 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RISnet: A Domain-Knowledge Driven Neural Network Architecture for RIS Optimization with Mutual Coupling and Partial CSI
Mar 06, 2024
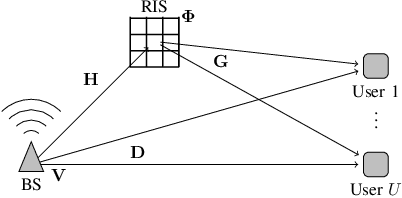
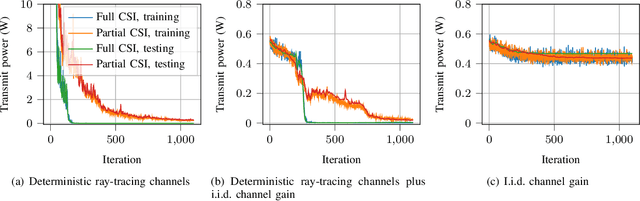
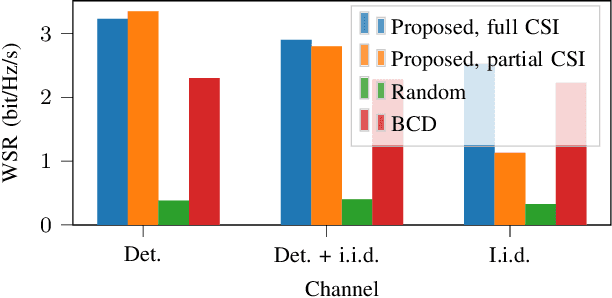
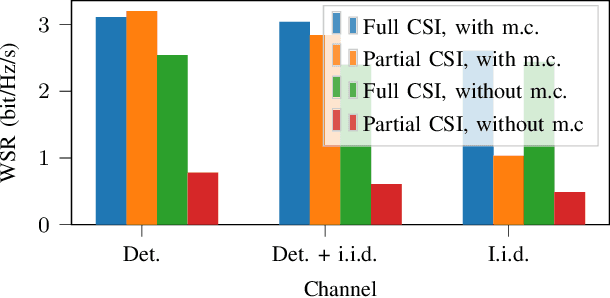
Multiple access techniques are cornerstones of wireless communications. Their performance depends on the channel properties, which can be improved by reconfigurable intelligent surfaces (RISs). In this work, we jointly optimize MA precoding at the base station (BS) and RIS configuration. We tackle difficulties of mutual coupling between RIS elements, scalability to more than 1000 RIS elements, and channel estimation. We first derive an RIS-assisted channel model considering mutual coupling, then propose an unsupervised machine learning (ML) approach to optimize the RIS. In particular, we design a dedicated neural network (NN) architecture RISnet with good scalability and desired symmetry. Moreover, we combine ML-enabled RIS configuration and analytical precoding at BS since there exist analytical precoding schemes. Furthermore, we propose another variant of RISnet, which requires the channel state information (CSI) of a small portion of RIS elements (in this work, 16 out of 1296 elements) if the channel comprises a few specular propagation paths. More generally, this work is an early contribution to combine ML technique and domain knowledge in communication for NN architecture design. Compared to generic ML, the problem-specific ML can achieve higher performance, lower complexity and symmetry.
