 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Q-Net: Query-Informed Few-Shot Medical Image Segmentation
Aug 24, 2022
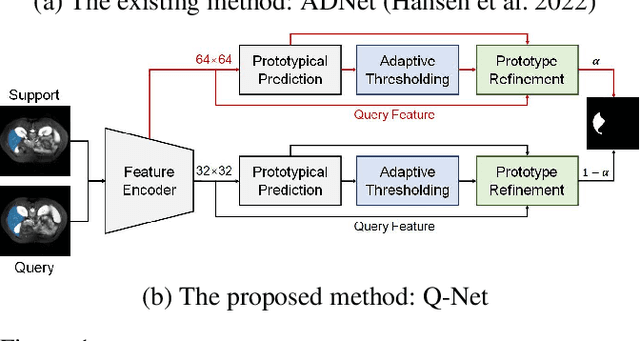
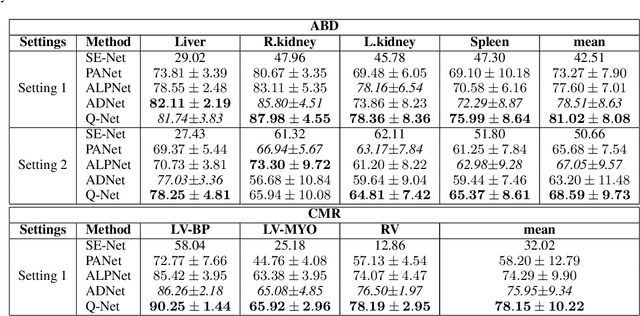
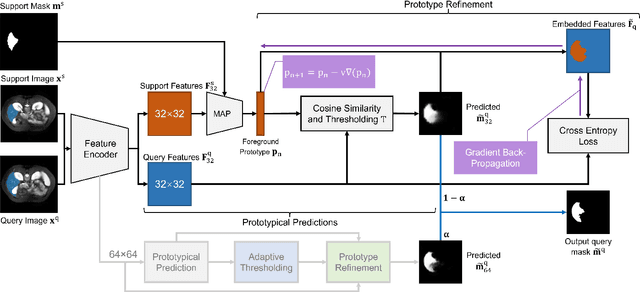
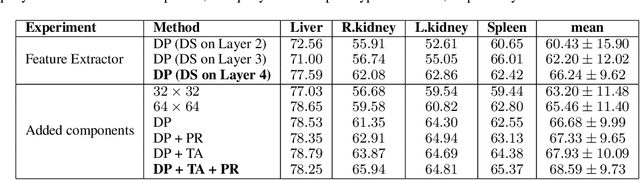
Deep learning has achieved tremendous success in computer vision, while medical image segmentation (MIS) remains a challenge, due to the scarcity of data annotations. Meta-learning techniques for few-shot segmentation (Meta-FSS) have been widely used to tackle this challenge, while they neglect possible distribution shifts between the query image and the support set. In contrast, an experienced clinician can perceive and address such shifts by borrowing information from the query image, then fine-tune or calibrate his (her) prior cognitive model accordingly. Inspired by this, we propose Q-Net, a Query-informed Meta-FSS approach, which mimics in spirit the learning mechanism of an expert clinician. We build Q-Net based on ADNet, a recently proposed anomaly detection-inspired method. Specifically, we add two query-informed computation modules into ADNet, namely a query-informed threshold adaptation module and a query-informed prototype refinement module. Combining them with a dual-path extension of the feature extraction module, Q-Net achieves state-of-the-art performance on two widely used datasets, which are composed of abdominal MR images and cardiac MR images, respectively. Our work sheds light on a novel way to improve Meta-FSS techniques by leveraging query information.
