 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Recognizing and Extracting Cybersecurtity-relevant Entities from Text
Aug 02, 2022

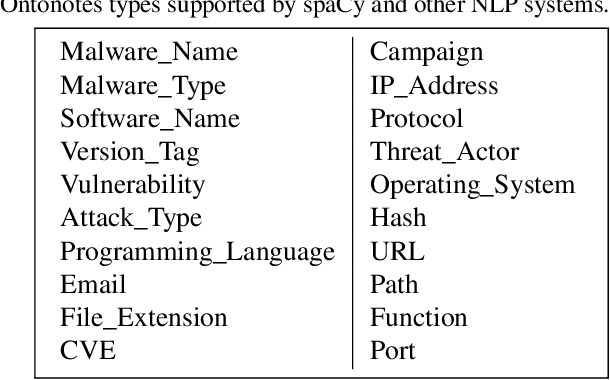
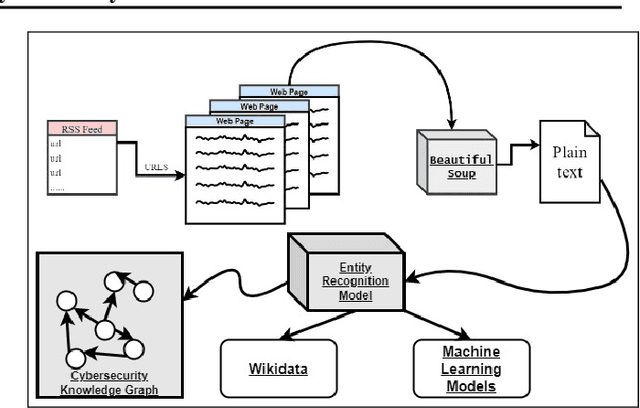
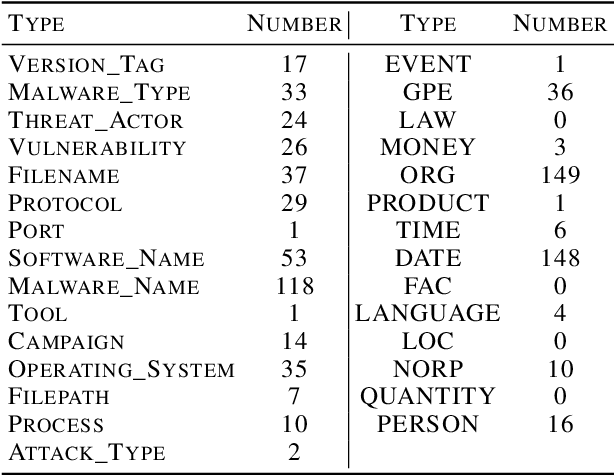
Cyber Threat Intelligence (CTI) is information describing threat vectors, vulnerabilities, and attacks and is often used as training data for AI-based cyber defense systems such as Cybersecurity Knowledge Graphs (CKG). There is a strong need to develop community-accessible datasets to train existing AI-based cybersecurity pipelines to efficiently and accurately extract meaningful insights from CTI. We have created an initial unstructured CTI corpus from a variety of open sources that we are using to train and test cybersecurity entity models using the spaCy framework and exploring self-learning methods to automatically recognize cybersecurity entities. We also describe methods to apply cybersecurity domain entity linking with existing world knowledge from Wikidata. Our future work will survey and test spaCy NLP tools and create methods for continuous integration of new information extracted from text.