HoloVIC: Large-scale Dataset and Benchmark for Multi-Sensor Holographic Intersection and Vehicle-Infrastructure Cooperative
Mar 06, 2024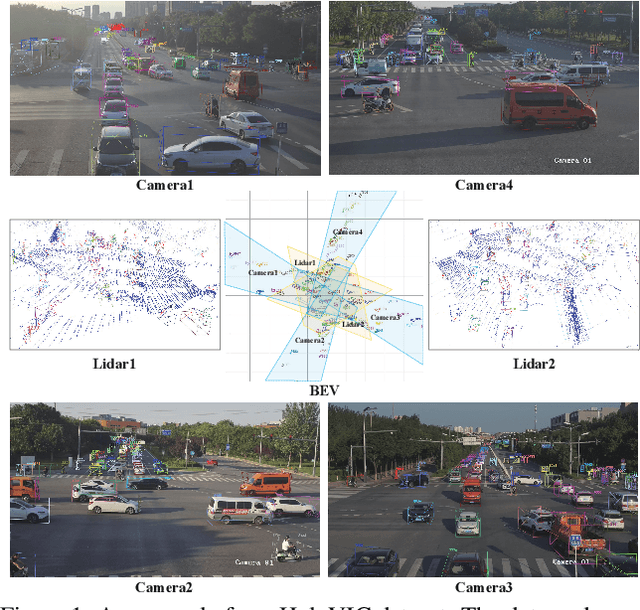
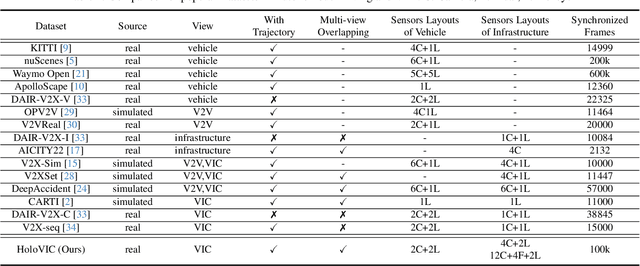
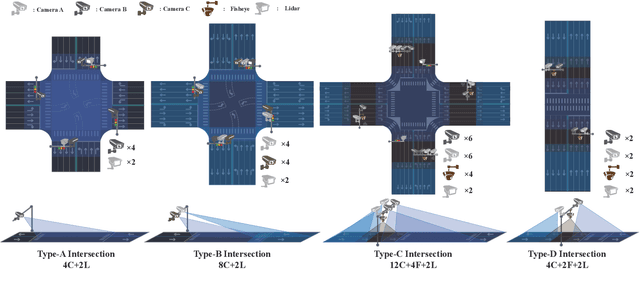
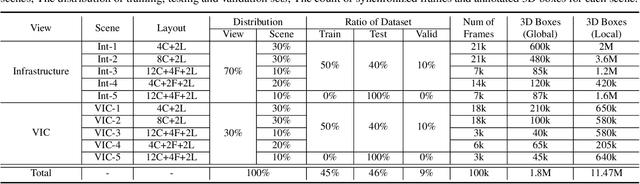
Vehicle-to-everything (V2X) is a popular topic in the field of Autonomous Driving in recent years. Vehicle-infrastructure cooperation (VIC) becomes one of the important research area. Due to the complexity of traffic conditions such as blind spots and occlusion, it greatly limits the perception capabilities of single-view roadside sensing systems. To further enhance the accuracy of roadside perception and provide better information to the vehicle side, in this paper, we constructed holographic intersections with various layouts to build a large-scale multi-sensor holographic vehicle-infrastructure cooperation dataset, called HoloVIC. Our dataset includes 3 different types of sensors (Camera, Lidar, Fisheye) and employs 4 sensor-layouts based on the different intersections. Each intersection is equipped with 6-18 sensors to capture synchronous data. While autonomous vehicles pass through these intersections for collecting VIC data. HoloVIC contains in total on 100k+ synchronous frames from different sensors. Additionally, we annotated 3D bounding boxes based on Camera, Fisheye, and Lidar. We also associate the IDs of the same objects across different devices and consecutive frames in sequence. Based on HoloVIC, we formulated four tasks to facilitate the development of related research. We also provide benchmarks for these tasks.