UIT-ViCoV19QA: A Dataset for COVID-19 Community-based Question Answering on Vietnamese Language
Sep 14, 2022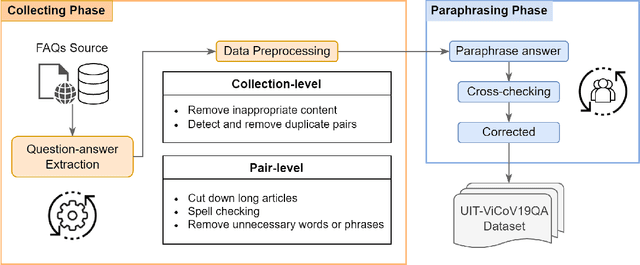
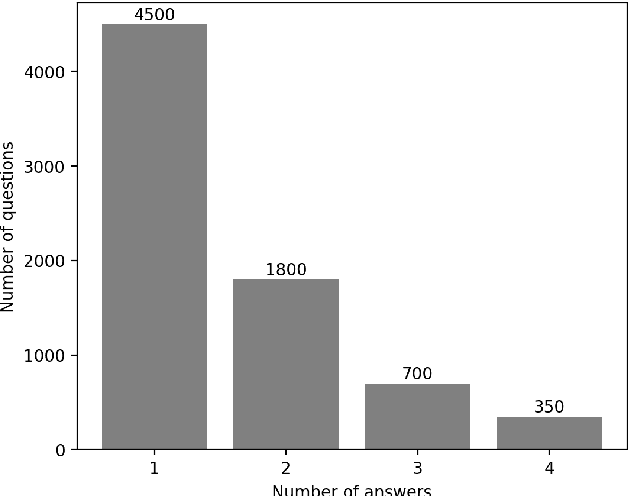
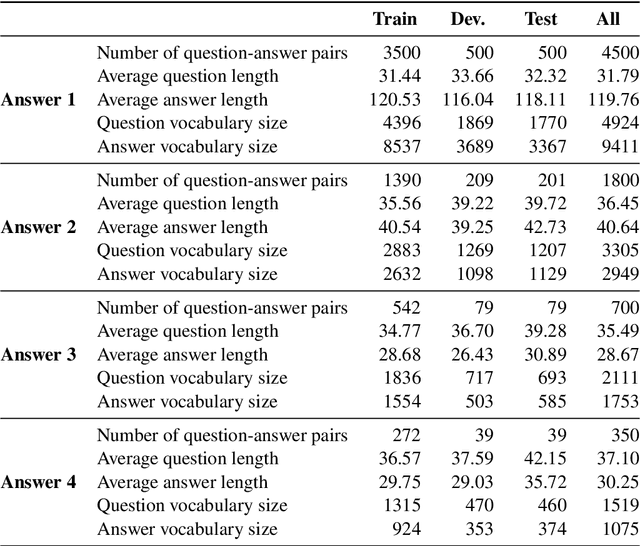
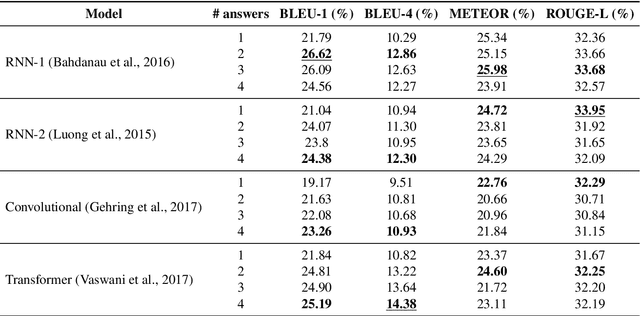
For the last two years, from 2020 to 2021, COVID-19 has broken disease prevention measures in many countries, including Vietnam, and negatively impacted various aspects of human life and the social community. Besides, the misleading information in the community and fake news about the pandemic are also serious situations. Therefore, we present the first Vietnamese community-based question answering dataset for developing question answering systems for COVID-19 called UIT-ViCoV19QA. The dataset comprises 4,500 question-answer pairs collected from trusted medical sources, with at least one answer and at most four unique paraphrased answers per question. Along with the dataset, we set up various deep learning models as baseline to assess the quality of our dataset and initiate the benchmark results for further research through commonly used metrics such as BLEU, METEOR, and ROUGE-L. We also illustrate the positive effects of having multiple paraphrased answers experimented on these models, especially on Transformer - a dominant architecture in the field of study.