Exploiting Positional Information for Session-based Recommendation
Jul 09, 2021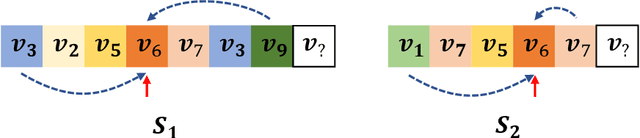
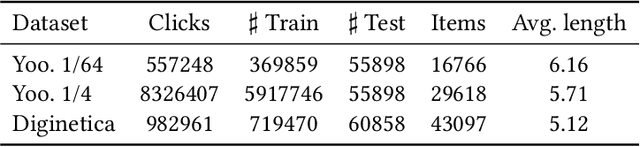
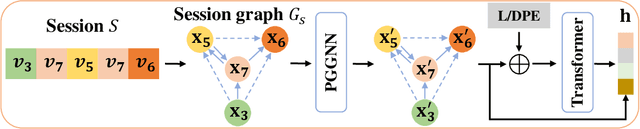
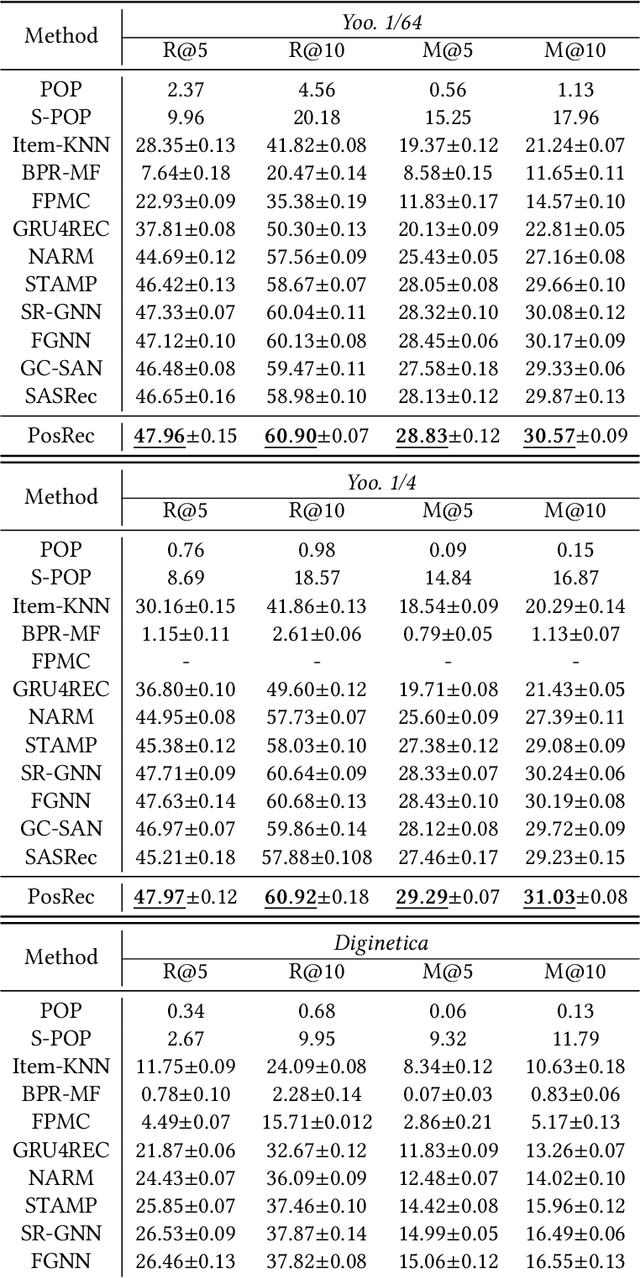
For present e-commerce platforms, session-based recommender systems are developed to predict users' preference for next-item recommendation. Although a session can usually reflect a user's current preference, a local shift of the user's intention within the session may still exist. Specifically, the interactions that take place in the early positions within a session generally indicate the user's initial intention, while later interactions are more likely to represent the latest intention. Such positional information has been rarely considered in existing methods, which restricts their ability to capture the significance of interactions at different positions. To thoroughly exploit the positional information within a session, a theoretical framework is developed in this paper to provide an in-depth analysis of the positional information. We formally define the properties of forward-awareness and backward-awareness to evaluate the ability of positional encoding schemes in capturing the initial and the latest intention. According to our analysis, existing positional encoding schemes are generally forward-aware only, which can hardly represent the dynamics of the intention in a session. To enhance the positional encoding scheme for the session-based recommendation, a dual positional encoding (DPE) is proposed to account for both forward-awareness and backward-awareness. Based on DPE, we propose a novel Positional Recommender (PosRec) model with a well-designed Position-aware Gated Graph Neural Network module to fully exploit the positional information for session-based recommendation tasks. Extensive experiments are conducted on two e-commerce benchmark datasets, Yoochoose and Diginetica and the experimental results show the superiority of the PosRec by comparing it with the state-of-the-art session-based recommender models.