FedHCDR: Federated Cross-Domain Recommendation with Hypergraph Signal Decoupling
Mar 06, 2024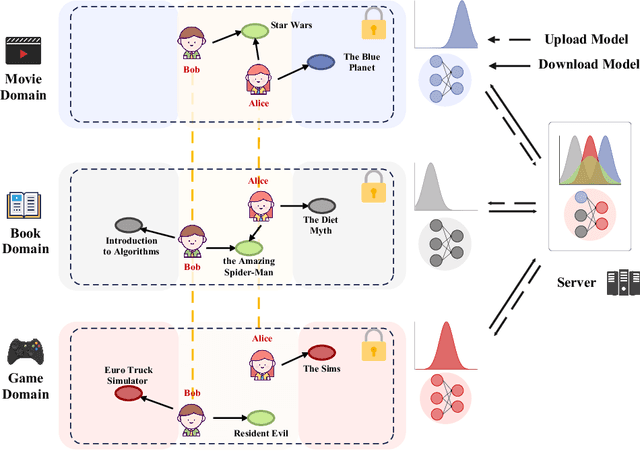
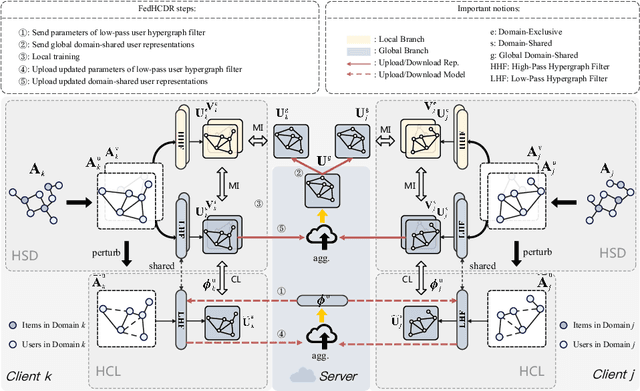
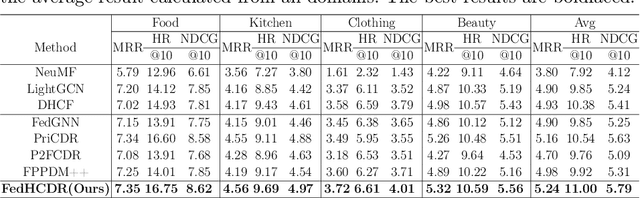
In recent years, Cross-Domain Recommendation (CDR) has drawn significant attention, which utilizes user data from multiple domains to enhance the recommendation performance. However, current CDR methods require sharing user data across domains, thereby violating the General Data Protection Regulation (GDPR). Consequently, numerous approaches have been proposed for Federated Cross-Domain Recommendation (FedCDR). Nevertheless, the data heterogeneity across different domains inevitably influences the overall performance of federated learning. In this study, we propose FedHCDR, a novel Federated Cross-Domain Recommendation framework with Hypergraph signal decoupling. Specifically, to address the data heterogeneity across domains, we introduce an approach called hypergraph signal decoupling (HSD) to decouple the user features into domain-exclusive and domain-shared features. The approach employs high-pass and low-pass hypergraph filters to decouple domain-exclusive and domain-shared user representations, which are trained by the local-global bi-directional transfer algorithm. In addition, a hypergraph contrastive learning (HCL) module is devised to enhance the learning of domain-shared user relationship information by perturbing the user hypergraph. Extensive experiments conducted on three real-world scenarios demonstrate that FedHCDR outperforms existing baselines significantly.
ZF Beamforming Tensor Compression for Massive MIMO Fronthaul
Mar 06, 2024
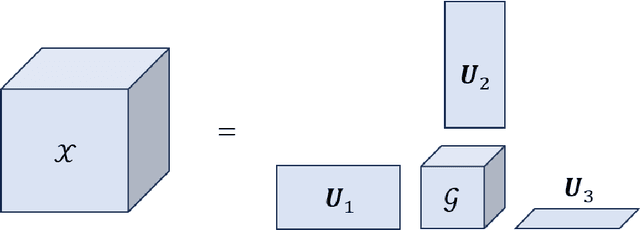
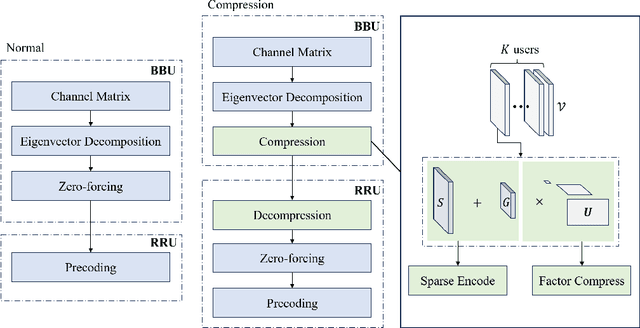
In the rapidly evolving landscape of 5G and beyond 5G (B5G) mobile cellular communications, efficient data compression and reconstruction strategies become paramount, especially in massive multiple-input multiple-output (MIMO) systems. A critical challenge in these systems is the capacity-limited fronthaul, particularly in the context of the Ethernet-based common public radio interface (eCPRI) connecting baseband units (BBUs) and remote radio units (RRUs). This capacity limitation hinders the effective handling of increased traffic and data flows. We propose a novel two-stage compression