Non-Coherent Massive MIMO Integration in Satellite Communication
Sep 20, 2022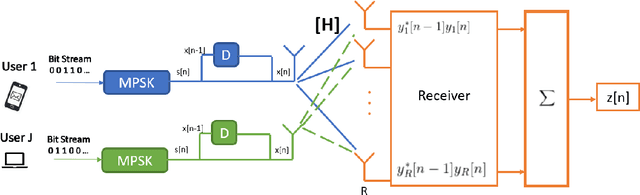
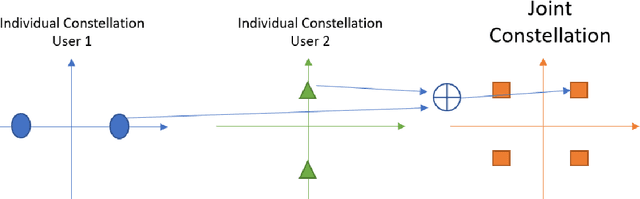
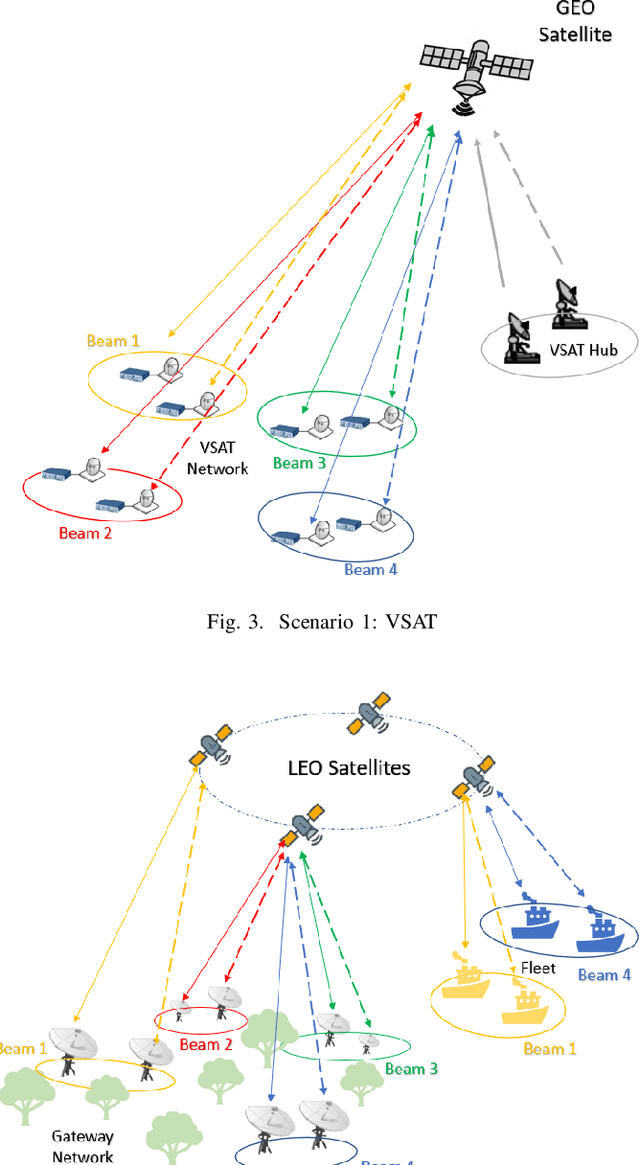

Massive Multiple Input-Multiple Output (mMIMO) technique has been considered an efficient standard to improve the transmission rate significantly for the following wireless communication systems, such as 5G and beyond. However, implementing this technology has been facing a critical issue of acquiring much channel state information. Primarily, this problem becomes more criticising in the integrated satellite and terrestrial networks (3GPP-Release 15) due to the countable high transmission delay. To deal with this challenging problem, the mMIMO-empowered non-coherent technique can be a promising solution. To our best knowledge, this paper is the first work considering employing the non-coherent mMIMO in satellite communication systems. This work aims to analyse the challenges and opportunities emerging with this integration. Moreover, we identified the issues in this conjunction. The preliminary results presented in this work show that the performance measured in bit error rate (BER) and the number of antennas are not far from that required for terrestrial links. Furthermore, thanks to mMIMO in conjunction with the non-coherent approach, we can work in a low signal-to-noise ratio (SNR) regime, which is an excellent advantage for satellite links.
SoK: On the Impossible Security of Very Large Foundation Models
Sep 30, 2022Large machine learning models, or so-called foundation models, aim to serve as base-models for application-oriented machine learning. Although these models showcase impressive performance, they have been empirically found to pose serious security and privacy issues. We may however wonder if this is a limitation of the current models, or if these issues stem from a fundamental intrinsic impossibility of the foundation model learning problem itself. This paper aims to systematize our knowledge supporting the latter. More precisely, we identify several key features of today's foundation model learning problem which, given the current understanding in adversarial machine learning, suggest incompatibility of high accuracy with both security and privacy. We begin by observing that high accuracy seems to require (1) very high-dimensional models and (2) huge amounts of data that can only be procured through user-generated datasets. Moreover, such data is fundamentally heterogeneous, as users generally have very specific (easily identifiable) data-generating habits. More importantly, users' data is filled with highly sensitive information, and maybe heavily polluted by fake users. We then survey lower bounds on accuracy in privacy-preserving and Byzantine-resilient heterogeneous learning that, we argue, constitute a compelling case against the possibility of designing a secure and privacy-preserving high-accuracy foundation model. We further stress that our analysis also applies to other high-stake machine learning applications, including content recommendation. We conclude by calling for measures to prioritize security and privacy, and to slow down the race for ever larger models.