Narcissus: A Practical Clean-Label Backdoor Attack with Limited Information
Apr 11, 2022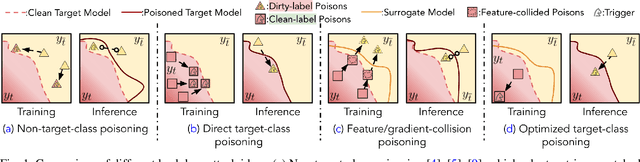

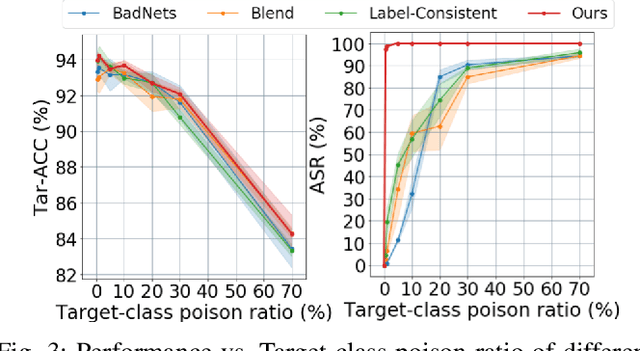
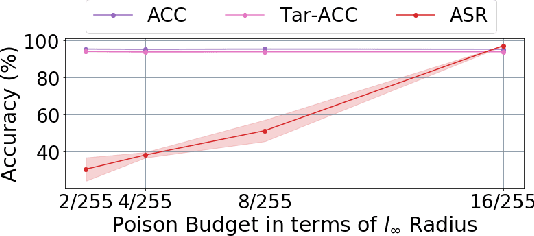
Backdoor attacks insert malicious data into a training set so that, during inference time, it misclassifies inputs that have been patched with a backdoor trigger as the malware specified label. For backdoor attacks to bypass human inspection, it is essential that the injected data appear to be correctly labeled. The attacks with such property are often referred to as "clean-label attacks." Existing clean-label backdoor attacks require knowledge of the entire training set to be effective. Obtaining such knowledge is difficult or impossible because training data are often gathered from multiple sources (e.g., face images from different users). It remains a question whether backdoor attacks still present a real threat. This paper provides an affirmative answer to this question by designing an algorithm to mount clean-label backdoor attacks based only on the knowledge of representative examples from the target class. With poisoning equal to or less than 0.5% of the target-class data and 0.05% of the training set, we can train a model to classify test examples from arbitrary classes into the target class when the examples are patched with a backdoor trigger. Our attack works well across datasets and models, even when the trigger presents in the physical world. We explore the space of defenses and find that, surprisingly, our attack can evade the latest state-of-the-art defenses in their vanilla form, or after a simple twist, we can adapt to the downstream defenses. We study the cause of the intriguing effectiveness and find that because the trigger synthesized by our attack contains features as persistent as the original semantic features of the target class, any attempt to remove such triggers would inevitably hurt the model accuracy first.
