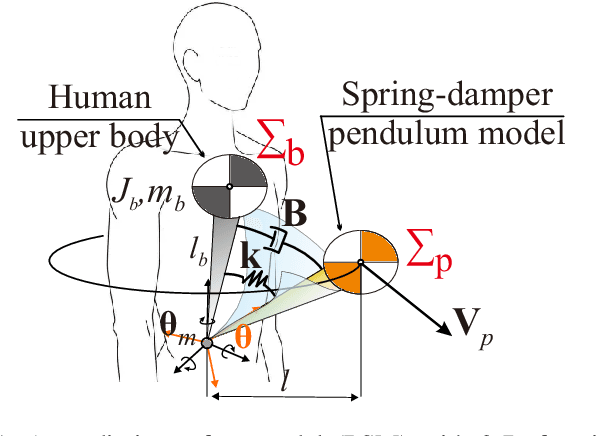
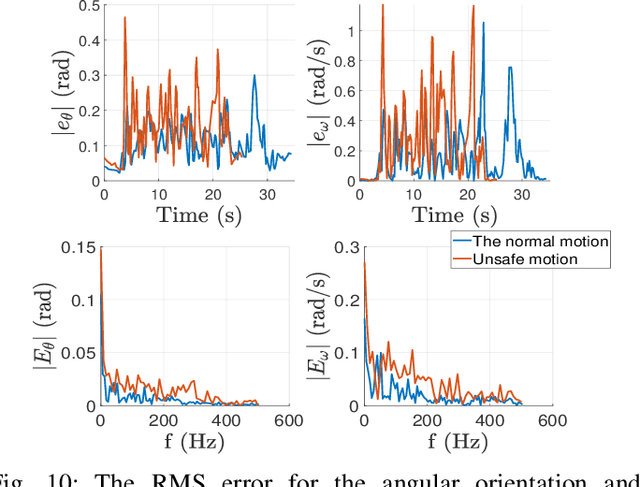
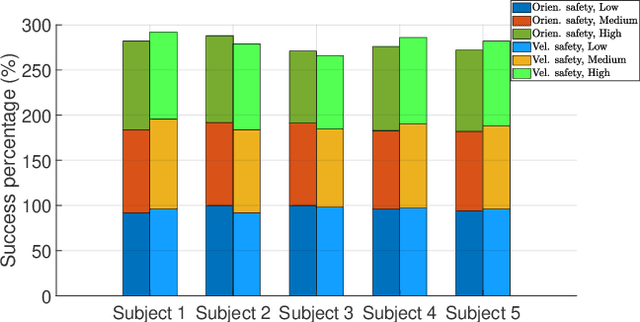
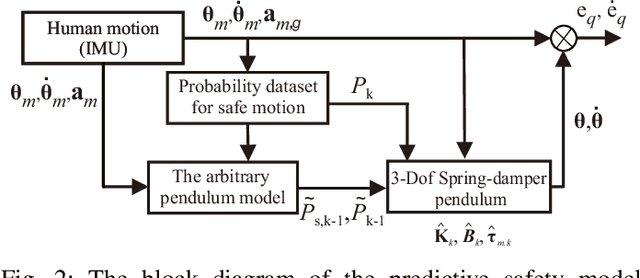
Quantifying the safety of the human body orientation is an important issue in human-robot interaction. Knowing the changing physical constraints on human motion can improve inspection of safe human motions and bring essential information about stability and normality of human body orientations with real-time risk assessment. Also, this information can be used in cooperative robots and monitoring systems to evaluate and interact in the environment more freely. Furthermore, the workspace area can be more deterministic with the known physical characteristics of safety. Based on this motivation, we propose a novel predictive safety model (PSM) that relies on the information of an inertial measurement unit on the human chest. The PSM encompasses a 3-Dofs spring-damper pendulum model that predicts human motion based on a safe motion dataset. The estimated safe orientation of humans is obtained by integrating a safety dataset and an elastic spring-damper model in a way that the proposed approach can realize complex motions at different safety levels. We did experiments in a real-world scenario to verify our novel proposed model. This novel approach can be used in different guidance/assistive robots and health monitoring systems to support and evaluate the human condition, particularly elders.