approach to address this bottleneck. The first stage employs sparse Tucker decomposition, targeting the weight tensor's low-rank components for compression. The second stage further compresses these components using complex givens decomposition and run-length encoding, substantially improving the compression ratio. Our approach specifically targets the Zero-Forcing (ZF) beamforming weights in BBUs. By reconstructing these weights in RRUs, we significantly alleviate the burden on eCPRI traffic, enabling a higher number of concurrent streams in the radio access network (RAN). Through comprehensive evaluations, we demonstrate the superior effectiveness of our method in Channel State Information (CSI) compression, paving the way for more efficient 5G/B5G fronthaul links.
Prompt Mining for Language-based Human Mobility Forecasting
Mar 06, 2024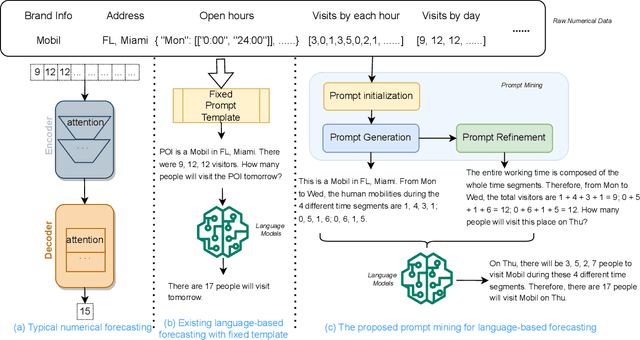
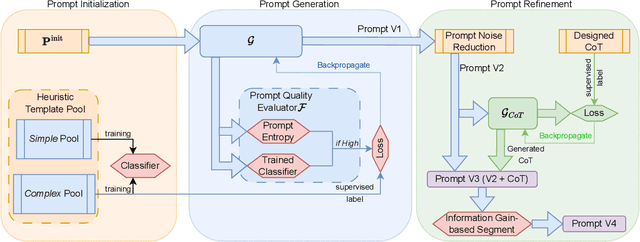

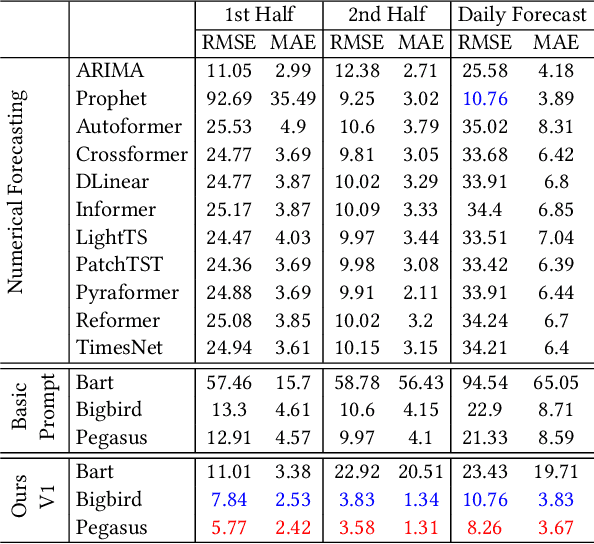
With the advancement of large language models, language-based forecasting has recently emerged as an innovative approach for predicting human mobility patterns. The core idea is to use prompts to transform the raw mobility data given as numerical values into natural language sentences so that the language models can be leveraged to generate the description for future observations. However, previous studies have only employed fixed and manually designed templates to transform numerical values into sentences. Since the forecasting performance of language models heavily relies on prompts, using fixed templates for prompting may limit the forecasting capability of language models. In this paper, we propose a novel framework for prompt mining in language-based mobility forecasting, aiming to explore diverse prompt design strategies. Specifically, the framework includes a prompt generation stage based on the information entropy of prompts and a prompt refinement stage to integrate mechanisms such as the chain of thought. Experimental results on real-world large-scale data demonstrate the superiority of generated prompts from our prompt mining pipeline. Additionally, the comparison of different prompt variants shows that the proposed prompt refinement process is effective. Our study presents a promising direction for further advancing language-based mobility forecasting.