Data Valuation for Vertical Federated Learning: An Information-Theoretic Approach
Dec 15, 2021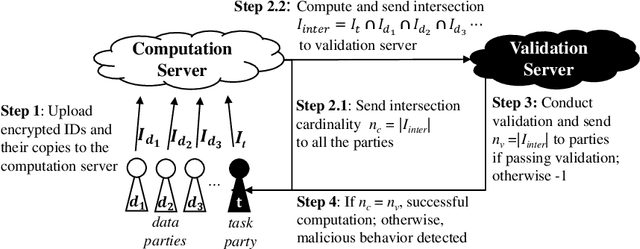
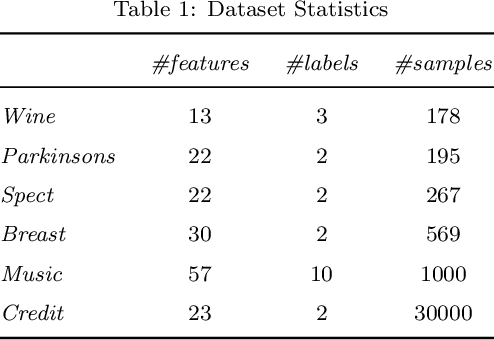
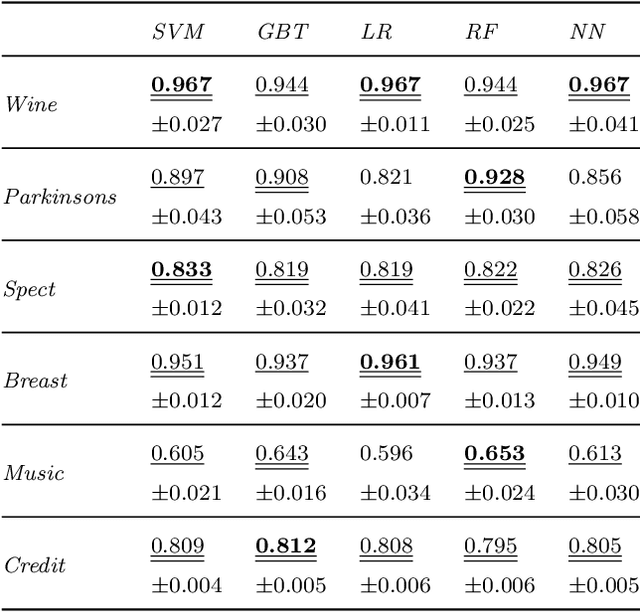
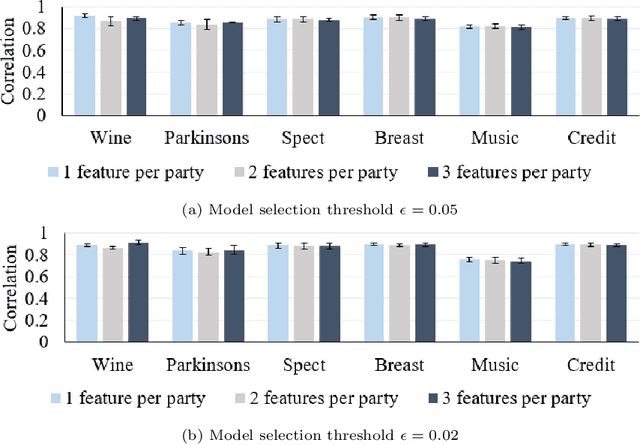
Federated learning (FL) is a promising machine learning paradigm that enables cross-party data collaboration for real-world AI applications in a privacy-preserving and law-regulated way. How to valuate parties' data is a critical but challenging FL issue. In the literature, data valuation either relies on running specific models for a given task or is just task irrelevant; however, it is often requisite for party selection given a specific task when FL models have not been determined yet. This work thus fills the gap and proposes \emph{FedValue}, to our best knowledge, the first privacy-preserving, task-specific but model-free data valuation method for vertical FL tasks. Specifically, FedValue incorporates a novel information-theoretic metric termed Shapley-CMI to assess data values of multiple parties from a game-theoretic perspective. Moreover, a novel server-aided federated computation mechanism is designed to compute Shapley-CMI and meanwhile protects each party from data leakage. We also propose several techniques to accelerate Shapley-CMI computation in practice. Extensive experiments on six open datasets validate the effectiveness and efficiency of FedValue for data valuation of vertical FL tasks. In particular, Shapley-CMI as a model-free metric performs comparably with the measures that depend on running an ensemble of well-performing models.