Neighborhood Gradient Clustering: An Efficient Decentralized Learning Method for Non-IID Data Distributions
Sep 30, 2022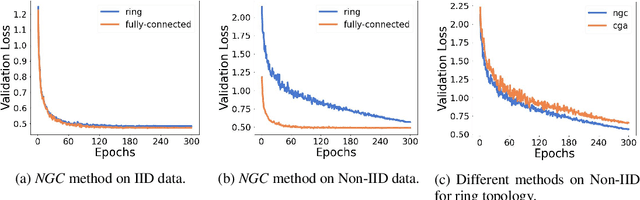
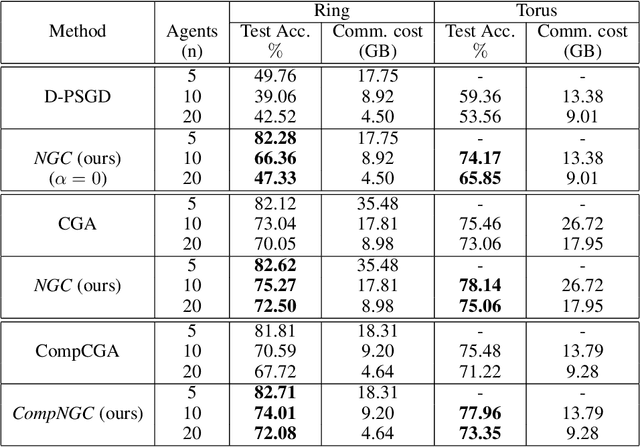
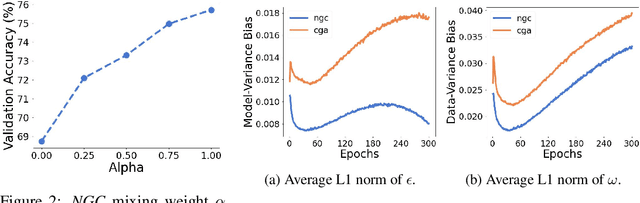
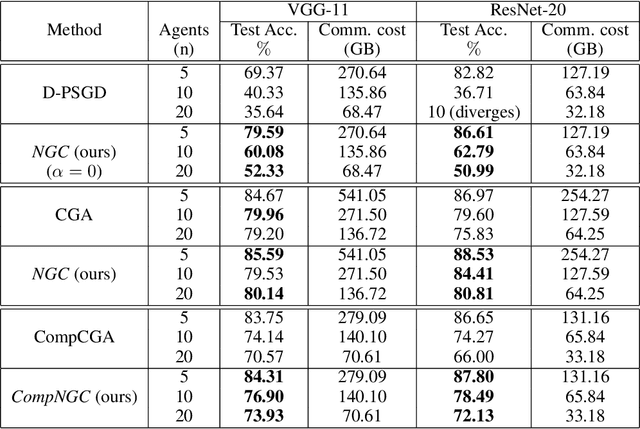
Decentralized learning algorithms enable the training of deep learning models over large distributed datasets generated at different devices and locations, without the need for a central server. In practical scenarios, the distributed datasets can have significantly different data distributions across the agents. The current state-of-the-art decentralized algorithms mostly assume the data distributions to be Independent and Identically Distributed (IID). This paper focuses on improving decentralized learning over non-IID data distributions with minimal compute and memory overheads. We propose Neighborhood Gradient Clustering (NGC), a novel decentralized learning algorithm that modifies the local gradients of each agent using self- and cross-gradient information. In particular, the proposed method replaces the local gradients of the model with the weighted mean of the self-gradients, model-variant cross-gradients (derivatives of the received neighbors' model parameters with respect to the local dataset), and data-variant cross-gradients (derivatives of the local model with respect to its neighbors' datasets). Further, we present CompNGC, a compressed version of NGC that reduces the communication overhead by $32 \times$ by compressing the cross-gradients. We demonstrate the empirical convergence and efficiency of the proposed technique over non-IID data distributions sampled from the CIFAR-10 dataset on various model architectures and graph topologies. Our experiments demonstrate that NGC and CompNGC outperform the existing state-of-the-art (SoTA) decentralized learning algorithm over non-IID data by $1-5\%$ with significantly less compute and memory requirements. Further, we also show that the proposed NGC method outperforms the baseline by $5-40\%$ with no additional communication.