Automated Multi-Task Learning for Joint Disease Prediction on Electronic Health Records
Mar 06, 2024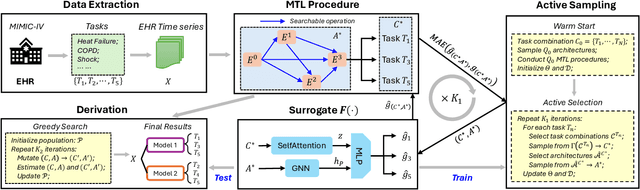
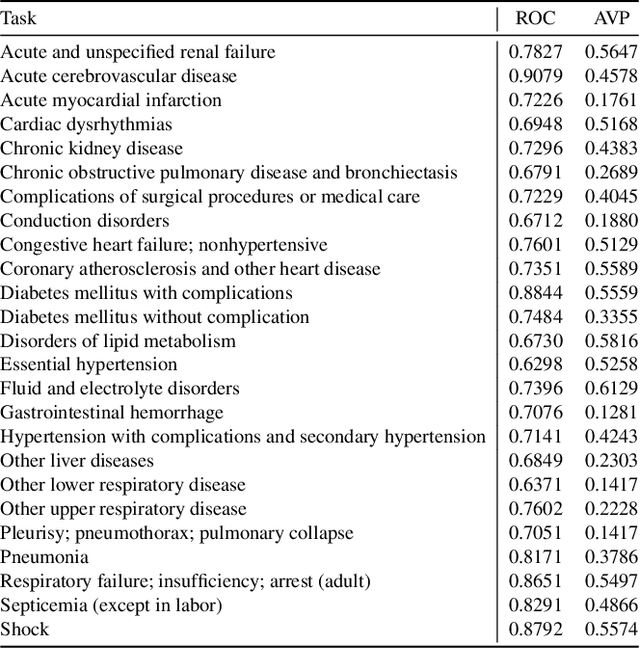
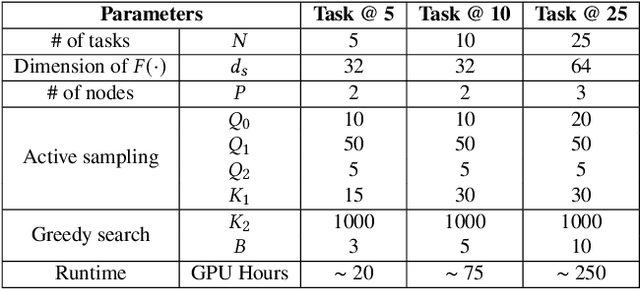
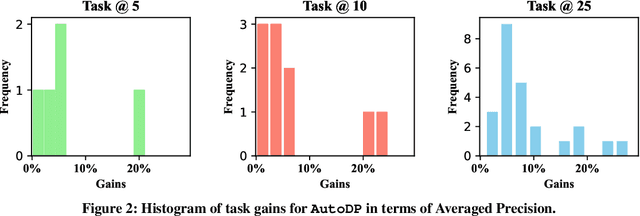
In the realm of big data and digital healthcare, Electronic Health Records (EHR) have become a rich source of information with the potential to improve patient care and medical research. In recent years, machine learning models have proliferated for analyzing EHR data to predict patients future health conditions. Among them, some studies advocate for multi-task learning (MTL) to jointly predict multiple target diseases for improving the prediction performance over single task learning. Nevertheless, current MTL frameworks for EHR data have significant limitations due to their heavy reliance on human experts to identify task groups for joint training and design model architectures. To reduce human intervention and improve the framework design, we propose an automated approach named AutoDP, which can search for the optimal configuration of task grouping and architectures simultaneously. To tackle the vast joint search space encompassing task combinations and architectures, we employ surrogate model-based optimization, enabling us to efficiently discover the optimal solution. Experimental results on real-world EHR data demonstrate the efficacy of the proposed AutoDP framework. It achieves significant performance improvements over both hand-crafted and automated state-of-the-art methods, also maintains a feasible search cost at the same time.