A Masked Bounding-Box Selection Based ResNet Predictor for Text Rotation Prediction
Sep 06, 2022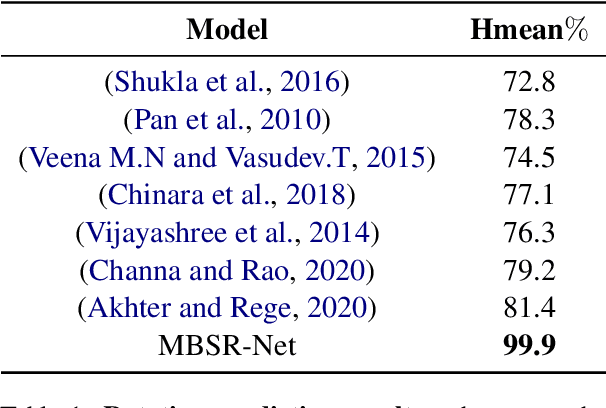
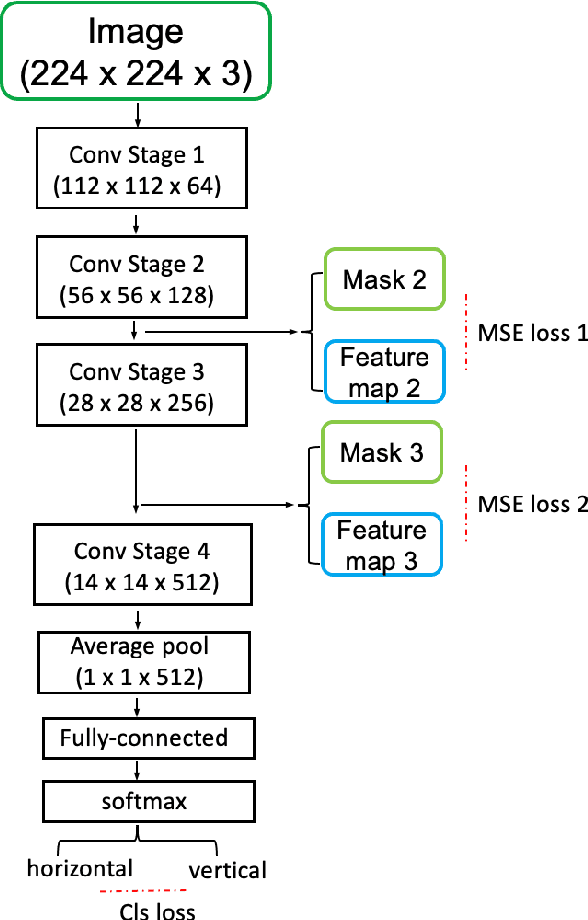
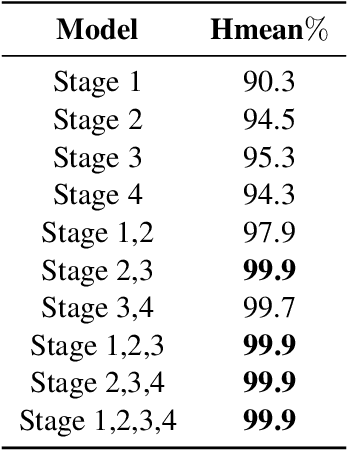

The existing Optical Character Recognition (OCR) systems are capable of recognizing images with horizontal texts. However, when the rotation of the texts increases, it becomes harder to recognizing these texts. The performance of the OCR systems decreases. Thus predicting the rotations of the texts and correcting the images are important. Previous work mainly uses traditional Computer Vision methods like Hough Transform and Deep Learning methods like Convolutional Neural Network. However, all of these methods are prone to background noises commonly existing in general images with texts. To tackle this problem, in this work, we introduce a new masked bounding-box selection method, that incorporating the bounding box information into the system. By training a ResNet predictor to focus on the bounding box as the region of interest (ROI), the predictor learns to overlook the background noises. Evaluations on the text rotation prediction tasks show that our method improves the performance by a large margin.
Dimension of Activity in Random Neural Networks
Aug 07, 2022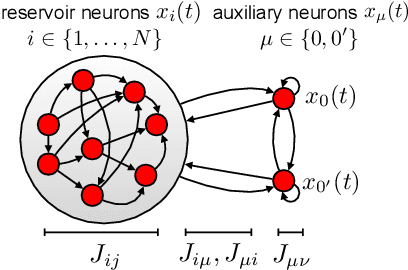
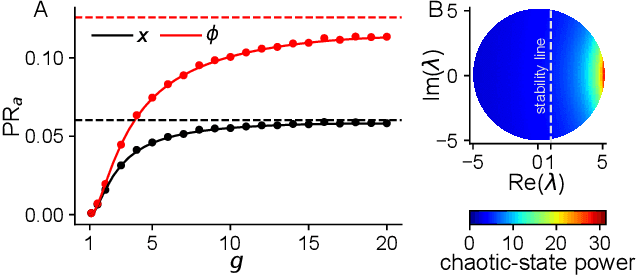
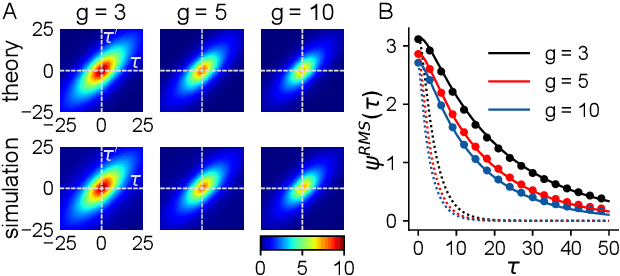
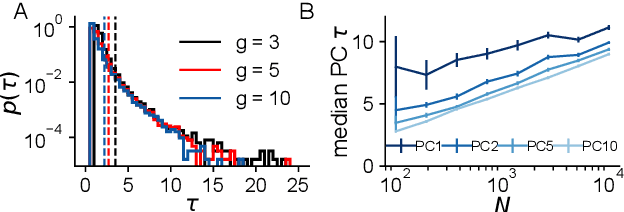
Neural networks are high-dimensional nonlinear dynamical systems that process information through the coordinated activity of many interconnected units. Understanding how biological and machine-learning networks function and learn requires knowledge of the structure of this coordinated activity, information contained in cross-covariances between units. Although dynamical mean field theory (DMFT) has elucidated