Husformer: A Multi-Modal Transformer for Multi-Modal Human State Recognition
Sep 30, 2022

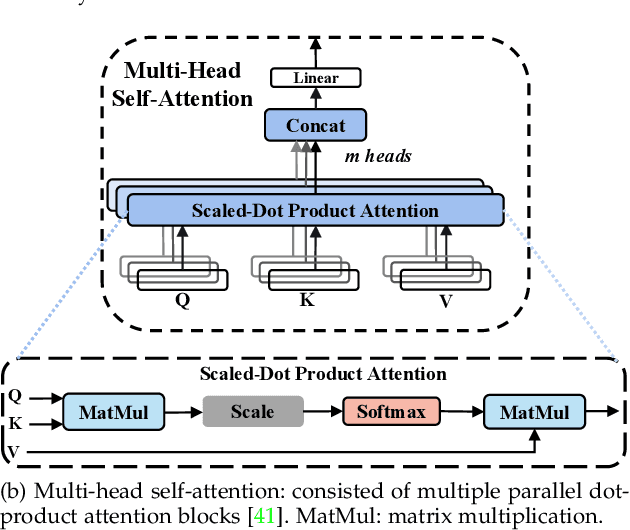

Human state recognition is a critical topic with pervasive and important applications in human-machine systems.Multi-modal fusion, the combination of metrics from multiple data sources, has been shown as a sound method for improving the recognition performance. However, while promising results have been reported by recent multi-modal-based models, they generally fail to leverage the sophisticated fusion strategies that would model sufficient cross-modal interactions when producing the fusion representation; instead, current methods rely on lengthy and inconsistent data preprocessing and feature crafting. To address this limitation, we propose an end-to-end multi-modal transformer framework for multi-modal human state recognition called Husformer.Specifically, we propose to use cross-modal transformers, which inspire one modality to reinforce itself through directly attending to latent relevance revealed in other modalities, to fuse different modalities while ensuring sufficient awareness of the cross-modal interactions introduced. Subsequently, we utilize a self-attention transformer to further prioritize contextual information in the fusion representation. Using two such attention mechanisms enables effective and adaptive adjustments to noise and interruptions in multi-modal signals during the fusion process and in relation to high-level features. Extensive experiments on two human emotion corpora (DEAP and WESAD) and two cognitive workload datasets (MOCAS and CogLoad) demonstrate that in the recognition of human state, our Husformer outperforms both state-of-the-art multi-modal baselines and the use of a single modality by a large margin, especially when dealing with raw multi-modal signals. We also conducted an ablation study to show the benefits of each component in Husformer/