Reducing the dimensionality and granularity in hierarchical categorical variables
Mar 06, 2024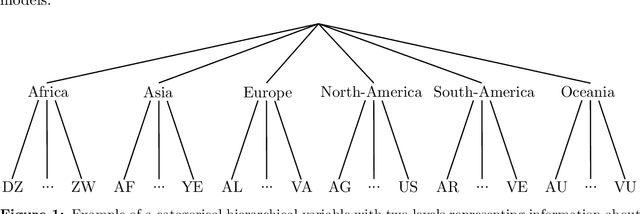
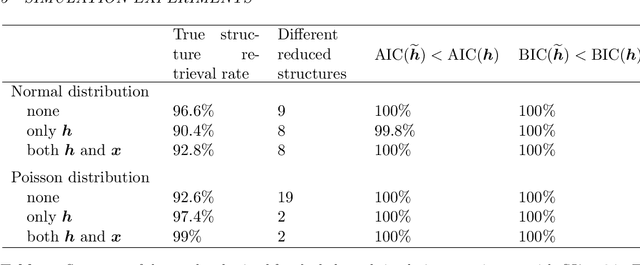
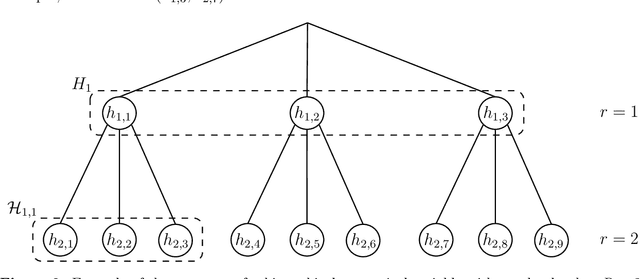
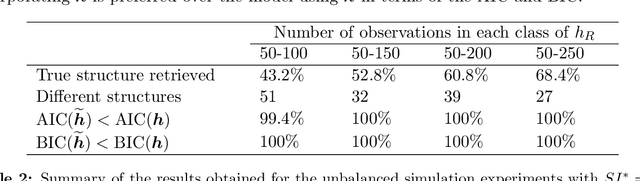
Hierarchical categorical variables often exhibit many levels (high granularity) and many classes within each level (high dimensionality). This may cause overfitting and estimation issues when including such covariates in a predictive model. In current literature, a hierarchical covariate is often incorporated via nested random effects. However, this does not facilitate the assumption of classes having the same effect on the response variable. In this paper, we propose a methodology to obtain a reduced representation of a hierarchical categorical variable. We show how entity embedding can be applied in a hierarchical setting. Subsequently, we propose a top-down clustering algorithm which leverages the information encoded in the embeddings to reduce both the within-level dimensionality as well as the overall granularity of the hierarchical categorical variable. In simulation experiments, we show that our methodology can effectively approximate the true underlying structure of a hierarchical covariate in terms of the effect on a response variable, and find that incorporating the reduced hierarchy improves model fit. We apply our methodology on a real dataset and find that the reduced hierarchy is an improvement over the original hierarchical structure and reduced structures proposed in the literature.