several features of random neural networks -- in particular, that they can generate chaotic activity -- existing DMFT approaches do not support the calculation of cross-covariances. We solve this longstanding problem by extending the DMFT approach via a two-site cavity method. This reveals, for the first time, several spatial and temporal features of activity coordination, including the effective dimension, defined as the participation ratio of the spectrum of the covariance matrix. Our results provide a general analytical framework for studying the structure of collective activity in random neural networks and, more broadly, in high-dimensional nonlinear dynamical systems with quenched disorder.
Handcrafted Feature Selection Techniques for Pattern Recognition: A Survey
Sep 06, 2022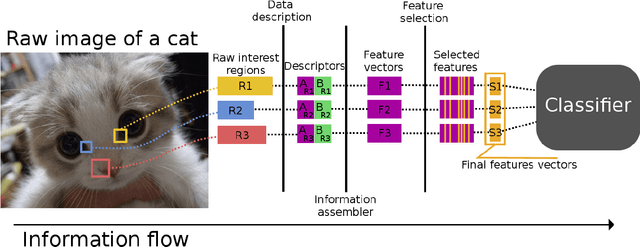



The accuracy of a classifier, when performing Pattern recognition, is mostly tied to the quality and representativeness of the input feature vector. Feature Selection is a process that allows for representing information properly and may increase the accuracy of a classifier. This process is responsible for finding the best possible features, thus allowing us to identify to which class a pattern belongs. Feature selection methods can be categorized as Filters, Wrappers, and Embed. This paper presents a survey on some Filters and Wrapper methods for handcrafted feature selection. Some discussions, with regard to the data structure, processing time, and ability to well represent a feature vector, are also provided in order to explicitly show how appropriate some methods are in order to perform feature selection. Therefore, the presented feature selection methods can be accurate and efficient if applied considering their positives and negatives, finding which one fits best the problem's domain may be the hardest task.