PART: Pre-trained Authorship Representation Transformer
Sep 30, 2022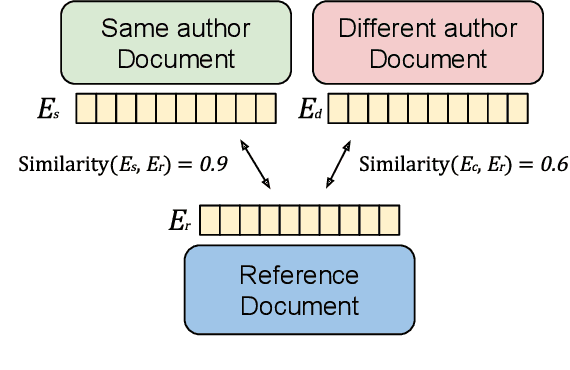
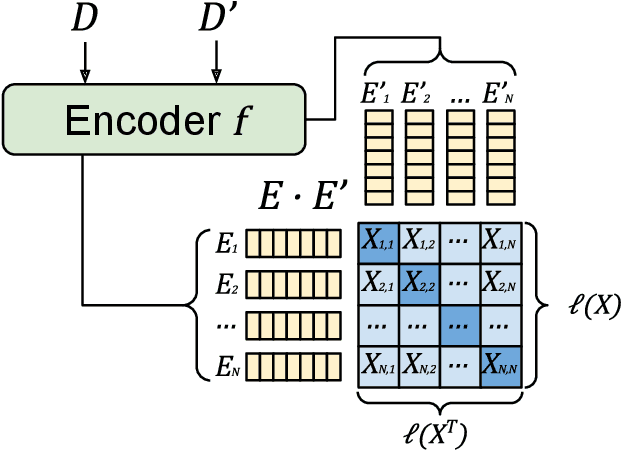
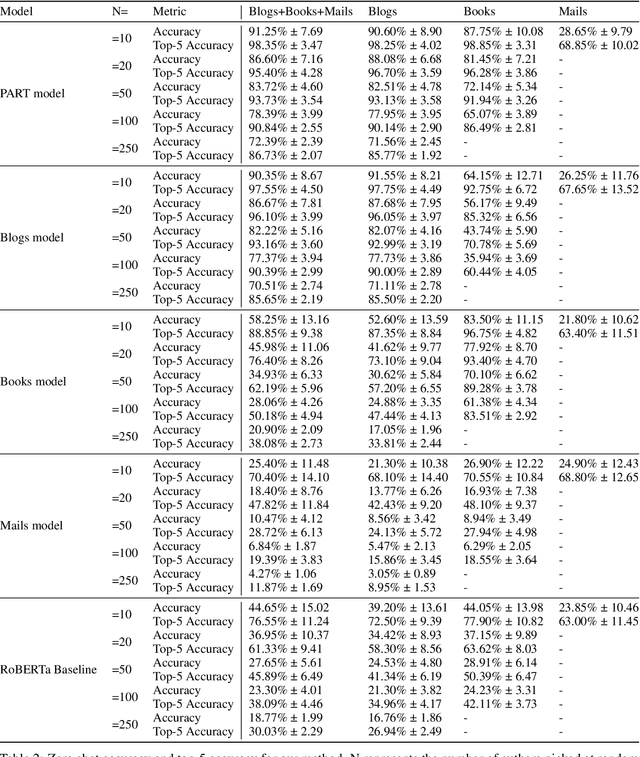
Authors writing documents imprint identifying information within their texts: vocabulary, registry, punctuation, misspellings, or even emoji usage. Finding these details is very relevant to profile authors, relating back to their gender, occupation, age, and so on. But most importantly, repeating writing patterns can help attributing authorship to a text. Previous works use hand-crafted features or classification tasks to train their authorship models, leading to poor performance on out-of-domain authors. A better approach to this task is to learn stylometric representations, but this by itself is an open research challenge. In this paper, we propose PART: a contrastively trained model fit to learn \textbf{authorship embeddings} instead of semantics. By comparing pairs of documents written by the same author, we are able to determine the proprietary of a text by evaluating the cosine similarity of the evaluated documents, a zero-shot generalization to authorship identification. To this end, a pre-trained Transformer with an LSTM head is trained with the contrastive training method. We train our model on a diverse set of authors, from literature, anonymous blog posters and corporate emails; a heterogeneous set with distinct and identifiable writing styles. The model is evaluated on these datasets, achieving zero-shot 72.39\% and 86.73\% accuracy and top-5 accuracy respectively on the joint evaluation dataset when determining authorship from a set of 250 different authors. We qualitatively assess the representations with different data visualizations on the available datasets, profiling features such as book types, gender, age, or occupation of the author.