Guiding Enumerative Program Synthesis with Large Language Models
Mar 06, 2024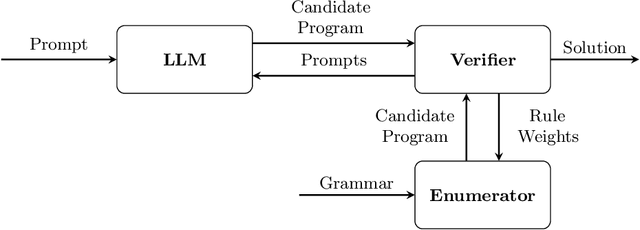
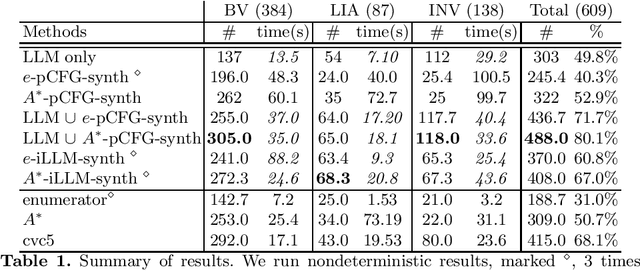
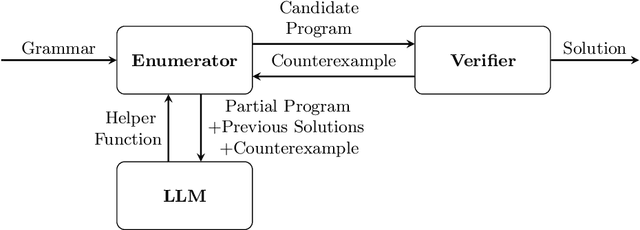
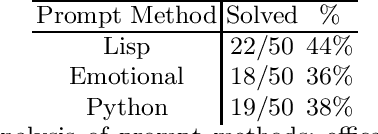
Pre-trained Large Language Models (LLMs) are beginning to dominate the discourse around automatic code generation with natural language specifications. In contrast, the best-performing synthesizers in the domain of formal synthesis with precise logical specifications are still based on enumerative algorithms. In this paper, we evaluate the abilities of LLMs to solve formal synthesis benchmarks by carefully crafting a library of prompts for the domain. When one-shot synthesis fails, we propose a novel enumerative synthesis algorithm, which integrates calls to an LLM into a weighted probabilistic search. This allows the synthesizer to provide the LLM with information about the progress of the enumerator, and the LLM to provide the enumerator with syntactic guidance in an iterative loop. We evaluate our techniques on benchmarks from the Syntax-Guided Synthesis (SyGuS) competition. We find that GPT-3.5 as a stand-alone tool for formal synthesis is easily outperformed by state-of-the-art formal synthesis algorithms, but our approach integrating the LLM into an enumerative synthesis algorithm shows significant performance gains over both the LLM and the enumerative synthesizer alone and the winning SyGuS competition tool.
Map-aided annotation for pole base detection
Mar 04, 2024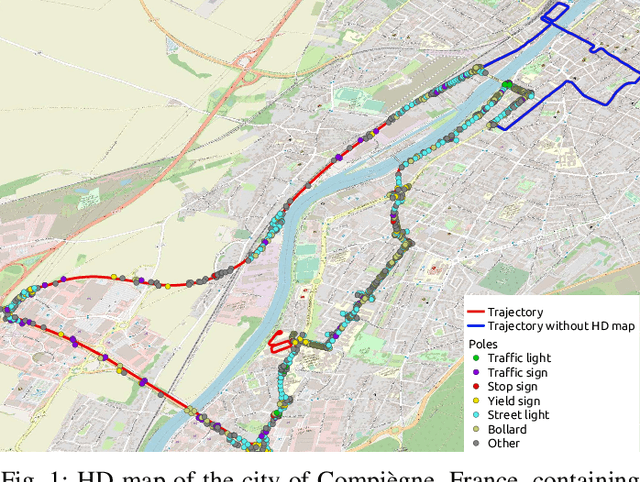



For autonomous navigation, high definition maps are a widely used source of information. Pole-like features encoded in HD maps such as traffic signs, traffic lights or street lights can be used as landmarks for localization. For this purpose, they first need to be detected by the vehicle using its embedded sensors. While geometric models can be used to process 3D point clouds retrieved by lidar sensors, modern image-based approaches rely on deep neural network and therefore heavily depend on annotated training data. In this paper, a 2D HD map is used to automatically annotate pole-like features in images. In the absence of height information, the map features are represented as pole bases at the ground level. We show how an additional lidar sensor can be used to filter out occluded features and refine the ground projection. We also demonstrate how an object detector can be trained to detect a pole base. To evaluate our methodology, it is first validated with data manually annotated from semantic segmentation and then compared to our own automatically generated annotated data recorded in the city of Compi{\`e}gne, France. Erratum: In the original version [1], an error occurred in the accuracy evaluation of the different models studied and the evaluation method applied on the detection results was not clearly defined. In this revision, we offer a rectification to this segment, presenting updated results, especially in terms of Mean Absolute Errors (MAE).