Risk-aware linear bandits with convex loss
Sep 15, 2022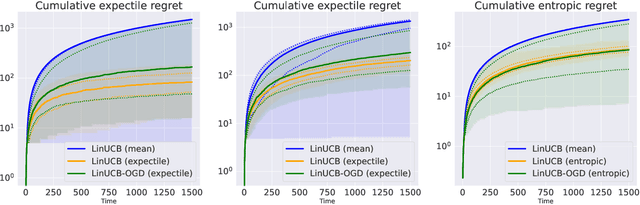

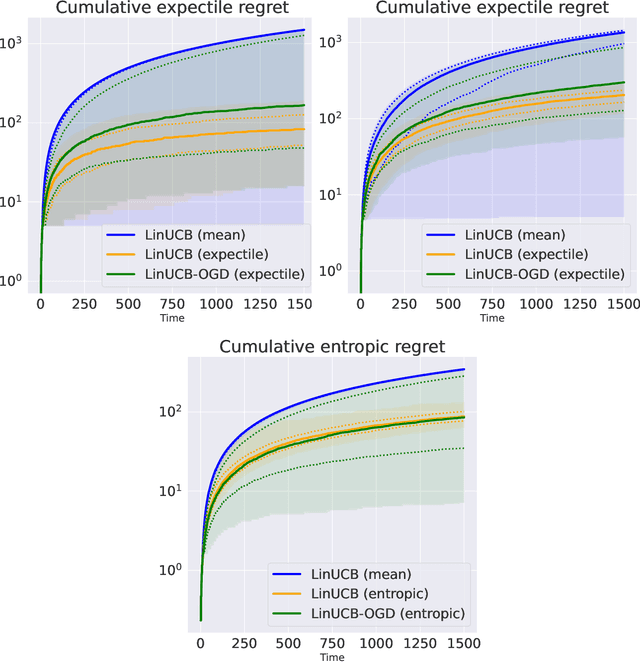

In decision-making problems such as the multi-armed bandit, an agent learns sequentially by optimizing a certain feedback. While the mean reward criterion has been extensively studied, other measures that reflect an aversion to adverse outcomes, such as mean-variance or conditional value-at-risk (CVaR), can be of interest for critical applications (healthcare, agriculture). Algorithms have been proposed for such risk-aware measures under bandit feedback without contextual information. In this work, we study contextual bandits where such risk measures can be elicited as linear functions of the contexts through the minimization of a convex loss. A typical example that fits within this framework is the expectile measure, which is obtained as the solution of an asymmetric least-square problem. Using the method of mixtures for supermartingales, we derive confidence sequences for the estimation of such risk measures. We then propose an optimistic UCB algorithm to learn optimal risk-aware actions, with regret guarantees similar to those of generalized linear bandits. This approach requires solving a convex problem at each round of the algorithm, which we can relax by allowing only approximated solution obtained by online gradient descent, at the cost of slightly higher regret. We conclude by evaluating the resulting algorithms on numerical experiments.
DualCam: A Novel Benchmark Dataset for Fine-grained Real-time Traffic Light Detection
Sep 03, 2022
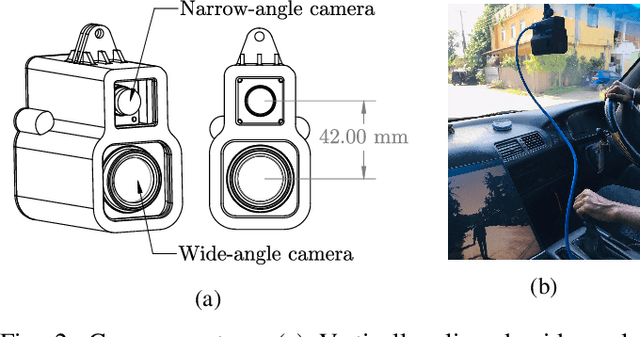

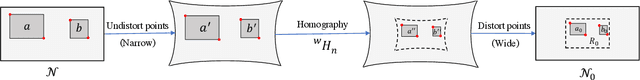
Traffic light detection is essential for self-driving cars to navigate safely in urban areas. Publicly available traffic light datasets are inadequate for the development of algorithms for detecting distant traffic lights that provide important navigation information. We introduce a novel benchmark traffic light dataset captured using a synchronized pair of narrow-angle and wide-angle cameras covering urban and semi-urban roads. We provide 1032 images for training and 813 synchronized image pairs for testing. Additionally, we provide synchronized video pairs for qualitative analysis. The dataset includes images of resolution 1920$\times$1080 covering 10 different classes. Furthermore, we propose a post-processing algorithm for combining outputs from the two cameras. Results show that our technique can strike a balance between speed and accuracy, compared to the conventional approach of using a single camera frame.