The Royalflush System for VoxCeleb Speaker Recognition Challenge 2022
Sep 20, 2022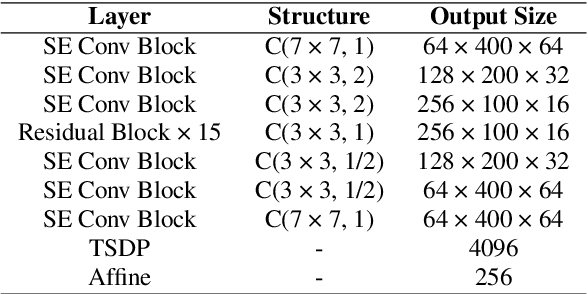
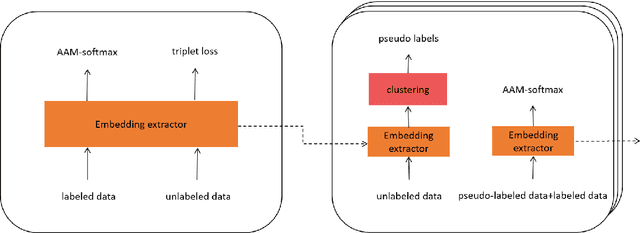
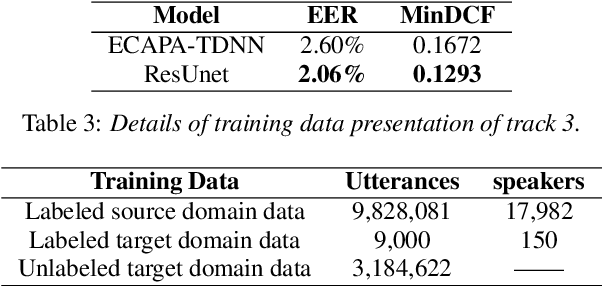

In this technical report, we describe the Royalflush submissions for the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22). Our submissions contain track 1, which is for supervised speaker verification and track 3, which is for semi-supervised speaker verification. For track 1, we develop a powerful U-Net-based speaker embedding extractor with a symmetric architecture. The proposed system achieves 2.06% in EER and 0.1293 in MinDCF on the validation set. Compared with the state-of-the-art ECAPA-TDNN, it obtains a relative improvement of 20.7% in EER and 22.70% in MinDCF. For track 3, we employ the joint training of source domain supervision and target domain self-supervision to get a speaker embedding extractor. The subsequent clustering process can obtain target domain pseudo-speaker labels. We adapt the speaker embedding extractor using all source and target domain data in a supervised manner, where it can fully leverage both domain information. Moreover, clustering and supervised domain adaptation can be repeated until the performance converges on the validation set. Our final submission is a fusion of 10 models and achieves 7.75% EER and 0.3517 MinDCF on the validation set.
Distributed Multi-Robot Obstacle Avoidance via Logarithmic Map-based Deep Reinforcement Learning
Sep 14, 2022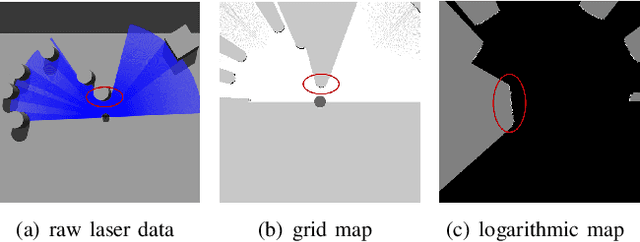

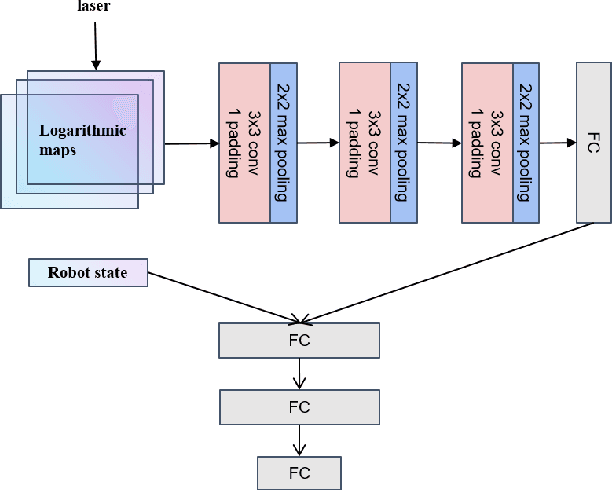
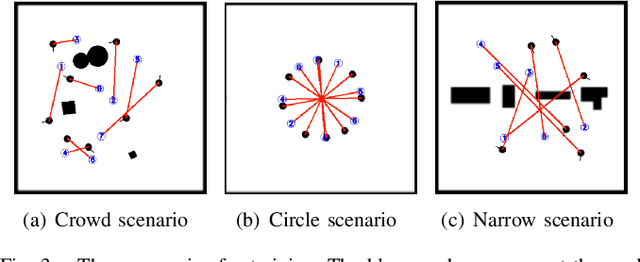
Developing a safe, stable, and efficient obstacle avoidance policy in crowded and narrow scenarios for multiple robots is challenging. Most existing studies either use centralized control or need communication with other robots. In this paper, we propose a novel logarithmic map-based deep reinforcement learning method for obstacle avoidance in complex and communication-free multi-robot scenarios. In particular, our method converts laser information into a logarithmic map. As a step toward improving training speed and generalization performance, our policies will be trained in two specially designed multi-robot scenarios. Compared to other methods, the logarithmic map can represent obstacles more accurately and improve the success rate of obstacle avoidance. We finally evaluate our approach under a variety of simulation and real-world scenarios. The results show that our method provides a more stable and effective navigation solution for robots in complex multi-robot scenarios and pedestrian scenarios. Videos are available at https://youtu.be/r0EsUXe6MZE.