Evaluating the Explainability of Neural Rankers
Mar 04, 2024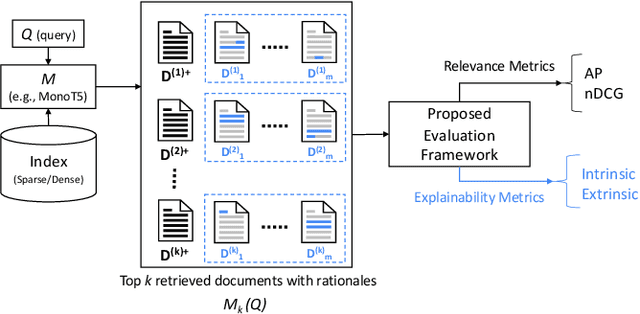
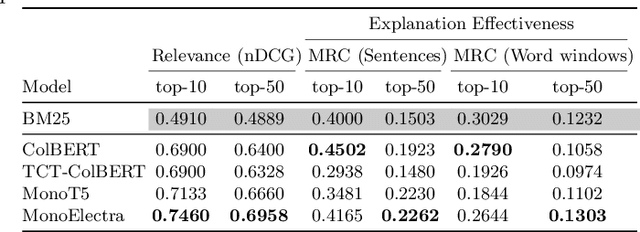
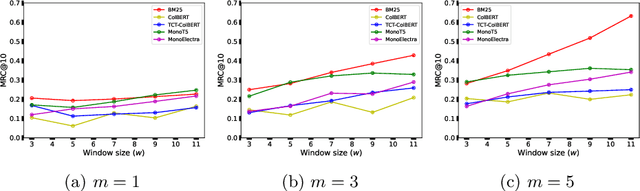
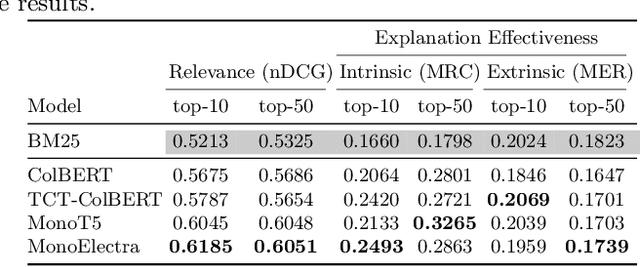
Information retrieval models have witnessed a paradigm shift from unsupervised statistical approaches to feature-based supervised approaches to completely data-driven ones that make use of the pre-training of large language models. While the increasing complexity of the search models have been able to demonstrate improvements in effectiveness (measured in terms of relevance of top-retrieved results), a question worthy of a thorough inspection is - "how explainable are these models?", which is what this paper aims to evaluate. In particular, we propose a common evaluation platform to systematically evaluate the explainability of any ranking model (the explanation algorithm being identical for all the models that are to be evaluated). In our proposed framework, each model, in addition to returning a ranked list of documents, also requires to return a list of explanation units or rationales for each document. This meta-information from each document is then used to measure how locally consistent these rationales are as an intrinsic measure of interpretability - one that does not require manual relevance assessments. Additionally, as an extrinsic measure, we compute how relevant these rationales are by leveraging sub-document level relevance assessments. Our findings show a number of interesting observations, such as sentence-level rationales are more consistent, an increase in complexity mostly leads to less consistent explanations, and that interpretability measures offer a complementary dimension of evaluation of IR systems because consistency is not well-correlated with nDCG at top ranks.