Residual Correction in Real-Time Traffic Forecasting
Sep 12, 2022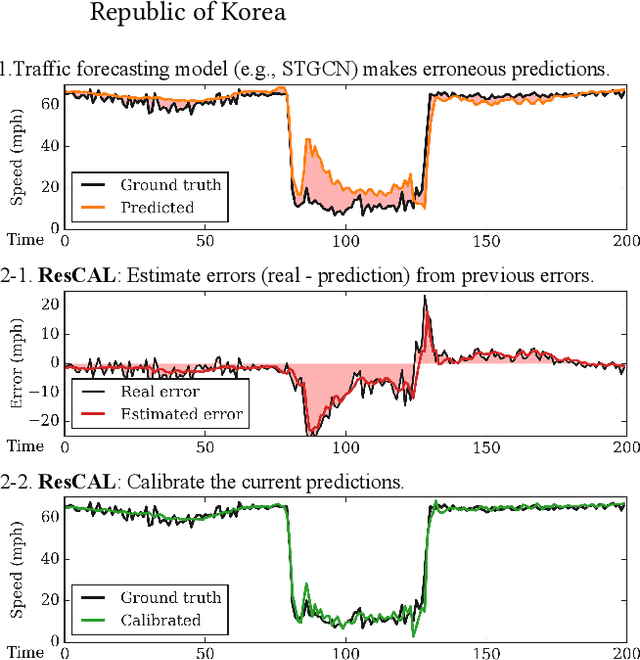
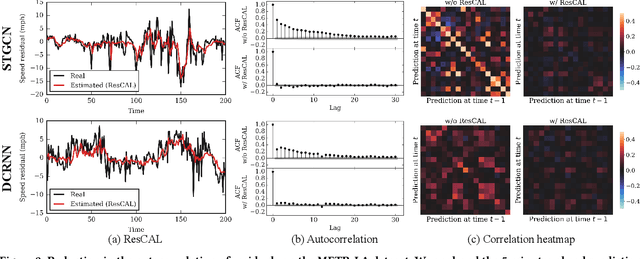
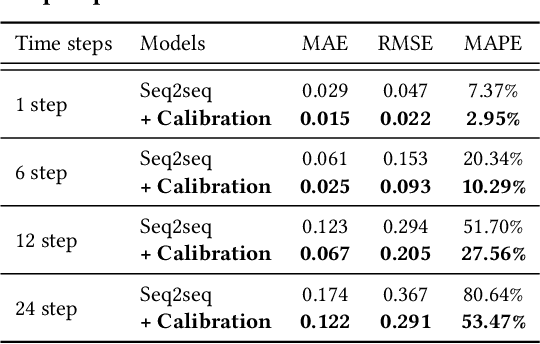
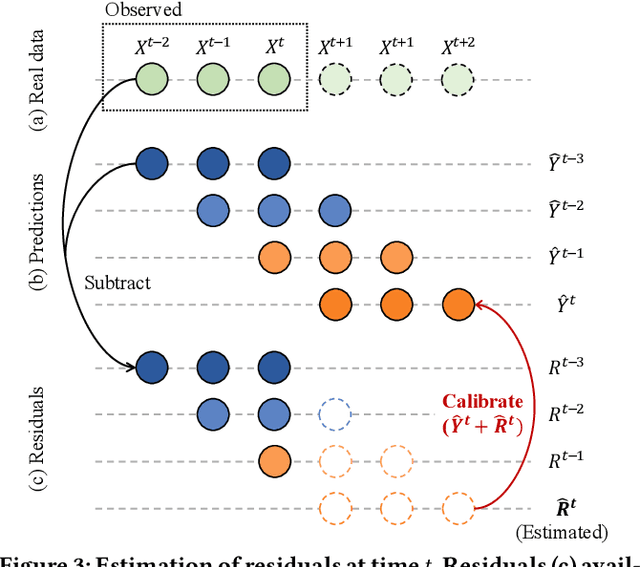
Predicting traffic conditions is tremendously challenging since every road is highly dependent on each other, both spatially and temporally. Recently, to capture this spatial and temporal dependency, specially designed architectures such as graph convolutional networks and temporal convolutional networks have been introduced. While there has been remarkable progress in traffic forecasting, we found that deep-learning-based traffic forecasting models still fail in certain patterns, mainly in event situations (e.g., rapid speed drops). Although it is commonly accepted that these failures are due to unpredictable noise, we found that these failures can be corrected by considering previous failures. Specifically, we observe autocorrelated errors in these failures, which indicates that some predictable information remains. In this study, to capture the correlation of errors, we introduce ResCAL, a residual estimation module for traffic forecasting, as a widely applicable add-on module to existing traffic forecasting models. Our ResCAL calibrates the prediction of the existing models in real time by estimating future errors using previous errors and graph signals. Extensive experiments on METR-LA and PEMS-BAY demonstrate that our ResCAL can correctly capture the correlation of errors and correct the failures of various traffic forecasting models in event situations.