Event-based Image Deblurring with Dynamic Motion Awareness
Aug 24, 2022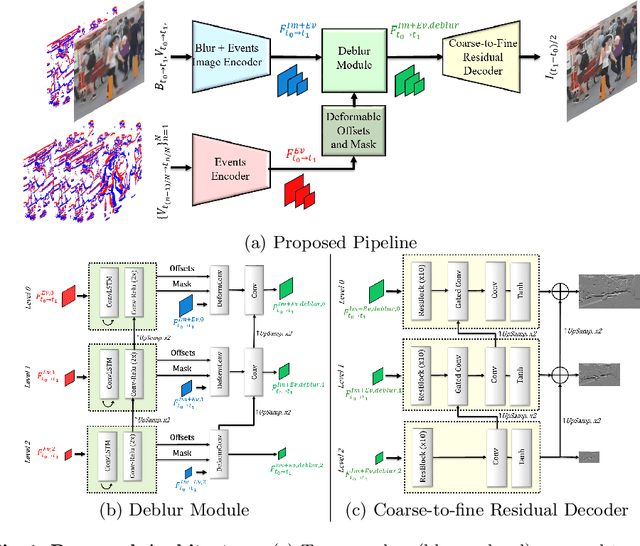

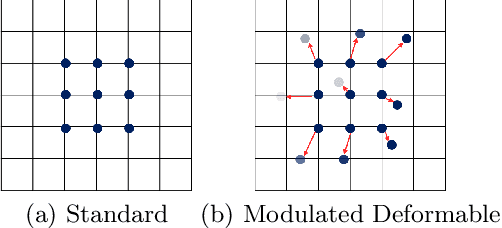
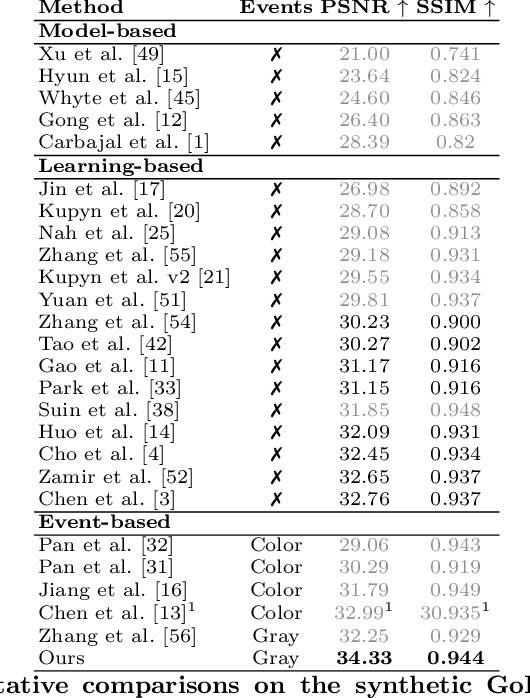
Non-uniform image deblurring is a challenging task due to the lack of temporal and textural information in the blurry image itself. Complementary information from auxiliary sensors such event sensors are being explored to address these limitations. The latter can record changes in a logarithmic intensity asynchronously, called events, with high temporal resolution and high dynamic range. Current event-based deblurring methods combine the blurry image with events to jointly estimate per-pixel motion and the deblur operator. In this paper, we argue that a divide-and-conquer approach is more suitable for this task. To this end, we propose to use modulated deformable convolutions, whose kernel offsets and modulation masks are dynamically estimated from events to encode the motion in the scene, while the deblur operator is learned from the combination of blurry image and corresponding events. Furthermore, we employ a coarse-to-fine multi-scale reconstruction approach to cope with the inherent sparsity of events in low contrast regions. Importantly, we introduce the first dataset containing pairs of real RGB blur images and related events during the exposure time. Our results show better overall robustness when using events, with improvements in PSNR by up to 1.57dB on synthetic data and 1.08 dB on real event data.